Многие из вас уже заметили, что искусственный интеллект активно проникает во все сферы нашей жизни. Он проникает и в бизнес, а задачи бизнеса так или иначе связаны с интеграциями. Ведь мало где можно встретить огромный мегамонолит или группу разрозненных микросервисов, которые не взаимодействуют друг с другом и с внешним миром. Поэтому было бы странно, если бы для решения подобных задач не применялись технологии и инструменты искусственного интеллекта, существующие на текущий момент.
Я хотел бы рассказать об инструменте, который позволяет эффективно решать задачи интеграции, используя под капотом мощный инструментарий агентов искусственного интеллекта.
Эволюция n8n: от простых задач к AI-агентам
В 2021 году на конференции «Инфостарт» я впервые рассказал об инструменте n8n. В то время я активно использовал его в работе для автоматизации рутинных задач и небольшого числа задач интеграции с простыми обменами, так как на тот момент у инструмента были серьезные проблемы с производительностью, которая проявлялась на высоконагруженных интеграциях.
Но продукт не стоит на месте и разработчики, прислушавшись к сообществу, проделали серьезную работу над оптимизацией производительности.
А через некоторое время они добавили возможность включения высокопроизводительного режима, при правильной настройке которого производительность n8n возрастает в десятки раз.
Но действительно популярным n8n сделало появление агентов искусственного интеллекта – AI-агентов. Они были добавлены в 2023 году, а уже через год появилась поддержка MCP-клиентов и RAG. Можно сказать, что именно 2023 год стал началом активного, «хайпового» развития этого продукта.
Прикладной AI и реальные кейсы
В этой статье я не буду подробно рассказывать, как строить рабочие процессы в n8n или разбирать его особенности, которые легко изучить по документации или же с помощью видео, которые в огромном количестве можно найти на видеохостингах. Например, на YouTube. Я сосредоточусь на прикладном инструментарии AI, встроенном в n8n, и кейсах его применения в реальных бизнес-задачах. Поделюсь лайфхаками и подходами, которые использую в работе и приемами, которые действительно помогают. В заключение затрону тему безопасности и производительности в продуктовой среде, так как, на мой взгляд, это действительно важно, а также поделюсь полезными ссылками.
Перед тем, как перейти к кейсам, коротко расскажу об n8n, чтобы дать общее представление о том, что это за инструмент.
n8n: оркестратор рабочих процессов
n8n – это оркестратор рабочих процессов. Можно строить практически неограниченное количество рабочих процессов. Для этого используются строительные блоки – ноды (или узлы). Ноды бывают нескольких типов:
-
Ноды интеграции – например, с Rabbit, Kafka или произвольным API стороннего поставщика.
-
Ноды действий: проверка условий, циклы, разветвления, точки соединения.
-
Ноды выполнения произвольного кода – на JavaScript или Python. n8n это поддерживает и работает по принципу, аналогичному методу «Выполнить» в платформе 1С.
На текущий момент существует уже более 500 нод, и это только те, которые официально разрабатываются вендером. Так как продукт опенсоурсовый, у него есть комьюнити, а это еще примерно 3,5 тысячи нод. Например, среди них можно найти ноды для интеграции с «Битрикс24» или с мессенджером Max. Такая интеграция, созданная в n8n, будет работать стабильно – даже с парковки. Проверено лично.
Чтобы процесс построения нод и рабочих процессов был не утомительным, а более творческим, я рекомендую использовать шаблоны (templates), размещенные в библиотеке n8n. Там можно подсмотреть идеи и подходы, развернуть готовые шаблоны и автоматизировать целые участки работы. Это экономит время и высвобождает ресурсы для решения других задач.
Кейс 1: Telegram-бот с LLM и памятью
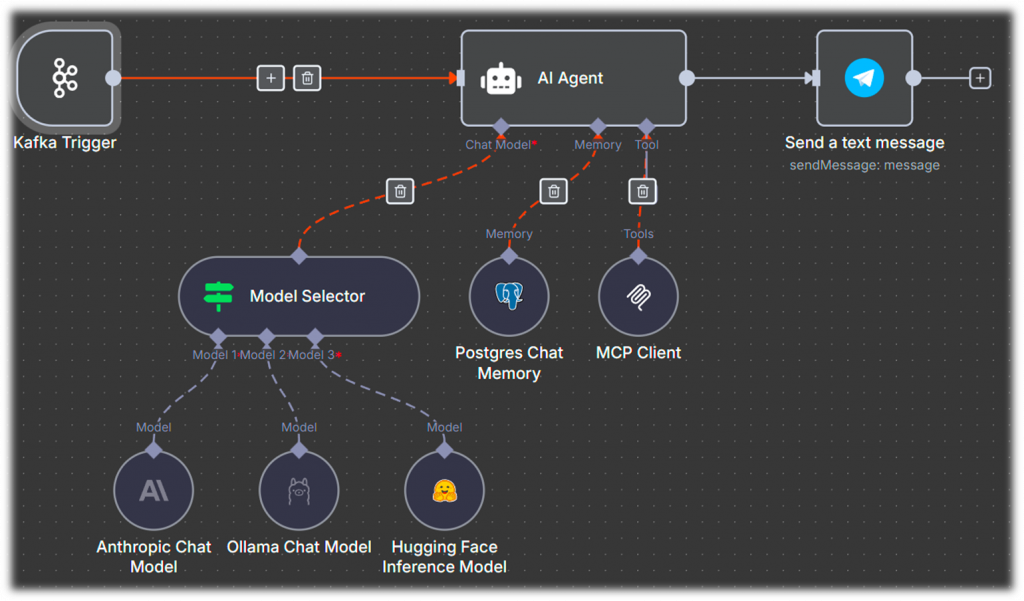
Наш первый кейс, как бы это странно в наше время не звучало – Telegram-бот. Но не простой бот: под капотом у него будет модель LLM и память. Этот бот будет знать и помнить историю взаимодействия с пользователем.
