
{kind=link}
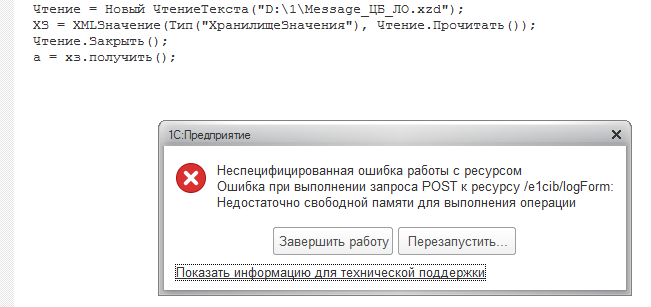
Однажды, когда я был молодой и глупый (последнее правда с тех под и не изменилось), я решал задачу автоматического РИБ обмена через веб-сервис и в качестве контейнера для данных, я решил использовать передачу хранилища значения, в котором упакована с сжатием (9) строка содержимым XML файла сообщения. И всё бы ничего, работало это без проблем. Как вдруг, попался один узел, для которого накопилось ну очень много данных (смотря конечно для кого), а именно, XML данные весили чуть больше 400 Мб. в сжатом виде же это занимало примерно 60 Мб, через интернет клиент веб-сервиса данные то скачал, но при попытке ХранилищеЗначение.Получить(); (База файловая, памяти 2 Гб) 1С сначала кушала память ложками, до без малого 1 Гб съедала и с грохотом падала пугая голубей в соседнем дворе. Конечно, ручной обмен ни-кто не отменял (через классические файлы) и там всё проходило без проблем (как минимум по тому, что 1С не весь файл XML читает в память). Данная проблема воспроизводилась как на релизах 8.3.10.2699 и 8.3.12.1855 так и на других версиях.
А вы знали? 1С любит держать данные помещенные в ХранилищеЗначения в временном файле на диске? Разумеется имеется ввиду те данные, то лежат в памяти. Возможно, она так любит избавляться только от больших данных, но это уже совсем другая история...
Я было просто забил на проблему, ибо она редкая и можно обмен сделать ручками, так как просто не представлял как её можно решить, но тут я совершенно случайно наткнулся отличную публикацию: //infostart.ru/public/618906/ от SerVer1C (за что ему огромное спасибо!) и тут понеслось... Итогом этого, стал собственный метод, получающий значение хранилища значений, который по минимуму питается оперативной памятью, предпочитая ей обычный диск и главное, не валящий процесс 1С ну и конечно выполняющий свою задачу ;)
Суть решения "проста", запакованное хранилище значения из себя представляет данные, запакованные алгоритмом Deflate (которая сама 1С использует везде, а доступа к методам дать не могут) и некоторое служебные данные. Этим же методом Deflate, упаковываются ZIP архивы. Итого весь процесс проводится к следующему:
1) Получение из хранилища значений двоичных данных (да-да, 1С не добавила возможности прямого получения):
ДанныеВBase64 = XMLСтрока(ХранилищеЗначения); // Получим Base64 хранилища значения
ДвоичныеДанные = Base64Значение(ДанныеВBase64); // Получаем двоичные данные хранилища значения
2) Получаем буфер двоичных за вычетом префикса хранилища значения
РазмерСлужебногоЗаголовка = 18; // Размер в байтах служебного заголовка хранилища значения
Поток = ДвоичныеДанные.ОткрытьПотокДляЧтения(); // Открываем поток для данных
Поток.Перейти(РазмерСлужебногоЗаголовка, ПозицияВПотоке.Начало); // Прыгаем в начало данных
РазмерПотока = Поток.Размер() - РазмерСлужебногоЗаголовка;
БуферТелаФайла = Новый БуферДвоичныхДанных(РазмерПотока); // Создаем буфер под данные
Поток.Прочитать(БуферТелаФайла, 0, РазмерПотока); // Читаем данные в буфер
Поток.Закрыть();
3) Формируем структуру ZIP архива и добавляем к нему данные из буфера двоичных данных
ДлинаИмениСжатогоФайла = СтрДлина(ИмяФайлаВАрхиве);
РазмерСжатогоФайла = РазмерПотока;
... // Подробнее можно ознакомится в приложенном файле и/или в исходной публикации: //infostart.ru/public/618906/
НовыйБинарник = ПотокВПамяти.ЗакрытьИПолучитьДвоичныеДанные();
НовыйБинарник.Записать(ПутьКФайлуАрхива);
ПотокВПамяти.Закрыть();
4) Распаковать ZIP архив, игнорируя ошибки распаковки (так как у нас нет данных о CRC сумме НЕ запакованных данных, а так же об их размере)
// Можно было и в памяти извлекать, но слишком много памяти кушает
Архив = Новый ЧтениеZipФайла(ПутьКФайлуАрхива);
Попытка
Архив.Извлечь(Архив.Элементы[0], КаталогОбмена);
//файл извлечется, хотя здесь возникнет исключение из-за некорректных размера файла и контрольной суммы
Исключение
КонецПопытки;
