В преддверии открытого вебинара по управлению рисками для тимлидов хочу немного поделиться опытом.
На конференции по Скрам я познакомилась с Shape-up - методологией для продуктовых команд. Подход интересный, но это тема для отдельного разговора (есть книга в открытом доступе - если не найдете - напишите, подскажу). А зацепил меня там заключительный шаг предлагаемого процесса “формовки” продукта. Ну то есть сначала всё понятно - команда определила цель, результат, исключения и почти готова к работе. Последний шаг - найти “кроличьи норы” (rabbit holes), в которые можно “провалиться” в процессе выполнения задачи, и вместо быстрого результата застрять надолго… Потерять время в бесконечных разборках и уточнениях от заказчиков вместо работы над глобальным проектом, неожиданно остаться без облачного сервиса из-за ужесточения санкций, выкатить на прод обновление с критичными ошибками из-за отсутствия протокола тестирования - всё это и многое другое - примеры “кроличьих нор”, в которые может провалиться команда.
Вот это подход, который, на мой взгляд, стоит перенять всем командам разработки.
Потому что всем нам хочется, чтобы мы могли быть уверены, когда будет готова та или иная задача. Ну, конечно, не точно - это невозможно, но хотя бы приблизительно. На этом графике по горизонтали - время выполнения задачи, а по вертикали - вероятность. На схеме ниже мы понимаем, что плюс минус за 6 недель мы продукт поставим.
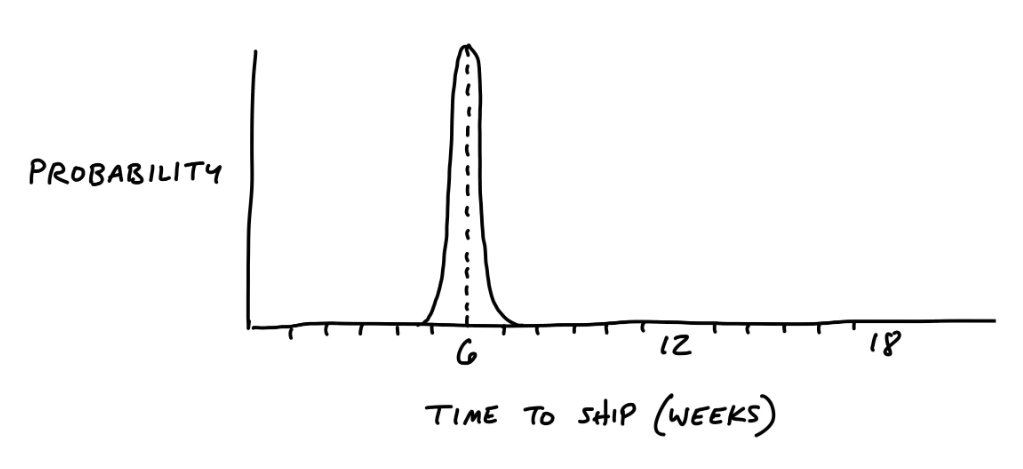
Но, если не работать с кроличьими норами, то есть с рисками, то прогноз будет выглядеть не так радужно. Да, скорее всего мы разработаем продукт примерно за 6 недель, но, возможно вмешается какой-нибудь чертик из табакерки - невыявленные требования заказчика, незапланированная сложная интеграция, невозможность реализации функционала штатными инструментами и так далее. И ответ на вопрос “когда будет готово?” становится гораздо менее определенным - “скорее всего за 6 недель, но если не повезет - то может быть и 12, и 18”...
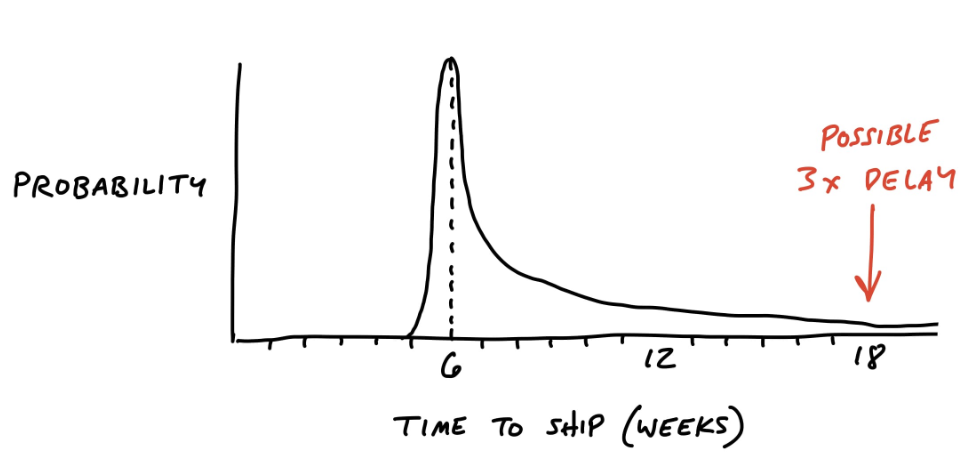
Если вам так же, как и мне, больше нравится картинка, которая сверху, дело за малым - попробовать кроличьи норы найти и закопать. То есть выявить и устранить возможные риски в вашей команде.
