

















Введение
Здравствуйте! Меня зовут Алина, и я хочу с вами поделиться своим опытом проведения BDDSM-практик. Мой Господин принудил меня к этому. Было немножко больно, но потом очень приятно.
Для начала давайте разберёмся в терминах. BDDSM - это Behavior Driven Development and Story Mapping, а не то, что вы, шалунишки, подумали. Термин родился в ходе обсуждения командой 1Service инструмента StoryMapper в рамках проектирования знаменитого (в узких кругах) программного продукта Checkушка.
Методика BDDSM может применяться как для разработки нового функционала (классика), так и для организации регрессионого тестирования legacy-систем (ана... ну вы поняли).
Методика подразумевает выполнение следующей последовательности шагов:
- Разработка карты пользовательских историй
- Составление критериев приёмки пользовательских историй (с примерами!)
- Написание сценариев с шагами первого уровня (под каждый критерий приёмки)
- Написание шагов второго уровня (с использованием библиотечных шагов Vanessa Automation, она же VA)
- Вынесение шагов второго уровня в экспортные сценарии (чтобы не загромождать основные сценарии)
- Мониторинг результатов выполнения сценариев в Checkушка (ну собственно то, ради чего)
А теперь по каждому из этих шагов подробнее.
Разработка карты пользовательских историй
Почему это первый шаг? Потому что карта пользовательских историй - это инструмент визуальной структуризации хаоса пользовательских требований. Когда требования не структурированы, с ними очень тяжело работать, трассировать, отслеживать зависимости, и в результате понимать, какой блок функционала проблемный, а какой нет. Конечно, существуют и другие методы структурирования информации, но поскольку парадигма BDD - это порождение экосистемы Agile, то вполне логично использовать соответствующий инструментарий (Story Mapping). Это приемлемо как для задач разработки нового функционала, так и для проверки регресса legacy-систем. В первом случае Story Map порождается в ходе мозгового штурма на начальном этапе каждой итерации разработки, во втором - как результат интервьюирования пользователей legacy-системы. Для желающих прикоснуться к тайнам искусства SM предлагаю следующий состав первоисточников ([1], [2]).
Следующий вопрос - это правила структурирования. Поскольку мы на территории Agile, то эти самые правила гибкие до невозможности. Например, существуют такие распространённые вариации (из [1]):
- Goal→Activity/Feature→Task/Epic→User Story
- User→Goal→Journey→Activity→Story
- NFR(non-functional requirement)→Requirement→Story
В инструменте StoryMapper используется следующая иерархия: Usage Flow→User Activity→User Story. Usage Flow - это некий поток бизнес-ценности в рамках предприятия (как вариант: направление деятельности, подразделение предприятия, цепочка поставки ценности, бизнес-процесс). В рамках этого потока существует разнообразная пользовательская активность, которая расшифровывается конкретными пользовательскими историями, реализующими эту активность.
Это была теория, теперь, собственно, практика. В качестве примера рассмотрим разработку функционала по автоматизации процессов предприятия в рамках направления деятельности "Электронная коммерция".
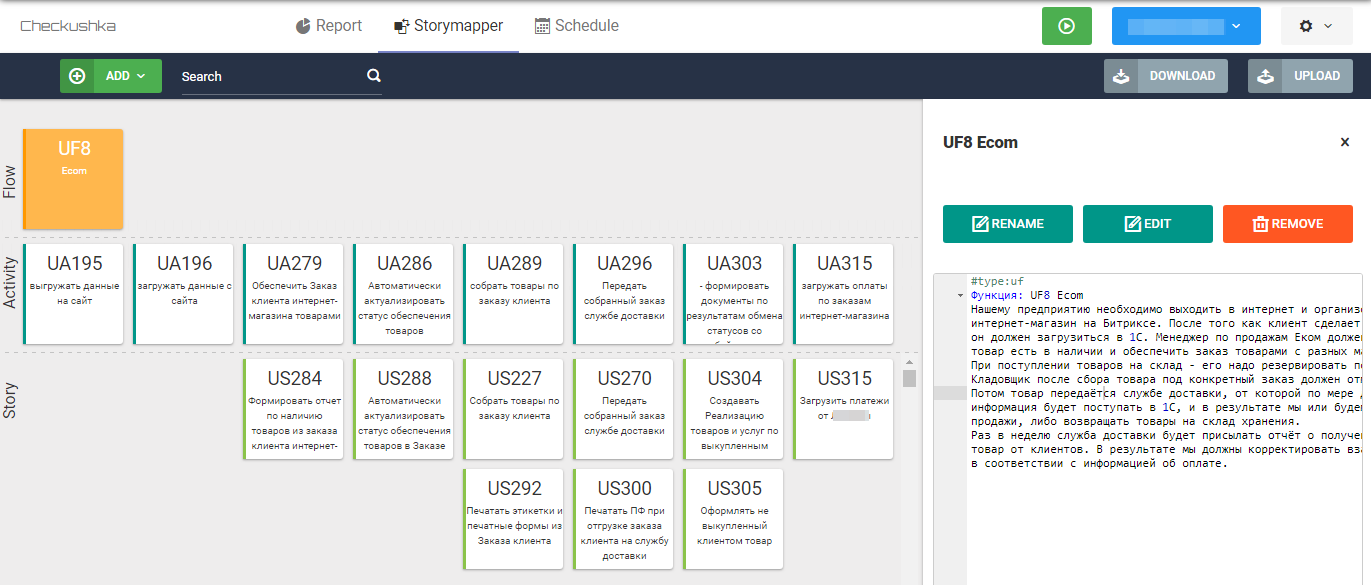
Я созванивалась с ИТ-директором заказчика, и он мне рассказал свою грустную историю своё видение нового направления деятельности его предприятия. В рамках этого направления: каталог товаров выгружается на сайт, довольные клиенты заказывают эти товары на сайте (за рамками системы), заказы с сайта загружаются в учётную систему. После этого ответственный работник изучает хватает ли на предприятии товаров под этот заказ и обеспечивает его товарами (с центрального склада и магазинов). Когда товары приезжают, кладовщик группирует их под каждый заказ. Когда приезжает машина службы доставки, кладовщик печатает этикетки и сопроводительные документы и передаёт заказы службе доставки. По мере доставки товаров клиентам, учётная система службы доставки меняет статусы заказов и товаров, система получая эти статусы либо фиксирует факт продажи, либо формирует возврат товаров. После того, как цикл доставки завершён, служба доставки присылает информацию об оплате с разбивкой по каждому заказу - и в системе должны сформироваться документы по корректировке задолженности. По ходу общения я составляла карту активностей в рамках UF "Ecom", и вот что получилось:

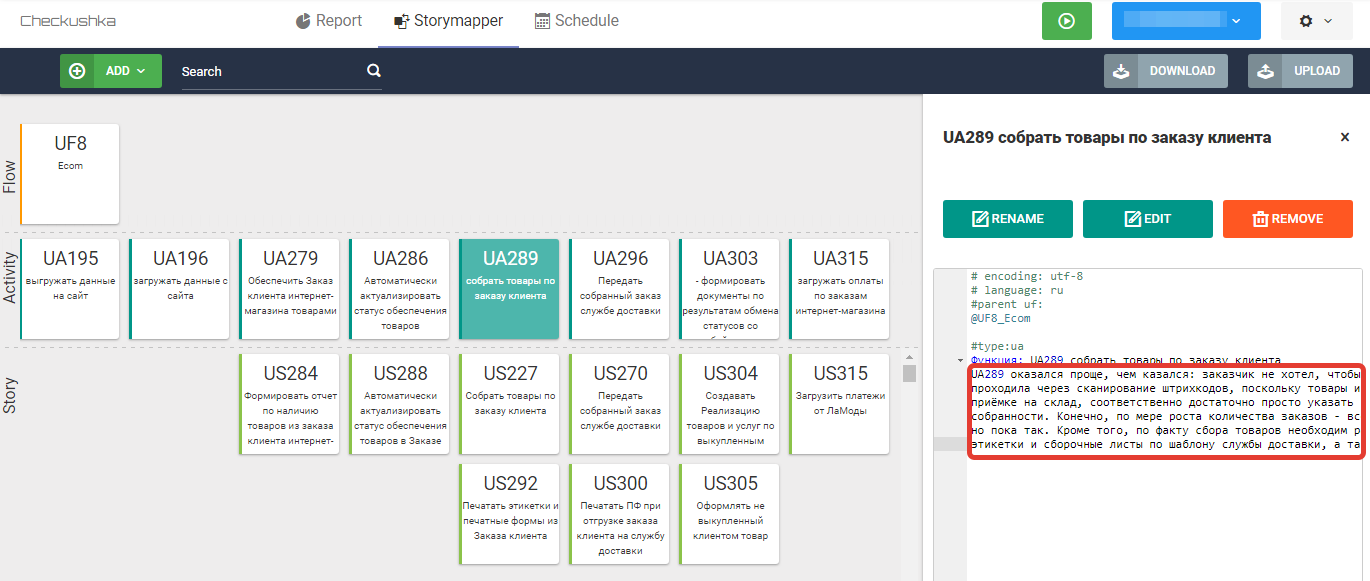
Я продолжила разговор. В результате мы выяснили, что UA195 и UA196 - это типовой функционал модуля обмена с сайтом, про него пока думать не нужно, будем считать, что он заработает "из коробки". По поводу UA279 мне сказали, что здесь достаточно будет построить отчёт с информацией о наличии товаров из заказа на всех складах предприятия, заказы на перемещение и сами перемещения менеджер и кладовщик будут формировать вручную. UA286 подразумевает, что когда товары будут перемещены на склад электронной коммерции, то они должны автоматически зарезервироваться под соответствующие заказы, без необходимости заходить в каждый из них. UA289 оказался проще, чем казался: заказчик не хотел, чтобы сборка под заказ проходила через сканирование штрихкодов, поскольку товары и так сканировали при приёмке на склад, соответственно, достаточно просто указать в заказе признак его собранности. Конечно, по мере роста количества заказов - всё может поменяться, но пока так. Кроме того, по факту сбора товаров необходимо распечатать и наклеить этикетки и сборочные листы по шаблону службы доставки, а также ТОРГ-12 или УПД. В рамках UA296 необходимо под каждый заказ, передаваемый службе доставки, сформировать пакет документов учётной системы, так, чтобы можно было учитывать какие товары сейчас находятся у службы доставки. Кроме того, необходимо распечатать ТТН по всем заказам, которые передаются водителю. UA303 подразумевает, что у службы доставки есть API (веб-сервис) и нужно организовать его периодический опрос с целью уточнения состояния доставки наших товары. Если товары отгружены клиенту, то необходимо сформировать документ отгрузки. Если клиент отказался от товаров, то надо отработать возврат товаров на склад хранения. И вот получилась такая карта пользовательских историй:
Составление критериев приёмки пользовательских историй
Следующий шаг находится на стыке SM и BDD. С одной стороны, критерии приёмки (acceptance criteria) - это инструмент конкретизации пользовательской истории, когда мы фиксируем ключевые моменты, которые важны заказчику при реализации данной пользовательской истории, с другой стороны (и это надо чётко осознавать!), критерии приёмки - это будущие сценарии приёмочного тестирования. В начальном своём виде критерии приёмки - это некий чеклист, каждый пункт которого озвучивается заказчиком, то есть он их просто называет: "вы когда будете делать учтите вот этот момент, и ещё очень важно чтобы было вот так-то, и обязательно чтобы не было возможности сделать", а я их просто записываю 😉. Если заказчик не готов сходу формулировать критерии приёмки, то я его подбадриваю вопросом: "А как вы будете проверять, что мы вам всё сделали правильно?".
Далее, при более детальной проработке я требую от заказчика примеры (а то и несколько) на каждый критерий приёмки. Почему так? Потому что критерии приёмки должны быть чёткие и конкретные, иначе они не нужны - ни программист не поймёт как это делать (и по статистике общения с программистами начнёт экспериментировать с юзабилити), ни тестировщик не поймёт как это тестировать и тоже начнёт сочинять тест-кейсы. То есть плюсы в чём, когда заказчик участвует в составлении примера для критерия приёмки - он, с одной стороны, подписывается, что именно так и надо делать и проверять, а с другой - если пример показывает убогость решения - может пересмотреть сам критерий приёмки, либо сформулировать какой-то дополнительный. Подробнее у Аджича в Specification By Example [3].
Теперь о том, как зафиксировать критерии приёмки в StoryMapper. Как вы, наверное, уже успели заметить, все объекты, создаваемые в StoryMapper - это feature-файлы (всё в рамках концепции "документация - это код"). Стало быть вы вольны записывать критерии приёмки в свободной форме. Например, немногие из тех, кто пишет фичи в курсе, что в рамках синтаксиса Gherkin, можно писать свободный текст после блока "Функция/Функционал" или после блока "Сценарий" вплоть до ближайшего ключевого слова, написанного с начала строки:
|
|
|
|---|
То есть практическая идея такая: если у вас критерии приёмки не сформулированы, а есть сырой текст от заказчика - смело его вставляйте после блока "Функция/Функционал". Если дошли руки до кристаллизации критериев приёмки - фиксируйте их блоком "Сценарий/Структура сценария", а наброски примеров - опять же свободным текстом после блока "Сценарий".
