Меня зовут Юрий Гончарук, я работаю DevOps-инженером в компании «Финтех Решения». Одна из моих задач – это настройка Jenkins.

Основная специализация Jenkins – это, прежде всего, CI/CD. Но мы его у себя пристроили и для кучи других очень интересных задач, которые непосредственно к CI/CD не относятся. Это:
-
разбор хранилищ;
-
настройка развернутых копий баз – когда мы поднимаем копию базы, смотрим;
-
перезагрузка кластера – мы его тоже делаем через Jenkins;
-
и управление доступом к базам для дежурных разработчиков.
Разбор 40 хранилищ

Начнем с разбора хранилищ.
Мы стараемся весь код хранить в Git, но разработка у нас по-прежнему ведется в хранилищах. Соответственно, у нас около сорока различных хранилищ – от УПП до ERP. Все их нужно разбирать в Git, потому что основной формат хранения, с которым мы работаем в дальнейшем – это Git. Хранилища – это среда внесения изменений непосредственно для разработчиков.
Для мелких «исправительных» расширений у нас есть отдельные проекты, в которые мы разбираем эти расширения через precommit1c – здесь участие CI/CD не требуется.
Мы сейчас пытаемся уходить от хранилищ – хотя бы для расширений, но пока это никуда от нас не денется и очень долгое время будет жить с нами.

При попытке контролировать разработку в сорока с лишним хранилищах, появляются вопросы:
-
Как сделать так, чтобы все эти хранилища разбирались?
-
Как подключить в систему разборки новое хранилище?
-
Как отключить хранилище от разборки при необходимости?
Для этого у нас в Jenkins есть шаблонное задание, которое мы при необходимости просто подключаем к хранилищу.
Мы создаем новое задание – его jenkinsfile показан на слайде. Задание совершенно несложное, буквально из четырех шагов. И настраиваем его на периодический разбор – чуть дальше покажу.
Все настройки для этого задания хранятся в конфигурационных файлах.
Т.е. задание используется шаблонное, а к нему – такие маленькие конфигурации, где задано:
-
какие плагины подключать;
-
дополнительные настройки плагинов;
-
куда подключаться;
-
куда синхронизировать.
Все это задается в файле конфигурации.

Как добраться до этого файла конфигурации? Мы решили, что так как каждое задание уникальное и имеет собственное имя в Jenkins, то и файл конфигурации будет иметь точно такое же название и будет располагаться в подключаемой библиотеке.
На слайде показано, каким образом мы его загружаем. Загруженный таким образом файл конфигурации сразу объявляет все указанные в нем переменные переменными среды – нам ничего дополнительно делать не нужно.

Теперь – то, что касается Gitsync.
Для разбора разных хранилищ нам нужен разный набор плагинов Gitsync. Каким образом это сделать?
Мы объявляем переменную GITSYNC_PLUGINS_PATH, и в ней инициализируем плагины. У нас есть список предопределенных плагинов:
-
sync-remote
-
limit
-
check-comments
-
check-authors
-
increment и прочее.
Все эти плагины у нас подключены для всех хранилищ. И дополнительно через переменную env.Plugins мы можем передать какие-то еще.
Сборочная линия проверяет, что каталог плагинов существует, и, если его нет, инициализирует необходимые плагины по списку.
Это дает нам возможность для каждого разбора иметь свой собственный набор плагинов – очень удобная вещь.

Шаг синхронизации достаточно простой.
Задаем переменные окружения.
Отдельно через Credentials передаем учетные данные. Это очень важный момент, потому что их можно задать в командной строке явно, но самым безопасным и рекомендуемым способом является передача через Credentials – Gitsync эту функцию поддерживает.
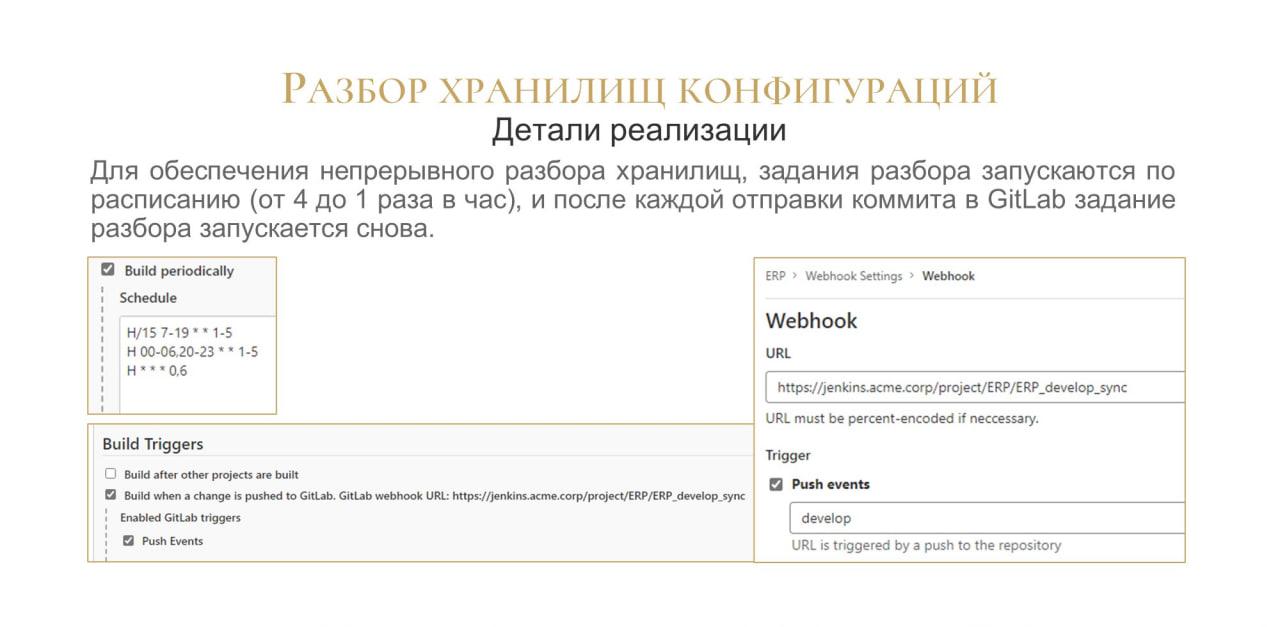
Следующий вопрос, который перед нами встал – как часто разбирать.
На слайде показано расписание, которое у нас используется. Мы запускаем задания разбора каждые 15 минут в рабочее время и каждый час в любое другое время.
Тут хочется сказать: у нас что, каждый час будет разбираться по одному коммиту? Мы это решили другим способом: когда очередная версия помещается в репозиторий, репозиторий через вебхук перевызывает это задание. Таким образом задание запускается по новой и будет так работать до тех пор, пока не разберет все версии из хранилища.
Разворачиваем копии

Следующая функциональность – копии баз. Практически всегда, когда вы разворачиваете копию, это еще не значит, что в эту копию можно сразу всех пускать. Нет, для этого с копией нужно поработать предварительно – этой подготовкой тоже занимается Jenkins.
Что мы делаем в копии?
-
Обязательно обновляем нумерацию объектов, это прямо must have.
-
И затем последовательно выполняем БСП-шные функции – запрещаем выполнение регламентных заданий.
-
Удаляем настройки подключений ко всем внешним сервисам, чтобы разработчик случайно не запустил синхронизацию в копии. Мы сразу удаляем все настройки подключений и убираем эту проблему.
-
Если нам все-таки нужно использовать какие-то внешние сервисы, мы переключаем на mock-заглушки либо на тестовые версии внешних сервисов.
-
Поскольку у нас используется механизм копий баз данных, мы отключаем копии баз данных для копии базы данных. Звучит как рекурсия, но это разные механизмы.
-
Следующий момент – у нас разработчики не имеют доступ на продуктовую базу, но мы им разрешаем заходить на копию. Поэтому мы настраиваем в поднятой копии доступ тем пользователям, которым нельзя в рабочую базу, но можно в копию.
-
И еще у каждой базы есть своя специфика.

Мы это реализовали достаточно просто.
-
Сделали отдельный репозиторий в GitLab, где хранятся исходники внешних обработок, которые выполняют эту настройку. Они там хранятся в прямо в XML-ках и при запуске заданий собираются. Всего набралось пять таких специфичных обработок: отдельно для УПП, Бухгалтерии, ERP и так далее. В каждом типе баз свои особенности.
-
Для запуска задания, которое выполняет настройку базы, используется возможность Jenkins запускать задание через вебхук.
-
Когда админ разворачивает копию базы на SQL, он дергает этот вебхук, и все.
-
При окончании работы задания Jenkins публикует в канале Teams уведомление, и разработчики уже могут заходить.

