Финансовый аспект внедрения 1С на ORACLE
Первый вопрос, который мне хотелось бы рассмотреть – это финансовый аспект внедрения 1С на ORACLE. У большинства сложилось такое мнение, что внедрение 1С на ORACLE очень дорогое, и что в принципе, если в проекте использовать СУБД ORACLE, то стоимость проекта вырастет на порядок. Это не совсем необоснованное мнение, однако, все-таки хотелось бы разобраться подробнее, из чего будет складываться стоимость проекта, если для его реализации будет выбрана СУБД ORACLE.

Первое – это, конечно, лицензии. Поскольку я не эксперт по лицензированию, я просто набрал в интернете ORACLE и MSSQLServer, посмотрел стоимость лицензий для одного человека (не по SOCKET, не по памяти, не по серверам – а в наиболее упрощенном варианте) и получил приблизительно такие суммы. Как видим, одна лицензия ORACLE стоит даже дешевле, чем аналогичная ей лицензия MSSQL. Для сравнения использую редакции StandartEditionONEORACLE и StandartEditionMSSQLServer, потому что это начальные редакции, и 1С нам большинство «фич», которые есть в Enterprise версиях, запрещает к использованию.
OC на сервер для ORACLE вообще бесплатна (условно бесплатна, конечно) – это LINUX. Дело в том, что ORACLE – это продукт, который изначально разрабатывался под LINUX, и он изначально «линуксовый» - посмотрите на структуру каталогов, на кучу настроечных файликов, на JAVA-интерфейс, - вы сразу это заметите. Для Microsoft – это, соответственно, WindowsServer (другого варианта у нас нет), но даже в StandartEdition версии он все равно стоит 1000 руб.
Сам сервер (железо) – конечно, составит большую долю стоимости проекта, но для сравнения стоимости внедрения СУБД его стоимость нас волновать не будет.
А вот последний пункт (наличие DBA - ORACLEDBAилиMSSQLDBA) – он самый интересный. Если мы говорим о внедрении на MSSQL – то все-таки у большинства были внедрения, в которых можно было обойтись без DBA, поскольку MSSQLServer – это продукт не такой сложный, у него хорошее usability, хорошая методология Microsoft, с его администрированием более-менее можно разобраться самому. Для ORACLE – на маленьких проектах, конечно, есть шанс – на больших проектах (от 100 пользователей), конечно, уже необходим отдельный человек, который будет следить за работой СУБД, который будет администрировать ее работу, будет ею управлять. Графические средства администрирования СУБД ORACLE не такие мощные, не такие красивые и не такие замечательные, как в MSSQLServer.
Основные понятия
Дальше я, по возможности кратко, рассмотрю основные понятия. Без них понять, почему 1С так работает с ORACLE, не получится.
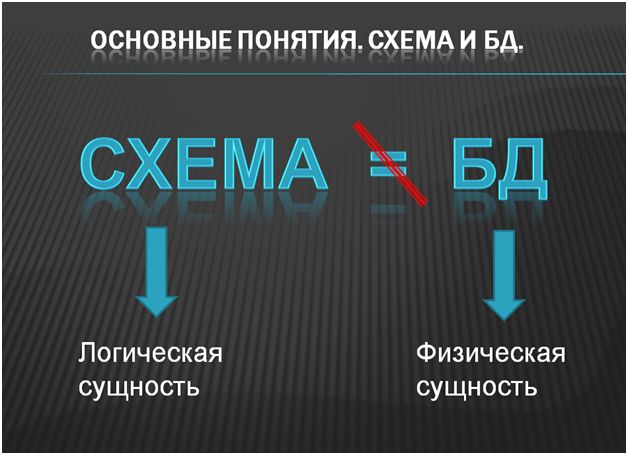
Первое понятие – это схема ORACLE и база данных.
Очень часто, при обсуждении работы 1С на ORACLE, принимается за правило такое упрощение, что для ORACLE база данных это схема. Это самое популярное заблуждение. В нем корень всех проблем (очень многих проблем работы 1С с СУБД ORACLE).
Схема – это логическая сущность. Это группа таблиц. База данных – это физическая сущность. Это группа файлов. Ставить между ними знак равенства – никоим образом не правильно!
Поэтому в ORACLE есть проблемы с резервным копированием, с ведением логов, с перемещением баз данных на отдельный диск и т.д.
1С, для упрощения себе жизни, выбрала схему как инструмент для создания в консоли кластера. Чтобы можно было из 1С создать базу данных, они выбрали вместо нее схему. Дело в том, что создание базы данных в ORACLE – это нетривиальный процесс. Каждая база данных в Oracle - это отдельный сервис, отдельный instance. 1С все это упростила, и для отдельной базы данных использует отдельную схему. Мне кажется, что 1С выбрала неправильную политику. Это некоторый такой обман пользователей. Нет знака равенства между понятиями Схема и База данных. Крупное решение на ORACLE может нормально функционировать только в том случае, если у вас на одном сервере, на одном Instance есть только одна база 1С. Другого варианта нет.
Версионность.
Не буду подробно останавливаться. Скажу только, что есть версионные СУБД и блокировочные СУБД.

В блокировочных СУБД, если одна транзакция уже начала изменять данные, то другая транзакция в этот момент вынуждена ждать. В версионных СУБД другая транзакция может прочитать данные.
Версионная СУБД – это хорошо, блокировочная СУБД – плохо. Однако, версионная СУБД – это не панацея от всех бед, потому что если вы в результате ее использования получите предыдущую версию остатков – вы не очень обрадуетесь. Все равно приходится накладывать управляемые блокировки, все равно параллельно записать ничего не сможете – чудес не бывает!
Блокировочные СУБД – это IBMDB2 и MSSQLServer (надо признать, что в MSSQLServer есть режим Read_Commited_Snapshot, - некая пародия на версионирование – его используют в версии платформы 1С 8.3, еще его используют в MicrosoftDynamics AX). Версионные СУБД – это ORACLEи PostgreSQL. Про Postgre ничего плохого сказать не хочу, это бесплатная СУБД, проект энтузиастов. Лично я не рассматриваю его как СУБД для серьезных проектов. Мне кажется, что среди версионных СУБД, поддерживаемых платформой 1С, ORACLE – единственный полноценный вариант.
За что же любят ORACLE?
Сразу скажу, что в статье будет много плохого про эту СУБД, но есть некоторые положительные моменты, характерные чисто для ORACLE.
Обычно – с СУБД ORACLE связывают качества высокой производительности, unbreakable и т.д.
По моему мнению, суть тут немножко в другом. В Oracle применяются две прогрессивные технологии – RACи ASM.

RAC (кластер типа «активен» - «активен») – это полноценный кластер. Именно полноценный, не как мы привыкли в MSSQLServer. Я сомневаюсь, что кто-то смог реализовать распараллеливание запросов в MSSQLServer по разным серверам (или что это в ближайшее время появится). В ORACLE это появилось давно. Это уже обкатанная на крупных системах технология (для действительно больших систем это необходимо). Вoraclestandardeditionone кластеризация RAC в полной мере не поддерживается.
ASM как правило используется совместно с RAC. Это отдельно устанавливаемый на каждый узел кластера мини-экземпляр Oracle, предоставляющий сервисы работы с дисками и позволяющий избежать обращения к диску (позволяющий работать на RAWdevices - дисках без файловой системы – всю работу по кэшированию данных выполняет сам Oracle)
ASM повышает производительность путем автоматического рассредоточения объектов базы данных по большому количеству устройств, увеличивает доступность базы данных, так как позволяет добавлять в базу данных новые дисковые устройства, не останавливая ее.
ASM автоматически, с минимальным вмешательством в работу производит выравнивание распределения файлов по устройствам.
