Контекст: портал, технологии и архитектура

Так выглядит наше единое информационное пространство для закупочной деятельности. С точки зрения пользователя это один портал, но на самом деле пользователь авторизуется во множестве бэкендов, которые являются информационными базами 1С.
Используемые технологии:
-
Фронтенд: Vue 3. Сделан набор компонент для быстрой разработки, технология FEaaS (Front-End-as-a-Service).
-
Бэкенд: 1С (8.3.24z), PostgresPro.
-
Транспорт: Прокси на Rust, RabbitMQ/HTTP для обмена сообщениями, подписчики SSE (Server Sent Events).
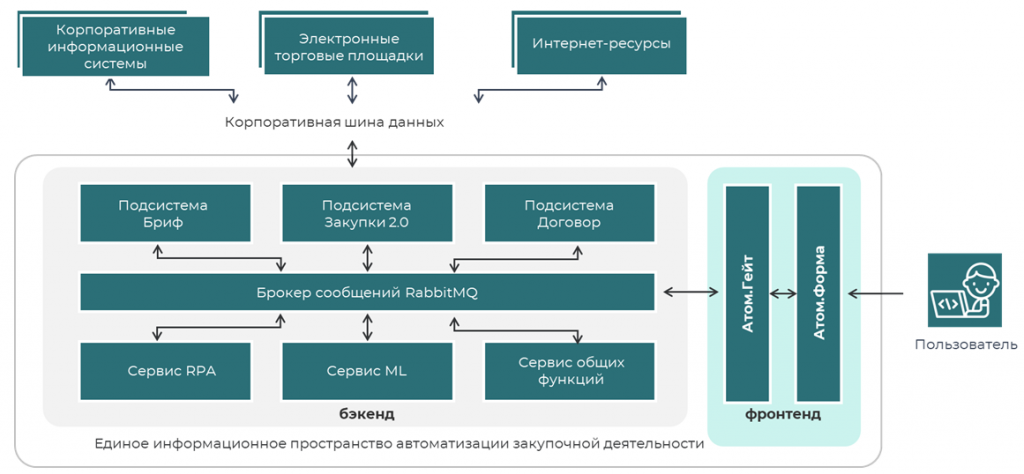
Пользователь авторизуется через портал, через proxy все это передается в RabbitMQ, в нужные системы эти данные отправляются по запросу и отображаются пользователю на портале.
Масштаб и проблемы производительности
В нашей системе очень много пользователей в пиковые часы: больше четырех тысяч. У нас сотни интеграционных сценариев, тысячи фоновых заданий. Более 40 серверов, которые находятся в разных контурах. Есть отдельный контур для внутренних сотрудников и отдельный контур для внешних поставщиков. Контуры связаны обменами. Требуется большое количество изменений с каждым релизом. У некоторых систем Apdex составлял 0,85 и ниже.
Какие проблемы мы выделили:
-
Отсутствие мониторинга производительности на серверах 1С.
-
Без системного мониторинга информационные комплексы постепенно деградируют по производительности, вплоть до недоступности.
-
Растет количество обращений пользователей, в том числе из-за вопросов производительности.
Чтобы их решить, мы создали технологическую группу, которая занимается вопросами производительности проектов.
Система мониторинга: из чего состоит и как устроена
Как мы подошли к мониторингу:
-
Мониторинг железа – это типовые средства: Zabbix, Grafana, алерты ответственным сотрудникам.
-
Мониторинг технологического журнала проводим еженедельно и отдельно после релизов.
-
Мониторинг ошибок журнала регистрации.
-
Мониторинг баз данных (размеры, отчеты pg_pro_pwr).
-
Apdex: за ним нужно следить в динамике.
