Обнаружил, что вопросы синтаксического анализа не очень широко освещаются в контексте программирования на 1С. Навскидку нашел здесь, здесь и здесь. И почему-то все публикации посвящены чтению данных в формате CSV. Видимо, эта проблема сильно волнует умы населения. Вообще-то, изначально я собирался взять в качестве примера что-нибудь более классическое, вроде первичного разбора текста на лексемы. Но, раз уж задача чтения CSV так популярна, то решил и в своей статье взять её в качестве примера. Заодно будет возможность сравнить мой подход с подходами предшественников.
Также нашел публикацию, посвященную вопросу автоматической генерации синтаксических анализаторов. Тема интересная, когда-то давно сам занимался подобной задачей на 1С. Но решил пока осознанно уклониться от этой темы. Всё-таки, моя статья называется «Синтаксический анализ на коленке», а это значит – простые решения, своими руками и без использования каких-либо сторонних инструментов.
В этой статье я познакомлю читателей с приемами синтаксического анализа с использованием конечных автоматов. Тем, кто изучал конечные автоматы, статья наверняка покажется тривиальной и неинтересной. Рассчитываю на интерес тех читателей, кто ранее не сталкивался с этой областью знаний.
Что это такое?
Я не буду здесь излагать математическую теорию конечных автоматов, об этом можно почитать в разнообразной профильной литературе. Попробую объяснить на пальцах.
Конечный автомат (КА) – это объект, управляемый входным потоком символов и имеющий внутреннее состояние. При обработке очередного символа КА изменяет свое состояние. При переходе в некоторые состояния КА может выполнять какие-то полезные действия. В итоге КА достигает одного из своих конечных состояний, после чего его работа останавливается. Вот и всё.
Использование КА в синтаксическом анализе основано на том, что синтаксические правила формального языка могут быть преобразованы в правила изменения состояний КА. Переход КА в то или иное состояние будет означать, что обработанный к этому моменту фрагмент текста представляет собой то или иное слово или выражение входного языка.
КА бывают без памяти и с памятью. КА без памяти – более простые и используются для анализа простых грамматик, не содержащих рекурсивно вложенных конструкций. Состояние КА без памяти характеризуется только одной переменной – собственно текущим состоянием, которое обычно выражается целым числом (номером состояния), но, впрочем, никто не запрещает обозначать состояния какими-то осмысленными именами.
КА с памятью – более сложные. Помимо переменной, содержащей текущее состояние, они также содержат стеки, в которых могут хранить свои прошлые состояния, ранее обработанные символы и много чего еще, что нужно для анализа сложных грамматик. В этой статье мы рассмотрим только КА без памяти.
Зачем это надо?
Вот примеры задач, которые можно решать при помощи конечных автоматов:
-
Обработка текста, имеющего некоторую формализованную структуру (рассматривается в этой статье на примере чтения CSV-файла).
-
Вычисление выражений по формулам – если вам вдруг захочется превратить табличный документ 1С в некое бледное подобие Excel (вот вы смеетесь, а мне приходилось).
-
Разбор XML файла со сложной структурой. Символами здесь будут не текстовые символы, а узлы XML (первичный низкоуровневый разбор нам обеспечивает объект ЧтениеXML).
-
Реализация бота для взаимодействия с системой через мессенджер в диалоговом режиме. Роль символов здесь будут играть команды пользователя, а состояние КА будет обозначать текущую позицию в диалоговом сценарии.
Простейший пример
Визуализировать КА принято в виде диаграммы состояний. Она представляет собой ориентированный граф, где вершины графа соответствуют состояниям КА, а ребра графа соответствуют переходам между состояниями и обозначены символами, при поступлении которых осуществляются эти переходы.
Вот диаграмма состояний КА, который ищет в тексте подстроку «мат».
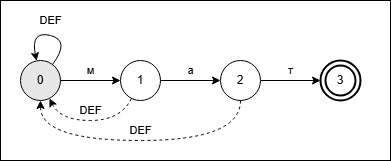
Сразу скажу, что данный КА не представляет никакой практической ценности для решения задачи поиска подстроки, функция СтрНайти гораздо эффективнее. Но он позволяет проиллюстрировать основные принципы описания и функционирования КА.
