Когда возникают задачи аналитики и интеграции, многие хватаются за голову и не знают, как к ним подойти. Высокая неопределенность, много сложностей. Постараюсь упорядочить информацию из моей практики и рассказать, как я решаю такие задачи в компаниях.
-
Рассмотрим методики и инструменты, которые помогают аналитику эффективнее справляться с задачами, а также подходы к разработке.
-
Разберем НСИ и интеграции – что такое нормативно-справочная информация для интеграции и как строятся схемы в привязке к НСИ.
-
Затронем набор знаний аналитика по конфигуратору и метаданным 1С.
-
Обсудим обязательные требования к аналитику 1С, который хочет развиваться в сторону архитектора.
-
Рассмотрим вопросы, связанные с шиной, и то, как аналитику подойти к этой теме: какие есть особенности.
-
Разберем несколько кейсов по использованию искусственного интеллекта.
Сложности разработки интеграции и необходимость проектного подхода
По сложности разработки интеграции – это область высокой неопределенности. Часто система представляет собой «черный ящик» – исторически сложившиеся, импортные или отраслевые решения, сильно доработанные за годы разными командами. Интеграция обычно требует взаимодействия нескольких команд, каждая из которых отвечает за свою систему и коммуникации.
Возникают сложности с коммуникацией, оценкой трудозатрат и сроков, необходимостью погружения в бизнес-логику или, наоборот, отказом от нее. Вопросы тестирования, производительности и масштабирования также относятся к разработке интеграций.
Каждую интеграцию можно рассматривать как мини-проект со всеми вытекающими: проектный подход и соответствующие практики здесь полностью применимы. Часто именно в этой задаче отсутствует методика и подход, поэтому разберем, как это делать правильно.
Классический подход waterfall подходит для проектов любого масштаба, в том числе для отдельно взятой интеграции. С точки зрения проектных технологий интеграцию целесообразно структурировать на этапы:
-
Обследование,
-
Моделирование,
-
Проектирование,
-
Разработка,
-
Тестирование,
-
Опытно-промышленная эксплуатация (ОПЭ).
Роль аналитика на каждом этапе интеграции
Все этапы процесса плотно задействуют аналитиков, кроме этапа разработки, на котором разработчики создают правила обмена, подключают транспорт и выполняют техническую часть.
На этапе обследования интеграции нужно определить задачу, описать бизнес-процессы, нормативно-справочную информацию и сами интеграции. Далее – определить метрики для оценки, чтобы иметь количественные показатели и понимать масштаб работы.
Моделирование – один из самых важных этапов, который при интеграциях часто упускают. Здесь проводится анализ данных и проработка ожидаемых результатов. Еще до начала разработки необходимо промоделировать итоговое поведение системы.
На этапе проектирования выбираются форматы и протоколы с учетом требований безопасности и особенностей инфраструктуры. После этого аналитики выполняют мэппинг данных, когда необходимо сопоставить объекты различных систем.
Очень важный элемент – сценарий тестирования. Его нужно заранее проработать и подробно описать в документации: как именно будет проверяться интеграция. Это не только пользовательские сценарии вроде «ввести документ и проверить, как он передался в другую систему», но и технические инструменты проверки.
При нагрузочном тестировании применяются генераторы данных. Если нужно прокачать исторические данные из старой системы, например номенклатуру, используются авторегистраторы – они позволяют зарегистрировать данные на узлах обмена и затем выполнить сам обмен. Также применяются автоматизированные сверки.
Сценарии переходят на этап тестирования, по ним аналитик проверяет результаты.
Часто итоги работы переходят в опытно-промышленную эксплуатацию, где начинаются итерации: всплывают особенности, выполняются доработки, повторные прокачки и проверки. На этот этап часто ставят бэклог и оптимизацию, и он нередко превращается в «бесконечный процесс», если не учесть ключевые моменты, связанные с моделированием и тестовыми сценариями.
Все предыдущие этапы имеют гранулярную структуру – их можно применять и разбивать в привязке к объектам, бизнес-процессам или функциональным блокам: рассматривать отдельно НСИ, остатки и перенос исторических данных.
Оценка трудоемкости интеграции
Количество задач быстро растет, если разложить процесс по всем этапам. Шесть этапов, умноженные на количество объектов, дают внушительный объем работы: при 10–20 объектах это уже около 120 задач. Поэтому задачи стоит объединять в кластеры – так проще управлять процессом и планировать работу.
На начальном этапе важно провести оценку разработки правил обмена. Оценка строится по простому принципу: считаем количество объектов интеграции в одну и другую сторону и умножаем на норматив. Например, если нужно передать 10 документов и 20 справочников, то при нормативах 20 часов на документ и 10 часов на справочник получаем общую оценку трудоемкости разработки правил.
Далее добавляется трудоемкость настройки обменов и оценки по остальным шести этапам. Их можно рассчитывать в процентном отношении от объема разработки – например, 20% на постановку, 30% на тестирование. В итоге формируется универсальная формула.
Нормативно-справочная информация (НСИ) и ее описание

Нормативно-справочная информация в контексте интеграции – это описание информационных ресурсов: серверов, сервисов, каталогов обмена, участвующих в процессе. Сюда входят системы и конфигурации – БП, УТ, комплексная ERP, УХ, документооборот, SAP, ACSAP и другие информационные системы.
Далее идут информационные базы: для каждой системы их может быть несколько – например, отдельная Бухгалтерия и ЗУП для каждого юридического лица.
Возникает вопрос, где все это описывать. Чаще всего используют Excel. Бывают и абсурдные случаи – на одном оборонном предприятии базы и конфигурации фиксировали в Google-таблицах, то есть инфраструктура оборонного предприятия велась в облачном сервисе.
Существуют стандарты и инструменты вроде СППР и ITIL, где предусмотрены справочники для таких целей. У нас это описано в собственной системе на базе 2iS:Интеграции: справочники заполняются там, а по ним формируются отчеты и документация.
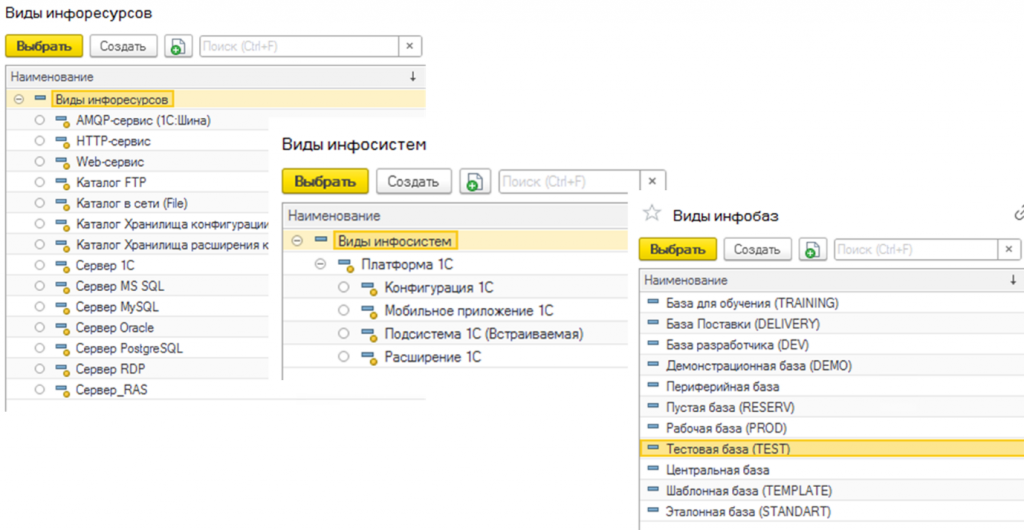
К видам информационных ресурсов относятся серверы, каталоги и сервисы. Далее идут классификаторы: виды ресурсов и информационных систем – конфигурации 1С, мобильные приложения, встроенные подсистемы, расширения. По видам инфобаз выделяются рабочие, тестовые, центральные, шаблонные, эталонные, учебные базы и так далее.