Как мы выстроили систему мониторинга:
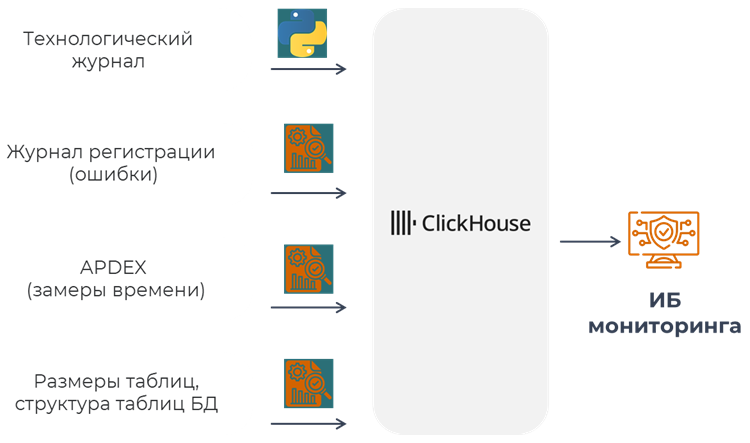
Система мониторинга состоит из нескольких подсистем. Первая – парсер технологического журнала на скриптах на Python плюс дополнительные обработки в каждой информационной базе для сбора дополнительной информации: Apdex, структура таблиц, ошибки журнала регистрации. Все это сливается в ClickHouse, и есть специальная информационная база мониторинга, где мы смотрим результаты того, что туда загрузили.
Парсер на Python
Почему мы выбрали Python? Он простой в разработке и поддержке, достаточно производительный для своих задач, кроссплатформенный. Он уже есть в Linux, поэтому ничего устанавливать не надо: написал скрипт – все работает. Он читает данные ТЖ порциями, по HTTP отправляет их, чтобы весь ТЖ не держать в оперативной памяти, и штатно запускается через cron с некоторой периодичностью. Есть различные ключи запуска: можно грузить не только новые данные за предыдущий час, но и с фильтром.
ClickHouse
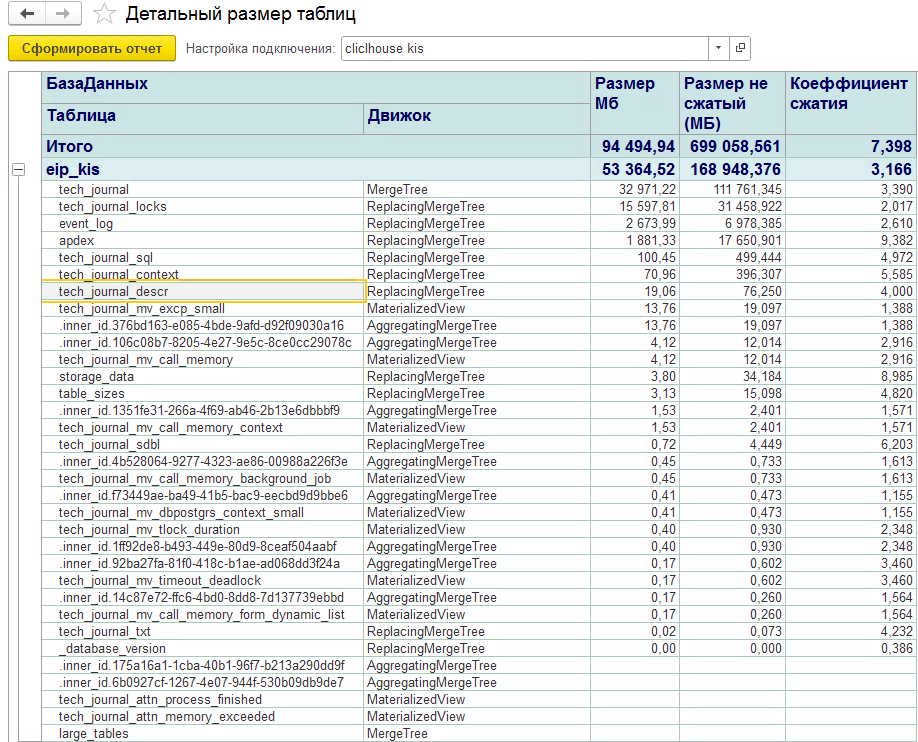
Почему мы выбрали ClickHouse в качестве базы, в качестве СУБД для накопления логов? ClickHouse обрабатывает внушительные объемы логов. За счет колоночного хранения снижает требования к дисковому пространству. На картинке пример: это одна из баз, в ней хранится 4 технологических журнала достаточно нагруженных проектов за неделю. Занимает это 53 гигабайта, что довольно немного. Там легко настроить жизненный цикл данных (TTL). Так нам не нужно вручную подчищать логи: выставляем TTL, и логи живут столько, сколько нужно.
Информационная база мониторинга

Сначала мы хотели делать красивые дашборды в Grafana. Но мы все-таки 1С-ники, поэтому сделали информационную базу, которая представляет из себя набор отчетов. По сути она ничего в себе не хранит, кроме настроек подключения. В ней заложены отчеты для анализа наших проблем производительности.
Как мы анализируем данные мониторинга
Посмотрим на самый часто используемый анализ запросов. В методике ничего нового нет: берем контексты, суммируем время и получаем самые плохие запросы.
Медленные запросы до сих пор остаются самой актуальной проблемой в наших системах на 1С. Неоптимальные запросы – самая частая проблема производительности. Когда вы анализируете тяжелые запросы, важно анализировать не только конкретную информационную базу, а все информационные базы, которые находятся в одной СУБД. У нас были ситуации, когда оказалось, что проблемы, о которых никто не догадывался, были в служебных базах.
Важно смотреть не только на время запроса, но и на показатель rowsaffected – сколько строк он вернул, особенно при помещении во временную таблицу. Эти данные потом нужно обрабатывать: если запрос выполнился быстро, но вернул много строк, это приведет к замедлению алгоритма.
В отчетах есть общая статистика, расшифровка и отборы. Мы их видим по пользователю, видим конкретный SQL. Так как мы грузим структуру, то мы можем расшифровать текст запроса SQL в нечто, похожее на запрос в 1С.
Нужно учитывать блокировки. Проблема блокировок на сервере 1С, по крайней мере в самописных конфигурациях, как у нас, до сих пор актуальна. Мы выводим группировки по жертвам, есть расшифровка до виновника. Сделали это в виде списка и условного оформления, чтобы понимать, кто жертва, кто виновник. Кто-то делает это диаграммой Ганта, мы сделали списком – для анализа хватает.

По железу: если у вас нет Zabbix, это не страшно. ТЖ собирает события CLSTR с Event=‘Performance update’. Если его настроить, вы получите данные о железе: CPU, очередь, время атомарных операций, которые 1С регулярно собирает. Это можно увидеть в ТЖ без Zabbix.

Call’ы тоже нужно анализировать. Детальная статистика по call дает понимание, какие операции стоит прорабатывать в первую очередь. Начинать важно с экстремально больших цифр. Например, одна из длительных операций имеет 24 гигабайта на пике – это очень много. В первую очередь стоит взять ее в работу.
Как извлечь из этого больше информации? Если мы берем call, нам известна его длительность. По ID соединения и пользователю можно построить список того, что было, и посмотреть хронологию. Важно смотреть не только на длительность и количество событий, которые были зафиксированы, но и на разрывы. На втором изображении событие DBPOSTGRS имеет время 1,7 секунды, а до следующего события TLOCK – финального события блокировки на запись – прошло 6 минут. Разрыв возник из-за того, что запрос вернул 2,5 миллиона строк: проблема была в запросе, хотя время выполнения было небольшим.

Так как мы храним данные в ClickHouse, а это СУБД, то мы можем встраивать произвольные запросы. Можно использовать оконные функции, включая OVER (PARTITION BY...), и строить интересные алгоритмы, которые стандартными скриптами реализовать сложно. Для примера запрос на рисунке выше: ищем запросы, которые положили больше всего данных во временные таблицы. Пользователь положил 46 миллионов строк с контекстом «КонсольЗапросов». Такие сложные выборки можно строить за счет того, что данные у вас хранятся в СУБД.
Apdex мы тоже собираем и смотрим в динамике. Высчитываем вклад конкретной операции в общий Apdex (Delta APDEX). Получаем эти цифры, выстраиваем приоритет, над чем работать. Важно смотреть и на сырые данные – на сами замеры: там тоже бывает полезная информация.
Приведу пример. Мы увидели, что все операции становились медленными в начале часа. Думали, что это регламенты, начали отключать – оказалось, нет. Это были особенности платформы, связанные с удалением старых файлов технологического журнала. Мы сделали простые скрипты, чтобы все чистилось нашими скриптами, а не 1С, и замирание пропало. Это актуально для платформы 8.3.24; на более новых платформах это уже поправлено.
Особенности расчета Apdex у 1С тоже нужно учесть. Ошибки трактуются так: если в замере зафиксирована ошибка, но она вложилась во время, Apdex будет 1. Мы ловили моменты, когда Apdex был нормальным, но при этом 100% операций были с ошибкой. Пользователя это не устраивает, поэтому обращайте на это внимание, если используете типовой Apdex.

Ошибки журнала регистрации тоже нужно мониторить: они имеют свойство прирастать, особенно с релизами. Сейчас это актуально для наших проектов. Благодаря ClickHouse эти отчеты формируются быстро. Данные компактно хранятся за счет колоночного хранения и быстро отрабатывают.
За динамикой размеров таблиц также нужно следить. Некоторые таблицы имеют свойство распухать, особенно когда разработчики пишут логи. Это нужно мониторить в динамике и, по возможности, пресекать рост и чистить. Можно смотреть не только на объем, но и на количество записей: оно тоже может многое сказать о том, как быстро та или иная таблица прирастает.
Примеры оптимизаций
Думаю, никому не интересно смотреть на типовые вещи вроде добавления индексов в поле отбора или избавления от запросов в цикле. Посмотрим оптимизацию, связанную с производительным RLS.
Есть группа доступа и набор групп доступа. Алгоритму важно понять, есть ли такой набор групп доступа у нас в базе с данным набором групп. Фирма 1С использовала умножение на 2, степень двойки. По сути, это битовая маска. Если взять эти числа в степени двойки и сложить, получится большое число, которое характеризует список. Так можно быстро сравнить наборы групп доступа и понять, одинаковые они или нет, нужно их создавать или не нужно.
Однако при достижении примерно 40–42 тысяч групп доступа алгоритм выдает ошибку row is too big: превышается объем строки – больше 8 килобайт.
Что еще может охарактеризовать список? Подходит хэш: если взять набор групп доступа и вычислить хэш, то можно сравнить все между собой. Так мы избавляемся от ошибки СУБД, потому что у нас остается одна колонка в запросе, а не много. Даже на проектах, где превышения количества групп доступа не было, скорость оказалась в десятки раз лучше. Эту ошибку мы отправили в 1С, и в релизе 3.11.255 она была исправлена.
Другой пример оптимизации – расчет свободного места в томах. На картинке фрагмент кода БСП. У нас есть присоединенные файлы, и считается их размер, строится динамический запрос. Чтобы оценить свободное место, 1С сначала считает размер. Когда присоединенных файлов становится очень много – сотни тысяч (а у нас есть проекты, где их действительно много) – получаются тяжелые запросы. Кроме того, результат может не соответствовать действительности.
На Linux есть простое решение: скрипт с командой df с нужными флагами, сохранение во временный файл и чтение решают задачу без нагрузки на СУБД.
Итоги работы нашей технической группы
-
Внедренная система мониторинга позволяет быстро реагировать на проблемы производительности в наших системах и не требовательна к ресурсам.
-
APDEX всех проектов улучшился до 0.95+ (некоторые проекты достигли 0.99).
-
Снизились затраты на железо (18%).
-
Снизилось количество простоев до минимума.
Даже в тяжелых проектах, каких как бэкенды на 1С, ошибки чаще всего в нашем коде. В большинстве случаев следование стандартным рекомендациям вендора значительно улучшает производительность. Избавление от обращений к ссылкам через точку, избегание запросов в цикле, индексы на поля отбора и связи таблиц – все это помогает.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт