Что такое Observability
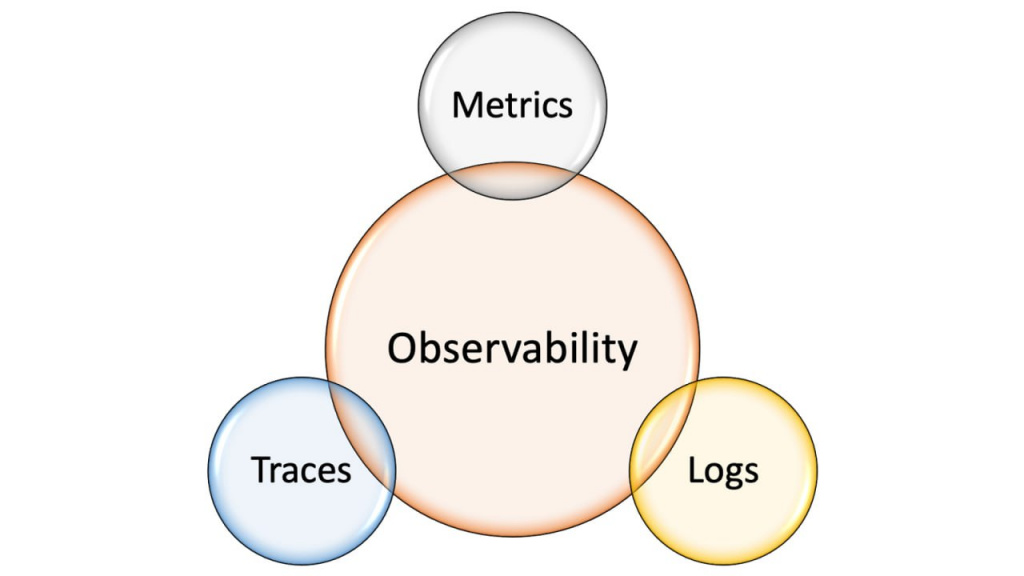
Есть такое понятие, как Observability – по-русски это обозримость или наблюдаемость. Это степень нашего понимания того, как функционирует информационная система и в каком она состоянии. Если система начинает работать неправильно, Observability показывает, насколько быстро мы можем определить, где именно произошла ошибка, и устранить ее. Она строится на трех столпах: метрики, трассировка и логирование.
Я считаю, что обеспечение Observability информационных систем – одна из задач DevOps. В нашей компании этому уделяют большое внимание.
Архитектура и назначение Prometheus
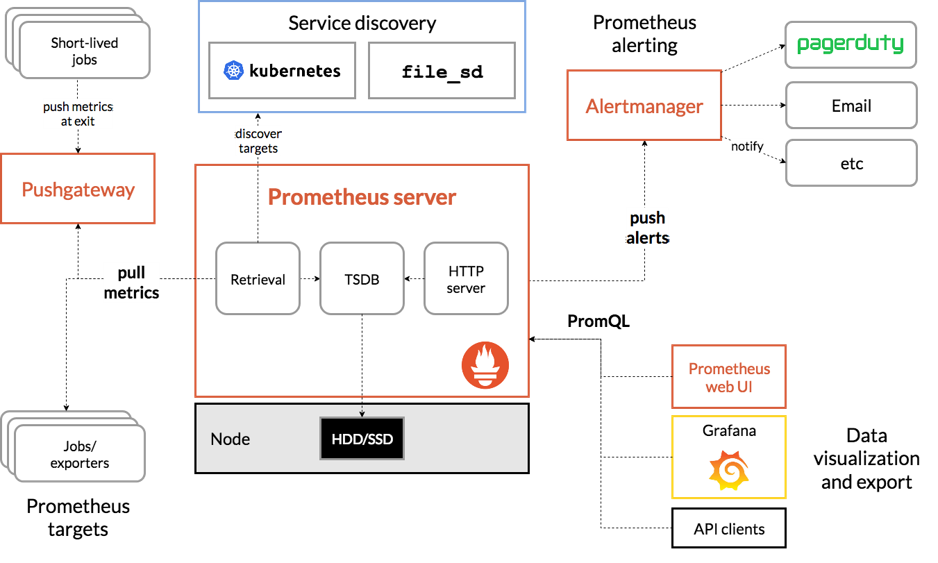
У нас есть схема, мы по ней пройдемся и разберем все, что на ней изображено.
Начнем с главного – с Prometheus. Prometheus – это база данных временных рядов, Time Series Database. Это узкоспециализированная база данных. Она не умеет выполнять многие операции, которые доступны реляционным базам: в ней нет апдейтов и вставок внутрь таблицы. Если максимально все упростить, все устроено просто: сверху добавляем нужные данные, снизу удаляем ненужные.
В этой базе хранятся пары ключ-значение, привязанные ко времени. Благодаря своей специализации, Prometheus позволяет хранить большое количество меток времени и, что важнее, очень быстро выполнять вычисления над ними.
Все системы мониторинга делятся на две основные группы. Они работают либо по модели PULL, либо по модели PUSH. Если система мониторинга работает по модели PULL, это означает, что мы должны в заданном формате опубликовать метрики, а система мониторинга приходит и забирает их. Если используется модель PUSH, из информационной системы отправляют метрики в систему мониторинга.
Prometheus работает по модели PULL. Это означает, что должны быть службы-экспортеры, которые публикуют метрики в заданном формате, а Prometheus приходит и забирает их.
Модель данных в Prometheus

Немного о модели данных. Как данные хранятся в Prometheus? По сути, это набор ключ-значение: ключ – метрика, значение – ее текущее состояние. Этот набор ключ-значение привязывается к метке времени и сохраняется в базе данных.
Каждая метрика может быть помечена определенным количеством лейблов (меток). Например, у нас есть десять серверов, и каждому можно присвоить имя, чтобы при необходимости быстро отфильтровать нужный сервер и увидеть, что на нем происходит. Сервера можно разделить по окружениям, например «прод» и «тест», и так же быстро фильтроваться по ним.
Формат OpenMetrics
Для того, чтобы собирать данные, они должны быть представлены в специальном формате – OpenMetrics. Вот так этот формат выглядит:


Здесь есть два служебных тега. Они необязательны, но их принято указывать. Первый тег – help: он описывает метрику, ее назначение и смысл. Второй тег – type: это тип метрики. Всего существует четыре типа, они имеют разные свойства, и с каждым нужно работать по-разному. Мы разберем их далее.
Дальше указывается сама метрика и ее значение. В угловых скобках можно указать необходимый набор меток.
Процесс сбора данных (Scraping)
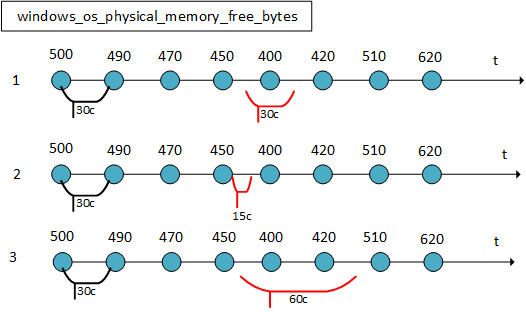
Немного о том, как происходит сбор данных, или Scrape. Scrape – это процесс, в котором Prometheus забирает данные. Здесь все устроено интересно, и есть две основные настройки:
-
Первая – с какой частотой экспортер обновляет данные на своей странице.
-
Вторая – с какой частотой Prometheus приходит и забирает эти данные.
Эти настройки независимы и конфигурируются отдельно.
На первом графике экспортер обновляет данные каждые 30 секунд, и Prometheus забирает их каждые 30 секунд. При этом отсчет интервалов у экспортера свой, у Prometheus свой. Можно настроить так: экспортер публикует данные каждые 30 секунд, а Prometheus забирает их каждые 15 секунд – тогда значения будут задваиваться. Можно сделать наоборот: экспортер публикует каждые 30 секунд, а Prometheus читает каждые 60 секунд – тогда часть данных будет потеряна.
Подтверждения чтения здесь нет. Экспортер не знает, прочитал Prometheus данные или нет. Его задача – периодически обновлять значения. Метку времени ставит Prometheus в момент чтения, а не в момент публикации экспортером.
По этой схеме очевидно, что Prometheus – не про точность. Если нужна точность, нужно смотреть журналирование и определять, что произошло раньше: нагрузка на СУБД или нагрузка на СП. Prometheus – про оперативность, про то, чтобы как можно быстрее увидеть, что произошло, и успеть отреагировать.
Счетчики
Gauge
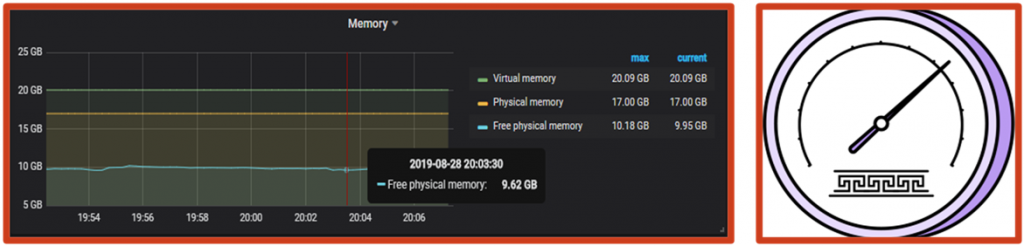
Теперь о типах счетчиков. Начнем с Gauge. Это счетчик типа «стрелка». Значение может увеличиваться, уменьшаться и снова увеличиваться.
Здесь показано, как такие счетчики выглядят в Grafana. Обычно при работе с Gauge нас интересует текущее значение: например, сколько сейчас потребляется ЦП и памяти. Также нас интересует тренд – растет ли потребление, уменьшается или остается на постоянном уровне. Это самый простой тип счетчика.
Counter
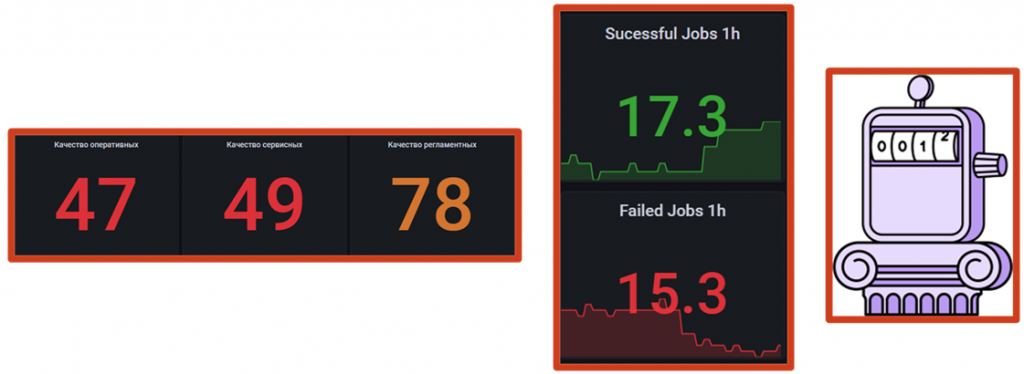
Следующий тип счетчика – Counter. В его свойства заложено непрерывное увеличение. Он не может уменьшаться, он только растет. Например, количество ошибок: если ошибка произошла, мы фиксируем +1. Даже если ее исправили, она уже была.
Текущее значение такого счетчика мало что дает. Если сейчас значение равно 40, это много или мало? Если считать с начала года – нормально, а если за последние 15 минут – уже много. Поэтому при работе с Counter нас интересует изменение за период, то есть прирост. Чтобы вычислить его, используется язык запросов Prometheus – PromQL.

Отлаживать выражения удобнее всего на странице Prometheus в соответствующем разделе. Мы вводим метрику «количество ошибок» и смотрим результат. Метрика обычно представлена в разрезе разных лейблов, поэтому сначала нужно отфильтроваться.
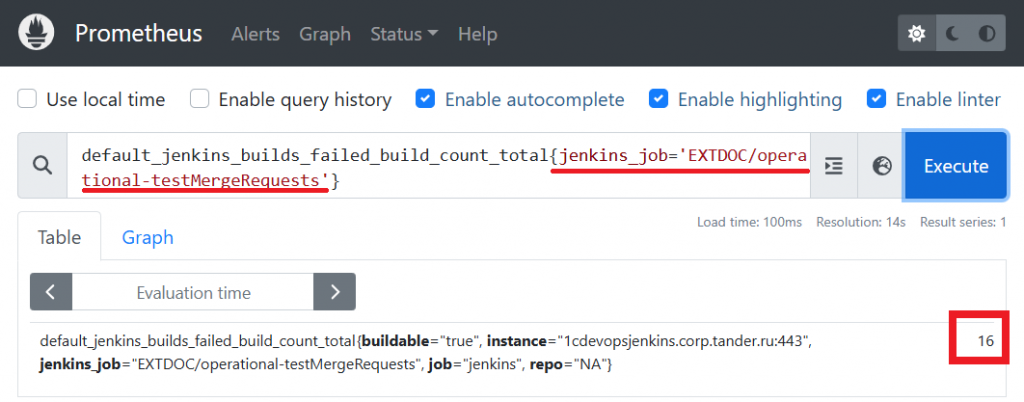
Фильтрация указывается в фигурных скобках, поддерживаются регулярные выражения. После фильтрации мы получаем одно значение: на текущий момент 16 ошибок. Но нас интересуют последние четыре часа, поэтому метрику нужно развернуть.
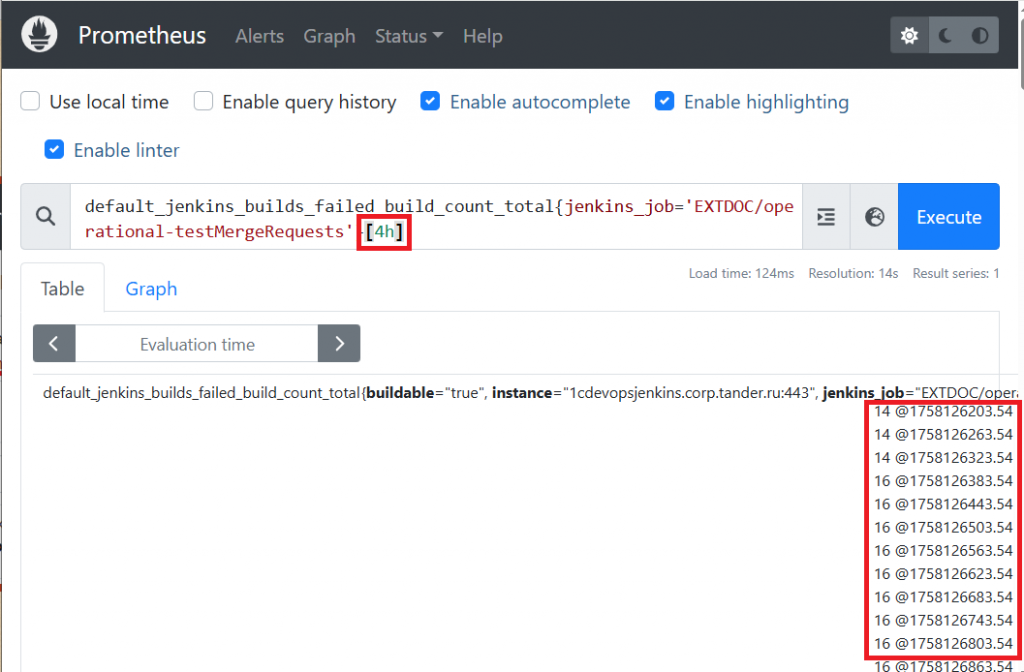
Мы указываем выражение в квадратных скобках и просим показать данные за этот период. В результате получаем массив значений из меток времени. По этому массиву понятно, с какого значения мы начинали и к какому пришли.
Для получения одного числа нужна агрегирующая функция. Как в SQL есть функции суммы, максимума и среднего, так и в PromQL есть свои агрегатные функции.

Мы применяем агрегирующую функцию rate – это производная, показывающая скорость роста метрики в секунду. Приводим результат к часам и получаем 2.

Можно использовать и функцию increase. Она возвращает абсолютное приращение метрики за заданный период.

Также можно применить функцию offset: она берет текущее значение и вычитает значение, которое было четыре часа назад. Мы снова получаем 2.
Кажется, что все варианты дают одинаковый результат. Какой правильный? На самом деле два варианта правильные, один – нет.
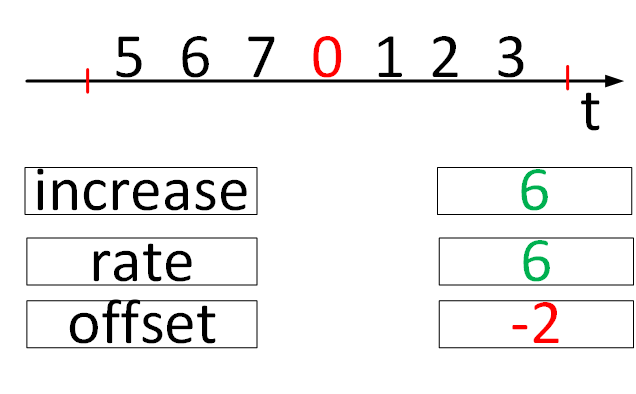
Чтобы понять, где ошибка, возьмем пример со сбросом счетчика. За анализируемый период произошел сбой или перезапуск службы, и счетчик обнулился. Increase и rate распознают, что работают с Counter, который должен непрерывно расти, и вычисляют корректно – они покажут 6 событий. Offset в этом случае вернет –2.
Поэтому при работе с Counter нужно быть осторожным. В функциях агрегирования, используемых для оповещений, важно выбирать те, в описании которых прямо указано, что они поддерживают сброс данных. Разница между increase и rate минимальна: rate показывает скорость в секундах, increase – абсолютное приращение.
Histogram и Summary
Следующие два типа счетчиков используются реже, но они представляют большой интерес. Возьмем ключевую операцию с целевым временем выполнения 5 секунд. Был сделан замер: тысяча измерений. В 820 случаях операция уложилась в 5 секунд – пользователи довольны. В 150 случаях она не уложилась в 5 секунд, но завершилась за 20 – пользователи просто удовлетворены. Мы посчитали Apdex: это оценка на уровне «четверка с плюсом».

Если взять эту выборку – тысячу замеров – и представить ее в виде метрик Histogram, получится вот такое распределение. Мы могли бы просто хранить замеры: операция и время ее выполнения. Но вместо этого на каждый срез времени хранится распределение по категориям.
Здесь есть принципиальная разница. Если операция выполнилась за 4 секунды, с точки зрения Apdex она попадает в одну категорию. С точки зрения Histogram она попадет сразу в две: «меньше 5 секунд» и «меньше 20 секунд».

При наличии такого распределения классический Apdex легко вычисляется по формуле и является частным случаем Histogram.

Последний тип – Summary. Он выглядит следующим образом и читается так:
-
50% всех выполнений ключевой операции уложились в 4,2 секунды или быстрее,
-
75% – в 4,8 секунды или быстрее,
-
95% – в 6,4 секунды или быстрее.
Или другими словами: 5% всех выполнений операции были медленнее 6,4 секунды.
Push-модель и Push-gateway
Я упоминал о том, что Prometheus работает по модели PULL. Но что делать, если нам нужно отправлять данные в Prometheus, то есть работать по модели PUSH? В этом случае используется служба Push-gateway. Push-gateway не является частью Prometheus и может не устанавливаться, если он не нужен.
Задача Push-gateway проста: он принимает запросы с метриками и публикует их на своей странице по определенному адресу. Prometheus взаимодействует с Push-gateway как с обычным экспортером. По сути, Push-gateway нужен для того, чтобы «обмануть» Prometheus и дать ему возможность получать данные в PUSH-модели.
Push-gateway часто используют в связке с 1С, когда создание полноценного экспортера слишком накладно или когда события возникают нерегулярно, и их нужно лишь изредка отправлять в систему мониторинга. В таких случаях Push-gateway отлично подходит.
Система оповещений (Alerting)
Если метрики хранятся, то они имеют свои значения, и иногда эти значения выходят за пределы допустимого. В таких ситуациях нам нужно получать оповещения. Для этого служит Alerting. У Prometheus есть собственный Alert-менеджер, который можно настроить и получать оповещения.

Если Prometheus работает в связке с Grafana, можно настроить Alerting и в Grafana. Кроме того, можно установить внешние системы оповещений и настроить их.
В зависимости от выбранного варианта, для Alerting доступны следующие возможности:
Мы можем настроить эскалацию. Например, память превысила 80%, и мы отправляем оповещение в канал, где находится первая группа сотрудников. Если они не решают проблему в течение 30 минут, автоматически отправляется оповещение в другой канал, где подключается вторая группа.
Доступна группировка. Если событий много, их можно объединить в одно письмо, чтобы не отправлять десятки отдельных уведомлений.
Доступно подавление. Например, у нас есть кластер с двадцатью веб-сервисами. Мы настроили мониторинг: сервис жив или недоступен. Если упал кластер, обычно приходит одно оповещение о его падении и двадцать оповещений о том, что какой-то веб-сервис недоступен. Мы можем настроить так, что при падении кластера отправляется только одно оповещение – кластер упал. Очевидно, раз кластер недоступен, значит все остальное тоже недоступно. Мы получаем одно оповещение и реагируем на него.
Доступны разные способы доставки: мессенджеры или обычная почта.
Визуализация данных через Grafana
Если данные хранятся в Prometheus, нам хотелось бы видеть их в виде удобных дашбордов. Обычно Prometheus используют с Grafana, но это не обязательное требование. Grafana через PromQL обращается к Prometheus, получает метрики и отображает их в виде дашбордов.
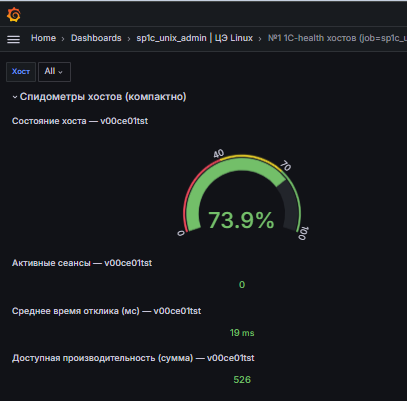
Grafana не ограничивается Prometheus: она может получать данные из Loki (журналирование), выполнять прямые запросы к СУБД: например к ClickHouse. В одном дашборде можно выводить данные из разных источников, что часто бывает удобно.
