Программисты при произнесении слов "граф" или "дерево" , не задумываясь продолжают : "Понятно.. это рекурсия !" . Не вдаваясь в дискуссию о том , почему рекурсия в БД есть синоним неэффективности, мы на простом примере рассмотрим решение задачи "разузлования" номенклатуры принципиально "нерекурсивным" методом. Выберем эпиграф для статьи :
"Запрос в БД - это сила. Рекурсия - это зло ."
§ 1. Где и зачем это нужно ?
На предприятиях ,осуществляющих сборку сложных изделий (летательных аппаратов, электровозов, судов), состоящих из тысяч и десятков тысяч комплектующих, актуальна задача ведения спецификаций изделий.В статье мы рассмотрим одну из частей этой задачи - "разузлование" номенклатуры : по спецификации изделия определить состав и количество "элементарных", входящих в него составляющих. Все известные способы решения такой задачи - "медленные"и время выполнения может доходить в реальных задачах до нескольких минут.
Какой же из "медленных" способов - самый быстрый, надежный , эффективный ?
Достаточно ли встроенных возможностей платформы 1с для решения таких задач ?
§ 2. Постановка задачи.
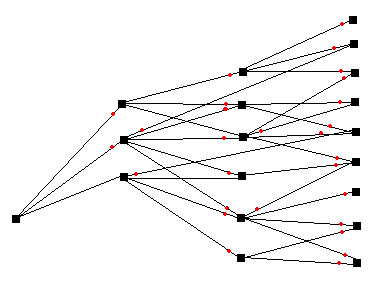
На нижеприведенном рисунке изображено два способа отображения графа "Спецификации" :
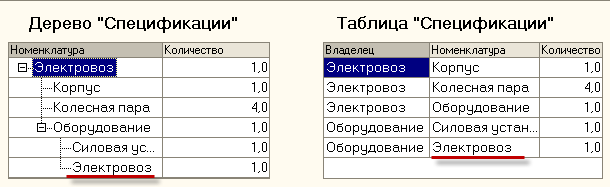
Рис. 1. Два способа отображения графа.
В базе данных (БД) такой граф хранится в табличной форме , поэтому в дальнейшем мы будем рассматривать таблицу "Спецификации" в качестве исходных данных. Итак , сформулируем задачу разузлования "узко" для изображенного примера : для номенклатуры "Электровоз" найти все составляющие его номенклатуры , неимеющие подчиненных ("детей") с расчетом необходимого количества .Т.е. в качестве решения мы должны получить таблицу :

Рис. 2. Выходная таблица.
§ 3. Решение.
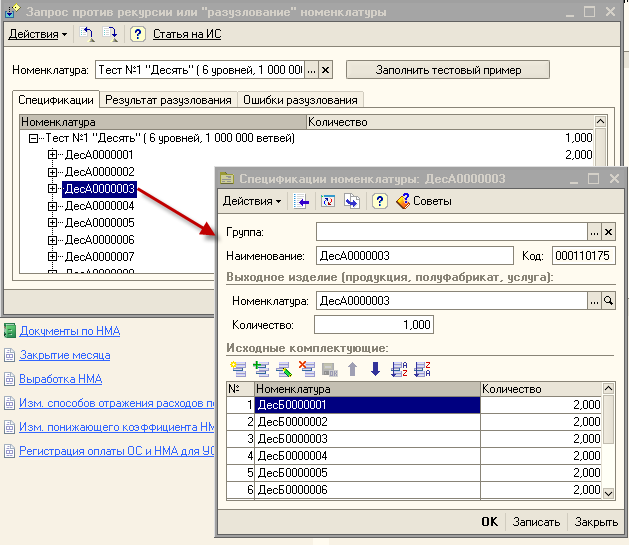
Преобразуем заданную в условии задачи таблицу "Спецификации", добавив колонку
"КодНоменклатуры" :

Рис. 4. Таблица "Спецификации".
Создадим временную таблицу "ВремТаблица0" с единственной записью ,содержащей
номенклатуру "Электровоз" :
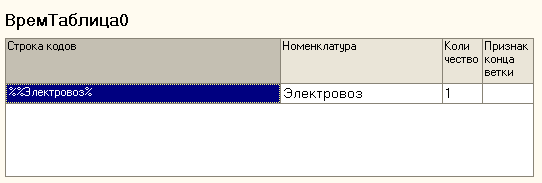
Рис. 5. Начальная таблица ВремТаблица0.
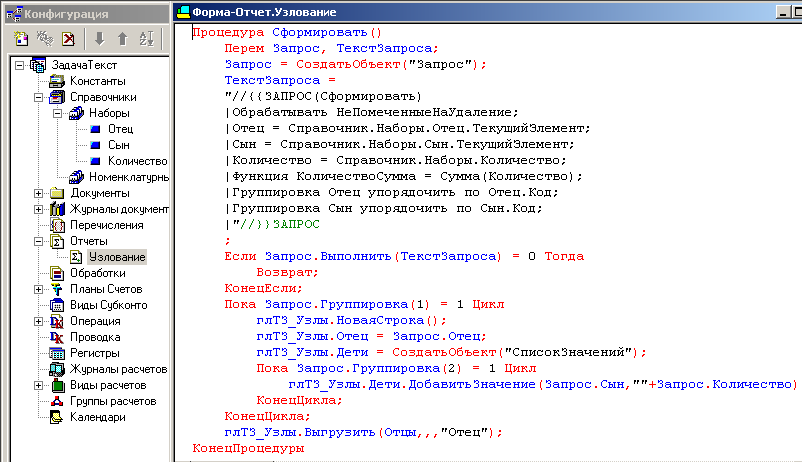
Начальные данные заданы. Рассмотрим код обработки :
ТекстЗапроса = "ВЫБРАТЬ
| ЕСТЬNULL(Спец.Номенклатура, Исх.Номенклатура) КАК Номенклатура,
| Исх.Количество * ЕСТЬNULL(Спец.Количество, 1) КАК Количество,
| Исх.СтрокаКодов + ЕСТЬNULL(Спец.КодНоменклатуры, """") КАК СтрокаКодов,
| ВЫБОР
| КОГДА Исх.ПризнакКонцаВетки > 0
| ТОГДА Исх.ПризнакКонцаВетки
| КОГДА Спец.КодНоменклатуры ЕСТЬ NULL
| ТОГДА 1 // нормальное завершение ветки
| КОГДА Исх.СтрокаКодов ПОДОБНО Спец.КодНоменклатуры
| ТОГДА 2 // зацикливание
| ИНАЧЕ 0 // ветка продолжается
| КОНЕЦ КАК ПризнакКонцаВетки
|ПОМЕСТИТЬ Последующая
|ИЗ
| Исходная КАК Исх
| ЛЕВОЕ СОЕДИНЕНИЕ Спецификация КАК Спец
| ПО (Исх.ПризнакКонцаВетки = 0) // соединяемся только тогда, когда ветка продолжается
| И Исх.Номенклатура = Спец.Владелец
|;
|УНИЧТОЖИТЬ Исходная
|;
|ВЫБРАТЬ ПЕРВЫЕ 1 Посл.Номенклатура
|ИЗ Последующая КАК Посл
|ГДЕ Посл.ПризнакКонцаВетки = 0";
//Цикл получения выходной таблицы
Для Счетчик =0 по КоличествоЦиклов+1 Цикл
Запрос.Текст = СтрЗаменить(ТекстЗапроса,"Исходная","ВремТаблица"+ Счетчик);
Запрос.Текст = СтрЗаменить(Запрос.Текст,"Последующая","ВремТаблица"+(Счетчик+1));
РезультатЗапроса = Запрос.Выполнить();
Если РезультатЗапроса.Пустой() Тогда
Счетчик = Счетчик + 1 ;
Прервать;
КонецЕсли;
КонецЦикла;
На рис. 5-8 расмотрены промежуточные временные таблицы алгоритма во всех циклах решения.
Рис. 5 Таблица ВремТаблица0.
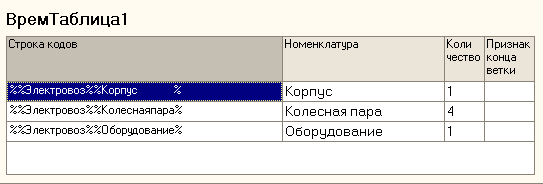
Рис. 6. Вид таблицы после исполнения первого цикла ( перед началом второго).
В колонке ""СтрокаКодов" накапливаются все коды номенклатуры текущей ветки.
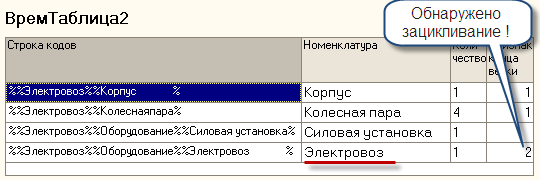
Рис. 7. Вид таблицы после исполнения второго цикла . Обратите внимание ,
обнаружено зацикливание , но работа "по графу" продолжается. Следующий цикл
- третий.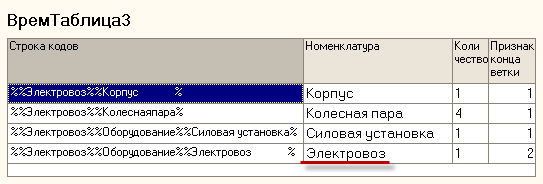
Рис. 8. Вид таблицы после исполнения третьего цикла. Все записи таблицы имеют
ненулевой ПризнакКонцаВетки - осуществляется выход из цикла.
ВремТаблица3 содержит все необходимые данные для вывода результатов решения :
- графа ошибок ( по колонке "СтрокаКодов" для номенклатуры "Электровоз" получаем дерево "Ошибки")
- выходной плоской таблицы номенклатур
Замечания.
- применен последовательный поуровневый обход графа , т.е . принципиально "нерекурсивный" метод решения.
- количество обращений к БД при таком обходе равно уровню графа , увеличенному на 1.
- 99.9% времени исполнения алгоритма занимает выполнения запросов к БД .
§ 4. Тест по быстродействию.
Чтобы оценка быстродействия была предельно конкретной , в качестве среды выберем - демонстрационную конфигурация БП 1.6(2.0) и представим два лёгких теста начального заполнения справочника "СпецификацииНоменклатуры", реализованных в обработке "ЗапросПротиврекурсии.epf". Нижеприведенные тесты-"миллионники", надеюсь, с лихвой перекрывают все возможные случаи медленного "разузлования" в реальных задачах. Действительно , практически невозможно представить себе предприятия , на которых бы справочник Номенклатура имел размер более 300 000 записей и уровень графа, описывающего Спецификацию сложного изделия, превышал бы число 20.
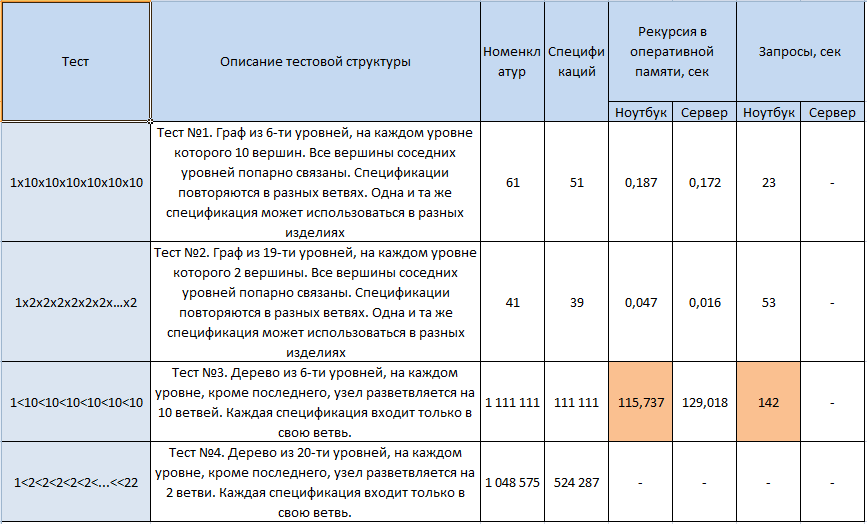
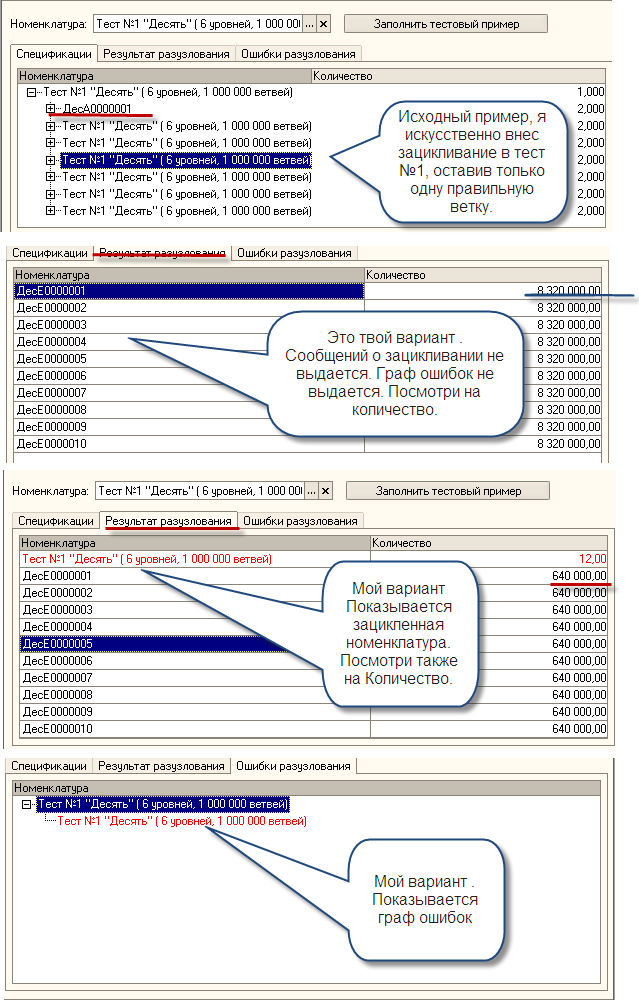
Тест № 1. "Десять"
Справочник "СпецификацииНоменклатуры" содержит 6-уровневый 10-арный граф , имеющий 1 000 000 различных ветвей и при обходе такого графа таблица ВремТаблица6 на выходе цикла алгоритма содержит 1 000 000 записей. Но сам справочник "СпецификацииНоменклатуры" в своей табличной части содержит лишь 60 записей.
Проще говоря , корневому элементу подчинены 10 элементов, каждому из которых подчинен одинаковый набор из десятка следующих элементов и т.д.
Тест № 2. "Два"
Справочник "СпецификацииНоменклатуры" содержит 20-уровневый бинарный граф , имеющий 1 048 576 различных ветвей и при обходе такого графа таблица ВремТаблица20 содержит 1 048 576 записей. Но сам справочник "СпецификацииНоменклатуры" в своей табличной части содержит лишь 40 записей.
Рис. 9. Быстрое (4-6 сек) создание тестового примера в обработке "ЗапросПротивРекурсии.epf"
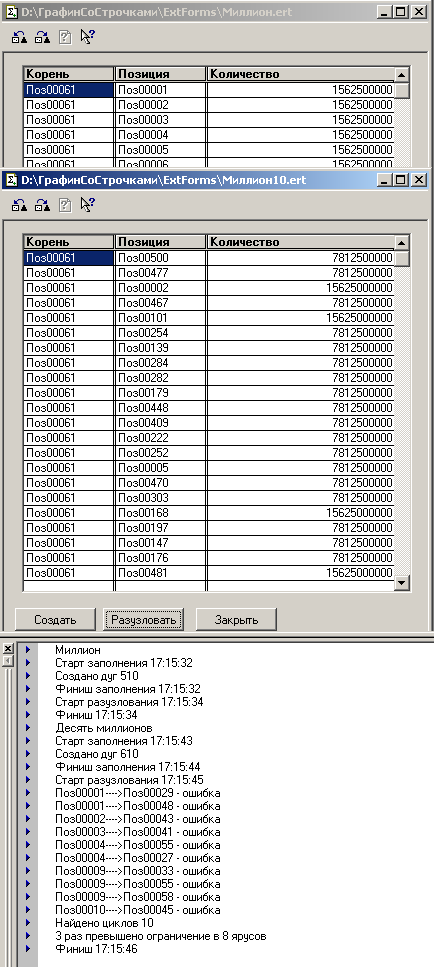
Небольшой объём исходных данных в тестах №1 и №2 порождает иллюзию : сейчас загрузим всё в таблицу значений и в оперативной памяти всё "быстренько" порешаем с помощью рекурсии. Прозрение к любителю рекурсии приходит после замера времени выполнения. Автор провёл опрос среди знакомых специалистов и для Теста №1 получил следующую информацию (приводится обобщенно , со слов авторов) : Разузлование номенклатуры для Теста № 1 140-220 сек в файловом варианте. Понимая всю условность приведенной информации , автор самостоятельно реализовал простейшую имитацию рекурсионного алгоритма :
Рис. 10. Имитация рекурсионного алгортима. Количество циклов 1 111 111 равно количеству узлов в графе
теста №1.
В этой имитации "ничего нет". В ней заведомо многократно меньше операторов , таблица значений пуста, затратный контроль зацикливания не осуществляется и т.д. Время выполнения этой имитации лишь на 15%-20% меньше времени выполнения обработки "ЗапросПротивРекурсии.epf" в тесте №1 . Стал очевиден качественный вывод : рекурсионный алгоритм проигрывает и проигрывает много.
Приведем результаты тестирования для обработки "ЗапросПротивРекурсии.epf". Замеры производились для "теплого"(второго) запуска обработки как в клиент -серверном, так и в файловом варианте. Нижние пределы диапазонов приведены как оценки значений, полученных на компьютере автора. Про верхние пределы диапазонов : скажем так , автору не удалось найти такие серверы и такие рабочие станции для файлового режима , на которых бы время выполнения было хуже. Итак , оценки (подчеркиваю , оценки) для "среднеофисных" серверов и локальных станций с оперативной памятью 1Гб.
Тест № 1 "Десять"
|
Для файлового варианта |
25-60 сек |
| Для клиент- серверного варианта | 25-60 сек |
Тест № 2 "Два"
|
Для файлового варианта |
60-150 сек |
| Для клиент- серверного варианта | 120- 300 сек |
Рис.11. Результаты тестирования.
§ 5. Для любопытных.
В статье ни слова не сказано о сравнении по быстродействию с другими не-1совскими реализациями решения тестов №1и №2. А вдруг всё дело только в том , что 1с-овский интерпретатор неэффективен ? Может быть , если реализовать задачу на Си или Delfi, то удастся достичь лучшего быстродействия, чем указано в теме ? Или , может быть , использовать "чисто" TSQL ? Прогноз автора : НЕТ. НЕ ПОМОЖЕТ. Такая Рекурсия всё равно проиграет запросу 1с. Но буду рад ,если появятся публикации на эту тему с другими мнениями.
Прошу только помнить, что в статье идет речь не о "заточке" для тестов №1 и № 2, а об универсальной обработке произвольного графа ( в общем случае, циклического), которая " в среднем" оптимальна, на взгляд автора, для решения задачи "разузлования" на предприятии. Это значит , что таблица Спецификации может иметь миллионы записей и это существенно не скажется на быстродействии представленной обработки (в клиент-серверном варианте). Это значит также , что алгоритм различные графы и деревья , содержащиеся в таблице Спецификации, обрабатывает одинаково и априорно (на входе) не имеет никакой "подсказывающей "информации о характере графа .
Второй вопрос , который никак не затронут в статье : как нам не попасть на "миллиард" ? как оптимизировать работу с повторениями элементов при "разузловании" ? Можно заметить ,в частности, что при отсутствии контроля зацикленности можно было вставить в демонстрационный запрос "СГРУППИРОВАТЬ ПО " и тогда время выполнения по тесту № 1 было бы меньше 2 сек. Подход же с контролем зацикленности сложнее, и, думаю, мало востребован в практических задачах учета. "Миллиард" оставим без рассмотрения. В обработке "ЗапросПротивРекурсии.epf" лишь применено ограничение на размер промежуточных временных таблиц.
§ 6. Заключение
Автор убежден , что встроенных возможностей платформы 1с без использования рекурсии вполне достаточно для создания надежного и эффективного механизма "разузлования".
Главное же преимущество, на взгляд автора, представленной демонстрационной обработки не в том , что она выиграет по скорости выполнения у какой-то другой "рекурсионной обработки", а в том , что она более технологична и надежна - вся тяжесть вычислений (99.9%) ложится на сервер БД и мы "отвязываемся" от слабости клиента.
Статья была уже написана , когда я на ИС получил информацию и поверхностно познакомился с подходами к задаче "разузлования" , применяемыми в реальных, "вполне взрослых" проектах . Подходы эти несколько смутили. Но не отменили главного вывода статьи : применение рекурсии в задачах "разузлования" ( в постановке см.§2) избыточно.
§ 7. Благодарности
Автор приносит благодарности всем участникам дискуссии , предшествующей появлению данной статьи :
Hogik ,Tango , Wkbapka , Арчибальд , Ildarovich, ILM. Эти авторы разными способами и с разной силой толкали к пониманию новой для меня задачи "разузлования".Спасибо.
Вступайте в нашу телеграмм-группу Инфостарт