Инструмент для RCM-анализа
Уже по названию понятно, что, как минимум, одна из главных задач системы для управления надежностью — проведение RCM-анализа.
Но почему именно он? Зачем потребовалась целая новая система для автоматизации какого-то там конкретного вида анализа?
Предлагаю посмотреть на это с точки зрения «управленческих решений» в процессах.
У нас есть понятный процесс ТОиР, включающий использование следующих инструментов:
- планирование мероприятий (планово-предупредительные ремонты (ППР), регламентные мероприятия),
- обеспечение этих мероприятий материалами и ресурсами (МТО и ресурсное планирование),
- эффективное исполнение мероприятий (наряды на работы и акты о выполнении этапа работ),
- реакции на неожиданные события (дефекты, предписания).
Этот процесс в целом понятен. Но! На предприятиях разное оборудование. А если и одинаковое, то разные условия эксплуатации. А если одинаковые сейчас, то могут измениться со временем. Возникает вопрос: как выстраивать эффективный процесс ТОиР и эффективно управлять им, реагируя на изменения ситуации?
Тут нужны другие инструменты и другой процесс. Процесс «управления», а не «исполнения». Процесс, который большей частью смотрит в будущее. Эдакий процесс «второго порядка» — процесс построения процессов.
Что у него будет на входе?
- иерархия оборудования;
- понимание, какое оборудование является критичным;
- знания экспертов;
- данные поставщиков оборудования;
- история дефектов на предприятии;
- различные прогнозы;
- требования к надежности и производительности.
Что от него требуется на выходе?
- оптимальная и обоснованная программа обслуживания, которая обеспечит нам требуемую надежность (т.е. это и есть описание того, каким должен быть эффективный процесс ТОиР для этого оборудования).
Какие инструменты можно использовать, чтобы работать с «будущим», ведь оно не определено?
- концепция рисков;
- рассматривать несколько вариантов с вероятностями;
- прогнозы и аппроксимации.
Такова наша ситуация, если мы хотим осознанно управлять нашими процессами ТОиР. Мы можем использовать что угодно, лишь бы это подходило нам в описанной нами «системе координат», в нашем «фреймворке» — использовало входы и давало, что нужно, на выходе.
RCM-анализ был выбран нами именно как алгоритм, решающий нашу задачу. Это комплексный экспертный анализ надежности, который последовательно рассматривает вопросы:
- «Что может произойти?»
- «Какие причины могут это вызвать?»
- «Что можно сделать, чтобы этого не произошло?»
- «Что из этого мы выберем для обслуживания оборудования, чтобы его надежность была достаточной?»
Это был не просто «какой-то анализ, использующийся для обеспечения надежности авиационных двигателей». Мы адаптировали его для наших целей и научили работать с понятиями нашей предметной области.
В нашей версии получился процесс, состоящий из 4 этапов.
4 этапа процесса RCM-анализа и формирования оптимальной программы обслуживания оборудования
1. Подготовка данных для анализа
- Формирование нормативно-справочной информации об объектах анализа.
- Определение логических и функциональных моделей систем и подсистем.
- Формирование структуры надежности.
Здесь решаются задачи загрузки данных из других систем — 1С:ТОИР 2 КОРП, 1С:ERP 2.5 и 2.4 или любой другой системы через универсальные загрузчики. Данные упорядочиваются, систематизируются и «обогащаются» экспертами.
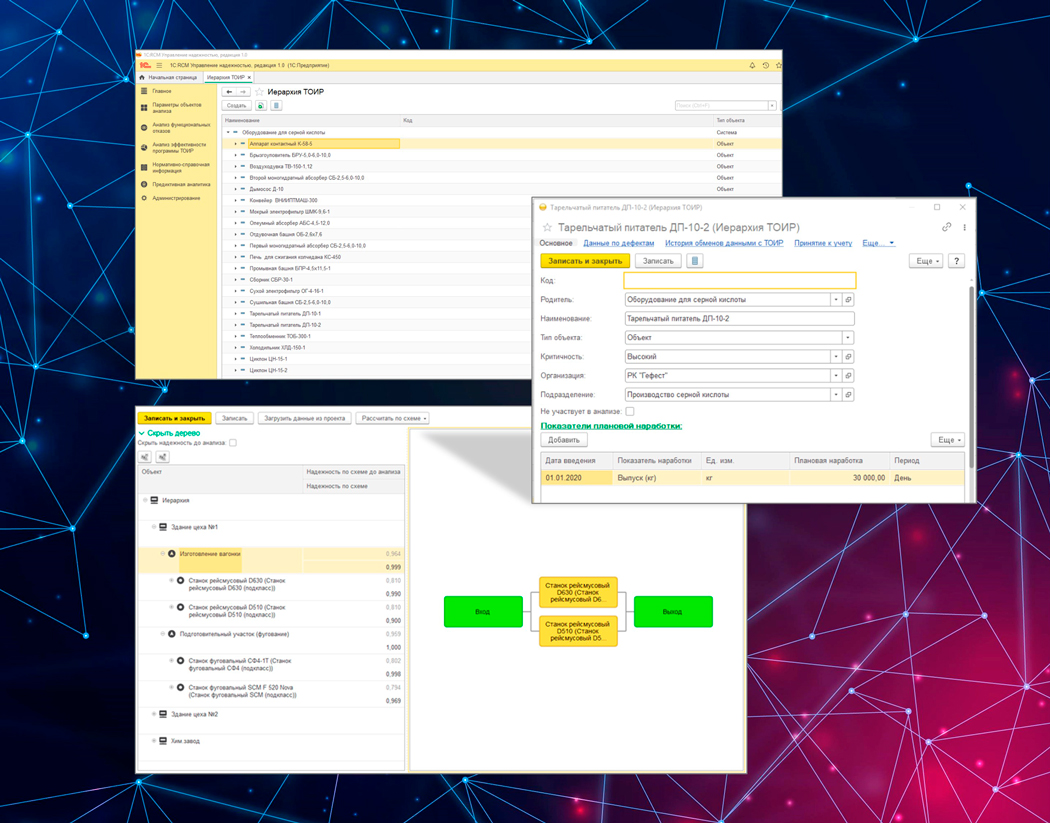
2. Анализ отказов (FMEA/FMECA)
- Определение списка объектов для проведения анализа.
- Определение видов отказов и вероятности их возникновения.
- Определение возможных последствий отказов и их тяжести.
- Формирование матрицы оценки рисков.
- Определение критичности отказов.
- Определение параметров надежности.
- Формирование отчетности.
Больше всего работы проводится на этом этапе. Мы прикладывали силы, чтобы создать инструменты, облегчающие принятие решений, например:
- рекомендации видов отказов из прошлых анализов, истории дефектов и прогнозов;
- использование матрицы рисков для быстрой оценки последствий.
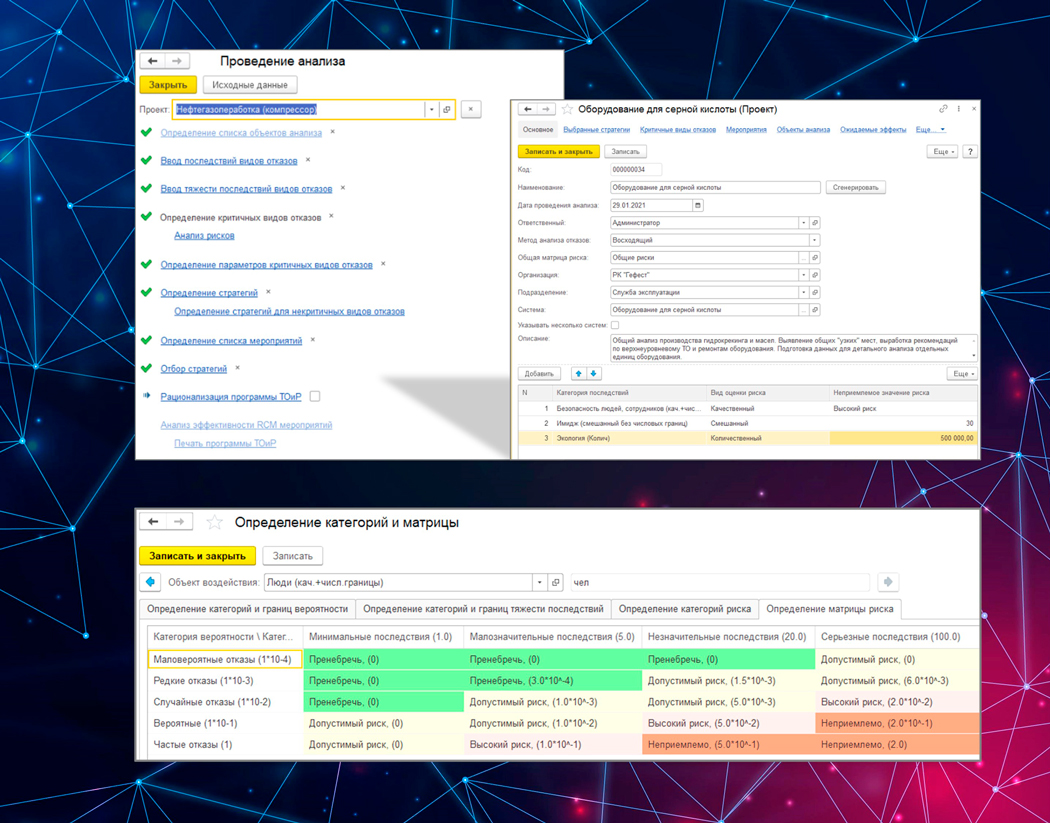
3. Формирование оптимальной программы ТОиР
- Определение списка необходимых мероприятий.
- Выбор наиболее оптимальной стратегии обслуживания с определением ее ориентировочной стоимости.
- Формирование оптимальной программы ТОиР.
- Оптимизация проводимых мероприятий.
Это второй по величине этап — мы также добавили сюда инструменты для помощи в принятии решений:
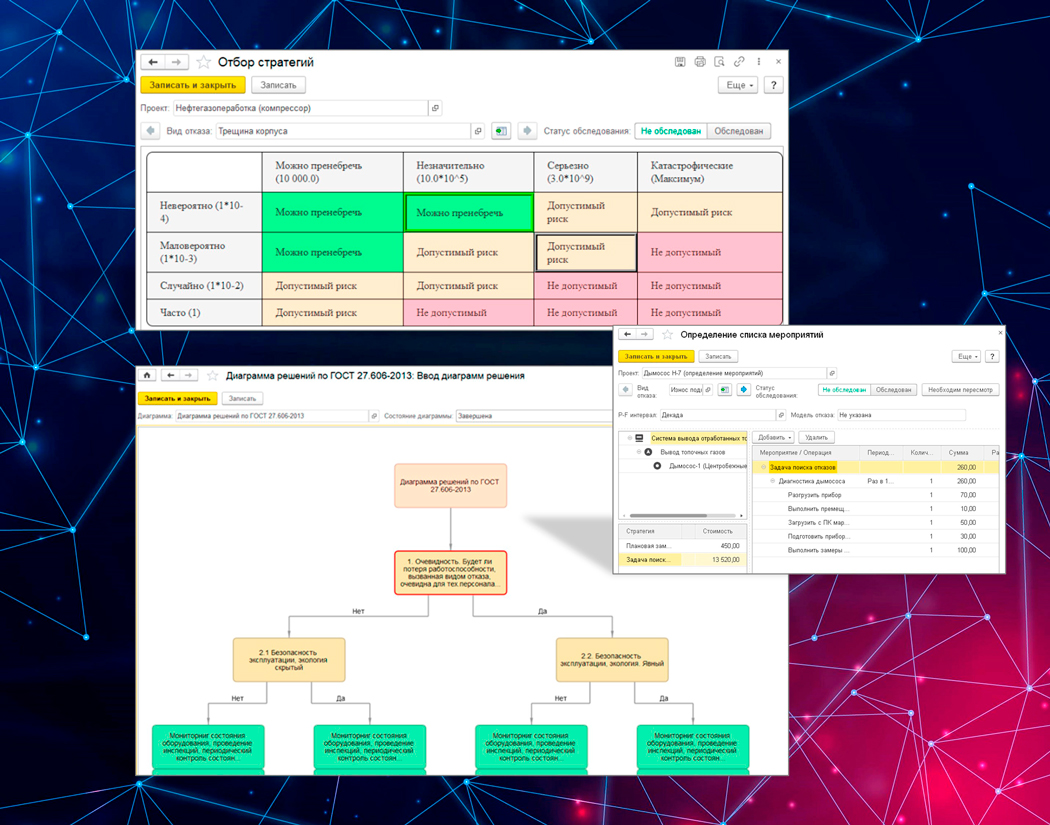
- диаграммы решений,
- просмотр влияния программы на матрице риска,
- рабочее место для рационализации получившейся программы (удаления дубликатов мероприятий и определение оптимальной периодичности).
4. Анализ эффективности мероприятий
- Анализ эффективности RCM-мероприятий.
- Передача сформированной программы ТОиР на исполнение в систему управления ремонтами и обслуживанием (это, напомню, EAM- или ERP-система).
- Корректировка исполняемой программы ТОиР.
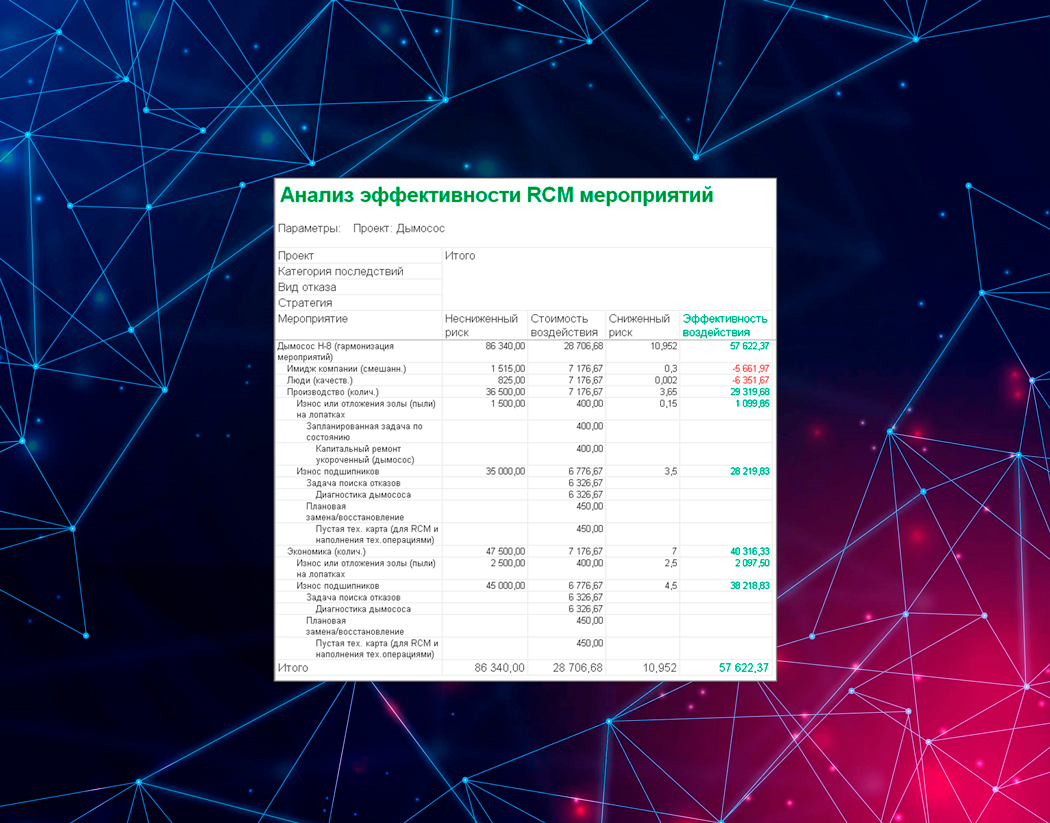
Вообще RCM-анализ — повторяющийся, цикличный процесс. Поэтому, чтобы добиться эффективности, его рекомендуется повторять как минимум каждые 9–12 месяцев.
