Меня зовут Дмитрий Макаревич, я представляю компанию «Содружество-Инфо».
Многие компании для интеграции 1С-систем используют концепцию EDA (Event-Driven Architecture) и брокеры сообщений (Kafka или RabbitMQ). Но есть не так много информации о том, как это сделано. Именно этим я и хочу с вами поделиться.

Вначале скажу пару слов о компании, где все это происходило.
Нашим плацдармом для опытов стала группа компаний «Содружество», куда входит компания «Содружество-Инфо» – один из крупнейших переработчиков семян масличных культур в Европе и в мире. Годовой оборот компании – 200 миллиардов.
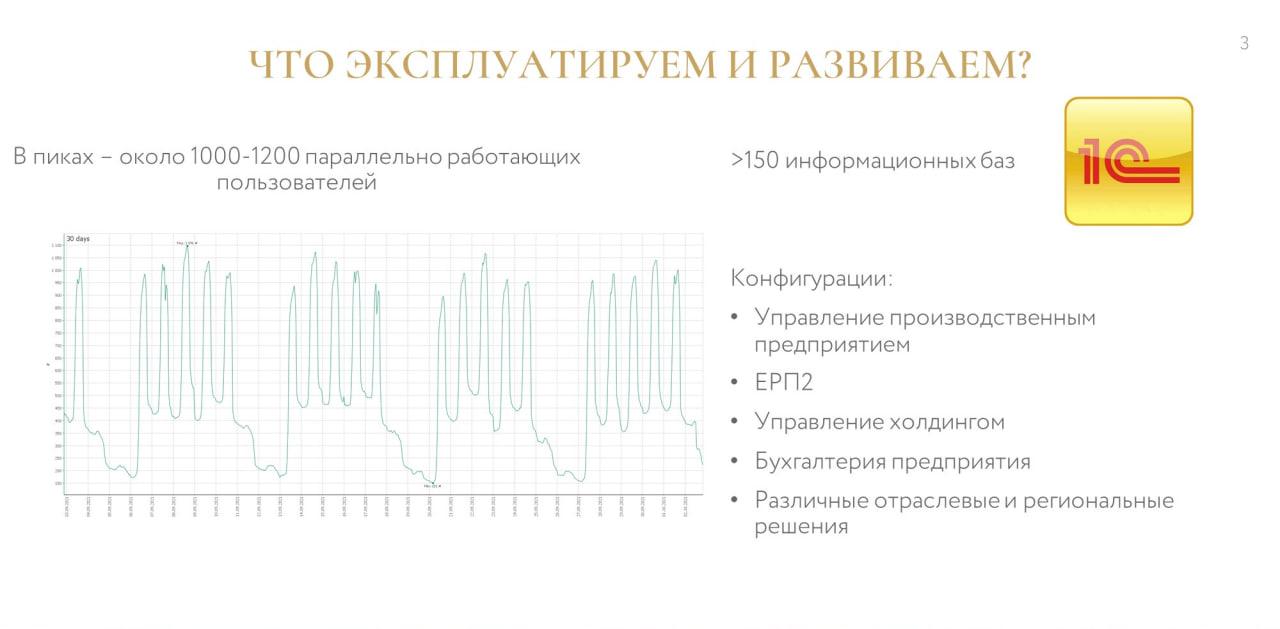
Компания большая, тем не менее, у нас нет highload: в среднем по всем базам у нас ежедневно работают 1000-1200 пользователей.
Хотя самих информационных баз у нас много – больше 150:
-
В основном, это мелкие базы: «Бухгалтерии», региональные «Зарплаты» и различные сервисные базы.
-
И есть несколько крупных баз: «Управление холдингом», «Управление производственным предприятием», а также сейчас идет переход на ERP2.
Все это нужно как-то дружить между собой.

До внедрения нового механизма мы использовали для интеграции:
-
«Конвертацию данных 2.1» и механизм планов обмена;
-
во многих конфигурациях использовались самописные обмены на XML;
-
в редких случаях для обмена использовался JSON – то, что было реализовано еще без БСП;
-
и были обмены на текстовых файлах в своих форматах.
В качестве транспорта мы использовали:
-
веб-сервисы, HTTP-сервисы по протоколу HTTPS;
-
COM-соединение;
-
обмен через файлы.
На заре перехода на ERP2 мы поняли, что это все неуправляемо и медленно. Что нам нужно что-то более быстрое.
И еще немаловажно, что нам очень хотелось это как-то унифицировать – управлять таким зоопарком форматов было очень трудно.
Событийный обмен через RabbitMQ и Enterprise Data

Пару слов о том, почему в качестве связующего ПО мы выбрали RabbitMQ.
Я очень боюсь, что однажды проснусь с утра и увижу письмо в почтовом ящике или сообщение в мессенджере о том, что мне нужно изучить три новых языка программирования, пять или шесть новых СУБД и т.д.
В этом плане RabbitMQ и AMQP-протокол – это проверенное долгосрочное решение, которое завтра не умрет. Многие вендоры, такие, как Facebook, Instagram, Amazon, используют такой обмен – по сути, это был основной довод для наших стейкхолдеров.
Более того, по RabbitMQ есть практики – это тоже был немаловажный выбор.

В качестве основного связующего формата мы выбрали Enterprise Data. Почему именно Enterprise Data?
-
Во-первых, это формат от вендора, фирмы «1С». Этот формат поддерживается, причем срок поддержки достаточно длительный.
-
С помощью этого формата удобно описывать бизнес-объекты.
-
Немаловажно, что большинство конфигураций содержит готовые правила обмена, в которые всегда можно подсмотреть и что-то себе заимствовать. Это касается как обновлений, так и поставки.
-
«Конвертация данных 3» представляет собой удобный менеджер, который управляет правилами и автоматизирует генерацию кода общего модуля для обмена.
-
На слайде указан еще один, немного смелый, пункт – нам казалось, что с помощью Enterprise Data все можно унифицировать. Правда, потом оказалось, что это не так – я к этому еще вернусь позже.
-
Также на выбор повлияло то, что на Инфостарте уже были ребята, которые сделали подобный механизм – я прочитал об этом статью и понял, что двигаюсь в правильном направлении.

В итоге мы собрали свой «велосипед». Одной из причин этого стало то, что у нас был ограничен бюджет. Плюс некоторые готовые Enterprise-решения нам просто не подходили по логике – они не давали того, чего мы хотели.
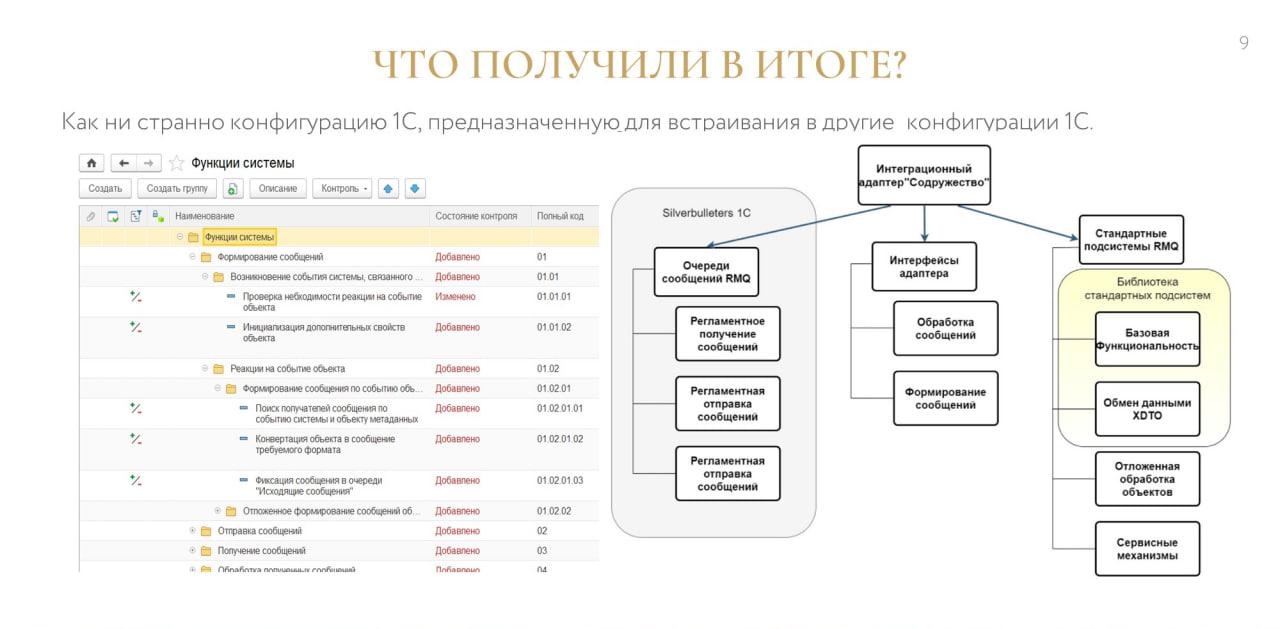
Поэтому мы купили компоненту Yellow RabbitMQ от «Серебряной пули» и решили разработать свое решение – конфигурацию 1С для встраивания в другие конфигурации 1С.
Срок запуска продукта в продуктив составил недели три. Прототип я подготовил за три дня, через неделю он уже работал, и потом мы что-то отлаживали.
Но в целом на запуск решения ушло полгода, потому что только через полгода мы получили продукт, который не заставлял нас плакать и условно стабильно работал.
Архитектурно в упрощенном виде его можно разбить на три части:
-
часть «Серебряной пули» – мы не меняли то, что приобрели;
-
часть наших интерфейсов;
-
и часть стандартных подсистем RMQ – я их так назвал. По факту, там под капотом лежат стандартные подсистемы БСП, которые нужны для механики обмена в «Конвертации данных 3.0».

Мы получили продукт, который:
-
разрабатывается в EDT;
-
распространяется с помощью стандартного механизма поставки 1С;
-
архитектурно ведется в СППР;
-
технический долг мы контролируем с помощью плагина «Серебряной пули» и платформы SonarQube;
-
активно тестируем этот продукт с помощью Vanessa ADD.
Причем продукт позволяет использовать не только формат Enterprise Data и БСП-шный обмен данными через XDTO, но позволяет подключать к себе любые другие модули, реализующие определенный интерфейс.
Полгода хождения по граблям. Как это было

Я рассказал о контексте появления нашего механизма обмена. И тут мы, наконец, подобрались к основной теме моего доклада – к тому, на что мы напоролись в процессе становления продукта.
Мне показалось, что будет удобно рассказать о проблемах именно в разрезе кейсов, чтобы было понятно, почему мы приняли то или иное решение.
Грабли №1. Множественное изменение объектов за небольшой промежуток времени

Первый кейс – это управление НСИ.
Думаю, что 90% тех, кто использует в 1С брокер сообщений RabbitMQ, используют его ради организации мастер-базы НСИ, потому что RabbitMQ для этого идеально подходит.
С какой проблемой мы столкнулись?
-
При множественных изменениях любой объектной сущности за небольшой промежуток времени могло получиться так, что подписчик при обработке сообщений фиксировал не последнее состояние объекта.
-
В связи с этим возникала и вторая проблема – при одномоментной обработке множества сообщений, связанных с одним объектом, обработка части сообщений завершалась с ошибкой, содержащей какой-то контекст SQL.
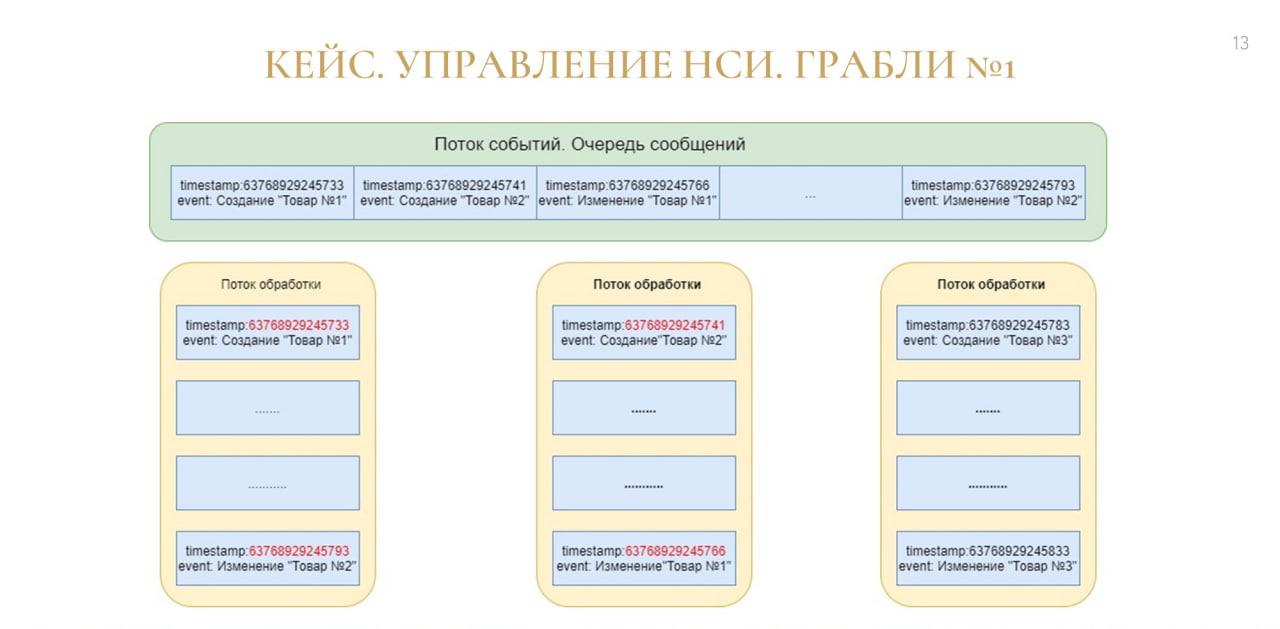
Чуть подробнее о том, что происходило.
Наш адаптер по определенному регламентному заданию засасывает в себя сообщения и выстраивает очередь обработки сообщений по своей определенной логике – он выбирает определенную порцию сообщений, бьет ее на определенные потоки и грузит параллельно.
Проблема была в том, что в этой многопоточной загрузке мы не учли исходную логику самой 1С – из-за этого один и тот же объект мог одновременно грузиться в нескольких потоках.
И получалось, что какое состояние раньше запишется, такое и фиксировалось в базе данных.
Ошибка SQL (попытка вставки дублирующегося ключа в уникальный индекс), которая происходила при этом – это еще не худшее, что могло произойти. Гораздо хуже было, когда ошибки не было, и пользователь просто получал не то, что хотел.

Как мы это вылечили?
Протокол AMQP для каждого сообщения предоставляет свою структуру – properties.
В ней есть еще одна вложенная структура – это headers, заголовки, куда уже можно добавлять нетиповые расширяемые свойства.
В заголовок каждого сообщения мы добавили новое свойство «Ключ объекта», которое представляло собой хэш MD5 от ссылки и имени объекта.
И переделали механику так, чтобы все сообщения порции, которые относятся к одному объекту, были в одном потоке. Всего потоков может быть 5-6, но то, что относится к одному объекту, будет обрабатываться в одном потоке строго последовательно, чтобы не нарушить событийную логику.
Это касается не только однотипных объектов, но и взаимосвязанных сущностей – например, при заведении нового договора и контрагента тоже недопустима их обработка в разных потоках, это может вызвать накладки.

При этом автоматически была устранена ошибка, связанная со SQL-контекстом, про которую я говорил.
Дело в том, что в процессе гонки за многопоточностью мы забыли, что у нас под капотом – БСП-шный модуль «ОбменДаннымиXDTO», который использует определенную логику: там объект создается по ключевым свойствам, а потом для него подгружаются все остальные данные. Причем, если эти данные не подгрузились, то объект будет удален – в общем, там много всего интересного.
И именно «Ключ объекта» помог нам все это разрулить – тем самым мы эту «граблю» автоматически закрыли.
Грабли №2. Массовое изменение объектов

Второй кейс тоже был связан с управлением НСИ, но, в отличие от первого, касался не множественного изменения одного объекта, а потребности в массовом изменении объектов. Такая потребность часто возникает у служб НСИ, когда им нужно массово заполнить какой-то реквизит, либо просто что-то массово перевыгрузить.
Изначально инструмент массовой обработки объектов у нас предусмотрен не был. И проблемы, обозначенные на слайде, больше относятся к тому, что нам просто пришлось срочно что-то дорабатывать в нашей системе.
Что нужно было учесть при массовой обработке:
-
Во-первых, сообщения нужно формировать не всегда, нужно их правильно выделять. В Event-Driven Architecture не каждое изменение объекта должно приводить к обмену данными. Нужно четко понимать, что конкретно является событием в том или ином бизнес-кейсе.
-
Второе – правила обмена в потребителе могут содержать ошибку. Это нужно учитывать.
-
Третье – правила обмена в издателе могут содержать ошибку, и в некоторых случаях может потребоваться перевыгрузить данные. Это тоже нужно учитывать.
-
И четвертая проблема – при массовой обработке сообщений база данных-потребитель сильно просаживалась по производительности.
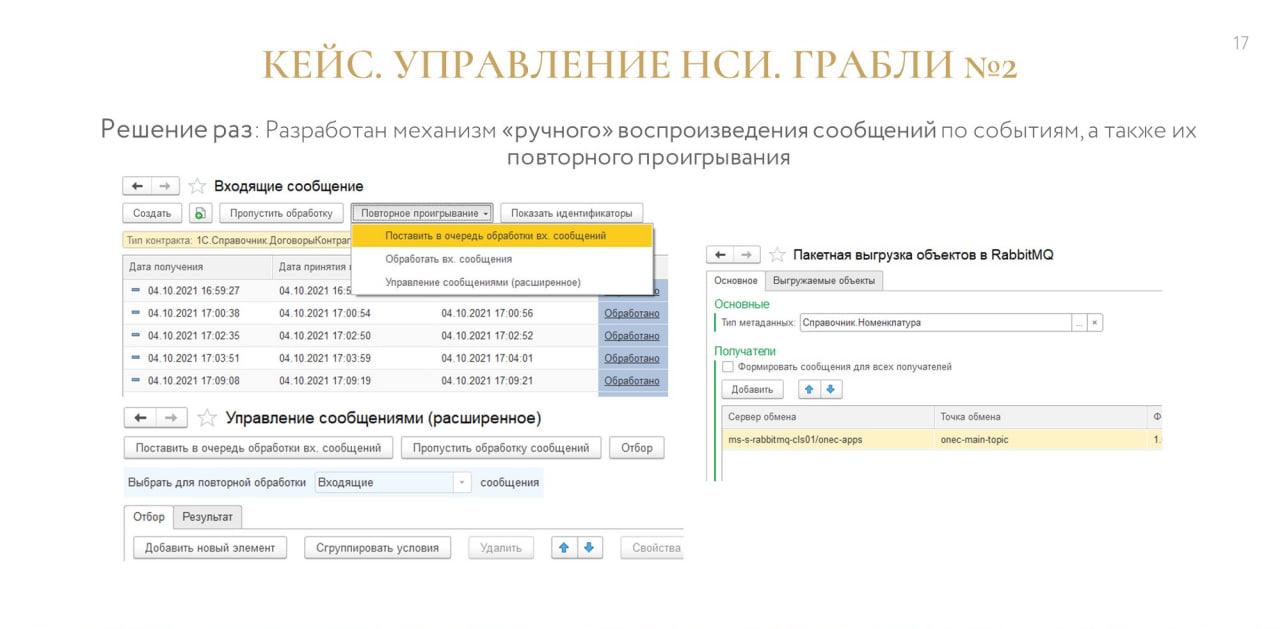
Решение раз. Первые три пункта мы закрыли тем, что разработали свой механизм, который позволял повторно проигрывать полученные сообщения, а также повторно воспроизводить сообщения в издателе.
Для этого тем же НСИ-шникам не требовалось вызывать групповую обработку и перезаписывать 10 тысяч элементов – все это с гибкими отборами настраивалось и аккуратно воспроизводилось.

Решение два. Оказалось, что система у нас простаивала на блокировках.
На эту тему на конференции Инфостарта в 2019 году был интересный доклад от Софтпойнта. Я с ним ознакомился и очень быстро нашел проблему.
Оказалось, что в момент, когда происходила массовая загрузка однотипных объектов, оптимизатор какого-либо запроса решал обновить статистику – у нас было включено асинхронное обновление. Соответственно, пользователи, которые формировали отчет с этими объектами, просто ждали, пока эта статистика асинхронно сформируется.
Эту проблему мы решили тем, что отключили автообновление и стали более внимательно следить за этим на уровне базы данных.
Грабли №3. Переход с УПП на ERP2

