Меня зовут Никита Федькин, ранее вы могли знать меня как Никита Грызлов. Я работаю в компании Первый Бит, занимаюсь автоматизацией в сфере образования и также очень много времени посвящаю вопросам автоматизации сборочных линий – не написанию тестов как таковых, а тем, как всё завести, как построить сборочную линию и как принести максимальную пользу от этого процесса.
Сегодня мы поговорим про Jenkins – это хороший проверенный сервер сборок, на котором можно строить сборочные линии любой сложности. Причем необязательно эта линия связана с процессом тестирования или развертывания – это в принципе про автоматизацию.
Я очень надеюсь, что у вас уже есть какие-то элементы контура CI/CD или как минимум вы собираетесь в скором времени начать настройку этого контура.
Предположим, что у вас уже:
-
установлен Jenkins;
-
есть какой-то Git-сервер, например, GitLab;
-
есть пустой SonarQube;
-
файлы конфигурации уже хранятся на Git-сервере;
-
есть сценарии тестирования на Vanessa Automation;
-
и есть скрипты для Vanessa-runner.
Наверное, если бы у вас все это было, то и мой доклад был бы уже не нужен, но, предположим, у вас такая идеальная ситуация.
Мой доклад будет про то, как связать все эти элементы между собой, как начать использовать Jenkins с минимумом усилий и кода, если вдруг (с чего бы это, не правда ли?) вас занесло в 1С.
Как выглядит сборочная линия в 1С, и в чем проблема масштабировать сборочные линии между командами и проектами
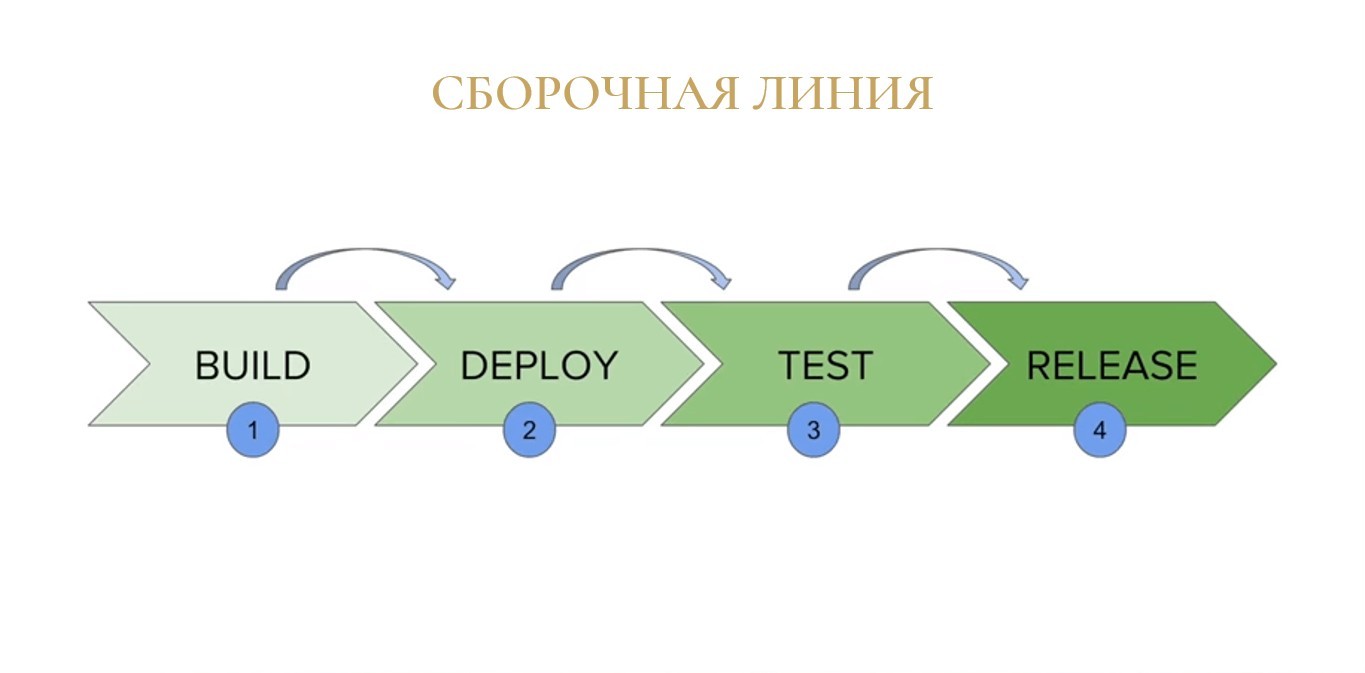
В основе работы с серверами сборок лежит понятие «Сборочная линия» или в английском варианте - «pipeline». Второй популярный перевод этого термина на русский язык – конвейер.
Наш код преобразуется прямо как продукт на конвейерном производстве:
-
сначала из россыпи исходников возникает некий бинарный артефакт (конфигурация);
-
конфигурация развертывается в какой-то базе тестовом окружении;
-
путем запуска тестов база преобразуется в протестированное решение;
-
а протестированное решение превращается в релиз, который впоследствии может быть раскатан на продуктив или передан клиентам.
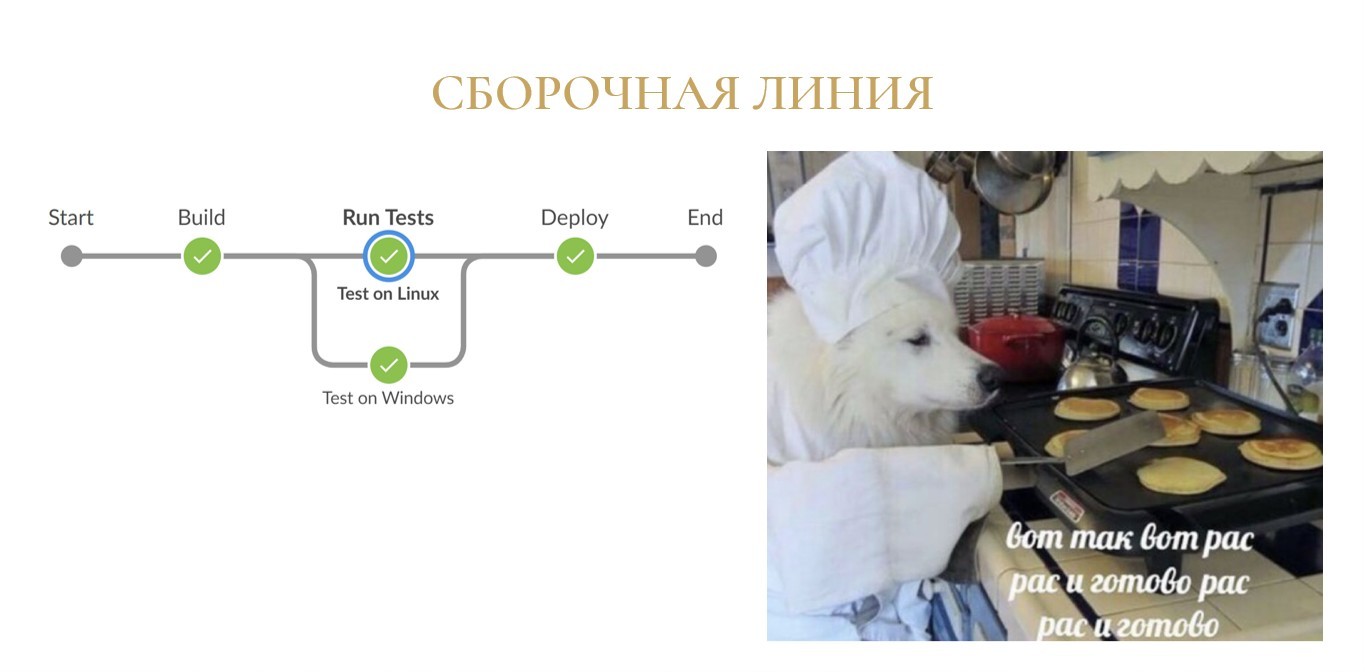
На слайде пример простейшей сборочной линии в интерфейсе Jenkins, взятый из интернета.
Храбрым ребятам из туториалов даже сборка релиза не нужна. Они собрали артефакт, протестировали и сразу на прод деплоят, без каких-либо промежуточных шагов.
Складывается ощущение, что сборочная линия – это просто.
И да, чаще всего это просто – для других языков программирования, для других экосистем и других типов приложений. Но не в 1С. Разве у нас когда-нибудь было просто?
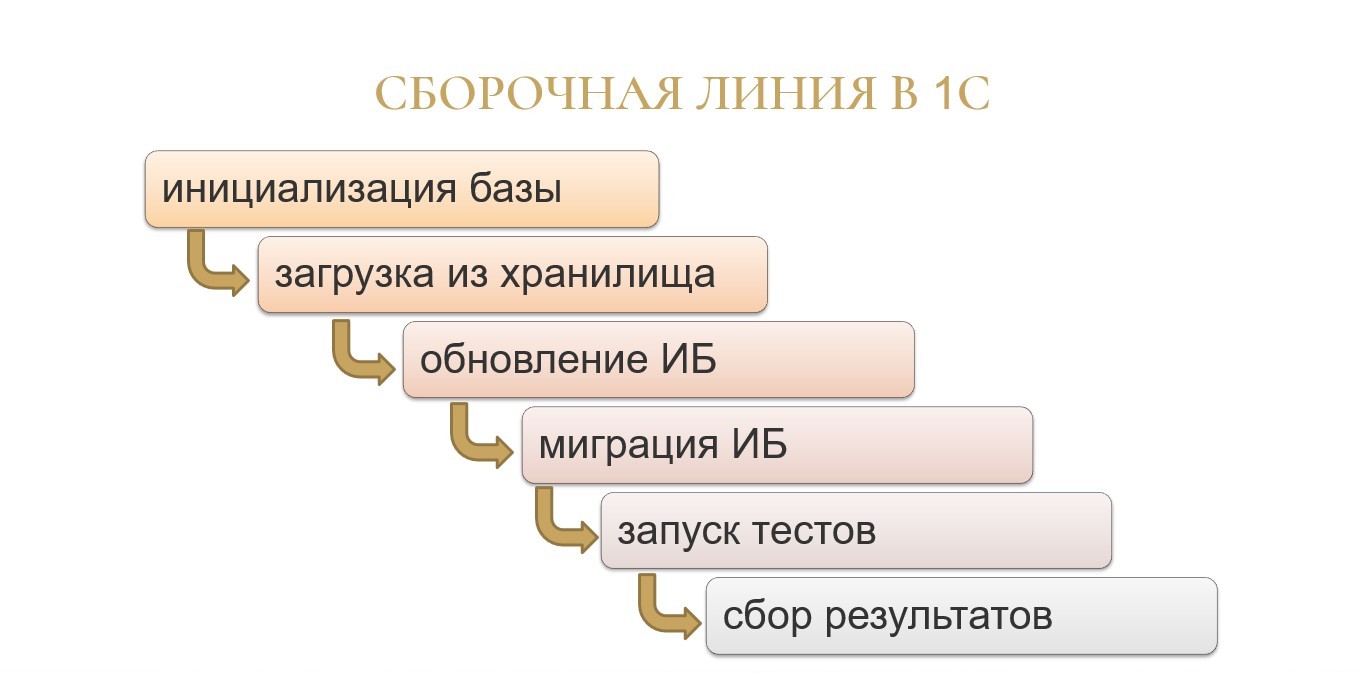
Во-первых, для осуществления самого простого тестирования в 1С шагов в сборочной линии потребуется чуть больше. Только подготовка информационной базы к тестированию – это минимум четыре шага:
-
нам нужно базу создать;
-
нужно загрузить туда правильную конфигурацию;
-
нужно нажать на синий бочонок;
-
потом эту базу нужно запустить, чтобы там выполнить все нужные миграции.
И только после этого мы можем там что-то запускать.
А во-вторых, реализация этих шагов может быть нетривиальной и иногда даже сложной из-за того, что у нас довольно бедный инструментарий со стороны платформы по запуску всех этих процессов.
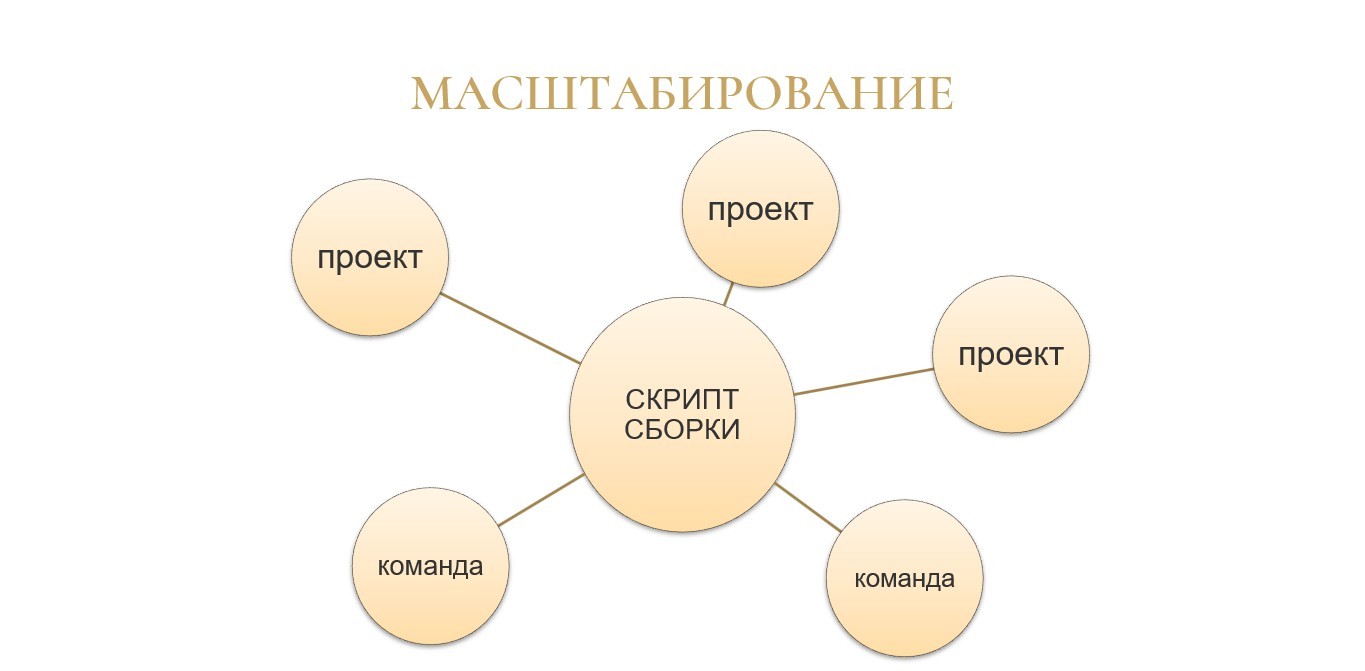
В-третьих, все еще больше усложняется, если у вас появляется несколько проектов или несколько команд.
Скрипты сборки начинают копироваться между репозиториями, в них вносятся несовместимые изменения – примерно так же, как это происходит с внедрением типовых конфигураций у разных клиентов. Вроде бы вы делаете примерно одно и то же, но везде немного по-разному.
А если говорить еще и про масштабирование ваших сборочных процессов на другие команды, то появляется задача легкого ввода новой команды во всю эту кухню автотестирования и становится совсем грустно, сложно и чаще всего непонятно.

Скрипты для сборочных линий Jenkins описываются в специальных файлах, которые называются Jenkinsfile. На слайде показан кусок такого Jenkinsfile для 1С – одного из самых ранних, что я нашел на GitHub.
Складываем сложную логику работы с информационной базой, бедный инструментарий, проблему масштабирования – получаем в каждом репозитории вот такие огромные простыни, в которых вообще непонятно, что происходит. А если еще нужно вносить туда какие-то изменения, то становится даже немного страшно.
Мне в какой-то момент все это надоело. Надоело копипастить все эти скрипты из проекта в проект. Надоело объяснять, что значит то, что здесь написано.
Хочу проще.

Хочу одной простой командой pipeline1C(), как на слайде.
Предпосылки появления jenkins-lib

Итого при настройке Jenkins для 1С мы имеем три указанные проблемы:
-
многослойность самого процесса;
-
масштабирование на другие проекты и команды;
-
и сложность имеющихся скриптов Jenkinsfile.

На Инфостарте есть несколько статей на тему унификации сборочных линий, крутящихся вокруг идеи единой сборочной линии для всех проектов.
Валерий Максимов на Infostart Event в 2019 году выступил с прекрасным докладом, где представил идею «библиотечного» Jenkinsfile, который загружается извне репозитория, и на который накладываются настройки из файла внутри репозитория.
Основываясь на теоретических выкладках Валерия и собственном опыте, я разработал собственное открытое и бесплатное решение, которое призвано решить озвученные ранее проблемы.

Хочу представить вам проект под названием «jenkins-lib».
Проект опубликован на GitHub, имеет открытую лицензию MIT. В репозитории помимо исходного кода можно найти и инструкцию по использованию.
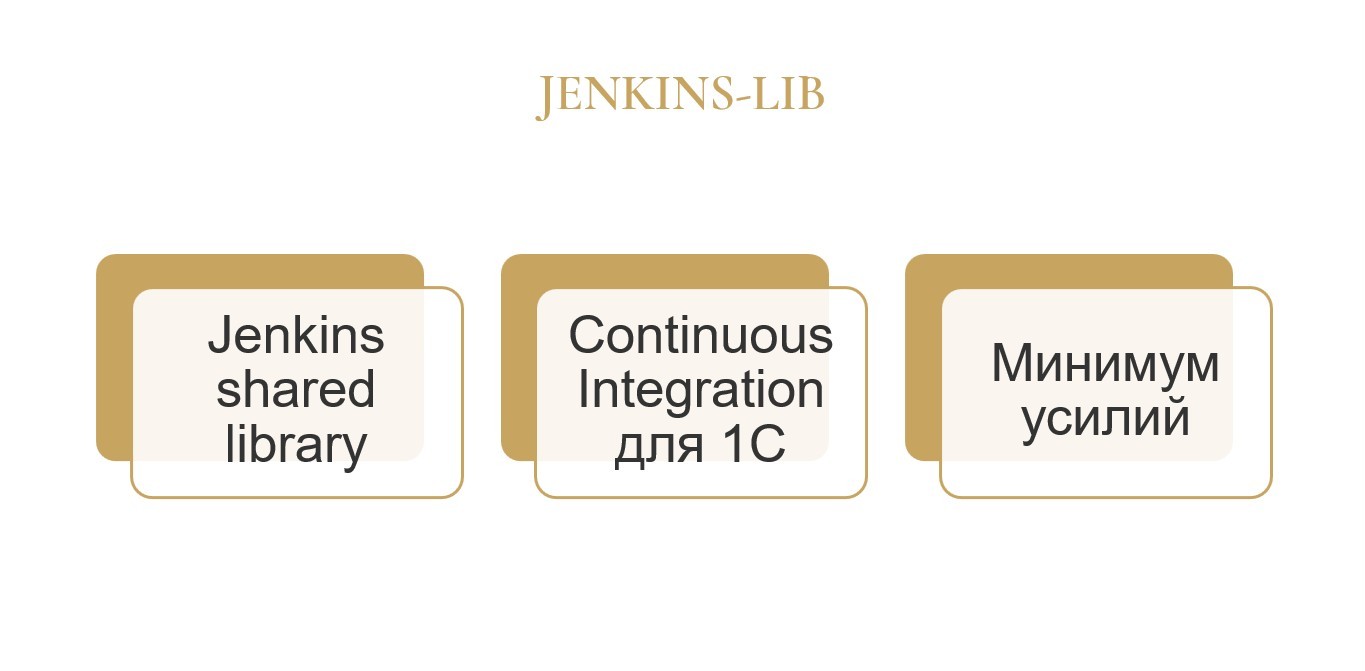
Что же такое jenkins-lib?
Это библиотека для Jenkins, которая создана по специальной технологии разработки библиотек под названием shared library.
jenkins-lib представляет собой готовую сборочную линию для 1С, с помощью которой вы можете настроить процессы непрерывной проверки качества вашего программного решения.
И все это с минимумом усилий – как со стороны того, кто будет внедрять эту библиотеку, так и со стороны проектной команды, которая будет это потом использовать.

Цель проекта довольно проста. Сделать так, чтобы использование Jenkins и 1С перестало быть адским мучением.