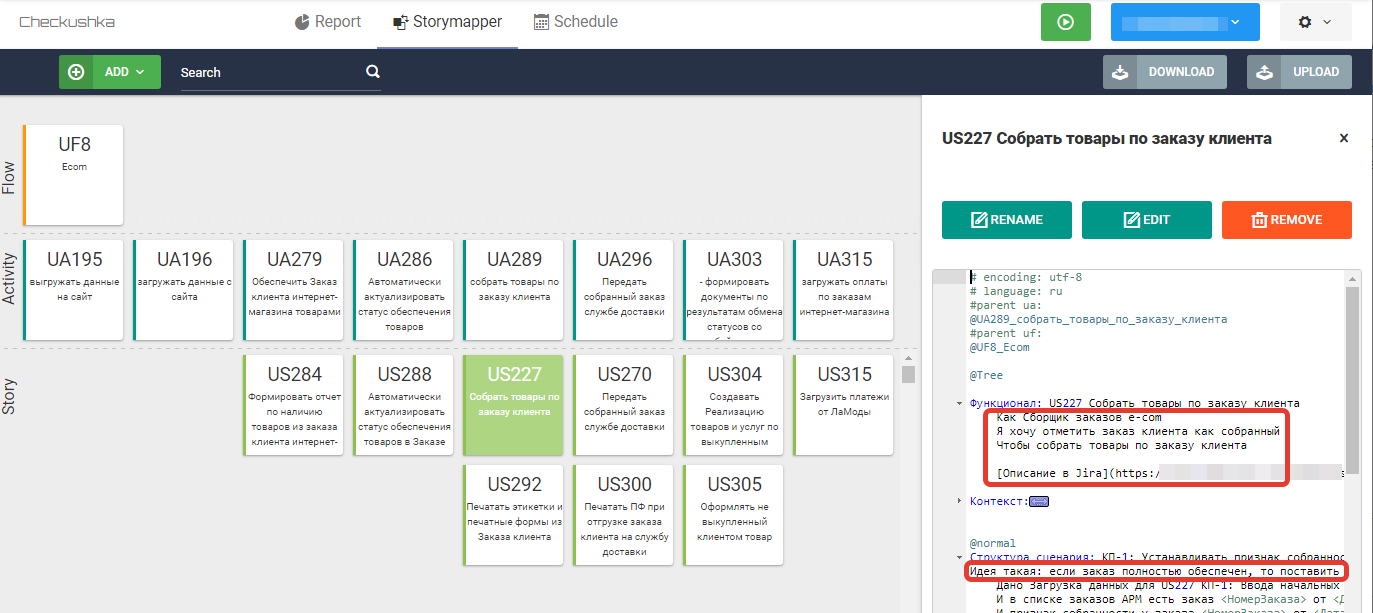
Итак, критерии приёмки в рамках UF "Ecom":
|
US304 Создавать Реализацию товаров и услуг по выкупленным товарам |
|
|
|
US227 Собрать товары по заказу клиента |
|
1. Установка собранности полностью обеспеченного заказа 2.1 Частично обеспеченного заказа 2.2 Не обеспеченного заказа 3. Отменяем собранность полностью обеспеченного заказа 4. Проверка статуса собранности в шапке заказа клиента 5.1. Строим структуру связанных документов для заказа, который имеет в таблице товаров пять единиц 5.2. Строим структуру связанных документов для заказа, который имеет в таблице товаров одну единицу |
|
US270 Передать собранный заказ службе доставки
|
|
1. Создаём Перемещения когда в заказе клиента есть услуга доставки 2.1. Отбор заказов по марке 1 2.2. Отбор заказов по марке 2 3. Создаём Перемещения когда в заказе клиента не предусмотрена услуга доставки |
|
US284 Формировать отчет по наличию товаров из заказа клиента интернет-магазина |
|
|
|
US288 Автоматически актуализировать статус обеспечения товаров в Заказе клиента при проведении Перемещения товаров
|
|
|
|
US292 Печатать этикетки и печатные формы из Заказа клиента |
|
1. Формируем печатную форму ТОРГ-12 из заказа клиента 2.1. Формируем печатную форму Реализация марки 1 из заказа клиента 2.2. Формируем печатную форму Реализация марки 2 из заказа клиента 3. Формируем печатную форму Этикетки доставки всего заказа из заказа клиента 4. Формируем печатную форму Этикетки доставки для каждого товара из заказа клиента
|
|
US300 Печатать ПФ при отгрузке заказа клиента на службу доставки |
|
|
|
US305 Оформлять не выкупленный клиентом товар |
|
|
Написание сценариев с шагами первого уровня
Очень важный этап. Именно на этом этапе происходит та самая магия BDD по модели "Three Amigos", когда заказчик, программист и QA начинают говорить на одном языке, а скромный автор этих строк является переводчиком на этот язык. Что важно на этом этапе? Самое важное - это абстрагироваться от конечной реализации, от интерфейса, от всех этих кнопочек, надписей, полей ввода, динамических списков etc. Мы должны формулировать шаги в терминах бизнес-пользователя, рассчитывая на то, что этот сценарий может быть реализован в любом другом учётном продукте, либо стать основой для разработки нового продукта. Такой уровень абстракции позволяет придать сценариям универсальность и независимость от конечной реализации, что, в свою очередь, приводит к тому, что наши требования будут достаточно долговечными. Всю зависимость от конечной реализации мы стараемся уносить на второй уровень шагов.
Шаги первого уровня - это формализация критериев приёмки посредством языка Gherkin. Наша цель состоит в том, чтобы трансформировать критерий приёмки в простую, линейную, короткую последовательность действий. Идеальный сценарий с шагами первого уровня состоит из трёх предложений, начинающихся с "Дано, Когда, Тогда". В "Дано" мы описываем какие данные поступают на вход сценария (элементы справочников, документы, регистры сведений/накопления), в "Когда" - каким воздействиям мы будем подвергать эти входные данные (создание/проведение документов, выполнение обработок, запуск регламентных заданий), в "Тогда" - во что должны трансформироваться входные данные (сформированные документы, движения регистров, содержимое отчётов). Но вот эти подробности - они будут уже на втором уровне, первый - максимально от этого абстрагируется (но мы должны держать в голове, что в конечном итоге придём к этому).
Теперь практика. В качестве примера, я хочу привести несколько показательных вариантов написания сценариев с шагами первого уровня. Первый пример - это формирование отчёта. Имейте в виду, что мной используется модель подготовки начальных данных - эталонная база. В качестве эталонной базы у меня используется копия продуктива, в котором удалены ВСЕ документы. Эталонная база перед каждым запуском копируется в рабочую тестовую, все сценарии прогоняются в ней. Каждый сценарий обязан сам себе создать окружение из начальных данных, а в конце подчистить за собой. Начальные данные для сценариев я предпочитаю хранить в макетах. Вариант компромиссный, дискуссионный, но я выбрала именно его. Итак, сценарий из US284:

На что нужно обратить внимание. Общий подход - это использование раздела "Контекст" для выполнения действий общих для всех сценариев: указание названия вышестоящей пользовательской активности в качестве эпика (используется для группировки сценариев в Allure), подключение тест-клиента с полными правами, чтобы иметь возможность выполнять вспомогательные действия (загрузка и проведение документов, старт фоновых заданий и т.д.) по ходу выполнения сценариев, загрузка данных или установка настроек общих для всех сценариев.
Далее вы видите, что используется конструкция "Структура сценария". Для тех, кто не в курсе, "Структура сценария" - это тот же сценарий, но дополненный блоком примеров. Каждая строчка примера приводит к выполнению сценария с подстановкой значений из этой строчки. Эта "структура сценария" несовершенна. В примеры не вынесены загружаемый макет из блока "Дано", а также макет отчёта, используемый для проверки в строке 32 (они захардкожены в шагах второго уровня). Поэтому это просто заготовка под "структуру сценария", но рабочий вариант - это только одна строчка примеров. Для возможности использовать несколько строчек примеров нужно доработать напильником. Но мне важно донести вам принцип, оставим перфекционизм занудам.
Посмотрите, как я постаралась сгладить формулировки, чтобы уйти от деталей реализации. "Я инициирую создание отчёта" - не "нажимаю на кнопку", не "выбираю из пункта меню", не "даблкликаю на строчку". Это даёт программисту определённую свободу действий, но при этом ограничивает его наличием некого списка, в котором будет выбираться заказ, прежде чем отчёт будет сформирован. Программист понимает последовательность действий пользователя, понимает какие данные на входе, и чего от него ждут на выходе - в принципе этого достаточно для реализации данного функционала. Если функционал требует замысловатости интерфейса, то я вместе с заказчиком делаю набросок, ссылку на который вставляю в feature-файл. Шаг в строке 33 - технический, а не бизнесовый. Похоже его нужно будет вынести в обработчик "ПередОкончаниемСценария", также как туда уже вынесены шаги по очистке данных, созданных в ходе выполнения сценария.
Следующий пример уже с реально рабочей "структурой сценария". Это пример сценария интерактивного взаимодействия пользователя с интерфейсом "АРМ кладовщика", так называемый "негативный сценарий", когда мы отрабатываем кейс, где система не должна позволять пользователю выполнять определённые действия:

Как видите, принцип построения сценария выдерживается всё тот же: загрузка начальных данных и проверка предусловий, выполнение действий пользователя, проверка корректности реакции системы на действия пользователя. Обрабатываются два негативных случая, когда товар под заказ совсем не приехал, и когда приехал не весь. Снова не устану обращать ваше внимание на обтекаемость формулировок: "признак собранности у заказа установлен", "есть товары не готовые к отгрузке", "отмечаем заказ как собранный". И примеры! Это очень важно: конкретику и проверяемость в обтекаемые формулировки могут добавить только чёткие примеры.
И последний сценарий, которым я бы хотела с вами поделиться. В этом сценарии главным действующим лицом является система. То есть это функционал, работу которого пользователь инициирует опосредовано. В нашем случае работа системы будет заключаться в запуске регламентного задания, которое поставит в резерв товар, перемещённый на склад электронной коммерции под конкретный заказ.

Что необычного в этом сценарии. Семантически значимо в сценариях чётко следить за личностностью шагов. Личный шаг с использованием "я" говорит об интерактивности данного действия, безличностные шаги с использованием инфинитивов и отглагольных существительных говорят об автоматичности этого действия (загрузка и устанавливается резерв).
Подведу итог по этому этапу. Важность этого этапа трудно переоценить. Именно здесь создаётся техническая документация. Если спустя время вам (как пользователям) потребуется ответ на вопрос "как работает ваша система?" - то ответ будет именно в этих шагах первого уровня сценариев. Следующие этапы нужны для того, чтобы сделать эту документацию по-настоящему живой (хотя и в этом виде она уже неплоха).
Написание шагов второго уровня
Когда я обычно перехожу к этому этапу? Если идёт разработка нового функционала, то шаги второго уровня я начинаю записывать после того, как разработчик отдаёт мне на проверку первую версию функционала. При этом подразумевается, что он, как минимум, читал мои сценарии из предыдущего этапа, как максимум - с их помощью вручную тестировал результат своей разработки. Если он этого не делал, то мне приходится объяснять ему, что так делать нужно - поскольку заказчику важны, и он ожидает реализацию именно таких сценариев, а то, что у программиста не получалось, и он сделал "немного по-другому" - такое со мной не проходит. Конечно, если оригинальность идеи разработчика мне нравится - я пойду пересогласовывать сценарии с заказчиком, я же не садистка 😉. Если же речь идёт о регрессионном тестировании готового функционала, то к этому этапу можно переходить сразу после предыдущего.
В самом начале я вручную набиваю входные данные для примеров и сохраняю макеты данных (те самые fixtures). Я по старинке выгружаю в формате mxl, хотя на сегодняшний день сериализатор поддерживает формат json более выгодный при хранении макетов в git. При этом в сериализаторе есть возможность сохранять в файл настройки выбора выгружаемых в макет данных, что позволяет мне актуализировать макеты после обновления базовой конфигурации или изменения структуры метаданных выгруженных в макет объектов. Знаете эту проблему? Когда ваши макеты перестают загружаться, потому что какие-то реквизиты документов были удалены или переименованы. Это та цена, которую приходится платить за скорость подготовки и очистки тестовых данных. Так вот сохранение в файл настроек выгрузки в сериализаторе для каждого сценария и последующее помещение их в git позволяет эту проблему слегка нивелировать. Выгруженные макеты данных я также складываю в git в отдельную папку Examples. Дальше в разделе "Дано" каждого сценария мне нужно эти макеты загружать. К сожалению, в стандартной библиотеке VA нет шага по загрузке макета из внешнего файла (ну или я не нашла). Тот, что есть, грузит данные только из макета обработки со step definitions. Ну и поскольку "я не настоящий сварщик", я обратилась к нашим программистам, и добрые программисты мне сделали шаг "И я загружаю макет из внешнего файла './Examples/US42договор.mxl' " для нашей внутренней библиотеки шагов. Файл ищется относительно каталога проекта. Кроме того, я столкнулась с такой проблемой, что несмотря на установленную галку "выгружать движения", движения ни в какую не выгружаются. Разбираться мне было некогда, поэтому я после загрузки макетов провожу документы в нужном мне порядке: сначала ввод остатков, затем заказы клиентов в с резервом и только потом РТиУ. Собственно этот порядок делает весьма затруднительным автоматическое проведение документов после загрузки, поскольку непонятно в каком порядке нужно проводить документы, а так, конечно, добрые программисты пришли бы мне на помощь. Шаги проведения документов я сначала записывала "кнопконажималкой", но потом узнала, что в библиотеке есть волшебный шаг " И Я открываю навигационную ссылку 'e1cib/data/Документ.ЗаказКлиента?ref=bacaba6e71f047c911e9610fc4adcbf5' " - и моя жизнь наладилась. Итак, вот пример написания шагов второго уровня для шага загрузки входных данных:

Я надеюсь, что меня читают опытные feature-писцы, и объяснять, что второй уровень шагов работает только при наличии в начале feature-файла тега @Tree, никому не нужно. В последних версиях VA появилась настройка "тэг @tree включен по умолчанию", включенная по умолчанию, видимо потому что создатель VA считает стандартом де-факто использование многоуровневых сценариев. Как сказал мой Господин: "На фоне условий и циклов в шагах - это детские шалости!" (с).
