Сразу оговорюсь, что я прекрасно понимаю, что есть способы гораздо проще, нежели CDC конвейер, но, по определённым причинам, мы выбрали именно этот способ.
Представьте, что перед вами на столе стоит бутылка воды и стакан, и все, что вы хотите сделать, это попить воды из стакана. Кажется, самым простым способом будет налить воды из бутылки в стакан и попить, в крайнем случае, можно попить сразу из бутылки. Но вам все эти варианты не нравятся, вы решаете построить водонапорную станцию, резервуары, насосы, системы фильтрации, проложить трубы до своей квартиры и только после всего этого попить воды. (Бутылка по прежнему стоит на столе). Задача стоящая, не так ли?
Примерно так ощущается настройка CDC конвейера для подсчёта APDEX, однако и у этого подхода есть ряд существенных плюсов. Мне, как человеку, мало знакомому с миром 1С, поначалу было трудно понять, почему добавить метрику в код может быть проблематично. Я бы не хотел останавливаться на противостоянии 1С и "классического IT".
Просто перечислю плюсы внедрения конвейера:
1. Всегда можно масштабировать схему. Хотите добавить новый домен? Добавляете Debezium коннектор и топик в kafka.
2. Данные попадают в Clickhouse с минимальной задержкой, что позволяет делать онлайн аналитику.
3. Можно строить аналитику не только по техническим метрикам, но и по ключевым бизнес-операциям (создание заказа, проведение платежа). Собственно говоря, в моем случае фокус направлен на это.
4. Минимальная нагрузка на команду разработки. Работа сводится к использованию встроенной библиотеки и записи метрик в 1сную базу.
Из минусов:
1. Сложность настройки. Cтек не простой, требует навыков и времени.
2. Нагрузка на MSSQL. CDC создаёт дополнительные системные таблицы и нагрузку на журнал транзакций.
3. При изменении схемы таблиц (например, новые поля в 1С) нужно обновлять коннекторы и структуру в Clickhouse.
4. При сбоях возможны задержки доставки или дублирование событий, что требует дополнительной логики дедупликации в ClickHouse. Как настроить дедупликацию, опишу далее.
Что необходимо учитывать до внедрения:
1. Необходимость администрировать CDC таблицу в MSSQL.
2. Дополнительные работы по настройке каждого модуля в конвейере.
3. Понимание как работает CDC таблица. CDC – это таблица изменений, а не бизнес-данных. Важно помнить это на каждом этапе передачи данных.
4. Вам нужен ключ, по которому вы будете схлопывать данные в Clickhouse.
5. Дополнительно нужно знать как работает колоночная СУБД.
Схема архитектуры и описание всех модулей и взаимосвязей
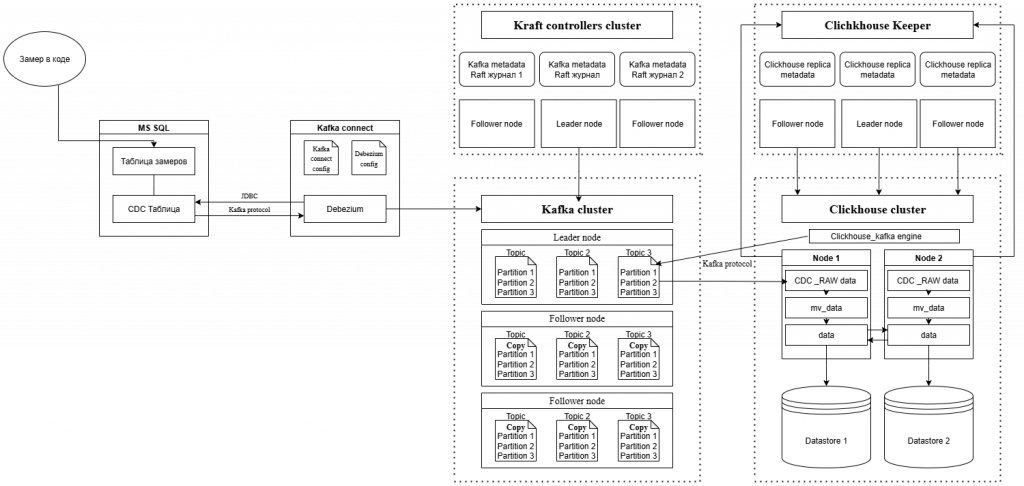
Основные особенности компонентов:
MSSQL (CDC) Источник данных: база 1С, таблица ключевых операций.
