



")


{kind=link}
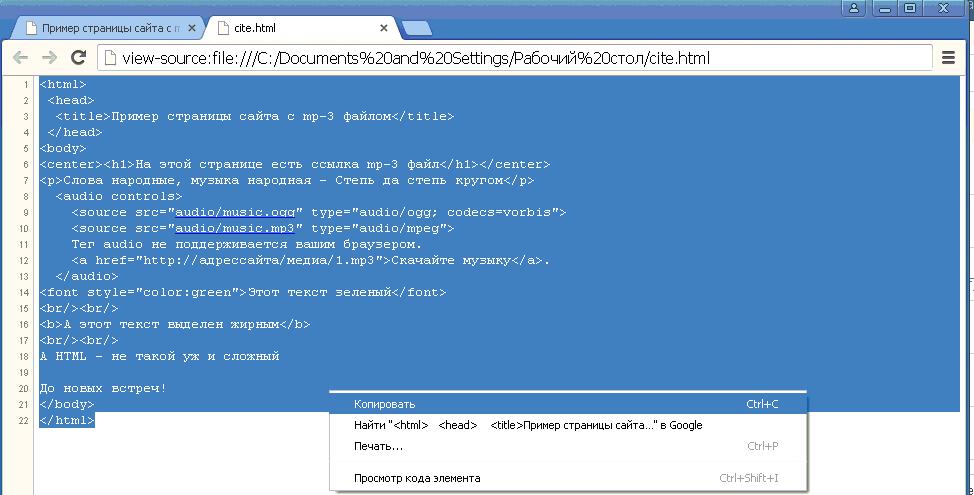
Если открыть исходный код некоторых сайтов, то можно обнаружить, что они содержат ссылки на mp3-файлы, следующего вида: http://адрессайта/медиа/1.mp3.
Для парсинга таких ссылок используется регулярное выражение:
RegExp.Pattern = "([^\s\t\n\r\\:\|\*<>]+)(\.mp3)".
Обработка выбирает все ссылки из текстового файла (HTML-кода) и загружает их в выбранную папку.
Инструкция по использованию:
1. Заходите на нужный Вам сайт и открываете его исходный код. Для этого обычно хватает нажать правую клавишу мыши на странице сайта и выбрать из появившегося меню пункт "Просмотр кода страницы" или т.п.
Если не получается, прочтите об этом здесь.
2. Проверьте, есть ли в коде страницы ссылки нужного формата.
Нажмите Ctrl+F, в появившемся окне введите ".mp3", браузер покажет количество ссылок с таким расширением.
Ссылки формата /медиа/1.mp3 обработка загрузить не сможет.
3. Выделите весь код страницы (Ctrl+A) и скопируйте его в буфер (Ctrl+С).
4. Создайте новый текстовый файл и вставьте туда код страницы (Ctrl+V).
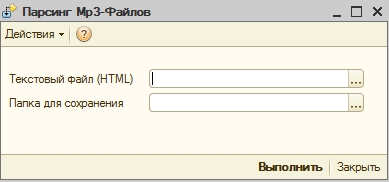
5. Выберете полученный файл в обработке, а также укажите папку, куда сохранять файлы.
6. Нажмите "Выполнить".
Вступайте в нашу телеграмм-группу Инфостарт