Остальные шаги второго уровня я пишу при помощи кнопконажималки, кнопки "Добавить известный шаг" в VA и такой-то матери. Разработчики StoryMapper обещают в ближайшем будущем добавить в редактор фич контекстную подсказку из предопределенного набора библиотечных шагов - и тогда дело пойдёт веселее. На чём бы я хотела заострить внимание. Иногда мне снова-таки приходилось прибегать к помощи добрых программистов. В частности, когда была необходимость сравнить значение некоего реквизита на форме документа со значением ячейки табличного документа (то есть печатной формы). Мне приходилось выкручиваться вот так:
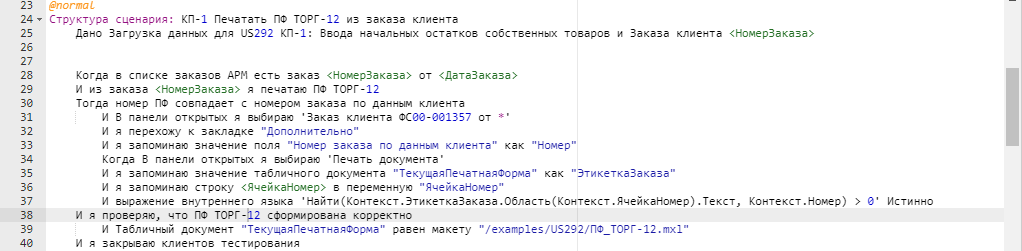
То есть я складывала в Контекст значение поля формы, ВСЮ печатную форму, адрес ячейки в табличном документе. После чего добрые программисты написали мне странную конструкцию со словом "Найти", чтобы можно было найти вхождение переменной контекста в тексте ячейки табличного документа. Это на случай, если в этой ячейке будет длинная строка, в которой одним из слов будет искомое мной значение. По словам создателя VA в последних версиях в контекст уже можно складывать значение конкретной ячейки табличного документа, что позволит избежать помещения в контекст целой печатной формы.
Ну и очень полезным шагом проверочной части сценария является "И Табличный документ 'ТекущаяПечатнаяФорма' равен макету '/examples/US292/ПФ_ТОРГ-12.mxl' ". Его прелесть заключается в том, что я могу предварительно сохранить макет печатной формы или отчёта, которым собираюсь проверять корректность разработанного функционала, и потом одним шагом сравнить сохранённый макет со сформированным на этапе выполнения сценария табличным документом. Очень рекомендую.
Ещё один момент, как корректно формировать отчёты и печатные формы для последующей проверки. Когда я была ещё совсем зелёной неофиткой культа огуречного монстра, тогда по неопытности позволила себе написать такое:
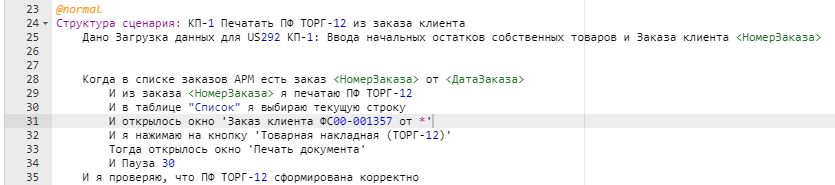
Увидев этот набор шагов, мой Господин очень разнервничался, топал ногами и кричал слова "асинхронность" и "аяяяй". Потом успокоился и объяснил, что "Паузу" надо использовать только в тех случаях, когда другого выхода нет и нужно просто подождать. В случае же ожидания формирования отчётов или печатных форм нужно пользоваться асинхронными шагами типа "И я жду, что в табличном документе 'ТекущаяПечатнаяФорма' ячейка 'R2C1' станет равна 'ТОРГ-12' в течение 20 секунд". В этом случае мы задаём верхний предел ожидания, но если формирование печатной формы закончится раньше, то выполнение сценария успешно продолжится. Но ждать нужно в любом случае - иначе печатная форма или отчёт ещё не сформируются, а шаги по проверке результата начнут выполняться и падать.
На выходе этого этапа (при настроенном процессе автоматического тестирования на сборочной линии) вы получите зеленые и красные кружки на ваших фичах в StoryMapper, ну и соответственно красоту в Allure.
Вынесение шагов второго уровня в экспортные сценарии
Этот этап, с одной стороны, полная вкусовщина, но с другой стороны, надо помнить для кого пишутся сценарии. Конечный потребитель - это заказчик, с которым договаривались про критерии приёмки. Сценарии с шагами первого уровня - это, по сути, те самые критерии приёмки, но огуречно-формализованные. То есть бизнес-пользователь реально сможет их читать и понимать. И если они будут зеленеть после прогона сценариев на сервере сборки - это будет определенный уровень доверия. То есть бизнес-пользователь смотрит на это так: мы с исполнителем договаривались именно об этом, и это так и работает. Наличие шагов второго уровня в основных сценариях превращает их в нечитаемые простыни. Бизнес-пользователю не интересен Gherkin-assembler из библиотечных шагов. Это слишком низкий уровень абстракции, и так низко опускаться не нужно из-за угрозы отторжения такого результата. "Сложна, нипанятна" - вот, что мне приходилось слышать, когда я не прятала шаги второго уровня. Так что этот мессидж адресован и тем братьям во огурце, которые шпарят фичи кнопконажималкой и выдают это заказчику за конечный продукт тестирования системы. Друзья, это профанация, не делайте так.
Итак, что я делала для того, чтобы избавиться от шагов второго уровня. Первый вариант был таким: оставить в сценарии только шаги первого уровня, сгенерировать epf с определениями шагов, а потом шаги второго уровня перенести в обработчики шагов с обрамлением вида Ванесса.Шаг("И я нажимаю на кнопку 'Записать' ").
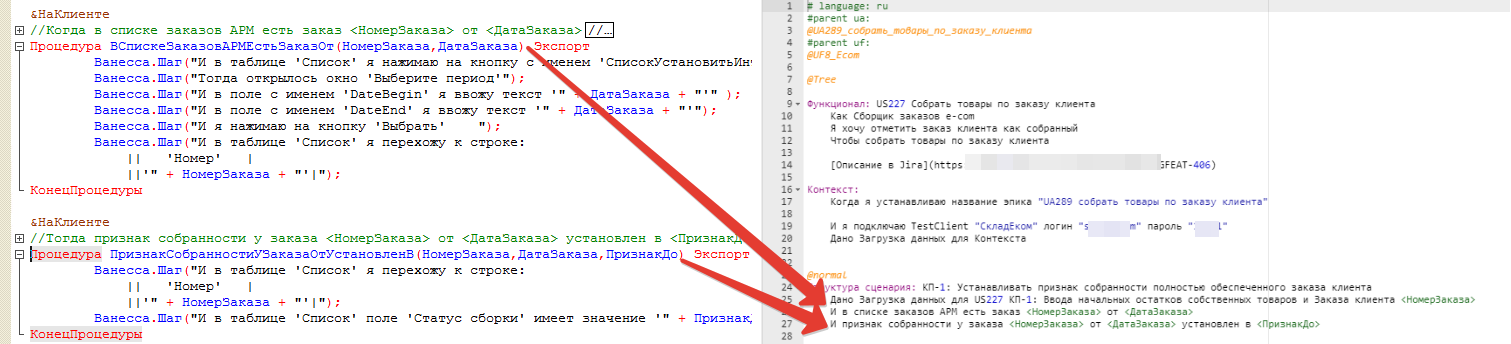
Этот вариант имеет право на существование. Но я вижу такие минусы: для редактирования, при необходимости, шаги второго уровня, нужно заходить в Конфигуратор (а мне ох как не хочется), связь шага в фиче с его определением не очевидна и не интерактивна, дополнительные усилия по обрамлению шагов (особенно это чувствуется, когда шаг с параметрами в виде таблицы), и самое неприятное - при таком подходе шаги второго уровня в отчёте Allure никак не будут фигурировать (то есть если будет ошибка - то нужно будет снова таки открывать Конфигуратор, и смотреть на каком же шаге упало выполнение). Но если вы больше программист, чем аналитик, возможно такой вариант вам подойдёт - и вы настроите сборку epf с определениями шагов, а редактировать будете исходники в VSC с плагином BSL.