На диаграмме состояний кружками обозначены состояния КА и их номера (0, 1, 2, 3). 0 – начальное состояние. Кружком с двойной стенкой обозначено конечное состояние. Стрелки обозначают переходы между состояниями. Буквы «м», «а», «т» - символы, сопряженные с переходами. При поступлении символа на вход КА осуществляется соответствующий переход. Символ DEF (от слова default) – это условный символ, обозначающий переход «по умолчанию», который выполняется, если не выполнилось условие перехода по одному из явно заданных символов.
Сплошными стрелками обозначены переходы со сдвигом, пунктирными стрелками – переходы без сдвига. Отличие в том, что при переходе со сдвигом указатель чтения сдвигается на следующий символ, а при переходе без сдвига – остается на текущем символе, т.е. на следующей итерации этот же символ будет обработан повторно.
В начале работы КА находится в состоянии 0. На вход ему подается текстовая строка. Он обрабатывает строку посимвольно, начиная с первого символа. Читает символ: если это «м», то переходит в состояние 1, иначе (DEF) – остается в состоянии 0. Предположим, что в конце концов символ «м» попался и КА перешел в состояние 1. Если сразу за «м» следует символ «а», то КА перейдет в состояние 2, в противном случае (DEF) вернется в состояние 0 (без сдвига). В конце концов, если будет прочитана последовательность «мат», КА перейдет в конечное состояние 3 и на этом остановится. Затем его можно сбросить в начальное состояние 0 и продолжить поиск следующей подстроки.
Также КА может быть описан матрицей переходов, где колонки соответствуют текущим состояниям, строки – символам, а в каждой ячейке указывается следующее состояние. Эта форма описания нам мало пригодится ввиду того, что в 1С отсутствуют удобные средства для определения константных матриц. В простых задачах реализация КА выполняется при помощи конструкций «Если».
Реализация нашего простейшего КА на языке 1С будет выглядеть следующим образом:
Функция НайтиСтрокуМАТ(Текст, Поз = 1)
Состояние = 0; // текущее состояние КА
НачПоз = 0; // предполагаемая позиция начала подстроки
Пока Поз <= СтрДлина(Текст) Цикл
Сим = Сред(Текст, Поз, 1);
Если Состояние = 0 Тогда
НачПоз = Поз;
Если Сим = "м" Тогда
Состояние = 1;
КонецЕсли;
ИначеЕсли Состояние = 1 Тогда
Если Сим = "а" Тогда
Состояние = 2;
Иначе
Состояние = 0;
Продолжить; // переход без сдвига
КонецЕсли;
ИначеЕсли Состояние = 2 Тогда
Если Сим = "т" Тогда
Состояние = 3;
Иначе
Состояние = 0;
Продолжить; // переход без сдвига
КонецЕсли;
ИначеЕсли Состояние = 3 Тогда
// В конечном состоянии 3 совершаем полезное действие:
// возвращаем позицию начала найденной подстроки
Возврат НачПоз;
Иначе
// Перестраховка на случай возникновения неизвестного состояния
ВызватьИсключение "Ошибка алгоритма";
КонецЕсли;
Поз = Поз + 1;
КонецЦикла;
Возврат 0;
КонецФункции
Практический пример: чтение CSV
Перейдем теперь к более полезному применению КА. Существует текстовый формат CSV для обмена данными в табличной форме, который до сих пор популярен ввиду своей компактности. Стандарт CSV описан в RFC-4180.
В простейшем случае данные в CSV-файле хранятся в виде строк, которые, в свою очередь, состоят из полей, разделенных символом-разделителем (стандартно это запятая «,», но также может использоваться точка с запятой «;», а в экзотических случаях – вертикальная черта «|»). Казалось бы: читай файл построчно и используй СтрРазделить. Но есть одна закавыка (ха-ха): стандарт допускает наличие закавыченных полей, которые могут внутри кавычек содержать и запятые, и переносы строк, и саму кавычку в виде удвоенной кавычки. СтрРазделить не годится, нужен более умный парсер.
Нашей задачей будет реализация функции, которая читает строку CSV и возвращает прочитанные поля в виде массива. Циклически вызывая эту функцию, можно прочитать весь CSV-файл.
