Это статья о том, как команда из четырех человек за два дня создала бота, который берет на себя 40% работы с обращениями в техническую поддержку.


Толчком к созданию проекта стал пост во ВКонтакте о хакатоне «Атомикхак 2.0». Одна из тем звучала так: «Создание системы технической поддержки пользователей с использованием искусственного интеллекта в контексте 1С». Для меня это было пересечением двух ключевых интересов: ИИ и платформы 1С.
Нам предстояло решить следующую задачу: в государственной корпорации все обращения пользователей регистрируются в единой информационной системе (ЕИС). У каждого обращения есть краткое наименование, описание проблемы от пользователей и идентификатор.
Наша цель: уменьшить количество обращений пользователей к линии ИТ поддержки.
Проблемы
Пользователи не используют инструкции для самостоятельного решения проблемы. Детально рассмотрев проблему, предложенную на хакатоне, мы выяснили, что почти у каждой компании имеются написанные инструкции, предоставляемые к разработанному функционалу. Но пользователи не хотят «рыться в стоге документов» ради нескольких строк, решающих их проблему.
Обращение к коллегам неэффективно. При возникновении проблемы можно обратиться за помощью к коллегам. Однако если коллега погружен в рабочий процесс, такое обращение отвлечет его от задачи. Для восстановления концентрации ему потребуется до двадцати минут, что снижает общую эффективность команды. При удаленной работе ситуация усугубляется: в ответ на сообщение часто приходит «отвечу позже», и сотруднику приходится тратить время на ожидание решения.
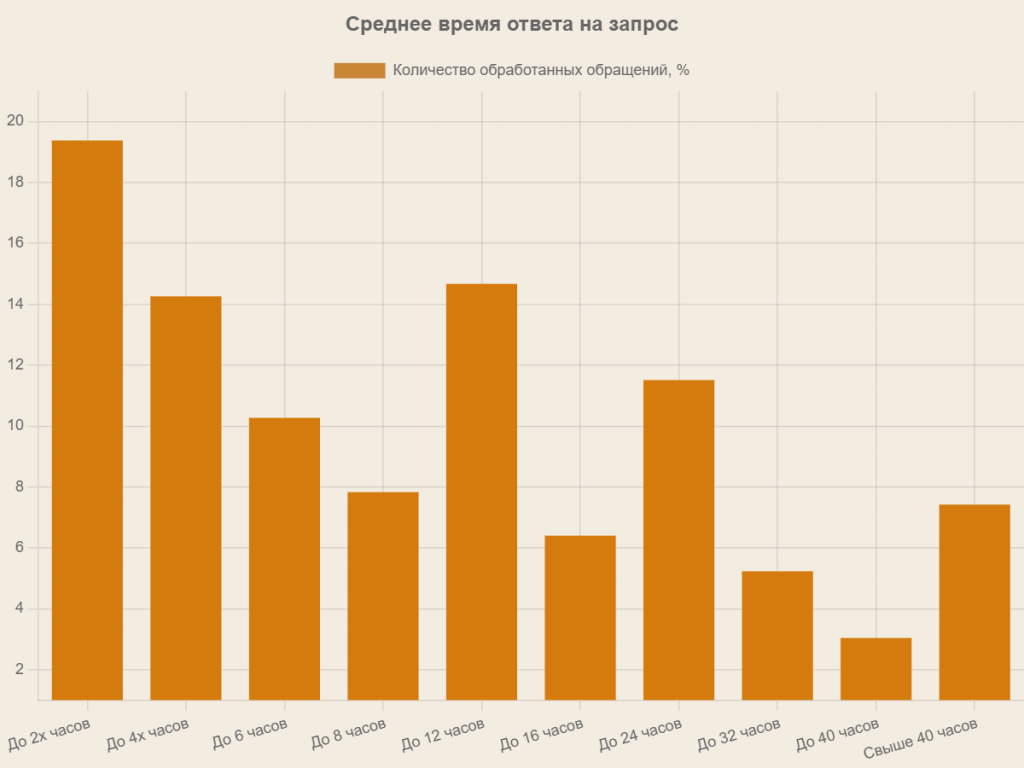
Техподдержка перегружена. Только 19% обращений закрываются за первые два часа. Остальные накапливаются в очереди. Получение оперативного ответа на простой вопрос отнимает много времени как у службы поддержки, так и у пользователя. Особенно критична ситуация, когда решение необходимо немедленно.
Типовые подходы к решению
Контекстные подсказки. Хотя метод эффективен, его разработка сложна: помимо основного функционала требуется прогнозировать все возможные сценарии ошибок и варианты поведения. Это существенно увеличивает стоимость реализации.