Но это не про меня, поэтому - второй вариант. Я создаю техническую US-feature в StoryMapper, ставлю в ней тег @ExportScenarios и для каждого шага первого уровня создаю одноименный сценарий, а в него уже помещаю шаги второго уровня. В результате я получаю то, что мне нужно: бизнесовые фичи как критерии приёмки, технические фичи несут в себе подробности реализации, в Allure на первом уровне сценария светятся шаги первого уровня, а на втором (о чудо!) - шаги второго уровня, редактировать я могу прямо в редакторе StoryMapper (а в VSC с плагином Gherkin Step Autocomplete - это можно делать прямо из бизнес-фичи). Я делаю отдельную техническую фичу для загрузки начальных данных сценариев, и отдельную для шагов-действий и проверочных шагов.
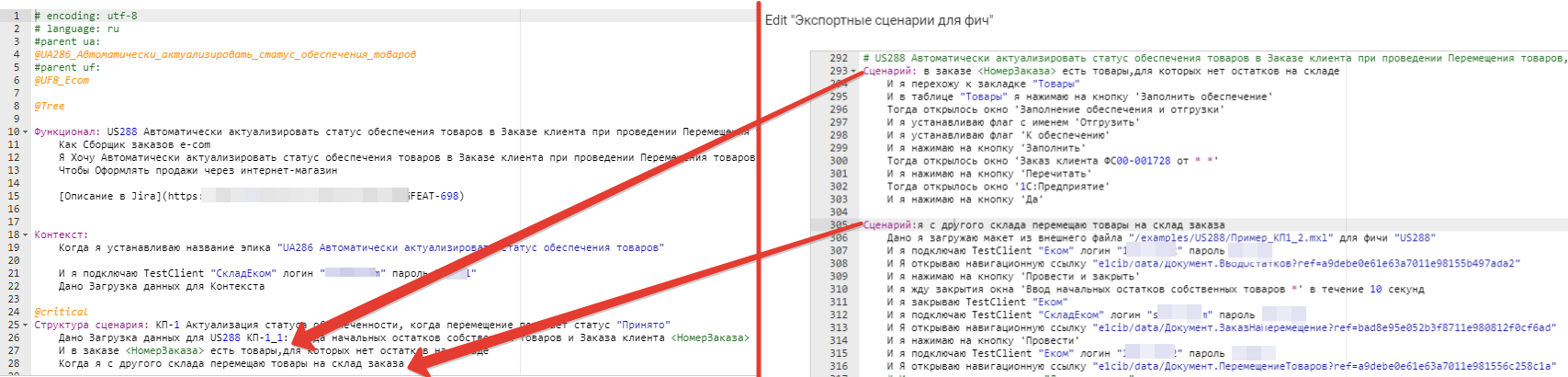
Дальше совсем техника - в VBParams нужно дополнить список тегов-исключений тегом ExportScenarios. Запускаете прогон сценариев и проверяете в Allure, что всё выполнилось корректно, экспортные сценарии подхватились в бизнес-фичах, и можно переходить к следующему этапу.
Мониторинг результатов выполнения сценариев в Checkушка
Завершающий этап нашей BDDSM-эпопеи. Немного теории. Традиционно результаты выполнения сценариев на Gherkin могут консолидироваться в специализированных отчётах типа Cucumber-report, отчёт SpecFlow, ну и наконец всеми любимый Allure. Эти отчёты позволяют увидеть результаты выполнения сценариев с различными группировками и детализацией. В Allure есть красивые диаграммы. Единственное, чего нам не хватало в Allure - это иерархическая визуализация результатов выполнения. Да, есть некоторые ухищрения, которые позволяют выстроить иерархию сценариев в Allure, но она не так наглядна как нам хотелось бы. А хотелось бы нам окинуть систему с достаточно высокого уровня абстракции - увидеть преобладание зелёного над красным и понять: так, в закупках спокойно, продажи более-менее, а вот склад опять подкачал - проблемы какие-то на приёмке. И уже видя сверху проблемную часть - углубиться в Allure, сценарии, шаги, скриншоты, разобраться с тем ошибка ли это сценария, или всё таки функционал подкачал и т.д. В общем всё то, ради чего мы и составляли наши человекочитаемые сценарии. Такое вот обоснование архитектурного решения. Итак, в StoryMapper мы видим ту самую высокоуровневую картину "здоровья системы", так сказать, среднюю температуру по палате, а в Allure (который бесшовно встроен в Checkушку) мы уже как со стетоскопом исследуем конкретную боль. Разобравшись, возвращаемся в StoryMapper и редактируем сценарии, сохраняемся - и снова запускаем прогон сценариев.
Теперь практика. Я пользуюсь тегами. Для того, чтобы в отчёте Allure заиграла диаграмма "Severity" из раздела Graphs я перед каждым сценарием проставляю теги важности, с тем чтобы определиться, выполнение какого сценария исключительно важно для стабильности системы, а какого не так уж и важно. Это позволит сосредоточить усилия на исправлении важных ошибок, если они возникнут, и не распыляться на менее важные, которыми можно заняться позже.
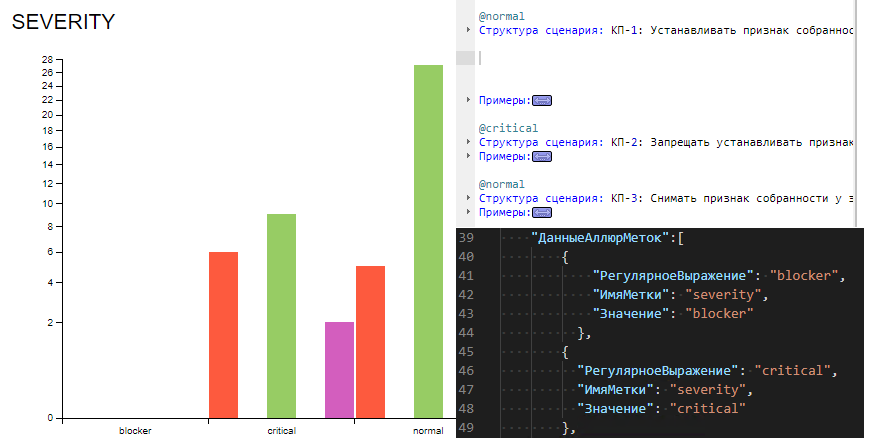
То есть что необходимо: проставить метки в сценариях, а в VBParams добавить вот такие описания меток - и в результате диаграмма Severity заиграет всеми доступными Allure красками.