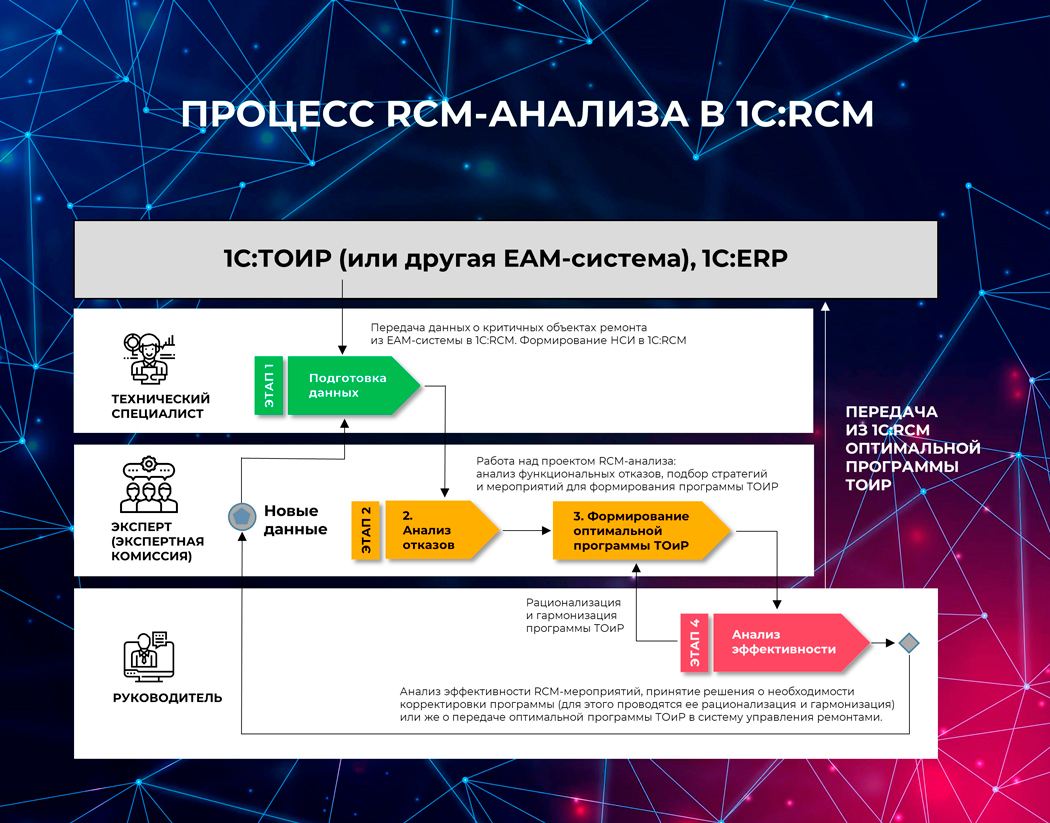
В целом следует рассматривать систему 1C:RCM как каркас, который структурирует данные в области ТОиР и содержит инструменты для «процесса управления процессами ТОиР» — управления надежностью. В нем уже есть один штатный метод — RCM-анализ. Его можно использовать как есть или адаптировать, расширять и даже добавлять что-то совсем новое, но в рамках имеющихся данных.
Инструмент для предиктивного анализа
Как я уже отметил, процесс управления надежностью в нашем понимании смотрит в будущее, и одним из входов этого процесса являются прогнозы и аппроксимации. В 1С:RCM встроен инструмент для организации предиктивного анализа своего оборудования.
Этот инструмент состоит из двух больших частей, или «слоев».
- Подсистема «Предиктивная аналитика».
- Механизм поиска аномалий в данных с датчиков, установленных на оборудовании и постоянно диагностирующих его состояние.
Подсистема «Предиктивная аналитика»
1-й слой. Подсистема «Предиктивная аналитика» внутри 1C:RCM сделана из расчета работы почти с любыми поставщиками предиктивной аналитики.
При ее создании мы исследовали, что предлагают компании, занимающиеся машинным обучением. Обнаружили, что обычно всё сводится к одному из следующего:
- прогнозу наступающего отказа,
- прогнозу остаточного срока компонентов или узлов,
- прогнозу значений производственных показателей,
- детектированию аномалий в состоянии оборудования.
Прогнозы отказов и остаточных сроков могут прямо использоваться экспертами в анализе надежности. Обычно инструменты, которые дают такие данные, специфичны, сделаны на заказ или поставляются производителем оборудования.
Прогноз показателей обычно относится к тонкой настройке параметров производственных процессов (подбор времени обработки, количества ингредиентов и пр.). Они больше нужны для производственной системы, так что не так нам интересны.
Обнаружение аномалий интересно тем, что не требовательно к знаниям о тонкостях работы оборудования. Не нужно быть экспертом в узкой области, чтобы установить факт аномалии, достаточно следить за допустимыми параметрами значений показателей оборудования.
Мы добавили в подсистему средства для хранения и использования полученных прогнозов.
А для данных об аномалиях разработали много инструментов, помогающих извлечь из них пользу, — преобразовать в конкретные виды отказов, которые могут произойти.
- шаблоны оборудования с датчиками;
- паттерны отклонений (диагностики);
- рабочее место для разбора аномалий.
В них использовано много приемов для облегчения принятия решения специалистам по надежности — средства просмотра графиков прошлых значений, иконки направления отклонений и прочее.
Система также пытается быть «умной» и сама подбирает подходящие виды отказов по введенным паттернам отклонений (диагностикам).
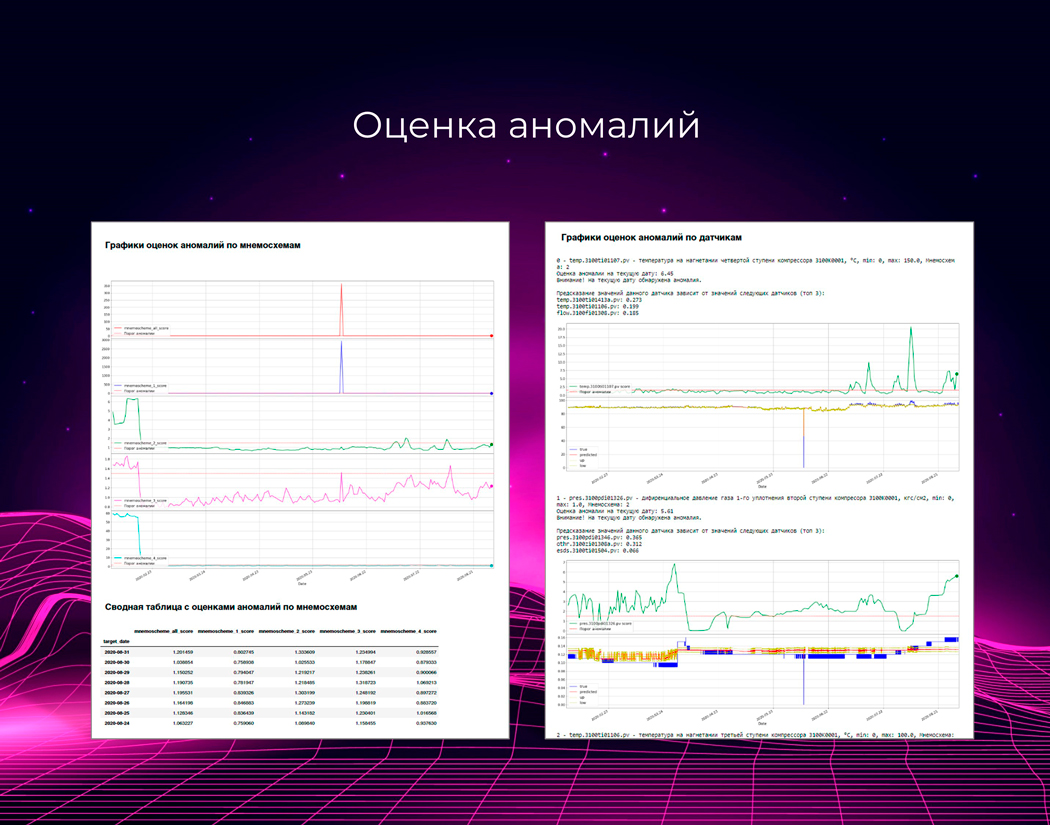
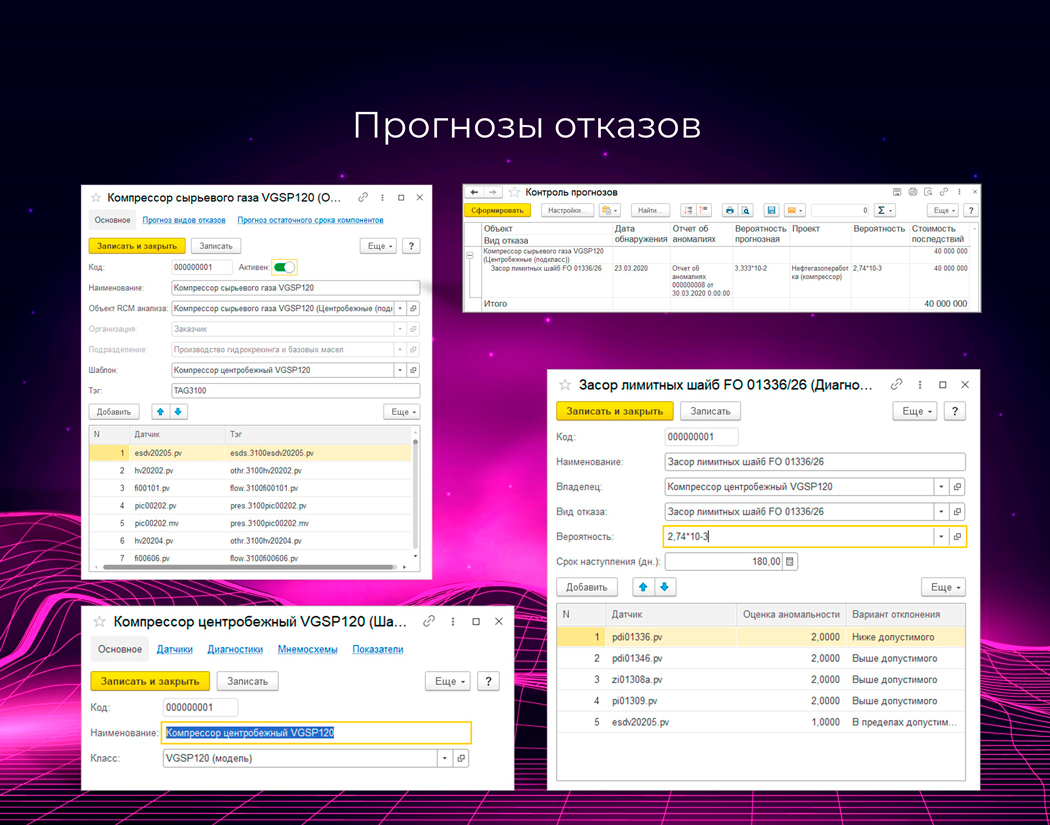
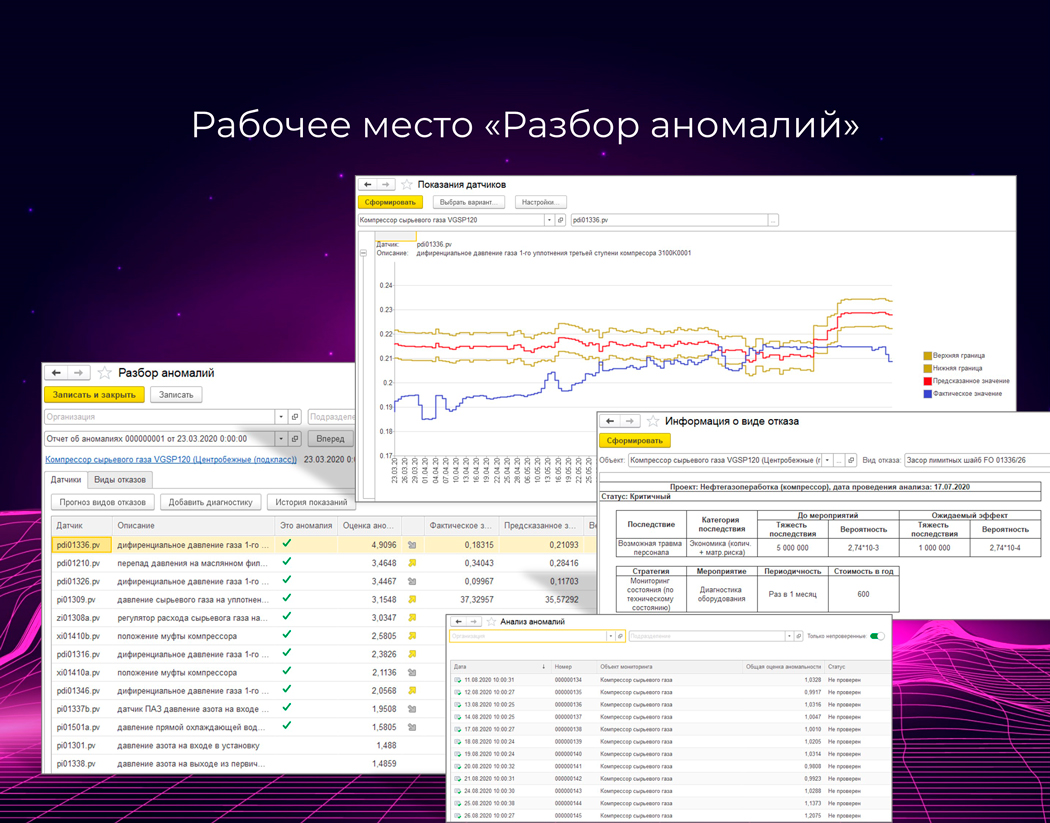
Механизм детектирования аномалий
А теперь 2-й слой. Это одна реализация механизма, который может поставлять данные в нашу подсистему предиктивной аналитики. Он основан на разработанном нами сервисе обнаружения аномалий в работе оборудования, из которого 1С:RCM может получать данные. Мы предлагаем его нашим клиентам, если нет желания заниматься разворачиванием инструмента у себя.
Принцип работы — взаимное предсказание значений датчиков в каждый момент времени. Модель обучается, запоминает «нормальный режим работы» и потом способна сказать, когда какие-либо датчики ведут себя «не так, как от них ожидается».
Механизм написан на языке Python и использует открытые библиотеки машинного обучения. С помощью библиотеки функциональных подсистем, разработанной фирмой 1С (сокращенно БФП), мы включили наш инструмент в коробку 1С:RCM.
Использовать сервис из коробки довольно просто, нужно лишь выполнить несколько шагов.
1. Подключить по инструкции расширение с предиктивной аналитикой.
2. Средствами библиотеки БФП установить Python и необходимое окружение.
3. Подготовить по инструкции сведения о датчиках и исторические данные в нужном формате, а затем обучить модель.
4. Организовать по инструкции поступление текущих данных.
5. Сделать настройки на стороне 1С:RCM:
1) загрузить из сервиса данные об объекте мониторинга (состав и описание датчиков);
2) ввести известные диагностики отказов (если таких сведений нет, можно начинать работать с чистого листа и собирать базу диагностик в процессе работы);
3) настроить расписание по загрузке аномалий;
4) назначить исполнителей для проведения анализа аномалий.
Система диагностирования аномалий
Как именно система диагностирования аномалий в показаниях датчиков помогает «предсказывать» отказы?
Важны три момента:
- «предсказание» на основе состояния.
- обнаружение не абсолютных, а относительных отклонений.
- обнаружение заранее неизвестных аномалий.
«Предсказание» на основе состояния
Рассмотрим для иллюстрации пример из жизни. В середине дня вы обнаружили, что в вашем автомобиле на треть «спустило колесо», хотя утром все было нормально. В такой ситуации, скорее всего, вы можете «предсказать», что доехать до шиномонтажа еще можно успеть, а вот оставить это на завтра и ездить дальше так уже не получится. И, вероятно, будете правы.
По такому же принципу работает и наш механизм: аномалия — «низкое давление в шине», диагностика — «если давление в шине ниже положенного, то с вероятностью 90% через 5 часов произойдет повреждение корда».
Обнаружение не абсолютных, а относительных отклонений
Важно, что детектирование аномалий не сводится к проверке выхода за допустимые границы. Это умеет проверять любая АСУ ТП, и в 1С:ТОИР 2 КОРП есть система сигнализации о таких отклонениях.
Система умеет находить ситуации, когда с виду допустимое значение выглядит «подозрительно»: например, показатель «открытие заслонки» принимает значения от 0 до 100% и вообще не может «выйти за границы». Тем не менее, был реальный пример, когда по показаниям этого датчика можно было предотвратить отказ, — заслонка открывалась всё больше и больше, хотя не должна была.
Обнаружение заранее неизвестных аномалий.
Системе не надо объяснять, «куда смотреть». Она сама сопоставляет все значения со всеми. Это позволит не пропускать даже то, о чем не подумали заранее. По такой аномалии нельзя будет автоматически сказать, к какому виду отказа она приведет (если не будет соответствующего паттерна в системе), но она будет отправлена специалисту на разбор. И он сможет внести данные в систему или отметить, что это было несущественно.
Все вышеперечисленные моменты — это уже даже не просто «умный» механизм, которые скрывает сложность. Это уже почти «интеллект» — который думает и старается помочь.