Вот так вот выглядит pipeline, он достаточно простой.
Мы передаем имя базы через параметр – Jenkins поддерживает такую функцию.
И внизу показано, как мы оповещаем о запуске обработки в Teams. Вот таким нехитрым образом мы можем опубликовать любое сообщение. Не только текст, но и, например, красивую табличку с данными. Туда можно передать что угодно, это очень удобно.

Справа показано, как у нас выглядит обработка для настройки копии базы ERP.
«Who is on duty today?» – Кто сегодня дежурный?

Разработчики у нас не имеют доступа в рабочую базу, но есть исключение – это дежурство. Дежурства бывает ночные, на выходные, но самые интересные – это дневные дежурства, которые идут в рабочее время.
-
Дежурным по очереди является каждый разработчик команды, причем дневное дежурство назначается на неделю. Мы утром включаем, а вечером выключаем разработчику доступ к рабочей базе.
-
Для ночных дежурных доступ в базу открывается с 18:00 до 09:00 следующего дня.
-
И в выходные разработчики заступают на дежурство с вечера пятницы до утра понедельника.
Расписание дежурств задается полностью в Teams, а в Jenkins настроена задача, которая по расписанию запускается, получает информацию из расписания Teams и разрешает или запрещает вход конкретных пользователей в базу.

Для этого у нас есть две небольшие библиотечки – для работы с Teams и для работы с Jira. Мы там реализовали далеко не всю функциональность API, только то, что нужно:
-
авторизация;
-
получение данных из расписания Teams;
-
и получение данных для выдачи дежурным разрешения работать в Jira – дежурные помимо доступа к рабочей базе должны разбирать и классифицировать новые задачи в Jira.
Сложного в принципе тут ничего нет. Все делаем по документации к API.
Рестарт кластера одной кнопкой

Следующее – это перезапуск кластера.
Jenkins умеет работать не только с cmd, чтобы запускать скрипты на OneScript, у него есть отдельная функциональность для работы через PowerShell – эту функциональность мы используем для перезапуска кластера.
Кластер у нас большой, в основном рабочем кластере содержится 5 рабочих серверов – их нужно погасить в правильной последовательности, а потом поднять в правильной последовательности.
Руками это сделать можно, но сложно, потому что это нужно делать безошибочно и каждый раз. А такая ситуация обычно возникает из серии: «У нас все упало, давайте перезагрузим».
Чтобы трясущимися руками не ошибиться, у нас есть такое задание, которое это делает автоматически:
-
перезапускает кластер;
-
также завершает все рабочие процессы, которые штатно не завершились;
-
очищает временные каталоги и каталоги сеансовых данных у кластера;
-
убирает файлы журнала регистрации из каталога кластера – это связано с тем, что у нас журнал регистрации перегоняется в GreyLog практически онлайн, поэтому хранить его постоянно на рабочем сервере смысла не имеет;
-
и потом запускает в определенной последовательности.

Вот так выглядит пайплайн, который запускает скрипт PowerShell.
Опять же через Credentials мы передаем имя пользователя и пароль. И запускаем скрипт PowerShell.

На слайде показан фрагмент скрипта PowerShell – мы подключаемся к удаленному компьютеру, используя объявленные в пайплайне переменные окружения.

А это – фрагмент команды для остановки сервиса на конкретной машине.
Из интересного – обратите внимание на то, что здесь используется модификатор области видимости «$Using». Он позволяет прокинуть локальную переменную в сессию. Если забыть его указать, можно долго мучиться – удивляться, почему ничего не работает.
Сборка и тестирование

Ну и «родная» функциональность Jenkins – build, test and deploy.
Сборку проектов, разрабатываемых в хранилище, мы, конечно, не производим, потому что там конфигурацию легко получить стандартными средствами – в любой момент можно вытащить из хранилища готовый CF версии.
А для сборки проектов, которые разрабатываются в Git, мы в Jenkins используем vanessa-runner, обернутый в скрипт на OneScript – фрагмент текста этого скрипта показан на слайде. Дополнительная обертка нужна, потому что в этом скрипте помимо вызова vanessa-runner обрабатывается дополнительная логика.
Справа показан шаг сборки расширения.