По сути, управление дисками и ФС автоматизировано и отдано на откуп DBA. В случае использования SAN и большого числа дисков – очень актуально.
Логгирование
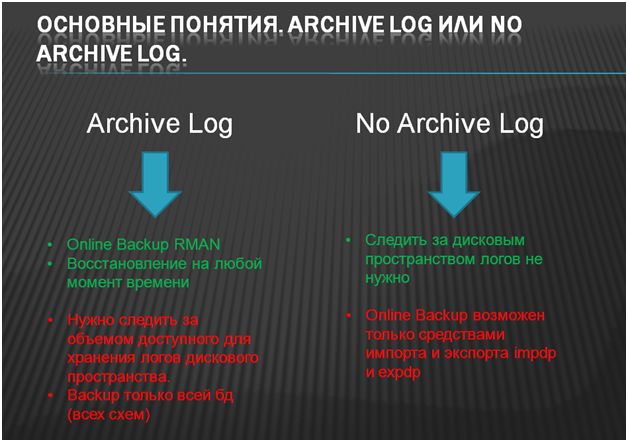
С логгированием все достаточно сложно. Единственное, на что хотелось бы обратить внимание, что если мы работаем в режиме ArchiveLog – мы можем делать полноценные Backup-ы, а если мы работаем в режиме NoArchiveLog – мы полноценных Backup-ов делать не можем (только средствами impdp и expdp).
В режиме ArchiveLog если у вас на сервере есть более 1 БД 1С и вы хотите использовать полнофункциональные бэкапы – понадобится вторая БД, созданная специальным образом, для восстановления бэкапа, чтобы потом средствами datapump перенести в основной сервер. Вообще в 90% случаев для 1С будет NoArchiveLog. Всё зависит от выбранной стратегии резервного копирования и SLA (если таковой имеется). По сути ArchiveLog – банальная ротация, но без неё online резервное копирование невозможно. Если кончится место для ArchiveLog, 1С тупо упадёт.
Табличные пространства в Oracle
Интересная тема. В MSSQLServer-е табличные пространства – это просто группа файлов. В ORACLE это понятие сильно расширили, т.к. в ORACLE по традиции для файлов нужно увеличивать начальный размер и приращение, т.е. для ТП можно задать размер блока, bigfile, ведение логов. Если не bigfile, то ограничение 32 ГБ.
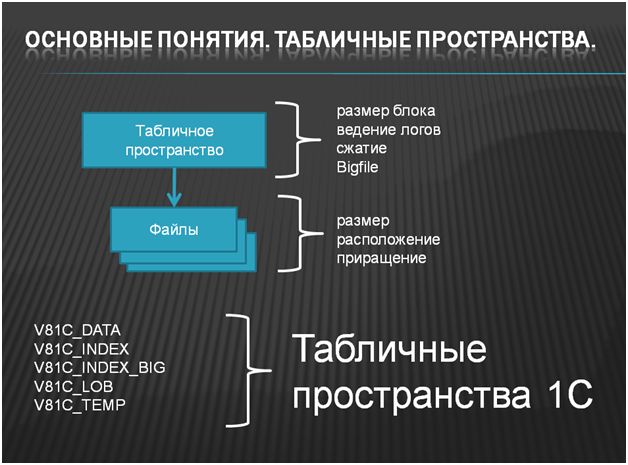
Табличные пространства 1С:
- Data – Сами таблицы
- Index – индексы
- Index_Big – размер блока 16КБ. Если индекс не удаётся создать в Index, платформа пытается создать его в Index_big. Еще нужно установить размер кэша для 16 КБ блоков. Собственно, размер блока можно варьировать. Чем меньше – тем быстрее запись. Чем больше, тем быстрее чтение больших объемов
- LOB – хранилища значений и строки неограниченной длины. Очень хорошо, что разделили. Теперь можно, не нарушая лицензионного соглашения, вынести весь мусор на отдельный диск
- Temp – tempdb. Нужен очень быстрый дисковый массив.
Хотелось бы обратить внимание на табличное пространство 1С V81C_LOB. ORACLE на данный момент времени единственная СУБД, в которой есть полноценное хранение файлов и строк неограниченной длины. В ORACLE мы можем файлы и строки неограниченной длины переложить на отдельный диск. Что это значит? Мы можем, к примеру, внедрять 1С:Документооборот в больших компаниях, на больших объемах данных и при этом не ставить эту галочку, которую все любят – «хранение файла во внешнем хранилище». ORACLE позволяет нам хранить все наши файлы непосредственно в базе данных (эта база данных будет размещена на нескольких дисках). Самое интересное, что не только ORACLE – любая СУБД нам позволяет это сделать, просто лицензионное соглашение 1С накладывает ограничения – для любых других СУБД стандартных средств переноса файлов и строк неограниченной длины на отдельное дисковое пространство сервера у нас нет. А в случае с ORACLE 1С догадались выделить для этого отдельное табличное пространствоV81C_LOB. Замечательная «фича».
Еще несколько основных понятий:
- REDOLOG (текущий лог) – Нужно следить за размером свободного пространства. Можно отключать. Oracle «не прощает ошибки». Если заканчивается место под логи – просто «падает». Если нет Backup-ов, то и логи не нужны
- ALERTLOG(технологический журнал) - /u01/app/oracle/diag/rbms/main/OID/alert смотреть в него придётся даже если есть dba
- LISTENER (организация сетевого доступа) – при работе с MSSQLServer мы не привыкли, что сетевой доступ к базе – это отдельное приложение
- SYSDBA (режим работы с базой) - root для oracle – обычные действия в этом режиме недоступны. Режим только для администратора.
С основными понятиями разобрались. Теперь перейду к «основной статье» - буду рассказывать конкретно о работе ORACLE с 1С.
Проблемы разработки 1С на ORACLE
Первая и самая главная – специфичная лингвистическая сортировка. Если мы говорим о работе в ORACLEс текстовыми строками, то это, наверное, главная проблема.
Платформа 1С использует одинаковые механизмы работы со всеми вариантами СУБД (в том числе с файловой версией). Соответственно, сортировку строковых значений в таблицах баз данных платформа 1С реализует по своим правилам. В частности, если в строке присутствуют точка или запятая, то для 1С это будет влиять на сортировку. В ORACLE, которая ориентирована на стандарты, точка или запятая на сортировку не влияют. Из-за такой элементарной проблемы 1С пришлось городить целый «огород» - использовать функцию NLSSORT для того, чтобы была своя сортировка. А уже использование этой функции повлекло существенные модификации.
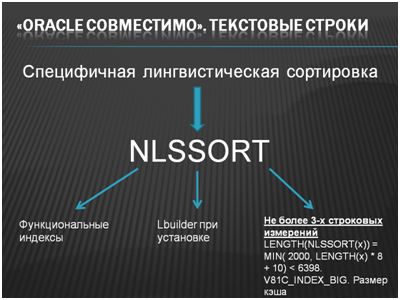
Любой индекс и любая сортировка по строке, которые у вас есть, будут использовать функцию NLSSORT (неявно ее вызывать). Использование этой функции вызывает также обязательность установки для работы ORACLE с 1С специфичного приложения Lbuilder (это единственное, что отличает установку ORACLEдля 1С от простой установки ORACLE).
Чем это грозит для разработчиков? А для разработчика это грозит тем, что у вас (по умолчанию) не будут работать регистры, имеющие более 3-х строковых измерений. И еще тем, что размер строкового индекса будет очень большой. Короче – любая длинная строка в регистре сведений либо в регистре бухгалтерии, либо в регистре накопления – это очень плохо. Любой индекс по строке – это тоже плохо, и сортировка по строке – это тоже плохо. Однако, в целом, функциональный индекс работает быстро. То, что такие строковые индексы в табличном пространстве V81C_INDEX_BIG занимают большие объемы, конечно, не очень хорошо, но не критично. Просто нужно знать, что в целом регистр накопления с измерением типа «Строка» - это архитектурная ошибка. В частности, ORACLE просто об этом напоминает.