Change Data Capture (CDC) фиксирует изменения в таблицах (INSERT, UPDATE, DELETE). В нашем случае только INSERT И DELETE. Как мне объяснили знающие 1сники, в таблице замеров не может быть UPDATE из-за внутренней логики 1с. CDC создаёт специальные системные таблицы, из которых Debezium может читать изменения.
Debezium (Kafka Connect) cлушает MSSQL CDC и преобразует изменения в события (JSON). Публикует эти события в Kafka топики. Под каждую таблицу ключевых операций лучше создать отдельный топик.
Может работать параллельно для разных таблиц/баз.
KRaft и Clickhouse Keeper нужны для управления кластерами Kafka и Clickhouse соответственно.
Clickhouse потребитель Kafka сообщений. Нужно содержать как минимум 3 таблицы:
1. Таблица подписчик на события в топике кафка. Движок — Kafka Engine.
2. Materialized view который преобразует полученные сообщения в табличный вид.
3. Основная таблица данных, к которой мы будем обращаться запросами.
В случае если в вашу таблицу замеров не будут приходить DELETE, этим можно обойтись, если же DELETE приходят, то нужно добавить таблицу-копию MSSQL CDC и MV для схлопывания INSERT И DELETE по ключу.
Минимально рабочий кластер для прода:
ClickHouse — 2 ноды.
ClickHouse Keeper — 3 ноды.
Kafka Brokers — 2–3 ноды.
Kafka KRaft Controllers — 3 ноды.
В старых версия конвейера рекомендовали использовать сборку с Zookeeper вместо KRaft и Clickhouse Keeper
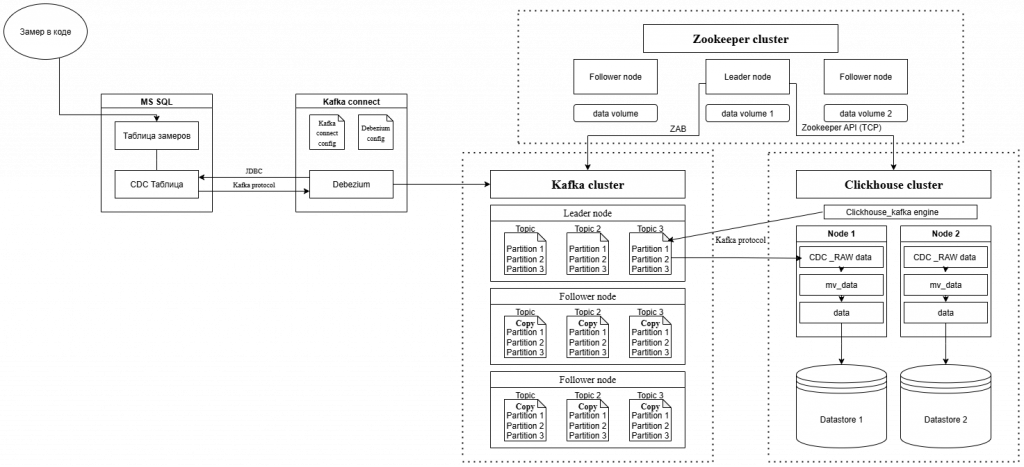
Схема передачи данных и описание потока
Первичная таблица
В таблицу замеров поступают данные с уровня кода. Все изменения( INSERT ,DELETE , UPDATE(в нашем случае он не нужен) фиксируются в транзакционном логе MSSQL.
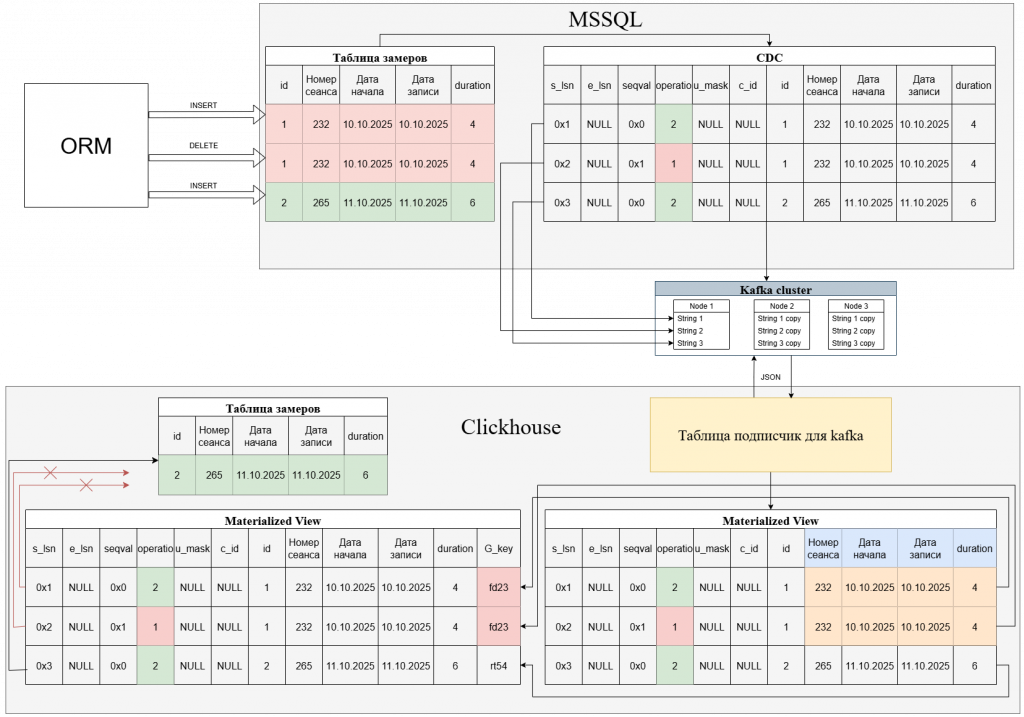
CDC таблица
CDC читает транзакционный лог и складывает изменения в таблицу cdc.dbo_tablename_CT.
Служебные поля CDC:
__$start_lsn — идентификатор транзакции (Log Sequence Number).
__$end_lsn — конец транзакции. Для INSERT/DELETE обычно NULL.
__$seqval — порядок записи внутри транзакции (физический порядок в логе).
__$operation — тип операции:
1 = DELETE
2 = INSERT
3 = UPDATE (before)
4 = UPDATE (after)
__$update_mask — битовая маска изменённых полей (актуально для UPDATE).
__$command_id — порядковый номер команды внутри транзакции.
CDC таблица читается коннектором, каждое событие превращается в Kafka сообщение.
Clickhouse таблица с движком Kafka Engine читает события из Kafka топика. Первичный MV перегоняет данные в таблицу буфер (отсутствует на схеме), которая по сути является копией MSSQL CDC таблицы. Основная особенность работы CDC заключается в том, что в ClickHouse попадают все изменения из MSSQL — как INSERT, так и DELETE. Если сохранять их напрямую, анализ данных будет некорректным: в таблице окажутся одновременно и вставки, и удаления, без понимания актуального состояния.
Для решения этой проблемы:
Добавляем ещё один MV, который выполняет выполняет преобразование событий.
Каждому INSERT присваивается sign = 1.
Каждому DELETE присваивается sign = -1.
Дополнительно формируется суррогатный ключ из четырёх бизнес полей (номер сеанса , Дата начала, Дата записи, Duration). Этот ключ уникально идентифицирует строку.
Последняя таблица с движком CollapsingMergeTree использует суррогатный ключ и sign, чтобы схлопывать пары событий:
Если на INSERT приходит соответствующий DELETE, они взаимно уничтожаются, и запись исчезает из финальной таблицы. Если приходит DELETE без соответствующего INSERT (например, запись уже была удалена ранее), он не попадает в финальную таблицу, так как нет строки для удаления. Таким образом, в финальной таблице остаётся только актуальное состояние данных. Далее уже можно прикрутить Grafana, либо любой удобный для вас инструмент визуализации данных и подключить Clickhouse как источник. Можно считать перцентили, строить графики, SLA, в общем все, на что у вас хватит фантазии и тех задания)
Понятно, что в данной системе возникнет большое количество подводных камней, и содержать ее дорого, и потребуется много трудозатрат и ровные руки. По ходу обслуживания конвейера будут появляться новые задачи (или проблемы, в зависимости от того как вы воспринимаете :) ) по его обслуживанию. Например, проверки наличия дубликатов или проверки целостности полученных данных. Но, в случае если у вашей компании есть ресурсы, конвейер как минимум упростит работу 1с разработчикам и не будет сильно влиять на 1сные базы.
Как-то так, это был мой первый опыт написания технических статей, прошу строго не судить)
Вступайте в нашу телеграмм-группу Инфостарт