Итак, традиционное мнение, что "Индекс это хорошо, а блокировка это плохо", часто бывает неверным до противоположности.
Картинка выше, которую я выбрал для заголовка статьи, очень часто напоминает многие базы 1С, которые неожиданно начинают "быстро расти"и "тормозить".
Но прежде чем перейти к сути, придётся немного покопаться в теории.
Что такое индексы, для чего они нужны, какие они бывают?
Далее будет немного теории, объясняемой простым языком. Если все эти вопросы вам давно известны и вы считаете, что нет необходимости в таком примитивном объяснении, то вы, наверное, слишком редко заглядывали в доработки конфигураций, да что и говорить, в типовые конфигурации 3-4 летней давности, в любом случае, этот раздел всегда можно пропустить.
Итак, как работает индекс? Наверное, все в детстве играли в игру "угадай число"? Кто-то загадал число от 1 до 50, а вам его нужно угадать за наименьшее число вопросов.
Как вы будете его угадывать? Перебором: "Это 1? Это 2? Это 3?". Скорее всего, вы будете задавать вопросы вида: "Оно больше 25?". И только когда вариантов останется около 2-3, вы будете перебирать возможные.
Т.е. поступите примерно так, как показано на картинке:
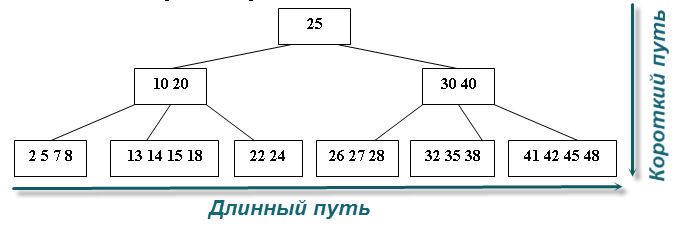
В ВУЗ-е мы уже узнаём, что подобные структуры называются графами, вернее, даже разновидностью графа - деревьями. Бывают ещё более вырожденные разновидности деревьев, так называемые B-деревья.
Собственно, они и лежат в основе большей части индексов.
Хотя, конечно, не большей. Индексы делятся на два типа: кластерные и не кластерные.
Конечно, можно вспомнить, что есть битовые индексы, функциональные индексы, XML индексы.
Но принципиальным отличаем будем считать физическую организацию и принцип работы.
Кластерный индекс - это по сути дела не индекс, а определенным образом организованная таблица. В Oracle его, к примеру, вообще называют Index Organized Table или IOT.
Некластерный индекс - это отдельная структура, как правило, вида B-дерева, которая создаётся дополнительно к основной таблице.
Если вы сейчас думаете, что эти два вида индексов придумали ИТ специалисты, то вы сильно ошибаетесь.
Вот так выглядит кластерный индекс, который появился ещё до появления компьютера:

А как-то вот так, соответственно, некластерный:

Данная аналогия оказывается на удивление полной.
Каким образом вам бы удобнее было искать? Сразу выбрать страницу, начиная с той буквы, которая указана на срезанных полях,
или сначала заглянуть в предметный указатель, потом узнать там номер страницы и уже искать нужную страницу по номеру?
Конечно, первый способ куда удобнее. Но вот только не очень он гибкий... обычно на полях ставят только буквы.
Нельзя написать целое слово или несколько слов, в то время как в предметном указателе их можно организовать как угодно.
Кроме того, предметный указатель по сути ссылается на номера страниц книги, на которых расположена нужная информация.
Сами номера страниц являются при этом по сути кластерным индексом.
Теперь давайте посмотрим уже более детально, применительно к MS SQL Server:
В MS SQL существуют 2 физических операции Index Seek и Index Scan. Index Seek - это хорошо, Index Scan - плохо.
Index seek означает просмотр индекса в порядке упорядочивания, либо по B-Дереву, Index Scan - обычная операция просмотра всех
записей таблицы, аналогичная всем известной Table Scan. Чаще всего данная операция присутствует в случае "неполного покрытия" индекса,
Если в индексе, к примеру, есть поле "Контрагент, Номенклатура" а отобрать записи надо по "контрагенту, номенклатуре и заказу покупателя".
В этом случае в плане запроса MS SQL можно будет увидеть что-то вида:
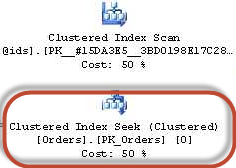
Т.е. сначала по индексу были выбраны записи, соответствующие покрытию, а остаток записей был получен полным последовательным просмотром таблицы.
А если мы сделаем у таблицы не кластерный индекс, то в итоге увидим примерно следующую картину:
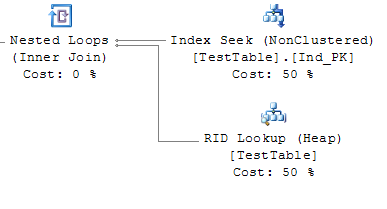
Тут есть ещё одна интересная операция - RID Lookup, занимающая целых 50% времени - столько же, сколько поиск по индексу.
Собственно, дополнительная операция требуется из-за того, что некластерный индекс не производит выборку по самой физической таблице, следовательно, требуется ещё сам поиск нужной физической страницы, чтобы считать сами данные.
Но в данном случае есть ещё одна специфика - это слово "Heap", указанное в скобках операции. Но о нём далее.
Чем плохи индексы?
1) Накладные затраты при записи данных
Очевидно, что для поддержания какой-либо дополнительной структуры данных, либо определенной организации данных, требуется совершать дополнительные действия.
Действий не так много, накладные затраты на них небольшие. Но плохо то, что эти затраты и действия возникают при записи данных. А запись данных происходит в транзакции.
Хуже если в транзакции происходит и запись и чтение данных (контроль остатков). В этом случае индекс должен быть всегда в актуальном состоянии.
Затраты на запись или чтение в транзакции намного "дороже" внетранзакционных издержек. Дело в том, что запись может вестись строго последовательно, и время на фиксацию изменений в БД сократить достаточно сложно. Более мощное оборудование тут не всегда помогает.
Внетранзакционное же чтение данных может вполне успешно выполняться параллельно, при этом в случае увеления количества запросов на чтение данных, к примеру, вследствие роста количества пользователей, то они вполне могут решиться наращиванием аппаратных ресурсов.
2) Накладные затраты на обслуживание индексов
При интенсивной записи данных в таблицу данные индексов к ней не всегда распологаются на той странице, на которой должны. Появляются "пропуски", физическая структура индексов становится неэффективной. Поэтому иногда бывает необходимо производить дефрагментацию индексов. Производительность запросов к СУБД во время дефрагментации, соответственно, падает. Есть ещё процесс полного перестроения индексов - но в современных версиях MS SQL необходимости выполнения данной операции по регламенту нет.
3) Влияние индексов на размер базы
Не самое страшное последствие, но так или иначе если база весит 150-200 ГБ, то об этом надо уже задуматься. Для средней OLTP базы размер индексов, как правило, превышает объём самой базы.
Не верите? Вполне можете воспользоваться какой-либо обработкой вроде этой: //infostart.ru/public/19463/ и посмотреть, сколько же в вашей базе места занимают индексы.
4) Затраты на создание и поддержание актуальной статистики
Статистику в базе нужно регулярно обновлять при интенсивных операциях вставки и обновления. Это занимает вычислительные ресурсы, хоть и не влияет непосредственно на процесс.
Неактуальная статистика может привести к проблемам производительности системы.
Но это не значит, что индексы - это плохо, без них СУБД были бы бесполезны. Плохи индексы, которые не используются.
Как оптимизатор выбирает, какой индекс ему использовать? (статистика, плотность, селективность, кардинальность)
Итак, про то, что "статистика должна быть" и "её нужно обновлять", слышали, наверное, все.
Многие даже знают, что нужно обновлять статистику, наизусть помнят запрос:
EXEC sp_MSForEachTable 'UPDATE STATISTICS ? WITH FULLSCAN;'
Главное - не забыть, что хитрый MS SQL кэширует планы запроса, которые он уже раз посчитал. Даже если статистика изменится,
для того, чтобы что-то заработало по-другому, надо бы выполнить:
DBCC FREEPROCCACHE
Но гораздо реже люди заморачиваются с тем, чтобы посмотреть статистику БД. Давайте попробуем это сделать на тестовой таблице:
Сделаем в БД простейшую таблицу следующего вида:
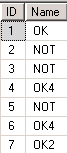
Потом выполним:
DBCC SHOW_STATISTICS('TAB', NAME)
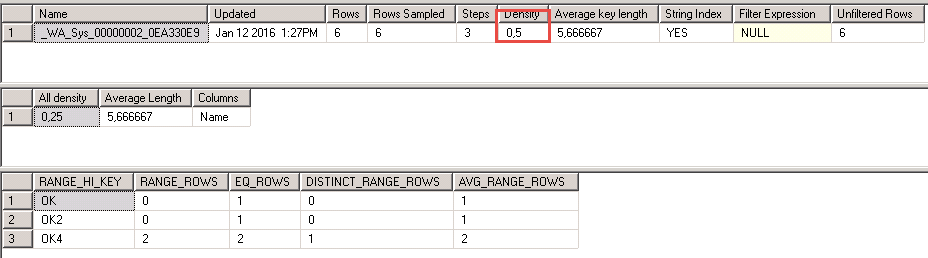
Оказывается, сколько всего сохраняется для такой маленькой таблицы. Интересен ещё тот факт, что вы же не выполняли никакого кода по созданию статистики.
Если статистика для таблицы не отключена, то она создаётся сама. И это тоже ложится на накладные расходы.
Сейчас нам интересен в этой таблице столбец Density - Плотность записей. Плотность рассчитывается как
Плотность = Число дубликатов в колонке / Общее число записей в таблице
И является одним из самых выжных статистических показателей данных в таблице. Очевидно, что чем меньше плотность записей, тем эффективнее можно будет воспользоваться индексом.
А при плотности 0.5, как в приведённом примере, индекс в принципе вообще не нужен. Чем ниже в таблице значение Density, тем более правильно спроектирована данная таблица.
Для СУБД лучше всего таблицы с уникальными записями. Обратите внимание на столбец All density - его значение уже 0.25. Это означает, что в таблице есть ещ одна колонка. Для MS SQL этот показатель важен, когда вы пишете "СГРУППИРОВАТЬ ПО".
Но плотности записей оптимизатору недостаточно. Основная задача оптимизатора - "догадаться", сколько строк вернёт запрос.
Допустим, у нас в базе куча складов по всем регионам - небольшие торговые точки + виртуальные склады. И есть один центральный склад.
Плотность по складу будет достаточно неплохая. Но вот число строк по центральному складу, которое вернёт запрос, и по региональному будет различаться в тысячи раз.
Для этого есть показатель селективности:
Селективность=число строк удовлетворяющих предикату/всего строк в таблице
Предикат - определенное условие.
Из картинки выше селективность определяется в третьей таблице. Там указан "ключ" - RANDE_HI_KEY и соответственно количество строк ему соответствующее... и количество значений, ему соответствующее в таблице.
Ну, и остался последний показатель статистики:
Кардинальность - это и есть предположительное число строк, которое вернёт запрос
В каждом элементе плана запроса этот показатель присутствует.
Если навести на элемент плана запроса курсор, то его можно увидеть во всплывающей подсказке примерно так:
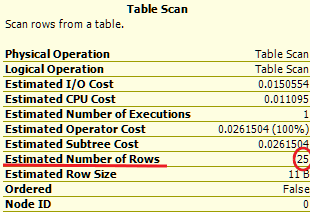
Итак, если итоговый запрос возвращает половину таблицы или около того, то индекс тут совсем не нужен.
Вспомним УТ 10.2, 10.1, даже 10.3, по-моему... В каждом документе был индекс по полю "Организация". В последних версиях его нет. Как думаете, почему?
Индекс также бесполезен, если оптимизатор MS SQL решает, что итоговый запрос вернёт половину таблицы или вроде того.
Почему MS SQL так может решить, вроде разобрались.
Теперь самое время разобраться, какие индексы есть в 1С:
Всё просто. Все объекты 1С делятся на ссылочные (у которых есть ссылка и, соответственно, GUID) и табличные (регистры).
У всех таблиц 1С есть кластерный индекс.
У ссылочных кластерный индекс создаётся по ссылке (GUID) - это самая быстрая выборка, которая только может быть.
У табличных кластерный индекс создаётся по всем изменениям. Что тоже предельно логично. И, конечно, этот индекс уникальный.
А как же затраты на запись? Зачем создавать кластерный индекс везде?
Дело тут в том, что так работает MS SQL. В стандартной таблице просто должен быть кластерный индекс.
Без него выборка из этой таблицы будет приводить к тому, что операция поиска записи по индексу (как было на картинке выше) будет занимать непростительно много времени.
В MS SQL таблицы без кластерного индекса называют Heap Table - куча. Что примерно соответствует их физической организации.
Тем не менее, такие таблицы могут быть важны. Если у вас 99% операций в этой таблице - запись, а для анализа этих данных вы, к примеру, применяете отдельное OLAP решение.
Поэтому возможность убирать кластерные индексы из таблиц очень бы не помешала разработчикам 1С.
Когда вы ставите у какого либо реквизита, ресурса или измерения объекта 1С признак "индексировать" - создаётся дополнительный или обновляется существующий не кластерный индекс для этой таблицы.
Включая реквизиты объекта в критерий отбора, вы также создаёте по ним отдельный индекс.
Это лишь общие правила, по которым платформа создаёт индексы на уровне СУБД. В каких-то деталях они могут отличаться, тем более в разных версиях платформы.
К счастью, 1С не пожадничали и дали нам инструмент, чтобы структуру БД просматривать - я про фукнкцию "ПолучитьСтруктуруХранения()".
Умельцы этой функцией воспользовались и сделали для неё неплохой интерфейс, которым можно вопспользоваться, чтобы точно посмотреть, какие же есть индексы у таблицы:
//infostart.ru/public/147147/
Зачем я всё это прочитал?
Что делать простому разработчику 1С?
Простой разработчик в отличие от оптимизатора MS SQL может заранее предсказать, какие будут данные в запросе, какие будут предикаты и какие нужны индексы.
Что же нужно делать, чтобы ваши запросы выполнялись быстро и при этом при записи данных в БД это не приводило к перезаписи нескольких десятков бесполезных индексов.
-
Делайте индексы, покрывающие предикаты, если данный запрос планируется к использованию достаточно часто. Но не забудьте, что уже существуют кластерные индексы.
-
Если находится индекс, уже покрывающий предикат в запросе, не создавайте нового индекса.
-
Если индекс покрывает почти всё условие запроса - оцените число записей, которое придётся перебрать СУБД при данной выборке, если оно невелико (менее нескольких тысяч) - не создавайте нового индекса
-
Определите селективность и/или плотность записей в выборке так, как их определит в данном случае оптимизатор. Если в итоговой выборке получится много записей по отношению к общему числу записей в таблице - не создавайте индекса, он лишний
-
Когда пишете запрос, думайте о том, как его будет анализировать оптимизатор, сможет ли он корректно посчитать ориентировочное число строк, возвращаемое каждой частью запроса.
-
В конце концов проверьте план полученного запроса, если он вам действительно важен, особенно если данный запрос нужно выполнять в транзакции.