В дашбордах можно использовать переменные. Если у нас есть пятнадцать серверов, нам не нужно создавать пятнадцать одинаковых дашбордов. Мы создаем один и выбираем переменной, по какому серверу хотим видеть показатели.
Также доступна расшифровка: можно кликнуть на показатель, и откроется новый дашборд с детализацией.
Практическая часть: развертывание мониторинга
Мы подготовили репозиторий, в который положили минимальный набор, необходимый для самостоятельного развертывания мониторинга кластера 1С. Пройдемся по шагам, что нужно сделать, чтобы появился собственный мониторинг.

Сначала все нужно установить. Grafana, Prometheus и Push-gateway – родом из Linux, поэтому лучше всего устанавливать их на Linux. Если Linux есть, это идеальный вариант. Если хочется потренироваться, можно использовать WSL – подсистему Windows для Linux – и развернуть все там.
Используется технология Docker Compose – надстройка над Docker, позволяющая поднимать сразу несколько контейнеров. После запуска мы должны увидеть три поднятых контейнера и иметь возможность открыть страницу Grafana, страницу Prometheus и страницу Push-gateway.
Подключение Exporter
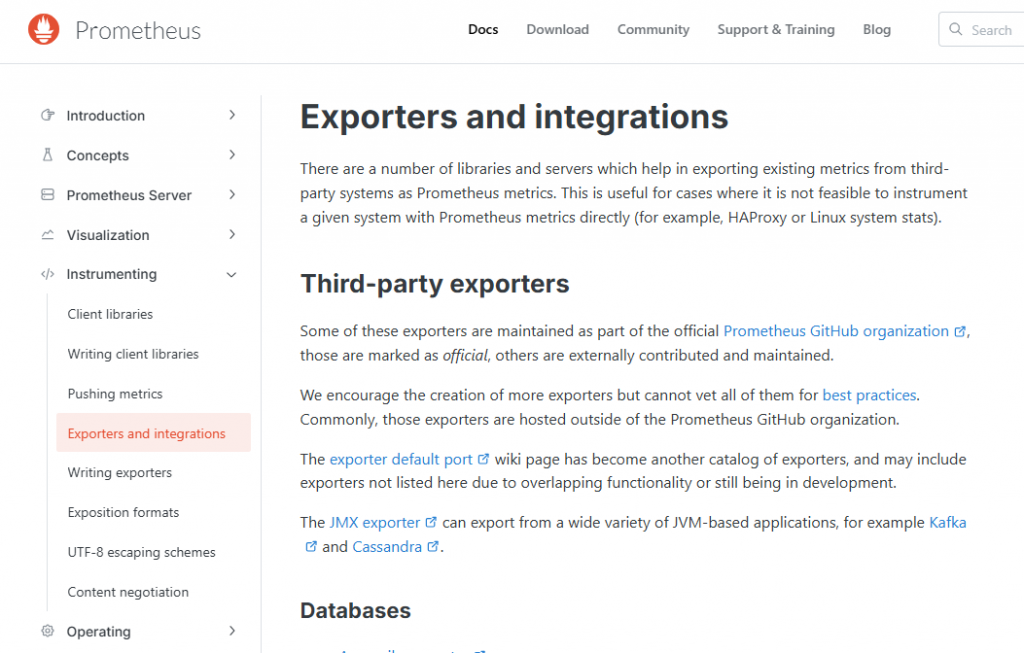
Мы все подняли. Теперь нужны данные. Чтобы получать данные, нужны экспортеры. Где их искать? Экспортеров существует огромное количество, и начинать поиск стоит с сайта Prometheus – там есть раздел с опубликованными экспортерами.
В первую очередь это Windows Exporter, который позволяет мониторить железо: загрузку процессора, память и так далее. Есть экспортеры для MSSQL и PostgreSQL, позволяющие мониторить СУБД. Если у вас CI на Jenkins, есть Jenkins Exporter. GitLab даже не требует экспортера – он сам может отдавать метрики в формате OpenMetrics.
Мы скачиваем нужные экспортеры, запускаем, настраиваем частоту обновления данных и адрес, по которому они будут опубликованы.

Затем нужно указать Prometheus, откуда брать данные. Для этого в конфигурационный файл Prometheus в формате YAML вносятся изменения. В разделе scrape_configs мы перечисляем экспортеры, задаем имя, интервал сбора и необходимые метки.
После этого данные появляются в Prometheus. Мы можем открыть консоль, выполнить выражения и получать результаты.
Использование готовых дашбордов

Но нам нужно, чтобы все выглядело красиво. Значит, нужны дашборды. Если мы работаем с Grafana, соответственно, нужны дашборды для Grafana. Их существует огромное количество. Первое место, где стоит искать – сайт Grafana. Там есть что-то вроде маркетплейса дашбордов. Мы можем зайти туда и скачать готовые дашборды для стандартных экспортеров. При необходимости их можно кастомизировать и настраивать под себя. Если дашборд подходит, мы работаем с ним; если нет – переделываем или скачиваем другой.
Это относится к стандартным экспортерам.
Мониторинг кластера 1С
Что касается 1С, если платформа выше версии 25 и используется КОРП-лицензия, доступен HTTP-сервис получения параметров производительности. Его можно настроить, и данные будут публиковаться в формате OpenMetrics.
Если эти условия не выполняются, существуют open-source-решения. Их несколько, и работают они одинаково: получают данные из кластера и публикуют их в формате OpenMetrics.

Разберем случай, когда все условия выполняются. У нас есть служба RAS, и для публикации данных в формате OpenMetrics ее нужно запускать с ключом --monitor-base=/metrics. Далее нужно указать путь, по которому будут публиковаться метрики. В конфигурационном файле для сбора метрик этот путь должен быть указан точно так же, как в настройке RAS.
Что нам доступно, если все настроено? Мы можем получать:
-
метрики менеджера кластера (managers),
-
метрики рабочих серверов (servers),
-
метрики рабочих процессов (processes),
-
метрики сеансов (sessions).

Если нужно получать все – оставляем полный набор. Если требуется только часть, в секции params можно указать, какие данные нужны, а какие нет.
Собственный экспортер

В итоге, когда мы все сделали, мы можем получать дашборды. В репозиторий мы положили несколько примеров дашбордов. Их можно взять за основу. Это не полноценное решение, скорее MVP-версия.
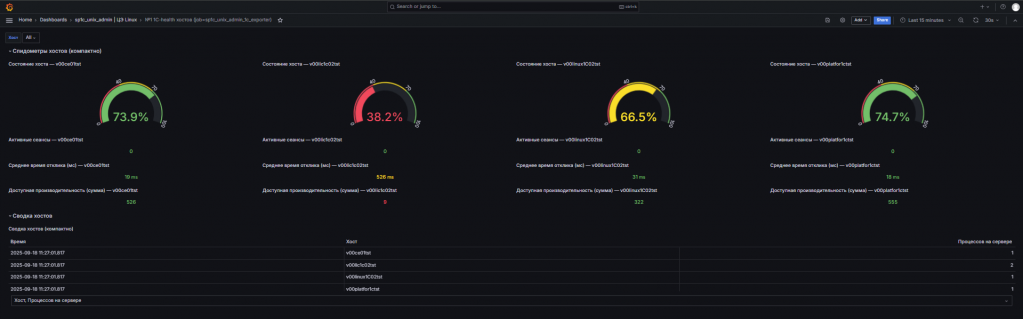
Эти дашборды можно просматривать, настраивать под свои задачи и при необходимости добавлять Alerting.
На этом можно остановиться: у нас уже есть мониторинг железа и мониторинг кластера. Но можно пойти дальше и сделать собственный экспортер.
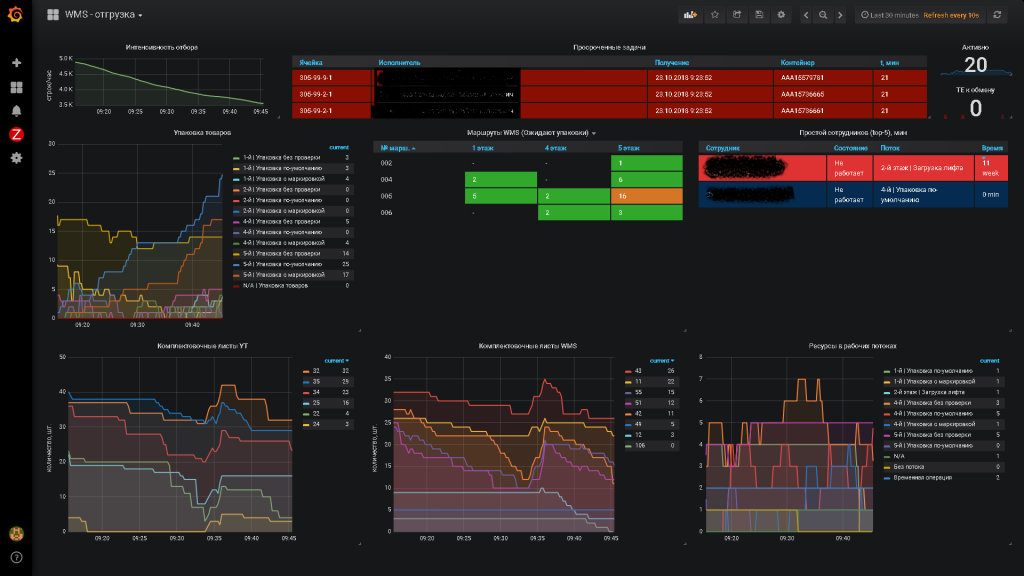
Мы, например. вдохновившись решением, описанным в статье //infostart.ru/1c/articles/811821/, реализовали в нашей компании собственную подсистему, из которой можно отправлять данные.
Данные могут отправляться через Push-gateway или в виде полноценного экспортера. Это могут быть бизнес-показатели – очередь заявок, распределение оплат – или технические показатели: количество пакетов в очереди, количество ошибочно обработанных пакетов. Все это можно гибко настраивать.
Итоги и рекомендации
Я постарался коротко рассказать о Prometheus – системе, которая специально создана для получения данных и их хранения. Нужно отметить, что все, что я показывал, можно реализовать на 1С. В принципе, все, что есть в этом мире, можно реализовать на 1С – и многое уже реализовано.
Есть ЦКК, которые собирают счетчики производительности и строят дашборды. Есть система оценки производительности в БСП, которая практически полностью повторяет функциональность Prometheus: она хранит значение показателя и время его фиксации. Все это можно сделать, и все это будет работать. Но можно пойти другим путем и интегрироваться с уже готовыми решениями.
Путь внедрения мониторинга может выглядеть так. Первый шаг – стандартный мониторинг со стандартными экспортерами. Это очень просто и действительно можно сделать за 10–15 минут. Возможно, не с первого раза, а с третьего или четвертого, но именно за эти 10–15 минут можно получить мониторинг железа, СУБД и готовые дашборды.
Дальше можно подключить мониторинг кластера 1С и получить метрики по кластеру. Затем можно не останавливаться и делать свои дашборды, которые будут иметь значение только для вашей компании: собственные бизнес-показатели, уникальные кастомные настройки. Эти дашборды помогут анализировать работу систем и принимать решения.
Такой путь я вижу, и желаю, чтобы вы его прошли, не останавливались и полностью обеспечивали Observability – чтобы все было наблюдаемым, предсказуемым и работало без падений.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт