Введение
Одно из требований к специалистам на экзамене «1С:Эксперт по технологическим вопросам». (http://1c.ru/rus/partners/training/expert.htm) - владение методиками и технологиями нагрузочного тестирования систем на платформе «1С:Предприятие 8». Изучим доклад Виктора Богачева о нагрузочном тестировании ООО «Деловые Линии» (Infostart Event 2014).
Попробуем на тестовой базе повторить избранные места доклада:
Ситуация 1. При увеличении числа запросов к базе до 3-4 тысячи в секунду стали наблюдаться pagelatch из-за создания/удаления временных таблиц и индексов
Ситуация 2. При завершении сессий возникает нагрузка на сервер СУБД из-за уничтожения временных таблиц
Оборудование и ПО
Платформа 8.3.12, без совместимости. Управляемый режим блокировок. Сервер приложений – отдельно, 1С:Предприятие запущено на сервере СУБД (MS SQL 2012). Жесткий диск – SSD. В приложении к статье – база данных с обработкой нагрузочного тестирования. Кто захочет – cможет повторить все примеры.
Ситуация 1
Для создания нагрузки, будем запускать несколько потоков, запрос в цикле, например
Запрос1.Текст = "ВЫБРАТЬ
| ""флаг запроса"" КАК Поле2
|ПОМЕСТИТЬ Таб1
|
|ИНДЕКСИРОВАТЬ ПО
| Поле2
|;
|
|////////////////////////////////////////////////////////////////////////////////
|УНИЧТОЖИТЬ Таб1";
Запрос2 – то же без создания временной таблицы и без индексирования, Запрос3 – с созданием временной таблицы, но без создания индекса. Более подробно – смотрите обработку в приложенной базе данных 1С.
Объем доступной памяти не контролируем. Почти отсутствует нагрузка на жесткий диск: задержки возникают из-за того, что разные потоки не могут параллельно писать в одну страницу жесткого диска (памяти). Ниже характерное состояние дисковой системы во время теста.
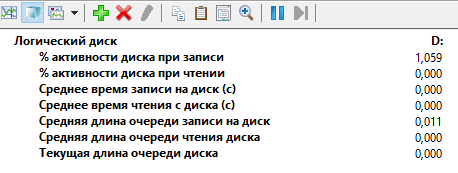
Количество запросов, latch проверяем с помощью монитора производительности: Мой компьютер - Управление – Производительность - SQL Server, Latches Object. Как и рекомендуют в документации.
Варианты и результаты теста:
- Процедура «ПодключитьОбработчикОжидания». (Запрос1)
- Фоновые задания, ни временная таблица, ни индекс НЕ создаются. (Запрос2)
- Фоновые задания, индекс временной таблицы НЕ создается. (Запрос3)
- Фоновые задания, создается индекс временной таблицы. (Запрос1)

- При подключении обработчика ожидания несколько раз мне не удалось получить больше 1,6 тысяч запросов в секунду. Скорее всего, ПодключитьОбработчикОжидания, не обеспечивает параллельной работы: клиент «подвисает». О том же указано и в описании: …Подключает вызов указанной процедуры модуля управляемого приложения (модуля обычного приложения) или глобального общего модуля через определенный интервал времени. Вызов будет осуществляться только в "состоянии покоя", то есть в тот момент, когда программа не выполняет никаких действий… Поэтому метод «ПодключитьОбработчикОжидания» для нагрузочного тестирования использовать не будем.
- Если в тексте запроса не создавать ни временных таблиц, ни индексов к ним - ожиданий latch не возникает.
- Из-за создания большого числа временных таблиц, появились ожидания latch.
- В случае создания временных таблиц, индексов возникают значительные ожидания latch: время теста 30 секунд, total latch wait time 2.4 секунд.
Еще одно замечание по нагрузочному тестированию нашел на ИТС, Влияние внешних обработок на производительность http://its.1c.ru/db/metod8dev#content:5940:hdoc : Компиляция модулей встроенных в конфигурацию выполняется однократно в процессе инициализации, тогда как для внешних обработок компиляция будет выполняться многократно, отдельно для каждого пользователя. Это приводит как к снижению производительности (компиляция модуля требует времени), так и существенному повышению нагрузки на CPU. Поэтому не рекомендуется выносить во внешние обработки функционал, который может одновременно использоваться большим количеством пользователей.
Итак, для максимальной нагрузки тест будет выполняться в несколько потоков с помощью фоновых заданий (если нужно расписание - используем регламентные задания), будет создаваться индекс временной таблицы, внешние обработки использоваться не будут.
Посмотрим на ситуацию со стороны СУБД. Будем использовать sys.dm_os_latch_stats. Очистить существующую статистику DBCC SQLPERF ('sys.dm_os_latch_stats', CLEAR) - запустить нагрузочный тест. Выборка статистики по нагрузке Select * from sys.dm_os_latch_stats where wait_time_ms > 0
|
latch_class |
waiting_requests_count |
wait_time_ms |
max_wait_time_ms |
|
ACCESS_METHODS_HOBT_COUNT |
48 |
7 |
1 |
|
BUFFER |
184436 |
7492 |
309 |
Динамическое представление sys.dm_os_latch_stats указывает, что основной тип latch – BUFFER. Как указано в документации (https://msdn.microsoft.com/ru-ru/library/ms175066%28v=sql.120%29) Используется для синхронизации краткосрочного доступа к страницам баз данных. Кратковременная блокировка буфера необходима перед считыванием или модификацией любой страницы базы данных. Конфликт кратковременной блокировки буферов может указывать на наличие ряда проблем, в числе которых — «горячие» страницы и низкая производительность подсистемы ввода-вывода.
Представление sys.dm_os_wait_stats устанавливает различие между ожиданиями кратковременных блокировок страниц, вызванными операциями ввода-вывода и операциями чтения и записи на данной странице. Очистить существующую статистику DBCC SQLPERF ('sys.dm_os_wait_stats', CLEAR) запустить нагрузочный тест. Выборка статистики по нагрузке Select * from sys. dm_os_wait_stats where wait_time_ms > 0
|
wait_type |
waiting_tasks_count |
wait_time_ms |
max_wait_time_ms |
|
LATCH_SH |
21 |
1 |
0 |
|
LATCH_EX |
45 |
6 |
0 |
|
PAGELATCH_SH |
24552 |
1680 |
280 |
|
PAGELATCH_UP |
88271 |
3460 |
267 |
|
PAGELATCH_EX |
115741 |
2012 |
1 |
|
PAGEIOLATCH_UP |
227 |
14 |
0 |
PAGELATCH и PAGEIOLATCH – соответственно доступ к страницам памяти и жесткого диска. LATCH – доступ к нестраничным ресурсам. Расшифровку типов ожидания можно посмотреть https://www.sqlskills.com/help/waits/ Очень хорошая, подробная статья. Приведу выдержку.
Common causes of PAGELATCH_XX contention are:
- Allocation bitmap contention in tempdb (PAGELATCH_UP for multiple threads trying to change the same bitmap), and under extreme loads, in user databases
- Table/index insert hotspot (PAGELATCH_EX for threads inserting onto the same page and possibly PAGELATCH_SH for threads reading from that page)
- Excessive page splits from random inserts (PAGELATCH_EX for threads trying to insert/update rows on a page and possibly PAGELATCH_SH for threads reading from that page)
Еще одна статья https://habr.com/post/216309/, на русском.
Для системного представления sys.dm_io_virtual_file_stats команда очистки не предусмотрена. Поэтому сначала выгрузим содержимое динамического представления во временную таблицу
use tempdb
go;
select * into MyTempDB01 from sys.dm_io_virtual_file_stats(null,null)
потом выполним нагрузочное тестирование и найдем разницу между старой и новой статистикой с помощью запроса
select tab1.database_id,
tab1.file_id,
tab1.num_of_reads-tab2.num_of_reads AS num_of_reads,
tab1.num_of_bytes_read - tab2.num_of_bytes_read AS num_of_bytes_read,
tab1.num_of_writes - tab2.num_of_writes AS num_of_writes,
tab1.num_of_bytes_written - tab2.num_of_bytes_written AS num_of_bytes_written,
tab1.io_stall-tab2.io_stall AS io_stall,
tab1.io_stall_read_ms-tab2.io_stall_read_ms AS io_stall_read_ms,
tab1.io_stall_write_ms-tab2.io_stall_write_ms AS io_stall_write_ms,
tab1.size_on_disk_bytes - tab2.size_on_disk_bytes AS size_on_disk_bytes
from sys.dm_io_virtual_file_stats(null,null) AS tab1
inner join MyTempDB01 AS tab2
on tab1.database_id = tab2.database_id
and tab1.file_id = tab2.file_id
|
database_id |
file_id |
num_of_reads |
num_of_bytes_read |
num_of_writes |
|
1 |
1 |
0 |
0 |
0 |
|
1 |
2 |
0 |
0 |
0 |
|
2 |
1 |
0 |
0 |
57 |
|
2 |
2 |
0 |
0 |
4672 |
Более подробно таблицу можно посмотреть в приложенном файле *.xls. Как видно, запись и чтение происходила только в базу ID = 2. Наверное, это TempDB. Сделаем запрос select DB_ID('tempdb') – получим результат = 2. Так и есть.
Удалим временную таблицу drop table dbo.MyTempDB01
Поскольку мы выяснили, что latch происходят в таблице TempDB, можно попробовать перенести ее на более быстрый (или медленный) носитель. Для этого применяются команды
USE master
GO
ALTER DATABASE tempdb
MODIFY FILE (NAME = tempdev, FILENAME = 'E:\tempdb.mdf')
GO
ALTER DATABASE tempdb
MODIFY FILE (NAME = templog, FILENAME = 'E:\templog.ldf')
GO
Имена для файлов, соответствующих tempdev, templog можно посмотреть в свойствах таблицы. После изменения настроек TempDB службу SQL Server необходимо перезапустить. В моем случае тестирование после переноса не выявило изменений.
У системного представления sys.dm_db_index_operational_stats(,,,) первый аргумент ID базы -берем из прошлого примера. DMV не содержит имени таблицы – приходится делать левое соединение с таблицей sys.objects
Select tab2.name, tab1.page_latch_wait_count
from sys.dm_db_index_operational_stats(2,NULL,NULL,NULL) AS tab1
left join sys.objects as tab2 ON tab1.object_id = tab2.object_id
where tab1.page_latch_wait_count > 0
Строки повторяются: одна для таблица, другая – ее индекс. Назначения таблиц – из документации: https://msdn.microsoft.com/ru-ru/library/ms179503%28v=sql.120%29.aspx
|
name |
page_latch_wait_count |
Назначения таблиц |
|
sysrscols |
102147 |
Порядок полей таблиц |
|
sysrowsets |
40659 |
Существует в каждой базе данных. Содержит по строке на каждый набор строк секции для индекса или кучи. |
|
sysallocunits |
546855 |
Существует в каждой базе данных. Содержит по строке на каждую единицу распределения памяти. |
|
sysallocunits |
684 |
|
|
sysschobjs |
57 |
Существует в каждой базе данных. Каждая строка представляет объект базы данных. |
|
sysschobjs |
1 |
|
|
syscolpars |
3 |
Существует в каждой базе данных. Содержит по строке на каждый столбец таблицы, представления или табличной функции. |
|
syscolpars |
2 |
|
|
sysidxstats |
40 |
|
|
sysiscols |
1 |
Существует в каждой базе данных. Содержит по строке на каждый материализованный столбец индекса или статистики. |
|
sysobjvalues |
12 |
Существует в каждой базе данных. Содержит по строке на каждое общее свойство сущности. |
Любопытно, что таблица sysobjvalues в нашем случае производит гораздо меньше latch, чем топовые таблицы, а в докладе она наоборот, входит в топ. Возможно, изменилась архитектура ПО. Более подробно таблицу можно посмотреть в приложенном файле *.xls
Ситуация 2.
Включим замер производительности. Создадим много временных таблиц с помощью 1С. Как известно, при завершении запроса 1С, СУБД использует не DROP TABLE, а TRUNCATE TABLE - оставляет временную таблицу для повторного использования. Чтобы временных таблиц было много - каждая временная таблица должна иметь уникальный набор столбцов. Более подробно – смотрите обработку в приложенной базе данных 1С. У меня временные таблицы выглядят примерно так, их около 10 тысяч.
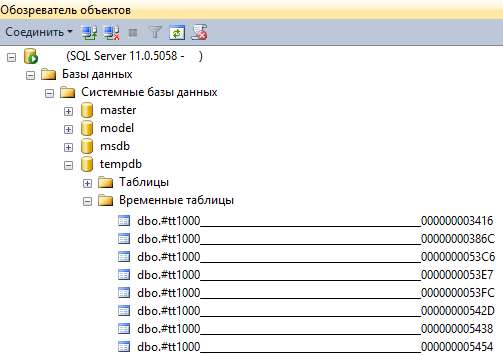
Посмотрим активные сессии: select * from sys.dm_exec_sessions where program_name = '1CV83 Server'
|
session_id |
login_time |
host_name |
program_name |
status |
|
51 |
2018-06-19 13:12:34.050 |
U1C01 |
1CV83 Server |
sleeping |
|
. . . |
|
|||
|
62 |
2018-06-19 13:12:34.050 |
U1C01 |
1CV83 Server |
sleeping |
При завершении сеанса 1С сессия SQL не завершается, а переходит в спящий режим. Поэтому чтобы уничтожить временные таблицы, принудительно завершим все активные сессии 1С пакетом команд
kill 51
. . .
kill 62
Кстати, чтобы не повторять однообразные строки, можно использовать скрипт, на основе https://ru.stackoverflow.com/questions/733831
Посмотрим результаты замера производительности.
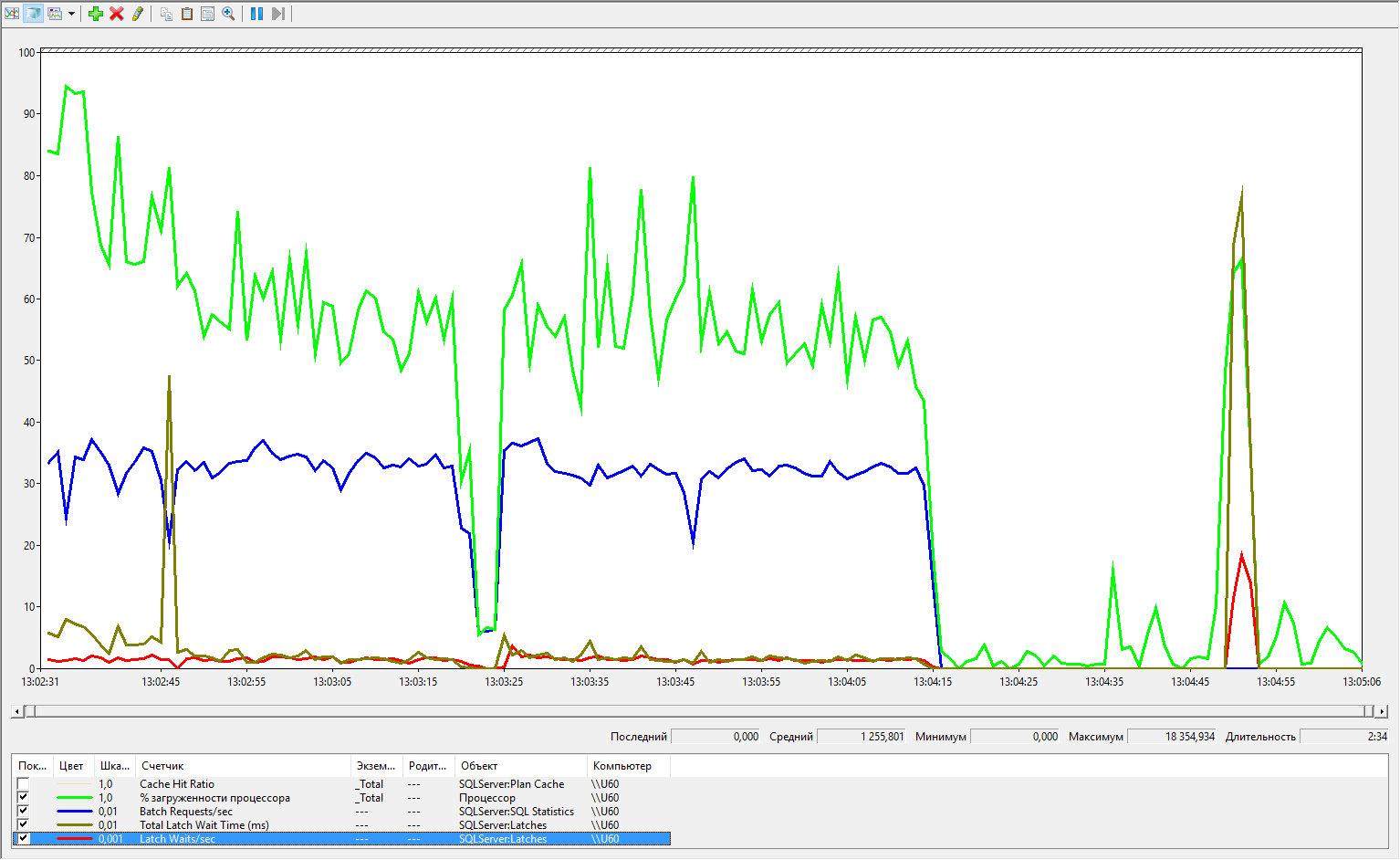
Здесь до 13:04:15 идет создание временных таблиц, между 13:04:45 и 13:04:55 – завершение сессий SQL. Максимальные значения показателей latch более чем в три раза превосходят значения предыдущего эксперимента.
Для сравнения: если запустить запросы без создания временных таблиц, а затем завершить сессии SQL, ожиданий latch наблюдаться не будет. Хотя в момент завершения нагрузка на процессор почти такая же.
Посмотрим еще одно DMV sys.dm_exec_query_stats. Для него тоже нет способа очистки, но события можно выбирать по времени, например
SELECT st.*, qs.*
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
where qs.last_execution_time > DATETIMEFROMPARTS(2018,06,24,13,56,50,0)
--and qs.last_execution_time < DATETIMEFROMPARTS(2018,06,24,13,57,0,0)
ORDER BY execution_count DESC;
Это представление группирует исполняемые запросы по тексту. Видно, как часто встречаются одинаковые тексты запросов. Например, при присваивании имени временной таблицы выполняется запрос типа SELECT 1 WHERE OBJECT_ID('tempdb..#tt674') IS NOT NULL.
Отчеты по DMV dm_os_wait_stats, dm_db_index_operational_stats отличаются от ситуации 1 только в процентном соотношении распределений количества latch.
Флаги трассировки, влияющие на latch
- 8048 – применяется в случае, если в вашей системе более 8 логических процессоров и наблюдается большое число ожиданий CMEMTHREAD и кратковременных блокировок.
- 1117 - позволяет управлять параметрами роста таблицы TEMPDB. в случае, если используется несколько файловых групп.
- 1118 - отключает смешанные экстенды. Влияет на GAM и SGAM. Pagelatch бывают PFS (pafe free space), IAM (index allocation map), GAM (global allocation map), SGAM (shared global allocation map).
Более подробно смотрите на ИТС – новая статья Флаги трассировки для работы с MS SQL Server http://its.1c.ru/db/metod8dev/content/5946/hdoc/_top
Выполним команду DBCC TRACESTATUS (1118), результат ниже
|
TraceFlag |
Status |
Global |
Session |
|
1118 |
0 |
0 |
0 |
Выполним команды DBCC TRACEON (1118); DBCC TRACESTATUS (1118), результат ниже
|
TraceFlag |
Status |
Global |
Session |
|
1118 |
1 |
0 |
1 |
Проверим, как влияет на количество latch. Запустим нагрузочный тест. Ниже отчет монитора производительности. Длительность latch была значительной, почти 2,6 секунды и ощутимо уменьшилась.
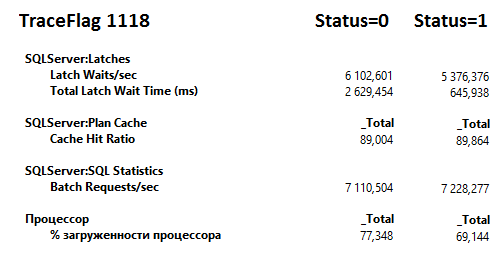
Не знаю, насколько чисто мне удалось выполнить этот эксперимент. Повторял несколько раз - получается. У меня возникло ощущение, что для прекращения использования нового флага трассировки службу сервера иногда приходится перезапускать. Проверьте у себя – поделитесь впечатлениями.
Любопытно, что в стандартных отчетах MS SQL Manager Studio видны изменения флагов трассировки от стандартных установок: Max degree of parallelism и TraceFlag 1118.
Кстати
Свойство SQL request wait - длительность запросов, о котором Виктор рассказывает в докладе на минуте 17, описано https://docs.microsoft.com/ru-ru/sql/database-engine/configure-windows/configure-the-query-wait-server-configuration-option?view=sql-server-2014. Посмотреть список таких свойств свойств можно командой select * from sys.configurations.
Заключение
Уважаемый читатель, если Вы добрались до этой строчки, значит есть интерес. Ищу мотивацию писать дальше, повторить исследование для postgres. Лучше, если это будет нужно не только мне, а кому-то еще. Поэтому я беру на себя супер-обязательство: если тема будет интересна и наберет хотя бы 50 звездочек на Инфостарт, я изучу postgres и дополню статью. Ошибки и неточности этой статьи буду исправлять по мере возможности. Кроме этого, жду Ваших конструктивных замечаний. Все в ваших руках.
Вступайте в нашу телеграмм-группу Инфостарт