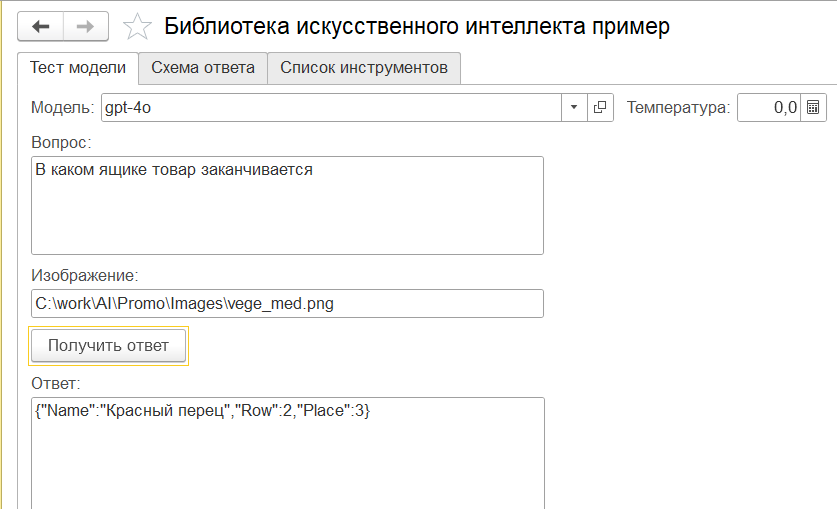





Некоторое время назад я добавил в Библиотеку искусственного интеллекта для 1С опцию ввода изображения. Тестирование новой опции, как и положено 1С-нику, я начал с распознавания УПД. Результаты получились отличными, но сама история с распознаванием первички сейчас уже, что называется, "не модна". В самом деле, ну кто сейчас возится с бумагой. Поэтому я решил попробовать что-нибудь более актуальное. Взял первое понравившееся мне фото.

И задался простым вопросом: сможет ли state-of-art модель определить какой товар заканчивается. Так как нам нужно на выходе не бла-бла-бла, а четкий ответ, набросал JSON-схему и начал экспериментировать.
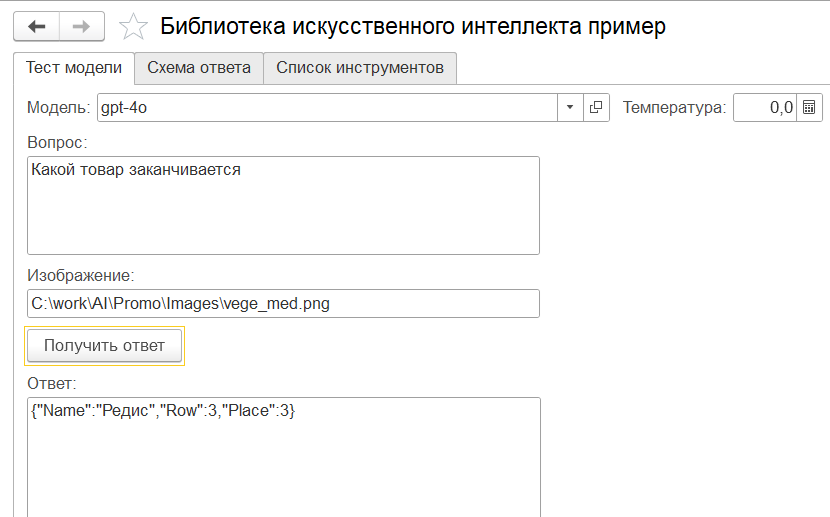
Упс! Вообще-то я ожидал получить сообщение о том, что заканчиваются кабачки. Ну ладно, пробуем дальше
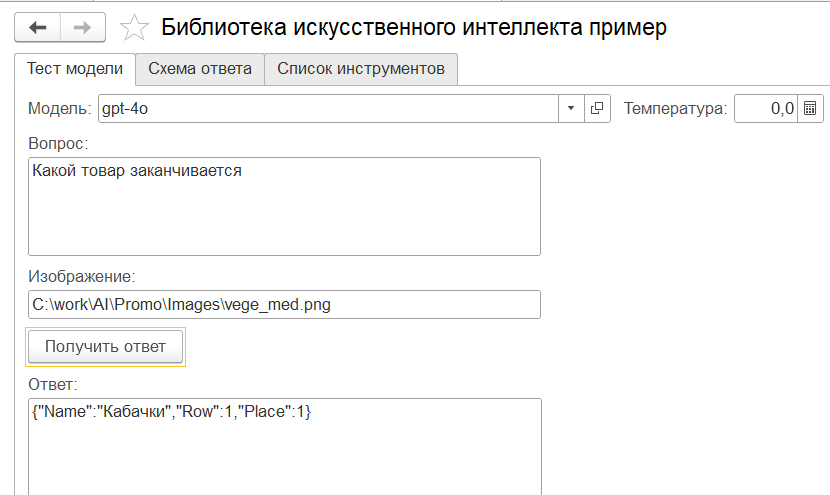
На этот раз действительно "кабачки". Потом еще раз выдало "кабачки". А потом
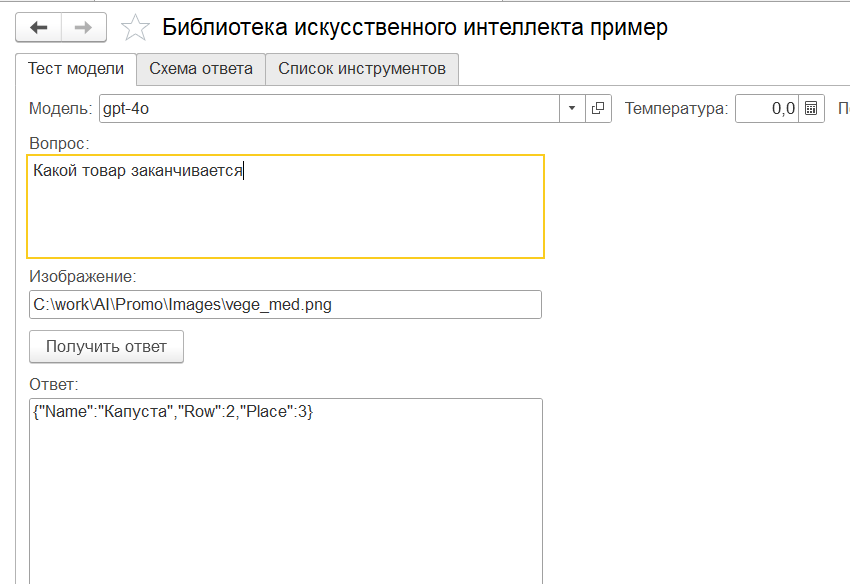
Потом еще были 2 раза "кабачки". Потом вдруг "красный перц"...
Если вы на этом месте сказали себе: "ага! не работает", то вас, возможно, удивит то, что я на этом самом месте сказал себе: "ага! работает".
Как такое происходит и почему мы видим одно и то же, но приходим к прямо противоположным выводам? На мой взгляд, именно здесь кроется причина неприятия новой технологии. До сих пор область ИТ была царством строгой логики. Мы привыкли иметь дело с детерминированными системами. И это "сбивает нам прицел". При столкновении с вероятностной системой, наша интуиция нам подсказывает: "это не работает". Но здесь она ошибается. Вероятность надежна, как бы контринтуитивно это не звучало. В самом деле. Если в 10 запусках я получил 6 раз "кабачки", 2 раза "редис", 1 раз "перец" и 1 раз "капуста", тогда все что мне нужно, это запускать 10 раз и выбирать наиболее часто встречающееся.
