Сейчас, наверное, всем известно, что перемещаться быстрее, чем скорость света в вакууме, невозможно. Однако мексиканский физик Мигель Алькубьерре предложил концепцию, с помощью которой теоретически можно построить двигатель, который позволит преодолеть этот барьер. Правда для этого потребуется некая экзотическая материя и количество энергии, по оценкам, эквивалентное массе Юпитера.
А теперь про «срез последних» регистра сведений 1С и проблемы, с ним связанные. Реализация «среза» в 1С, основанная на стандарте SQL, при росте количества записей начинает заметно тормозить. Мы имеем здесь аналогию со скоростью света - при приближении к определенному количеству записей в регистре, получить результат "среза последних" за приемлемое время уже невозможно.
Альтернативные варианты реализации, например здесь, позволяют ускорить получение результата примерно на 50%. И эта проблема связана не с 1С, а со стандартом SQL. Если придерживаться стандарта, эффективно решить задачу уже невозможно. Проблема в том, при росте количества записей замедление увеличивается экспоненциально. И выигрыш в несколько десятков процентов не спасет ситуацию.
Чтобы проиллюстрировать ситуацию, перейдем к цифрам, полученным на практике:
Есть независимый и непериодический регистр сведений с исторически сложившейся структурой, которую уже нельзя изменить по различным причинам (место на диске, недопустимо большое время реструктуризации):
Три измерения (именно в таком порядке):
Товар (Ссылка, ~20 000 различных значений)
Магазин (Ссылка, ~10 000 различных значений)
Дата (ДатаВремя)
Четыре ресурса (три числовых и ссылка) и один реквизит с типом «Строка».
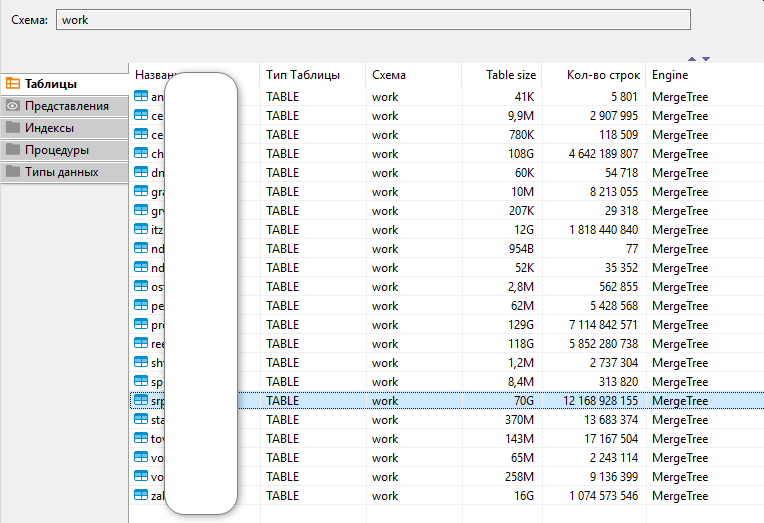
Количество записей в регистре на текущий момент приближается к двум миллиардам (1 784 781 077). При таком количестве записей реализация «среза последних» на MS SQL, даже при наличии всех необходимых индексов исполняется около двух часов на сервере (Intel(R) Xeon(R) CPU E5-2697 v3 , 128 Гб ОЗУ).
Чтобы кардинально решить проблему, данные регистра были выгружены в СУБД ClickHouse. Выгрузка из базы MS SQL в формат CSV выполнялась с помощью утилиты bcp.exe параллельно в 12 потоков и заняла полтора часа. Загрузка из файлов CSV в СУБД ClickHouse осуществлялась последовательно и потребовала всего 14 минут.
Все операции выполнялись из интерфейса специально разработанной для работы с ClickHouse конфигурации. База данных с этой конфигурацией использовала два соединения - HTTP с ClickHouse и HTTP - с базой 1С, которая соответствует базе SQL (для получения структуры хранения базы данных, необходимой для формирования запроса при вызове bcp.exe).
Конфигурация расширяет возможности интеграции с ClickHouse - добавляет пакетные запросы, управляемые временные таблицы (с автоудалением после завершения пакетного запроса), сжатие данных при обмене по HTTP с ClickHouse и другие необходимые возможности.
Теперь самое интересное: СУБД ClickHouse полностью не поддерживает стандарт SQL, но имеет свои расширения стандарта, которые позволяют решать многие задачи гораздо эффективнее и элегантнее.
Был создан cледующий запрос для получения среза последних по данным таблицы в ClickHouse:
SELECT
*
FROM
work.itz AS itz
INNER JOIN
(
SELECT
tovar,
magaz,
maxIf(itz.dat, itz.dat <= '<ДатаСреза>') AS dat
FROM
work.itz
GROUP BY (tovar, magaz)
HAVING maxIf(itz.dat, itz.dat <= '<ДатаСреза>') <> '0000-00-00 00:00:00'
) AS srez
USING
(tovar, magaz, dat)
Здесь work - имя базы, itz - имя таблицы в ClickHouse, наименование остальных полей (tovar, magaz, dat) соответствуют их сокращенной англоязычной транскрипции. Строка <ДатаСреза> в тексте запроса заменялась конкретной датой перед исполнением запроса (запрос был отправлен через HTTP интерфейс).
В этом запросе ключевым является использование агрегатной функции max с комбинатором If. Комбинаторы как раз и являются специфическим расширением стандарта SQL в ClickHouse, и предоставляют возможности, отсутствующие в стандарте SQL. О комбинаторах в ClickHouse можно прочесть в открытой документации: https://clickhouse.tech/docs/ru/sql-reference/aggregate-functions/combinators/
И на том же наборе данных, на котором «срез последних» в MS SQL рассчитывался 2 часа, результат приведенного запроса к CУБД ClickHouse был получен через 40 секунд (около 10 миллионов записей).
Результат был получен быстрее не на десятки процентов, а на два порядка ! При этом СУБД ClickHouse установлена на одном компьютере с такими же характеристиками, что и компьютер для базы MS SQL (Xeon 14 ядер 28 потоков, 128 Гб ОЗУ). Кстати, сравнение сложности «многоэтажного запроса» в MS SQL и запроса из нескольких строк к СУБД ClickHouse также весьма красноречиво выглядит.
Вот это и есть «варп-двигатель» для «среза последних». Самая быстрая в мире, по независимым оценкам, СУБД ClickHouse и грамотное использование её возможностей для нестандартного решения типовой задачи. А если учесть, что производительность СУБД ClickHouse практически линейно зависит от количества ядер и компьютеров, на которых она развернута, то "срез последних" для больших данных теперь не является нерешаемой проблемой.
"ClickHouse не тормозит !" - лозунг, которым руководствуются разработчики СУБД из компании Яндекс, полностью оправдывается при решении частной задачи - получении данных "среза последних".
Вступайте в нашу телеграмм-группу Инфостарт