




Предисловие
Данную подсистему сделал в свободное время, так как была интересна тема распознавания изображений. Потом, в компании, в которой работаю, оценили разработку и успешно используют в загрузке специфичных и сложных для ручной обработки документов от вендера.
Выкладываю с одной целью - понять, актуально ли данное решение для других компаний, так как сейчас набирает популярность ЭДО (хотя на данном этапе у него много минусов). Если актуально, то собрать пожелания, идеи и сделать продукт, который полезен и выгоден для пользователя.
PS. Данная штука не особо никому не нужна. Выложил всё в открытый доступ. Всё предоставляется "как есть".
Требования
Платформа не менее 8.3.12, режим совместимости не менее 8.3.12. Система Windows.
Описание
Программа использует различные варианты распознавания. Tesseract, ABBY FineReader, ABBY Hot Folder, ABBY Recognition Server, ABBYY Cloud OCR SDK. Выбор продукта зависит от количество документов и удобства использования в целом. Выбор пал именно на продукты ABBY, так как именно они выдают результат с наиболее приемлемым качеством распознавания и, самое важное, сохраняют структуру исходного файла.
По сути, данная разработка - парсер, которая выуживает определённым способом данные из распознанного файла данные, структурирует их, и по настройкам пользователя загружает в 1с. Более того, позволяет пользователю расширять список документов для автоматического распознавания, что позволяет загружать не только какие-то типовые формы, но и произвольные (которые соответствуют определенным критериям, о которых ниже), притом именно в те документы в 1с, которые нужны пользователю, и так, как это нужно именно пользователю, а не как предусмотрел разработчик.
Механизм работы следующий. Файл преобразуется в htm файл (или xml, при работе с облаком). Если блок данных распознаётся как таблица, то программа пытается получить шапку таблицы и на основании этих данных, пытается соотнести информацию в ячейках к конкретной колонке в шапке. Поэтому:
Ограничение №1: Шапка таблицы должна быть только горизонтальная
Ограничение №2: Строки таблицы не должны быть многоуровневыми
Ограничение №3: Таблица должна распознаться, следовательно в исходном документе должна быть явно выделена
Если блок не таблица, то программа считает, что это информации относящиеся к шапке документа и пытается выделить из него полезную информацию, такие как поставщик, покупатель, номер, дата и прочее.
После программа пытается полученный массив полезных блоков информации логически разделить на документы, так как один документ может быть разбит на несколько файлов, так и в одном файле может содержаться несколько документов.
Пользователю выводится список файлов, на каждый вид документа есть своя настройка загрузки. По этой настройке данные загружаются в 1с.
Порядок установки, работы и нюансы более подробно в документации.
Пример
Счет из Демо-базы УТ

При распознавании данного файла получим следующий результат.
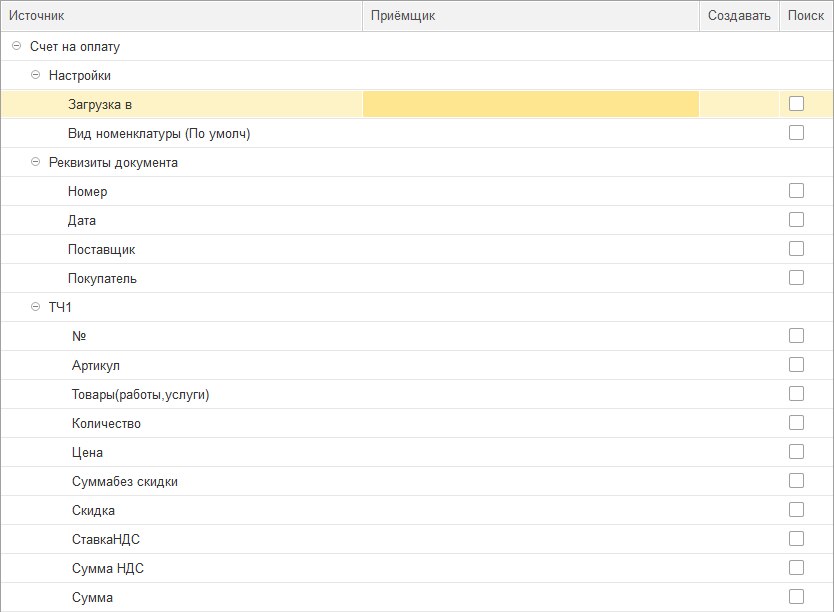
Загрузим в «Приобретение услуг и прочих активов». Сделаем следующие настройки.

Создадим документ.
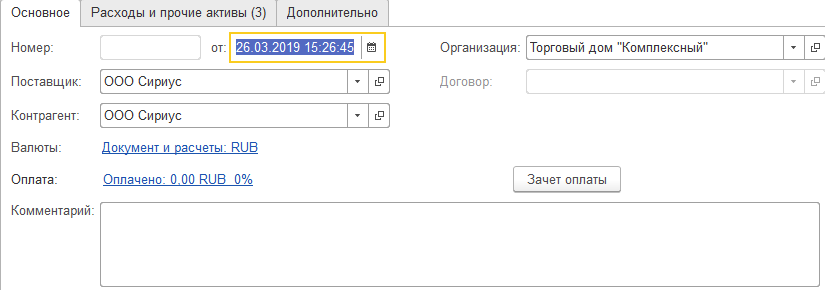

Осталось проверить корректность загрузки и заполнить требуемые поля.