Наш следующий кейс – это переход с УПП на ERP2. Именно ради него мы и начали внедрять механизмы обмена.
Те, кто занимается внедрением, понимают, что одним махом перевести большую систему на новое ПО трудно. Поэтому мы использовали поэтапный переход, когда сначала переносится некий контур, в нем моделируются бизнес-процессы, потом продукт дорабатывается и дальше происходит реальное внедрение.
В то же время УПП 1.2 – это наша основная учетная система, в ней у нас отчетность МСФО и много всего другого. А бизнесу-то все равно, что у него там – ERP2 или УПП. Ему главное, чтобы это давало результат, и чтобы работа в системе не останавливалась.
Для таких случаев обычно делается двойной ввод – учет ведется одновременно в двух базах. Мы это обходили с помощью интеграции – когда пользователи работают в одной базе, а объекты быстро событийно мигрируют в другую базу. И наоборот. Получалось так, что в обеих системах всегда была вся необходимая информация, и создавалась иллюзия, как будто человек вводит информацию только в одном месте.
При этом мы столкнулись с тем, что некоторые «быстрые» операции в основной базе учета УПП внезапно стали очень долгими.
Оказалось, что эта дельта вызвана длительным формированием сообщения по правилам обмена КД3. У нас в адаптере на тот момент не было возможности формировать сообщение отложенно – оно формировалось в момент записи объекта, и эта механика могла занимать много времени, потому что менеджеры просили, чтобы одновременно по ссылкам выгружались все связанные с ним объекты. И когда мы выполнили их просьбу, то получили такой интересный парадокс.
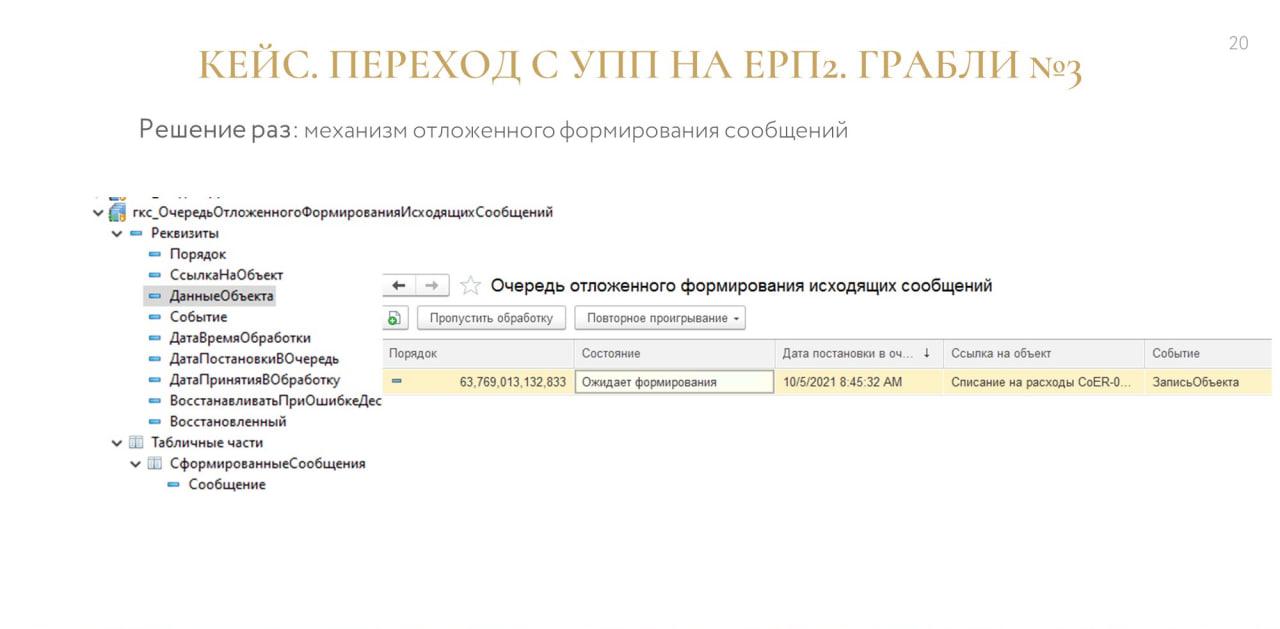
Эту проблему мы обошли с помощью механизма отложенного формирования сообщений – когда при возникновении события у тебя быстро снимается образ сообщения и формируется очередь отложенного формирования сообщений.
Для создания образа мы использовали формат Fast Infoset – позаимствовали идею в модуле версионирования из БСП.
А потом через какое-то время гуляет фоновое задание, которое берет эти сериализованные представления объектов, восстанавливает объект и по нему фоном формирует уже какое-то бизнесовое сообщение.
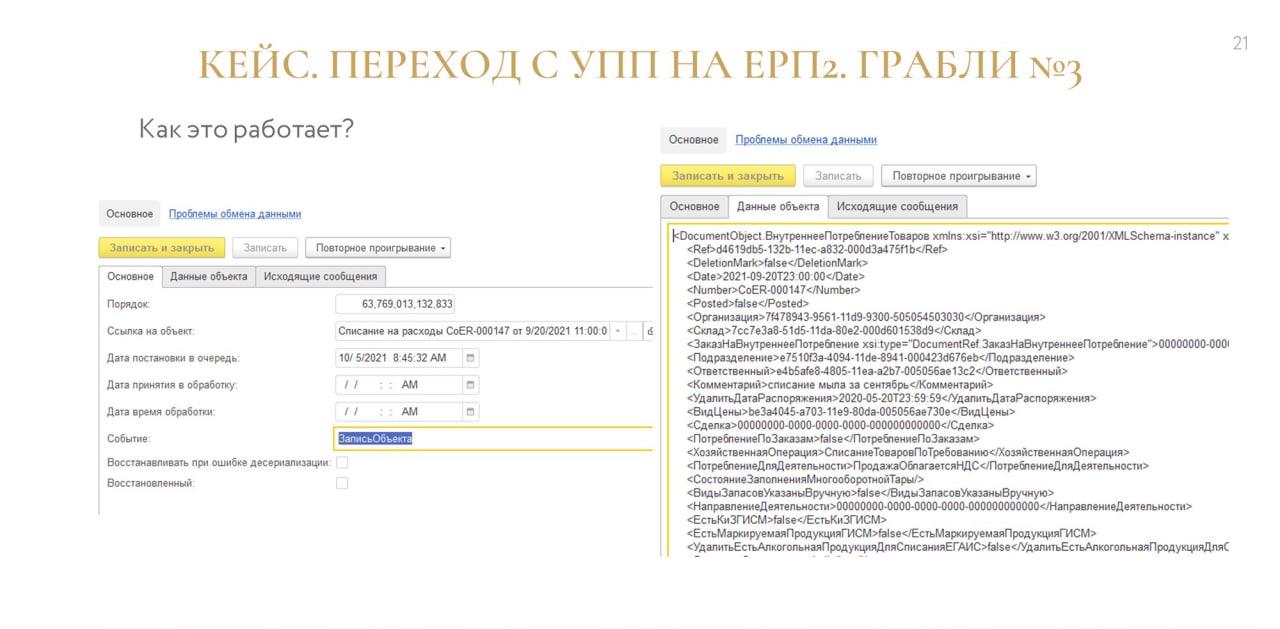
Почему мы используем Fast Infoset, а не формат платформенной истории данных? Дело в том, что у нас есть базы с разным уровнем совместимости на разных платформах.
-
А история данных, во-первых, не везде работала.
-
Во-вторых, до версии платформы 8.3.18 история данных работала точно нестабильно (есть проблемы с формированием версий в английском интерфейсе платформы) – это я могу доказать. И поэтому это нам не подходило.
-
Плюс ко всему при формировании версии там есть многоступенчатая обработка – соответственно, возникали вопросы, нужно ли повторно дергать фоновое задание, что будет по производительности, если версии накопились и т.д.
Поэтому мы использовали проверенный механизм версионирования из БСП.
Грабли №4. Интеграция с Directum
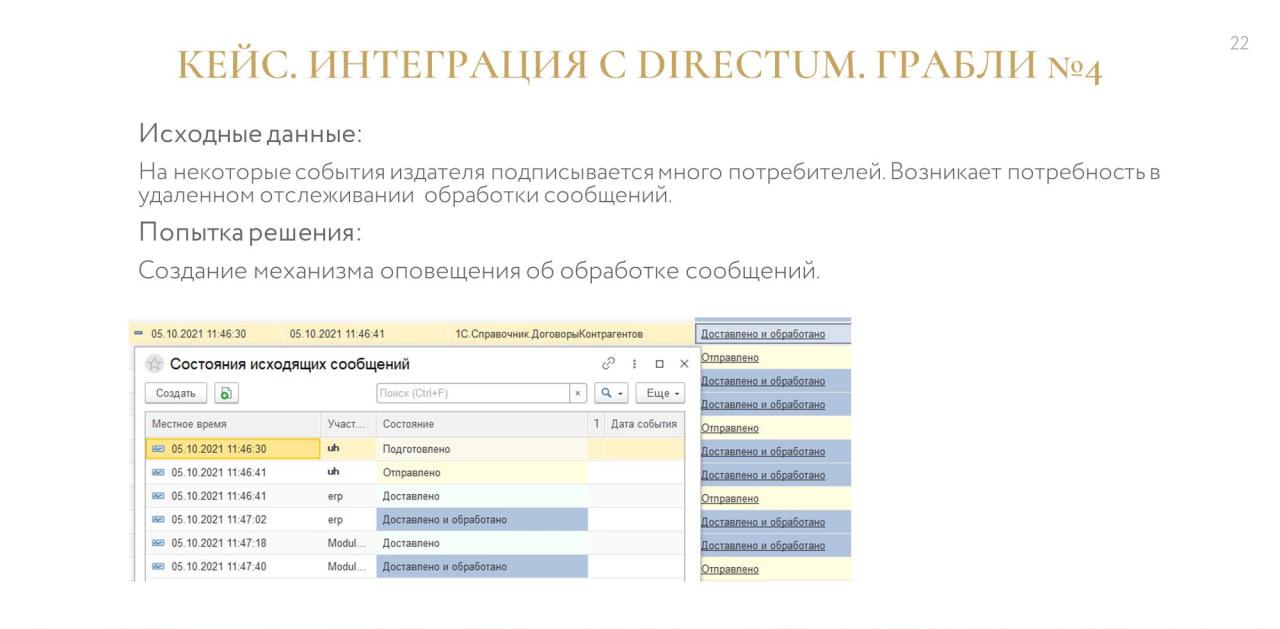
Еще один кейс – это интеграция с системой по работе с договорами Directum.
У нас все договоры рождаются в Directum, а потом по бизнес-процессу они приходят в «Управление холдингом». Там они дообогащаются своими данными и уже из «Управления холдингом» разлетаются по другим системам, которым они интересны.
Проблема была в том, что НСИ-шники и другие люди, ответственные за договорную работу, порой хотели видеть обратную связь – понимать, ушло ли сообщение, обработалось или не обработалось.
Например, если у нас подписано 20 баз, нам в каждую базу заходить проверять, что там с нашим договором?
Поэтому был сделан механизм для получения этой обратной связи и оповещения об обработке сообщений.
-
Когда приемник потреблял сообщение, он должен был сформировать обратное сообщение, используя свойство replyTo (ответ на) и опубликовать его в очередь Callback.
-
А когда приемник обрабатывал сообщение, он публиковал ответ «Обработано» либо «Ошибка обработки получателем».
Получается, что при включенном оповещении об обработке, у нас на одно сообщение было возможно получение двух обратных сообщений, которые необходимо обработать.
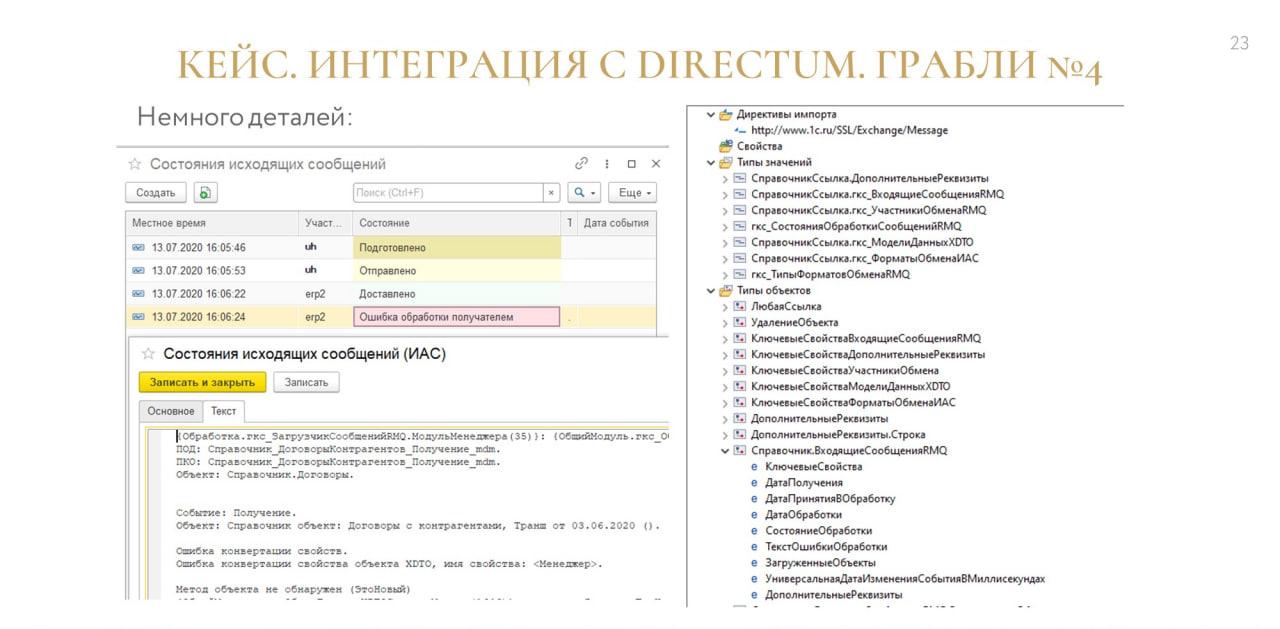
Вроде бы все хорошо продумано – служебный формат был отделен от бизнесового, это был свой пакет.
Всех все устраивало. И работало все это достаточно долго, год точно.
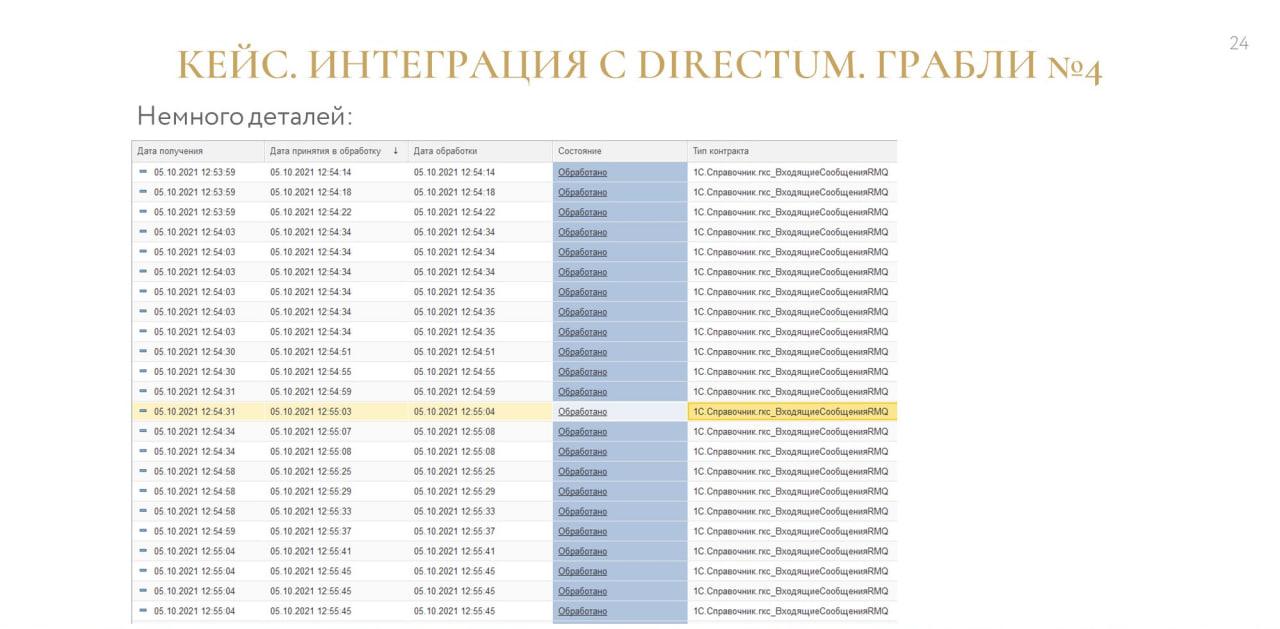
До тех пор, пока таких сообщений не стало неприлично много. Например, если мы меняем 5000 объектов и на каждый из этих объектов хотим получить два ответных сообщения – это уже 10 тысяч сообщений.
А у нас таких потребителей, допустим, 10 – и потом все эти сообщения необходимо было обработать в издателе, чтобы понять, что стало с нашим сообщением.
Это долго, а у нас очередь-то одна, и в ней еще рядом бизнесовые события, которые тоже нужно обрабатывать, и они, кстати, важнее, потому что это всего лишь сервис.

Здесь пока однозначного решения мы не нашли – эта задача сейчас в процессе решения.
Технологическое качество системы я восстановил, разделив потоки:
-
у нас теперь есть бизнесовый поток событий;
-
и есть поток служебных событий.
По факту поставлена задача переработать хранение логов там, где это должно быть.
Для этого есть специальные инструменты, которые, наверное, будет удобно использовать в этой задаче – это либо Elastic стек (ELK), либо Graylog.
Грабли №5, 6. Интеграции с внешними системами

Еще один кейс, тоже интересный. У нас компания большая, есть не только 1С, но и другие разработчики – в основном те, кто программирует на стеке C# и использует Blazor.
С ними возникали периодические трудности, потому что, как ни странно, двигателями прогресса в использовании брокера сообщений были мы. И возникали проблемы с контрактами:
-
они не хотели писать на кириллице – думаю, это для всех знакомо;
-
им не нравился XML, они все хотели JSON;
-
и формат Enterprise Data для них был тяжелый, а на каждый чих им отправлять изменения тоже особо не хотелось.
Покажу на конкретном кейсе.
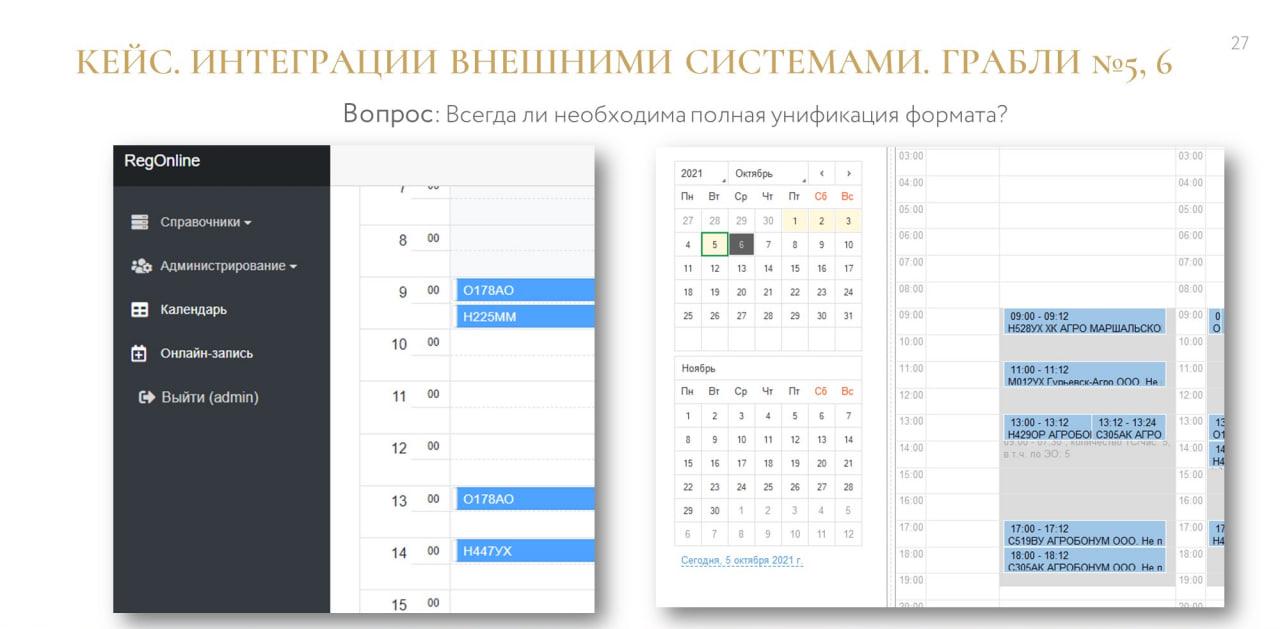
У нас есть система электронной очереди, которая предназначена для поставщиков.
Это наш фронт – туда поставщик может записать свою машину на приемку.
Эта же очередь у нас есть в самой системе ERP2 – там с ней уже работают другие люди, и на основе этого принимают какие-то свои взвешенные решения по оценке качества того, что машина привезла. Или решают, нужно ли там перераспределение в самой очереди.

Конкретно в этом кейсе мы посчитали, что сама по себе структура события хорошо подходит под 1С.
В очереди есть два регистратора: это документы «Регистрация в графике» и «Регистрация в очереди». Чтобы в очереди появилась запись, необходимо их создать.
По сути, вся сложная транзакционная механика – заполнение, регистрация – уже вся есть в правилах обмена. Нужно просто создать документ и его провести. В этом случае мы продавили наших разработчиков на C#, и они стали работать с кириллицей.
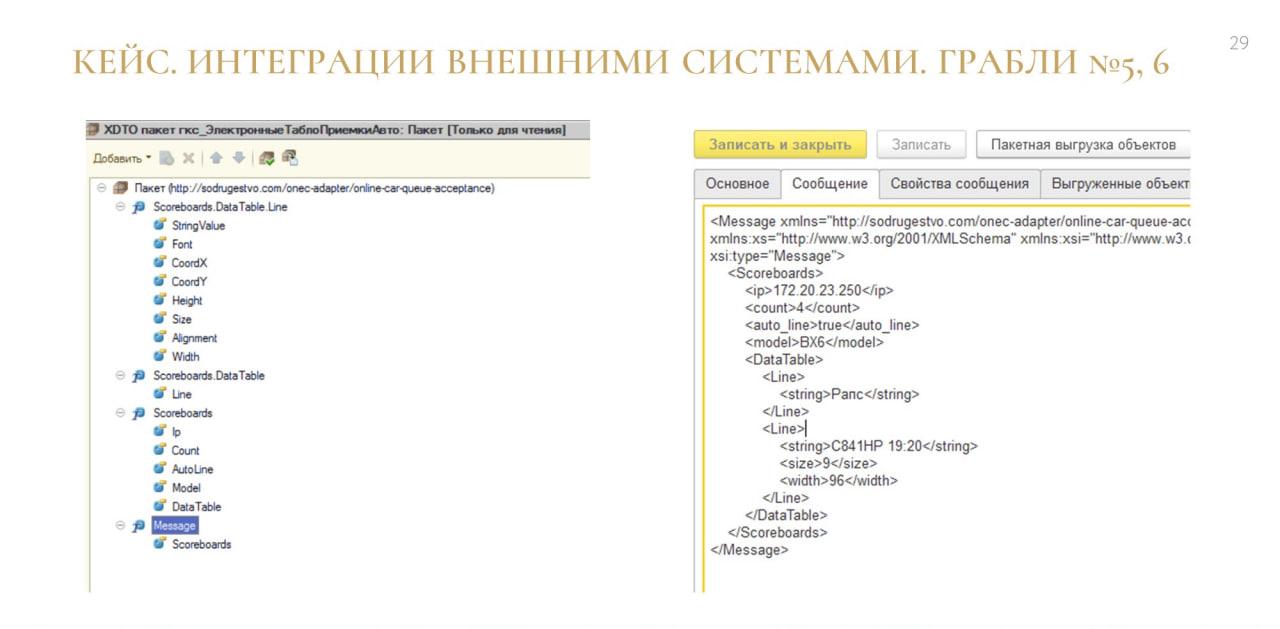
Здесь показана эта же электронная очередь, но вид сбоку – в таком виде выводится интерфейс на табло водителям, которые подъезжают на разгрузку.

Также необходимо было передавать все данные, чтобы понимать, какая машина по порядку идет первой, а какая – второй. Это уже никак не ложилось на 1С-объекты, да и вообще формат, с которым это табло работало, был очень своеобразным.
Поэтому мы сделали простой XDTO-пакет, отдали его им в JSON, и наступило счастье всем.
Грабли №7. Эксплуатация и обслуживание

Завершающий кейс – в процессе поддержки крупной корпоративной системы всегда происходит какое-то развитие. Оно может происходить по частям – одна система развивается, другая нет.
Не все хотят постоянно меняться. В том же Directum мы контракт зафиксировали, и больше он никак не зависит от наших обновлений – там разработчик не хочет постоянно заходить и менять у себя XDTO-пакет каким-то образом.

Поэтому мы сделали специальный интерфейс, в котором можно было фиксировать контракты и гибко настраивать их под себя.
В каждом формате обмена загрузка, формирование и потребление сообщений разбиты на разные слои абстракции:
-
отдельный менеджер формирования сообщений;
-
отдельный менеджер обработки сообщений;
-
отдельный менеджер загрузки;
-
и отдельный менеджер выгрузки.
Менеджер – это название общего модуля, в котором зарезервирована процедура с определенным именем, с определенными параметрами.
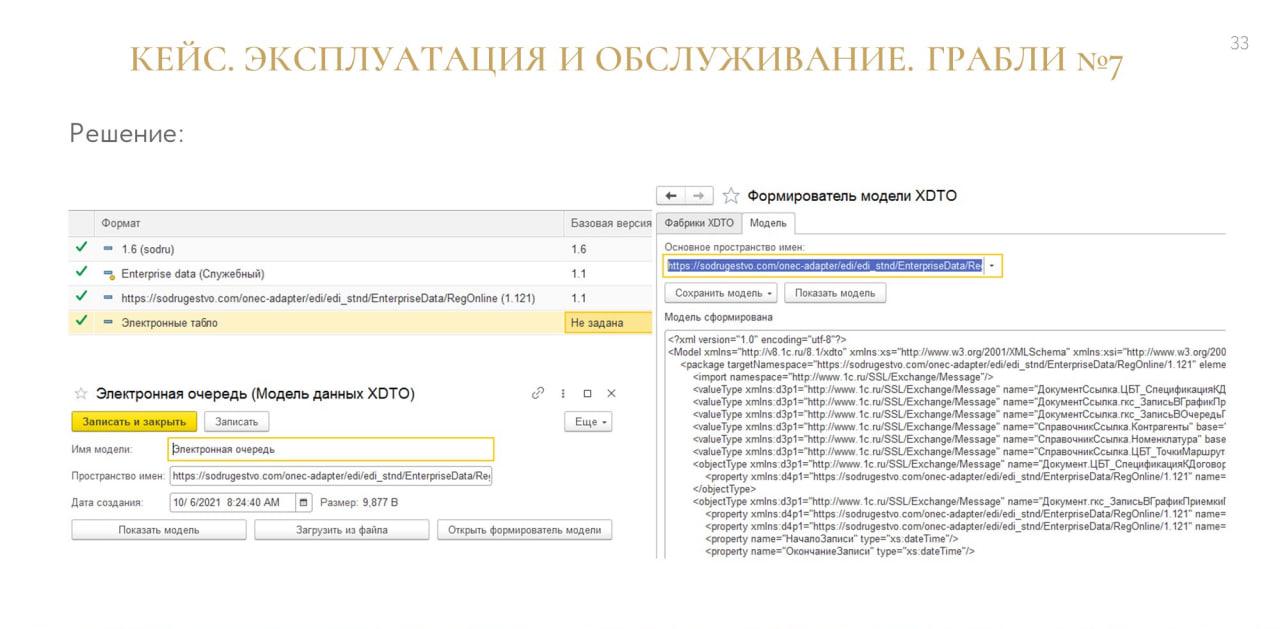
Для аварийных случаев и случаев жесткой фиксации мы стали частично хранить сам формат в информационной базе. При этом у нас происходит обратная сериализация самой фабрики – мы ее сохранили в тексте.
Например, мы знаем, что для Directum нужен конкретно этот формат – пожалуйста, основной формат в основной конфигурации обновился, а в справочнике остался формат для взаимодействия с Directum, мы применяем его.
Почему бы тогда все форматы не хранить в справочнике? Зачем нам тогда в самом конфигураторе держать этот XDTO-пакет?
Я делал замер на разных машинах – формирование формата занимало от 0.1 до 0.4 секунды. И представьте себе, что будет, если на каждую операцию с формированием сообщения добавлять это время.
Если брать какую-то долгую операцию в 5 секунд, мы не почувствуем разницы. А если брать обработку 5000 объектов накопительным итогом, то, понятно, разница уже будет.
Поэтому, когда формат встроен в конфигурацию, все это работает намного быстрее.
Плюс ко всему формат Enterprise Data монолитен – там один большой пакет, там куча всяких данных, порой даже между собой не особо связанных.
А мы от этого отходим и в своей практике стараемся формировать много разных пакетов. Там, где это возможно, разбивать их по бизнесовому направлению – закупки, склад хранения, продажи.
Не отступайтесь от своего выбора!

Какие выводы можно сделать по результатам? Некоторые из них тривиальны.
-
Когда мы используем брокер сообщений в бизнес-задачах, мы должны понимать, что мы используем архитектурный паттерн, у которого есть свои плюсы и минусы. Это все уже хорошо документировано, и это нужно изучать.
-
Сделать единый формат для всех информационных систем – это задача утопичная, у нас так не получилось. И это не всегда нужно. Порой нужно сделать, чтобы приложение менялось именно так, как ему удобно. Это, наверное, будет правильно.
-
Событий в системах может быть очень много, поэтому важно научиться правильно их отделять. Например, к бизнес-событиям относится не запись документа, а добавление строки заказа. Не изменение элемента справочника номенклатуры, а замена единицы измерения. Нужно научиться правильно понимать, какие события интеграции нам нужны, а какие – нет.
-
Также хочется отметить, что событийно-ориентированная архитектура и применение брокеров наложит свой отпечаток на всю вашу инфраструктуру. Это будет огромный пласт интеграционной логики, за которой нужно будет следить, за это нужно будет платить, и это нужно будет тестировать, проверять. Прежде чем туда ввязываться, вы должны трезво оценить, нужно вам это или нет.
-
И последний вывод – не всегда нужно придумывать что-то новое. Есть много всего уже готового и изученного. Но если вы сделали какой-то выбор, нужно ему следовать, идти вперед, его защищать и не отступать. И самое главное – научиться принимать ответственность и научиться справляться с последствиями этого выбора.
Вопросы
Как организована передача данных подготовленного пакета из RabbitMQ в базу-потребитель? База-потребитель самостоятельно обращается в RabbitMQ и забирает пакет?
RabbitMQ – это брокер, он реализует выталкивающую методологию.
Под капотом – внешняя компонента от «Серебряной пули». Периодически стартует регламентное задание, поднимается соединение с брокером AMQP, и, если в очереди есть сообщение, он его выталкивает и происходит потребление.
Получается, что в RabbitMQ много очередей, и каждая база знает, в каких очередях она должна забирать сообщение?
Да, есть типичный механизм подписки. Мы подписываемся на то, что нас интересует. База данных знает, на что ей подписаться.
В базе-потребителе одно регламентное задание, считывание производится в один поток?
Это все настраиваемо, есть много уровней настройки по приоритетам.
Допустим, НСИ-шную очередь нам всегда интересно забирать сразу. А очередь каких-то других событий не обязательно мониторить в реал-тайме – можно стучаться к ней раз в 15 минут.
Делается отдельное задание, которое поднимается раз в 15 минут, забирает сообщения и обрабатывает. Это настраивается.
Получается, что в каждой базе есть одно или целый ряд регламентных заданий, которые этим занимаются. И в 150 базах целая куча заданий, которые могут работать или не работать. За ними же нужно как-то следить?
Мы для этого используем ЦКК, «Центр контроля качества», конфигурацию от «1С» – я ее доработал и организовал там определенный мониторинг по слежению за этими заданиями.
В качестве одного из выводов доклада я как раз и говорил, что событийно-ориентированная архитектура наложит свой отпечаток – у нас появляется то, за чем нужно следить. И это – то, чем нужно заплатить.
Вы же для формирования сообщений используете Enterprise Data? А как вы реализовали проблему пометок на удаление, проведенности документов, отмены проведения?
Не буду врать, для проведенности документов у нас пока нет единого решения:
-
В части правил это передача определенной структуры, которая за это отвечает, через AdditionalInfo.
-
В части объектов кто-то добавлял свойство и по нему ориентировался.
По пометкам удаления – при удалении объекта у нас происходит формирование сообщения об удалении объекта. Оно работает, только если правило поиска – «По полям поиска и по уникальному идентификатору». Для правил просто «По полям поиска» это не работает, поэтому мы за этим тоже следим.
Вы используете компоненту Yellow RabbitMQ. У нее нет никаких проблем с точки зрения производительности? Сколько сообщений в секунду летает?
Нет, проблем с этой компонентой у нас не было ни разу. Один раз была проблема, связанная с очередями Quorum, потому что в компоненте жестко зашито значение prefetch = 1, а очереди Quorum с этим не работают. Но с самой компонентой проблем не было.
Были проблемы, когда зависали регламентные задания, но эти проблемы, я так понимаю, были на стороне 1С, потому что после обновления платформы они уходили.
А с компонентой никаких проблем и нареканий не было.
А сколько сообщений в секунду, в час, в метриках?
10 тысяч сообщений в час я точно вижу на графиках. Там от пиков зависит. У нас сейчас процессы в компании не устоявшиеся, идет много перезагрузок, перевыгрузок, поэтому трудно понять, когда система в рабочем состоянии, а когда – в аварийном, и нужно что-то массово перезагружать. Но 10 тысяч сообщений в час у нас точно есть всегда.
А какая гранулярность отправки сообщений? Одно сообщение – это один объект, один справочник, один документ?
Тут тоже по-разному. В 90% кейсов один объект – это одно маленькое, быстрое сообщение.
Но у нас в компании есть менеджеры, которые считают, что это неправильно, и нужно выгружать все по ссылкам. Поэтому я и рассказывал о проблеме с тем, что некоторые документы проводились долго.
Стандартно механика БСП смотрит, и если объект уже был выгружен, то выгружает ссылку. А если нет, выгружает объект. Плюс мы доработали модель БСП, и она смотрит на уровне вложенности – понятно, что теоретически так можно выгрузить полбазы.
Поэтому в определенных кейсах связанные объекты тоже выгружаются, но в большинстве кейсов один объект – это одно сообщение,
Вы рассказывали, что была проблема с множественным изменением одного и того же объекта. А почему решили формировать ключ объекта? В RabbitMQ же есть стандартное поле timestamp.
У нас в адаптере есть своя очередь – происходит подключение к RabbitMQ, RabbitMQ пуляет сообщения, и мы предварительно сохраняем их в информационной базе.
В настройках задается какой-то порог – мы выбираем порцию сообщений, которую хотим обработать. У нас есть порция и есть математика, которая рассчитала, что эту порцию будет эффективно раскидать на 4, 5 или 6 потоков.
Если не делать такой ключ, непонятно, какой объект мы обрабатываем. И может получиться так, что у нас один и тот же объект окажется в двух разных потоках.
Но почему вы пытаетесь получить сообщения и сразу же начать раскидывать по объектам? Почему сначала не делаете сортировку по хронологическому порядку? Если мы в источнике 10 раз один и тот же объект поставили на регистрацию, то он проведется 10 раз. А вам же нужно, чтобы осталось только одно состояние объекта, причем последнее.
Тогда он в потребителе пройдет не все состояния, правильно?
Но я не знаю ни одной конфигурации, где объект должен пройти все состояния.
Тут все зависит от того, как это запрограммировано. Например, у нас есть подсистема, связанная с бизнес-процессами – когда у тебя пришел объект с таким-то статусом, и он требует сделать с ним такие-то действия. Если мы возьмем только последнее состояние, не факт, что это все правильно отразится.
Это сейчас ваша фантазия, или вы точно знаете, что у вас в базах есть такие проблемы?
У нас в базе такие проблемы точно есть, потому что бизнес-процессы у нас используются. Поэтому я и не рассматривал возможность брать у объекта только последнее состояние. Но технически это сделать можно, согласен.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.


Вступайте в нашу телеграмм-группу Инфостарт