А стало райским наслаждением.
Возможности и особенности библиотеки jenkins-lib
Что вам может дать эта библиотека?
На самом деле, довольно много. Давайте пройдемся по этим зеленым кружочкам.
-
во-первых, библиотека поддерживает два формата исходников – она умеет работать и в формате EDT, и в формате выгрузки из конфигуратора;
-
она может создать информационную базу, может ее проинициализировать и выполнить операции по первоначальному запуску;
-
операции проверки качества вашего решения выполняются параллельно;
-
в рамках проверки доступен запуск BDD-сценариев с помощью Vanessa Automation или bddRunner из Vanessa-ADD, запуск дымовых тестов;
-
есть поддержка статического анализа средствами EDT и вырезание из результатов ошибок в модулях на поддержке;
-
есть синтаксический контроль конфигуратора;
-
есть запуск анализа SonarQube.;
-
все это сопровождается публикацией результатов сборки – либо в Allure, либо в jUnit
-
и отправкой результата сборки в телеграм или электронную почту.

В основе библиотеки лежит понятие «соглашения по конфигурации». Оно базируется на трех довольно простых принципах.
-
Во-первых, настройки по умолчанию покрывают потребности большинства так называемых обычных пользователей.
-
Во-вторых, наличие определенных файлов в структуре вашего репозитория сразу расценивается как призыв к действию – если у вас есть файл в определенном месте с определенным именем, значит, его можно использовать для сборки.
-
И в-третьих, у вас всегда остается возможность подтюнить какие-то настройки под особенности именно вашего проекта.
Если вы знаете и понимаете правила, по которым работает библиотека, и ваш Jenkins корректно (с точки зрения библиотеки) настроен, вы можете свести изменение настроек к минимуму.

Поговорим про установку библиотеки.
Казалось бы, что там устанавливать? Но никогда не стоит забывать про кучу дополнительных галочек.
Настройку библиотеки можно разделить на два больших блока.
Первый блок – это конфигурация самого сервера сборок, которую нужно сделать только один раз.
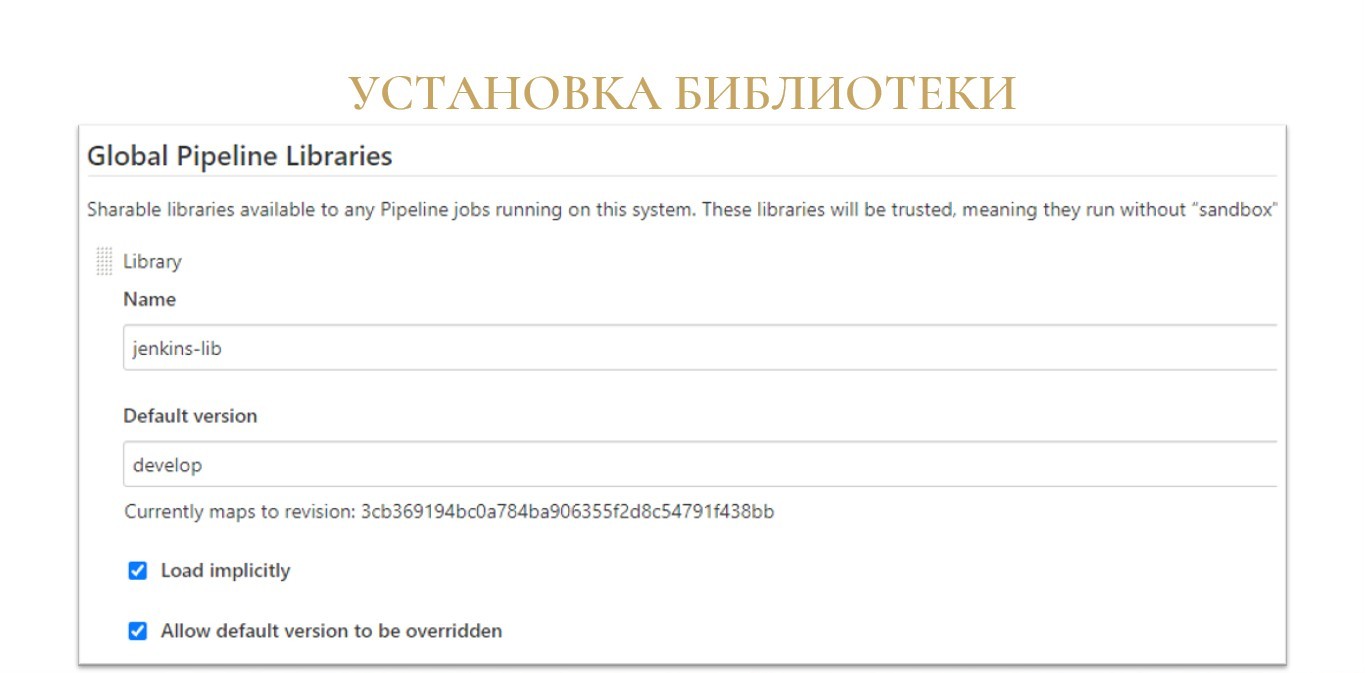
Для начала, нужно вообще рассказать Jenkins, что такая библиотека где-то существует, как ее можно подключить и как использовать. Делается это довольно просто. В настройках Jenkins в разделе «Конфигурация системы» находите подраздел Global Pipeline Libraries и добавляете туда новую строчку:
-
указываете имя библиотеки;
-
указываете, из какой ветки, тега или хэша коммита брать версию по умолчанию;
-
отмечаете флаг «Load implicitly», чтобы ее можно было загружать автоматически во все ваши сборочные линии без каких-либо дополнительных шагов;
-
отмечаете флаг «Allow default version to be overridden» – оставляете возможность переопределения версии;
-
и указываете репозиторий проекта
https://github.com/firstBitMarksistskaya/jenkins-lib.git.
Что вообще такое «версия по умолчанию»? Как я сказал, вы можете выбрать конкретную ветку, тег или хэш коммита. Я рекомендую вам использовать конкретный релиз – это защитит вас от возможных изменений в новых версиях. Несмотря на то, что библиотека разрабатывается уже больше полутора лет, в настройки иногда вносятся изменения, ломающие обратную совместимость. А если вы останетесь на каком-то конкретном релизе, то вы сможете плавно мигрировать на новую версию, и при этом не порушить ваши остальные проекты сборки.
Если вы любите экстрим, вы можете указать ветку master и тогда выход нового релиза станет для вас приятной неожиданностью. :)
Если вы хотите экстрима каждый день, то вы можете выбрать ветку develop, и тогда шуточное пожелание «вечно зеленых сборок» уже не становится таким уж шуточным.
Как вы, наверное, знаете, все задачи сборки выполняются на так называемых «агентах».
По своей сути, это обычные подключенные к Jenkins рабочие машины с установленным на них дополнительным софтом.
У каждого агента может быть одна или несколько меток. Это просто произвольные строки, которые вы присваиваете агенту, и по которым впоследствии ваши сборочные линии могут запрашивать у Jenkins для выполнения задачи какую-то конкретную машину на основании этой метки.

jenkins-lib в своей работе опирается именно на метки агентов – причем ему нужно несколько меток:
-
Для минимального запуска библиотеки у вас должен быть агент с меткой «agent». Никаких специальных настроек на этом агенте выполнять не нужно, это может быть буквально любая машина, которая подключена к вашему Jenkins – лишь бы у него была такая метка. На агенте с меткой «agent» будет выполняться минимальный ряд операций по преднастройке вашей сборочной линии.
-
Если вы планируете выполнять операции, требующие установленной платформы 1С, у вас должен быть агент с меткой, совпадающей с маской версии платформы – например, «8.3» или «8.3.18». На этом агенте должна стоять платформа указанной версии (в том числе конфигуратор) и OneScript. Версию платформы вы всегда сможете указать вплоть до конкретного билда – просто помните, что, если вы хотите собирать на конкретном билде, у вас должен быть агент, который называется точно так же.
-
Хотите анализировать проект на SonarQube – нужен агент с меткой «sonar».
-
Также логично, что для работы и для статанализа EDT нужен агент с меткой «edt».
-
И для ряда служебных операций по трансформации результатов нужен агент с меткой «oscript». В принципе, это может быть тот же самый агент, на котором стоит платформа, но у него значительно меньшие требования по вычислительным мощностям, поэтому я выделил его отдельно.

Вы можете поднимать агенты любым удобным вам способом – главное, чтобы на них были нужные метки.
Это могут быть как железные сервера, так и виртуальные машины или контейнеры. Если вы готовы с развлечению с Docker, могу посоветовать посмотреть мой доклад с Infostart Meetup Kazan 2020, где я рассказывал про то, как собрать Docker-образы агентов и подключить их к Jenkins с помощью плагина Docker Swarm, работающего по концепции Cloud Provider.
Настройка сборочной линии для проекта
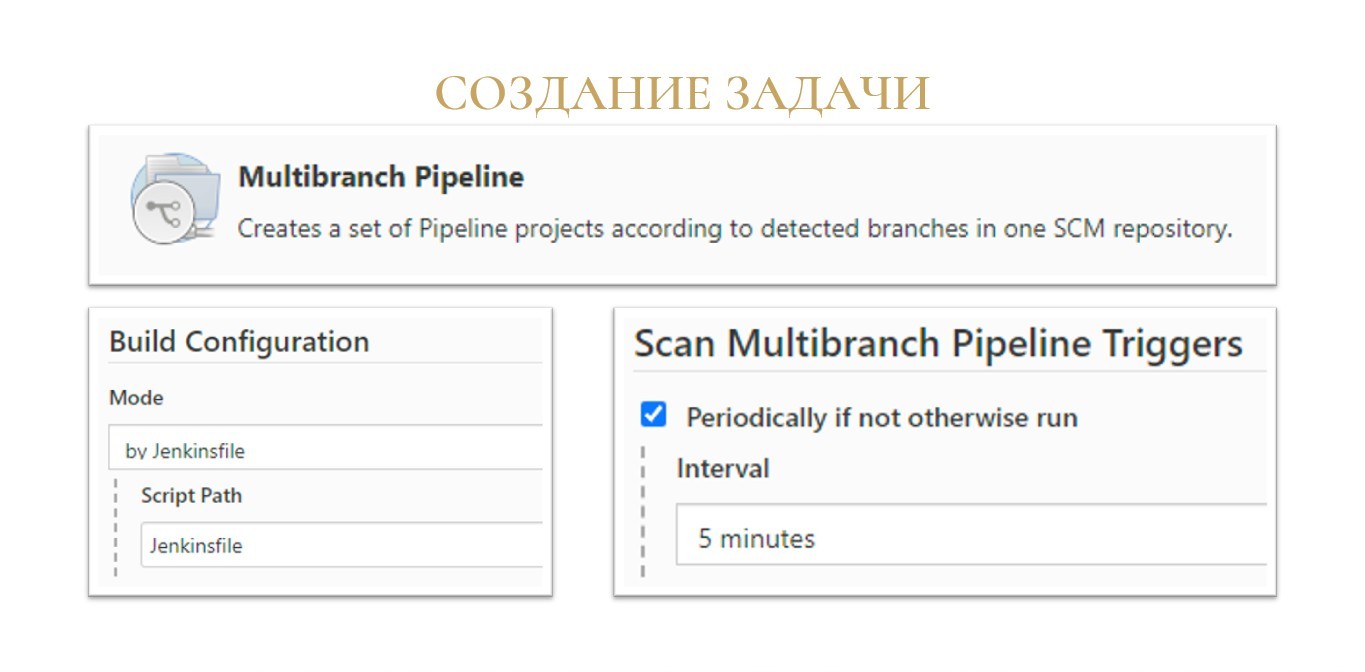
Когда мы настроили Jenkins, можно переходить к созданию сборки под ваш конкретный проект.
Библиотека заточена под работу в задачах сборки с типом Multibranch pipeline.
Как следует из названия, Multibranch pipeline – это в первую очередь pipeline, задача, все шаги которой описывается скриптом в файле Jenkinsfile.
Во-вторых, это мультибранч, такой тип задачи, который поддерживает параллельную работу сразу с несколькими ветками. У каждой ветки будет свой статус сборки.
Причем всю работу по созданию сборок под каждую ветку Jenkins берет на себя. Вам лишь нужно будет указать, как часто опрашивать репозитории, чтобы узнать, что там появились новые изменения в ветках. В самом простом варианте вы можете сказать, что мы просто раз в пять минут смотрим, поменялось ли что-нибудь в репозитории и запускаем сборки. Или вы можете настроить веб-хуки со стороны GitLab, например,
Причем даже если вы разрабатываете в хранилище, а код в Git-репозиторий попадает средствами GitSync, использование именно мультибранч-сборки в режиме нескольких веток все равно может быть полезным. Потому что в соседней ветке вы можете отлаживать изменения своих тестов, проверить работу вашей конфигурации на новой версии платформы, менять настройки самой библиотеки и т.д.
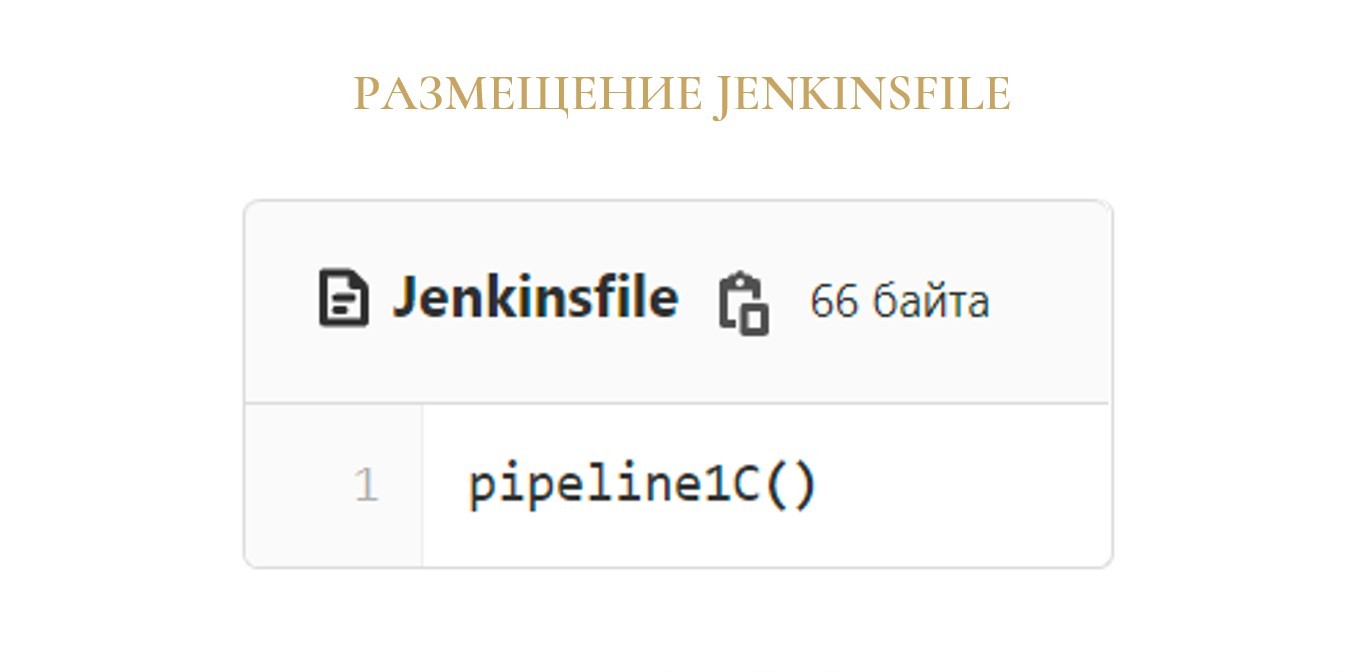
И конечно же, нам нужен сам Jenkinsfile.
Но теперь вся наша сложная логика, которая раньше была в большом Jenkinsfile, спрятана в недрах библиотеки, а вызов этой логики превращается в одну строчку – вызов функции pipeline1C(), которую предоставляет библиотека.
Просто мечта, на мой взгляд.
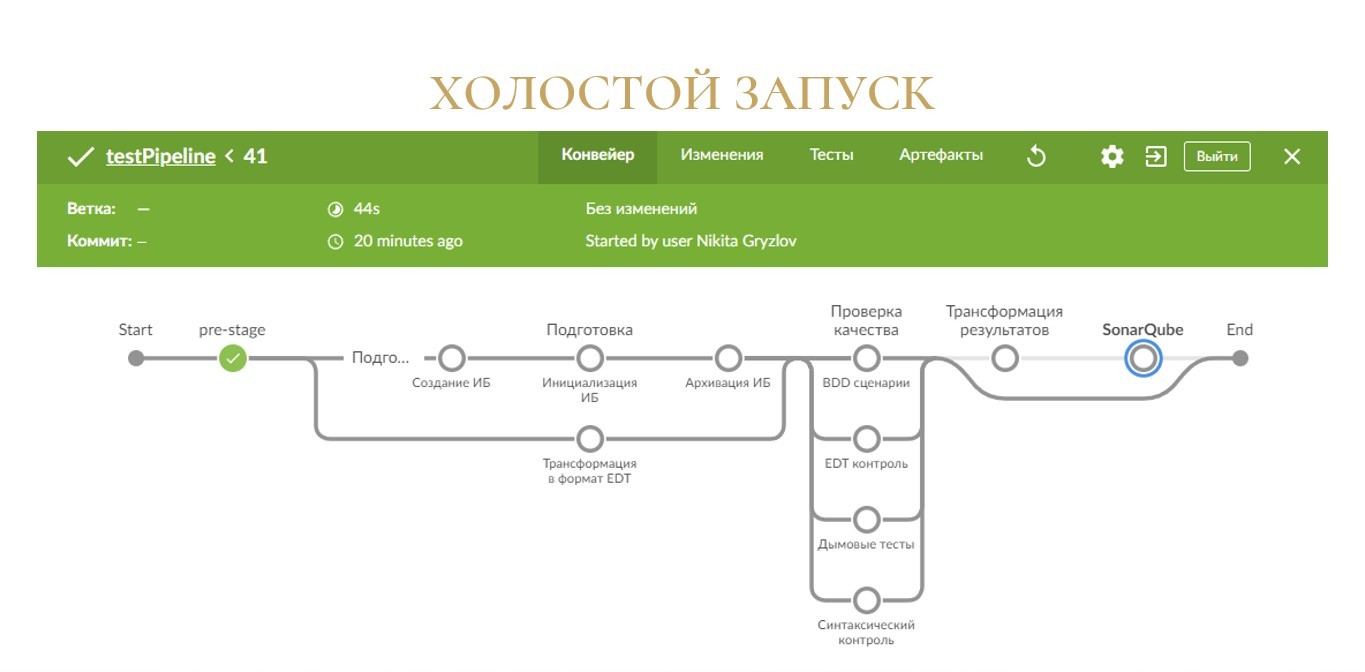
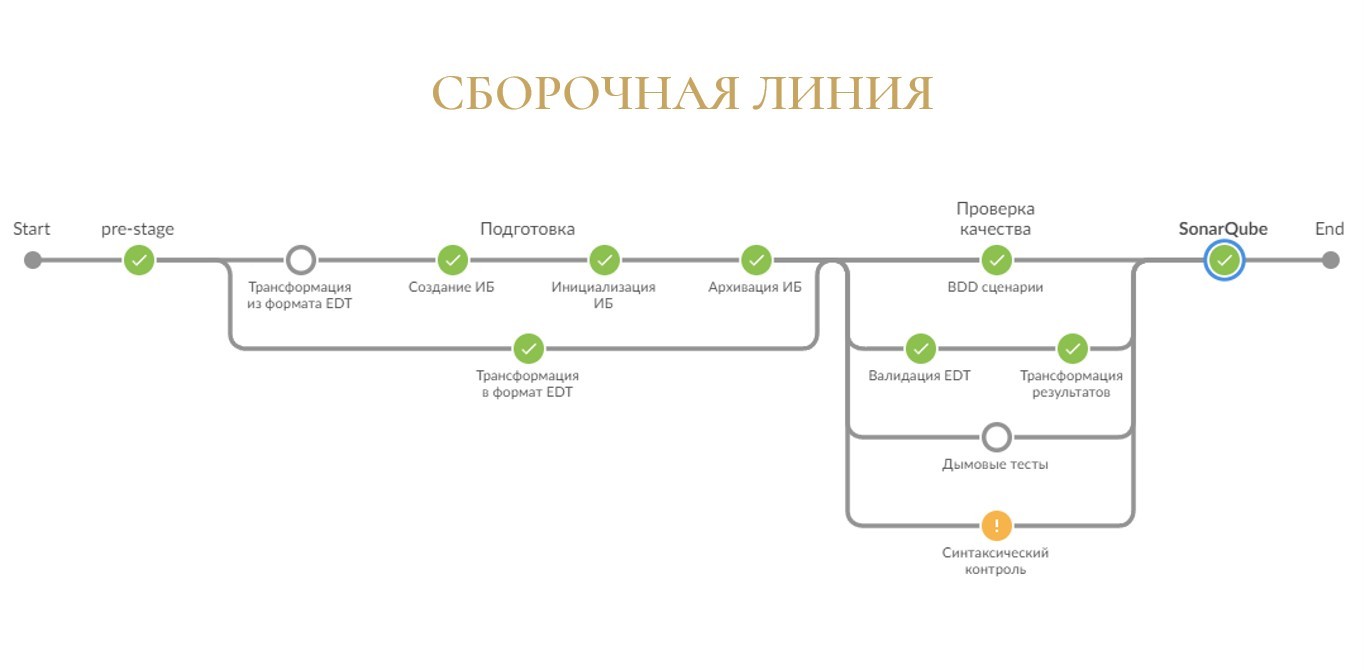
Что произойдет, если вы запустите такую сборку без каких-либо дополнительных настроек?
Если все настроено правильно, то через несколько секунд Jenkins порадует вас зеленой сборкой.
Да, ничего особо полезного он не сделал, но как минимум, теперь вы можете сказать, что у вас есть CI/CD, и ваша сборка всегда «зеленая». Этого же обычно хотят он нас топы.
Но если серьезно, то под капотом выполнилось несколько довольно важных операций.
-
Во-первых, на единственном зеленом шаге с именем «pre-stage» Jenkins попробует склонировать ваш репозиторий. Это тоже может случиться не всегда, если вдруг оказались неправильные настройки по авторизации на Git-сервере в Jenkins или неправильные настройки на машине агента для диспетчера учетных данных (Git Credential Manager для Windows).
-
Во-вторых, библиотека попыталась прочесть конфигурационный файл с настройками jobConfiguration.json в корне папки проекта. У вас его пока нет, поэтому применились настройки по умолчанию. И в этих настройках по умолчанию никакие шаги сборки далее не выполняются. Соответственно, все шаги пропустились, и сборка успешно завершилась.
Анализ на SonarQube

Знаете, что мы будем запускать в первую очередь? Всем же нужен Sonar? Давайте с него и начнем.
Базовая настройка Jenkins на анализ в SonarQube в принципе не отличается от этой настройки для других способов построения сборочных линий.
В глобальных настройках Jenkins в разделе «Конфигурация системы» нужно добавить сервер SonarQube и указать:
-
его имя;
-
URL-адрес;
-
токен аутентификации.
А уже в каждом вашем конкретном проекте в корень репозитория вам нужно положить файлик «sonar-project.properties», где указать параметры анализа:
-
sonar.projectKey – ключ проекта (его краткое имя);
-
sonar.sources – относительный путь к папке исходников;
-
sonar.sourceEncoding – кодировку исходников;
-
sonar.inclusions и sonar.exclusions – маски файлов, которые мы включаем/выключаем из анализа. Не забываем ограничивать расширения анализируемых файлов, ведь ненужный анализ XML и HTML можно ждать вечно.
Теперь переходим к самому интересному – как же заставить Jenkins запустить этот статический анализ?

Для включения шага сборки нам нужно в корне репозитория разместить JSON-файл с названием jobConfiguration.json.
В этом файле будут размещаться настройки, отличающиеся от настроек по умолчанию в библиотеке. Как я уже говорил, все шаги по умолчанию выключены, а значит, нам нужно добавить переопределение.
Для включения шага анализа с помощью SonarQube создадим элемент «stages» и его параметру «sonarqube» установим значение «true».

Если вам не подойдут настройки по умолчанию для этого шага, вы всегда в этом же файле можете что-то дополнительно переопределить, добавив соответствующую секцию настроек шага.
Например, с помощью параметра useSonarScannerFromPath для шага sonarqube можно не искать sonar-scanner в переменной окружения PATH, а сказать Jenkins, чтобы он устанавливал sonar-scanner на агент, используя механизм установки утилит.
Автодополнение при составлении конфигурационного файла
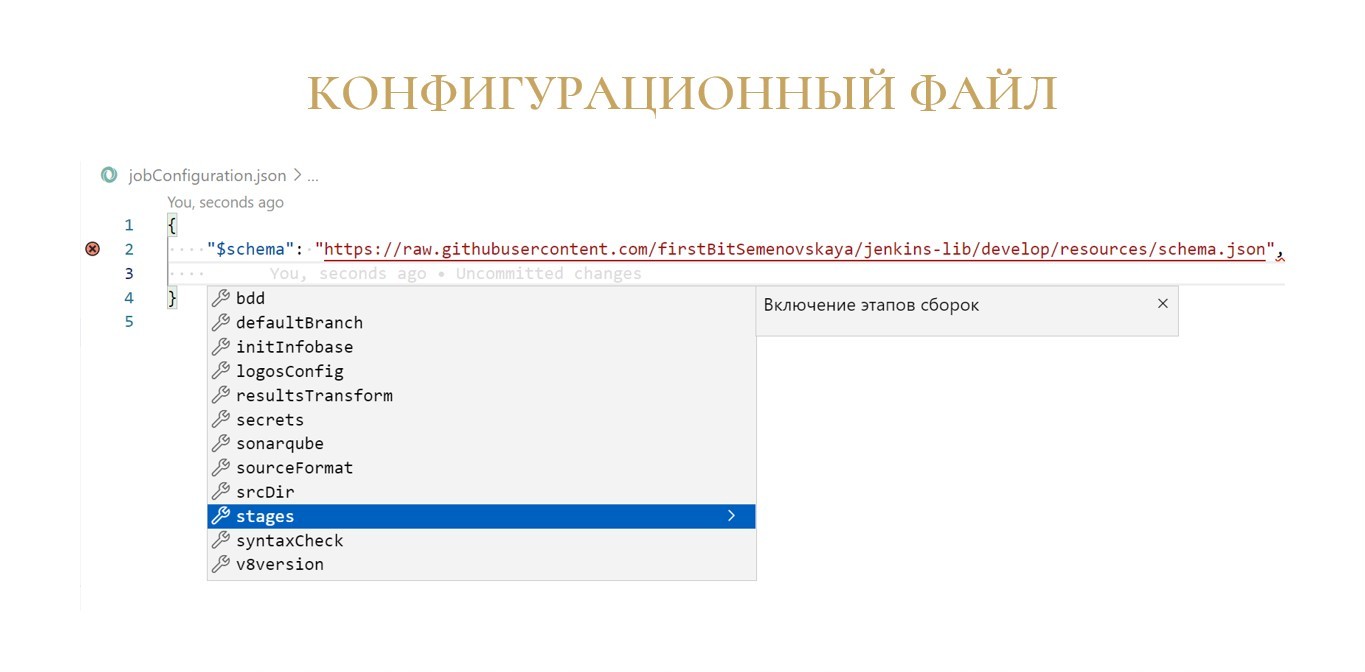
Для вашего удобства библиотека содержит файл schema.json, который сильно помогает в редактировании этого конфигурационного файла в текстовых редакторах.
При составлении своего конфигурационного файла вы можете в начало добавить строку:
"$schema": "https://raw.githubusercontent.com/firstBitMarksistskaya/jenkins-lib/master/resources/schema.json"
В результате при добавлении в этот файл новых опций будет доступно автодополнение.
На скриншоте пример из Visual Studio Code. Здесь открыто окно автодополнения, в котором как раз доступен список параметров на самом верхнем уровне файла.
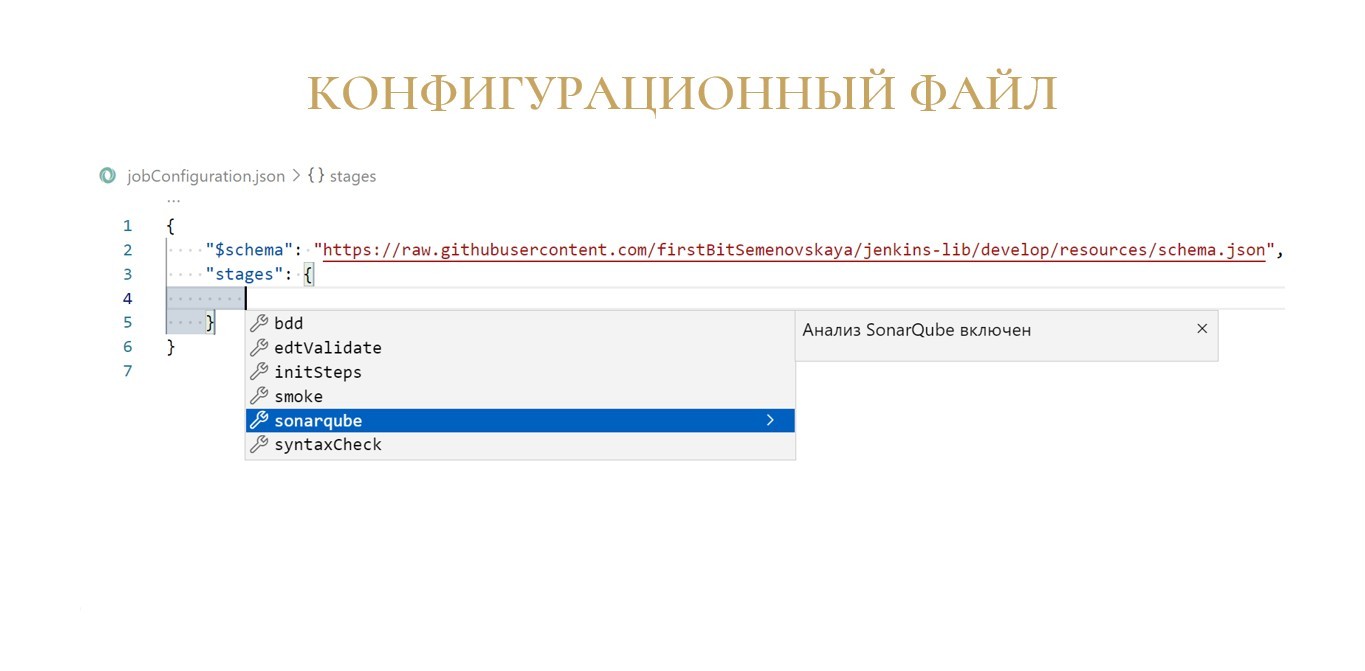
Мы выбираем «stages» – получаем список доступных для включения шагов.
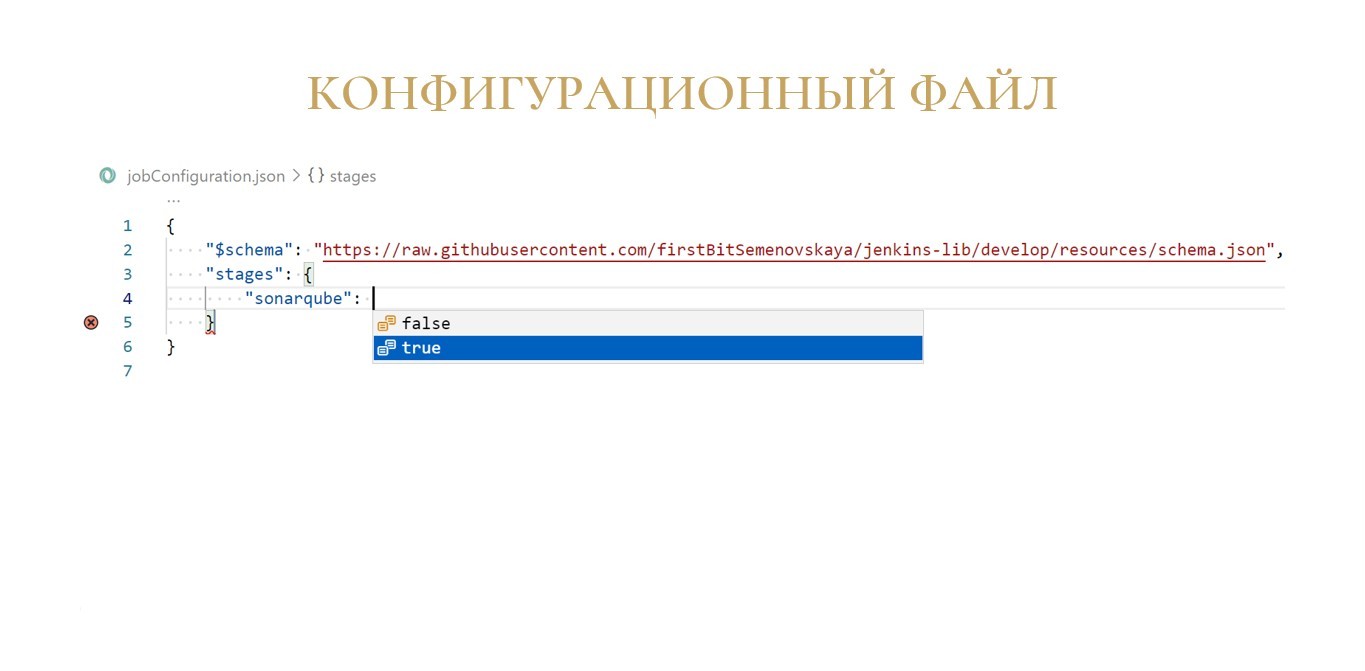
Выбираем шаг «sonarqube» – видим значения, которые мы можем установить этому параметру.
Аналогичные подсказки есть вообще для всех настроек, которые можно сделать в этом конфигурационном файле, причем везде есть краткое описание настройки на русском языке.
В подсказке также работает проверка типов – если вдруг вы в параметре, в котором нужно ввести строку, укажете число, Visual Studio Code заботливо вас предупредит волнистой линией и красным крестиком – скажет, в какой строчке у вас произошла ошибка.
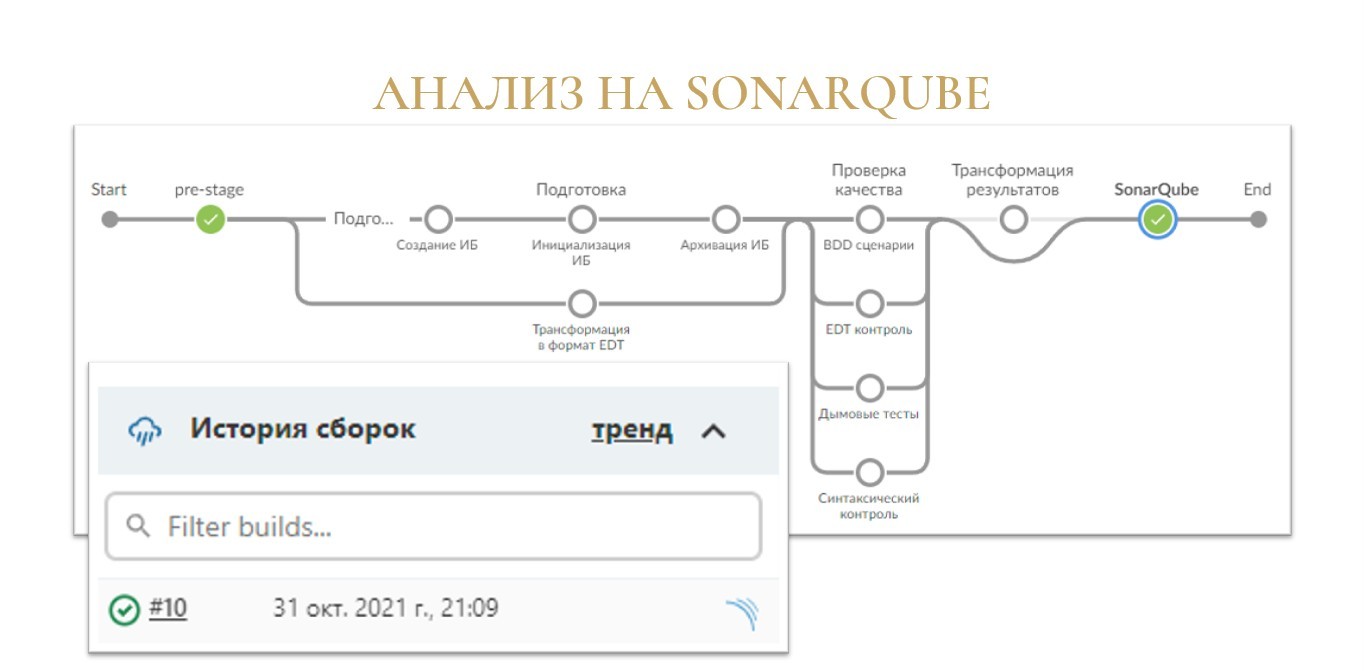
Итак, мы добавили в корень нашего репозитория файл sonar-project.properties и строчку про шаг sonarqube в конфиг jobConfiguration.json.
Что на выходе?
На выходе наша сборочная линия, которая обзавелась новым зеленым кружочком «SonarQube».
А рядом с номером сборки появилась небольшая иконка, где есть ссылка на результаты анализа на вашем сервере SonarQube.
Анализ EDT
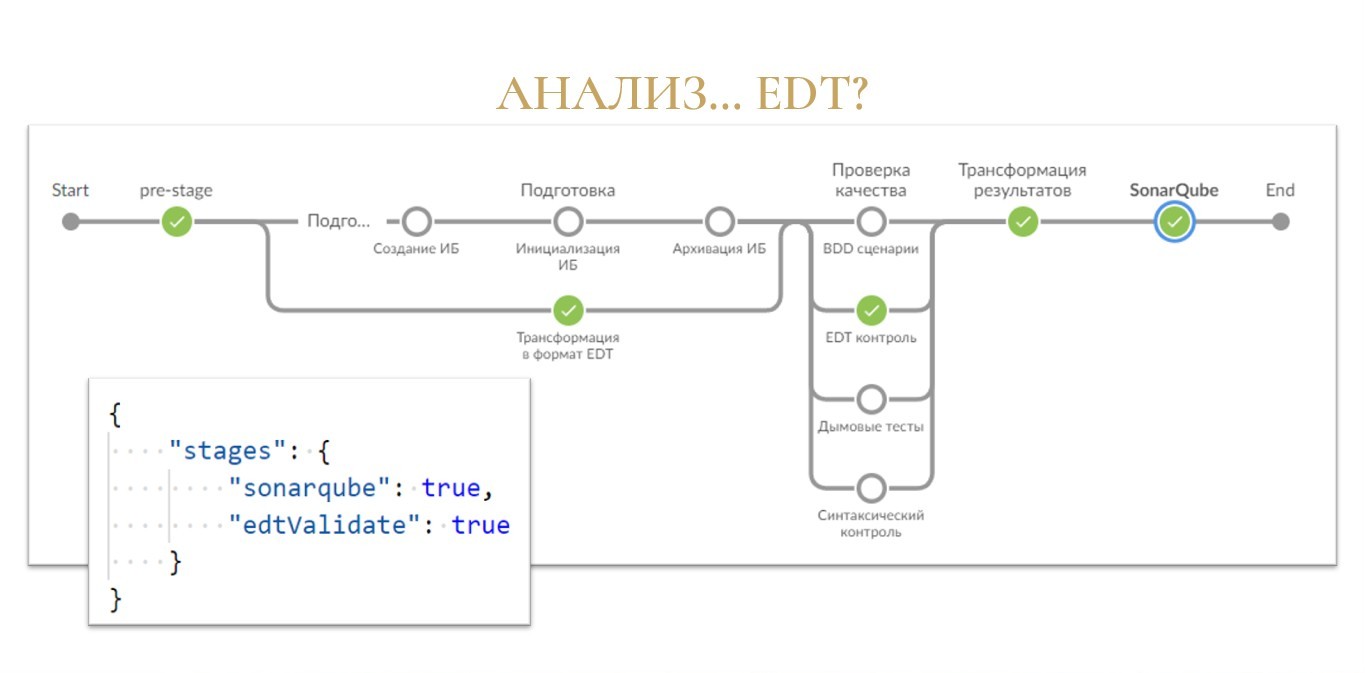
Но это только начало!
Идем дальше – как насчет подключения статического анализа средствами EDT? Видели же, когда вы код редактируете, у вас EDT-шный линтер сразу показывает, где есть ошибки. Вы это можете автоматизировать с помощью утилиты ring, которая входит в состав EDT.
С точки зрения библиотеки вам нужно всего лишь в конфигурационный файл добавить параметр edtValidate и поставить ему значение true.
Что мы получаем на выходе:
-
У нас закрасился зеленым кружочек «Трансформация в формат EDT», что в принципе логично – раз изначальная конфигурация лежит в репозитории в формате выгрузки из конфигуратора, значит, ее нужно сконвертировать для EDT, чтобы EDT понимала, что с ней делать.
-
Затем закрасился кружок «EDT контроль» в секции «Проверка качества», в котором как раз и запускается валидация средствами утилиты ring и EDT.
-
И дальше закрасился шаг «Трансформация результатов», где по умолчанию из результатов анализа вырезаются файлы на поддержке (те, которые с «полным замочком»).
И заметьте, все это – без единого скрипта с вашей стороны.

На стороне SonarQube появятся новые замечания с маркером «EDT», привязанные к конкретным файлам и строкам в коде.
А на стороне Jenkins в артефактах сборки у вас останутся файлы:
-
.log – лог рабочей области;
-
edt-generic-issue.json – результат анализа в формате generic-issue
-
edt-validate.out – результат анализа в родном формате для EDT, в csv.
Синтаксический контроль модулей 1С
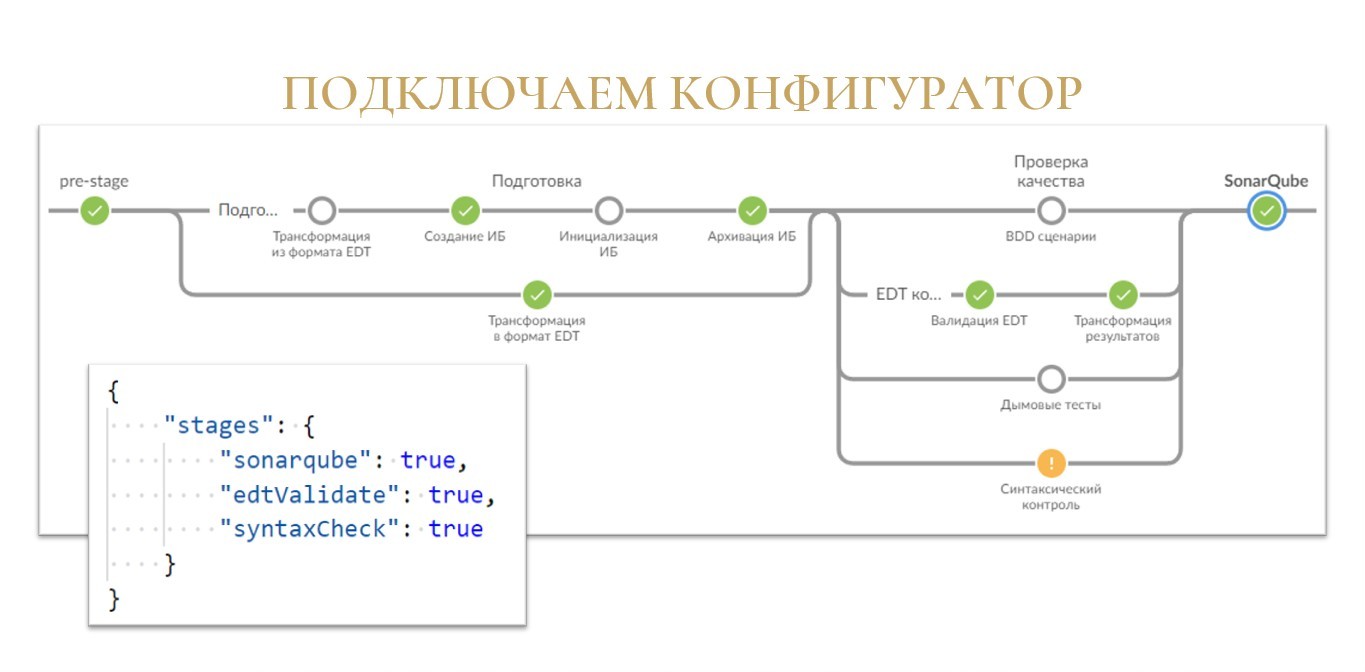
Теперь давайте все-таки попробуем подключить нашу сборочную линию к 1С.
Какая самая простая проверка, которую может дать нам 1С? Синтаксический контроль! В него же встроена и проверка модулей.
Надеюсь, вы догадались, к чему я веду. Мы взводим новый флаг «syntaxCheck» в значение «true» – и вуаля!
На этот раз шаг «Синтаксический контроль» у нас подкрашивается желтым, что символизирует о том, что обнаружились какие-то ошибки.
Конфигурации без ошибок не бывает, поэтому неудивительно.

Результаты синтаксического контроля сохраняются в формате jUnit.
Jenkins имеет довольно симпатичный просмотрщик этого результата: доступен как плоский список ошибок с группировкой по модулям, так и график с количеством ошибок в разрезе каждой сборки.
Отдельно в артефактах сборки у вас сохраняется лог проверки от конфигуратора syntax.xml.
А вас в запуске конфигуратора ничего не смущает? В том, что мы взяли и запустили конфигуратор. Откуда взялась база? Мы же вроде ничего не создавали.
Подготовка базы
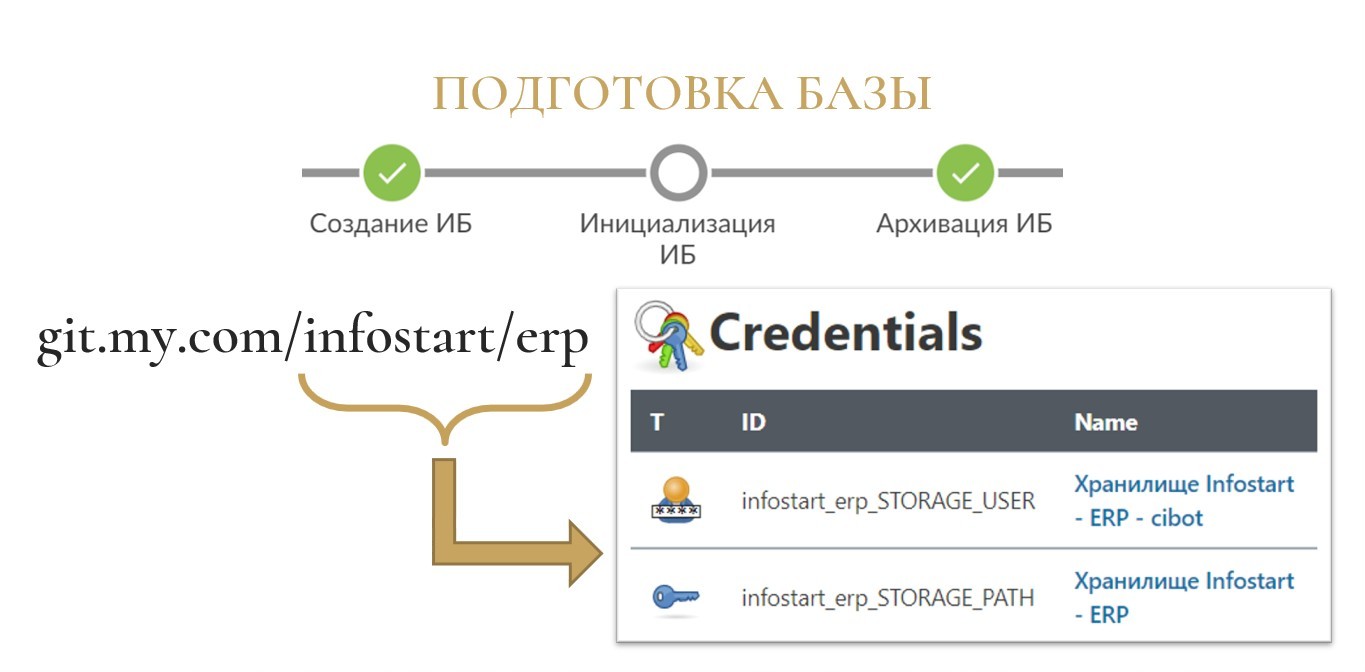
Давайте разберемся, что вообще происходит на этапе подготовки информационной базы?
Если вы успели рассмотреть скриншот сборочной линии с предыдущего слайда, там еще закрасились зеленым кружочки «Создание ИБ» и «Архивация ИБ».
Сначала создается пустая информационная база в текущей рабочей области сборки.
По умолчанию эта информационная база подключается к хранилищу. Чтобы подключиться к хранилищу, Jenkins нужно рассказать, где это хранилище живет, и как в нем авторизоваться. Для этого в Jenkins есть механизм сохранения данных авторизации и прочих секретов – Credentials.
Туда вы можете внести два новых секрета:
-
путь к хранилищу – секрет с типом secret text;
-
связка логин-пароль для хранилища – секрет с типом username with password.
Но затем возникает вопрос – как сборочная линия узнает идентификаторы получившихся секретов? Для этого есть два решения:
-
Когда вы по умолчанию заводите секрет, у него идентификатор генерируется в виде UUID. Вы можете эти UUID-ы указать в файле jobConfiguration.json в специальной секции «secrets» и библиотека будет использовать их в процессе сборки.
-
Второй вариант – вы можете сразу “правильно” указать идентификаторы этих секретов в Jenkins и тогда библиотека подберет их автоматически.
Предположим, что ваш проект живет где-то на вашем Git-сервере по пути git.my.com/infostart/erp, где Infostart – это группа проектов, а ERP – это сам проект.-
Если вы заведете секрет «infostart_erp_STORAGE_PATH», библиотека поймет, что это путь к хранилищу и будет его использовать для создания информационной базы.
-
То же самое для секрета «infostart_erp_STORAGE_USER» – библиотека воспримет этот секрет как логин/пароль от хранилища, явно указывать его в конфигурационном файле не потребуется.
-
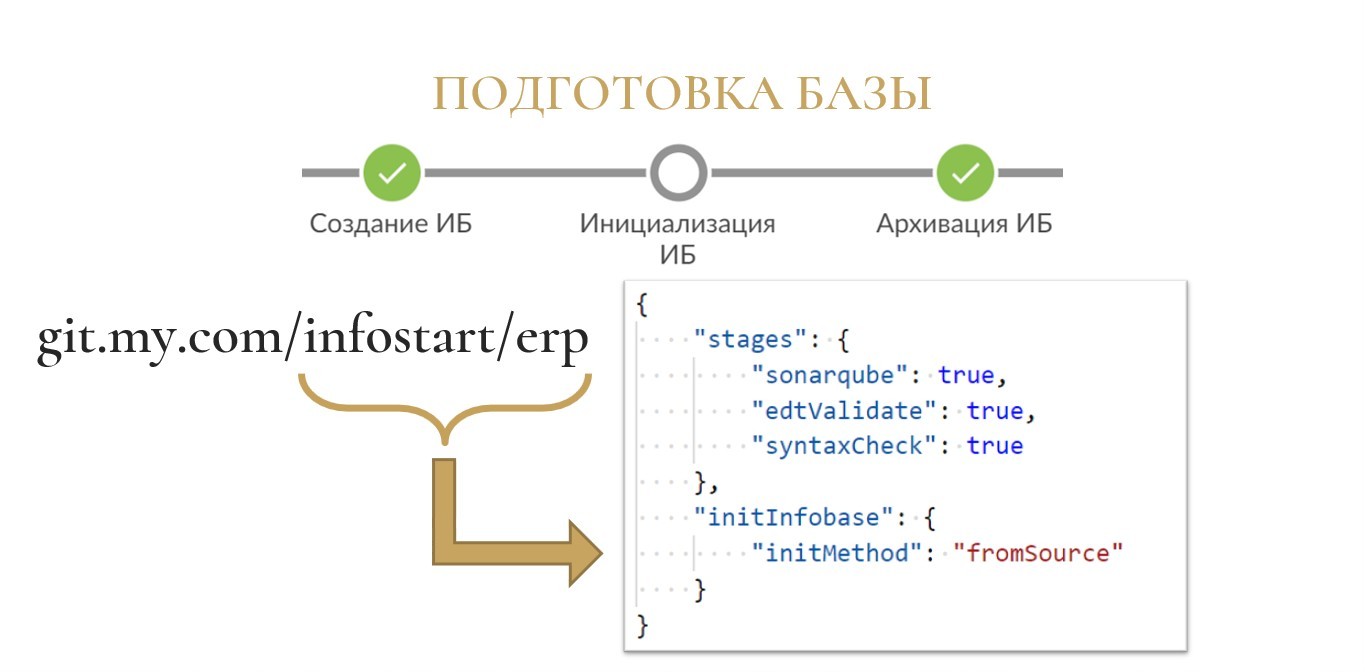
Либо же вы можете не использовать хранилище, а просто загрузить информационную базу из исходников. Для этого в отдельной секции по инициализации информационной базы вам нужно указать метод инициализации «fromSource».
Также поддерживается комбинированный вариант «defaultBranchFromStorage», когда основная ветка загружается из хранилища, а остальные подтягиваются из исходников.
Запуск BDD-сценариев

Переходим к запуску BDD-сценариев.
Обычно перед тем, чтобы хоть как-то работать интерактивно в базе, ее нужно предварительно подготовить.
Как минимум, после создания базы и наката на нее конфигурации, при первом запуске БСП от нас требует согласиться с тем, что мы легально получили обновления конфигурации, чтобы у нас запустились обработчики по миграции версии информационной базы.
jenkins-lib и используемый ею Vanessa-runner берет эту задачу на себя, если вы в конфигурационном файле включаете флаг «initSteps». В этом случае на шаге «Инициализация ИБ» библиотека понимает, что нужно запустить базу, дождаться, пока там выполнятся все обработчики, и только потом переходить к следующим шагам.
Также если в каталоге tools вашего репозитория будут лежать конфигурационные файлы запуска vanessa-runner с магическими init-именами vrunner.init.json (их может быть несколько, например, с номерами vrunner.init2.json и т.д.), то библиотека их также автоматически запустит, чтобы доинициализировать данные в вашей информационной базе. Например, создаст пользователей, контрагентов – все то, что у вас будет написано в ваших init-скриптах для vanessa-runner.
А включение флага «bdd» в конфигурационном файле запустит bdd-тестирование, используя файл tools/vrunner.json.
Все эти пути, которые библиотека берет по умолчанию, вы в любой момент можете переопределить. Это просто такое соглашение по структуре репозитория.
На выходе после отработки шага BDD на стороне Jenkins остаются артефакты в виде отчета Allure с поддержкой истории и графиков выполнения в разрезе сборок. Я думаю, что таких скриншотов на просторах Инфостарта вы уже видели много. Поэтому не будем на них подробно останавливаться.
Для простого использования библиотеки никаких дополнительных знаний больше не требуется.
Вы создали небольшой конфигурационный файл, в котором указали, какие шаги вам нужно включать. Если что-то у вас там нестандартное – переопределили, и все.
А для тех, кто хочет узнать, как это устроено внутри, или даже захочет доработать, прислать какой-то пулл-реквест, есть следующие несколько слайдов.
Устройство библиотеки

Исходники библиотеки можно изучить, скачав их из репозитория https://github.com/firstBitMarksistskaya/jenkins-lib.
Основной язык, используемый при написании jenkins-lib – это groovy, довольно «сладкий» язык (в том смысле, что в нем много синтаксического сахара), который работает поверх виртуальной машины Java.
Как и большинство библиотек, которые пишутся для Jenkins по технологии shared library, jenkins-lib содержит каталог vars, в котором опубликованы скрипты, доступные для вызова из вашего Jenkisfile. В частности, здесь находится самый главный скрипт – pipeline1C.groovy, в котором и указаны все stages – все шаги, которые будут запускаться в вашей сборочной линии.
Шаги сборочной линии обычно максимально простые, они состоят из двух частей:
-
фильтр о необходимости запуска шага;
-
собственно вызов нижестоящего скрипта.

Вся сложная логика вынесена в так называемые groovy-классы. Это полноценные классы с точки зрения объектно-ориентированного программирования, где вы можете сохранять состояние, строить нормальную декомпозицию, выносить какие-то утилитные методы или целые объекты в другие места. Это уже больше похоже на Java-разработку, чем на какое-то скриптописание.
То, что библиотека работает в окружении Jenkins, накладывает некоторые требования с точки зрения безопасности на то, как вам нужно писать код. Но после одного-двух раз, когда вы в них упретесь, они быстро запоминаются, и дальше код уже пишется без проблем.
А вся сила экосистемы Java позволяет использовать кучу готовых модулей и находить решения практически любых проблем.

Также в этом репозитории можно найти те самые настройки по умолчанию – файл resources/globalConfiguration.json.
По структуре это такой же json-файл jobConfiguration.json, который вы кладете в корень своего проекта, только здесь описаны все-все секции. По сути, это все параметры, которые вы можете переопределить.
Какие-то шаги имеют мало параметров для переопределения, какие-то – например, syntax-check – выглядят немного объемнее.
Планы развития

Что можно сказать о будущем библиотеки?
Планов, как обычно, громадье – как и у всех в Open Source.
В GitHub-репозитории есть раздел Issues, где можно посмотреть задачи, которые уже стоят перед библиотекой.
Из наиболее интересных могу отметить:
-
поддержку сбора покрытия кода тестами, используя утилиту CodeCoverageFor1C;
-
запуск дымовых и Unit-тестов – сейчас их библиотека не поддерживает, но добавить их не так уж сложно (Прим. из 2022-го года: дымовые тесты уже работают!);
-
уведомления о результатах сборки на почту, в телеграм, какие-нибудь другие мессенджеры (Прим. из 2022-го года: отправка в телеграм и почту уже реализована!);
-
недавно у одного из контрибьютеров появилась идея генерировать статичный сайт с программным интерфейсом вашей конфигурации. Например, у вас есть общие модули с областью программного интерфейса, и вы их можете превратить в HTML-описание с рубрикатором как на ИТС - полная информация о том, что в этих общих модулях есть. Такое описание можно автоматом генерировать с помощью специальной обработки. Либо, если у вас есть REST-сервисы, то по ним можно сгенерировать сайт с описанием в формате OpenAPI (Swagger).
Потребности по развитию библиотеки есть и внутри моей команды, и в целом в сообществе. Поэтому я надеюсь, что библиотека будет развиваться и дальше.
Вместо итогов
jenkins-lib в целом помогла решить озвученные в начале доклада проблемы.
-
Вместо сложносочиненного Jenkinsfile у нас теперь одна строчка.
-
Вместо проблем по добавлению новых блоков в этот Jenkinsfile, разработчикам теперь нужно завести один-два параметра в маленьком конфигурационном файле.
-
Вся магия и сложность по настройке сборочной линии скрыта внутри библиотеки, и конечных пользователей не касается.

Подытожить я хочу скриншотом конфигурационного файла с моего реального проекта, чтобы окончательно продемонстрировать, что библиотека действительно работает, и применять ее легко.
От рассмотренного ранее примера она отличается буквально тремя моментами:
-
указывается конкретная версия платформы «v8version» и имя ветки по умолчанию «defaultBranch»;
-
в качестве способа инициализации информационной базы используется загрузка из хранилища для главной ветки и загрузка из исходников для остальных веток – defaultBranchFromStorage;
-
из результатов анализа EDT вырезаются не только файлы на замках, но и файлы просто с «желтым кубом» (“supportLevel”: 1) – у нас такие особенности ведения проекта.
Вроде бы ничего сложного и страшного. Приглашаю попробовать и рассказать о впечатлениях :)
Полезная информация
Обещанные полезные ссылки на репозитории и доклады.
-
jenkins-lib – https://github.com/firstBitMarksistskaya/jenkins-lib
-
onec-docker – https://github.com/firstBitMarksistskaya/onec-docker
-
Валерий Максимов «CI/CD для 1С проектов, унифицировано, с кастомизацией» – //infostart.ru/1c/articles/1198146/
-
Антон Степанов «Конвейер проверки качества кода» – //infostart.ru/public/1117485/
-
Никита Федькин «1С on demand – скажи "нет" постоянным билд-агентам» – //infostart.ru/1c/articles/1368078/
*************
Данная статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Moscow Premiere.


Вступайте в нашу телеграмм-группу Инфостарт