При построении проекта мы меняем номер версии – добавляем в номер текущей сборки. Это очень серьезный подводный камень.
В самом CF-файле в поле версии указано четыре числа через точку, и последняя циферка всегда ноль. Но когда мы собираем конкретный файл, мы эту циферку меняем на текущий build number.
Благодаря этому бинарные файлы всегда будут иметь уникальную версию – разработчику не нужно думать, поменял он версию или нет. Она всегда будет уникальна.

Здесь показан фрагмент кода – как мы на OneScript добавляем номер сборки. Этот код, может быть, несколько костыльный, но он работает.
Важно – после того, как мы поменяли номер сборки в MDO-файле конфигурации и собрали проект, нужно не забыть отменить изменения командой:
git restore <ИмяФайлаКонфигурации>

Чтобы сохранить бинарные файлы для дальнейшего использования, есть команда «Сохранение артефактов». Потом их можно использовать в других сборках.
Собрав версию один раз, мы можем использовать этот номер в любой другой задаче. Повторно артефакт собирать не нужно – мы его уже собрали, и он там лежит. Мы его просто используем для работы.

С построением разобрались, теперь тесты.
На слайде приведен пример команды, которая подключает расширение с тестами.
Напомню, что тесты у нас разрабатываются в расширениях – об этом есть отдельный доклад.
Мы подключаем расширение и запускаем базу, а потом второй командой «Запуск тестов» запускаем тесты с помощью XUnit.
Деплоим на прод

Следующий пункт – деплой, обновление рабочей базы.
Рабочих баз у нас тоже достаточно много, но для их обновления используется одна и та же конфигурация задания Jenkins. Мы не учитываем специфику каждой базы, они все обновляются по одному и тому же сценарию.
Параметры этого сценария мы точно так же получаем по имени джобы.
На слайде показаны те шаги, которые у нас делаются:
-
мы закрываем активные сеансы;
-
устанавливаем блокировку сеансов;
-
обновляем;
-
запускаем в режиме предприятия;
-
и снимаем блокировку.
Здесь мы немного применили оптимизацию шагов – видите, у нас два шага выполняются параллельно:
-
мы ждем завершения сеансов;
-
и параллельно у нас обновляется база из хранилища.
Следующий шаг стартует только после их завершения.
А дальше все просто – обновляем конфигурацию, запускаем в режиме предприятия и снимаем блокировку.

Со снятием блокировки интересная штука – поскольку при первоначальном запуске мы накладываем блокировку на вход в базу, мы ее обязательно должны снять.
Что бы ни случилось в нашей джобе, мы должны снять блокировку.
Поэтому все шаги внутри пайпа у нас обернуты в catchError. Если мы ловим ошибку, то помещаем конкретный шаг как ошибочный, а buildResult у всей сборки выставляем как “NOT_BUILD”.
И последний шаг всегда снимает блокировку сеансов. Видите, тут даже в опциях указано retry(3) – то есть три раза пробуй, если что-то не получилось, еще два раза сделай.
Вот такая штука у нас используется.
Непрерывная проверка SonarQube

Следующий момент – проверка кода. Мы активно используем SonarQube, он подключается у нас практически ко всем репозиториям с кодом.
У нас есть несколько сценариев работы с SonarQube:
-
есть типовой маленький pipeline, который просто проверяет проект;
-
реализованы шаги, которые проверяют код – как для ветки, как для проекта, так и для мерж реквеста;
-
ну и отдельный пункт у нас – прохождение порога качества.

Для простого анализа у нас есть совсем простой pipeline, в котором буквально два шага – проверить и дождаться прохождения порога качества.
В этот пайплайн мы передаем параметры проверки проекта:
-
сколько памяти,
-
сколько ждать тайм-аута проверки
-
где хранятся настройки проверки SonarQube
Сам анализ включает в себя три параллельных шага:
-
первый шаг – это проверка всего проекта целиком;
-
потом – проверка конкретной ветки проекта;
-
и следующий момент – проверка мерж реквеста.

На слайде показана разница между этими шагами – они отличаются тем, какие параметры будут переданы в SonarQube при проверке.
Очень важно, что бесплатная версия SonarQube Community Edition поддерживает только один режим работы – это проверка целиком проекта.
Анализ веток проекта и мерж-реквестов доступен только у старших редакций SonarQube.
Но сообщество SonarQube реализовало Community Branch Plugin, который позволяет использовать эту функциональность и для младшей версии.
Без Community Branch Plugin эти два последних шага были бы нерабочими, был бы только вариант №1. Спасибо сообществу SonarQube, они помогают и 1С-никам.

Следующий момент – порог качества SonarQube.
Для большинства проектов порог качества – это скорее сообщение о том, как мы работаем.
А для некоторых проектов мы используем порог качества как такой терминатор – успешная сборка или нет. Если не прошли порог качества, все, сборка падает, и она помечается не рабочей.

Вот примеры настройки порога для таких проектов. Для ветки.

И для мерж-реквеста.

Вот как мы проверяем порог качества.
Если порог качества не пройден, мы помечаем сборку как нестабильную, и показываем, что это именно из-за падения порога качества.
К примеру, у нас есть небольшой проект, в котором процент покрытия 76 процентов (сейчас уже больше 80). Для новых версий этого проекта непрохождение порога качества по покрытию является терминальным. Не прошли – все, мерж-реквест не будет принят.
Пока у нас таких проектов буквально два, сейчас появится третий, в котором это будет использоваться. Но мы так уже работаем.
Вопросы
Декорирование мерж-реквестов у вас работает без проблем?
Да, работает. Без проблем. Какое-то время не работало из-за того, что использовалась некорректная связка ПО, но после того, как мы обновили и GitLab, и SonarQube на последнюю версию – все отлично работает, и все показывается.
Вы сказали, что используете хранилище, при этом делаете еще артефакты и прочее. Зачем хранилище?
У нас есть проекты и на Git, и на хранилище. Артефакты мы делаем для тех проектов, в которых разработка ведется в исходных кодах.
Вы сказали, что при деплое базы, если что-то пошло не так, вы в любом случае снимаете блокировку. А вы уверены, что блокировку точно можно снимать и работать в исходном режиме? Может быть, там что-то такое случилось, что мы немного порушили то, что было?
У нас пока примеров, когда все ломалось, не было. Поскольку у нас обновление базы подразумевает, что работают роботы, а не человек, то логика такая – мы запустили обновление базы и смотрим за результатом. Если обновление упадет по той или иной причине, туда уже зайдет человек и будет смотреть, в чем дело. И дальнейшее решение принимает человек, принимает не система. Мы разрешаем вход, но если что-то упадет, всегда есть человек, который за этим смотрит.
Почему именно Jenkins? Есть же много разных инструментов, например, GitLab CI. Если у вас Enterprise версия GitLab, почему бы сразу его не использовать? По коду видно, что в большей части используются скрипты на OneScript и Powershell. Почти всю эту функциональность можно перенести и на GitLab CI.
Да, мы именно так и хотели, чтобы сама логика была реализована именно в скриптах.
Почему именно Jenkins? Наверное, потому что так исторически сложилось: Jenkins использует комьюнити Инфостарта, о нем очень много было полезных докладов и статей.
В принципе, это все можно сделать и на GitLab CI. Здесь нет никакой проблемы.
Можно сделать и на других CI платформах, здесь нет ничего уникального. Здесь интересно только то, что можно делать и так, и так, и так.
Если ничего нет, то даже Jenkins уже хорошо.
Есть ли у вас опыт использования библиотеки от Никиты Грызлова?
Мы сознательно делаем так, чтобы не реализовывать на стороне Jenkins вообще никакую логику. У нас groovy – это максимум обертка. Те шаги, которые я показывал, просто перегоняют параметры в командную строку. Никакой бизнес-логики внутри нет.
Вся логика у нас написана либо в OneScript, либо в PowerShell. На groovy у нас логики нет. Groovy и pipeline отвечают только за логику прохождения шагов, но не за логику выполнения шагов.
А почему так? Для уменьшения порога входа, чтобы 1С-ники могли это делать?
В лучших практиках Jenkins прямо написано: «Не пишите логику на groovy». Там это чуть ли не в первом же абзаце написано. Раз не нужно писать логику на groovy, тогда на чем? Ответ очевиден, на 1С (т.е. на OneScript).
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.


Вступайте в нашу телеграмм-группу Инфостарт