Необходимое уточнение: под термином «строка CSV» будем понимать строку таблицы (row), которая может состоять из нескольких текстовых строк (line) из-за наличия многострочных полей.
Начнем с формализации синтаксиса CSV. Вы можете научиться строить диаграмму состояний КА у себя в голове (это приходит с опытом), но письменную формализацию входного языка рекомендуется выполнять всегда. Формализация условий задачи – залог ее успешного решения.
Для описания используем общепринятую форму РБНФ (расширенная форма Бэкуса-Наура, EBNF).
(подсветка синтаксиса абсолютно левая, не знаю как отключить, просто игнорируйте)
Файл = Строка [EOL Файл].
Строка = Поле [Разделитель Строка].
Поле = [Незакавыченное] | Кавычка [Закавыченное] Кавычка.
Незакавыченное = !(EOL | Разделитель | Кавычка) [Незакавыченное].
Закавыченное = (!Кавычка | Кавычка Кавычка) [Закавыченное].
Кавычка = '"'.
Разделитель = ','.
EOL = 0x0A.
Теория требует, чтобы формальное описание языка содержало описание его алфавита. Но данные в файле CSV вполне могут содержать что-нибудь на китайском или арабском, а перечислять все символы Unicode – занятие неблагодарное. Поэтому мы вывернемся хитрым образом: введем знак отрицания. Это будет наше с вами маленькое расширение стандарта. Знак отрицания «!» следует читать как «любой символ, кроме указанного».
Существует набор формальных правил, позволяющий построить КА по БНФ-описанию. На этом построена работа автоматически генераторов КА, таких как yacc или bison. Но мы построим наш КА вручную, «на коленке». Даже не зная формальных правил, для простой грамматики это можно сделать интуитивно.
Диаграмма КА для чтения строки CSV будет выглядеть так:
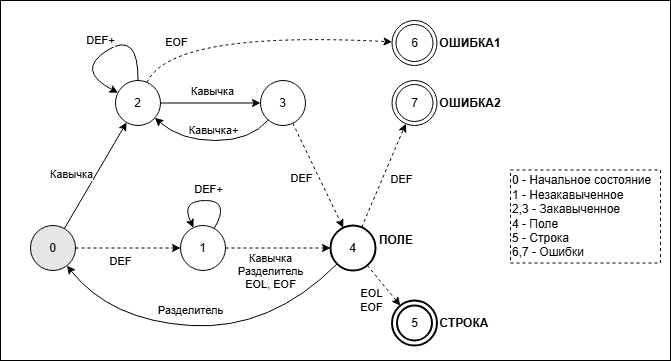
Расшифровка используемых обозначений:
-
Кавычка – символ двойной кавычки
-
Разделитель – символ-разделитель полей (стандартно – запятая, но мы его параметризируем)
-
EOL – символ конца текстовой строки
-
EOF – условный символ конца файла (на самом деле, в конце файла нет никакого специального символа, поэтому будем его имитировать)
-
DEF – условный символ «по умолчанию» (был рассмотрен выше)
-
…+ - знак «+» после символа означает, что при переходе символ добавляется в накопительный буфер
-
ПОЛЕ – действие: добавление прочитанного поля (накопительного буфера) в массив полей
-
СТРОКА – действие: возврат прочитанной строки CSV в виде массива полей
-
ОШИБКА1 – ошибка: неожиданный конец файла
-
ОШИБКА2 – ошибка: недопустимый символ
Этот КА несколько сокращенный: при его построении не использовалась первая строка из БНФ-описания (Файл). Это из-за того, что мы реализуем КА для чтения только одной строки CSV.
Имея диаграмму состояний КА, не составляет труда реализовать его в виде функции:
// Читает одну строку таблицы из файла CSV.
//
// Параметры:
// ЧтениеТекста - ЧтениеТекста
// Разделитель - Строка - Символ-разделитель полей
// ОписаниеОшибки - Строка - В случае ошибки здесь возвращается описание ошибки, иначе пустая строка.
//
// Возвращаемое значение:
// - Массив из Строка - Массив значений полей при успешном чтении. Может содержать 0 элементов.
