Исследователи из Центра искусственного интеллекта Samsung в Москве описали алгоритм создания «живых портретов» всего лишь из одной фотографии.
Проблему синтеза фотореалистичной анимации изучали исследователи Егор Захаров, Александра Шишея, Егор Бурков и Дмитрий Лемпицкий. Подобные алгоритмы применяются для телеприсутствия, включая видеоконференции, многопользовательские игры и индустрию спецэффектов.
Ожившая классика
Авторы называют свой метод «обучением в несколько приемов», когда алгоритм для создания убедительного анимационного портрета использует малое количество изначальных данных.

Исследователи, используя единственный исходный снимок, смогли оживить картины и знаменитые портреты. Федор Достоевский, который умер задолго до того, как кинокамеры стали доступными, двигается и говорит. После работы нейросети «оживает» и Таинственная незнакомка.

Почему это сложно
Синтезировать реалистичные анимированные портреты сложно по двум причинам:
- человеческие головы имеют высокую фотометрическую, геометрическую и кинематическую сложность, поэтому моделировать лица сложно;
- острота зрительной системы человека, которая заметит даже незначительные ошибки в мимике «смоделированной головы».
Поэтому обычно динамическому генератору изображений требуется большое количество фотографий с целевым объектом и времени на обработку данных. Разработка ученых из Центра искусственного интеллекта Samsung упрощает задачу создания «говорящих голов».
Суть работы
«Фотореалистичные модели говорящих голов» созданы с использованием сверточных нейронных сетей: алгоритм обучили на большом наборе видео говорящих голов с широким разнообразием видов. Для этого использовали общедоступные базы данных VoxCeleb, содержащие 7 тыс. изображений знаменитостей из видеороликов YouTube. Так программа учится распознавать черты лица: глаза, формы рта, длину и форму переносицы.
Как это работает
В процессе обучения система создает три нейронные сети: встроенная сеть делит кадры на векторы, сеть генераторов отображает лицевые ориентиры в синтезированном видео, а сеть дискриминатора оценивает реалистичность сгенерированных изображений.
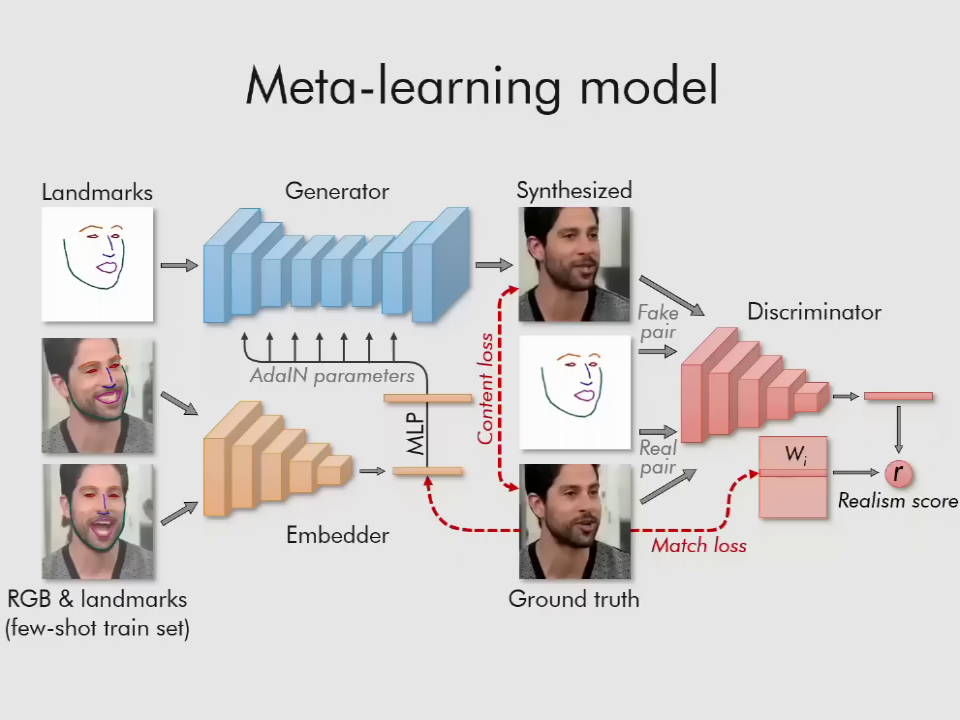
Схема обучения алгоритма
На каждое лицо в кадре наложена маска, которая обозначает его границы и базовую мимику. Информация о том, как маска соотносится с исходным кадром, хранится в виде вектора, данные из которого используются для наложения маски на изображение человека, после чего готовое изображение сравнивается с первоисточником.
«Система определяет параметры как генератора, так и дискриминатора для каждого человека индивидуально, так что для обучения нейросети хватит нескольких изображений, несмотря на необходимость настройки десятков миллионов параметров. Мы показываем, что такой подход позволяет создавать реалистичные и персонализированные модели говорящих голов новых людей и даже портретные картины», – сообщают авторы в резюме статьи.








