















1С: Документооборот, Data Science и Python
На нашем предприятии внедрен 1С: Документооборот и нам приходится постоянно думать о повышении качества работы пользователей в системе. В 1С: Документообороте пользователи работают прежде всего с текстом и мы искали возможности «умного» анализа текстов для повышения эффективности работы программы. Уверены, что использование машинного обучения позволит достичь поставленных задач и в конце концов мы придем к тому, что искусственный интеллект будет проверять тексты договоров и писать замечания вместо юристов и бухгалтеров)
Описание задачи
В статье в общих чертах описывается процесс обучения и применения модели машинного обучения. Возможно, данный пример подтолкнет кого-то для применения новых технологий в своей работе.
Для «пробы пера» и знакомства с машинным обучением нами была выбрана следующая проблема: в 1С: Документооборот активно используется постановка задач на исполнение. По каким-то задачам руководители ожидают получение ответного документа: письмо контрагенту, отчет или другой документ (например, «Прошу проработать вопрос и подготовить ответ покупателю»), а некоторые задачи не требуют, чтобы исполнитель прикладывал документ (например, «Для сведения»).
В 1С: Документооборот еще на этапе внедрения мы создали два шаблона задач: с подготовкой ответа и без. Шаблон с подготовкой ответа имеет заполняемый предмет и тем самым требует от исполнителя приложить документ исполнения, но практика показывает, что, те кто ставит задачи не всегда выбирают необходимый шаблон, они нажимают «Отправить на исполнение» и выбирают первый попавшийся шаблон и уже в описании задачи пишут «Подготовить ответ», «Подготовить отчет» и пр. Исполнитель выполняет задачу не прикладывая файл, а постановщик не принимает ответ и требует приложить документ. Такая переброска задачами затягивает процесс. Конечно, эту задачу можно решить «1С-ными» механизмами, например, добавить признак или каждый раз переспрашивать постановщика задач, ожидает ли он ответ и прочее.
Но мы решили на этом процессе протестировать возможности машинного обучения: если мы научим алгоритм определять по тексту постановки задачи, требуется ответ или нет, мы можем рекомендовать исполнителю приложить файл исполнения (или запретить выполнение без приложенного файла).
Подготовительная работа
Программировать будем на Python – это основный язык Data Science, он очень простой, лаконичный и для 1С-ника не должно составить серьёзных проблем с ним разобраться. Устанавливаем Anaconda. Этот пакет установит и Python с основными библиотеками и Jupiter где мы будем писать код. В Jupiter код пишется в отдельный строках, исполняется построчно и показывает результат после выполнения строк (если нам есть, что показать) – это сначала кажется необычным – но в итоге оказывается очень и очень удобным.
Создание обучающей выборки
Для начала нам нужна обучающая выборка. Выбираем из 1С: Документооборот 5 000 задач исполнения и в отдельной колонке проставляем признак 1- поручение требует документального ответа, 0 – поручение не требует документального ответа.
У нас получается вот такая таблица (представлена часть таблицы):
|
text |
priznak |
|
Прошу проверить, при отсутствии замечаний принять к учету. |
0 |
|
Прошу рассмотреть и подготовить ответ |
1 |
|
В работу |
0 |
|
Прошу собрать информацию у ОМ + КД. |
1 |
|
проработать, подготовить ответ |
1 |
Загрузка и подготовка данных в Jupiter
После подготовки обучающей выборки начнем программирование на python. Создаем новый файл в Jupiter и в первой строчке объявляем необходимые модули и переменные:
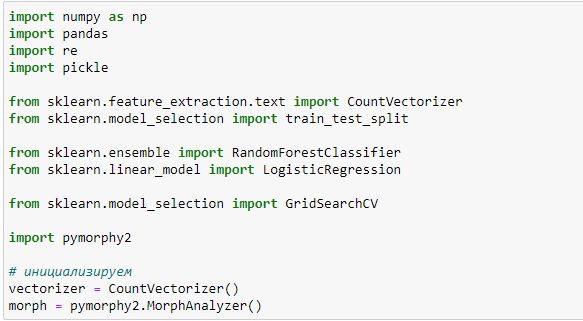
Загружаем файл
![]()
Перед началом процесса обучения необходимо подготовить текст.
Подготовка включает следующие этапы:
- Исключение из текста незначимых символов: цифр, знаков препинания. Они не влияют на текст поручения и будут мешать алгоритму.
- Лемматизация – приведение слов в нормальную (словарную) форму. В русском языке (да и в других) фразы можно формулировать по-разному и от этого будет меняться форма слова, хотя смысл может оставаться неизменный. Для того, чтобы повысить эффективность работы алгоритма мы все слова приводим в нормальную форму. Уменьшиться количество различных слов и наш алгоритм будет эффективнее.
Для этого будем использовать функцию лемматизации:
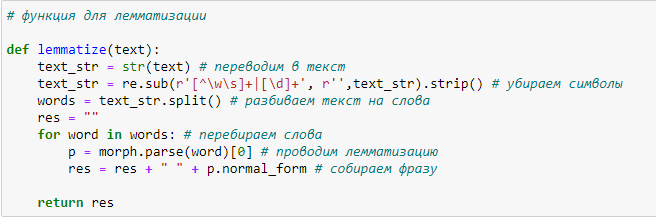
По комментариям понятно, что именно делает эта функция.
Вызываем функцию для всей таблицы:
![]()
Теперь текст выглядит иначе:
|
text |
priznak |
|
просить проверить при отсутствие замечание принять к учёт |
0 |
|
просить рассмотреть и подготовить ответ |
1 |
|
в работа |
0 |
|
просить собрать информация у ом кд подготовить сз с список конференция |
1 |
|
проработать подготовить ответ |
1 |
Формируем переменную текст
![]()
Создаем векторы слов
Дело в том, что системы машинного обучения понимают только числовые значения, в них нельзя загружать текст, картинки или другие типы и для обучения алгоритма необходимо перевести слова в цифровые значения.
Мы будем делать это с помощью механизма «Мешок слов».
Мешок слов — это модель текстов, в которой каждый документ или текст выглядит как неупорядоченный набор слов. Его можно представить в виде матрицы, каждая строка в которой соответствует отдельной строке текста, а каждый столбец — определенному слову. Ячейка на пересечении строки и столбца содержит количество вхождений слова в соответствующий документ.
Его работу лучше показать на примере:
Пусть у нас имеется текст в несколько строк.
|
Булок и чай |
|
Кто хочет чай |
|
Купи булок |
Из текста мы строим матрицу уникальных слов. Где каждое слово закреплено строго за свои индексом
|
Индекс |
Слово |
|
0 |
Булок |
|
1 |
И |
|
2 |
Чай |
|
3 |
Кто |
|
4 |
Хочет |
|
5 |
Купи |
Далее по каждой фразе строится матрица
|
|
Булок |
И |
Чай |
Кто |
Хочет |
Купи |
|
Булок и чай |
1 |
1 |
1 |
0 |
0 |
0 |
|
Кто хочет чай |
0 |
0 |
1 |
1 |
1 |
0 |
|
Купи булок |
1 |
0 |
0 |
0 |
0 |
1 |
«Мешок слов» игнорирует порядок слов. Но для нашей задачи этим можно пренебречь. Не так важно, что написал пользователь: «Подготовить ответ» или «Ответ подготовить до 15 августа»
Создаем векторы для нашего текста:

Теперь в переменной «X» хранится наш текст, разложенный в матрицу используя алгоритм «Мешок слов».
В переменную «y» записываем результаты нашей обучающей выборки
![]()
Теперь все готово для обучения.
Обучение модели
В этом примере мы упускаем анализ и оптимизацию различных алгоритмов. Обычно этот этап выглядит следующим образом:
- Вся выборка разбивается на обучающую и тестовую (примерно 80% на 20%)
- На обучающей выборке производится обучение (применяются различные алгоритмы или у алгоритмов меняются параметры), а на тестовой выборке проверяется качество предсказания, пока не будет получен приемлемый результат.
Мы будем обучать алгоритмом «Случайны лес». Он дал довольно хороший результат предсказаний и без дополнительных параметров (применяется один параметр random_state=241 для обеспечения повторяемости обучения).
Вообще все обучение сводится к двум строчкам:
![]()
Теперь в переменной clf мы имеем обученную модель и используя эту модель можем строить предсказания.
Проверим как работает наша модель:
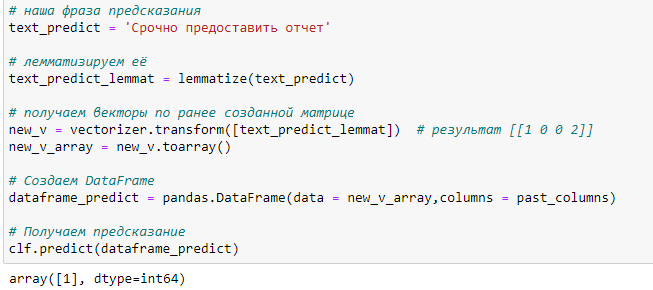
Ответ [1] говорит, о том, что исполнитель должен приложить документальный ответ к исполнению задачи, что соответствует смыслу текста.
Сохраняем обученную модель и модель векторов в файл для последующего использования:
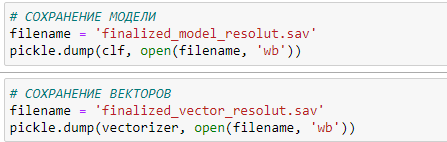
Далее встал вопрос как из 1С обращаться к обученной модели. Мы выбрали вариант - организация веб-сервиса (используем веб-сервер flask) к которому обращается 1С:
- 1С: Документооборот получает строку задачи
- С этой строкой обращается к веб-серверу flask
- Получает ответ от обученной модели
- Отражает результат предсказания.
Если алгоритм решает, что исполнитель должен подготовить ответ, то 1С: Документооборот показывает вот такую надпись в задаче исполнителя:

Резюме
На этом примере мы убедились, что использование машинного обучения дает положительный эффект:
- Процесс подготовки и обучения технологичен (есть множество специализированных библиотек, большое количество информации по их использованию и готовых технологий работы с текстом)
- Для обучения и последующего переобучения достаточно добавить фразы или расставить иначе признаки в файле Excel
- Алгоритм работает очень быстро. Ответ от сервера мы получаем меньше чем за секунду
- «Умные» подсказки помогают пользователям корректно оформлять документы
На данный момент с помощью механизма машинного обучения мы реализовали еще один проект: автоматическое создание связей документов (пользователи не всегда заполняют связи документов). Робот анализирует тексты документов (файлы word) и, если текст документа содержит ссылки на другие документы 1С: Документооборота, находит и связывает документы.
Предполагаем расширение применения механизмов машинного обучения в будущем. И кто знает, может быть скоро научим искусственный интеллект согласовывать договоры вместо бухгалтеров и юристов и процесс согласованию документов будет занимать несколько минут.
Вступайте в нашу телеграмм-группу Инфостарт