
{kind=link}
Первая публикация... она растянулась на несколько лет...
Вступление
В 2016 году я устроился на работу в одну достаточно известную в нашей стране компанию (не франч и даже не IT) на должность 1С разработчика. Основная деятельность компании - оптовая торговля, по мимо этого компания занималась и другими направлениями, документооборот - не сколько сотен тысяч документов в год... Конфигурация используемая на предприятии самописная, за основу взяли УТ 10.3 и потом пошло поехало... сейчас что то типового там днём с огнём не сыщешь...
Шло время и количество пользователей увеличивалось, как и число 1С разработчиков. Базы данных росли как на дрожжах, с каждым годом количество документов становилось все больше и больше, пользователи все чаще многократно корректировали свои документы, программисты внося изменения в конфигурацию все чаще меняли документы чтобы получить нужный результат для выполнения задачи (добавление новых реквизитов, измерений в регистрах и заполнение данных в документах старого периода и т.д.)... Настал тот момент, когда копии разворачивались очень долго, обслуживание базы скриптами длилось уже гораздо дольше прежнего, в результате анализа размера таблиц БД выяснилось что основной "камень на шее" это регистр сведений "Версии объектов", о нём и пойдёт речь в данной публикации.
Большие данные
Регистр сведений "Версии объектов" занимал несколько сотен ГБ, он не чистился с момента перехода компании на новую конфигурацию и был "жизненно" необходим многим пользователям, с помощью него расследовались спорные ситуации по изменениям документов и справочников, исправлялись ошибки... В общем стало понятно, что просто так взять и почистить не получится, а так хотелось:)
Пользователи работали в разных БД на основе одной конфигурации - две базы разных структурных подразделений для работы "рядовых" пользователей, отельная база для другого направления деятельности и база для аналитики - куда были вынесены сложные и ресурсоёмкие расчеты - закрытия месяца и т.д. И это все не просто жило жизнью "сильной и не зависимой женщины", а так или иначе обменивалось данными с регулярной периодичностью – через планы обмена и веб сервисы, изменения в одной базе выгружались в остальные или если этого не требовалось то не выгружались… Пользователь в рамках одной базы знал про изменения и видел следующую картину
Кто то внес изменения в другой базе и к нему это пришло с обменом, но чтобы найти «виновника» нужно зайти в базу где эти изменения произошли – чтобы этого избежать напрашивалась централизация сбора версий…
Отрицательный опыт это тоже опыт
Чтобы не изобретать велосипед и тратить время на разработку технической истории решили вложится с продукт стороннего разработчика, по описанию казалось как раз тем что нам нужно. Продукт был куплен, написали обработку для сериализации наших версий в формат нового продукта и пошел процесс начального заполнения…. Продукт хранил версии раскладывая их по реквизитам, а не как у нас в сериализованном виде XML. База Хранилища заполнялась крайне медленно и её размер уже превышал размер самой базы источника, и это было только начало, версии остальных баз решено было не загружать так как «бочка» оказалась не бездонной – стал еле ворочаться на сервере заняв все его ресурсы и медленно отвечать на запросы в получении произошедших с объектом изменений.
Хочешь сделать хорошо – сделай сам
Решать проблему было надо и другого пути, чтобы максимально быстро это сделать на горизонте не намечалось. Итак появилась конфигурация «Хранилище версий» на платформе всем известной 1С... да можно было для этого использовать иные продукты типа Elasticsearch, но… что сделано то сделано…
Выглядит интеграция «Хранилища версий» следующим образом:
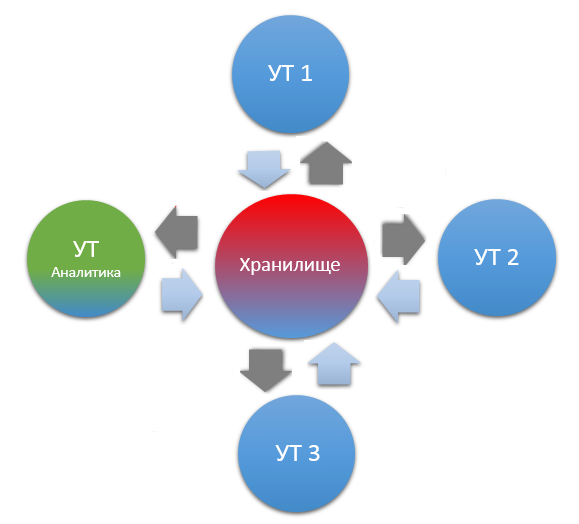
3 рабочих базы и 1 аналитическая служат первоисточником получения данных по версиям. При изменении объекта версия пишется в саму базу источник, затем регламентно по веб сервису хранилище забирает порциями версии объектов, перед записью предварительно сравнивает контрольные суммы версий – для того чтобы определить произошли ли какие то изменения или объект был записан без изменений. Если изменения имели место быть то версии присваивается номер и она записывается в базу хранилища.
Структура регистра для хранения версий:
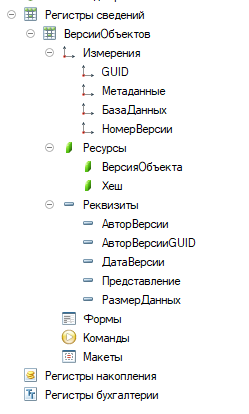
Отсюда же снимаем красивые отчеты о количестве версий и объеме который они занимают, находим кто является самым модифицирующим данные пользователем. В ряде случаев это помогло выявить регламенты (почти каждый регламент крутился под своим пользователем - необходимость в случае когда конфигурацию разрабатывает много команд) , которые делали очень много изменений, как в последствии выяснилось это было лишним и регламенты были отключены или переписаны на более оптимальный алгоритм работы.
Ускоряемся
Эволюционируем и переходим к более быстрым технологиям обмена данными - передаче и получению версий объектов через брокер сообщений Rabbit MQ. Используя компоненту YellowRabbit передаем из баз источников версии в хранилище (почти в онлайн режиме), версии уже не хранятся временно в базах - при записи объекта версия пишется в сообщение для брокера и уже через секунду оно отправляется в брокер, при получении версий в хранилище выполняется аналогичный алгоритм проверки контрольной суммы.
Для получения версий также используем Rabbit MQ - с помощью асинхронного вызова делаем запрос к хранилищу и получаем данные по версиям объекта...
Спасибо, что уделили время;)
Вступайте в нашу телеграмм-группу Инфостарт