Дальше – еще одна очень неприятная новость. ORACLE не использует кластерные индексы. То есть ORACLE, конечно, использует кластерные индексы – они там называются IOT – это более правильное название для кластерных индексов в ORACLE. Просто 1С на ORACLE кластерные индексы не использует, а создает обычные индексы.
Чем это нам грозит? При работе 1С на ORACLE скорость записи у нас увеличивается, в отличие от других СУБД – кажется, что это плюс. С другой стороны – скорость чтения снижается. При работе с другими СУБД 1С строит кластерный индекс для любых ссылочных типов по ссылке – это наиболее быстрый способ выбора данных. А при реализации движка работы с ORACLE 1С пришлось от кластерных индексов отказаться. И мне иногда интересно наблюдать в интернете тесты, где красиво представлено, что когда решение работает на ORACLE, оно так быстро записывается, а читается чуть-чуть медленнее. На самом деле – это не совсем проблема ORACLE – это просто логика работы 1С. Если об этой логике знать – то ничего удивительно в этом нет.

Еще два неприятных момента
- по типу NULL у всех СУБД, кроме MSSQLServer, ведется обратный порядок сортировки.
- Временные таблицы – мы все уже привыкли к ним. Все разработчики с ними работают, но в случае использования ORACLE – временные таблицы становятся не совсем временными. Я считаю, что у разработчиков 1С это была методологическая ошибка – поскольку временные таблицы в ORACLE предназначены совсем для другого. Вцелом ORACLE не рекомендует использовать временные таблицы для сохранения промежуточных результатов. Там промежуточный результат сохраняется во вьюшках. 1С хранит этот промежуточный результат во временных таблицах, а эти временные таблицы создаются в базе как обычные таблицы и ничем от них не отличаются. Создаются, потом используются…. Очищаются. Но в словаре остаются. Кроме того, временные таблицы в ORACLE ориентированы на жесткую структуру, разве что данные из них используются только в рамках сеанса. Разделяются для каждой сессии, поэтому даже с включенным dynamic_sampling никто не обещает корректного плана выполнения запроса. Это не говорит о том, что не надо использовать временные таблицы, их надо использовать. Просто если, например, я сам писал запрос, в котором временные таблицы генерировались программно при сборе запроса, то это при работе на ORACLE вызовет существенные проблемы: если у вас в запросе 200 временных таблиц, то запрос при первом выполнении на ORACLE – хорошо, если выполнится, а может выполняться очень долго.
Не хочется произносить слова «баги», но всё-таки придётся. Слайд отчасти дублирует предыдущие.

- Если вы разрабатывали хотя бы раз конфигурации под управляемое приложение – вы, безусловно, знаете, что такое БСП. БСП на ORACLE даже не запускается… Проблема копеечная – быстро решается, можно было бы просто немного переписать запрос или внести маленькую модификацию в платформу, но – до сих пор эта проблема не решена (три последних релиза БСП эта проблема существует). Вызвана эта проблема тем, что в перечислениях обращение к реквизиту «порядок» приводит к ошибке. Напомню, что БСП – это основа всех последних решений 1С. 1С позиционирует БСП как «основной инструмент разработчика» и «флагманский продукт», не обращая внимания на эту ошибку. Это значит, что даже первичного тестирования работоспособности на ORACLE не проводится.
- Про проблему с БД (с ее резервным копированием и обслуживанием из-за использования схемы как БД) уже сказал. Резервное копирование в ORACLE – либо у вас одна база на Instance - Production, либо у вас резервное копирование осуществляется только средствами импорта (нет дифференциального, нет разностного резервного копирования).
- С временными таблицами и чтением данных из 1С в oracle всё плохо.
- Технологический журнал 1С от ORACLE не получает плана запросов – пока что эта фича не работает.
- Нормального Профайлера, как в MSSQL, нет – не найдёте. Есть куча различных LogAnalizer-ов. В т.ч. умеют Toad и Spotlight, о которых речь пойдёт ниже. Но Online, графического плана запроса, полноценной фильтрации не найти. Конечно, профессиональные ORACLEDBA умеют анализировать загруженность – они запускают консольные средства, генерируют html-файлики… Но это уже не «два клика» - следовательно, если на проекте идет речь об анализе производительности, то обязательно необходим ORACLEDBA.
- Оптимизатор Oracle не ориентирован на обширное использование вложенных запросов и, как правило, выбирает достаточно простой план выполнения для соединений (NASTEDLOOPS).
На этом слайде я собрал все то, что нарушает лицензионное соглашение 1С (1Сзапрещает нам использование данных возможностей). Тут есть некоторые важные моменты:

- Секционирование (в ORACLE его 6 видов, таблицу можно разбить на 2 диска) – 1С использование секционирования не предусматривает
- Storedoutline – «подсказки» оптимизатору. Насколько я знаю, в MSSQLServer мы можем повлиять на план запроса только косвенно (то есть мы раньше, чтобы блокировок в базе MSSQLServer не было, добавляли в регистр 2000 записей) – в ORACLE все гораздо проще. Oracle позволяет управлять планами запросов. 1С использование этой возможности не предусматривает
- Mat. View – индексированные представления, которые могут использоваться вместо таблиц. 1С также не использует эту возможность
- Сжатие
- Битовые индексы – вкратце – индекс по организации. Все, кто отслеживал историю становления прикладных решений фирмы 1С, могли обратить внимание: сначала реквизит «Организация» во всех документах был индексированным. Потом – развитие конструкторской мысли архитекторов прикладных решений 1С привело к тому, что реквизит «Организация» перестал быть индексированным. Логично. Организаций обычно 3-4 штуки, селективность маленькая, индекс не используется, он лишний. Потом опять появились рекомендации о том, что этот реквизит нужно добавлять в индекс. Это, что называется, «на безрыбье и рак рыба». Реквизит «Организация» - это типичный случай битового индекса. Когда у вас низкая селективность, но – при этом он везде используется, по нему везде есть отборы… К сожалению, эту возможность Oracle мы тоже не можем использовать…То есть можем, конечно, НО…
Параметры
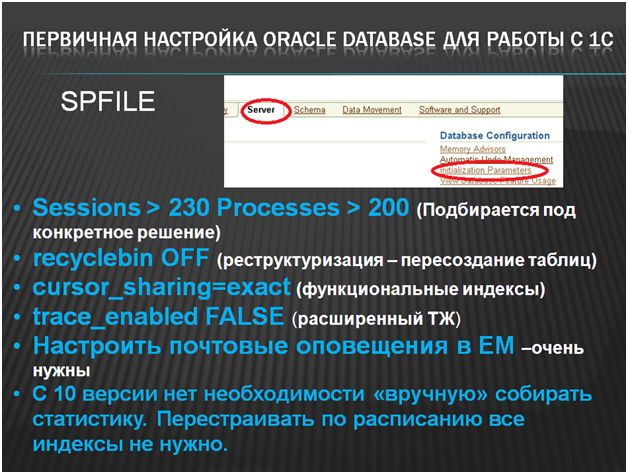
По умолчанию Oracle подойдёт только для тестовой среды. Обязательно при первичной настройке необходимо выставить следующие параметры:
- Sessions>230иProcesses>200. SessionsиProcesses всегда почти не хватит. В production не преступно увеличить до 200. Сессий может быть чуть больше. По сути, процесс – это соединение, но есть куча внутренних процессов
- Trace_enabledFALSE(расширенный технологический журнал) не SQLTrace конечно, но всё равно не нужен постоянно… да и нам не поможет
- RecyclebinOFF (Корзина) – можно только поулыбаться. По умолчанию, в ORACLE включено очень много всего. Корзина тоже по умолчанию включена – что правильно – потому что, если вы удаляете таблицу, то она помещается в корзину, а не удаляется. Очень радует, что она работает не на удаление строк – только на удаление таблиц. А в 1С любая реструктуризация – удаление таблиц… 1С вообще оригинально работает с базой данных в случае реструктуризации. Если вы реструктуризируете базу, то у вас таблица удаляется и создается заново. Добавили критерий отбора или общий реквизит и объём базы вырос в 2 раза J. Поэтому – конечно, корзину надо отключать
- Почтовые оповещения – оповещают о проблемах, заканчивающемся месте и т.п., если вовремя отреагировать, можно предотвратить «падение» Оракла. Обязательно включите!
- Cursor_sharing - управляет механизмом поиска запроса в кэше запросов. Чтобы уменьшить время на распарсивание запросов, надо сразу ставить exact. Менять нельзя – перестанут использоваться функциональные индексы. Т.е. все…
EXACT - ищется запрос, точно совпадающий с вашим. Никакой перезаписи вашего запроса (использование переменных связывания) для возможного использования другими сессиями не производится. С одной стороны, куча мелких запросов со сложными конструкциями - типичная ситуация для 1С: тратится много времени на их компиляцию
FORCE- ищется запрос, совпадающий с вашим запросом с точностью до связных переменных. Перезапись осуществляется: все литералы заменяются на связные переменные, план создается для «усовершенствованного» запроса
SIMILAR (появилось в 9i) -выполняются те же действия, что и при FORCE, но к тому же осуществляется проверка: можно ли подобрать аналогичный уже разобранный запрос, который не должен изменить план вашего запроса. То есть, если оптимизатор решит, что для выполнения вашего запроса нужен другой план, нежели в уже разобранном, то ваш запрос будет полностью разбираться - Статистика очень важна для CBO. Но в 10 версии Job сбор статистики есть уже системный, притом собирает статистику только по тем таблицам, по которым нужно. Тем не менее,сбор статистики можно запустить и вручную.
Параметры Backup-ов
Дальше – параметры Backup-ов. В ORACLE, если, не дай бог, нет администратора базы данных, нужно обязательно включить автоматическое управление памятью (AMM), иначе через какое-то время Oracle работать перестанет, а также в случае использования средств impdp и expdp – обычных средств импорта/экспорта отключить ArchiveLog и RedoLog ограничить.
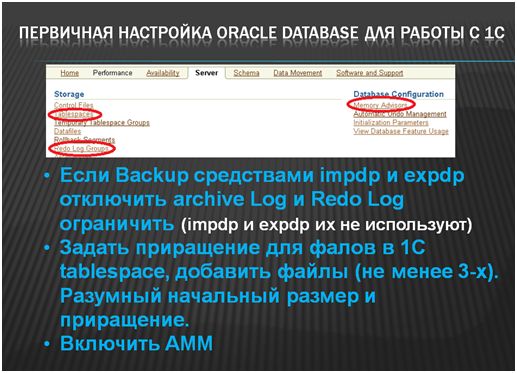
Тонкая настройка
- Вот еще один интересный параметр – optimizer_index_cost_adj - существенная настройка. Если мы поставим его в значение 1, то ORACLE будет использовать все индексы, которые только может. Чем меньше, тем ниже порог использования индексов. То есть, если у нас в справочнике всего 3 значения, то при значении этого параметра 1 у нас все равно все индексы будут использоваться. Если мы оставим значение по умолчанию (100) – то у нас будут использоваться индексы только в том случае, если мы выбираем одну запись из миллиона. Очень хорошо, что мы можем этим варьировать – в SQLServer, например, нельзя. Лучше всего выставить в 30, т.к индексы у нас только штатные
- Fileststemio_options = SETALL – отменяет использование файловой системы (можно использовать дисковые устройства без файловой системы: существенно повышается производительность, выполняется прямое обращению к диску - всю работу по кэшированию данных выполняет сам Oracle).
- Redo log group members > 2 Redo log groups > 1 – уменьшить число переключений

Средства администрирования ORACLE
Если обслуживаемая база ORACLE не имеет ORACLEdba, то без средств администрирования не обойтись (если вы конечно, не фанаты консоли и не горите желанием много писать в черном экране).
EnterpriseManager
SQLDeveloper
Другой инструмент для администрирования СУБД ORACLE – это SQLDeveloper. Этот инструмент больше всего похож на ManagementStudioMSSQL. Но реально этот инструмент можно использовать только для построения запросов и создания таблиц вручную.
TOAD
Spotlight
Очень красиво, правильно и быстро выявляет все текущие проблемы, даже вариант решения предложит. Показывает на одном экране все аспекты производительности.
В
Техническая поддержка
Как видите, разнообразие поддерживаемых языков поражает. По поддерживаемым языкам можно сделать вывод, в каких странах располагается основная масса специалистов oracle.
Собственно, специалистов высокого уровня ожидать там трудно. Просто могут хорошо покопаться во внутренней БД и внутренних ресурсах.
Обычно ответ приходит в течение дня.
Кроме сервиса обращений там же доступ к БД техподдержки и доступ к скачиванию обновлений.
Но сами обновления - целая история. Обновления включают перекомпиляцию схемы, пересоздание некоторых таблиц. Обновления выполняются только в консоли. Это не MSSQLServer и не WindowsUpdate, где «нажали кнопочку и все обновилось». Это целый день работы dba.
Последний вопрос, на который каждый из вас уже, наверное, сам себе ответил – это вопрос о том, когда же нам все-таки нужен ORACLE, когда от его использования на проекте будут какие-то преимущества?

Если у вас есть ORACLEDBA, тогда все озвученные мною проблемы – они все небольшие, они все решаемые, а ORACLEDBA – это такой человек, который может сделать работу вашего решения на Oracle красивым и корректным. Особенно если вам удастся в чем-то договориться с 1С или 1С разрешит нам использовать какие-то фичи из тех, которые я перечислил. Грамотный DBA может ускорить запуск и правильную работу вашего решения раза в два. Потому что количество средств, которые ORACLE нам предоставляет, действительно поражает.
Кластер в ORACLEпоявился уже давно – RAC – очень продуктивная технология, проверенная временем. Она используется в крупных организациях. Если у вас проект, в котором планируется несколько тысяч (несколько десятков тысяч) подключений – даже через разделитель, то RAC – это единственный вариант, который позволит вам полноценно это организовать с точки зрения СУБД. В частности, если 1С сейчас ориентируется на «облака», и у вас уже есть свое «облако» или вы планируете его сделать – то в этом случае, наверное, ORACLE – это самый полноценный выбор.
Однако решение на ORACLE – это специфичное решение. Если вы захотите использовать секционирование, захотите использовать math. view, захотите использовать какие-то другие «фичи» ORACLE, то тут конечно, надо будет постараться «договориться с 1С», поскольку на данный момент эти «фичи» 1С нам использовать не разрешает. Однако – решения, использующие такие «фичи» есть, и эти решения даже получили «1С:Совместимо» - например, решение, использующее прямую запись проводок.
А в других случаях лучше обойтись MSSQL.
*******
Статья написана на основе доклада, прочитанного на Конференции IE 2012 (15-16 ноября 2012 года). Также она опубликована в журнале Инфостарта №1
Приглашаем вас на новую конференцию INFOSTART EVENT 2019 INCEPTION.