К работе с вероятностными системами надо просто привыкнуть. В предыдущей статье А мы все видим говорилось о распознавании первичных документов, типа УПД. В обсуждении всплыла тема: а какова надежность всего этого? Каков будет процент ошибок? Так вопрос может ставить только тот, кто привык к детерминированным системам. Здесь, да. Если у вас одни и те же входные условия, в нашем случае это одно и то же изображение на входе, то если уж вы получили ошибку на выходе. То вы и дальше будете ее получать, хоть тысячу раз запускай. И если у вас из 100 документов 1 дает ошибку, то на этом все. У детерминированных систем. У вероятностных не так. Если у нас 1 ошибка на 100 документов, и нам это не нравится, то нет проблем. Будем запускать распознавание каждого документа 2 раза и получим уже 1 ошибку на 10 000 документов. Нужен миллион? Будем запускать по три раза. С учетом того, что запуск стоит несколько копеек, мы можем себе такое позволить. С вероятностными системами нет вопроса: каков будет процент ошибок? Есть только вопрос: какой процент вам нужен?
Осваивайте работу с искусственным интеллектом, дорогие коллеги! Тут интересно!
Пример, который я здесь привел, учебный. Не рассматривайте его, как готовый инструмент для работы в магазине или на складе. Для получения рабочего инструмента тут еще надо экспериментировать с изображениями, ракурсами, разрешениями, моделями (gpt-4o не самый лучший вариант). В приложении к статье заготовка для таких экспериментов.
PS Картинку взял на Freepik, ее автор aleksandarlittlewolf
Проверено на следующих конфигурациях и релизах:
- Управление торговлей, редакция 11, релизы 11.5.21.95
Вступайте в нашу телеграмм-группу Инфостарт