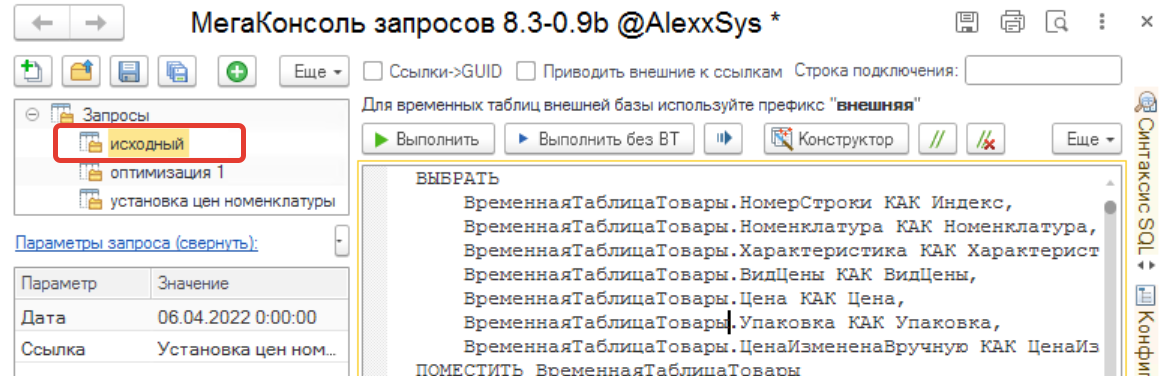
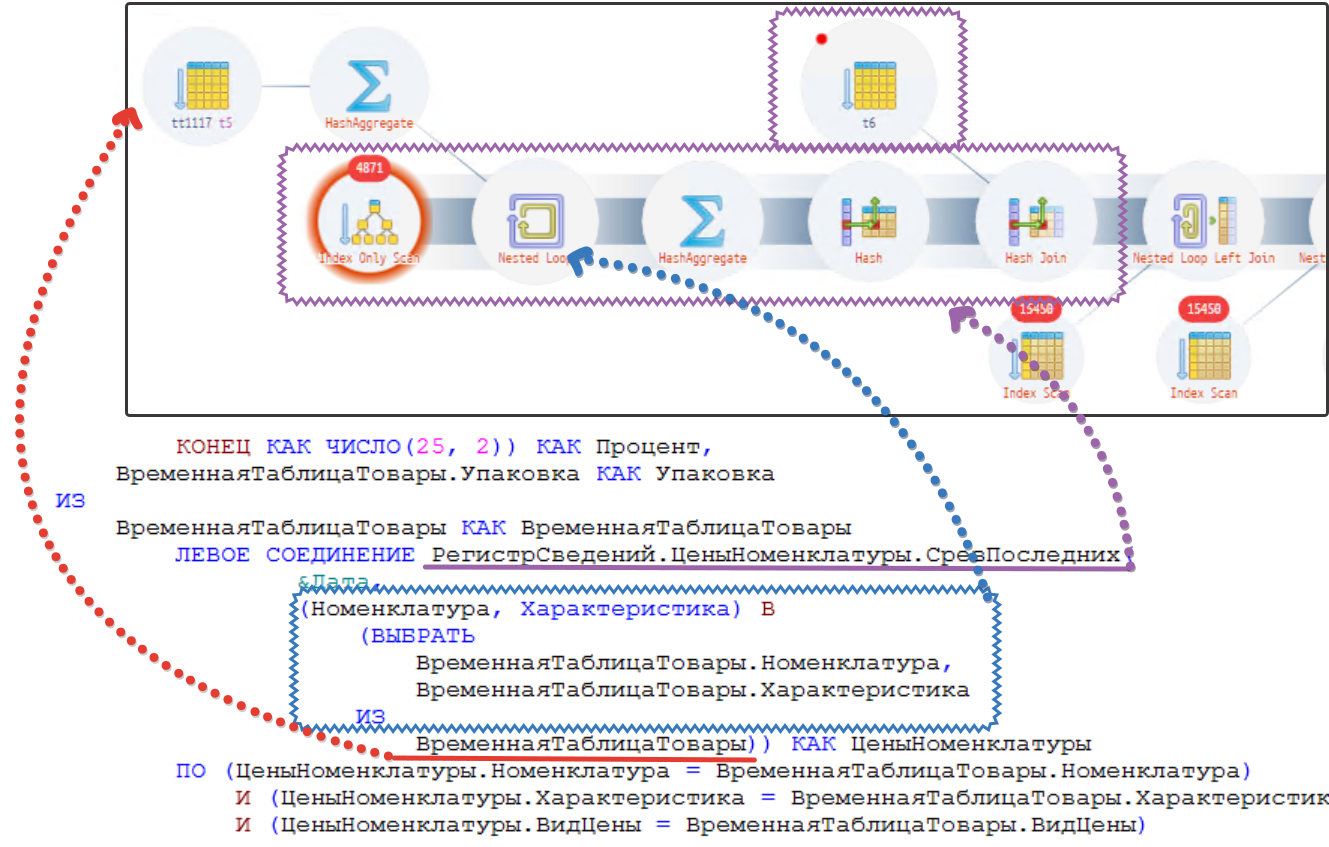
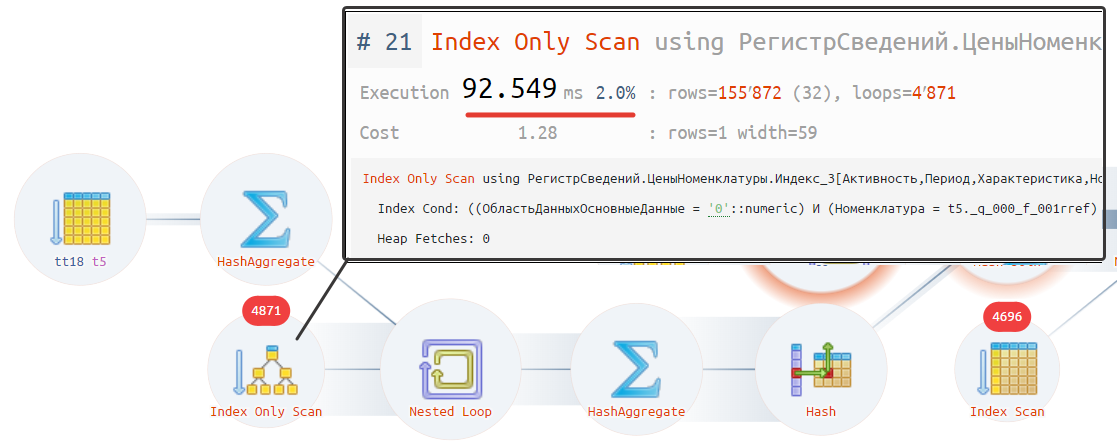
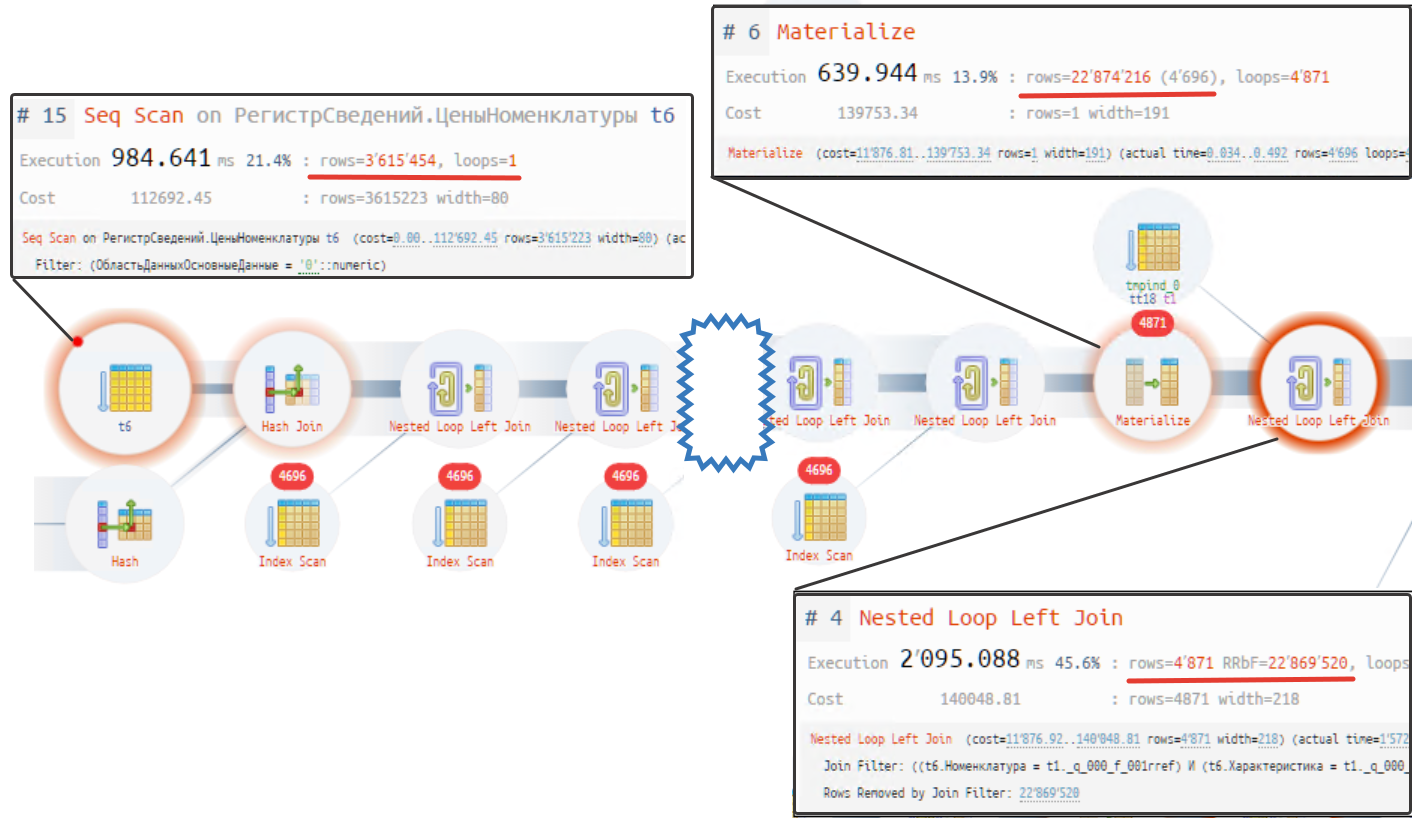
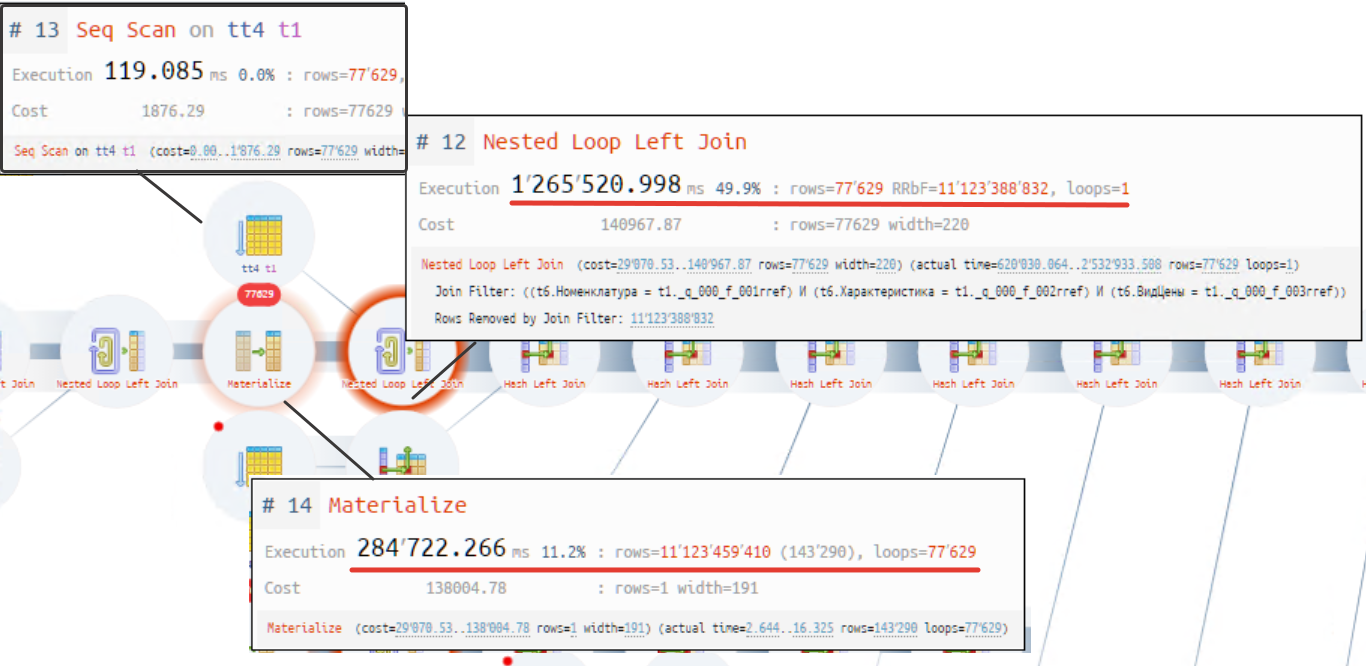
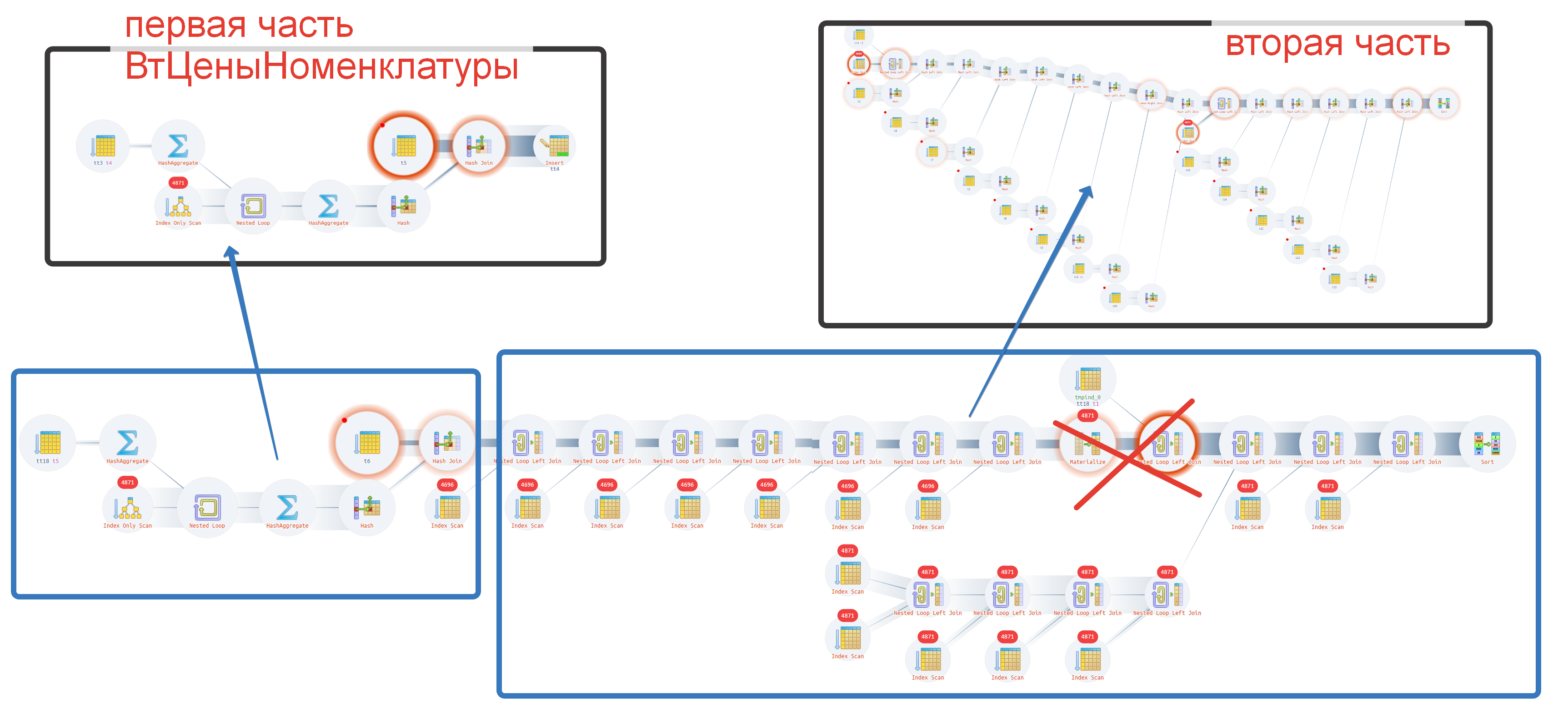
ВЫБРАТЬ
ВременнаяТаблицаТовары.НомерСтроки КАК Индекс,
ВременнаяТаблицаТовары.Номенклатура КАК Номенклатура,
ВременнаяТаблицаТовары.Характеристика КАК Характеристика,
ВременнаяТаблицаТовары.ВидЦены КАК ВидЦены,
ВременнаяТаблицаТовары.Цена КАК Цена,
ВременнаяТаблицаТовары.Упаковка КАК Упаковка,
ВременнаяТаблицаТовары.ЦенаИзмененаВручную КАК ЦенаИзмененаВручную
ПОМЕСТИТЬ ВременнаяТаблицаТовары
ИЗ
Документ.УстановкаЦенНоменклатуры.Товары КАК ВременнаяТаблицаТовары
ГДЕ
ВременнаяТаблицаТовары.Ссылка = &Ссылка
ИНДЕКСИРОВАТЬ ПО
Номенклатура,
Характеристика,
ВидЦены
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
"test_optim_part-1" КАК Ключ,
ЦеныНоменклатуры.Номенклатура КАК Номенклатура,
ЦеныНоменклатуры.ВидЦены КАК ВидЦены,
ЦеныНоменклатуры.Характеристика КАК Характеристика,
ЦеныНоменклатуры.Цена КАК Цена,
ЦеныНоменклатуры.Упаковка КАК Упаковка
ПОМЕСТИТЬ ВтЦеныНоменклатуры
ИЗ
РегистрСведений.ЦеныНоменклатуры.СрезПоследних(
&Дата,
(Номенклатура, Характеристика,ВидЦены) В
(ВЫБРАТЬ
ВременнаяТаблицаТовары.Номенклатура,
ВременнаяТаблицаТовары.Характеристика,
ВременнаяТаблицаТовары.ВидЦены
ИЗ
ВременнаяТаблицаТовары)) КАК ЦеныНоменклатуры
ИНДЕКСИРОВАТЬ ПО
Номенклатура,
Характеристика,
ВидЦены
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
"test_optim_part-2" КАК Ключ,
ВременнаяТаблицаТовары.Индекс КАК Индекс,
ВременнаяТаблицаТовары.Номенклатура КАК Номенклатура,
ВременнаяТаблицаТовары.Характеристика КАК Характеристика,
ВременнаяТаблицаТовары.ВидЦены КАК ВидЦены,
ВременнаяТаблицаТовары.Цена КАК Цена,
ВременнаяТаблицаТовары.ЦенаИзмененаВручную КАК ЦенаИзмененаВручную,
ВЫБОР
КОГДА ВтЦеныНоменклатуры.Упаковка = ВременнаяТаблицаТовары.Упаковка
ТОГДА ВтЦеныНоменклатуры.Цена
ИНАЧЕ ВтЦеныНоменклатуры.Цена / ЕСТЬNULL(ВЫБОР
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Вес)
И ВтЦеныНоменклатуры.Номенклатура.ВесИспользовать
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ВесЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ВесЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ВесЧислитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ВесЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ВесЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ВесЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ВесЧислитель / ВтЦеныНоменклатуры.Номенклатура.ВесЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Объем)
И ВтЦеныНоменклатуры.Номенклатура.ОбъемИспользовать
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ОбъемЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ОбъемЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ОбъемЧислитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ОбъемЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ОбъемЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ОбъемЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ОбъемЧислитель / ВтЦеныНоменклатуры.Номенклатура.ОбъемЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Площадь)
И ВтЦеныНоменклатуры.Номенклатура.ПлощадьИспользовать
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЧислитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ПлощадьЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЧислитель / ВтЦеныНоменклатуры.Номенклатура.ПлощадьЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Длина)
И ВтЦеныНоменклатуры.Номенклатура.ДлинаИспользовать
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ДлинаЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ДлинаЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ДлинаЧислитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ДлинаЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ДлинаЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ДлинаЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ДлинаЧислитель / ВтЦеныНоменклатуры.Номенклатура.ДлинаЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА (ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Мощность)
ИЛИ ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Энергия)
ИЛИ ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.ЭлектрическийЗаряд)
ИЛИ ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Время))
И ВтЦеныНоменклатуры.Номенклатура.ЕдиницаИзмерения.ТипИзмеряемойВеличины = ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
ТОГДА ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель / (ВтЦеныНоменклатуры.Номенклатура.ЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ЕдиницаИзмерения.Знаменатель)
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Упаковка)
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.КоличествоШтук)
ТОГДА 1
ИНАЧЕ NULL
КОНЕЦ, 1) * ЕСТЬNULL(ВЫБОР
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Вес)
И ВременнаяТаблицаТовары.Номенклатура.ВесИспользовать
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ВесЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ВесЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ВесЧислитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ВесЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ВесЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ВесЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ВесЧислитель / ВременнаяТаблицаТовары.Номенклатура.ВесЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Объем)
И ВременнаяТаблицаТовары.Номенклатура.ОбъемИспользовать
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ОбъемЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ОбъемЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ОбъемЧислитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ОбъемЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ОбъемЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ОбъемЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ОбъемЧислитель / ВременнаяТаблицаТовары.Номенклатура.ОбъемЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Площадь)
И ВременнаяТаблицаТовары.Номенклатура.ПлощадьИспользовать
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЧислитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ПлощадьЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЧислитель / ВременнаяТаблицаТовары.Номенклатура.ПлощадьЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Длина)
И ВременнаяТаблицаТовары.Номенклатура.ДлинаИспользовать
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ДлинаЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ДлинаЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ДлинаЧислитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ДлинаЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ДлинаЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ДлинаЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ДлинаЧислитель / ВременнаяТаблицаТовары.Номенклатура.ДлинаЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА (ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Мощность)
ИЛИ ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Энергия)
ИЛИ ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.ЭлектрическийЗаряд)
ИЛИ ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Время))
И ВременнаяТаблицаТовары.Номенклатура.ЕдиницаИзмерения.ТипИзмеряемойВеличины = ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
ТОГДА ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель / (ВременнаяТаблицаТовары.Номенклатура.ЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ЕдиницаИзмерения.Знаменатель)
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Упаковка)
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.КоличествоШтук)
ТОГДА 1
ИНАЧЕ NULL
КОНЕЦ, 1)
КОНЕЦ КАК ДействующаяЦена,
ВЫРАЗИТЬ(ВЫБОР
КОГДА ВтЦеныНоменклатуры.Цена <> 0
ТОГДА 100 * (ВременнаяТаблицаТовары.Цена - ВЫБОР
КОГДА ВтЦеныНоменклатуры.Упаковка = ВременнаяТаблицаТовары.Упаковка
ТОГДА ВтЦеныНоменклатуры.Цена
ИНАЧЕ ВтЦеныНоменклатуры.Цена / ЕСТЬNULL(ВЫБОР
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Вес)
И ВтЦеныНоменклатуры.Номенклатура.ВесИспользовать
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ВесЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ВесЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ВесЧислитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ВесЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ВесЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ВесЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ВесЧислитель / ВтЦеныНоменклатуры.Номенклатура.ВесЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Объем)
И ВтЦеныНоменклатуры.Номенклатура.ОбъемИспользовать
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ОбъемЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ОбъемЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ОбъемЧислитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ОбъемЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ОбъемЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ОбъемЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ОбъемЧислитель / ВтЦеныНоменклатуры.Номенклатура.ОбъемЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Площадь)
И ВтЦеныНоменклатуры.Номенклатура.ПлощадьИспользовать
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЧислитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ПлощадьЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЧислитель / ВтЦеныНоменклатуры.Номенклатура.ПлощадьЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Длина)
И ВтЦеныНоменклатуры.Номенклатура.ДлинаИспользовать
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ДлинаЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ДлинаЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ДлинаЧислитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ДлинаЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ДлинаЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ДлинаЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ДлинаЧислитель / ВтЦеныНоменклатуры.Номенклатура.ДлинаЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА (ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Мощность)
ИЛИ ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Энергия)
ИЛИ ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.ЭлектрическийЗаряд)
ИЛИ ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Время))
И ВтЦеныНоменклатуры.Номенклатура.ЕдиницаИзмерения.ТипИзмеряемойВеличины = ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
ТОГДА ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель / (ВтЦеныНоменклатуры.Номенклатура.ЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ЕдиницаИзмерения.Знаменатель)
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Упаковка)
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.КоличествоШтук)
ТОГДА 1
ИНАЧЕ NULL
КОНЕЦ, 1) * ЕСТЬNULL(ВЫБОР
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Вес)
И ВременнаяТаблицаТовары.Номенклатура.ВесИспользовать
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ВесЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ВесЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ВесЧислитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ВесЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ВесЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ВесЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ВесЧислитель / ВременнаяТаблицаТовары.Номенклатура.ВесЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Объем)
И ВременнаяТаблицаТовары.Номенклатура.ОбъемИспользовать
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ОбъемЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ОбъемЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ОбъемЧислитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ОбъемЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ОбъемЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ОбъемЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ОбъемЧислитель / ВременнаяТаблицаТовары.Номенклатура.ОбъемЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Площадь)
И ВременнаяТаблицаТовары.Номенклатура.ПлощадьИспользовать
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЧислитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ПлощадьЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЧислитель / ВременнаяТаблицаТовары.Номенклатура.ПлощадьЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Длина)
И ВременнаяТаблицаТовары.Номенклатура.ДлинаИспользовать
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ДлинаЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ДлинаЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ДлинаЧислитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ДлинаЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ДлинаЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ДлинаЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ДлинаЧислитель / ВременнаяТаблицаТовары.Номенклатура.ДлинаЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА (ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Мощность)
ИЛИ ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Энергия)
ИЛИ ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.ЭлектрическийЗаряд)
ИЛИ ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Время))
И ВременнаяТаблицаТовары.Номенклатура.ЕдиницаИзмерения.ТипИзмеряемойВеличины = ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
ТОГДА ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель / (ВременнаяТаблицаТовары.Номенклатура.ЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ЕдиницаИзмерения.Знаменатель)
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Упаковка)
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.КоличествоШтук)
ТОГДА 1
ИНАЧЕ NULL
КОНЕЦ, 1)
КОНЕЦ) / ВЫБОР
КОГДА ВтЦеныНоменклатуры.Упаковка = ВременнаяТаблицаТовары.Упаковка
ТОГДА ВтЦеныНоменклатуры.Цена
ИНАЧЕ ВтЦеныНоменклатуры.Цена / ЕСТЬNULL(ВЫБОР
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Вес)
И ВтЦеныНоменклатуры.Номенклатура.ВесИспользовать
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ВесЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ВесЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ВесЧислитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ВесЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ВесЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ВесЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ВесЧислитель / ВтЦеныНоменклатуры.Номенклатура.ВесЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Объем)
И ВтЦеныНоменклатуры.Номенклатура.ОбъемИспользовать
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ОбъемЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ОбъемЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ОбъемЧислитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ОбъемЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ОбъемЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ОбъемЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ОбъемЧислитель / ВтЦеныНоменклатуры.Номенклатура.ОбъемЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Площадь)
И ВтЦеныНоменклатуры.Номенклатура.ПлощадьИспользовать
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЧислитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ПлощадьЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ПлощадьЧислитель / ВтЦеныНоменклатуры.Номенклатура.ПлощадьЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Длина)
И ВтЦеныНоменклатуры.Номенклатура.ДлинаИспользовать
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ДлинаЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ДлинаЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ДлинаЧислитель, 0) <> 0
И ЕСТЬNULL(ВтЦеныНоменклатуры.Номенклатура.ДлинаЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ДлинаЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ДлинаЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Номенклатура.ДлинаЧислитель / ВтЦеныНоменклатуры.Номенклатура.ДлинаЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА (ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Мощность)
ИЛИ ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Энергия)
ИЛИ ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.ЭлектрическийЗаряд)
ИЛИ ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Время))
И ВтЦеныНоменклатуры.Номенклатура.ЕдиницаИзмерения.ТипИзмеряемойВеличины = ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
ТОГДА ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель / (ВтЦеныНоменклатуры.Номенклатура.ЕдиницаИзмерения.Числитель / ВтЦеныНоменклатуры.Номенклатура.ЕдиницаИзмерения.Знаменатель)
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Упаковка)
И ЕСТЬNULL(ВтЦеныНоменклатуры.Упаковка.Знаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ(ВтЦеныНоменклатуры.Упаковка.Числитель / ВтЦеныНоменклатуры.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))
КОГДА ВтЦеныНоменклатуры.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.КоличествоШтук)
ТОГДА 1
ИНАЧЕ NULL
КОНЕЦ, 1) * ЕСТЬNULL(ВЫБОР
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Вес)
И ВременнаяТаблицаТовары.Номенклатура.ВесИспользовать
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ВесЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ВесЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ВесЧислитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ВесЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ВесЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ВесЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ВесЧислитель / ВременнаяТаблицаТовары.Номенклатура.ВесЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Объем)
И ВременнаяТаблицаТовары.Номенклатура.ОбъемИспользовать
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ОбъемЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ОбъемЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ОбъемЧислитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ОбъемЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ОбъемЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ОбъемЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ОбъемЧислитель / ВременнаяТаблицаТовары.Номенклатура.ОбъемЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Площадь)
И ВременнаяТаблицаТовары.Номенклатура.ПлощадьИспользовать
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЧислитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ПлощадьЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ПлощадьЧислитель / ВременнаяТаблицаТовары.Номенклатура.ПлощадьЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Длина)
И ВременнаяТаблицаТовары.Номенклатура.ДлинаИспользовать
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ДлинаЕдиницаИзмерения.Числитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ДлинаЕдиницаИзмерения.Знаменатель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ДлинаЧислитель, 0) <> 0
И ЕСТЬNULL(ВременнаяТаблицаТовары.Номенклатура.ДлинаЗнаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ((ВЫРАЗИТЬ((ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ДлинаЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ДлинаЕдиницаИзмерения.Знаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))) / (ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Номенклатура.ДлинаЧислитель / ВременнаяТаблицаТовары.Номенклатура.ДлинаЗнаменатель КАК ЧИСЛО(15, 7))) КАК ЧИСЛО(15, 7))
КОГДА (ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Мощность)
ИЛИ ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Энергия)
ИЛИ ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.ЭлектрическийЗаряд)
ИЛИ ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Время))
И ВременнаяТаблицаТовары.Номенклатура.ЕдиницаИзмерения.ТипИзмеряемойВеличины = ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
ТОГДА ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель / (ВременнаяТаблицаТовары.Номенклатура.ЕдиницаИзмерения.Числитель / ВременнаяТаблицаТовары.Номенклатура.ЕдиницаИзмерения.Знаменатель)
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.Упаковка)
И ЕСТЬNULL(ВременнаяТаблицаТовары.Упаковка.Знаменатель, 0) <> 0
ТОГДА ВЫРАЗИТЬ(ВременнаяТаблицаТовары.Упаковка.Числитель / ВременнаяТаблицаТовары.Упаковка.Знаменатель КАК ЧИСЛО(15, 7))
КОГДА ВременнаяТаблицаТовары.Упаковка.ТипИзмеряемойВеличины = ЗНАЧЕНИЕ(Перечисление.ТипыИзмеряемыхВеличин.КоличествоШтук)
ТОГДА 1
ИНАЧЕ NULL
КОНЕЦ, 1)
КОНЕЦ
ИНАЧЕ 0
КОНЕЦ КАК ЧИСЛО(25, 2)) КАК Процент,
ВременнаяТаблицаТовары.Упаковка КАК Упаковка
ИЗ
ВременнаяТаблицаТовары КАК ВременнаяТаблицаТовары
ЛЕВОЕ СОЕДИНЕНИЕ ВтЦеныНоменклатуры КАК ВтЦеныНоменклатуры
ПО (ВтЦеныНоменклатуры.Номенклатура = ВременнаяТаблицаТовары.Номенклатура)
И (ВтЦеныНоменклатуры.Характеристика = ВременнаяТаблицаТовары.Характеристика)
И (ВтЦеныНоменклатуры.ВидЦены = ВременнаяТаблицаТовары.ВидЦены)
УПОРЯДОЧИТЬ ПО
Индекс