- Введение
- Концепция
- Техническая реализация
- Перевод модели конфигурации по словарю
- Результат перевода
- Перспективы и дальнейшие планы
Введение
1C:Language Tool – это официальный плагин для среды разработки 1C:EDT, который предназначен для автоматизации перевода интерфейса на дополнительные языки, а также исходного кода и метаданных конфигураций на платформе "1С:Предприятие 8" на альтернативный язык, например с русского на английский. Инструмент предназначен для решения следующих задач:
- Синхронный выпуск конфигурации на исходном языке кода и метаданных и конфигурации с кодом и метаданными, переведенными на другой язык, например, конфигурации на русском языке кода и метаданных и той же конфигурации на английском языке.
- Автоматизация разработки конфигураций с интерфейсом на нескольких языках. Эта задача может решаться как одной командой разработчиков, так и с привлечением внешних команд для перевода интерфейса.
- Разработка локализованных версий конфигурации внедряющим партнером на национальном рынке на основе международной или другой национальной поставки.
На портале ИТС доступен вебинар посвященный Language Tool: Дмитрий Мармышев, занимающийся разработкой этого инструмента, достаточно подробно рассказывает про возможности и сценарии использования плагина.
Итак, плагин EDT Language tool позволяет выполнять перевод метаданных конфигурации по словарю. Например, используем следующий словарь:
#Translations for: common
АктВыполненныхРабот=AcceptanceCertificate
После перевода конфигурации лексема "АктВыполненныхРабот" будет заменена на "AcceptanceCertificate". То есть будет переименован документ, соответственно изменены все обращения к нему, имена переменных и т.д.
Дополнительно, Language tool умеет менять язык скрипта с русского на английский (или обратно):

А значит, если составить словарь для метаданных, плагин выполнит автоматический перевод модели конфигурации. Плюс можно одновременно переключить встроенный язык платформы с русского на английский.
Концепция
В 1C Vietnam мы ведём разработку нескольких типовых конфигураций для Вьетнамского рынка. Почти все они представляют собой локализованные версии российских типовых конфигураций.
Один из продуктов - конфигурация Company Management (cокращённо CM), разработанная на основе 1С:УНФ 1.4 и полностью переведённая на английский язык, включая код и метаданные.
При переносе функционала из современных редакций УНФ в Company management, помимо различий в структуре конфигураций, дополнительную сложность вызывает отличие в языках конфигураций. И большой объём работы связан с переводом русского кода и метаданных УНФ на английский язык.
Объём этой работы можно существенно сократить, если перед переносом функционала предварительно перевести модель УНФ на английский язык. Причём выполнить перевод необходимо сохранив уже использованные в Company management термины. Например Касса перевести не как Cash или Cashbox, а как PettyCash потому что в СМ использован этот вариант перевода.

Далее, имея актуальную редакцию УНФ с именами метаданных из Company management, можем с помощью Language tool перенести контекстные переводы (сообщения, элементы форм и прочее).
Можно ли "перенести" перевод из СМ в актуальную редакцию УНФ?
Имеем конфигурацию с английским кодом и английскими метаданными. Она разработана на основе русской УНФ. Если выполнить сопоставление объектов двух конфигураций, получим англо-русский словарь для перевода метаданных. В качестве ключа сопоставления будем использовать внутренний uuid объектов.