5) На выходе, мы уже получаем распакованные данные, которые были помещены в хранилище значения, НО, они окружены структурой, похожей на JSON которая всюду используется в 1С как минимум с 1С 7.7 (или даже раньше), для того чтобы от неё избавится, надо в начале файла отрезать чуток и в конце, а так-же убрать экранирование кавычек. Тут я пробовал разные варианты (кроме считывания всего текста и СтрЗаменить, ибо память не безлимитная, но и такой способ работает и 1С не падает), но самым оптимальным как по скорости, так и по потреблению памяти, оказалось порционное чтение из файла, замена двойных кавычек на одинарные и запись в результирующий файл (выполняется мгновенно, пруфов нет)
ПотокЧтения = Новый ФайловыйПоток(ПутьКИзвлеченномуФайлу, РежимОткрытияФайла.Открыть, ДоступКФайлу.Чтение);
ЧтениеТекста = Новый ЧтениеТекста(ПотокЧтения, КодировкаТекста.UTF8);
ПотокЗаписи = Новый ФайловыйПоток(ПутьКФайлуРезультата, РежимОткрытияФайла.Создать, ДоступКФайлу.Запись);
ЗаписьТекста = Новый ЗаписьДанных(ПотокЗаписи, КодировкаТекста.UTF8);
БуферТекста = ЧтениеТекста.Прочитать(50*1024*1024); // Делим по 50 мегабайт
ТекущаяПорция = Неопределено;
ПерваяСтрокаСчитана = Ложь;
Пока БуферТекста <> Неопределено Цикл
Если ТекущаяПорция <> Неопределено Тогда
ЗаписьТекста.ЗаписатьСимволы(ТекущаяПорция, КодировкаТекста.UTF8);
ЗаписьТекста.СброситьБуферы();
КонецЕсли;
Если Не ПерваяСтрокаСчитана Тогда
БуферТекста = Прав(БуферТекста, СтрДлина(БуферТекста) - 15);
ПерваяСтрокаСчитана = Истина;
КонецЕсли;
Если Прав(БуферТекста, 1) = """" Тогда
// В конце нашли одинокую кавычку, надо её удалить
БуферТекста = Лев(БуферТекста, СтрДлина(БуферТекста) - 1);
КонецЕсли;
ТекущаяПорция = СтрЗаменить(БуферТекста, """""", """");
БуферТекста = ЧтениеТекста.Прочитать(ДелитьПо);
КонецЦикла;
Если ТекущаяПорция <> Неопределено Тогда
ТекущаяПорция = СтрЗаменить(ТекущаяПорция, """}", "");
ЗаписьТекста.ЗаписатьСимволы(ТекущаяПорция, КодировкаТекста.UTF8);
КонецЕсли;
ЧтениеТекста.Закрыть();
ПотокЧтения.Закрыть();
ЗаписьТекста.Закрыть();
ПотокЗаписи.Закрыть();
6) Profit! На выходе мы получаем файл имеющий в точности то же содержимое, что и положили в Хранилище значение. Тут можно и сразу в память считывать порцию данных из файла и в порции производить все замены, но так как мне дальше не обязательно держать в памяти именно строкой всю XML и для ещё большей оптимизации, решил делать запись в файл и его потом уже подавать процедуре чтения сообщения обмена.
7) Так же не забывайте убирать за собой, помогите сборщику мусора 1С, донесите свой мусор хотя бы до помойки:
Мусор = Неопределено;
Как и писалось в анонсе, данный способ не претендует на использование в продакшене (хотя мы у себя впилили, вместо ХранилищеЗначение.Получить() на проде), но надеюсь, данная публикация вам поможет, когда нужно через хранилище значения, передать много данных, а штатный механизм прожорлив или вообще падает (как в моём случае). Разумеется, вы бы сделали лучше чем я и код фактически один большой костыль.
Тем же, кто думает о своей реализации обмена данными через веб-сервис, я бы пожалуй посоветовал паковку в ZIP архив на сервере (можно даже в памяти это сделать, без записи на диск) и передавать двоичные данные, а на клиенте уже сохранить полученные двоичные данные на диск, а дальше можно использовать типовой механизм.
Выражаю благодарность автору обработки, которая сделала сказку - былью!
Если у вас есть лишние помидоры и яйца, то вспомните о голодающих ;)
PS: Прошу обратить внимание на то, что данная публикация, получает строку, помещенную в хранилище значение, если вы хотите таким образов получать другие типы данных помещенные в хранилище значение, вам явно придется вооружится напильником, но нет ничего не возможного!
PS: Так же надо учитывать, что данный способ медленней чем штатный способ получения значения! Обратите так же внимание, тестировать обработку лучше в файловой базе или хотя бы на 32-х битном сервере 1С, где есть техническое ограничение на потребляемую память. На 64-х битном сервере 1С, даже очень большие данные сможет получить. Да, обработка не демонстрирует проблему, а демонстрирует решение.
Вступайте в нашу телеграмм-группу Инфостарт