Разрабатывая системы автоматизации учета, любой 1С-разработчик периодически сталкивается с проблемами производительности. Используя отладчик 1С, можно легко найти запрос, который выполняется недостаточно быстро. Но почему запрос медленный, разобраться с помощью отладчика мы не сможем. Чтобы ответить на этот вопрос, нужно понять, что происходит с запросом на уровне базы данных.
Что такое план запроса?
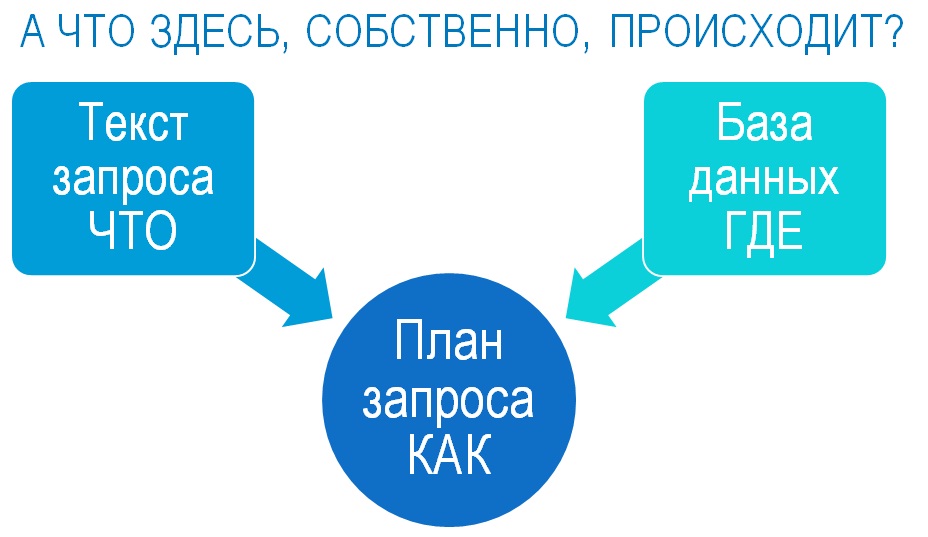
Итак, начнем. Что здесь происходит?
- Когда мы пишем запросы в среде 1С на SQL-подобном языке, мы используем декларативный подход к написанию: в тексте запроса мы не указываем способ получения данных, а просто говорим, какие данные хотим извлечь, что хотим получить.
- Структура базы данных определяет, где эта информация находится.
- А план запроса отвечает на вопрос «Как извлечь информацию из базы данных таким образом, чтобы набор данных соответствовал исходному тексту запроса».

Для лучшего понимания и запоминания попробуем провести аналогию, между строительством дома и формированием плана запроса. Понятно, что любая аналогия ложна, но это все же лучше, чем ничего.
Все начинается с того, что мы пишем текст запроса, который определяет, что должно быть получено на выходе. Дальше анализатор запроса раскладывает этот текст на логические единицы, чтобы получить результат.

- Дальше оптимизатор запроса ищет, не делал ли он недавно похожий запрос, возможно, аналогичный способ извлечения данных уже есть в кэше (в специальной области данных, где сохраняются планы выполнения запросов для того, чтобы не строить его каждый раз). Поэтому он просто идет в кэш и смотрит, нет ли там “типового проекта”.
Выполнение запроса можно условно разделить на два этапа:
- построение плана;
- выполнение запроса согласно плану.
Зачастую построение плана занимает больше времени, чем само выполнение, потому что этот процесс – достаточно сложный и ресурсоемкий.

Дальше планировщик запросов принимает решение, как будет происходить выполнение запроса:
- какими именно физическими операторами будут извлекаться данные из таблиц, и соединяться друг с другом;
- в каком порядке будет происходить выполнение этих операторов – сначала данные будут отфильтрованы, а потом отсортированы или сначала отсортированы, а потом отфильтрованы.

У каждого оператора есть своя стоимость в неких условных единицах процессорного времени, обращений к системе ввода-вывода и объема используемой памяти. Зная стоимость операторов, мы можем получить стоимость всего плана, просто сложив стоимость всех операторов.
Обычно оптимизатор строит несколько возможных планов выполнения запроса, т.е. каким именно образом можно извлекать данные и в каком порядке их можно обрабатывать. Он оценивает стоимость каждого плана и выбирает самый “дешевый”.
Так получается в большинстве случаев, но не всегда, потому что процесс построения плана и оценки его стоимости тоже требует ресурсов, а время на выполнение запроса не бесконечно, потому что время на поиск лучшего плана в итоге может превысить время исполнения запроса. Поэтому оптимизатор ограничивает время которое затрачивается на построение плана запроса. Если он успевает выбрать хороший план – значит все неплохо, но может и не успеть. Если оптимизатор не успел, то он выбирает первый (любой) попавшийся план, – какой успел построить, тот и будет. Дальше я покажу, как понять, хороший план выбран или просто первый попавшийся.

После этого происходит выполнение запроса – формируется набор данных.

И результат выполнения запроса возвращается инициатору вызова.
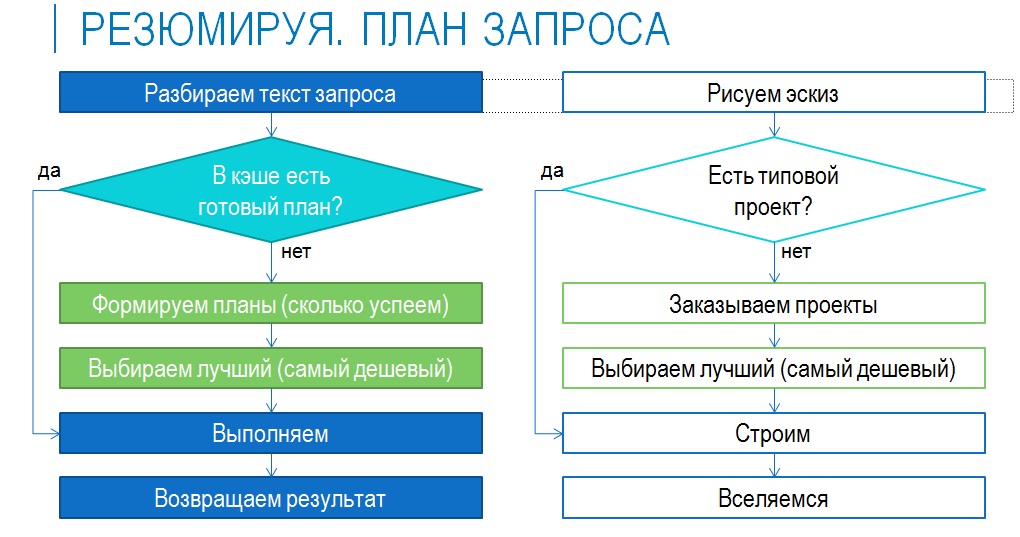
Теперь коротко еще раз то же самое по схеме:
- анализ текста запроса, его разбиение на элементы;
- поиск в кэше готового плана;
- если в кэше есть подходящий план – выполнение запроса по этому плану и возврат результата;
- если плана нет – его формирование, попытка выбрать наилучший, выполнение запроса, возврат результата.
На схеме можно увидеть аналогию со строительством.
Структура плана запроса
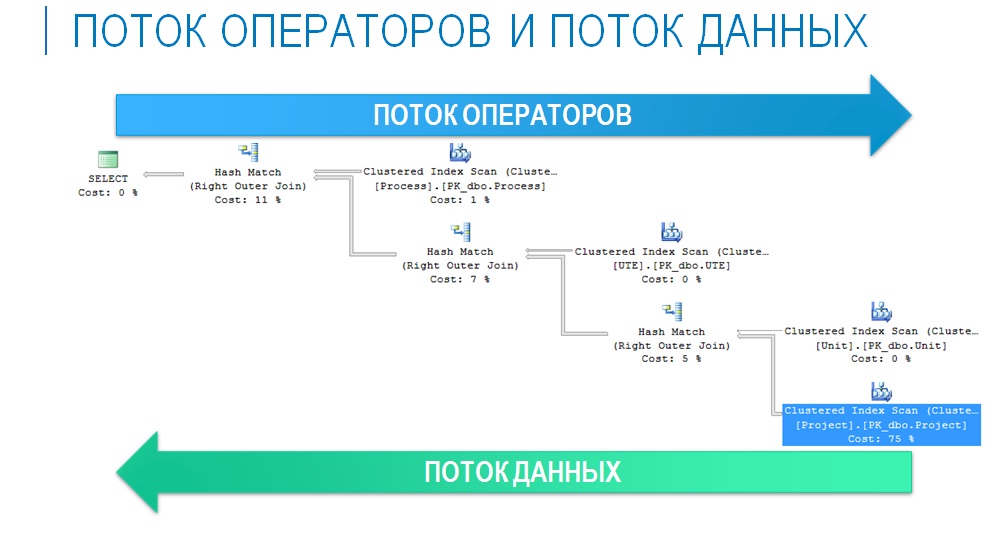
Давайте теперь рассмотрим подробнее, что представляет собой план запроса, из каких операторов он состоит.
Графически план запроса в SQL-сервере может выглядеть примерно так, как показано на слайде:
- здесь каждая иконка – это некий оператор.
- все операторы соединены между собой стрелками, которые показывают поток данных.
Есть два потока – поток операторов и поток данных. Поток операторов идет слева направо, поток данных идет справа налево.
С потоком данных все понятно:
- сначала мы должны извлечь данные из каких-то физических объектов, таблиц, индексов, представлений;
- далее мы должны обработать эти данные – соединить их между собой, выполнить сортировку, наложить отборы;
- и в конце вернуть результат.
Поток операторов идет в обратную сторону:
- начинается все с первого оператора (в данном случае это SELECT), который запрашивает данные у других операторов (в данном случае, у оператора соединения);
- оператору соединения на вход должны прийти два набора данных, которые он будет соединять – он запрашивает эти данные у следующих операторов;
- Таким образом, каждый оператор последовательно запрашивает данные у своих входов, они по очереди выполняются, и результат запроса возвращается инициатору.
Как это проверить, как в этом убедиться? Пишем запрос, в котором присутствует фраза «ВЫБРАТЬ ПЕРВЫЕ столько-то», проверяем. Этот запрос выполняется существенно быстрее, чем тот, который возвращает весь поток данных, потому что мы изначально ограничили размер выборки по количеству. Не так, что мы все данные сразу вытащили и отдали их следующему оператору – что хочешь, то и делай.
Мы сейчас говорим преимущественно про планы по выборке данных, потому что запросы, связанные с обновлением данных в контексте 1С, нам недоступны, их делает сама платформа, мы ничего с ними сделать не можем. Но на выборку (оператор SELECT) мы можем повлиять.
Основные операторы
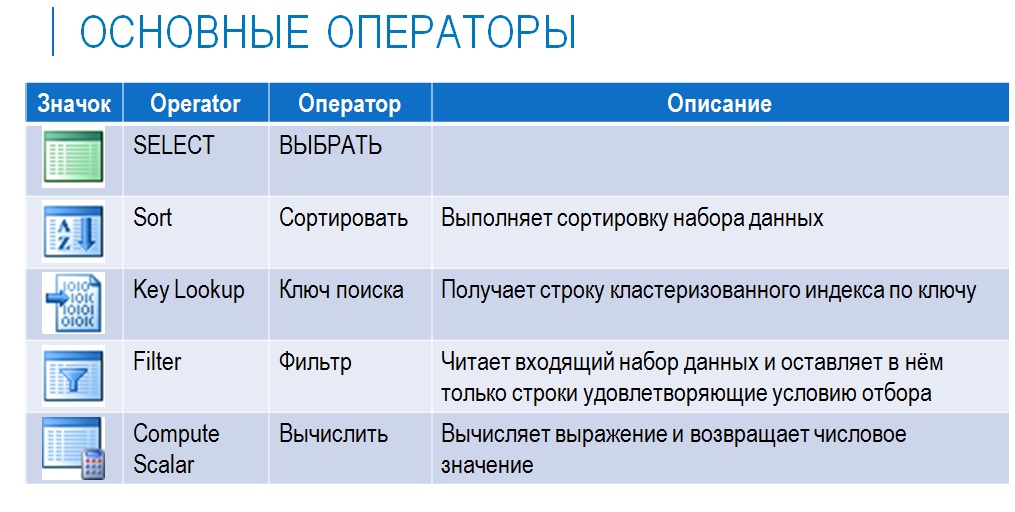
Здесь указаны основные операторы, которые чаще всего присутствуют в плане запроса. У каждого из них есть своя иконка в SQL Server Management Studio – она позволяет понять, о чем идет речь, что оператор делает. В зависимости от локализации оператор может иметь русское или английское наименование.
Самих операторов SQL намного больше, но в контексте 1С встречаются далеко не все.
Свойства оператора

Если схема плана запроса дает логическое представление о том, какие операторы и в каком порядке располагаются, то, наведя на каждого из них мышкой, можно получить более подробную информацию о том, что этот оператор собой представляет – появится окошко с его палитрой свойств (некая расширенная информация).
У разных операторов набор свойств будет немного отличаться. На слайде показаны свойства оператора Clustered Index Scan – это сканирование, (просмотр) кластеризованного индекса.
Что есть в данном случае?
- Physical Operation (физическая операция) и Logical Operation (логическая операция) чаще всего совпадают – это суть оператора, то, что он делает. В данном случае он просматривает кластеризованный индекс.
- Есть несколько свойств с указанием Estimated Cost – это то, из чего складывается цена самого оператора, та самая стоимость оператора, т.е. оценка количества вычислительных ресурсов, которые требуются на выполнение оператора. Стоимость может быть Estimated (ожидаемая), как в данном случае – это значит, что реально мы запрос не выполняли, а только строили для него план. Эта ожидаемая стоимость определяется на основе статистики. Кроме нее может быть еще Actual Cost – актуальная стоимость, она тоже определяется оценочным образом.
- Estimated Number of Rows – это количество строк, которые будут возвращены в результате, т.е. какой объем данных будет этим оператором возвращен;
- Estimated CPU Cost – это вычислительные затраты;
- Estimated I/O Cost – это затраты по памяти;
- Estimated Row Size – ожидаемый размер строки.
- Ordered – признак того, отсортирован или нет набор данных, полученный на выходе от этого оператора. Для некоторых операций требуется сортировка. Если набор данных уже отсортирован, то ничего дополнительно сортировать не надо. Например, он будет отсортирован, если идет получение данных из индекса, а не из таблицы, либо если на одном из предыдущих этапов сортировка уже была сделана.
- Если это оператор чтения данных, то у него есть Predicate – условие отбора, по которому читаются данные. Здесь идет обращение к конкретному полю таблицы и указывается фильтр по его конкретному значению.
- Object – это указание объекта, из которого производится чтение.
- А также здесь указывается Output List – список полей из этого объекта, которые будут возвращены.
Операции плана запроса
Что дальше? У нас есть две логические операции, которые имеют несколько физических. Это операции чтения данных и соединения таблиц.
Их нужно рассмотреть подробнее, потому что они оказывают существенное влияние на производительность.
Операторы доступа к данным
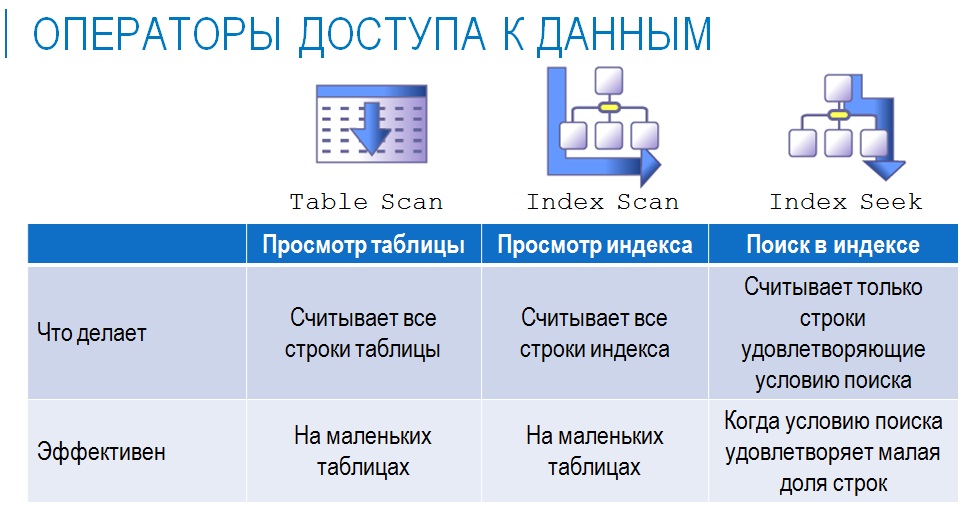
В контексте 1С в основном используются три физических операции доступа к данным:
- Table Scan – чтение данных напрямую из физической таблицы;
- Index Scan – чтение данных из физического индекса;
- Index Seek – поиск в индексе.
Если говорить в целом про производительность и про скорость, то:
- Index Seek – это хорошо, это быстро. Это значит, что у нас есть индекс и мы извлекаем не всю информацию, а только ту, которая удовлетворяет условиям отбора.
- Index Scan – это чуть похуже, но тоже неплохо. У нас есть индекс, но мы не можем из него сразу вытащить нужную информацию, нам нужно его просмотреть. Но поскольку индекс изначально отсортирован, процесс просмотра получается быстрый.
- Table Scan – это самое плохое, потому что нам нужно просмотреть всю таблицу. Но в некоторых случаях ничего другого не остается.
Я не говорю о том, что нужно всегда добиваться наличия Index Seek. Просто нужно понимать, что происходит, потому что если у нас, например, есть индекс, и мы думаем, что он используется, а, открыв план запросов, видим там Table Scan – мы ошиблись, индекс не используется. Почему он не используется – это повод для дальнейшего разбирательства.
Очень просто понять, используется индекс или нет – если в плане запроса мы видим Table Scan, значит, индекс не используется.
Операторы соединения
Соединения таблиц – это одна из самых ресурсоемких операций. На реальных проектах пользователи в отчетах 1С любят выводить «простыню», где «все по всем и все сразу». В этих случаях крайне редко источником данных является одна таблица – обычно этих таблиц несколько. Даже если явные соединения в запросе не используются, то, когда мы в 1С через точку обращаемся к реквизитам объекта, неявно все равно производится соединение с таблицей этого объекта. Таким образом, почти всегда есть несколько таблиц, которые должны быть определенным образом соединены.
Операция соединения может быть реализована тремя различными операторами.