Свойство характера - предполагать, что всё пойдет наилучшим образом. Большая часть планов, которые я видела и анализировала предполагали как раз оптимистичный сценарий развития событий.
В какой-то момент я еженедельно наблюдала на совещании одну и ту же картину: сначала менеджеры жестко давили на тимлида дедлайнами, и просили посчитать, сколько времени уйдет на ту или иную задачу. Тимлид честно вместе с ними считал трудоемкость задач, и набивал ими Спринт под завязку. После чего через неделю выяснялось, что существенная часть задач еще не сделана. Менеджер возмущался: почему??? доколе??? у нас релиз/дедлайн/заказчики!!!... Тимлид только флегматично разводил руками: мы заложили план на идеальный вариант развития событий, а дальше на него наложились непредвиденные усложнения в задачах, текучка, срочные задачи по сдаче отчетности бухгалтерией и т. п. После этого происходило планирование следующего Спринта - и опять под завязку!.. Когда менеджеру озвучивали предложение сразу договориться, что в работу берется меньше задач - она возмущалась - у нас же релиз/дедлайн/заказчики, меньше брать нельзя!.. В действительности, конечно же, от того, что в работу бралось больше задач, чем могло бы сделано, степень готовности к релизу не вырастала. Просто падало качество планирования - планы не соответствовали действительности. Ну и отношение к ним было соответствующим - никто и не верил.
Но на самом деле, управление рисками - оно в первую очередь не про закладывание резервов. Когда мы закладываем резервы - мы просто принимаем риск. Да, говорим мы, смиренно сложив руки на груди, этот риск существует, но мы ничего с ним поделать не можем. Нужно быть к нему готовым.
Управление рисками - про проактивное влияние. Когда мы заранее думаем, что может случиться, и заранее предпринимаем меры, чтобы неприятность либо не случилась, либо нанесла наименьший ущерб. То есть мы понимаем, что если наше рабочее пространство заточено на Гугл-диск, Гугл-почту и Гугл-календарь, а есть риск ухода этого сервиса из России - мы не ждем сложив лапки, простите - руки, а заранее предпринимаем меры по защите информации, выстраиванию дополнительных пространств и каналов коммуникации и т. п.
Я очень надеюсь, что большая часть из читающих эту статью в своей работе иногда ищет и закапывает кроличьи норы - даже когда не говорим красивые слова про работу с рисками. Процедура управления рисками - это, по сути, когда мы садимся и думаем - “что может пойти не так?”. И по итогам изменяем наши планы, делая их более надежными и устойчивыми (возможно, в ущерб продуктивности - но зато на пользу безопасности).
Если мы чаще всего и так это делаем, то в чем затык? По моему опыту, загвоздка в первую очередь в следующем:
Во-первых, в регулярности. Чтобы управление рисками работало, важно обсуждать возможные проблемы с регулярной периодичностью. Например, раз в месяц.
Во-вторых, в охвате. Есть занятный психологический эффект (увы, особенно свойственный руководителям, часто высоким), когда мы игнорируем проблемы, в том числе очевидные, с которыми мы не понимаем что делать. В своей книге “Вальсируя с медведями” Том ДеМарко и Тимоти Листер назвали этот эффект “А, вы имеете в виду этот приближающийся поезд…”. Допустим, мы понимаем, что если ключевой разработчик уйдет из команды (или просто временно потеряет трудоспособность) - наша работа попросту встанет, другого сеньора у нас нет, и нет идей, где его искать. Что с этим можно сделать - мы не представляем, и в итоге обсуждаем множество других рисков, но не этот.
Итак - попробую дать несколько советов, как можно выстроить управление рисками в команде.
1. Вести журнал возникших проблем. Чтобы было одно место, в котором можно посмотреть сложности, которые возникают. (задержка сдачи разработчиком работы из-за недостаточной компетентности, неполная проверка работоспособности релиза после обновления 1С, затык из-за задержки смежников и т. п.). При каких условиях такой журнал будет работоспособным?
Важное условие - это должен быть внутренний документ команды, недоступный высшему руководству - чтобы люди не боялись писать свои косяки!..
Не надо пытаться выяснять “Кто виноват?” Актуальнее вопрос “Что делать, чтобы такого не повторилось?” Читала про исследование, которое проводилось на предприятиях, связанных с решением задач, от которых зависят человеческие жизни - в частности, авиастроение. Их опыт показал, что когда разбор инцидента включает в себя выяснение, кто из команды виноват в произошедшем, это, как это ни парадоксально, только снижает эффективность работы. Люди начинают думать в первую очередь не о том, как лучше решить задачу, а о том, как “подстелить соломки” и не оказаться крайним в случае чего. В результате боятся давать новые предложения, проводить эксперименты. Гораздо продуктивнее система, когда при разборе инцидента не занимаются поиском виноватых, а сосредотачиваются на вопросе: “что мы можем сделать, чтобы не допустить подобных проблем в дальнейшем?”. В такой ситуации замотивированные на результат люди сосредоточены в первую очередь на поиске эффективных путей решения.
2. Проводить регулярные мероприятия по анализу рисков. Ключевое слово - регулярные. Как минимум, при составлении квартальных планов (если они у вас есть), в идеале - чаще (каждый месяц).
Откуда брать информацию о рисках?
- Тот самый журнал проблем, который мы создали на предыдущем шаге. Потому что те кроличьи норы, в которые мы УЖЕ провалились - это основа для анализа рисков будущих. Как мы можем избежать повторения аналогичной проблемы в следующий раз? Тут важно не увлекаться решением прошлых проблем - любой полководец легко расскажет тебе, как нужно было выиграть прошлое сражение, беда только в том, что оно больше не повторится. Но ценные мысли в прошлом почерпнуть всё равно можно.
- База знаний по рискам. По мере того, как ваш опыт в управлении рисками будет увеличиваться, у вас появится набор традиционных факторов риска (например, в случае команд 1С это могут быть непроработанная архитектура, зоопарки систем, накапливающийся технический долг и т. п.) и актуальных рисков. И дальше вам остается критически посмотреть на ваши планы и прикинуть, как это может на них повлиять?.. И что можно будет сделать, чтобы повлияло меньше?
- Жизненный опыт и здравый смысл. Задаем себе вопрос: а в какую кроличью нору мы можем провалиться в процессе работы? За счет чего наша команда не сможет выполнить свои задачи? Тут я предлагаю вспомнить старый добрый афоризм “за одного битого двух небитых дают”, и если у вас в команде есть дефицит “битых”, то есть опытных в тех задачах, которые вы решаете, то поискать, у кого можно проконсультироваться. Вы ожидаете, что у вас возникнут сложности при сборе требований с бизнес-заказчиков - потому что заказчики вместо создания тикета норовят прийти в личку с криком души капслоком: “ПАМАГИТЕ, У МЕНЯ ВСЁ СЛОМАЛОСЬ!” - и выяснить, где именно проблема, оказывается крайне сложно. Отнимает время, и, главное, нервы аналитиков и разработчиков. А нервы - ресурс дефицитный.
3. На выходе встречи по рискам - создавать реестр рисков. Экспертно оцениваем степень влияния, вероятность, величину, рисуем тепловую карту рисков.
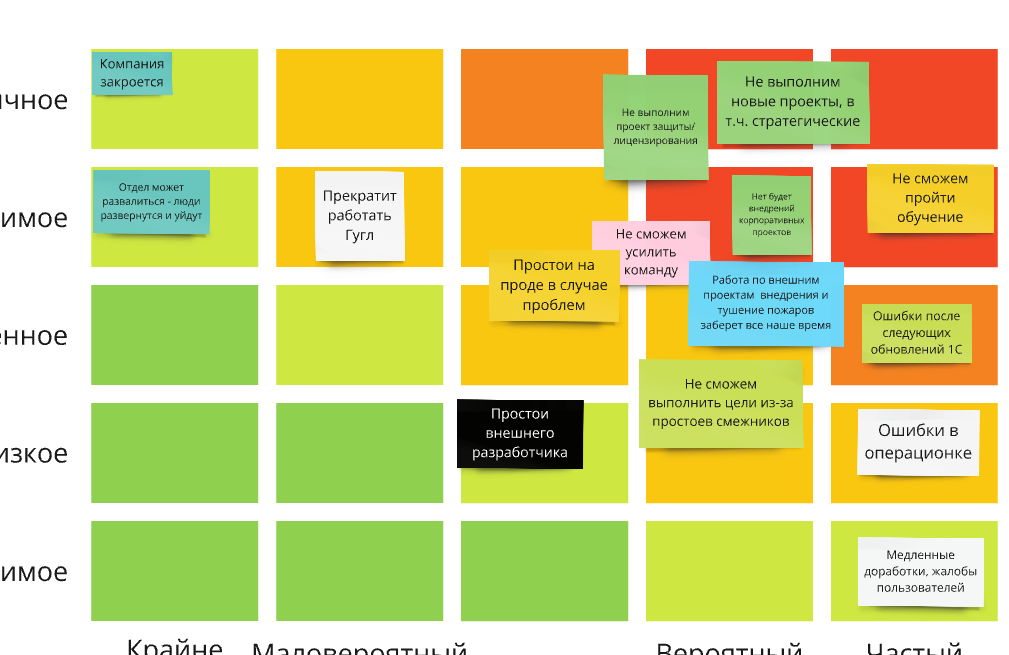
4. Дальше самое главное - определять стратегию реагирования.
Например, можем вспомнить пример выше, что отсутствие внятных инструкций от заказчика не дает возможности разработчикам эффективно решать проблемы.
Нам помогла, например, разработка брифов, в которых заказчик вынужден четко описать проблему/задачу в той форме, чтобы она стала понятна аналитику/разработчику. Без заполненного брифа задача в работу не берется. Брифы могут быть разными, например, удобная формулировка для сообщения об ошибке:
Указывай:
Что делаю, что вижу, что получаю, что ожидаю получить?
И не забудь приложить скриншот.
5. Самое главное: определить конкретные шаги.
Регулярность встреч и оценка величины рисков позволит рисовать профиль рисков. И месяц от месяца можем смотреть динамику, и оцениваем насколько мы продуктивны в проработке рисков.
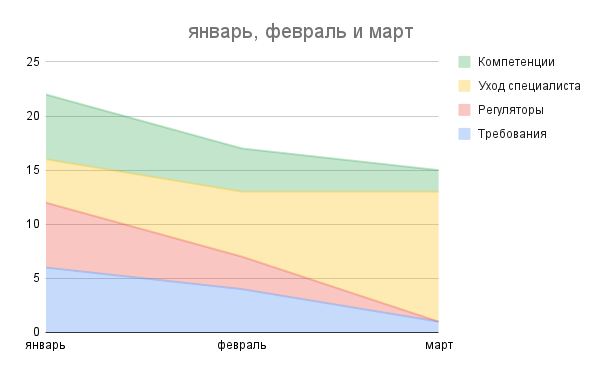
Например, риск снижения продуктивности/потери сотрудников в связи с выгоранием - что здесь можно сделать? На первый взгляд, этот риск останется с нами всегда. Так-то оно так, но снизить его можно точно. В нашей практике помогает проведение регулярных ретроспектив в команде, фиксация недовольства сотрудников жизнью. Кому-то не хватает интересных задач, у кого-то ощущение отсутствия ценности в работе, кто-то просто стабильно перегружен и вынужден работать по ночам. Перераспределили задачи, провели коуч-сессии, кого-то похвалили, с кого-то сняли груз невыполнимых задач (чтобы не давил) - и вот уже видно как на профиле рисков кривая поползла вниз…
6. Вести отдельный бэклог рисков. В чем проблема на практике? Да, мы знаем, что у нас большой технический долг. Да, мы знаем, что его надо делать. Но - систематически не доходят руки (см. выше - дедлайн/релиз/заказчики). Поэтому нужно, во-первых, завести на технический долг тикеты. А во-вторых, добавлять их в Бэклог Спринта наряду с задачами по запросу для заказчиков. И отслеживать их выполнение. Сразу замечание вскользь - если у вас большая часть задач регулярно кочует из Спринта в Спринт - значит, у вас есть проблемы с планированием. Тогда просто “добавить эту задачу в Спринт” не поможет - нужно обеспечить какой-то механизм, чтобы задача была сделана.
Тех, кому интересно подробнее познакомиться с работой с рисками в команде - приглашаю на открытый вебинар по управлению рисками для тимлидов. 7 ноября, четверг (в годовщину даты, когда 107 лет назад актуализировался серьезный риск, приведший к некоторым катаклизмам) в 18:00 мск - поговорим про то, как тимлиду выстроить управление рисками в команде. И жить долго и счастливо, без всяких признаков переутомления и выгорания.