Поиск по ключевым словам в существующих инструкциях. Пользователь, столкнувшийся с проблемой, часто не знает, какие термины использовать для поиска. Кроме того, система не анализирует контекст запроса. В результате выдается несколько вариантов ответа, среди которых пользователь вынужден выбирать вручную, тратя дополнительное время.
База знаний на основе часто задаваемых вопросов. Она позволяет систематизировать экспертные решения, предотвращать повторные обращения и служит материалом для обучения пользователей. Однако база знаний на основе часто задаваемых вопросов не покрывает все возможные проблемы пользователей.
Видеоинструкции. Несмотря на улучшение первоначального понимания функционала, пользователь, как правило, просматривает их однократно. При возникновении конкретной проблемы необходим повторный поиск нужного фрагмента, что требует знания временных меток и значительно увеличивает время решения.
Искусственный интеллект
В этой статье мы хотим рассказать, как современные технологии преодолевают описанные ограничения. Первым решением, приходящим на ум, неизбежно становится искусственный интеллект — технология, интегрируемая повсеместно: от смартфонов и автомобилей до бытовой техники. ИИ, работающие с текстом, демонстрируют впечатляющие результаты: они способны анализировать запросы, формулировать осмысленные ответы и порой неотличимы от человека в диалоге.
Альтернативным подходом является применение алгоритмов анализа больших данных для формирования комплексной базы знаний на основе истории обращений в техподдержку. Однако такой подход потребует разработки дополнительных инструментов для классификации входящих запросов и их сопоставления с историей обращений. Это трудоемкий и ресурсоемкий процесс. В сравнении с ним решения на основе ИИ предлагают более простой и интересный путь.
Большие языковые модели
Многие знакомы с ChatGPT, YandexGPT и GigaChat. Эти модели обучаются на огромных массивах данных, подготовленных Data-инженерами. Они обычно предоставляются по платной подписке, а их API тарифицируется за каждый запрос.
Альтернатива — открытые модели с лицензиями вроде Apache. На хакатоне мы выбрали Llama 3.0 — предварительно обученная большая языковая модель среднего масштаба (7 млрд параметров), способная качественно обрабатывать базовые запросы. Но ключевая проблема осталась: даже продвинутые ИИ, включая ChatGPT, не разбираются в специфике платформы 1С.
Теоретически модель можно дообучить на информации про 1С. Однако дообучение языковых моделей — один из самых ресурсоемких и дорогостоящих этапов разработки искусственного интеллекта. Даже при готовности к значительным финансовым затратам на дообучение модели возникает принципиальная проблема: при изменении функционала системы обучение на статических инструкциях теряет актуальность. Это приводит к нерелевантным ответам модели, которые дезориентируют пользователей и усугубляют проблему вместо решения.
RAG
Нашим решением стал подход RAG (Retrieval Augmented Generation). Его суть — программное обогащение запроса пользователя актуальными данными из надежных источников перед передачей в языковую модель.
Рассмотрим на примере запроса о курсе доллара. Сама по себе языковая модель не имеет доступа к реальным данным. Через поисковик (например, Яндекс) мы уточняем текущий курс доллара. После того, как поисковая система выдаст нам результат, вставляем страницу с ответом поиска в запрос языковой модели.
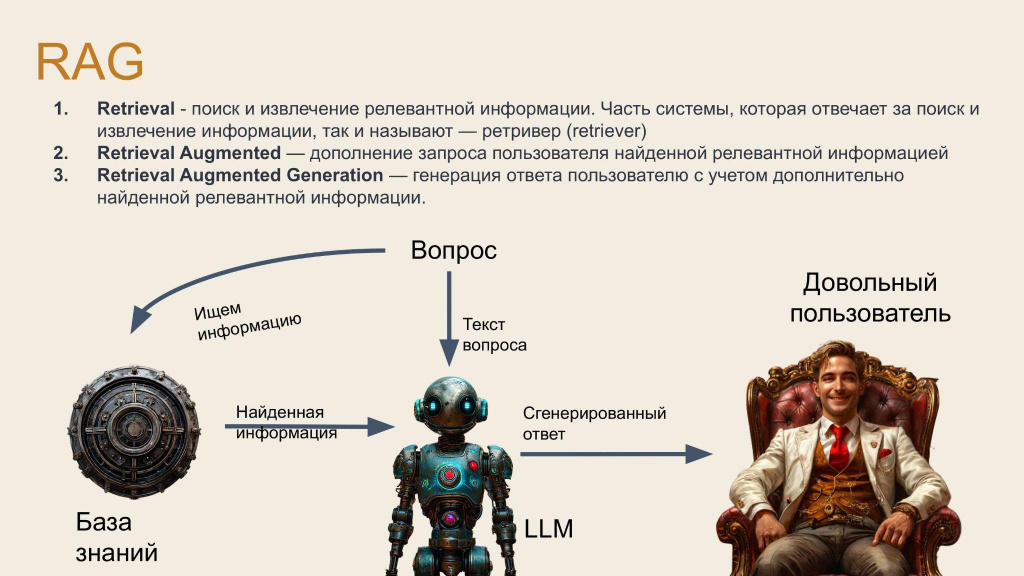
Преимущество подхода в том, что отсутствует необходимость создавать шаблоны ответов вручную. В сценарии техподдержки, когда пользователь задает вопрос в техподдержку, она перенаправляет вопрос боту. В это время система RAG ищет информацию по написанным ранее инструкциям и адаптирует запрос. Затем запрос уходит нейронной сети, которая формирует ответ.
Ключевым недостатком решения является то, что этап Retrieval воспроизводит классическую проблему точности поисковых систем. Как отмечалось ранее, критически важно разработать механизм поиска, гарантирующий релевантность найденных данных пользовательскому запросу. Таким образом, RAG представляет собой не радикально новую технологию, а комбинацию нового и старого подхода.
Насколько это эффективно?
Для оценки эффективности ответов языковой модели необходим практический инструментарий. Сгенерированный моделью ответ на заданный на хакатоне вопрос «Как оформить выпуск продукции в документе "Заказ на производство"?» приведен на рисунке ниже.

Для оценки эффективности модели необходимо самостоятельно сформировать тестовую выборку вопросов и примерные ответы. Далее производится сравнение ответов модели с экспертными.
На хакатоне для тестирования системы были предоставлены 15 вопросов: 10 с ответами в инструкциях и 5 — из смежных или не описанных в документации областей. Система корректно ответила на 8 из 10 вопросов (по инструкциям).
Внедрение в 1С
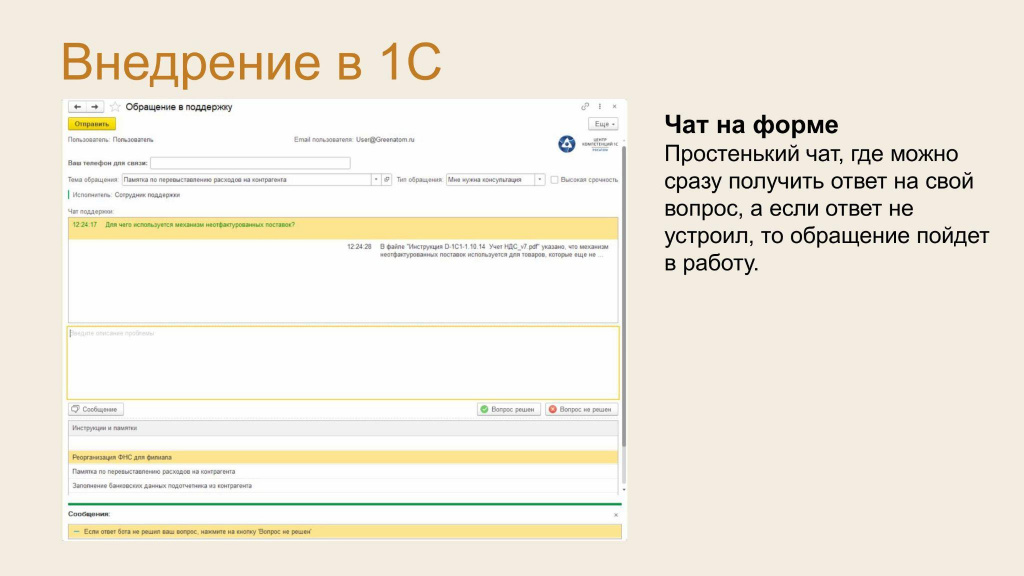
Для интеграции решения в 1С мы доработали форму создания обращения в техподдержку, добавив чат. Перед тем, как отправить обращение в поддержку, вам предлагается задать вопрос в чате. В нем вам отвечает бот. Если вас устроит ответ, то достаточно нажать на кнопку «Вопрос решен», и обращение автоматически закроется. Если ответ вас не устроит, то вы можете переспросить бота в чате или нажать на кнопку «Вопрос не решен», после чего обращение самостоятельно оформится и отправится специалистам поддержки. В случае, если бот не смог ответить на вопрос, запрос перенаправляется специалисту техподдержки автоматически.
