Американская компания OpenAI, которая занимается созданием технологий машинного обучения, представила новый язык программирования Triton. Он станет альтернативой CUDA от Nvidia и поможет быстро запускать модели с использованием мощностей видеокарты.
Машинному обучению – мощную графику
Производительные современные видеокарты давно скупают майнеры. Быстрая память и мощные процессоры, встроенные в них, позволяют ускорить вычисление хешей и эффективнее добывать криптовалюту.
Исследователи тоже «положили глаз» на графические адаптеры. Под них пишут программы для просчета сложных математических моделей, тренировки систем машинного обучения и других нагруженных вычислений.
Производитель видеокарт Nvidia разработал собственный инструмент программирования CUDA для работы с графическими адаптерами. Но простым его не назовешь – по крайней мере, специалисты, которые раньше писали на Python, испытывают сложности с переходом на CUDA.
Triton призван решить эту проблему. Он столь же прост, как Python, но при этом позволяет создавать сложные модели для запуска на видеокартах.
Назначение Triton
Triton – проект с открытым исходным кодом. Его репозиторий уже есть на GitHub.
Разработчик Triton Филипп Тилле – на тот момент выпускник Гарварда, а сейчас – сотрудник OpenAI, – впервые представил его в 2019 году. Он хотел создать язык, который был выразительнее стандартных библиотек для искусственного интеллекта, например, cuDNN от Nvidia, и мог бы обрабатывать широкий спектр операций с матрицами, задействованными в нейронных сетях. В то же время Тилле хотел добиться переносимости и производительности, сопоставимой с cuDNN и другими популярными решениями.
Triton позволит исследователям, у которых нет опыта работы с CUDA, писать высокоэффективный код для выполнения на графическом процессоре. Максимальной производительности можно будет добиться, приложив небольшие усилия. Например, чтобы создать ядра матричного умножения FP16, достаточно всего 25 строк кода.
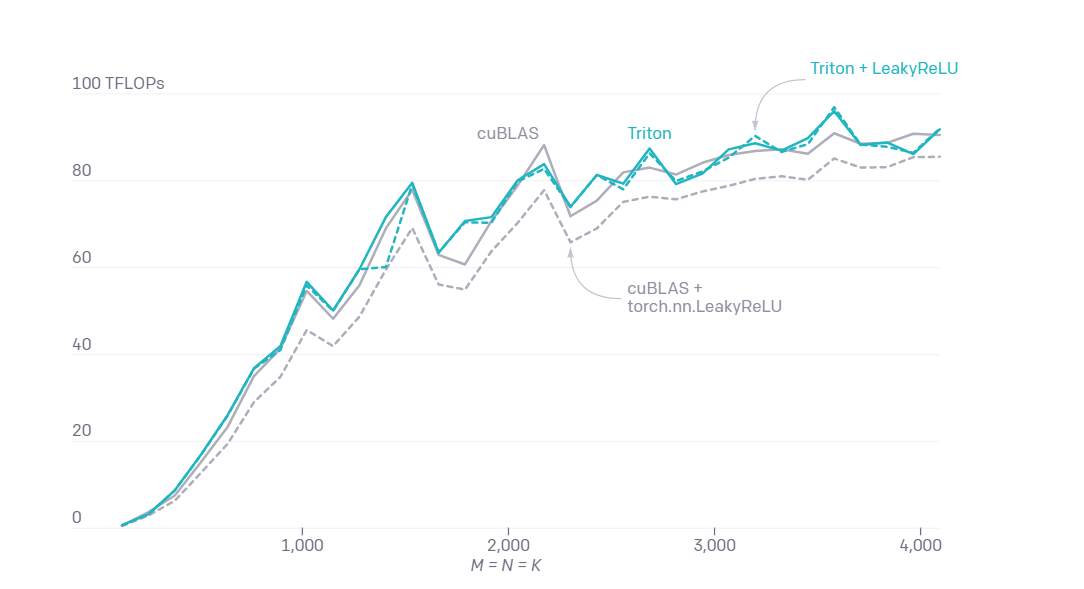
Производительность Triton по сравнению с популярными решениями в задачах умножения матриц
В OpenAI подчеркнули, что с Triton удалось создать ядра, которые в два раза эффективнее, чем эквивалентные реализации с библиотекой Torch для Python. Такой код часто используют в задачах глубокого обучения, и он потенциально может повысить эффективность работы нейросетей.