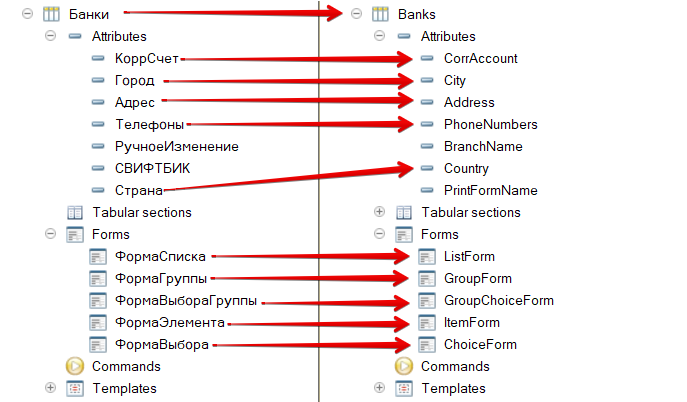
 Проверим соответствие
Проверим соответствие uuid объектов с помощью сравнения конфигураций:
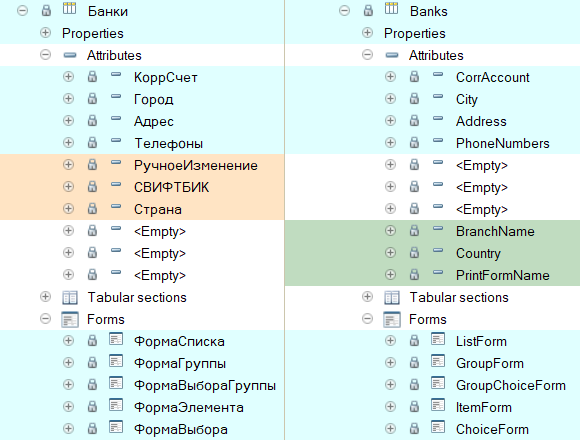

Как видим, у части совпадающих реквизитов uuid сохранился, а значит их имена пойдут в словарь. А например реквизит Country (Страна) был перенесён в Company management копированием, и его uuid отличается.
Техническая реализация
Для воплощения идеи в жизнь выполним следующие шаги:
- Составление словаря
- Нормализация словаря
- Перевод модели конфигурации по словарю
Рассмотрим подробно выполнение каждого этапа.
1. Составление словаря
В проекте EDT конфигурация 1С хранится в виде набора файлов, содержащих все свойства и идентификаторы объектов. Для сопоставления метаданных двух конфигураций получим необходимые сведения из этих файлов с помощью регулярных выражений.
Обратимся к файлу Банки.mdo. В файле хранится описание справочника Банки со всеми его свойствами, реквизитами, формами и прочим.
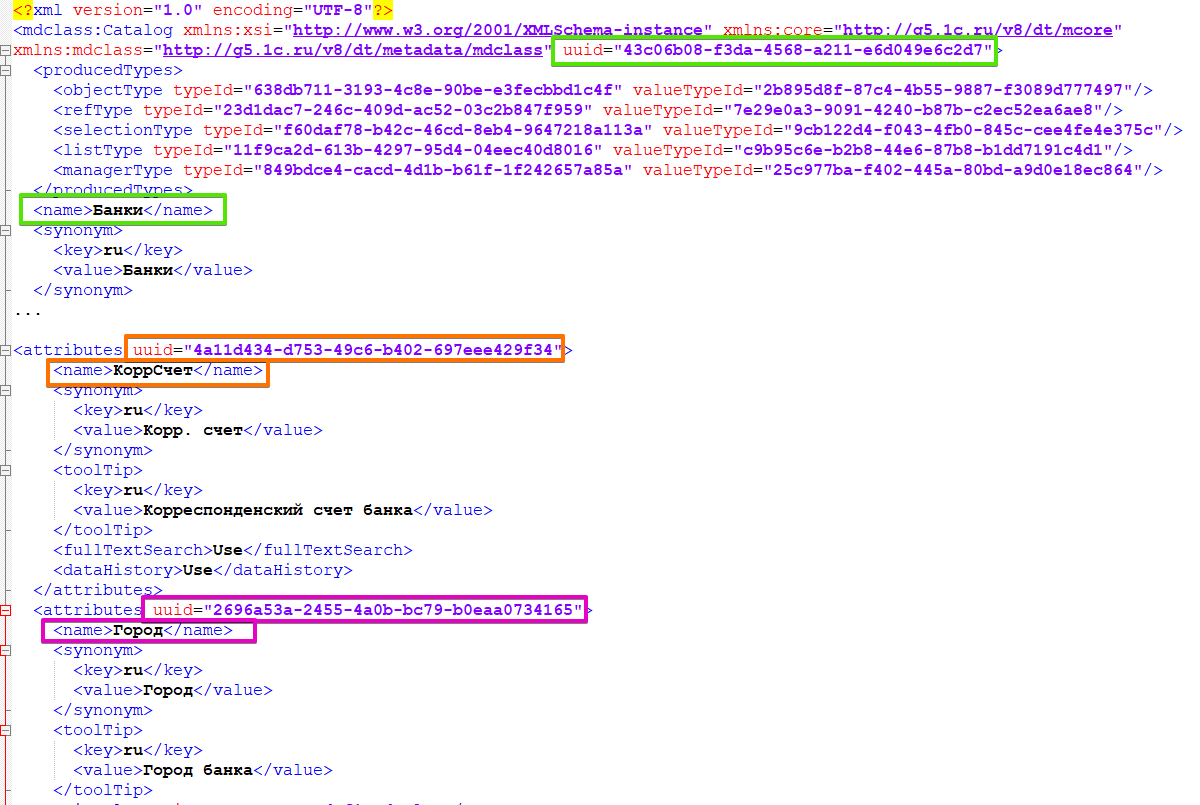
Из этого файла нас интересуют соответствия uuid - имя.