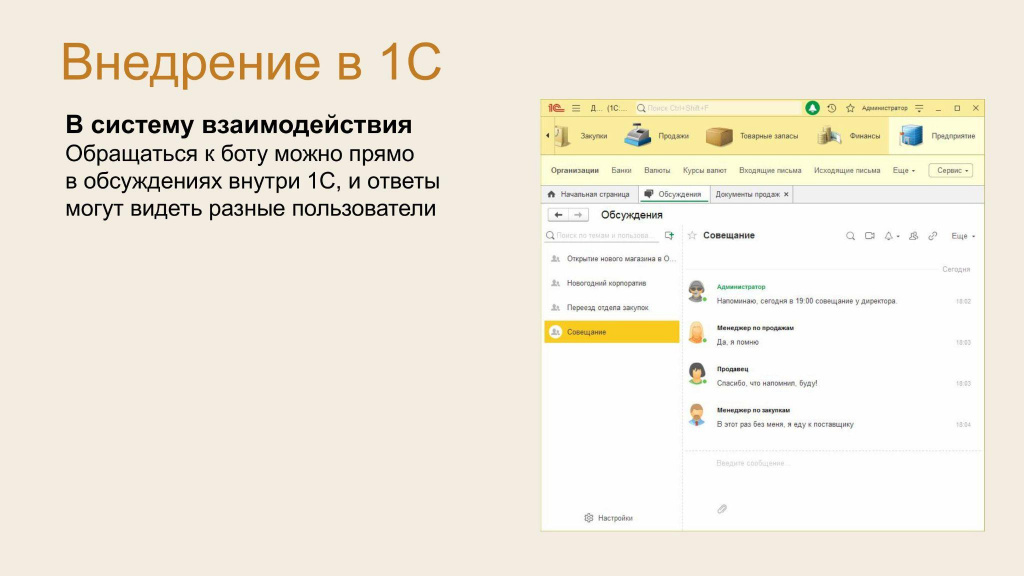
Еще один вариант использования — внедрить в систему взаимодействия. Так мы сможем накопить решения в базу знаний по каждому объекту метаданных.
Что мы получаем?
Ключевой результат внедрения — снижение нагрузки на отдел техподдержки за счет уменьшения числа обращений. Это обеспечивает качественный рост сервиса: специалисты смогут перераспределить ресурсы с обработки рутинных запросов на решение сложных задач и разработку инструментов для их обработки.
Параллельно достигается значительная экономия времени пользователей — ключевой показатель эффективности ИТ-сервисов.

Для внедрения решения потребуется:
-
Разработать и внедрить RAG-решение в 1С;
-
Обеспечить сервер для размещения больших языковых моделей;
-
Адаптировать часть бизнес-процессов компании под использование разработанного решения.
Для оптимизации работы требуется реорганизация процессов, которая включает внедрение нулевой линии техподдержки и детальную проработку сценариев использования (Use Case) решения. Также необходима подготовка сотрудников для работы с системой. Реализация этих изменений не требует много времени — достаточно двух недель.
Экономика
Разработка одной инструкции в среднем занимает 16 часов (интенсивный режим). Такие трудозатраты обусловлены тем, что качество ответа нейросети напрямую зависит как от качества написанных инструкций, так и от разработанного механизма поиска.
Для расчета экономической эффективности были установлены следующие временные нормативы:
-
Обработка входящего обращения (маршрутизация) — 15 минут. Это интервал между отправкой заявки пользователем и принятием ее в работу специалистом.
-
Подготовка ответа на типовой вопрос с использованием инструкций — 15 минут.

Ежедневно в техподдержку «Гринатома» поступает от 200 до 300 обращений при количестве ежедневно активных пользователей системы 10–13 тысяч человек. Для расчетов использовано среднее значение в 250 обращений в день. В разработке инструкций участвуют два технических писателя. В расчет также включены затраты на администрирование бота: 2 часа в неделю (с учетом интеграции новых инструкций в систему).
Прогнозируемые результаты внедрения:
-
За 160 дней непрерывной работы будет создано 160 новых инструкций;
-
С учетом существующей базы знаний бот сможет обрабатывать до 40 обращений ежедневно.
При постепенном внедрении инструкций ожидается, что за 133 дня будет сэкономлено достаточно времени, чтобы полностью окупить затраты на их создание, а также достигнута общая экономия в 4025 человеко-часов. Начиная с 134-го дня решение выйдет на полную проектную мощность и начнет приносить прямую финансовую экономию компании.
Вопреки распространенному мнению, искусственный интеллект не так сложен. Ключевая ошибка — воспринимать ИИ как «черный ящик». Наш опыт доказывает: внедрение искусственного интеллекта в техподдержку доступно даже небольшим командам. За два дня мы создали решение, которое способно обрабатывать до 40% обращений в техподдержку.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

