Одна из самых мощных многоязычных моделей распознавания речи XLS-R теперь доступна всем разработчикам. Facebook опубликовала исходный код решения на GitHub и Hugging Face.
Зачем нужна модель
Технологии перевода с одного языка на другой в режиме реального времени уже появились в Google Translate, Skype и других приложениях. Но пока они доступны для небольшого количества языков, ведь модели искусственного интеллекта, которые лежат в основе таких технологий, обычно обучают на ограниченных наборах данных.
Появление XLS-R в открытом доступе может изменить ситуацию, считают в Facebook. Модель включает более 2 млрд параметров. Для адекватного представления многих языков количество параметров имеет решающее значение – это улучшает производительность и точность распознавания даже сильнее, чем тщательное предварительное обучение на одном языке.
Как устроена XLS-R
Основа модели с самопроверкой – технология wav2vec 2.0. Она умеет анализировать аудиозаписи и определять структуру разговора.
XLS-R получила для обучения 128 языков – это вдвое больше, чем у прошлой модели XLSR-53, представленной год назад. Новое решение обучали на открытых данных: 436 тыс. часов записей речи – от аудиокниг до парламентских заседаний. Это примерно в десять раз превосходит базу предшественницы.
XLS-R успешно протестировали в системах BABEL, CommonVoice и VoxPopuli для распознавания речи, CoVoST-2 по переводу с иностранного языка на английский и VoxLingua107 для определения языка. Это позволило измерить качественные характеристики модели на разных этапах обработки речи и в различных ситуациях.
Разработчики показали результаты тестов для разных языков в системе BABEL. Новая модель ощутимо уменьшила количество ошибок (серым показаны итоги тестирования для прошлогодней XLSR-53, зеленым – для новой XLS-R ):
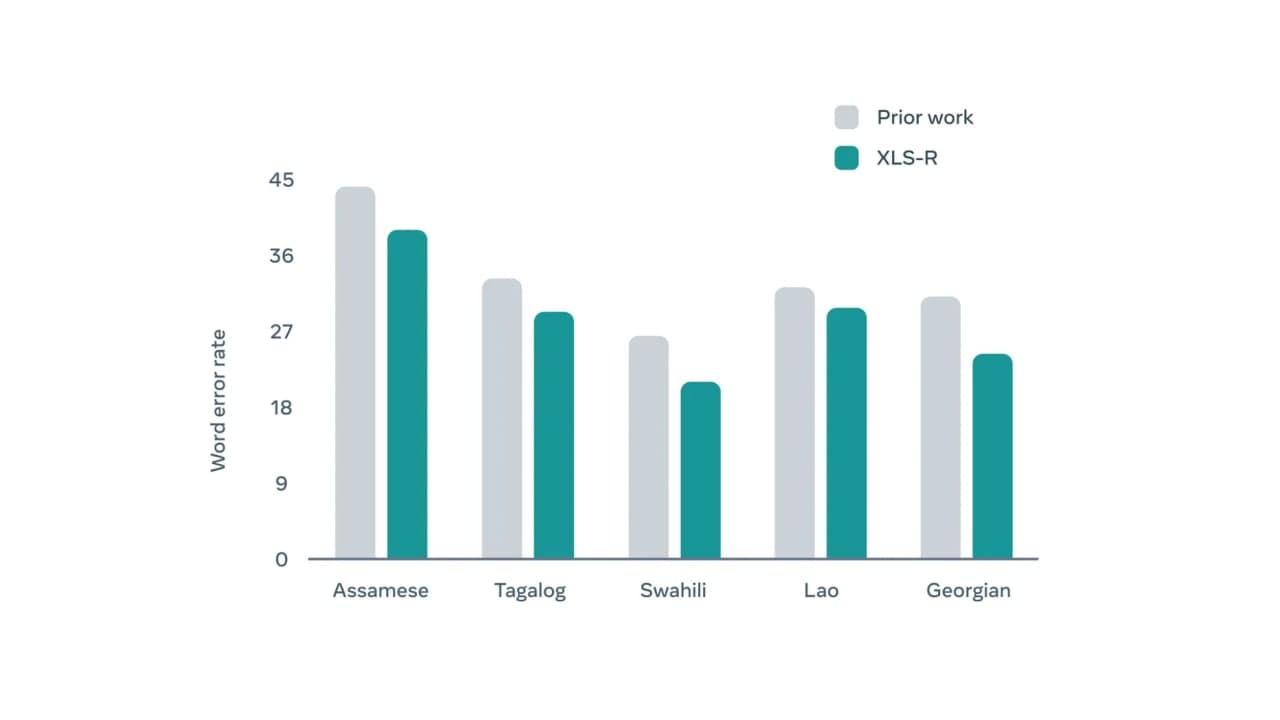
Масштабирование межъязыкового предварительного обучения модели XLS-R в будущем позволит сделать точнее переводы на редкие языки, например, лаосский, суахили или тагальский. Для них доступно не так много аудиозаписей, а структура речи очень сильно отличается от английского, с которым работает большинство моделей.
В результате подобные решения смогут действительно понимать человеческую речь, переводить не слово в слово, а смысл в смысл – как профессиональные переводчики. В Facebook заявили, что смогут работать с 7 тыс. языков – и это позволит общаться людям из любых уголков планеты.