Первый способ соединения – это Nested Loops (или вложенные циклы). Оператор самый простой, самый надежный, работает всегда и везде, но не слишком быстро.

Если бы мы этот оператор написали на 1С, он мог бы выглядеть примерно так, как показано на слайде. Он очень простой, самый универсальный, но при этом и самый медленный (среди операторов соединения таблиц).

Преимущество Nested Loops в том, что:
- он работает всегда, на любых данных, на любых условиях соединения;
- когда у нас маленькие наборы данных, он работает быстро, потому что проходов циклов не так много;
- он работает очень быстро, если нужно получить первые несколько строчек, потому что нам никаких дополнительных действий не нужно.
Его минус в том, что, если наборы данных большие, количество проходов цикла тоже большое, и тогда он работает медленно.

Второй способ – это Hash Match (соединение хэшированием). Способ более сложный, поэтому рассмотрим его чуть подробнее.
Для начала разберемся, что такое хэш-функция. Есть класс математических функций, которые на основе произвольного набора данных позволяют получить «слепок», сформированный по определенным правилам.
На слайде можно увидеть, к какому виду преобразовывается строка текста хэш-функцией md5.
Обратите внимание, что первые две исходные строки текста отличаются одним единственным символом. При этом хэш-функция отличается кардинально. Это особенность самих хэш-функций.

Соединение хэшированием особенно эффективно при соединении по нескольким условиям (когда в условии соединения используется не одно поле, а несколько). Тогда к комбинации из полей, входящих в условие, можно применить хэш-функцию и получить табличку с их хэш-кодами.
При соединении двух таблиц оптимизатор выбирает меньшую из них и выгружает ее поля, входящие в условие соединения, в хэш-таблицу. А потом с этой хэш-таблицей соединяет оставшуюся большую таблицу, т.е. производит небольшую предварительную обработку исходных данных, что позволяет несколько ускорить процесс.

На языке 1С это могло бы выглядеть примерно так, как на слайде.
Выбираем таблицу, для которой будет строиться хэш, строим эту хэш-таблицу и соединяем со второй. Поскольку хэш-таблица построена определенным образом, мы по ней уже не пробегаем, как во вложенных циклах, а сразу позиционируемся на нужной записи.

Преимущества и недостатки соединения хэшированием вы можете увидеть на слайде.

Третий способ – это Merge Join (соединение слиянием). Он самый быстрый с точки зрения выполнения, но применить его можно не всегда (если бы было по другому, то остальные способы были бы не нужны. Ведь зачем все остальные, если они более медленные).
В чем основное ограничение этого способа? В том, что он работает только тогда, когда на условиях соединения есть хотя бы одно равенство, при том, что исходные наборы данных должны быть отсортированы.

Алгоритм мог бы выглядеть примерно так, как показано на слайде.

Его существенный плюс в том, что у нас всего один проход по циклу – мы каждый из наборов данных считываем всего один раз.
А минус его в том, что его можно использовать только при определенных условиях.

Итак, что мы имеем?
У нас нет хорошего или плохого способа соединения.
Способ соединения выбирается оптимизатором исходя из того, что и как нужно соединить.
Если к нам пришел уже отсортированный набор данных, оптимизатор будет использовать слияние. Или бывает ситуация, когда пришел неотсортированный набор, но оптимизатор может решить, что затраты на сортировку “отобьются” и отсортировать его отдельной командой Sort, а потом сделать соединение слиянием. В итоге это может получиться дешевле, чем вложенный цикл. А может и не получиться.
Есть важное замечание – на уровне 1С у нас отсутствует возможность выбирать, какой способ соединения таблиц использовать. На уровне SQL мы можем увидеть в плане запроса, какой способ был использован. При написании текста запроса на языке T-SQL можно (в некоторых случаях) явно указать, какой способ соединения использовать, а можно дать “хинт” (рекомендацию) планировщику, какой именно способ соединения ему использовать. Но на уровне 1С у нас такой возможности нет.
Однако если мы видим, что для соединения был выбран неоптимальный способ, мы можем понять, что у оптимизатора были неверные данные, когда он его выбирал. Следовательно, мы можем сделать вывод о том, что у нас не актуальная статистика, пересчитать ее и таким образом решить проблему.
Как работает оптимизатор. При чем здесь статистика

Теперь несколько слов по поводу статистики – что это такое и зачем она нужна.
Когда оптимизатор выбирает способ выборки данных и соединения таблиц, он должен на чем-то основываться. Считывать для этого каждый раз все данные из таблицы – не самый оптимальный способ, поэтому используются вспомогательные механизмы, которые называются “статистика”.
С точки зрения 1С здесь ничего делать не нужно, сервер базы данных сам собирает и обновляет статистику. Чтобы он этого не делал, статистику нужно специально отключить на уровне базы.
Иногда на уровне 1С происходят события, которые приводят к существенному изменению данных. После этого желательно давать серверу базы данных принудительную команду на обновление статистики.
Например, когда у нас в документах отложенное проведение – сначала в регистрах были одни данные, мы запустили допроведение, и за короткий период времени таблицы регистров очень сильно изменились.
После всех тяжелых операций, особенно связанных с регламентами закрытия месяца, с допроведением, с перепроведением, нужно всегда принудительно запускать актуализацию статистики.
В обычном режиме, когда идет ввод документов или справочников, не бывает каких-то массовых серьезных изменений. Но если мы делаем групповую обработку документов с заменой значений – крайне желательно запускать обновление статистики.
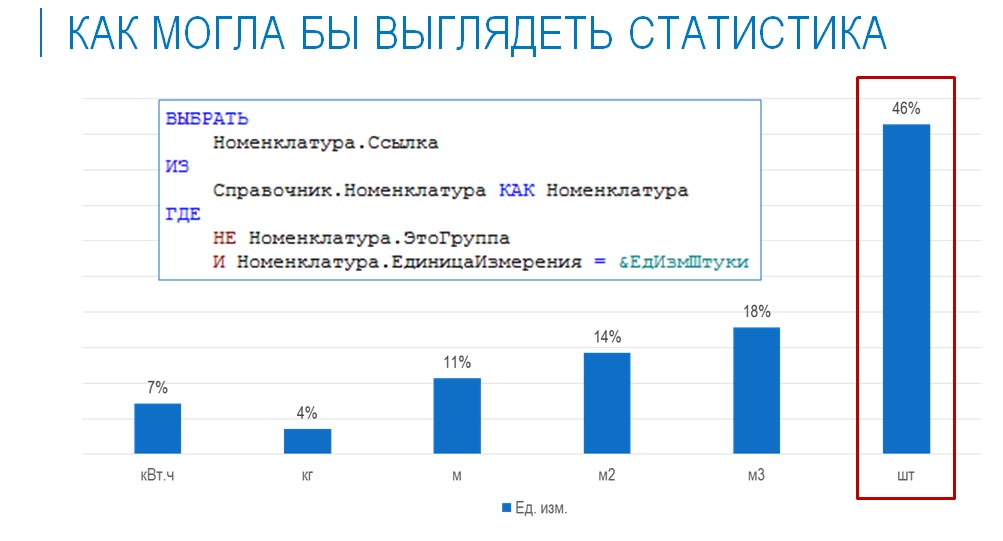
На слайде показан упрощенный пример того, как могла бы выглядеть статистика – это распределение номенклатурных позиций по разным единицам измерения в демо-базе бухгалтерии.
Если мы выполняем запрос с условием по единице измерения, и у нас есть статистика, согласно которой в базе содержится определенное количество номенклатурных позиций с этой единицей измерения, то оптимизатор, основываясь на этой статистике, может заранее сделать предположение о том, сколько данных вернется в результате выполнения запроса.
Оптимизатор знает, что общее количество записей в таблице, допустим, 1000, и что распределение значений по единицам измерений такое-то, и, таким образом, он может еще до выполнения запроса получить оценку того, сколько записей вернется в результате.

В реальности понятие статистики несколько шире, т.е. в статистике хранится больше информации:
- число строк в самой таблице;
- информация о том, когда статистика была собрана, чтобы понимать ее актуальность;
- гистограмма по селективности распределения самих значений (предыдущая картинка).
Здесь есть важный момент: для подзапросов никакой статистики нет. Оптимизатор может только очень приблизительно оценить, сколько данных вернется в результате выполнения подзапроса, пока он не выполнен. И чем больше вложенность подзапросов друг в друга, тем хуже точность этого предположения.
А если мы используем временную таблицу, то она, по сути, является физической таблицей, которая лежит не в основной базе данных, а в служебной (TempDB), поэтому для временных таблиц точно так же считается статистика. Оптимизатор при построении плана с использованием временных таблиц может более точно оценить, сколько данных будет возвращено, и принять решение о наиболее оптимальном способе соединения, чтобы запрос выполнялся максимально быстро.
К каким проблемам приводит неактуальная статистика?
У нас может быть выбран неправильный способ соединения, неправильный способ извлечения данных – запрос выполнится, вернет данные, которые нужны, но время выполнения будет далеко не лучшим.
Поэтому статистику нужно поддерживать в актуальном состоянии. И делается это только средствами базы данных, в 1С для этого средств нет.
База данных поддерживает актуальность статистики автоматически, но ей иногда нужно помогать. Обычно достаточно написать небольшой скрипт и либо поставить его на регламентное выполнение после тяжелых операций над базой, либо дергать его “руками”, если вы внепланово что-то натворили.

Несколько слов по поводу того, так ли хорош наш план запроса.
Прежде чем заниматься его оптимизацией, нужно понять, почему этот план такой. Если навести курсор мыши на оператор SELECT в схеме плана запроса, то появится меню с параметрами, среди которых будет параметр «Reason for Early Termination». С его помощью можно понять:
- является ли анализируемый план первым попавшимся (будет значение «Time Out»), т.к. оптимизатор не успел посмотреть другие. Возможно, на выбор оптимального плана просто не хватило ресурсов, поэтому можно попробовать выполнить запрос еще раз;
- или это план, который оптимизатор посчитал достаточно хорошим (значение «Good Enough Plan Found»), т.е. он сформировал несколько планов, оценил стоимость и выбрал наиболее подходящий (дешевый).
Ищем узкие места

По поводу поиска узких мест. Здесь все сложно. Каких-то общих однозначных рецептов не существует. Все очень индивидуально и упирается в конкретную ситуацию.

Но есть вещи, про которые нужно помнить. Это та же статистика. Когда мы смотрим на план запроса, то у нас внизу рядом с каждым оператором высвечивается его относительная стоимость. Не забывайте, что она всегда указывается в процентах, поэтому стоимость всех операторов плана всегда будет 100%. Уменьшение стоимости одного оператора всегда будет приводить к увеличению стоимости других. Нельзя взять и загнать их всех в 0. Нужно смотреть, какая из операций самая дорогая. Если самая дорогая операция – это Index Seek, то вряд ли мы что-то можем сделать, это поиск в индексе, быстрее уже ничего не бывает. Если самая дорогая операция – Join, то нужно смотреть, возможно, способ Join неправильный.
Также нужно оценивать размеры таблиц. Если таблицы маленькие, чтение данных из них может быть быстрым. А если таблицы большие, то это чтение и должно занимать какое-то время – нельзя же мгновенно прочитать миллион строк.

Рекомендации, которые можно считать общими, и которые будут работать практически для любого плана.
- Логично, что мы выбираем самый дорогой оператор и начинаем смотреть, можно ли с ним что-то сделать. Если самый дорогой оператор – это «Поиск в индексе», т.е. чтение первичных данных из исходной таблицы, то вряд ли мы что-то можем сделать, потому что нельзя выполнить запрос, не получив данные из таблицы.
- Наличие оператора Table Scan (просмотр таблицы) говорит о том, что подходящего индекса нет. Если навести на «Свойства», то можно увидеть Output List (список возвращаемых колонок) и Predicate (условие отбора) – с их помощью можно понять, почему не может использоваться индекс:
- либо в списке возвращаемых колонок присутствует поле, которого нет в индексе;
- либо в списке условий в Predicate присутствуют колонки, которых нет в индексе.
- Что мы делаем в таком случае? Добавляем индекс, выполняем тот же запрос, смотрим план. Если Table Scan сменился на Index Scan или Index Seek, значит, индекс подходит. Если индекс есть, но по-прежнему Table Scan, значит что-то не так с индексом – либо в нем отсутствуют нужные поля, либо оптимизатор решил, что использовать индекс нельзя.
Здесь есть важный момент: индекс может быть покрывающим и не покрывающим.
- Покрывающий индекс – это когда в нем содержатся все данные по колонкам, указанным в запросе.
- Не покрывающий индекс – это, когда в индексе есть только часть данных, а другая часть данных лежит в самой таблице, и после того, как мы получили данные с помощью индекса, нам оставшиеся данные нужно забрать из таблицы. Признаком такой ситуации является оператор Bookmark Lookup или Key Lookup, т.е. оператор со словом Lookup в названии. Это значит, что мы ходим куда-то, уточняя, “добирая” оставшиеся данные.
В некоторых случаях оптимизатор может решить, что лучше он прочтет сразу из таблицы, чем будет сначала считать из индекса, а потом ходить в таблицу и добирать из нее (одно из объяснений ситуации, когда индекс есть, состав полей соответствует, но индекс все равно не используется). Это особенно актуально на маленьких таблицах. Если у вас справочник единиц измерения, в котором редко бывает больше нескольких десятков записей, на него нет особого смысла делать какие-то индексы – на маленьких таблицах индексы чаще вредят, чем помогают.
Полезные ссылки
Полезные ссылки, которые использовались при подготовке доклада.
Обслуживание индексов и статистик MS SQL Server
Анализ запросов с помощью SQL Profiler
Планы запросов - это просто!
Как читать план запроса в SQL Server
MS SQL Books Online. Query Tuning
На Инфостарте есть публикации на тему планов запроса, статистики, но я считаю, что обучающей информации много не бывает, она всеми воспринимается по-разному – кому-то понятней так, кому-то по-другому. Когда ты ознакомился с большим объемом информации, сложил его в голове по кусочкам, тебе стало немного легче.
Вопросы:
– Вы говорили, что временные таблицы запросов помещаются в Tempdb, но она при этом слишком сильно разрастается. Как этого избежать?
– Tempdb – это исключительно служебная база данных. Ее нужно просто регулярно чистить, ей нужно делать TRUNCATE. Средствами самого SQL делается небольшой скрипт, который эту базу данных очищает. Его можно поставить на регламентный запуск. Если у вас приложение работает не в режиме 24/7 (если вы ночью отдыхаете), то вы просто запускаете его ночью. Если этого не хватает, и Tempdb разрастается слишком быстро, можно запустить этот скрипт в обеденный перерыв, еще в какие-то промежутки времени. Tempdb – это именно служебная база для хранения каких-то промежуточных данных – она используется только в процессе исполнения запросов. Соответственно, даже если ее “уронить” в неподходящий момент, самое худшее, что случится – это просто откатятся какие-то транзакции. Данные продуктивной, реальной базы вы не потеряете.
Есть еще один важный момент про статистику – когда используется соединение с помощью хэширования, построенную хэш-таблицу оптимизатор тоже кладет в Tempdb. Но прежде чем строить хэш-таблицу, оптимизатор на основе статистики пытается понять, какой объем данных придет на вход, и, исходя из этого, определяет, сколько памяти ему нужно для построения хэш-таблицы на этом объеме данных.
Но если у нас статистика плохая, и оптимизатор не угадал с объемом памяти, начинается «геморрой». Он хэш-таблицу строит, а выделенная память кончилась. Что делать? Надо положить в Tempdb кусок хэш-таблицы, достроить его дальше – если не хватило, опять положить. После того, как всю таблицу достроили, начать соединяться, периодически подтягивая ее из Tempdb. Поэтому, если у вас было все нормально, а потом внезапно на выполнение запросов стало тратиться много времени – и вы видите, что используется соединение хэшированием, возможная причина – это неактуальная статистика, из-за которой неправильно определился объем памяти под хэш-таблицу.
Первое, что нужно сделать – это обновить статистику, посмотреть. Если помогло – ура, если не помогло – смотрим дальше.
– Эта Tempdb не очищается автоматически встроенными средствами?
– Tempdb очищается при перезагрузке – там есть таблицы, которые создаются для сеанса, они удаляются при отключении сеанса. И есть таблицы, которые создаются для всех сеансов – они удаляются при перезагрузке. Следует помнить, что Tempdb – это тоже база данных и у нее есть своя модель восстановления. Если вы поставите ей полную (Full) модель восстановления, у вас для нее будет вестись журнал транзакций, который тоже будет разрастаться. Но, конечно, полная модель восстановления для нее не нужна.
– У меня вопрос по поводу того, что стоимость всех операторов в плане запроса всегда будет 100%. У меня был опыт – использование кластеризованного индекса занимало 90% от общего плана. Я создал обычный, не кластеризованный индекс, и производительность этой операции стала 70%. Но при этом поменялись процентные соотношения внутри других гистограмм, и в целом, осталось непонятно, стало ли оно быстрее работать или медленнее.
– Любое действие, изменяющее план запроса, ведет к тому, что у нас поменяется именно процентное соотношение стоимости операторов.
– А как мне в целом узнать, стал ли у меня запрос в результате создания нового индекса выполняться лучше, быстрее?
– Сам план запроса не дает ответа на вопрос – быстро выполняется запрос или медленно. План запроса говорит о том, как именно происходит выполнение запроса. Чтобы измерить скорость выполнения конкретного запроса, мы его запускаем и засекаем время. Если после оптимизации стало работать быстрее, значит, все хорошо. План запроса показывает, что поменялось внутри. Если у вас была оценка Index Scan – 90%, а стала 70%, это значит, теперь меньшая часть времени тратится на получение данных. Соответственно, большая часть времени тратится на их дальнейшую обработку. И, наверное, нужно смотреть, что там дальше с этими данными происходит.
– Получается, что общей оценки времени я в этом плане не найду?
Когда у нас есть план, у него есть оператор SELECT. Если на него навести и посмотреть его свойства, у него тоже будут Cost’ы. И можно будет по Cost’ам получить оценку – сколько вычислительных ресурсов было задействовано – сколько было потрачено процессорного времени, операций ввода-вывода, какой объем памяти. Если эта оценка уменьшилась – наверное, стало быстрее.
– Какой конкретно показатель нужно смотреть?
– Основное – это сам Operator Cost – стоимость самого оператора, суммарно CPU и I/O. Здесь есть значение в абсолютных единицах и в процентах. Ориентируйтесь на значение в абсолютных единицах.
– А вы одобряете распространенную практику запускания каждую ночь обновления статистики?
– Обновление статистики и full scan – это совершенно нормальная вещь. Если это делается по ночам, когда сервер все равно простаивает, хуже от этого точно не будет. Здесь есть важный момент – если у вас вечером был запущен какой-то тяжелый регламент, который что-то перепроводит, пересчитывает, меняет, а потом ночью прошло обновление статистики – это хорошо. Но если ну вас ночью прошло обновление статистики, а потом в обед делается перепроведение, то толку не будет. Потому что у вас данные сильно поменялись, и вы полдня живете с неактуальной статистикой.
Периодически SQL-сервер сам обновляет статистику. У него в настройках есть определенный параметр – он отслеживает, какая доля строк в таблице была изменена. Когда он видит, что после последнего обновления статистики был изменен определенный процент строк в таблице, он автоматически запускает операцию по обновлению статистики.
Здесь важен еще один момент – сам запрос может выполняться в двух режимах. В зависимости от настройки SQL-сервера, оптимизатор, прежде чем строить план запроса, сначала обращается к статистике. Он определился с перечнем объектов, которые ему нужны, и дальше ему по этим объектам нужна статистика, чтобы выбрать оптимальные способы доступа к данным. Движок возвращает ему статистику, но предупреждает, что она неактуальная. И здесь в зависимости от настроек есть два варианта. Либо оптимизатор говорит: «Хорошо, я выполняю запрос на том, что есть». Либо второй вариант – он дождется, когда будет получена актуальная статистика, и только после этого начнет строить план. Если у вас запрос, который выполнялся нормально, вдруг внезапно начал тормозить, возможно, как раз SQL решил, что статистика стала неактуальной, и оптимизатор ждет, пока она обновится. И здесь регулярное принудительное обновление статистики может помочь, потому что у вас может быть таблица, которая изменяется нечасто, изменения копятся, и в какой-то момент перешагивают через порог, когда SQL решает, что пора обновлять статистику. И чтобы этот момент не попал на неудачное время, когда нужно активно работать с базой, можно профилактически пересчитывать по ночам.
– А можно отключить автоматическое обновление статистики или не стоит?
– Можно. Но если вы отключаете автоматическое обновление, значит, должно быть ручное. Полностью отключать обновление статистики крайне не рекомендуется, это очень негативно скажется на производительности. Само по себе обновление статистики – нересурсоемкая операция. Она ресурсы потребляет, но не драматически. Важно, что статистику можно обновлять в процессе работы с базой, она не требует монопольного доступа. Пользователи так же работают с документами, в фоне идет обновление статистики, никто ничего не замечает.
Можно обновлять статистику полностью, можно только по конкретным таблицам, можно обновлять конкретные виды статистики, можно обновлять статистику по конкретным столбцам.
– А в тот момент, когда идет обновление статистики, оптимизатор статистикой не пользуется – какие-то более тупые планы строит?
– Он, в зависимости от настройки, либо ждет, когда обновление закончится, либо строит план на той статистике, которая есть.
– Еще один вопрос по созданию индекса. Можно ли создать индекс непосредственно в SQL, минуя конфигуратор?
– Крайне не рекомендую создание индекса через SQL, потому что как только вы сделаете «Обновить конфигурацию базы данных» из конфигуратора, все эти индексы “улетят”, сделаете реструктуризацию – тоже “улетят”. Платформа 1С то про них “не в курсе”. Если мы говорим про 1С, единственный правильный способ создания индексов – это зайти в конфигуратор, правой кнопкой нажать на реквизите и поставить для него «Индексировать». Или включить реквизит в состав критерия отбора.
– А покрывающий индекс как создать?
– 1С в основном, создает кластеризованные индексы, поэтому с этим особых проблем нет. Потом опять же, если мы говорим про регистры (и накопления, и сведений), то при создании регистра для него всегда создается индекс, куда включаются все измерения регистра. И если мы ставим на каком-то измерении «Индексировать», то добавляется индекс в котором опять присутсвуют все измерения регистра, но выбранное измерение просто идет первым в этом списке. А дальше они идут в том порядке, в котором они указаны в дереве конфигурации. Про этот момент некоторые не знают, но если мы говорим про регистры накопления и регистры сведений, то порядок измерений очень важен, его нельзя задавать произвольным образом. Потому что индекс для регистра создается всегда, и измерения в индексе всегда идут в том порядке, в котором они перечислены в дереве конфигурации. А если вы делаете дополнительный индекс, то он у вас отдельно будет вынесен вперед, но остальные индексы все равно останутся.
– У меня недавно на проекте были рекомендации – поменять порядок столбцов в регистре. Если я поставлю для измерения «Индексировать» – оно само перенесется вперед?
– Оно не перенесется вперед, будет создан дополнительный индекс, в котором этот столбец будет первым, но кроме него всегда будет существовать другой индекс, где перечислены все измерения в том порядке, в котором они указаны в дереве метаданных.
– Общий индекс создается для регистра по умолчанию?
– Индекс, включающий все измерения в том порядке, в котором они указаны в дереве метаданных, создается по умолчанию. Наиболее часто используемые – лучше выносить вверх.
Например, у вас есть регистр «Товары на складах» с измерениями «Склад» и «Номенклатура». Если вы чаще используете отбор по складам, то на первом месте должен быть склад. Но если вы чаще смотрите номенклатуру и вам все равно, на каком складе остаток, то наверху должна быть Номенклатура. А если и так и так, то ставим первым – склад, а для номенклатуры ставим «Индексировать». Для склада ставить «Индексировать» смысла нет, потому что если он идет первым, то индекс по нему в любом случае создастся.
Здесь еще момент такой – если у вас, к примеру, в регистре три измерения, и вы используете запрос, в котором идет отбор по первому и по третьему измерению, а по второму измерению отбора нет, то будет частичное использование индекса. Он с помощью индекса отберет данные по первому изменению, и дальше уже по этому набору пробежит оператором Filter и отберет все остальное. А если у вас указан отбор по всем трем измерениям, то он индексом сразу выдернет целиком ту часть, которую нужно. Поэтому даже если вы знаете, что у вас во втором измерении только одно значение – не надо лениться, лучше все равно включить его в отбор, потому что тогда оптимизатор сможет использовать индекс целиком, а не частично.
При пропущенном отборе по измерению индекс все равно используется, но частично. Потому что для того набора данных, который был возвращен, нужно будет еще произвести дополнительное действие
– Часто в 1С какой-нибудь несложный отчет (например, ведомость по взаиморасчетам с контрагентами) внутри содержит много соединений – из-за того, что многие поля указаны через точку, даже в типовом решении. Плюс, на каждый объект ведется RLS. Смотря на план такого запроса, даже люди, которые отлично себе представляют, что такое TableScan, теряются, потому что это – пять страниц вправо, 10 страниц вниз. Как проанализировать эти 120 кубиков и понять – что, откуда и куда? Есть ли какой-нибудь Whitepaper в таких случаях? Нужно ли вообще пытаться анализировать план запроса, когда в нем так много операторов?
– Если вы нашли запрос, который является источником проблемы, вам нужно понять – почему он тормозит. Что внутри него не так? Не заглядывая в план запроса, мы можем только предполагать, основываясь на знании, опыте и т.д. Точно знать мы не можем. Да, есть общие рекомендации самого SQL-сервера (в MS – свои, у Postgres – свои), есть общие рекомендации фирмы «1С». На сайте ИТС есть отдельный раздел по общим правилам оптимизации запросов. Можно просмотреть, соответствует ли запрос общим требованиям. Если там все нормально, все правильно, то единственный возможный вариант – это лезть в план, потому что больше некуда.
Если огромный запрос получается из-за RLS – можно попробовать выключить RLS или запустить этот же отчет под пользователем, на которого RLS не действует, сравнить. Если скорость примерно одинаковая, значит, дело не в RLS и можно анализировать запрос, на котором этого RLS нет. Если скорость существенно отличается, то, наверное, это RLS виноват.
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2017 COMMUNITY.


Вступайте в нашу телеграмм-группу Инфостарт