// - Неопределено - Конец файла или ошибка (см. ОписаниеОшибки)
//
Функция ПрочитатьСтрокуCSV(Знач ЧтениеТекста, Знач Разделитель, ОписаниеОшибки = "")
Поля = Новый Массив;
Буфер = "";
Текст = ЧтениеТекста.ПрочитатьСтроку();
Если Текст = Неопределено Тогда
Возврат Неопределено;
КонецЕсли;
Поз = 1;
Состояние = 0;
Пока Истина Цикл
Сим = ""; // EOF
Если Текст <> Неопределено Тогда
Длина = СтрДлина(Текст);
Если Поз <= Длина Тогда
Сим = Сред(Текст, Поз, 1);
ИначеЕсли Поз = Длина + 1 Тогда
Сим = Символы.ПС; // EOL
КонецЕсли;
КонецЕсли;
Если Состояние = 0 Тогда // Начальное состояние
Если Сим = """" Тогда
Состояние = 2;
Иначе
Состояние = 1;
Продолжить;
КонецЕсли;
ИначеЕсли Состояние = 1 Тогда // Незакавыченное
Если Сим = """" ИЛИ Сим = Разделитель ИЛИ Сим = Символы.ПС ИЛИ Сим = "" Тогда
Состояние = 4;
Продолжить;
Иначе
Буфер = Буфер + Сим;
КонецЕсли;
ИначеЕсли Состояние = 2 Тогда // Закавыченное
Если Сим = """" Тогда
Состояние = 3;
ИначеЕсли Сим = "" Тогда
Состояние = 6;
Продолжить;
Иначе
Буфер = Буфер + Сим;
КонецЕсли;
ИначеЕсли Состояние = 3 Тогда // Закавыченное
Если Сим = """" Тогда
Буфер = Буфер + Сим;
Состояние = 2;
Иначе
Состояние = 4;
Продолжить;
КонецЕсли;
ИначеЕсли Состояние = 4 Тогда // Поле
Поля.Добавить(Буфер);
Буфер = "";
Если Сим = Разделитель Тогда
Состояние = 0;
ИначеЕсли Сим = Символы.ПС ИЛИ Сим = "" Тогда
Состояние = 5;
Продолжить;
Иначе
Состояние = 7;
Продолжить;
КонецЕсли;
ИначеЕсли Состояние = 5 Тогда // Строка
Возврат Поля;
ИначеЕсли Состояние = 6 Тогда
ОписаниеОшибки = "Неожиданный конец файла";
Возврат Неопределено;
ИначеЕсли Состояние = 7 Тогда
ОписаниеОшибки = "Недопустимый символ";
Возврат Неопределено;
Иначе
ВызватьИсключение "Ошибка алгоритма";
КонецЕсли;
Поз = Поз + 1;
Если Текст <> Неопределено И Поз > СтрДлина(Текст) + 1 Тогда
Текст = ЧтениеТекста.ПрочитатьСтроку();
Поз = 1;
КонецЕсли;
КонецЦикла;
КонецФункции
Необходимые пояснения: Мы используем объект 1С ЧтениеТекста для построчного чтения файла. Метод ПрочитатьСтроку() обрезает символ конца строки, поэтому, при достижении указателем конца текущей строки, мы имитируем поступление символа EOL (в виде Символы.ПС). При попытке сдвига указателя еще дальше, выполняется попытка чтения следующей строки из файла. При отсутствии следующей строки имитируется поступление символа EOF (в виде пустой строки).
Замечу, что в этом КА количество состояний всего на 4 больше, чем в ранее рассмотренном "учебном" КА, зато его практическая полезность неизмеримо выше. Вообще, с ростом сложности грамматики количество состояний КА увеличивается, но при этом структурная сложность алгоритма не растет. Или можно сказать, что сложность растет количественно, но не качественно. Поэтому возможность реализации КА вручную, без генератора, сохраняется и при решении более сложных задач.
На этом всё. Если было интересно, то в следующий раз постараюсь рассказать про КА с памятью.
Обновление 22.01.2025. Если интересна тема недетерминированных конечных автоматов (НКА), то есть публикация, а в ней есть ссылка на презентацию, где доступно объясняется, как используется НКА для проверки совпадений по регулярным выражениям (regex).
Обновление 24.01.2025. Продолжение: Оптимизация КА по времени выполнения.
Вступайте в нашу телеграмм-группу Инфостарт