Вот так у меня выглядит раздел Behaviors:

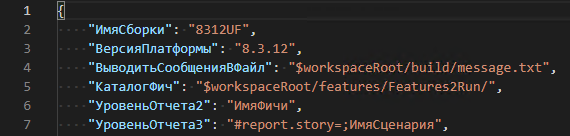
Остановимся на нём поподробнее, потому что именно такого вида мы добивались достаточно долго. Для начала обратите внимание на иерархию. Она, по сути, повторяет иерархию в StoryMapper, но достигается другими средствами. Для того, чтобы верхний уровень стал называться именно так, в контекст каждой фичи добавляется шаг "Когда я устанавливаю название эпика 'UA296 Передать собранный заказ службе доставки'". Это шаг из нашей библиотеки, который устанавливает значение метки "epic" результату выполнения текущего сценария. Подробнее можно уточнить у @pumbae, это его кусок работы.
Второй и третий уровень в виде US и названия сценария достигается вот такими настройками в VBParams (строка 6 и 7):
Ещё одно удобство в отчёте Allure - это осмысленное название конкретного примера в в структуре сценария. Если использовать структуру сценария, и не делать дополнительных телодвижений, то в левой части раздела Behaviors название конкретного примера будет выглядеть так "#1 <Название сценария>", потом "#2 ..." и так далее. Это совершенно не раскрывает, какой кейс мы хотели проверить этим конкретным примером. Поэтому, для того, чтобы осмысленно именовать пример применяется дополнительная колонка с названием Description, в которую для конкретной строчки примера можно вписать осмысленное название примера, которые потом отобразится в Allure (см. отчёты Allure ниже).
Теперь от отчёта Allure перейдём в инструмент StoryMapper. Здесь в визуальной форме доносится та же информация, которая есть в отчёте Allure.
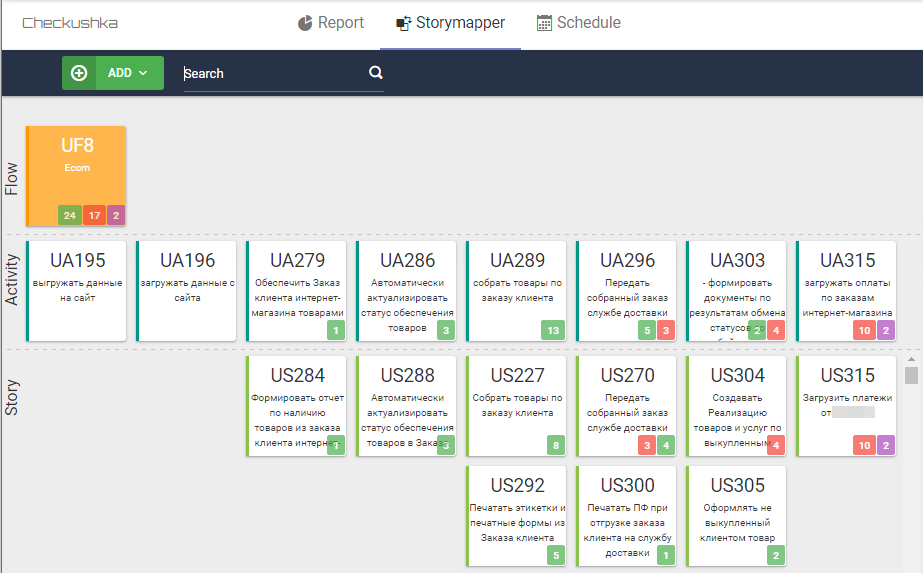
Как этим пользоваться? Для того чтобы посмотреть с высоты на состояние нашей системы в целом, нужно в строке поиска вписать "UF" и тогда на карте останутся только карточки с текстом UF - и будет видно, как дела на высоком уровне абстракции. Если анализировать конкретно эту картинку - видно, что с электронной коммерцией у нас беда: 17 сценариев упали - и это не шутки, надо разбираться. 2 Сценария в процессе написания (Pending), ну а 24 - в порядке. Опустимся на один уровень ниже (да, можно в поиске написать UA - и будут видны пользовательские активности и их родительские UF). На картинке видно, что проблемные UA296, UA303 и UA315. Я знаю, что 315-ая ещё сырая, и я с ней не закончила. Но 296 и 303 буквально вчера были зелёные, соответственно то, что какие-то сценарии у них упали - это явно ошибка, и это надо смотреть с программистом. Для проверки я иду в Allure и смотрю, что же там произошло:
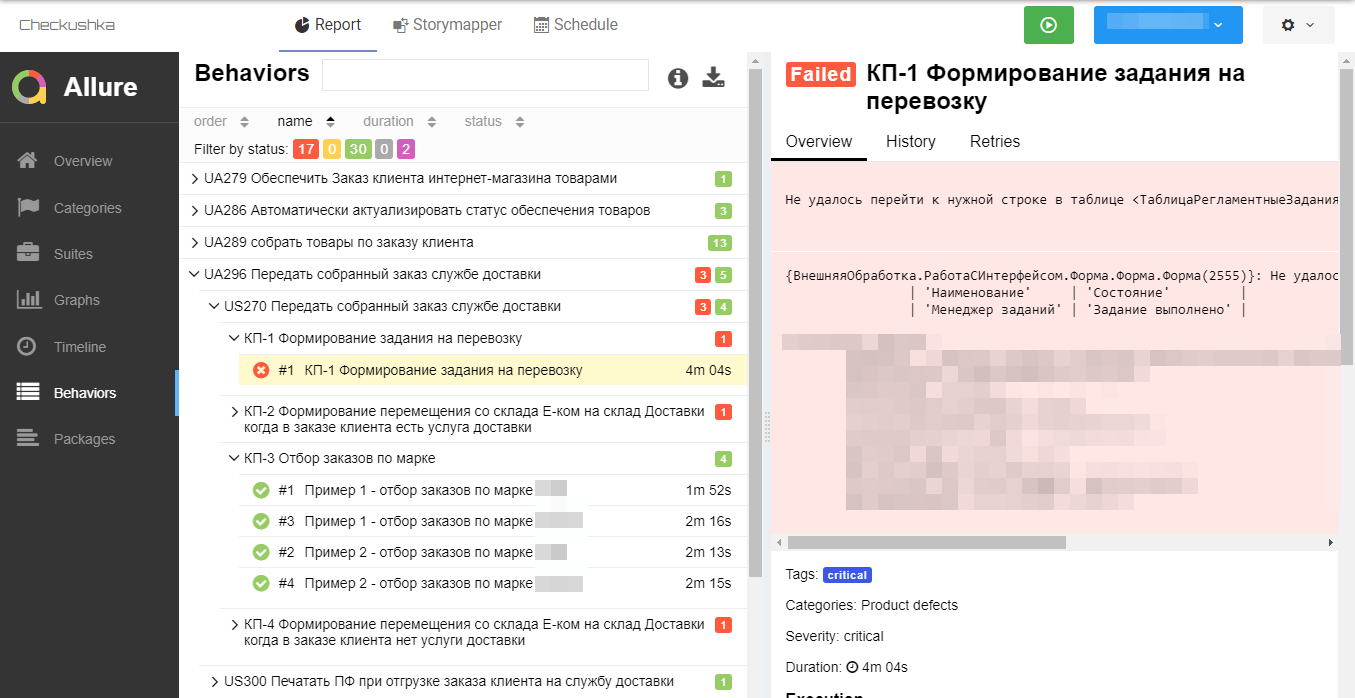
Что-то произошло с регламентным заданием "Менеджер заданий", которое в этом сценарии используется для фонового создания документов. Для окончательного уточнения своего предположения - смотрю на скриншот:
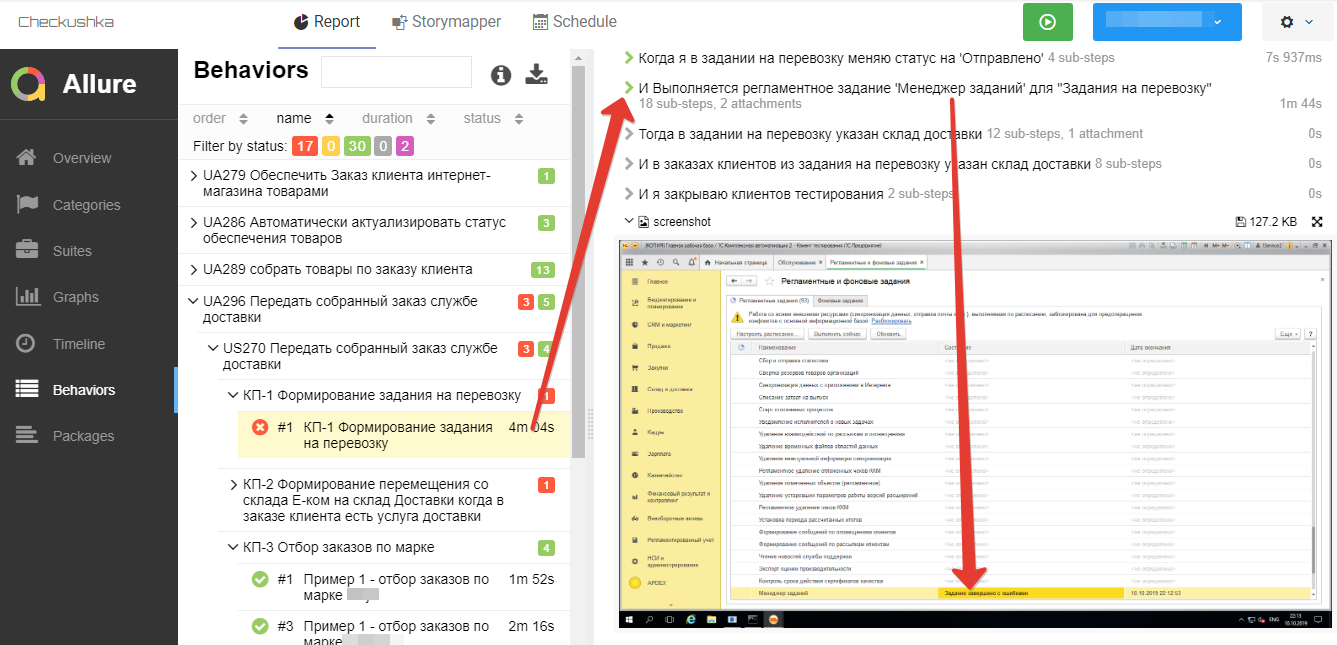
Пока всё сходится: регламентное завершилось с ошибкой. Для верности я могу запустить повторный прогон сценариев, чтобы убедиться, что ошибка не случайная (например, из-за проблем окружения на сервере тестирования), и потом идти к программисту.
Выводы
Поскольку данная статья посвящена практикам, то и выводы будут исключительно практические.
Польза. Их две. Первая - это собственно регрессионка. Ошибка с регламентным заданием - это реальный кейс, который случился при написании статьи. Недели за 2 до этого был пойман ещё один баг: доработка для использования мобильного клиента коснулась настройки начальной страницы, в результате рабочие столы продавцов магазинов, кладовщиков и менеджеров Ecom при запуске очищались. Если бы не было функциональных тестов - то в утро переноса нового функционала в продуктив мы бы поймали шквал недовольства от пользователей. Таких явных случаев было не так много, но они были, и они притушили искорку скепсиса, тлевшую в моей душе (Gherkin не нужен!). Вторая польза - это автодокументирование со встроенной верификацией на актуальность. То есть мы можем ответить на вопрос: а как же оно у нас работает, и быть уверенными, что наша документация - это не прошлогодний снег, поскольку каждый день она проверяется на сервере тестирования актуальной версией конфигурации, расширений и внешних отчётов-обработок.
Усилия. Ну они существенные, весьма. Об этом лучше расскажет Мой Господин, ведь именно он приобщил меня к таинственным BDDSM-практикам. Для меня самое сложное было, конечно, освоить Vanessa. Я была рядовым бизнес-аналитиком, с посредственным знанием УТ-КА (общение с пользователями, формальное описание задач, ручное тестирование, сдача работ заказчикам), когда мне была оказана высокая честь. Если с частью SM было более-менее понятно, литературы хватает. Но с частью функционального тестирование мне, как человеку совершенно далекому от программирования, было достаточно тяжело. Но Мой Господин ставил перед собой именно такую цель: доказать, что BDD - это не о программистах, это бизнес-анализ. И любая кухарка любой бизнес-аналитик при наличии опытного ментора и соответствующих инструментов сможет выдавать качественный результат. По моему скромному мнению, что-то из этого получилось.
Сроки. Часть с электронной коммерцией и ещё парой фич была реализована мной с нуля за три месяца. Причём с нуля - это и обо мне, и о функционале, и о фичах. Походу реализации Ecom было много инсайтов и переделок, позволивших чётче понять и осознать, как правильнее практиковать BDDSM. Я думаю, если бы я стартанула с моим текущим бэкграундом, за месяц можно было бы управиться.
Сложности. Ну а куда без них? Одна из сложностей - это то, что жизнь неумолимо летит вперёд, и я со своими сценариями должна была за ней поспевать. Ну и один раз не поспела. Пока я делала сценарии по проверке подсортировки магазинов товарами, была реализована новая более оптимальная версия алгоритма. Соответственно, мой труд был напрасным. Ну, не совсем. Заготовка шагов верхнего уровня поменялась несущественно, но вот примеры и шаги второго уровня придётся все переделывать. Вторая сложность - это поддерживать всё в актуальном состоянии. Всегда есть искушение побыстрее закрыть задачу по доработке текущего функционала, а разработку сценариев засунуть в глубокий бэклог. Ну и тут очень важна воля руководства сверху, и культура Definition Of Done внизу. Энтропия не дремлет.
Список литературы
- Джефф Паттон, Пользовательские истории. Искусство гибкой разработки ПО, Спб., Питер, 2017.
- Майк Кон, Пользовательские истории. Гибкая разработка программного обеспечения, М.-Спб.-К, Вильямс, 2012.
- Gojko Adjic, Specification by Example, NY, Manning Publication, 2011.
- Олейник Д.В., Полевые исследования концепции "Documentation as code"