Исследователи из лаборатории искусственного интеллекта Массачусетского технологического института (MIT) и подразделения Google AI научили нейросеть воссоздавать изображение лица по голосовой записи.
Нейросеть Speech2Face использует миллионы естественных видео в интернете. Она изучает корреляции голоса и лица и создает изображения, отражающие физические характеристики говорящих:
- возраст;
- пол;
- этническая принадлежность.
Нейросеть обучалась в режиме самоконтроля, используя естественное совпадение лиц и речи в видео. Индивидуальные особенности лица ей отражать не требовалось.
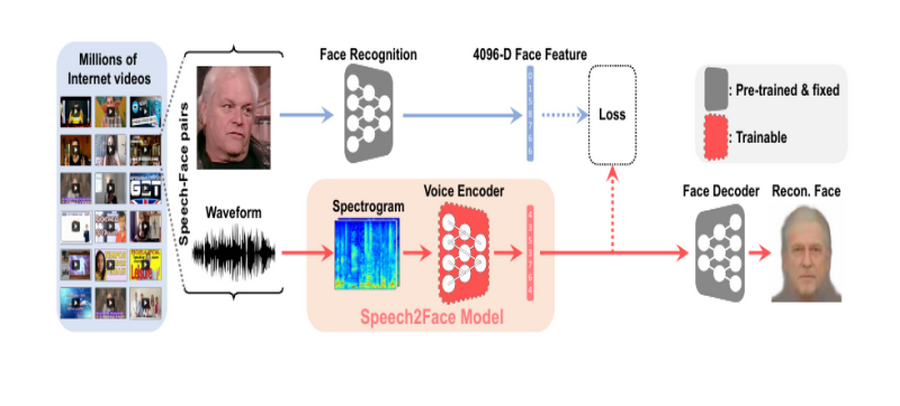
Принцип работы нейросети
Модель «Speech2Face»
Исследователи использовали модель распознавания лиц, предварительно обученную на большом наборе данных о лицах DeepFace. Нейросеть Speech2Face состоит из двух основных компонентов:
- речевой кодер, который принимает комплексную спектрограмму речи в качестве входных данных и прогнозирует признак, соответствующий связанному лицу;
- декодер, который принимает в качестве входного признака лицо и создает изображение в канонической форме – с фронтальной ориентацией и нейтральным выражением.
Во время обучения декодер фиксируется, и только голосовой кодер обучается, что дополнительно предсказывает функцию лица. Чтобы определить, насколько хорошо фиксируются различные черты лица в реконструкциях Speech2Face, ученые проверили различные аспекты модели.
Демографические атрибуты
Исследователи использовали Face++ – коммерческий сервис для вычисления атрибутов лица. Они оценили и сравнили возраст, пол и этническую принадлежность, запустив классификаторы Face ++ для исходных изображений и реконструкций Speech2Face. Классификаторы Face++ возвращают либо «мужской», либо «женский» для пола, непрерывное число для возраста и одно из четырех значений – «азиатское», «афроамериканское», «индейское» или «европейское» – для этнической принадлежности.
Исследователи оценивали черепно-лицевые измерения для определения соотношений и расстояний на лице. Ориентиры лица были рассчитаны с использованием библиотеки DEST.
Сходство черт
Далее ученые проверили, насколько хорошо человека можно узнать по признакам лица, предсказанным по речи. Выяснилось, что использование длинных аудиозаписей демонстрирует последовательное улучшение всех показателей. Они также оценили, насколько точно можно извлечь внешность говорящего из базы данных изображений лиц.
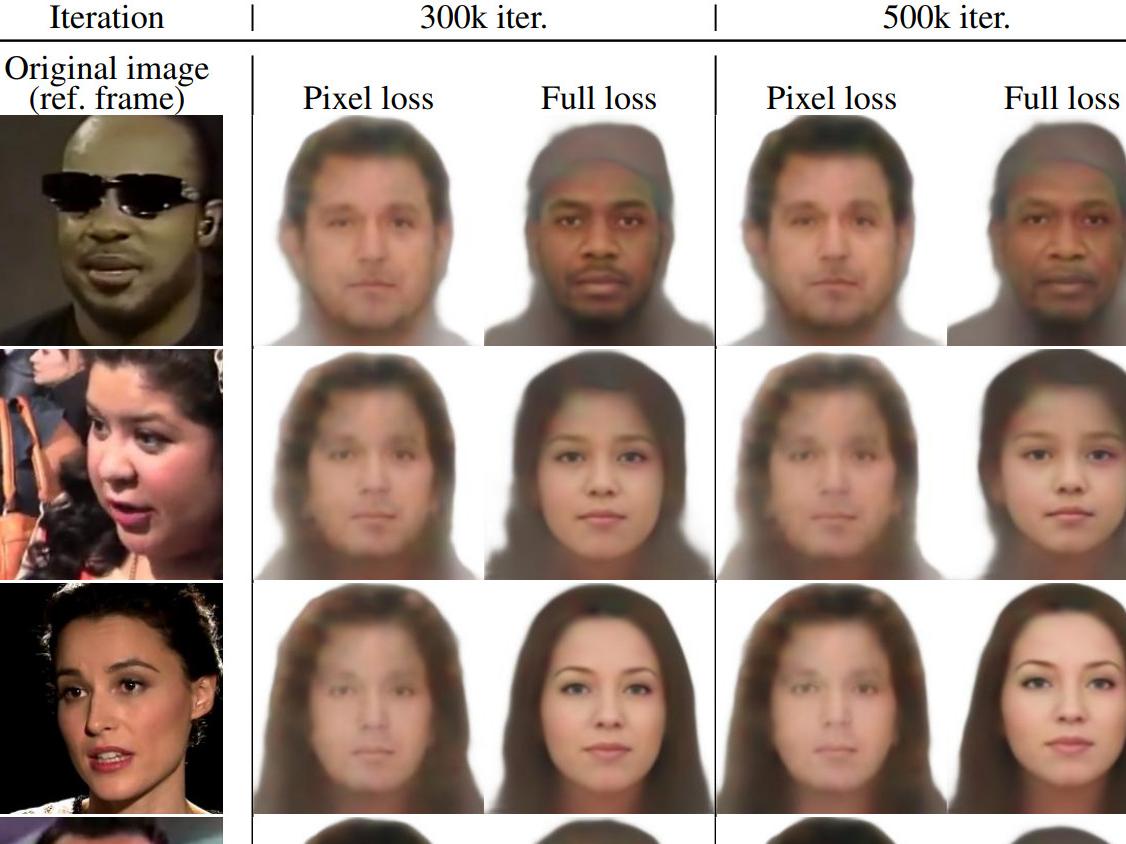
Результаты работы нейросети
На модель может повлиять неравномерное распределение данных. Если определенный язык не появляется в данных обучения, реконструкции не будут отражать черты, которые могут сочетаться с этим языком.
Ограничения
Чтобы проверить стабильность реконструкции Speech2Face, исследователи проверили модель на примере азиатского мужчины, который произносил одно и то же предложение на английском и китайском языках. В обоих случаях было бы идеально иметь одно и то же восстановленное лицо, но модель выявила разные лица на основе разговорной речи.

Изображение одного и того же человека в зависимости от языка, на котором он говорит
Авторы изучат модель поведения тщательнее, чтобы определить, в какой степени модель опирается на язык. Способность улавливать скрытые атрибуты речи – возраст, пол и этническая принадлежность – зависит от нескольких факторов: акцент, разговорная речь или высота голоса. В некоторых случаях эти характеристики не соответствуют внешности человека.