Особенности языка
Графические процессоры даже с CUDA и другими инструментами очень сложно оптимизировать для обеспечения локальности и параллелизма вычислений. Тилле решил использовать концепцию тайлов (плиток) – что-то подобное есть и в CUDA, но реализовано иначе.
В Triton матрицы, которые используются в программе машинного обучения, разбиваются на тайлы – фрагменты, которые можно эффективно распределять по общей памяти SRAM и быстрой регистровой памяти и обрабатывать параллельно с помощью нескольких потоков инструкций. Но если в CUDA для этого приходится создавать явные операторы синхронизации между потоками инструкций программы, в Triton все происходит автоматически.
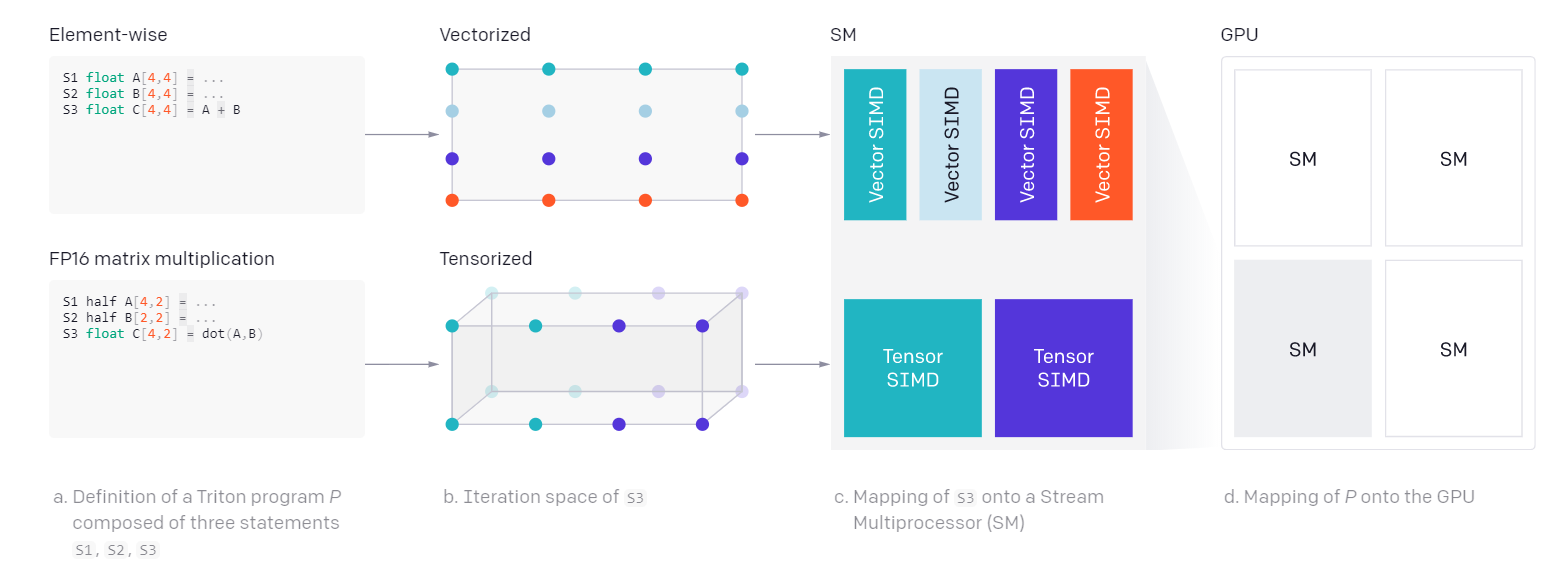
Автоматическое распараллеливание вычислений в Triton
Семантика Triton определяет тайлы как встроенные типы. Компилятор Triton знает, как эффективно распределить эти фрагменты между ядрами графического процессора и сопровождающими их регистрами. Выполняет он и другие оптимизации, так что исследователям не нужно сильно вникать в детали реализации.
Пока на Triton можно работать только с видеокартами Nvidia. Но Тилле и его коллеги ищут единомышленников, которые смогли бы заняться портированием проекта и на видеокарты AMD.