-
Чтобы собрать такие соответствия по всем объектам конфигурации, воспользуемся регулярным выражением:
grep -Przo --include=\*.mdo '(?s)uuid=".*?"\>.*?\<name\>.*?\<\/name\>\s\n'
Параметры:
-PПри интерпретации шаблона использовать дополнительный функционал Perl-скриптов
-rИскать рекурсивно в папке, из которой запущена прогррамма
-zОбрабатывайте входящие данные как набор строк, каждая из которых заканчивается нулевым байтом (символ ASCII NUL) вместо символа новой строки
-oВыводить только совпадающий фрагментВ результате получим все блоки текста между uuid и тегом name:
Банки.mdo:uuid="43c06b08-f3da-4568-a211-e6d049e6c2d7"> <producedTypes> <objectType typeId="638db711-3193-4c8e-90be-e3fecbbd1c4f" valueTypeId="2b895d8f-87c4-4b55-9887-f3089d777497"/> <refType typeId="23d1dac7-246c-409d-ac52-03c2b847f959" valueTypeId="7e29e0a3-9091-4240-b87b-c2ec52ea6ae8"/> <selectionType typeId="f60daf78-b42c-46cd-8eb4-9647218a113a" valueTypeId="9cb122d4-f043-4fb0-845c-cee4fe4e375c"/> <listType typeId="11f9ca2d-613b-4297-95d4-04eec40d8016" valueTypeId="c9b95c6e-b2b8-44e6-87b8-b1dd7191c4d1"/> <managerType typeId="849bdce4-cacd-4d1b-b61f-1f242657a85a" valueTypeId="25c977ba-f402-445a-80bd-a9d0e18ec864"/> </producedTypes> <name>Банки</name> Банки.mdo:uuid="4a11d434-d753-49c6-b402-697eee429f34"> <name>КоррСчет</name> Банки.mdo:uuid="2696a53a-2455-4a0b-bc79-b0eaa0734165"> <name>Город</name> Банки.mdo:uuid="7c7741be-fa4d-4665-a05c-d71a3338dc21"> <name>Страна</name> Банки.mdo:uuid="9e4f4597-380d-41b5-980d-b4ea881ffe08"> <name>ФормаЭлемента</name> Банки.mdo:uuid="25b39760-a17c-40d2-b5ae-49936c78ebc3"> <name>ФормаВыбора</name>
-
Удалим лишний текст с помощью регулярного выражения
perl -0pe 's|(?s).*?uuid="(.*?)">.*?<name>(.*?)<\/name>|\1 \2|g'
Команда perl в данном случае работает аналогично команде sed: поиск и замена фрагментов текста по шаблону. Но с помощью sed мне не удалось добиться замены многострочных фрагментов.На выходе получим:
43c06b08-f3da-4568-a211-e6d049e6c2d7 Банки 4a11d434-d753-49c6-b402-697eee429f34 КоррСчет 2696a53a-2455-4a0b-bc79-b0eaa0734165 Город ba5226c3-2e58-4190-95f4-00d4244f5a9e Адрес 3ec69c99-c530-4738-9cf3-f66fe89c6cd7 Телефоны 9431f164-17e1-4dce-893e-86ddb56d248d РучноеИзменение 8768f640-afff-452f-82e5-9925a9060d6c СВИФТБИК 7c7741be-fa4d-4665-a05c-d71a3338dc21 Страна da439aff-54e8-476d-aebf-f7280718837b ФормаСписка 36d95a22-4cfa-4468-b881-3d6d76a2a6ba ФормаГруппы e6866db9-ad0c-4568-a55d-9696ee37a862 ФормаВыбораГруппы 9e4f4597-380d-41b5-980d-b4ea881ffe08 ФормаЭлемента 25b39760-a17c-40d2-b5ae-49936c78ebc3 ФормаВыбора 62a0f412-b215-4cd5-948b-266705660162 УдалитьКлассификаторБанков
То что нужно! uuid + имя.
- Дополнительно обработаем результат с помощью команды
sed 's/\x0//', чтобы избавиться от ненужных нам незначащих символов в начале и конце строк:
- Соберём всё вместе (результат выводим в файл dict_ru.txt):
grep -Przo --include=\*.mdo '(?s)uuid=".*?"\>.*?\<name\>.*?\<\/name\>\s\n' | perl -0pe 's|(?s).*?uuid="(.*?)">.*?<name>(.*?)<\/name>|\1 \2|g' | sed 's/\x0//' > dict_ru.txt -
Аналогично сформируем dict_en.txt с уидами и английскими именами.
-
Теперь нужно соединить файлы dict_ru.txt и dict_en.txt по уиду и взять русское имя из первого файла, а соответствующее ему английское имя - из второго. Для этого используем команду join:
join -o 1.2,2.2 <(sort dict_ru.txt) <(sort dict_en.txt)Результат:
ФормаВыбора ChoiceForm Город City ФормаГруппы GroupForm Телефоны PhoneNumbers Банки Banks КоррСчет CorrAccount ФормаЭлемента ItemForm Адрес Address ФормаСписка ListForm ФормаВыбораГруппы GroupChoiceForm
2. Нормализация словаря
Словарь, собранный в первом шаге по метаданным справочника Банки, выглядит вполне пригодно для перевода конфигурации. Однако, если выполнить составление такого словаря по всей конфигурации, потребуется дополнительная обработка полученных данных.
Во-первых, нужно почистить дубли. Например, из каждого документа, в котором есть реквизит Автор, в словаре появится дополнительная строчка Автор=Author.
Во вторых, необходимо учесть ситуации, когда одна и та же русская лексема переведена на английский по-разному. Например слово Вид в основном переведено Kind, но кое-где как Type. Или слово Комментарий: почти везде переведено как Comment, но пару раз встречается вариант перевода Description, и так далее.
В словаре не должно быть подобных неоднозначностей, необходимо оставить только один вариант перевода для каждой лексемы. Правильно будет оставить тот вариант перевода, который используется чаще.
Для этого выполним следующие действия:
- Подсчитаем сколько раз встречается каждый вариант перевода с помощью команд:
sort | uniq -c - Упорядочим список по убыванию, самые часто используемые варианты перевода будут сверху списка:
sort -r - Теперь удалим колонку с количеством использований вариантов перевода:
sed -r 's/^\s*?[0-9]+ //' - Удалим дубли строк без изменения порядка строк. Для каждой лексемы останутся наиболее частотные варианты перевода:
awk '!a[$1]++' - Упорядочим полученный словарь по алфавиту и выведем в файл dict_ru_en.txt:
sort > dict_ru_en.txt
Всё вместе:
join -o 1.2,2.2 <(sort dict_ru.txt) <(sort dict_en.txt) |
sort | uniq -c | sort -r |
sed -r 's/^\s*?[0-9]+ //' |
awk '!a[$1]++' |
sort > dict_ru_en.txt
В итоге получаем практически готовый словарь:
АвтоматическиеСкидки=AutomaticDiscounts
Автор=Author
Адрес=Address
АдресЭлектроннойПочты=EmailAddress
АдресЭП=EmailAddress
АктВыполненныхРаботПрисоединенныеФайлы=AcceptanceCertificateAttachedFiles
АлгоритмПодписи=SignAlgorithm
АлгоритмХеширования=HashAlgorithm
АлгоритмШифрования=EncryptionAlgorithm
Артикул=SKU
БазовыйВидЦен=PricesBaseKind
БанковскиеСчета=BankAccounts
-
Проверим чтобы все имена объектов с префиксом Удалить при переводе имели префикс Delete. Таких объектов не очень много (40 строк), я сделал эту операцию вручную.
-
По-хорошему нужно выполнить ещё проверку совпадающих переводов: когда различные исходные лексемы имеют одинаковый перевод.
Например:
Покупатель=Customer и Заказчик=Customer
Услуга=Service и Служебный=ServiceКак правило это не является проблемой, пока не приводит к дублированию имён в рамках общего контекста. Если у нас есть две подсистемы Услуга и Служебная, то после перевода они сольются в одну подсистему Service. Это некорректная ситуация.
В то же время, если у одного справочника есть реквизит Услуга, а у другого справочника - реквизит Служебный, то после перевода реквизиты будут называться одинаково, но конфигурация останется работоспособной.Я пока остановился на поиске дублей имён метаданных верхнего уровня. Часть ошибок исправлял непосредственно в переведённой конфигурации.
Но вообще надо избавляться от образования дублей перевода - причесать словарь. Мы более подробно остановимся на этой работе во второй части статьи.
Комментарий разработчиков плагина по поводу совпадающих переводов:
[При дублировании имён] Например, параметры в СКД могут свернуться 2 в 1, поля структуры варианта отчетов, выбираемые поля запроса динамического списка и т.д. Практически в любой точке конфигурации может "выстрелить". И зачем?
Пока идем по стратегии - что если на исходном языке слова разные - должны быть и в переводимом языке разные.
3. Анализ полученного словаря
Исходный словарь метаданных русской УНФ насчитывает 38 402 строк, из них уникальных - 19 691
Словарь Company management 11 846 строк, из них уникальных - 5 598
У нас получился русско-английский словарь, включающий 4 834 уникальные лексемы.
Количество переведённых строк исходного словаря УНФ 17 754, то есть 46%.
Процент покрытия будет выше, если использовать не УНФ 1.6, а УНФ 1.4, более родтсвенную нашей СМ. Плюс не нужно учитывать при подсчёте словари выброшенных подсистем, таких как ЕГАИС, ВЕТИС, регламентированная отчётность и другие специфичные для России возможности, неактуальные во Вьетнаме - большая часть непереведённого русского словаря связана с ними.
Перевод модели конфигурации по словарю
Мы получили русско-английский словарь метаданных. Как теперь выполнить перевод конфигурации по этому словарю?
Здесь всё просто: подсовываем в Language Tool наш словарь, нажимаем Перевести конфигурацию и ждём. Время перевода будет зависить от используемого "железа" и размера конфигурации, у меня на ноутбуке с i5 1.8 GHz, 16 GB RAM процесс занимает примерно 3 часа.
Всё - получаем переведённую работоспособную конфигурацию.
Шутка 😄 Это не наш случай.
Инструмент ещё молодой, текущая версия 0.8 говорит нам о том что это пока бета. И после перевода я столкнулся с большим количеством ошибок: как ошибки работы плагина, так и ошибки в конфигурации. Дело в том, что автоматизированный перевод кода возможен благодаря типизации, вычисляемой EDT, и далеко не всегда эту типизацию кода 1С можно провести корректно. Плюс плагин сейчас очень чувствителен к соблюдению стандартов разработки в переводимой конфигурации. И это понятно - на что-то нужно опираться. Но в коде типовой УНФ (как впрочем и в БСП) стандарты соблюдаются не на 100%.
Не смотря на текущие сложности, Language tool инструмент очень перспективный и я с интересом буду следить за его развитием и использовать в работе. Замечательно, что у нас появилось новое мощное средство локализации.
Результат перевода
Посмотрим на нескольких примерах как выглядит переведённая конфигурация.
Имена объектов метаданных:

Программный код и запросы:

Запрос динамического списка:
Отчёт на СКД:
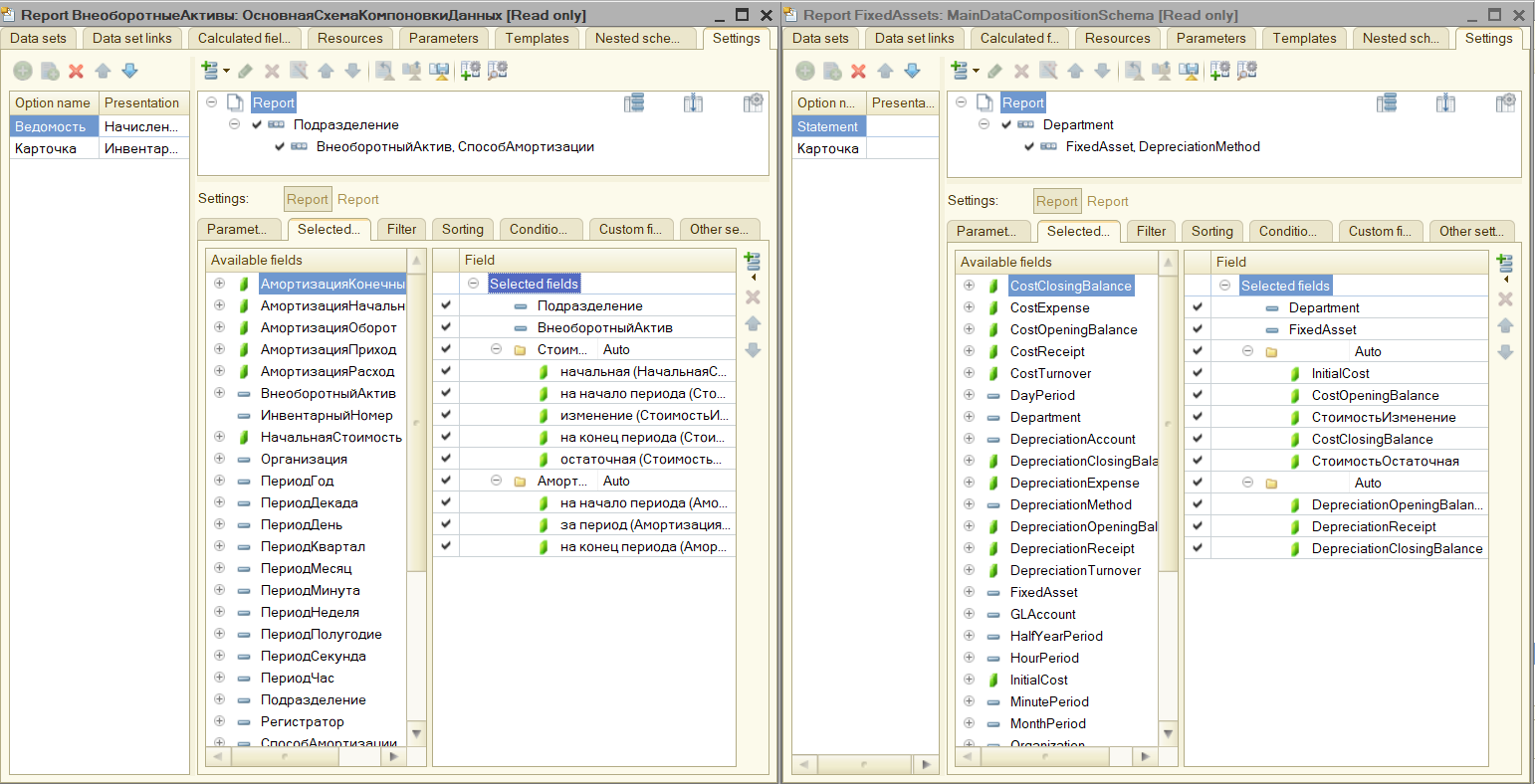
Видим, что Language Tool выполнил перевод имён метаданных в модулях, запросах, макетах СКД и других местах.
Использованы версии EDT 1.16.0.363, Language Tool 0.7.1.14
Перспективы и дальнейшие планы
В следующей части статьи я покажу как был составлен словарь для перевода УНФ на основе нескольких имеющихся словарей из разных источников. А так же более подробно остановлюсь на способах нормализации словаря и устранении неоднозначностей переводов.
В дальнейшем полученные словари могут быть использованы для перевода других конфигураций.
Вступайте в нашу телеграмм-группу Инфостарт