


По мотивам... Перевод документа с ietf.org:
Правило №1: Каждая запись (record) начинается с новой строки. (CRLF, #13#10, U+000D U+000A)
1. Each record is located on a separate line, delimited by a line break (CRLF). For example: aaa,bbb,ccc CRLF zzz,yyy,xxx CRLF
Правило №2: Последня запись может оканчиваться переносом строки.
2. The last record in the file may or may not have an ending line break. For example: aaa,bbb,ccc CRLF zzz,yyy,xxx
Правило №3: Опционально первая строка может являться заголовком, содержащим имена колонок.
3. There maybe an optional header line appearing as the first line of the file with the same format as normal record lines. This header will contain names corresponding to the fields in the file and should contain the same number of fields as the records in the rest of the file (the presence or absence of the header line should be indicated via the optional "header" parameter of this MIME type). For example: field_name,field_name,field_name CRLF aaa,bbb,ccc CRLF zzz,yyy,xxx CRLF
Правило №4: Поля разделены запятыми (разделителем). Заждая запись имеет одинаковое количество полей. Пробелы являются частью полей и не должны игнорироваться. После последнего поля не может быть запятой.
4. Within the header and each record, there may be one or more fields, separated by commas. Each line should contain the same number of fields throughout the file. Spaces are considered part of a field and should not be ignored. The last field in the record must not be followed by a comma. For example: aaa,bbb,ccc
Правило №5: Каждое поле может быть заключено в двойные кавычки. Если поле не заключено в двойные кавычки, то внутри уже не может находится сивол двойных кавычек. (По-умолчанию поле заключается в кавычки, если требуется экранирование, см. правило 6)
5. Each field may or may not be enclosed in double quotes (however some programs, such as Microsoft Excel, do not use double quotes at all). If fields are not enclosed with double quotes, then double quotes may not appear inside the fields. For example: "aaa","bbb","ccc" CRLF zzz,yyy,xxx
Правило №6: Поля, содержащие символ переноса строки, двойные кавычки и запятые должны быть заключены в двойные кавычки. (Поле может быть многострочным и содержать символ разделителя)
6. Fields containing line breaks (CRLF), double quotes, and commas should be enclosed in double-quotes. For example: "aaa","b CRLF bb","ccc" CRLF zzz,yyy,xxx
Правило №7: Если поле заключено в двойные кавычки, то кавычки внутри поля должны быть экранированы предшествующими кавычками.
7. If double-quotes are used to enclose fields, then a double-quote appearing inside a field must be escaped by preceding it with another double quote. For example: "aaa","b""bb","ccc"
ABNF грамматика:
file = [header CRLF] record *(CRLF record) [CRLF] header = name *(COMMA name) record = field *(COMMA field) name = field field = (escaped / non-escaped) escaped = DQUOTE *(TEXTDATA / COMMA / CR / LF / 2DQUOTE) DQUOTE non-escaped = *TEXTDATA
Примечания:
На практике под CSV часто понимают более общий формат DSV (delimiter-separated values,
значения, разделенные разделителем), который может использовать отличные от запятой
разделители. Наиболее популярные в нашей стране разделители – символ табуляции и точка
с запятой. Причем некоторые программы, как, например, Microsoft Excel, могут исполь-
зовать тот или иной разделитель в зависимости от региональных настроек (в MS Excel –
запятая в общих настройках и точка с запятой в российских).
Также в качестве разделителя используются как минимум: собака, табуляция,
вертикальная черта. Вне зависимости от использованного разделителя, остальные
рекомендации остаются неизменными.
- Имена файлов должны заканчиваться расширением .csv.
- Файлы должны иметь кодировку UTF-8.
- Файлы должны иметь одну строку заголовка. Эта строка должна быть первой строкой в файле.
- Каждый столбец в файле CSV называется полем и его имя находится в строке заголовка в том же столбце .
- Имя столбца должно быть уникальным среди полей заголовка, содержать по крайней мере один символ.
- Строки в файле не должны содержать больше полей, чем в строке заголовка (хотя они могут содержать меньше).
- Если CSV файл не следует этим правилам, то его специфический CSV диалект должен быть документирован согласно CSV Dialect Description Format.
//ПреобразоватьТЗвТекстCSV () экспортирует данные ТЗ в текст в формате CSV
//Параметры:
//ТЗ - Таблица значений данные которые сохраняются в файл
//флЭкспортироватьИменаКолонок - Первой строкой выводить имена колонок
//Разделитель - Для формата CSV разделителем является ',', но т.к.
// Excel берет разделитель из региональных стандартов, то
// используется ';'
//
&НаСервереБезКонтекста
Функция ПреобразоватьТЗвТекстCSV(ТЗ, Разделитель = ";", флЭкспортироватьИменаКолонок = Ложь) Экспорт
ТекстCSV = "";
Если флЭкспортироватьИменаКолонок Тогда
//Если нужно выгружать наименование колонок Выгружаем
ПодготовленнаяСтрока = "";
Для Каждого Колонка Из ТЗ.Колонки Цикл
ПодготовленнаяСтрока = ПодготовленнаяСтрока + Колонка.Имя + Разделитель;
КонецЦикла;
ПодготовленнаяСтрока = Лев (ПодготовленнаяСтрока,СтрДлина(ПодготовленнаяСтрока)-1);
ТекстCSV = ТекстCSV + ПодготовленнаяСтрока + Символы.ПС;
КонецЕсли;
Для Каждого Строка Из ТЗ Цикл
ПодготовленнаяСтрока = "";
Для Каждого Колонка Из ТЗ.Колонки Цикл
ПреобразованноеПоле = Строка[Колонка.Имя];
//по правилам CSV если поле содержит двойные ковычки они должны повторятся дважды
Если Найти(ПреобразованноеПоле,"""") Тогда
ПреобразованноеПоле = СтрЗаменить(ПреобразованноеПоле,"""","""""");
КонецЕсли;
//по правилам CSV если поле содержит перенос строки или запятую оно должно заключатся в двойные кавычки
Если Найти(ПреобразованноеПоле,Разделитель) ИЛИ Найти(ПреобразованноеПоле,Символы.ПС) ИЛИ Найти(ПреобразованноеПоле,"""") Тогда
ПреобразованноеПоле = """" + ПреобразованноеПоле + """";
КонецЕсли;
ПодготовленнаяСтрока = ПодготовленнаяСтрока + ПреобразованноеПоле + Разделитель;
КонецЦикла;
ПодготовленнаяСтрока = Лев (ПодготовленнаяСтрока,СтрДлина(ПодготовленнаяСтрока)-1);
ТекстCSV = ТекстCSV + ПодготовленнаяСтрока + Символы.ПС;
КонецЦикла;
Возврат ТекстCSV;
КонецФункции
казалось бы - всё, но кроличья нора оказалась намного глубже!
Процедура ПреобразоватьТЗвТекстCSV(ИмяФайла, ТЗ, Разделитель = ";", флЭкспортироватьИменаКолонок = Ложь)
//ТекстДок = Новый ТекстовыйДокумент; // вызывает проседание при конкатенации после 10 тыс. строк
ЗаписьТекста = Новый ЗаписьТекста(ИмяФайла);
Если флЭкспортироватьИменаКолонок Тогда
//Если нужно выгружать наименование колонок Выгружаем
ПодготовленнаяСтрока = "";
Для Каждого Колонка Из ТЗ.Колонки Цикл
ПодготовленнаяСтрока = ПодготовленнаяСтрока + Колонка.Заголовок + Разделитель;
КонецЦикла;
ПодготовленнаяСтрока = Лев (ПодготовленнаяСтрока,СтрДлина(ПодготовленнаяСтрока)-1);
ЗаписьТекста.ЗаписатьСтроку(ПодготовленнаяСтрока);
КонецЕсли;
Для Каждого Строка Из ТЗ Цикл
ПодготовленнаяСтрока = "";
// цикл в одну строку, т.к. "производительность 1С зависит от переноса строк"
// (не шутка, особенность стековой машины при интерпретации в байт-код)
Для Каждого Значение Из Строка Цикл ПодготовленнаяСтрока = ПодготовленнаяСтрока + """" + Значение + """"+ Разделитель; КонецЦикла;
ПодготовленнаяСтрока = Лев (ПодготовленнаяСтрока,СтрДлина(ПодготовленнаяСтрока)-1);
ЗаписьТекста.ЗаписатьСтроку(ПодготовленнаяСтрока);
КонецЦикла;
ЗаписьТекста.Закрыть();
КонецПроцедуры
метод годится для быстрой! записи _большой_ таблицы значений в файл, ведь учет кавычек и переносов в разы замедляет его... (в ответ на комментарий elinorkelt)
//ПреобразоватьТекстCSVвТЗ () импортирует данные в ТЗ из текста формата CSV
//Параметры:
//ТекстCSV - Строка, содержащая текст в формате csv
//Разделитель - Для формата CSV разделителем является ',', но т.к.
// Excel берет разделитель из региональных стандартов, то
// используется ';', поддерживает многострочные поля
//
&НаСервереБезКонтекста
Функция ПреобразоватьТекстCSVвТЗ(ТекстCSV="", Разделитель=";") Экспорт
ТЗ = Новый ТаблицаЗначений;
ОсобаяСтрока = "$#%^&*!xyxb$#%&*!^"; // для замены ""
НомерСтроки = 1;
Стр = СтрПолучитьСтроку(ТекстCSV,НомерСтроки);
Пока НомерСтроки <= СтрЧислоСтрок(ТекстCSV) Цикл
СтрокаТЗ = ТЗ.Добавить();
НомерПоля = 0;
Пока Стр <> "" Цикл
Токен = "";
ПозицияРазделителя = Найти(стр, Разделитель);
ПозицияОткрКавычек = Найти(стр, """");
//"";""
Если ПозицияОткрКавычек > 1 И Сред(стр, ПозицияОткрКавычек-1, 1) <> Разделитель Тогда
ПозицияОткрКавычек = 0;
КонецЕсли;
Если (ПозицияРазделителя > ПозицияОткрКавычек ИЛИ ПозицияРазделителя = 0) И ПозицияОткрКавычек > 0 Тогда
// начинающееся с кавычек читаем до тех пор
Токен = Сред(Стр, 1, ПозицияОткрКавычек);
Стр = СтрЗаменить(Сред(Стр, ПозицияОткрКавычек+1), """""", ОсобаяСтрока);
ПозицияЗакрКавычек = Найти(Стр, """");
Пока ПозицияЗакрКавычек = 0 Цикл
Токен = Токен + Стр + Символы.ПС;
НомерСтроки = НомерСтроки + 1;
Стр = СтрПолучитьСтроку(ТекстCSV, НомерСтроки);
Стр = СтрЗаменить(Стр, """""", ОсобаяСтрока);
// пока не встретим закрывающие
ПозицияЗакрКавычек = Найти(Стр, """");
КонецЦикла;
ПозицияРазделителя=Найти(Сред(Стр,ПозицияЗакрКавычек), Разделитель);
ПозицияРазделителя = ?(ПозицияРазделителя>0, ПозицияЗакрКавычек + ПозицияРазделителя-1, 0);
КонецЕсли;
Токен = Токен + ?(ПозицияРазделителя>0, Сред(Стр, 1, ПозицияРазделителя-1), Стр);
Стр = ?(ПозицияРазделителя>0, Сред(Стр, ПозицияРазделителя+1), "");
Если Лев(Токен, 1) = """" Тогда
Токен = Сред(Токен, 2);
Токен = ?(Прав(Токен, 1) = """", Сред(Токен, 1, СтрДлина(Токен)-1), Токен);
КонецЕсли;
Токен = ?(Токен = ОсобаяСтрока, "", Токен);
Токен = СтрЗаменить(Токен, ОсобаяСтрока, """");
НомерПоля = НомерПоля + 1;
Если ТЗ.Колонки.Количество()<НомерПоля Тогда
ТЗ.Колонки.Добавить("Колонка"+НомерПоля, Новый ОписаниеТипов("Строка"));
КонецЕсли;
СтрокаТЗ[НомерПоля-1] = Токен;
КонецЦикла;
НомерСтроки = НомерСтроки + 1;
Стр = СтрПолучитьСтроку(ТекстCSV, НомерСтроки);
КонецЦикла;
Возврат ТЗ;
КонецФункции
ps: данный автомат по разбору abnf грамматики считаю неудачным, так как он непредсказуемо ломается при неправильных входных данных
// Функция возвращает ТабличныйДокумент с данными файла.
//
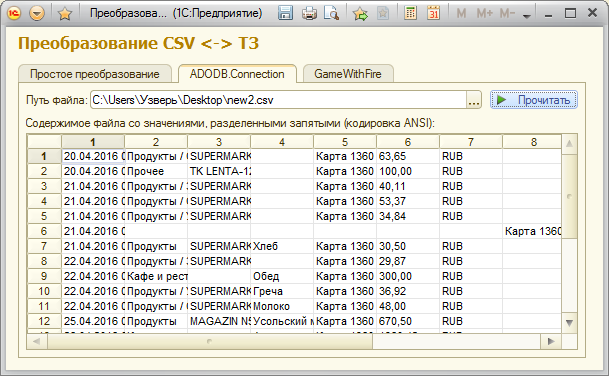
Функция ПрочитатьCSV_ADO(ИмяФайла, Разделитель=",")
ТабДок = Новый ТабличныйДокумент;
Файл = Новый Файл(ИмяФайла);
Connection=Новый COMОбъект("ADODB.Connection");
Connection.Open("Provider=Microsoft.Jet.OLEDB.4.0;Data Source="+Файл.Путь+";Extended Properties=""text;HDR=No;IMEX=1;FMT=Delimited""");
RecordSet=Новый COMОбъект("ADODB.Recordset");
RecordSet.ActiveConnection = Connection;
RecordSet.Open("select * from "+Файл.Имя, Connection);
сч=0;
Пока НЕ RecordSet.EOF() Цикл
сч=сч+1;
Для й=0 по RecordSet.Fields.Count-1 Цикл
ТабДок.Область(сч, й+1).Текст = RecordSet.Fields(й).Value;
КонецЦикла;
Если сч%1000=0 Тогда // ~ 1000 в секунду
Состояние(""+сч+" ...");
ОбработкаПрерыванияПользователя();
КонецЕсли;
RecordSet.MoveNext();
КонецЦикла;
RecordSet.Close();
Connection.Close();
Возврат ТабДок;
КонецФункции
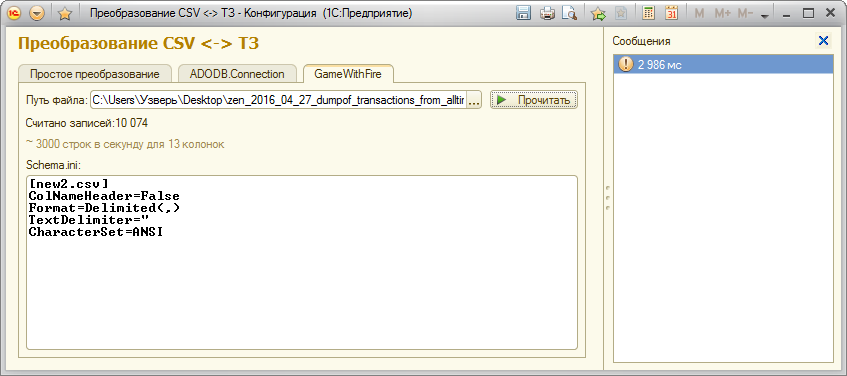
Для больших файлов можно использовать Microsoft.Jet.OLEDB. Понимает даты, числа и многострочные поля. Скорость: ~3000 строк в секунду. На msdn можно найти описание грамматики и Schema.ini. Пример использования здесь //infostart.ru/public/98398/
данный способ считаю наиболее приемлемым при разборе больших файлов, т.к. встреча с неправильными данными не ломает чтение последующих строк
// Функция возвращает ТаблицуЗначений с данными файла.
//
// Источник: http://forum.script-coding.com/viewtopic.php?id=5664
//
Функция ПрочитатьCSV_GWF(ИмяФайла)
Файл = Новый Файл(ИмяФайла);
// Schema.ini уже должен быть подготовлен
objRec = Новый COMОбъект("ADODB.Recordset");
strQuery = "SELECT * FROM [" + Файл.Имя + "]";
strConn = "Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + Файл.Путь + ";Extended Properties=""text;HDR=No""";
adOpenStatic = 3;
adLockOptimistic = 3;
adCmdText = 1;
objRec.Open(strQuery, strConn, adOpenStatic, adLockOptimistic, adCmdText);
Если ПодключитьВнешнююКомпоненту("GameWithFire.ADOUtils") Тогда
ADOUtils = Новый("AddIn.ADOUtils");
Возврат ADOUtils.ADORecordsetToValueTable(objRec); // ~ 3000 в сек
Иначе
Сообщить("Не удалось подключить компоненту GameWithFire");
Возврат Новый ТаблицаЗначений;
КонецЕсли;
КонецФункции
ps: поводом для написания этой статьи стал безуспешный поиск функции чтения csv средствами платформы, поддерживающей экранированные поля с символами переноса строки
Ссылки:
1. IETF. RFC 4180. Common Format and MIME Type for CSV Files
2. W3C. See sparql11-results-csv-tsv, the first W3C recommendation scoped in CSV and filling some of RFC4180's lacks
3. RFC 4180, спецификация (рус.)
4. JSON Data Specifications. CSV Dialect Description Format (CSVDDF)
upd: для чтения больших файлов данный код совершенно не годится, лучше использовать adodb или gamewithfire,
вот сравнение времени выполнения методов для файла из 10000 строк, на слабом процессоре:
- Native - 28 578 мс
- ADODB - 8 336 мс
- GWF - 7 236 мс
- Native regexp - 14 078 мс
upd2: Чтение csv файлов - чтение с использованием регулярок, которое быстрее в 2 раза чем вариант Native
Исходный код: github: https://github.com/kuzyara/ConvertCSV
Проверено на следующих конфигурациях и релизах:
- Управление торговлей, редакция 11, релизы 11.5.18.41
Вступайте в нашу телеграмм-группу Инфостарт


{kind=link}