Перейти сразу к коду
Предисловие...
Совсем недавно была поставлена задача: нужно периодически скачивать и читать файл поставщика товара, и брать из него цены и остатки, для записи в 1С. Задача как бы тривиальная: берешь построчно из файла текст и разбиваешь его на подстроки по разделителю, хотя бы той же функциейСтрРазделить(СтрокаТекст,Разделитель) .
Но при первом же взоре на файл, немного был ошарашен. Потому что никогда не видел, чтобы в CSV записывали описание номенклатуры прямо как на сайте. То есть, в одном из полей данного файла CSV содержалась строка, которая включает в себе и разделители, и кавычки, и переносы строк.
К слову сказать, сам файл содержал в себе 350 000 строк, которые впоследствии конвертируются в 32 000 строк данных. То есть на одну строку данных приходится где-то по 10 переводов строк в этом поле с описанием товара.
Примерный текст в файле и данные в виде таблицы
ARTIKUL; SKLAD; XARAKT; PRICE; OST 123331;"СВХ ""Северный""";"Пила цепная бензиновая Длина шины: 4""; Шаг цепи: 1/4""; Степень защиты: IP20; --------- отличное решение для Вас"; 1000,42;120 QW8 995;Южный склад;"Пила цепная электрическая Длина шины: 4""; Шаг цепи: 1/4""; Мощность : 40WT; @bk.com";500,99;22
|
ARTIKUL |
SKLAD |
XARAKT |
PRICE |
OST |
|---|---|---|---|---|
| 123331 | СВХ "Северный" | Пила цепная бензиновая Длина шины: 4"; Шаг цепи: 1/4"; Степень защиты: IP20; --------- отличное решение для Вас |
1000,42 | 120 |
| QW8 995 | Южный склад | Пила цепная электрическая Длина шины: 4"; Шаг цепи: 1/4"; Мощность : 40WT; @bk.com |
500,99 | 22 |
Для быстрого решения проблемы, поиск дал только решения с подключением с ADODB:
Основная публикация, которую чаще всего выдавал поиск на Инфостарт: Чтение CSV (быстрое).
У этого же автора нашел другую публикацию, где он решил проблему многострочных полей CSV, с написанием процедуры, в которой используются только встроенные средства 1С: 7 правил RFC 4180. Если честно, чтение кода для меня было не совсем понятным, и я попытался подойти к проблеме с другой стороны. Очень сильно помогли расписанные правила, в этой статье.
1. Читаем посимвольно.
Первая идея это было читать текст посимвольно, и следить открыта ли экранирующая кавычка, или же закрыта.
То есть если в тексте попадается кавычка, ставим флаг ЭтоЭкран, и все символы до следующей кавычки считаем символами одного поля CSV. Если снова попадается кавычка, то убираем флаг ЭтоЭкран, и обрабатываем последующий текст как данные CSV, смотрим на разделители и переносы строк. Единственный вариант, это если за кавычкой идет снова кавычка, тогда ЭтоЭкран не убирается, и продолжается чтение в одно поле.
Сразу скажу, что такой метод, возможно и точный, но оставляет желать лучшего по быстродействию. Когда текст обрабатывался уже минуту, я оставил развивать эту идею на корню. На всякий случай приведу код, хотя понимаю что он сырой:
2. Метод четности кавычек
В последующем поиске решения, и благодаря описанию правил формата CSV, мне пришла идея, что мы можем через четность кавычек в тексте, определять, это полная строка данных CSV или же нужно добавить следующую строку текста.
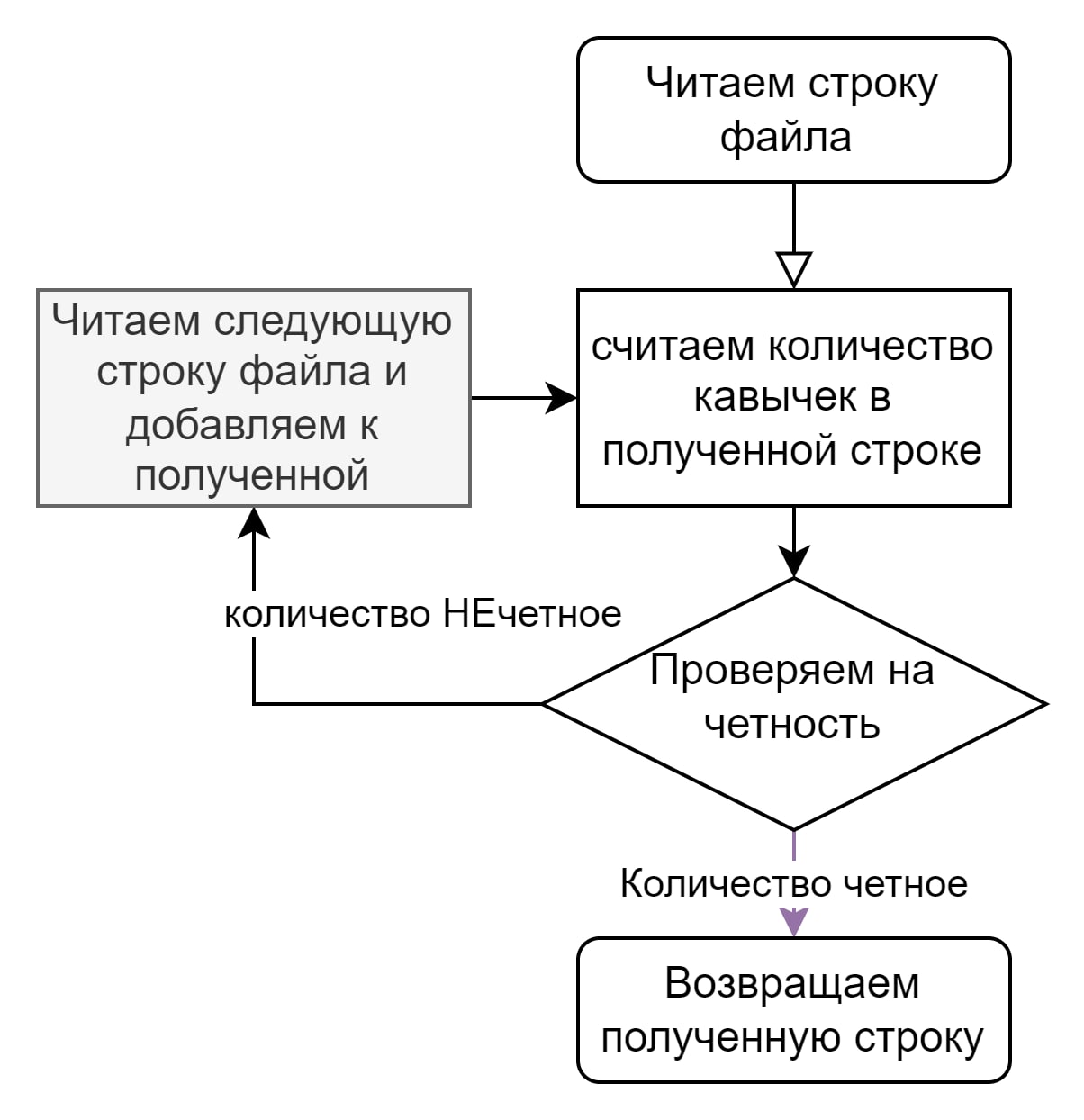 На примере из текста выше:
На примере из текста выше:
Читаем первую строку ARTIKUL; SKLAD; XARAKT; PRICE; OST - кавычки отсутствуют, значит их количество четное, значит можно уже эту строку разбивать по разделителю
2 строка - 123331;"СВХ ""Северный""";"Пила цепная бензиновая - 7 кавычек , количество нечетное: к этой строке нужно добавить следующую, пока не придем к четному количеству кавычек.
...
читаем 7 строку и добавляем к предыдущему тексту поля. Здесь уже получаем 12 кавычек и считаем что получившая строка и есть строка данных CSV
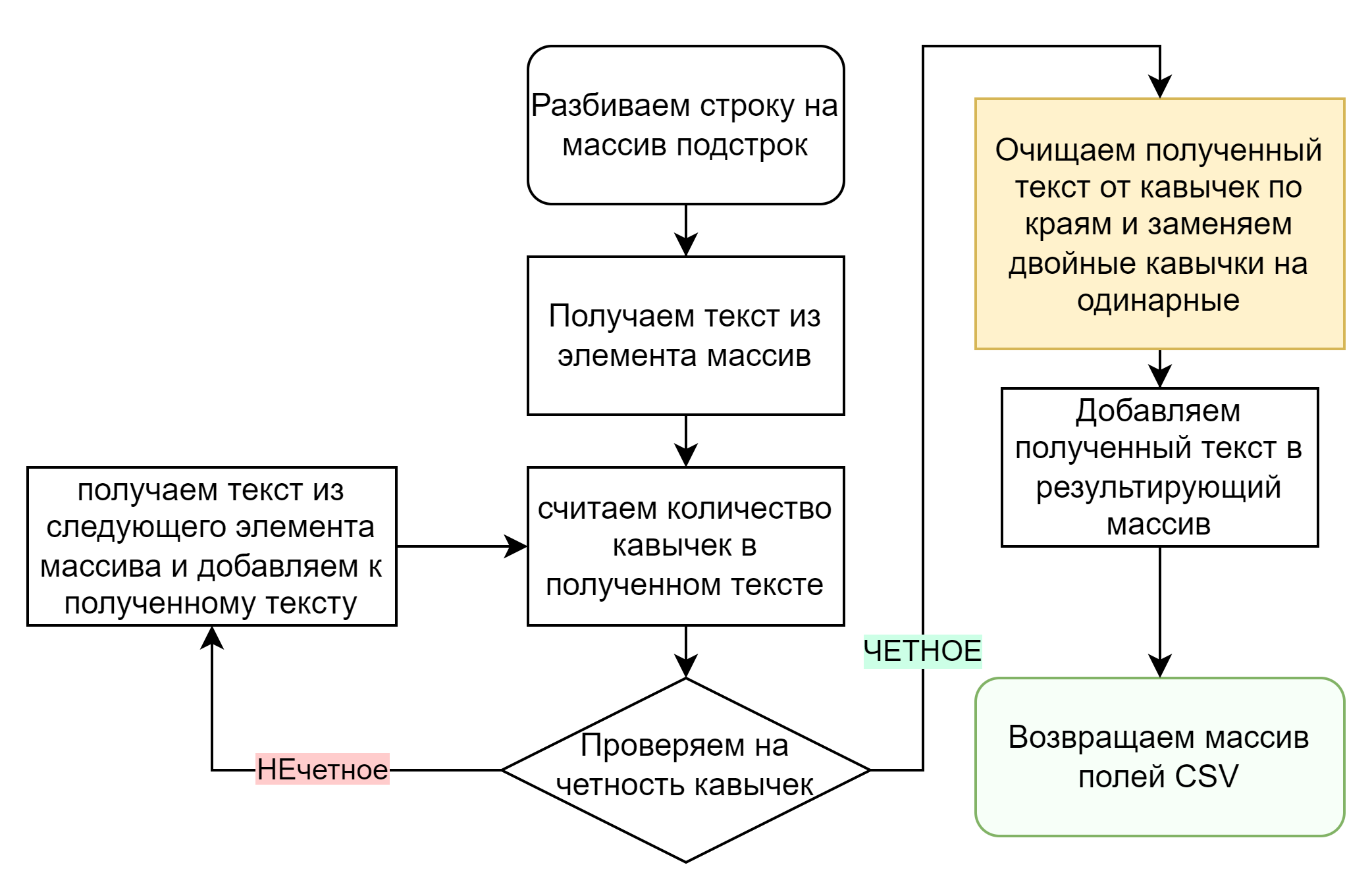 Возникает вопрос: а как разбить получившуюся строку данных по разделителям, ведь внутри могут содержаться собственно символы разделителя, означающие сами себя? Ну и хотелось бы очистить текст поля от лишних кавычек, двойных и экранирующих.
Возникает вопрос: а как разбить получившуюся строку данных по разделителям, ведь внутри могут содержаться собственно символы разделителя, означающие сами себя? Ну и хотелось бы очистить текст поля от лишних кавычек, двойных и экранирующих.
Здесь так же воспользуемся этим же методом: разделим текст строки по разделителю и будем перебирать элементы получившегося массива. Будем считать что поле не полное, если в нем нечетное количество кавычек.
Не полное поле дополняем следующим элемента массив, добавляя разделитель между элементами.
Итоговая функция
Для увеличение быстродействия эти функции лучше объединить в одну. Если в строке файла не будет кавычек вообще, то не имеет смысла проверять дополнительно проверять получившийся массив полей
В итоге получилась понятная функция, которая удовлетворяет по скорости быстродействия и использует только внутренние средства языка 1С. Файл с 350 000 строками парсится за 5-10 секунд. В режиме отладки правда почему то показывало 30 сек, что тоже устраивает заказчика.
Функция CSV_Reader(ЧтениеТекста,Разделитель = ";")
СтрокаТекста = ЧтениеТекста.ПрочитатьСтроку();
Если СтрокаТекста = Неопределено Тогда
Возврат Неопределено;
КонецЕсли;
КолКавычек = СтрЧислоВхождений(СтрокаТекста,"""");
Если КолКавычек%2 Тогда
МассивСложения = Новый Массив;
МассивСложения.Добавить(СтрокаТекста);
Пока КолКавычек%2 Цикл
СтрокаТекста = ЧтениеТекста.ПрочитатьСтроку();
КолКавычек = КолКавычек + СтрЧислоВхождений(СтрокаТекста,"""");
МассивСложения.Добавить(СтрокаТекста);
КонецЦикла;
СтрокаТекста = СтрСоединить(МассивСложения,Символы.ПС);
КонецЕсли;
Если КолКавычек = 0 Тогда
Возврат СтрРазделить(СтрокаТекста,Разделитель,Истина);
КонецЕсли;
МассивПодстрок = СтрРазделить(СтрокаТекста,Разделитель,Истина);
МассивЯчеек = Новый Массив;
Сч = 0; КоличествоЭл = МассивПодстрок.Количество();
Пока Сч <КоличествоЭл Цикл
Подстрока = МассивПодстрок[Сч];
КолКавычек = СтрЧислоВхождений(Подстрока,"""");
Если КолКавычек%2 Тогда
МассивСложения = Новый Массив;
МассивСложения.Добавить(Подстрока);
Пока КолКавычек%2 Цикл
Сч =Сч +1;
Подстрока = МассивПодстрок[Сч];
КолКавычек = КолКавычек + СтрЧислоВхождений(Подстрока,"""");
МассивСложения.Добавить(Подстрока);
КонецЦикла;
Подстрока = СтрСоединить(МассивСложения,Разделитель);
КонецЕсли;
Если КолКавычек <> 0 Тогда
Подстрока = Сред(Подстрока,2,СтрДлина(Подстрока)-2);
Подстрока = СтрЗаменить(Подстрока,"""""","""");
КонецЕсли;
МассивЯчеек.Добавить(Подстрока);
Сч =Сч +1;
КонецЦикла;
Возврат МассивЯчеек;
КонецФункции
Использование данной функции для получения таблицы значений с данными файла CSV.
Функция ПолучитьТаблицуДанныхЧерезREADeR(ИмяФайла_CSV,Разделитель = ";",ПерваяСтрокаСодержитЗаголовки = Истина)
ТаблицаЗначений = Новый ТаблицаЗначений;
ЧтениеТекста = Новый ЧтениеТекста(ИмяФайла_CSV,"UTF-8");
//Замер производительности
Старт = ТекущаяУниверсальнаяДатаВМиллисекундах();
//}}
МассивПолейCSV = CSV_Reader(ЧтениеТекста);
Если МассивПолейCSV = Неопределено Тогда
Возврат ТаблицаЗначений;
КонецЕсли;
// Устанавливаем колонки ТаблицыЗначений
Если ПерваяСтрокаСодержитЗаголовки Тогда
Для Каждого ПолеCSV Из МассивПолейCSV Цикл
ТаблицаЗначений.Колонки.Добавить(ПолеCSV);
КонецЦикла;
МассивПолейCSV = CSV_Reader(ЧтениеТекста);// Читаем вторую строку
Иначе
Для Каждого ПолеCSV Из МассивПолейCSV Цикл
ИндексКолонки = ТаблицаЗначений.Колонки.Количество();
ТаблицаЗначений.Колонки.Добавить("Колонка_" + Формат(ИндексКолонки,"ЧН=; ЧГ="));
КонецЦикла;
КонецЕсли;
КоличествоКолонокТЗ = ТаблицаЗначений.Колонки.Количество();
Пока МассивПолейCSV <> Неопределено Цикл
СтрокаТЗ = ТаблицаЗначений.Добавить();
ИндексКолонки = 0;
Для Каждого ПолеCSV Из МассивПолейCSV Цикл
Если ИндексКолонки = КоличествоКолонокТЗ Тогда
ТаблицаЗначений.Колонки.Добавить("Колонка_" + Формат(ИндексКолонки,"ЧН=; ЧГ="));
КоличествоКолонокТЗ = КоличествоКолонокТЗ +1;
КонецЕсли;
СтрокаТЗ[ИндексКолонки] = ПолеCSV;
ИндексКолонки = ИндексКолонки +1;
КонецЦикла;
МассивПолейCSV = CSV_Reader(ЧтениеТекста);
КонецЦикла;
//Замер производительности{{
финиш = ТекущаяУниверсальнаяДатаВМиллисекундах();
КоличествоСтрок = ТаблицаЗначений.Количество();
Сообщить(СтрШаблон("Потрачено: %1 сек, количество строк: %2",(финиш - Старт)/1000, КоличествоСтрок));
//}}
Возврат ТаблицаЗначений;
КонецФункции
И, конечно же, остается открытым вопрос с преобразованием типов данных, потому что все читается как текст. Но, думаю, этот вопрос читатель решит указанием настроек колонок ТЗ.
Также думаю, что если прочитать весь текст файла в переменную, можно немного ускорить обработку, но это увеличит объем использованной оперативной памяти.
Интересная заметка при тестировании: конкатенация строк работает намного медленнее, чем функцияСтрСоединить(МассивПодстрок,Разделитель)
Вступайте в нашу телеграмм-группу Инфостарт