Моделирование как критически важный этап
Моделирование интеграций – один из ключевых этапов, и его отсутствие – частая ошибка: когда разработчика сразу сажают писать переход из, например, УПП в ERP без этапа моделирования.
Моделирование – это ручное создание в целевой системе того результата, который мы хотим получить после настройки обмена. Да, это трудоемко и рутинно, но без этого разработчик не понимает, какой именно должен быть результат. Он пишет правила, как хочет: настроил, показал, нашли ошибку, что реквизиты не заполняются, пошли на второй, третий круг, и работа получается непродуктивной.
В системе-приемнике нужно зафиксировать результат, который должен получиться после настройки и выполнения обмена, то есть фактически «набить» этот результат. Например, если обмен идет с системой ТОИР, в ERP создается документ ремонта, заполняются табличные части, увязываются объекты, строится отчет – и проверяется, что данные легли правильно. Затем этот эталон передается разработчику: «Вот так должен выглядеть результат обмена».
То же самое касается системы-источника. Если это 1С, необходимо смоделировать данные и на входе, и на выходе. Если система историческая и представляет собой «черный ящик», моделирование включает разработку формата передачи – аналитик описывает перечень полей: фактически таблицу с колонками в Excel, которая должна превращаться в данные целевой системы.
Рекомендация проста: этап моделирования и миграции нужно начинать с самого начала проекта – параллельно или даже до основной разработки. Это снижает риск затягивания сроков, сбоев интеграции и переходов, а также позволяет использовать уже существующую нормативно-справочную информацию компании.
Проектирование интеграции: протоколы и форматы
Проектирование интеграции начинается с выбора протоколов передачи данных: HTTPS, веб-сервисов, SOAP, AMQP (протокола очередей) и других. Аналитику здесь, как правило, не требуется что-то настраивать – его задача определить то, как сейчас работает компания. Как правило, это требования системы информационной безопасности: в крупных организациях формат взаимодействия заранее закреплен: например, обмен только через SOAP-веб-сервисы.
Если компания более гибкая и открытая, удобнее использовать MQP-протокол – он поддерживается всеми современными брокерами сообщений (RabbitMQ и аналогичными шинами). Классический HTTP также остается популярным, а SOAP-веб-сервисы сегодня считаются устаревшими, хотя некоторые специалисты по-прежнему считают их более защищенными.
Далее выбираются форматы данных. Технические форматы – XML и JSON, прикладной формат – структура данных, описанная XML-схемой.
Около десяти лет назад, когда JSON появился в платформе 1С, проводились нагрузочные тесты, и было установлено, что по скорости обработки XML и JSON практически не различаются. JSON действительно занимает меньше места, так как не содержит тегов, но XML при передаче обычно сжимается (zip), и объем становится сопоставимым.
Таким образом, выбор между XML и JSON чаще определяется удобством, привычкой и требованиями конкретного проекта, а не техническими ограничениями.
Транспорт, мэппинги и инструменты аналитика
В части транспорта можно использовать шину, API или готовые библиотеки, встроенные в 1С.
API применяют, когда нужно открыть 1С наружу – описать форматы данных, чтобы внешние системы могли к ней подключаться.
Далее аналитики выполняют настройку соответствий – мэппинг. Оптимальный инструмент для этого – «Конвертация данных» (вторая или третья редакция). Продвинутые специалисты могут использовать XSLT-трансформацию, но это сложный международный инструмент, требующий высокой квалификации.
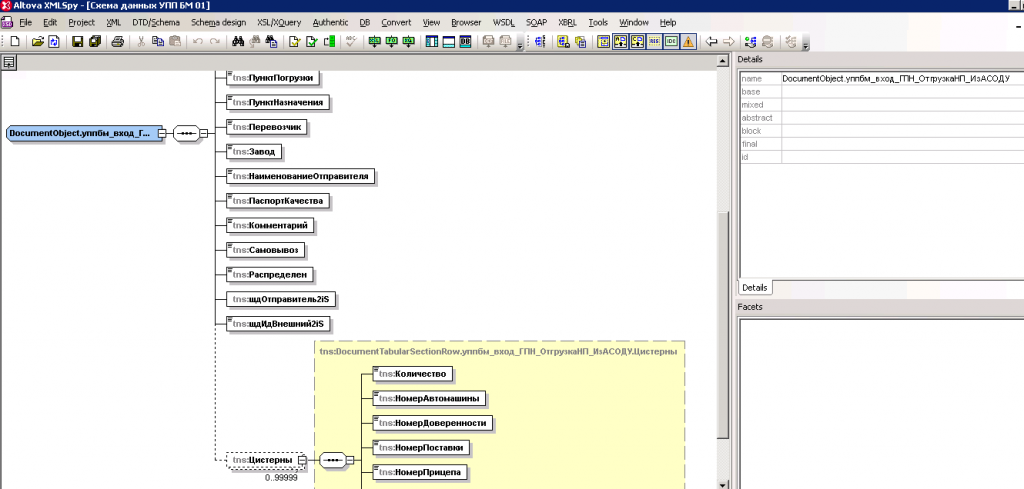
Когда интеграция ведется с внешними системами и нет готовых форматов, необходимо создать собственную структуру передачи данных. Пример – документ «Отгрузка НП» с реквизитами шапки и табличной частью «Цистерны». Для таких задач удобно использовать XMLSpy – инструмент немецкой компании Altova. У него есть 30-дневная бесплатная версия, и он до сих пор доступен для скачивания в России. Это один из лучших продуктов для редактирования XML-схем.
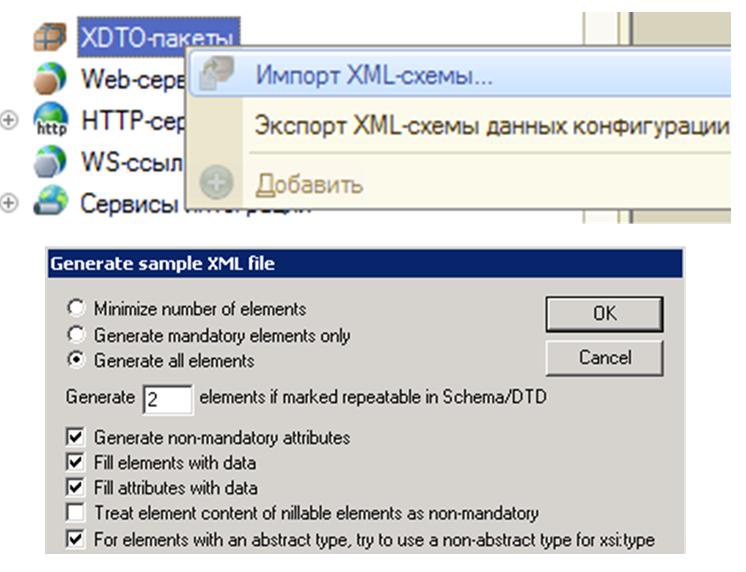
Результатом работы в XMLSpy является схема, которую затем можно загрузить в 1С. Она автоматически преобразуется в пакеты xDTO.
По разработанной схеме можно сгенерировать XML или JSON. В инструменте есть окно, где задается количество повторяющихся элементов и включается автозаполнение случайными данными. Таким образом, по созданной схеме XMLSpy формирует готовые XML- или JSON-файлы, которые можно использовать как основу для программиста.
Работа с инструментом не требует глубоких знаний. В новой версии добавлен встроенный искусственный интеллект, который понимает простые запросы на английском языке, например: «Сформируй XML-запрос для получения всех элементов типа “товар”» или «Создай схему данных по такому-то описанию». Движок достаточно мощный, но пока не был протестирован на практике.
На этом инструменте создано множество форматов для 1С. В свое время на XMLSpy разрабатывался CommerceML – формат обмена с «Битрикс» и сайтами, клиент-банковские протоколы, анкеты для ЗУП. Формат EnterpriseData, вероятно, также создавался с использованием этого инструмента, однако точных сведений об этом нет.
Конфигуратор как главный инструмент аналитика
Основной инструмент аналитика – это конфигуратор 1С. Внешние утилиты полезны, но главное преимущество аналитика, который хочет развиваться в этой области, – умение работать в конфигураторе. В нем можно описать структуры данных практически любых систем, адаптируя их под 1С. Любую внешнюю систему можно представить в виде структуры данных внутри чистой конфигурации.
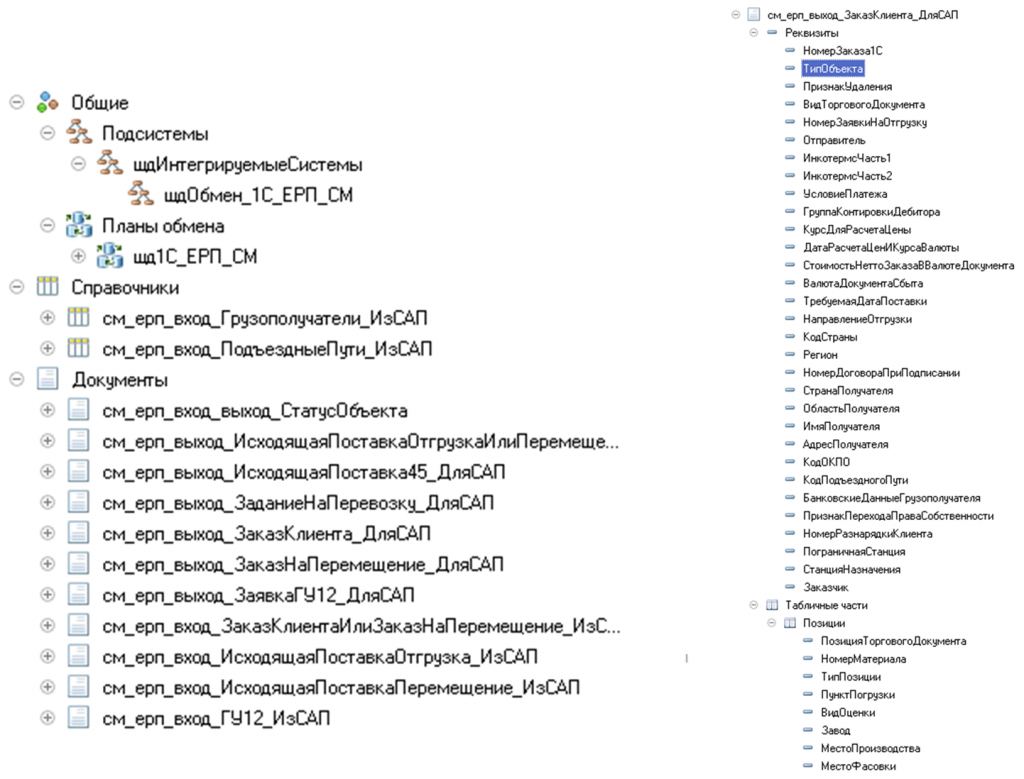
Так, например, в 1С описана структура данных для SAP. Взяты поля и объекты SAP и воспроизведены в конфигураторе – созданы два справочника («Грузополучатели» и «Подъездные пути») и набор документов. Справа отображен формат SAP-заказа, где в синонимах к реквизитам указаны оригинальные английские имена. Таким образом, мэппинг выполняется напрямую – «один к одному», что позволяет использовать те же поля, что и в SAP.
В конфигураторе можно описывать не только внешние системы, но и исторические данные или форматы Excel. Например, при загрузке остатков по основным средствам используется таблица с колонками: дата, сумма, первоначальная стоимость, эксплуатация. Эту таблицу можно описать в 1С как справочник, а затем через инструмент «Конвертация данных» связать (замэпить) столбцы Excel с реквизитами в 1С.
В конфигураторе можно описывать не только структуры данных, но и различные API – все необходимые объекты для этого есть: веб-сервисы, HTTP-сервисы, сервисы интеграции.
Отдельное внимание стоит уделить плану обмена – каждый аналитик должен понимать, что это такое и как работает, потому что это один из ключевых механизмов регистрации изменений в системе 1С. План обмена используется во множестве задач и требует обязательного знания. На собеседованиях по интеграциям вопрос о нем задают всегда, и нередко даже архитекторы затрудняются ответить. Например, что такое узлы? А узлы – это, по сути, описатели систем и баз, между которыми выполняется обмен.
Инструмент «Конвертация данных» применяется для настройки мэппингов – не только между базами 1С, но и при загрузке данных из Excel, исторических систем и НСИ.
Структуры SAP также можно описать в конфигураторе и затем использовать конвертацию данных для создания правил обмена между SAP и 1С или для загрузки Excel-данных в 1С. Этот инструмент настоятельно рекомендуется к освоению – он универсальный и удобный.
Документирование интеграций в 1С
Для документирования API подойдут Swagger (описание) и Postman (тестирование). Эти инструменты активно используются и хорошо зарекомендовали себя в работе.
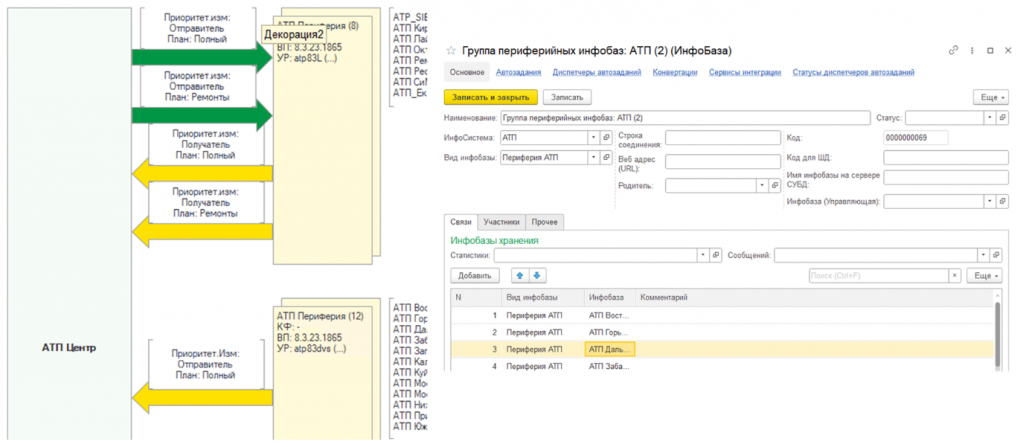
В нашей системе для документирования интеграций реализована визуальная схема, основанная на встроенном редакторе графических схем 1С. С его помощью все обмены можно описывать графически – в виде блоков и стрелок. Эти схемы создаются вручную, в свободной форме.
К каждому элементу схемы можно привязать карточку конкретного объекта. Если это база – карточку информационной базы; если группа баз – карточку группы, где указан их состав.
Решение оказалось удобным и наглядным: схема становится интерактивной точкой входа в настройки интеграции, объединяя визуализацию и документацию в одном месте. Рекомендую к использованию.
Когда нужна шина и как с ней работать
Шина данных необходима в случаях:
-
Наличия более трех ИнфоСистем.
-
Наличия более трех ИнфоБаз.
-
Наличия более 10 потоков (БП, ЗУП, ДО, CRM, Отраслевое решение…).
-
Необходимости маршрутизации по ЮЛ, ЦФО, Складам и т.д.
-
Необходимости передачи объектов «один ко многим».
-
Работы в гетерогенной среде, под управлением Linux.
-
Трудностей и проблем по мониторингу обменов (своевременная реакция, статистика) / производительности.
-
Систематизации и наведения порядка в обменах (разбор исторического наследия, документирование, внедрение MDM).
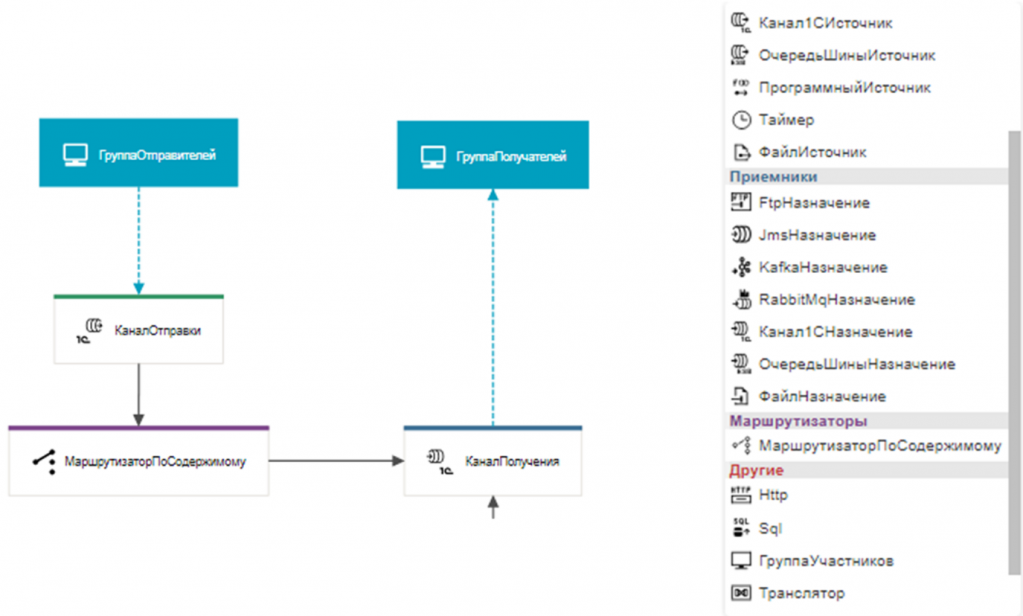
От аналитиков не требуется глубоких знаний – достаточно понимать принципы и применять их на практике.
Схема работы шины универсальна: есть группа отправителей и группа получателей. В группу отправителей можно добавить базы 1С, в группу получателей – другие базы, после чего настроить маршрутизацию пакетов.
Среди поддерживаемых адаптеров – Rabbit, Kafka, HTTP-коннекторы и другие решения, что позволяет подключать к шине внешние источники и другие шины. Этого достаточно, чтобы проектировать интеграции с ее использованием.
Схемы рекомендуется делать простыми. 1С официально советует не усложнять архитектуру.
Применение искусственного интеллекта
Мы активно используем искусственный интеллект: таймлисты, стенограммы, автопротоколы, статусные встречи, пресейлы, демонстрации. Ждем версию, которая сможет не только распознавать текст, но и вставлять изображения по команде – простая, но пока не реализованная функция.
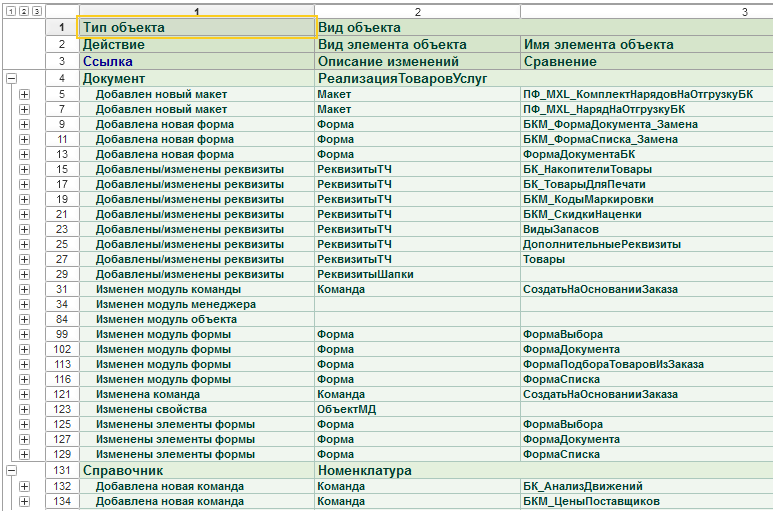
Из интересного – мы применили искусственный интеллект для сравнения доработанных конфигураций. Решение построено на GPT.
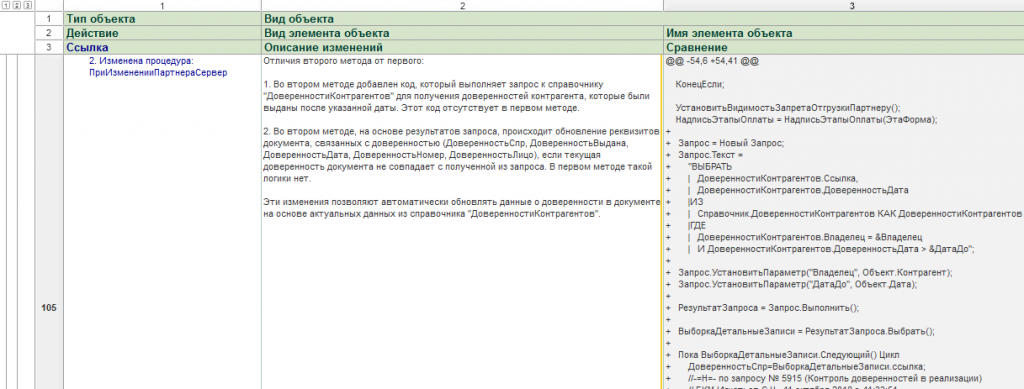
Процесс выглядит так: конфигурация выгружается в XML, затем с помощью kdif выполняется сравнение модулей – что добавлено, что изменено. Результат передается нейросети, и она автоматически формирует текстовые описания изменений.
Справа отображаются плюсы и минусы – что добавлено или удалено, а слева – сгенерированное нейросетью описание кода. У клиента на двух объектах набралось несколько сотен таких изменений, но все они структурированы и разобраны по блокам.
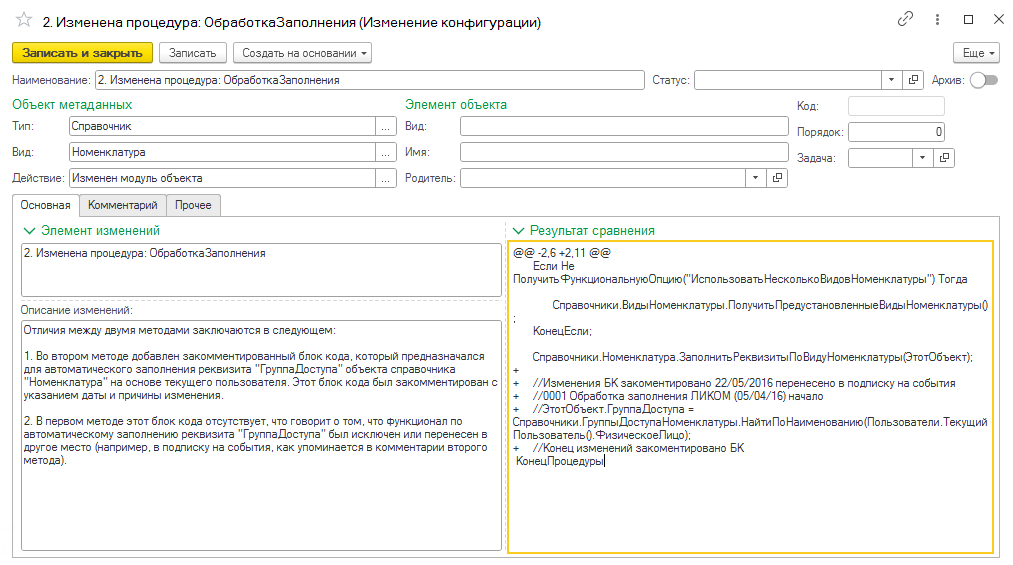
Мы сделали удобный интерфейс: карточку изменений с привязкой к метаданным и структурным элементам.
Это удобно, потому что основная задача – оценить старые доработки и определить, какие из них нужно перенести в новую систему. Искусственный интеллект значительно упрощает анализ, автоматизирует рутину и ускоряет процесс принятия решений.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Анализ & Управление в ИТ-проектах.