На видео показано, как мы за пару минут создаем такого бота без единой строчки кода. Он будет реальным, живым и способным отвечать на запросы пользователя. Демонстрацию в формате mp4 вы можете скачать по ссылке https://disk.yandex.ru/i/Bf_8ZDvcvUa9vQ.
Я заранее зарегистрировал учетную запись DeepSeek, а также бота в Telegram и отправил ему сообщение с вопросом, как сделать паузу на языке 1С. Достаточно простой, но популярный вопрос.
В n8n я внес токены доступов к боту и DeepSeek в Credentials. Это делается достаточно просто и подробно описано в документации (https://docs.n8n.io/credentials/add-edit-credentials/#create-a-credential).
Далее в n8n добавляется нода Telegram, которая реагирует на все новые входящие сообщения. После ее добавления выполняем ноду и видим схему полей, поступающих от пользователя, и их значения – это важно, они понадобятся нам в дальнейшем, на других шагах.
Следующим шагом добавляется AI-агент – ключевой элемент процесса. В нем указывается, что входящие данные берутся из предыдущей ноды Telegram.
С помощью drag-and-drop перетаскиваем поле text – это промпт, который передается модели. Далее указываем роль. Ее можно не задавать, но для корректного поведения модели важно определить system message, то есть системный промт, в котором мы и прописываем роль нашего агента. В данном случае я выбираю роль консультанта по программированию на языке 1С.
Следующий шаг – подключить агенту «мозги», а «мозги» – это, по сути, модельки. Справа доступен список актуальных моделей, и для примера я выбираю DeepSeek.
Чтобы агент обладал памятью, добавляем ноду Simple Memory, входящую в стандартный набор n8n, и с помощью drag-and-drop перетаскиваем в поле key значение chatId. Это нужно, чтобы история сохранялась в разрезе каждого конкретного чата.
Одно из интересных преимуществ n8n – каждую ноду можно дебажить, выполнить отдельно и увидеть input/output потоки данных: что поступает на вход и что выходит на выход. Это удобно для отладки, переиспользования и анализа поведения нод в процессе работы.
Внизу, в поле output, сформировался ответ. Он не представляет особого интереса, потому что современные модели обычно выдают ерунду на вопрос о том, как сделать паузу в 1С.
Последний шаг – отправить сообщение обратно пользователю в чат. Для этого подключаем ноду Telegram с операцией Send Message, с помощью drag-and-drop перетягиваем chatId и передаем output, полученный от модели. После выполнения ноды видим результат true – бот готов. Он получает сообщение, обрабатывает его и отправляет ответ.
Показывать, как именно это выглядит в Telegram, не буду – там слишком много рабочих чатов. Главное, что процесс полностью рабочий: его остается только активировать, и он будет функционировать в фоне без участия человека.
У этого подхода есть ряд преимуществ. Модель можно заменять «на горячую». Ноду памяти можно поменять на Postgres, чтобы получить постоянное хранилище данных. Кроме того, можно добавить другие каналы – например, «Битрикс24» или мессенджер Max, создав мультимессенджер для взаимодействия с ботом.
Таким образом, пользователь может начать диалог с ботом в Telegram, а дома продолжить переписку с компьютера в другом мессенджере. Благодаря встроенной памяти бот будет помнить историю общения и бесшовно поддерживать диалог.
Ограничения бота и расширение возможностей
Но у такого подхода есть один большой существенный минус. Он заключается в том, что наш бот никак не взаимодействует с внешним миром и наделен теми знаниями, которые были получены моделью на момент ее обучения.
У DeepSeeker точка среза знания – июль 2024 года. Это протухшие знания, и это минус. Чтобы нивелировать этот недостаток и расширить возможности n8n и агентов, в n8n есть возможность использования внешних инструментов – tools, а конкретно:
-
MCP клиентов,
-
Векторных хранилищ,
-
HTTP Request,
-
Вложенных рабочих процессовы n8n,
-
Агентов AI (вложенность не ограничена).
Эти tools могут быть MCP-клиентами, которые подключаются к MCP-серверам, обеспечивая выход во внешний мир – например, в поисковые системы. Это могут быть корпоративные хранилища знаний – например, база знаний компании в векторном хранилище. Это могут быть вложенные подпроцессы или другие агенты. Причем, подключая в качестве tools к агенту других агентов, мы организуем иерархическую структуру выполнения задач, и это равносильно поручениям внутри компании.
Используя знания по tools, применим их в следующем кейсе.
Кейс 2: Расширенный бот поддержки с голосовым управлением и доступом к базе знаний
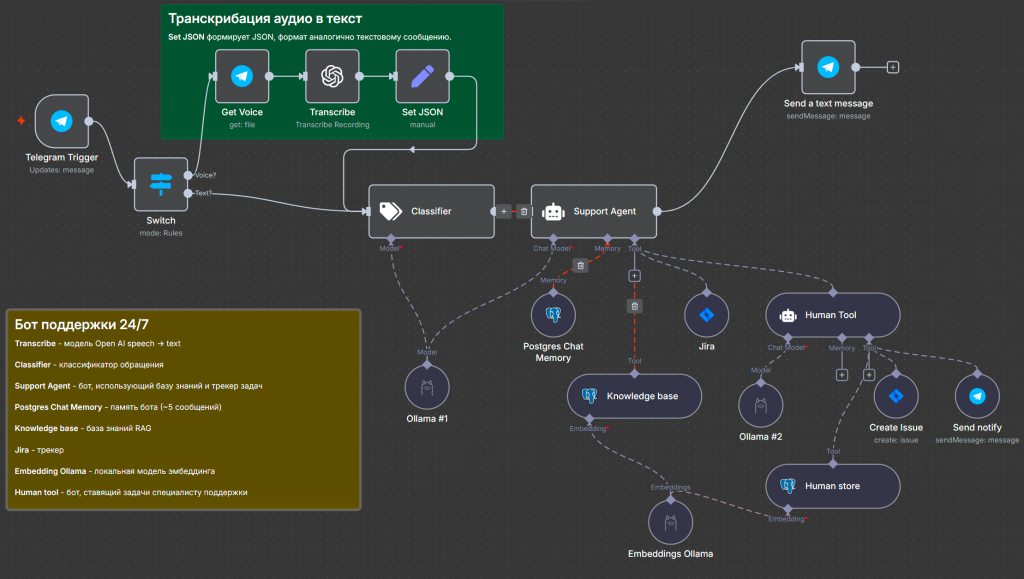
Мы расширим возможности нашего бота, чтобы он мог обращаться к базе знаний нашей компании, управлять трекером задач, и с таким ботом можно было взаимодействовать по средствам голосового управления.
Для этого мы можем копировать рабочий процесс или взять тот же самый процесс с простеньким ботом и слегка его модифицировать. Здесь никакого кодинга не потребуется.
Мы размещаем ноду Switch – переключатель, который анализирует, что подается на вход: текст или голосовое сообщение из Telegram. Если приходит голосовое сообщение, выполняем транскрибацию с помощью ноды OpenAI. Ее можно заменить на комьюнити-ноду транскрибации от «Яндекса» – будет работать, но немного хуже. Нодой Set JSON я преобразую полученный текст, чтобы формат сообщения был аналогичен текстовому сообщению в Telegram. Это важно.
Следующий шаг – классификация. Добавлена нода Classifier. Она использует под капотом модель LLM и классифицирует входящий текст по категориям: обращение, связанное с работой программы (например, 1С) или принтера, либо произвольные вопросы по кадровой структуре – где находится сотрудник или к кому обратиться по поводу зарплаты. Поэтому классификация важна.
Весь полученный текст вместе с классификацией передается ноде агента. Агент, используя эту информацию, идет в tools Jira и проверяет, есть ли последние закрытые обращения по теме. Если находит, генерирует и подготавливает ответ для пользователя. Если нет, обращается к векторной базе знаний, где хранятся знания компании. По сути, это нода Postgres с расширением «Vector».
Можно было бы отправить ответ пользователю, но на любом участке, где задействован искусственный интеллект, должен быть человек для контроля, проверки, модификации промптов и настройки агентов. Это непрерывный процесс.
В tools подключена нода Human Tool, которая делает следующее: агент создает Jira issue, идет в векторную базу, смотрит по классификации, кого из сотрудников можно назначить на задачу, описывает ее вместе с полученными из базы знаний ответами, формирует issue и отправляет ответственному сотруднику, затем передает управление обратно в ключевую ноду агента. Агент собирает полную картину с назначенным сотрудником, ответом и номером задачи и отправляет сообщение пользователю. В результате получается агент поддержки, который способен разгрузить работу сотрудников поддержки.
Кейс 3: Загрузка базы знаний в векторное хранилище
В предыдущем кейсе мы получали информацию из базы знаний в векторном хранилище. Но чтобы эти знания там оказались, их нужно сначала туда добавить.
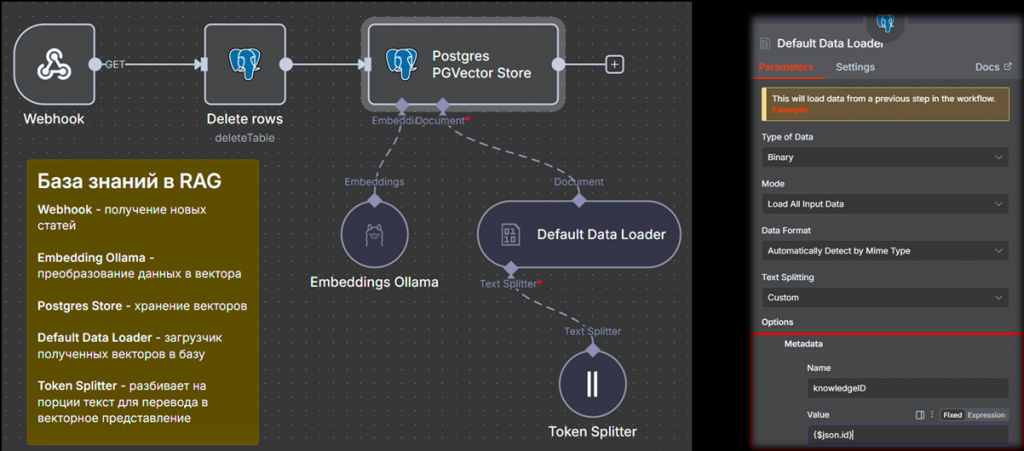
В этом кейсе разберем подход, позволяющий загружать базу знаний в векторное хранилище.
Есть неправильный способ – взять всю базу знаний, например из «Битрикса», и выполнить парсинг или скраппинг. Этот метод плох тем, что:
-
Большинство страниц содержит динамический JS-код.
-
Весь текст нужно передать модели, а модели, как мы знаем, ограничены длиной контекстного окна. Даже если уложиться в лимит, со временем закончится количество доступных токенов. У локальных моделей ограничение контекстного окна тоже сохраняется.
Более правильный подход – сначала привести базу знаний в порядок: нормализовать, структурировать, выделить категории, проставить теги, а затем заняться загрузкой данных в векторное хранилище.
В примере используется микросервис, который отслеживает изменения и добавление новых статей, а также их категории.
Далее он вызывает рабочий процесс n8n, который начинается с Webhook. Webhook превращает рабочий процесс в HTTP-публикацию, если говорить на языке 1С – это HTTP-сервис, принимающий данные на вход извне. Сервис отправляет информацию о новых или измененных статьях на Webhook. Далее текст разбивается на порции и преобразуется в математическое векторное представление – так называемый эмбеддинг.
С помощью ноды Default Data Loader все данные загружаются в векторное хранилище. На первый взгляд кажется сложно, но в n8n, в библиотеке нод, можно найти более тысячи решений с использованием разных хранилищ. Есть даже загрузка из Excel и PDF – все работает. Единственный нюанс – правильно подобрать модель эмбеддинга. Как это сделать – я расскажу в разделе с лайфхаками.
А теперь давайте вернемся к реальности и поговорим про бухгалтерию.
Кейс 4: Распределение платежей с помощью AI-агента
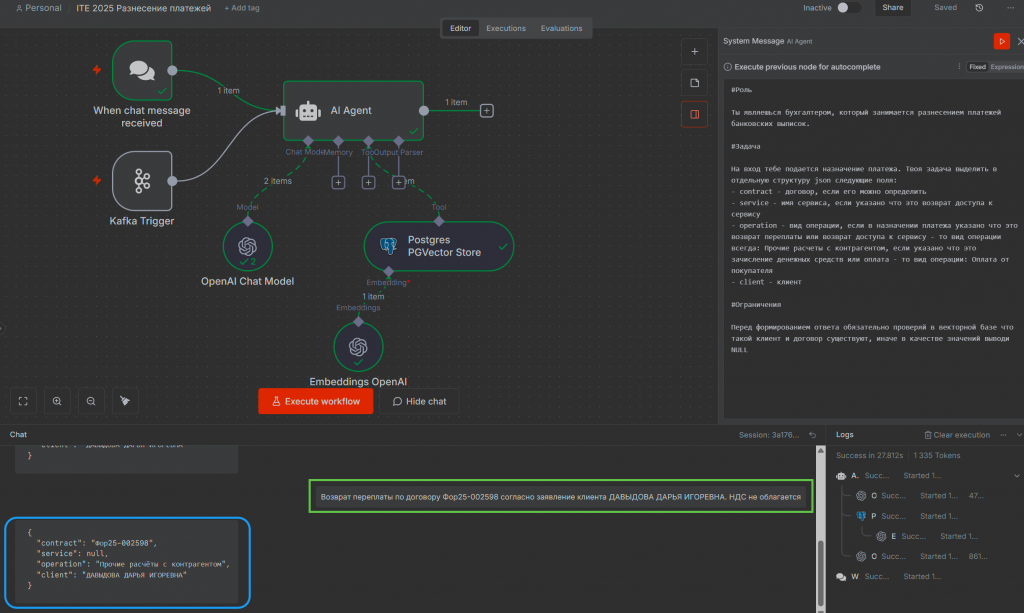
Как известно, бухгалтерия не может жить без финансового блока. В частности, без задачи распределения платежей – парсинга и анализа назначений платежей. С появлением n8n и AI-агентов эта задача получила новое развитие.
Ключевое преимущество в том, что больше не нужно применять классические подходы. Достаточно написать промпт, в котором детально указывается, как интерпретировать назначение платежа, какие поля нужно извлечь и в каком формате – например, в виде JSON.
Есть важный нюанс: при распределении назначений платежей нужно проверять, есть ли договор в базе 1С. Если договора нет, выполняются дальнейшие действия, предусмотренные процессом. Например, если договор не найден, мы не распределяем платеж, уведомляем сотрудника или откладываем запись в другую очередь.
Для этого подключено внешнее хранилище на Postgres, куда данные из 1С выгружаются событийно. Когда в 1С создается договор или он загружается через документооборот, срабатывает CDC, и через Apache Kafka данные попадают в векторное хранилище.
Такой подход хорош тем, что бухгалтер может сам видеть, как все работает в n8n – наглядные стрелки, интерфейсы, визуальная логика. Если бухгалтер хочет развиваться и погрузиться в тему AI, он может самостоятельно подправить промпт при изменении правил и без привлечения программиста обновить процесс.
В результате мы получаем FinOps-ресурс – FinOps-инженера в лице бухгалтера.
Кейс 5: OCR и проверка подлинности чеков
Следующий кейс – задача OCR. Мы хотим парсить чеки, распознавать их, получать товарные позиции и одновременно проверять, не является ли чек подделкой.
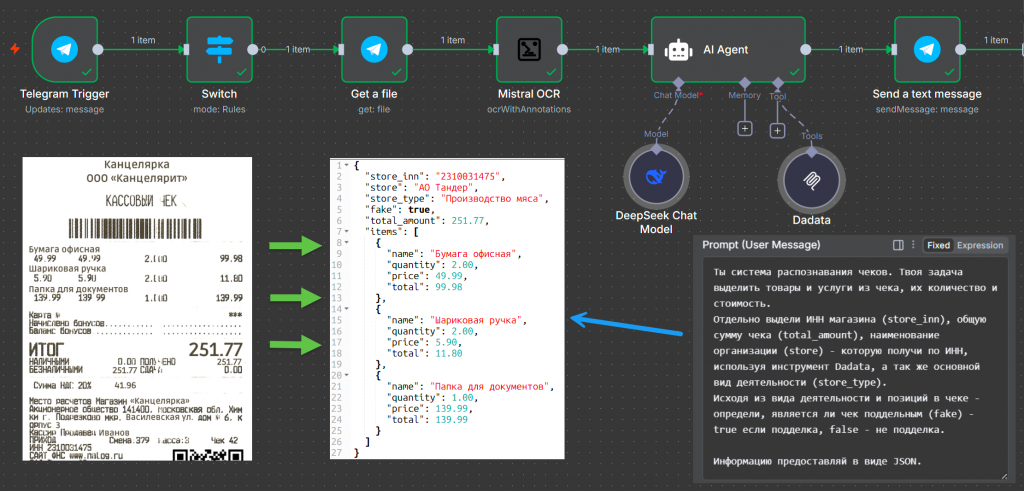
Это достаточно просто. Сейчас больше не нужно писать скрипты на Python, размечать тренировочные данные и обучать модели. Достаточно использовать n8n. В этом примере для распознавания я использовал комьюнити-ноду от Mistral – Mistral OCR. Эта модель эффективно справляется с распознаванием чеков, инвойсов, накладных и других документов, поэтому я подключил именно ее.
Следующий шаг – проверка контрагента. Получив товарные позиции и ИНН из чека, я проверяю, действительно ли контрагент, указанный в чеке и определенный по ИНН, занимается тем, что указано в документе. Тем самым мы можем косвенно определить, является ли чек подделкой.
Для этого полученный ИНН передаем на вход инструменту MCP-клиента, который подключается к серверу Dadata. У Dadata есть MCP-сервер, позволяющий получать информацию о клиенте по ИНН, телефону, адресу, а также проверять его благонадежность.
Мы передаем данные в Dadata и в промпте указываем, что хотим получить вид деятельности и наименование клиента. Затем сверяем полученные сведения с тем, что указано в чеке. Например, у организации вид деятельности – мясоразделка и свиноводство, а в чеке указана покупка карандашей. При этом наименование организации в чеке не совпадает с тем, что возвращает Dadata. Модель определяет, что чек не является настоящим.
Такой подход с обогащением данных, когда мы дополняем информацию о клиенте через обращение к Dadata, можно применять и в других задачах. Например, для обогащения лидов. Если из Bitrix поступает лид – холодный или горячий, неважно – и это юридическое лицо, мы можем обратиться к MCP-серверу Dadata, получить дополнительную информацию, обогатить лид, провести его классификацию и передать в рекомендательную систему или выполнить другие действия. Таким образом, сценарии применения инструмента не ограничены.
Кейс 6: n8n как MCP-сервер для анализа производительности
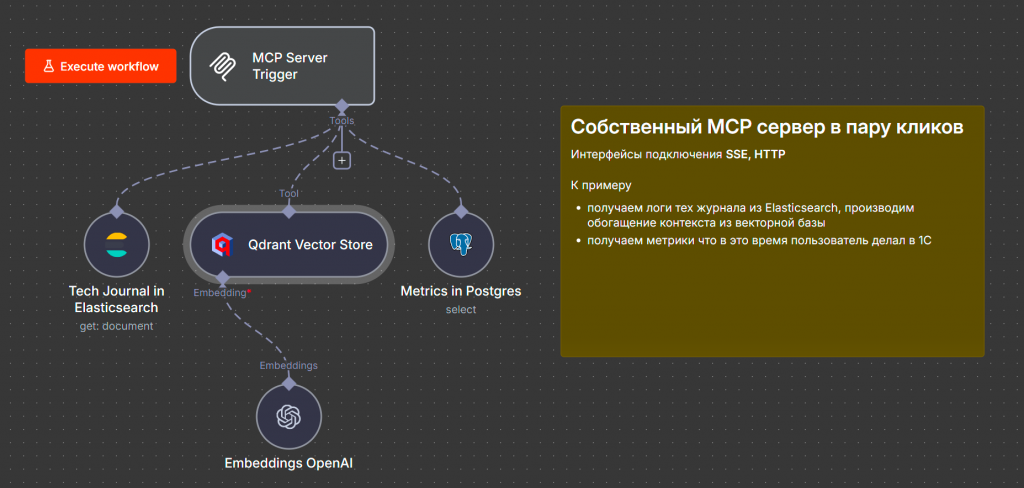
Последний кейс – это киллер-фича, появившаяся в n8n в версии 1.9.3. Она заключается в том, что теперь мы можем не только использовать MCP-клиентов и подключаться к MCP-серверам, но и превращать свой рабочий процесс в MCP-сервер без программирования.
В данном примере мы обращаемся к Elasticsearch, получаем технологический журнал, идем в векторную базу Qdrant, чтобы обогатить события из журнала метаданными, и подключаемся к Postgres, откуда получаем метрики работы оборудования и пользователей. После этого вся собранная информация передается обратно модели.
Таким образом, при анализе проблем производительности мы можем получить полную картину происходящего – кто какие действия выполнял, и что привело к сбою. Так что n8n может выступать как конструктор MCP-серверов практически без кодинга.
Лайфхаки по работе с n8n и AI-агентами
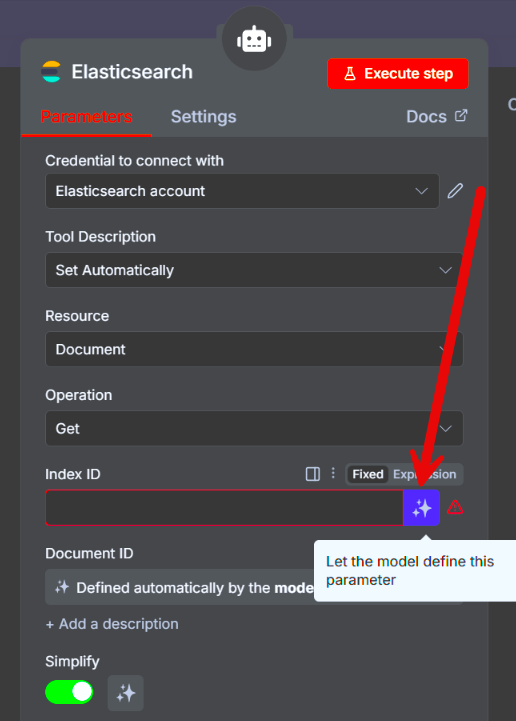
Большинство нод имеют возможность установки параметров, управляемых моделью. Нам не нужно ничего прописывать или кодить – достаточно нажать на три звездочки. Если нода подключена к агенту, модель сама определит значения параметров и передаст их в ноды. Это экономит время, и на практике не было случаев, чтобы модель ошиблась или подставила некорректные данные.
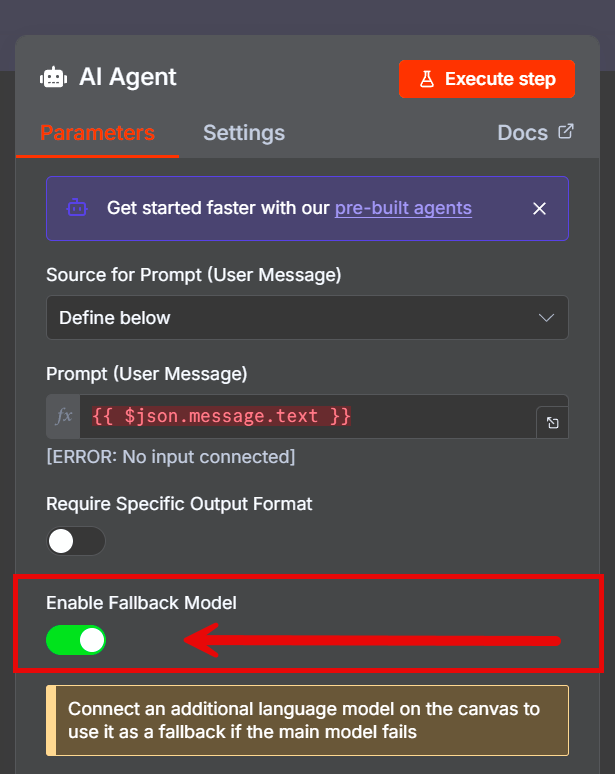
Второй лайфхак – использование резервной модели. Меня не раз выручала галочка Enable Fallback Model, доступная в любом агенте n8n.
Например, если у основной модели ChatGPT закончились токены, отключился VPN или произошел сбой, система автоматически и бесшовно переключится на резервную модель.
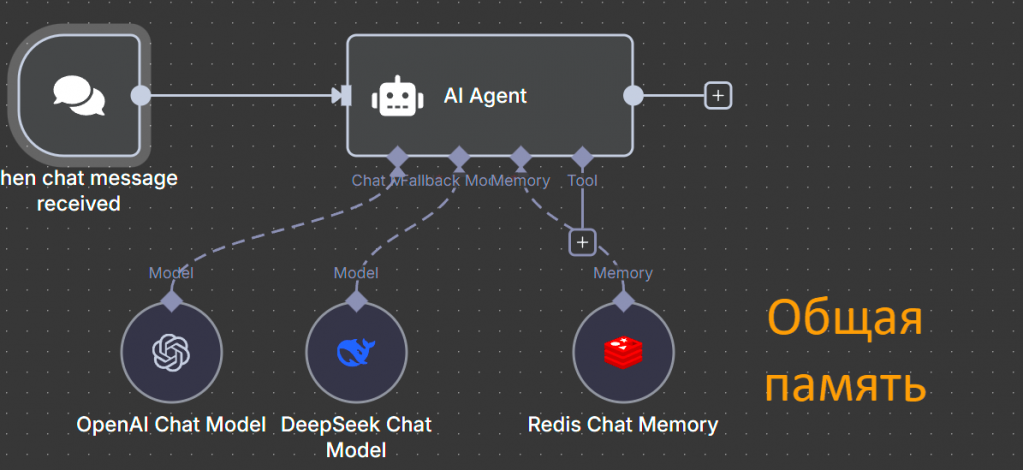
Если в дополнение использовать ноду памяти, переключение между моделями будет полностью бесшовным – диалог продолжится с того же места, и пользователь не заметит перехода.
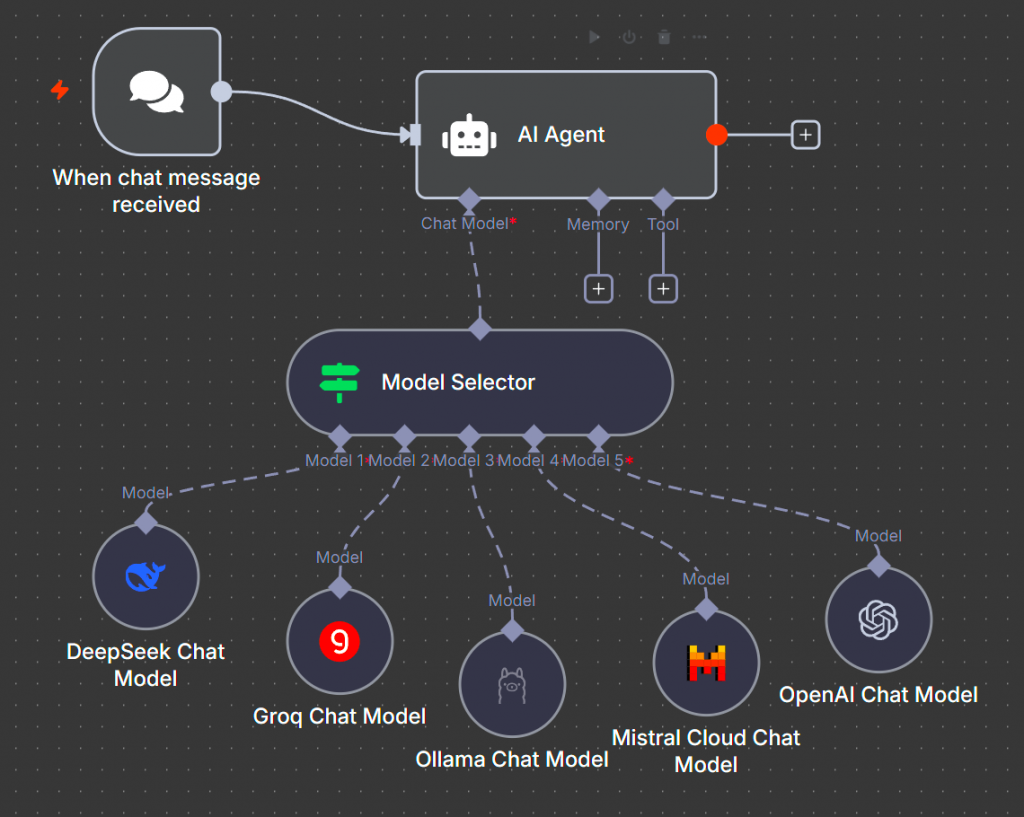
Мультимодельность – еще одна интересная фича n8n. Агенту можно подключить ноду Model Selector и выбрать от двух до десяти моделей. В промпте указывается, для каких кейсов используется каждая модель. Например, для задач по кодингу – Grok, для обработки больших текстов – локальные модели, чтобы не обращаться во внешний мир, а для обычного общения можно подключить DeepSeek.
Оптимизация RAG и выбор embedding-моделей
Немного про RAG и базы – как можно улучшить их работу.
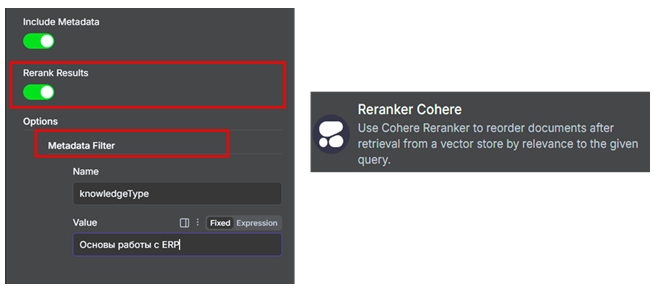
RAG – технология новая, но не лишенная недостатков. Выборку из векторного хранилища можно значительно улучшить, если включить одну галочку, которая есть у любой ноды векторного хранилища: использование кросс-энкодинга, или так называемого Reranking.
При его включении выполняется дополнительный скоринг выборки, и на вход модели передаются ответы с наивысшими значениями скоринг-балла. Кроме того, можно включить фильтрацию по метаданным, что еще больше повышает качество работы RAG.
Более продвинутые технологии – Light RAG и Graph RAG. Они используют подход, при котором в векторных базах хранятся связи между данными. LightRAG можно развернуть в Docker и подключить к n8n. Более зрелый и мощный вариант – использование RAGFlow.
Это корпоративный инструментарий, который можно развернуть с помощью Docker. В нем можно гибко и точно настраивать правила роутинга и выборки знаний.

Теперь о выборе эмбеддинг-модели. Тексты бывают разные: база знаний библиотеки и база знаний компании с техническими материалами требуют разных подходов. Универсальные модели использовать можно, но качество выборки при этом будет хуже.
Сервис Vectorize RAG Evaluation позволяет загрузить образец текста и получить рекомендацию, какая модель подойдет лучше всего и с какими параметрами. Эту модель можно подключить в n8n и использовать для загрузки знаний в векторное хранилище.
Рекомендации по проектированию и развертыванию рабочих процессов

Я сторонник подходов DRY и KISS, которые не усложняют рабочие процессы. Все, что можно вынести в отдельные подпроцессы, лучше так и сделать. Все, что можно заменить комьюнити-нодами, лучше тоже так сделать, потому что большие цепочки у того же Mistral заменяются одной нодой Mistral OCR из комьюнити библиотеки нод.
В последних версиях n8n появились подсказки: при создании рабочего процесса появляется мастер, который говорит, что необходимо сделать, чтобы рабочий процесс работал эффективно, был производительным и не падал.
И так как n8n хранит внутри себя любой рабочий процесс в виде JSON, любые рабочие процессы можно генерировать с помощью ChatGPT, GLM или DeepSeek. Они прекрасно понимают запрос «сделай мне такой-то рабочий процесс с такими-то нодами».

Немного про развертывание. Из этих четырех вариантов я рекомендую использовать последний. То есть арендовать виртуальную машину в публичном облаке, использовать образы Docker и развернуть это у себя. И обязательно включить высокопроизводительный режим, о котором я говорил в начале.
Безопасность, ограничения и отладка
https://docs.n8n.io/hosting/configuration/configuration-examples/isolation/
Даже если вы развернете n8n в локальном контуре, он будет отправлять на сервера разработчиков:
-
Метрики и телеметрию,
-
Проверки обновлений ядра,
-
Шаблоны и рекомендации,
-
Результаты диагностики.
Чтобы это отключить, можно установить один параметр в n8n. После этого мы перестаем получать информацию об обновлениях. Этот вопрос решаем, так как n8n – open source. Зайдите в GitHub, поставьте «звездочку» и тем самым вы подпишетесь на обновления релизов и появление нового функционала.
Ограничения тоже важны. При включении высокопроизводительного режима n8n перестает работать с локальным файловым хранилищем. Решение – установить любое локальное S3-хранилище, например Minio S3.
Если используются ноды кода с JS или Python, это эквивалентно выполнению кода 1С внутри метода «Выполнить», поэтому отладка практически невозможна.
Конкуренты и интеграция с другими инструментами
Пока я готовил эту статью, информация о конкурентах немного устарела, потому что сейчас OpenAI выпустили агент-билдеров, у Google есть Opal, у Zapier – механики и агенты, которые можно использовать в рабочих процессах.
Но я не считаю их конкурентами, потому что эти инструменты можно комбинировать между собой. Например, в сети можно найти кейсы применения Flowise вместе с n8n – это эффективно работает и расширяет возможности n8n.
Полезные ссылки
Подбор embedding-моделей – это сервис Vectorize, очень полезный инструмент.
Сборка n8n вместе с включенным производительным режимом, Flowise внутри, векторным графовым хранилищем и neo4j у ollama на борту https://github.com/coleam00/local-ai-packaged – это готовый мультитул, который можно развернуть и сразу использовать в работе.
Включение высокопроизводительного режима требует всего три строки команд и установку Postgres с Redis: https://docs.n8n.io/hosting/scaling/queue-mode/
LlamaParse https://github.com/maxgoff/llama_parse – интересный ресурс: если база знаний представлена в PDF или другом формате, можно загрузить ее в сервис и получить на выходе Markdown. Корректно разбираются таблицы, диаграммы, и есть API – с некоторыми ограничениями, но его можно использовать.
В заключении отмечу, что n8n на текущий момент времени является уникальным инструментом для построения AI first автоматизаций и интеграций. Попробуйте его в своих текущих процессах и задачах, которые стоят перед вами, и выведите ваши интеграции на качественно новый уровень.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт