






Вступление.
В последние годы я все чаще сталкиваюсь с внешними решениями в области управления товарными запасами, логистическими операциями, WMS и CRM. В той или иной реализации эти решения представляют собой даже не сторонний по отношению к 1С софт, который решает отдельные задачи, а, как правило, внешние ресурсы, которыми владеют третьи лица и на которые мы отправляем данные из 1С, чтобы получить результат их обработки какими-то (как нам говорят) сверхсложными алгоритмами на супермощных серверах. Ибо это же Big Data, ребята, и куда Вы со своим унылыми софтом и вычислительной мощностью лезете?
Конечно 1С, это не Боливар, и слишком многих он не вынесет, но взглянуть под капот имеющихся решений мне хотелось все больше и больше. А одна из самых загадочных подсистем, включенных в платформу 1С это подсистема анализа данных. Причем ее загадочность обусловлена не столько сложностью применения, а отсутствием внятной справки и примеров использования. Ну и, может быть, сложностью математического аппарата используемого при анализе.
Вот отсюда и родилась идея сесть и спокойно разобраться в этом вот всем, решив по ходу ряд понятных примеров.
Как Вы понимаете кластерный анализ это лишь часть возможностей подсистемы анализа данных, так что здесь пахнет циклом статей, но обещать всего, и тем более сразу не буду.
Итак, можно считать что с предисловием к будущему циклу я закончил, теперь перейдем непосредственно к кластерному анализу. А начнем с постановки задачи.
Постановка задачи.
Давайте представим, что у нас есть розничный on-line магазин в котором очень много клиентов и товаров тоже не мало. И есть какая-то CRM-ка в рамках которой имеются сведения, введенные пользователями в их профиле. Плюс, конечно, информация об истории взаимоотношений (просмотров, обращений, жалоб, комментариев, оценок и т.п). А также есть история покупок.
В общем-то, учитывая количество наших клиентов это все уже достаточно большая Data, пользы от которой, если мы ее не обработаем не будет никакой, а расходы, связанные со сбором и хранением имеются. И вот здесь важно понять, что с этим можно сделать и как коммерчески эффективно это использовать.
Это, конечно, задача маркетологов, а нам как программистам необходимо требовать ТЗ и понимать при этом, что никакого внятного ТЗ от них мы не получим. Зато на нашего маркетолога (или его начальника) выйдут маркетологи или продавцы компании, продающей услуги по обработке данных и впарят что-то, что должно выдать по нашим же данным понятный нашим маркетологам результат и бизнес станет эффективнее аж на 100500%.
И вот в промежутке между требовать ТЗ и купить слона на стороне наш правильный программист может сделать презентацию возможностей обработки данных непосредственно в 1С. Про сравнительную экономию, безопасность данных и возможность гибкого изменения механизма - это описывать не буду. Все люди опытные и умные. Ниже просто условный пример на условных данных кластеризации, анализа и прогнозирования поведения покупателей по мотивам всех имеющихся в нашем распоряжении Data. Или почти всех.
Разделение на кластеры.
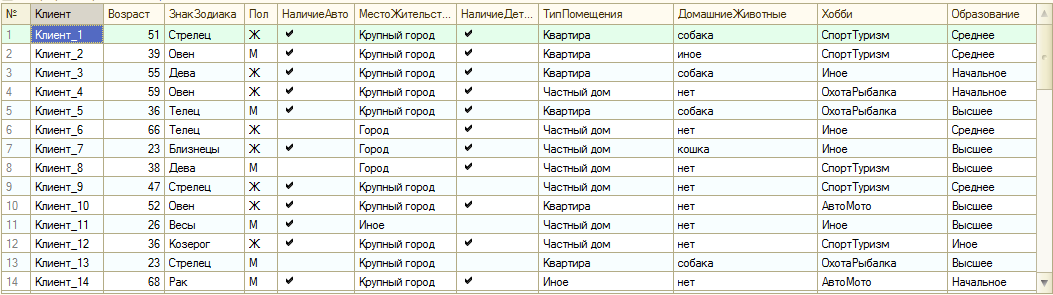
Давайте представим, что где-то в виде большой таблицы значений или результата запроса мы получили кучу непонятно как связанных между собой данных. Для примера я взял данные из профиля пользователя типичного интернет-магазина и усредненные данные по продажам пользователей за последний год. Данные по продажам разделены по категориям товаров. Думаю все это понятно из самих данных:
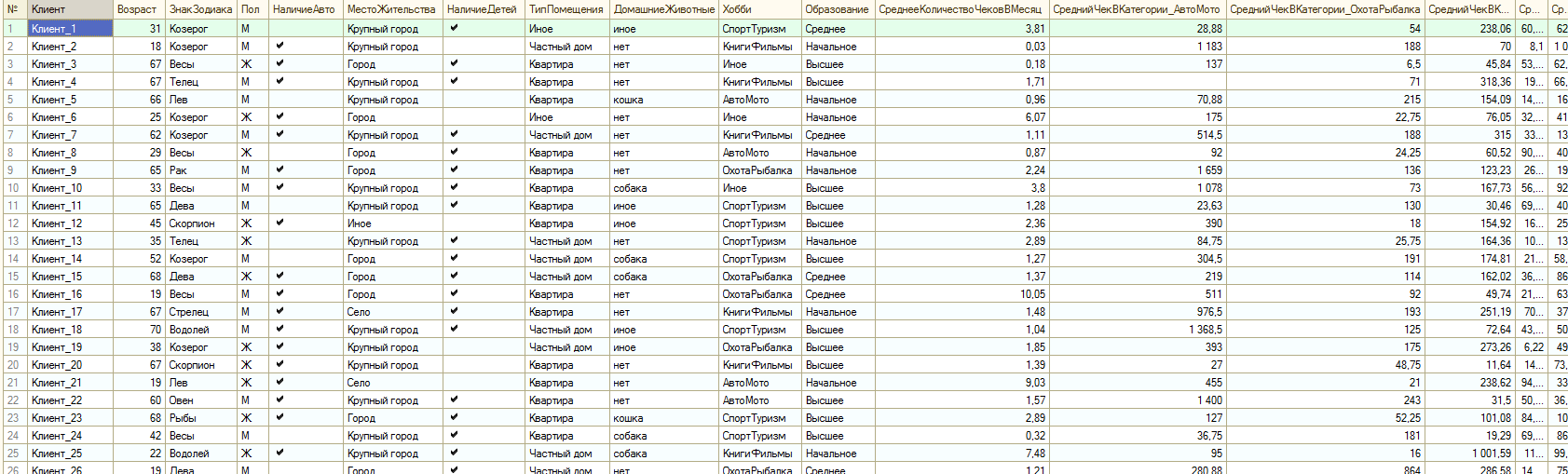
Данных может быть сколь угодно много и самой различной, как Вы поняли, типизации. Для механизма анализа это не принципиально. Не претендуя на оригинальность я назвал имеющуюся таблицу источника данных для анализа тИсточника.
И еще я решил, что кластеров должно быть 5. Опять же 2,3,4,6,7 и т.д. ничем не хуже. Просто так решил. Или, допустим, у нас есть 5 менеджеров по работе с клиентами и я хочу, чтобы кластер покупателей был закреплен за менеджером. В общем это не константа. Когда будем исследовать результат я еще вернусь к вопросу их количества.
А вот и сам код инициализации анализа:
Анализ = Новый АнализДанных;
Анализ.ТипАнализа = Тип("АнализДанныхКластеризация");
Анализ.Параметры.КоличествоКластеров.Значение = 5;
Анализ.Параметры.ТипЗаполненияТаблицы.Значение = ТипЗаполненияТаблицыРезультатаАнализаДанных.ВсеПоля;
Анализ.ИсточникДанных = тИсточника;
Дальше необходимо назначить тип и вес колонок источника. Не тип значений в колонках, а тип взаимоотношений анализа и данных в колонке. Тип колонки определяется логикой анализа. Как и вес, конечно.
Давайте посмотрим на исходные данные и постараемся понять какие данные будут влиять на отнесение покупателя к тому или иному кластеру. Скорее всего это будут все наши колонки из CRM, кроме наименования покупателя, ведь возраст, пол и т.д. вполне могут влиять как на интенсивность покупок, так и на предпочтения покупателя. Как и знак зодиака, хотя я лично в это не верю, но гипотетически... В общем-то, включив его во входящие параметры я ничего не потеряю, кроме времени обработки, зато полученные результаты позволят подтвердить или опровергнуть гипотезу о влиянии гороскопа на поведение покупателей. Если этот фактор окажется не существенным, то он будет поровну присутствовать во всех кластерах. И не более.
И еще мы должны ответить на вопрос о целях кластеризации. Если мы хотим в результате что-то спрогнозировать, то тип колонки для таких данных будет Прогнозируемый. Очевидно, что в нашем примере это будут колонки количества чеков и суммы по категориям товаров в чеке. Это необходимо для планирования продаж и маркетинговых мероприятий. Но в то же время эти данные могут быть поданы на вход анализа для существующих покупателей. Все опять же зависит от цели анализа.
Допустим мы хотим поручить разработку маркетингового мероприятия для каждого кластера его менеджеру. И установить цель, чтобы после реализации мероприятия продажи в кластере увеличились на 20% сверх ожидаемых значений. Очевидно, что нам нужно получить прогноз по кластеру именно в продажах и включить сумму прогноза +20% в KPI менеджера.
В этом случае мы должны сделать данные о продажах и входящими и прогнозируемыми, чтобы опираться при прогнозе не только на возраст и пол, но и на качественную историю продаж.
Итак, на данном этапе мы установим колонку с наименованием покупателя, как НеИспользуемую. Колонки из CRM как Входящие и колонки с показателями продаж, как ВходящиеИПрогнозируемые.
Теперь вес. Вес - это значимость колонки в анализе. По умолчанию он для каждого показателя равен 1. Но мы можем его уменьшить или увеличить в зависимости от контекста задачи. Так как потребительские предпочтения мужчин и женщин, как правило, очень сильно отличаются и я в этом твердо уверен, то я могу сознательно увеличить вес показателя пола до 2. Можно этого и не делать, особенно если выборка достаточно велика и правильное разделение скорее всего произойдет без наших подсказок.
Определив типы колонок и веса для таблицы источника данных из цели анализа и смысла показателей, записываем это кодом:
Анализ.НастройкаКолонок.Клиент.ТипКолонки = ТипКолонкиАнализаДанныхКластеризация.НеИспользуемая;
Анализ.НастройкаКолонок.ЗнакЗодиака.ТипКолонки = ТипКолонкиАнализаДанныхКластеризация.Входящая;
Анализ.НастройкаКолонок.Возраст.ТипКолонки = ТипКолонкиАнализаДанныхКластеризация.Входящая;
Анализ.НастройкаКолонок.Пол.ТипКолонки = ТипКолонкиАнализаДанныхКластеризация.Входящая;
Анализ.НастройкаКолонок.Пол.ДополнительныеПараметры.Вес = 2;
//...
Анализ.НастройкаКолонок.СреднийЧекВКатегории_ТоварыДляДетей.ТипКолонки = ТипКолонкиАнализаДанныхКластеризация.ВходящаяИПрогнозируемая;
Дальше выполняем сам анализ и выводим результат в специальный построитель отчета для анализа данных. Да. Есть такой специальный построитель. Для вывода ему нужны лишь результат анализа и табличный документ.
Ну и подсказка о применяемом типе анализа, конечно. В общем все просто.
Если же Вы не собираетесь анализировать результаты, то вывод отчета можно пропустить и сразу перейти к прогнозам. Но мы все-таки посмотрим на результат:
РезультатАнализа = Анализ.Выполнить();
Результат = Новый ТабличныйДокумент;
ПостроительОтчетаАнализаДанных = Новый ПостроительОтчетаАнализаДанных();
ПостроительОтчетаАнализаДанных.Макет = Неопределено;
ПостроительОтчетаАнализаДанных.ТипАнализа = Тип("АнализДанныхКластеризация");
ПостроительОтчетаАнализаДанных.Вывести(РезультатАнализа, Результат);
Результат.ПоказатьУровеньГруппировокСтрок(1);
Результат.Показать();
И вот что у нас получилось:
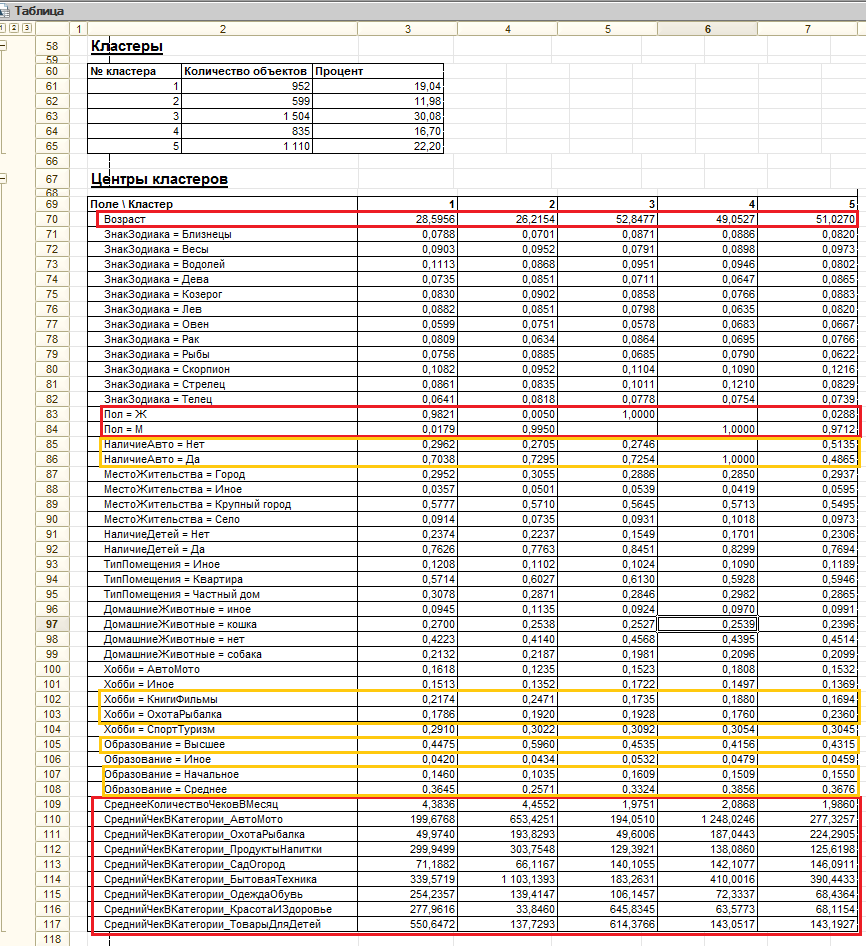
В результатах, как видим, у нас 5 кластеров и целая куча каких-то свойств.
Анализ данных.
Так как входящих данных было довольно мало, то все уместилось в пределах экрана и я на глаз отметил то, на что нужно обратить внимание в первую (красным) и вторую (оранжевым) очередь. Это, как можно заметить, значения свойств выборки по которым между кластерами наблюдается наиболее существенная вариация. Также можно заметить, что для непрерывных (числовых) величин как центр кластера выводится среднее значение, а для дискретных (строка, булево и т.п.) частота конкретного значения в кластере. То есть в каждом кластере сумма значений для Пол = М и Пол = Ж равна единице, как и сумма частот всех знаков зодиака.
Теперь можно дать описание кластеров, используя самые значимые по частоте и вариации признаки. Конечно оценить на глаз вариацию по частоте редких значений тяжело (например, различия между кластерами в значении Образование = Иное), но если сам случай редкий, то он едва ли станет значимой особенностью кластера.
Например:
Кластер1 - это молодые женщины в основном с автомобилями, совершающие покупки чаще 4-х раз в месяц и в основном интересующиеся товарами для детей и бытовой техникой.
Кластер6 - это пожилые мужчины лишь половина из которых имеет автомобиль, но они серьезно увлекаются охотой, рыбалкой и туризмом. Совершают покупки около 2-х раз в месяц. Меньше всего интересуются одеждой, обувью, косметикой и детскими товарами.
И вот именно здесь, если кто-то дочитал до этого места, как пасхалку, я дам простое определение кластера. Думаю, что к этому моменту повествования определение стало уже очевидным, но на всякий случай сформулирую: если каждого покупателя представить точкой в многомерном пространстве, измерениями которого служат колонки входящих данных, то кластерами будут облака или группы точек расположенных относительно близко друг к другу.
Ясно, что описания и глубокие мысли при виде таблицы описания кластеров совсем не наше дело. Для этого есть специально обученные люди. Но в рамках условного примера я, не претендуя на глубину и ширину мысли, все-таки сделаю ряд выводов и предложений:
1. Кластеры 3,4,5 покупают намного реже чем 1,2. Самая очевидная мысль - это связано с возрастом покупателей. Может для них такой способ приобретения просто непривычен, может слишком сложный интерфейс сайта и оформления покупки и т.д. Что с этим делать? Можно провести дополнительный анализ, разбив исследуемый кластер на новые кластеры. Может быть кроме возраста мы увидим в новом приближении еще какие-то важные для интенсивности покупок факторы: пол, наличие детей и т.д. Можно просто сделать репрезентативную выборку по кластеру и посадить менеджера на обзвон клиентов для выяснения причины. В любом случае мы должны сформулировать план действий, результатом которого должно стать выявление причины и меры по повышению интенсивности продаж в кластерах.
2. Аналогично п1 можно проанализировать почему кластеры 3,4,5 намного меньше покупают бытовой техники и сделать выводы.
3. "Мужские" кластеры 2,4,5 покупают в разы меньше товаров для детей. В чем причина? Может быть они просто не знают о существовании такого раздела на сайте?
И.т.д.
Замечу, что данные примера это чисто условная модель и реальность может оказаться совсем иной. Главный вывод для нас программистов состоит в том, что по результатам анализа мы должны выдать аналитикам не только параметры кластеров, но и состав самих кластеров, чтобы дальше делить уже эти кластеры на подкластеры, опрашивать покупателей кластера или вести по ним маркетинговый обстрел.
Так где же состав самих кластеров? Он находится в свойстве ТаблицаКластеризации результата анализа. Это всего лишь таблица значений, повторяющая исходные данные с добавленной колонкой "Кластер". Т.е. по обращению РезультатАнализа.ТаблицаКластеризации мы получим ТЗ примерно как на картинке:
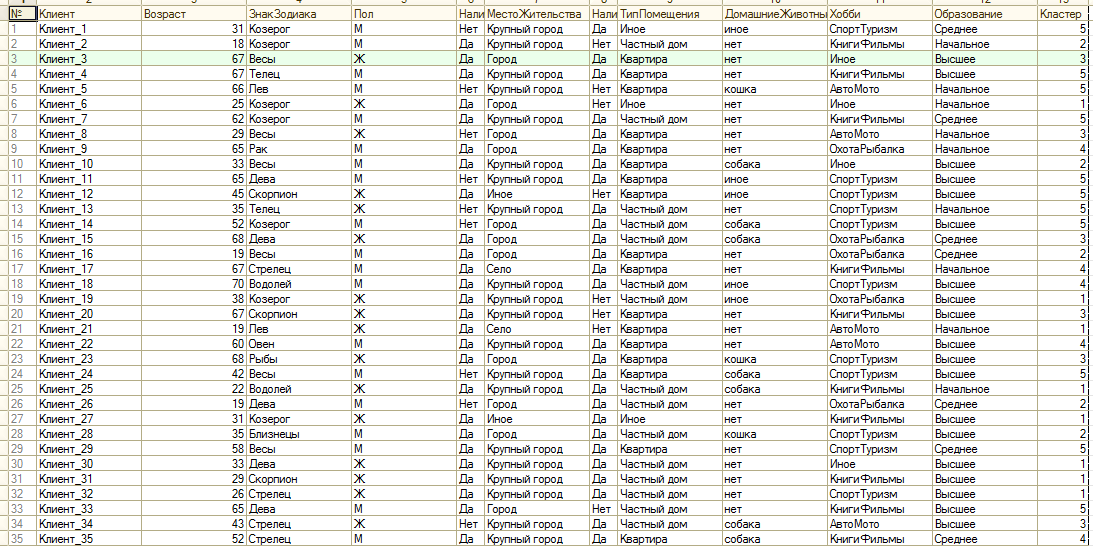
Последняя колонка таблицы указывает на текущий кластер покупателя. Дальше можете отобрать из нее покупателей нужного кластера и обработать как захотите.
Построение прогноза.
Переходя к прогнозу мы снова попадаем на вопрос о цели прогноза. Очевидных целей может быть несколько, но для меня очевидными являются две:
1. Планирование и оценка эффективности мероприятий связанных с увеличением продаж в существующих кластерах. Этот прогноз включает в качестве исходных данных сведения о продажах.
2. Прогнозирование поведения новых/потенциальных покупателей, не имеющих истории продаж. Этот прогноз не должен опираться на данные о продажах, а анализировать только доступные после регистрации покупателя данные из профиля.
Могут быть и другие варианты, главное, чтобы Вы понимали, что состав исходных данных для прогнозирования зависит от того по каким данным Вы будете делать необходимый прогноз.
Итак прогноз для цели №1 может быть получен из имеющегося у нас результата анализа, так как он включал, кроме данных профиля, и данные о продажах. В коде это выглядит так:
МодельПрогноза = РезультатАнализа.СоздатьМодельПрогноза();
МодельПрогноза.ИсточникДанных = тПрогноза;
тРезультатПрогноза = МодельПрогноза.Выполнить();
тПрогноза здесь это любая таблица значений, содержащая полный набор входящих колонок, использованных в источнике данных для результата анализа. Т.е. для первой цели мы можем вполне использовать тИсточника, тем более, что она содержит как раз необходимые для построения прогноза данные. Если же нам нужны прогнозы по отдельным кластерам - данные для прогноза можно получить отбором из таблицы кластеризации. Если нужен прогноз по мужчинам водолеям и т.д. просто делаем отбор из исходных данных.
Ну и конечно в качестве источника данных прогноза могут выступать результат запроса и область ячеек табличного документа. Главное чтобы в них совпадали колонки входящих и прогнозируемых данных.
Впрочем, колонки модели прогноза, после установки источника можно переопределить изменив роль и источник данных, но вот зачем?
А теперь посмотрим в тРезультатПрогноза:

Я специально вывел таблицу в консоли построителя, так как колонок очень много, и вывести все в табличный документ адекватного размера нельзя. Впрочем и информативным такой прогноз не назовешь. Как видим по каждому прогнозируемому показателю (тип колонки АнализаДанных = Прогнозируемая/ВходящаяИПрогнозируемая) прогноз добавил к таблице источника 3 колонки: ЗначениеС, ЗначениеПо и Вероятность. Но это нам мало говорит о том, каким собственно будет математическое ожидание показателя для кластера. Есть лишь диапазон значений с наибольшей вероятностью в него попасть.
Если же нам нужно математическое ожидание придется использовать допил решения кодом. Приведу пример для поля "СреднееКоличествоЧековВмесяц":
ПолеПрогноза = "СреднееКоличествоЧековВМесяц";
ПараметрыПрогнозирования = Новый Соответствие;
Для Каждого Кластер Из МодельПрогноза.Кластеры Цикл
НомерКластера = МодельПрогноза.Кластеры.Найти(Кластер) + 1;
ПараметрыПрогнозирования.Вставить(НомерКластера, Новый Соответствие);
Для Каждого ЗначениеПоляПрогноза Из Кластер.ЗначенияПолейПрогноза Цикл
Если ЗначениеПоляПрогноза.Ключ = ПолеПрогноза Тогда
Прервать;
КонецЕсли;
КонецЦикла;
Для Каждого РешениеАнализаДанных Из ЗначениеПоляПрогноза.Значение Цикл
Вероятность = РешениеАнализаДанных.Вероятность;
ТекРешение = РешениеАнализаДанных.Решение;
Если ТекРешение[0].ВидСравнения = ВидСравнения.МеньшеИлиРавно Или ТекРешение[0].ВидСравнения = ВидСравнения.Меньше Тогда
ЦентральнаяВеличина = ТекРешение[0].Значение / 2;
ИначеЕсли ТекРешение[0].ВидСравнения = ВидСравнения.ИнтервалВключаяОкончание Тогда
ЦентральнаяВеличина = (ТекРешение[0].ЗначениеС + ТекРешение[0].ЗначениеПо) / 2;
ИначеЕсли ТекРешение[0].ВидСравнения = ВидСравнения.БольшеИлиРавно Или ТекРешение[0].ВидСравнения = ВидСравнения.Больше Тогда
ЦентральнаяВеличина = 2 * ТекРешение[0].Значение - ЦентральнаяВеличина;
КонецЕсли;
ПараметрыПрогнозирования[НомерКластера].Вставить(ЦентральнаяВеличина,Вероятность);
КонецЦикла;
КонецЦикла;
МатематическиеОжиданияПоКластерам = Новый Соответствие;
Для Каждого ПараметрПрогноза Из ПараметрыПрогнозирования Цикл
МатОжидание = 0;
Для Каждого ОценкаВероятности Из ПараметрПрогноза.Значение Цикл
МатОжидание = МатОжидание + ОценкаВероятности.Ключ * ОценкаВероятности.Значение / 100;
КонецЦикла;
МатематическиеОжиданияПоКластерам.Вставить(ПараметрПрогноза.Ключ, МатОжидание);
КонецЦикла;
Суть кода в том, что я обхожу каждый кластер из модели прогноза и собираю центральные значения и вероятности из всех рассчитанных диапазонов значений. А потом суммирую произведения центров диапазонов на их вероятности.
Вот что в итоге окажется в соответствии МатематическиеОжиданияПоКластерам:
| Ключ | Значение |
| 1 | 4,3900185556722678665745 |
| 2 | 4,44971263772954127807075 |
| 3 | 1,99142345578457535242179 |
| 4 | 2,09649335029940116220585 |
| 5 | 1,990430605855855696439885 |
Если же идти в прогнозировании дальше и строить доверительные интервалы, то необходимо определиться с видом распределения значений. И получить параметры такого распределения. Это отдельная тема и здесь я не буду в нее погружаться, итак статья выходит длинноватой. Отмечу лишь, что подавляющее большинство практических данных сходятся к распределениям Пуассона или Гаусса (нормальному). Для Пуассона - единственным параметром будет математическое ожидание, а для Гаусса нужно еще посчитать среднеквадратичное отклонение в кластерах, с чем, думаю, все справятся.
Как пример приведу график функции вероятности Пуассона и практического распределения среднего количества чеков в месяц для кластера 1 (параметр мат. ожидания для распределения Пуассона = 4.39)
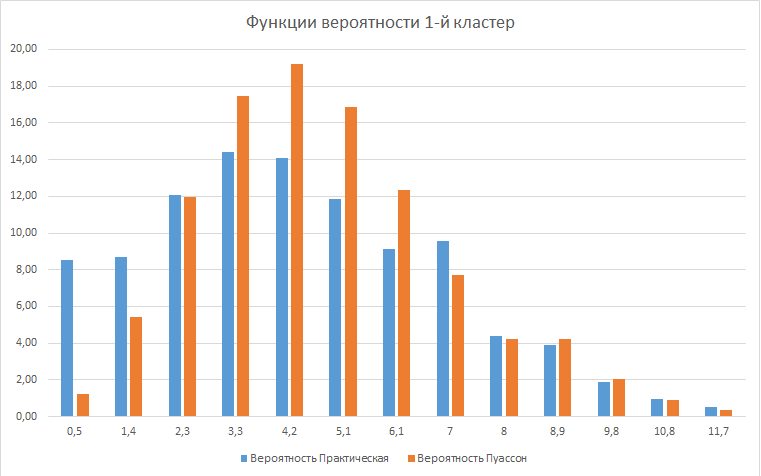
Схожесть распределений, конечно, очень не идеальна, но и исходные данные совсем не из практики.
Если же нам нужна оценка продаж за период нужно сложить математические ожидания продаж по группам номенклатуры в чеке, умножить это на математическое ожидание количества чеков в кластере и умножить это на количество месяцев и, не забыть умножить на размер самого кластера. Вот и готов ориентировочный KPI менеджеру кластера. С другой стороны понятно, что любой показатель в прогнозируемом периоде может с определенной вероятностью принять любое значение. А значит KPI может быть достигнут случайно, а не благодаря кому-то. К этому нужно относиться с пониманием и опираться в установке целей не только на математическое ожидание, но и на доверительные интервалы.
Теперь совсем немного расскажу про прогноз поведения новых покупателей. Для его построения необходимо в исходных данных колонки, связанные со сведениями о продажах, сделать просто прогнозируемыми и провести кластеризацию. Затем добавить в таблицу исходных данных для прогнозирования сведения о новых покупателях (без данных о продажах, естественно) и выполнить по ней прогноз. Вот эта таблица. Клиенты новые и не имеют истории продаж:
Помним, что таблицу источника данных для объекта анализа мы оставили ту же, но колонки с продажами настроили как ТипКолонкиАнализаДанныхКластеризация.Входящая
В результате получим такой результат прогноза:

Если приглядитесь, то заметите, что ничего нового в плане продаж этот прогноз не дал - те же оценки по тем же кластерам. Главное, что мы получили - кластеризацию новых покупателей. Дальше их оценки соответствуют оценкам всего кластера.
Как это использовать на постоянной основе?
Этот вопрос я выделил подпунктом потому что для меня он остается открытым. Может у читателей будут мысли, которые мы обсудим в комментариях.
Здесь я просто изложу свои мысли и предположения:
1. Очевидно, что нагрузка на оборудование и длительность анализа будут зависеть в первую очередь от объема BigData. Поэтому дальнейшие планы можно строить только на основе оценки нагрузки и наших возможностей.
2. Если данных много, то нет смысла пересчитывать их при каждом изменении и я бы не стал создавать для анализа фоновые задания с определенной периодичностью. Скорее мерой должна служить степень изменения данных. Допустим изменение количества и/или итогов по записям на 3, 5 или 10% приводит к обновлению кластеризации в фоновом задании в период наименьшей нагрузки на сервера.
3. Если нам нужно присвоить кластер новому элементу, но проводить кластерный анализ ради этого не хочется можно брать готовое решение. Результат анализа можно хранить в хранилище значения и при необходимости извлекать оттуда и классифицировать новые объекты через инструментарий прогноза. Для того, чтобы не помещать в хранилище весь массив исходных данных результат анализа можно избавить от таблицы кластеризации, указав в параметрах анализа:
Анализ.Параметры.ТипЗаполненияТаблицы.Значение = ТипЗаполненияТаблицыРезультатаАнализаДанных.НеЗаполнять;
РезультатАнализа после этого будет содержать только данные о кластеризации, без огромной таблицы исходных данных.
4. Если имеет смысл нагружать анализом отдельную базу данных, которая будет получать данные из основной (основных) баз. Отдавать для использования в основные базы она должна только итоги работы в виде результата анализа и списка объектов, у которых изменился кластер в ходе последнего пересчета. В основных же базах производить только изменения значения этого реквизита и обновлять хранилища с готовыми решениями.
И вот на этом, надеюсь, пока все.
P.S. Использованная версия платформы 8.3.12.1595
Вступайте в нашу телеграмм-группу Инфостарт
