




Для начала ответим на вопрос: зачем нам может понадобиться Python. В предыдущей статье Data science. Начало (infostart.ru) мы применили регрессионный анализ и построили дерево решений для того, чтобы получить оценку стоимости объекта недвижимости. Мы использовали штатный объект платформы под названием "АнализДанных". Путем некоторых ухищрений нам удалось немного повысить точность прогноза.
Язык программирования Python считается одним из обязательных инструментов для специалистов в области Data science и Data engineering. Попробуем использовать его для решения нашей задачи. Хорошая новость заключается в том, что вам не потребуется что-то скачивать и разбираться с установкой. Облачная среда разработки доступна всем и каждому. Регистрируетесь на Kaggle и создаете т.н. "notebook".
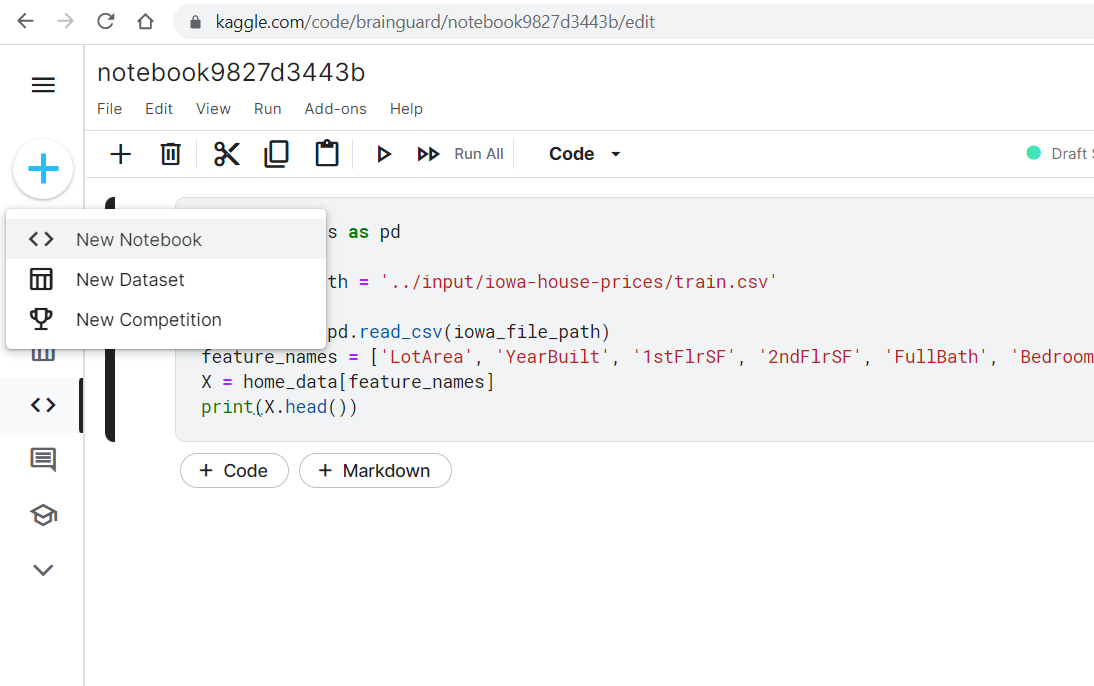
Добавляете набор данных. В нашем случае это будет iowa-house-prices. И ваша среда разработки готова
Напомню, что в прошлый раз мы начали с того, что построили прогноз, используя 7 колонок из исходных данных. В 1С это выглядело так:
//получение данных
Макет=РеквизитФормыВЗначение("Объект").ПолучитьМакет("ИсходныеДанные");
ТЗМодель=новый ТаблицаЗначений;
ТЗМодель.Колонки.Добавить("ПлощадьУчастка");
ТЗМодель.Колонки.Добавить("ГодПостройки");
ТЗМодель.Колонки.Добавить("Площадь1этажа");
ТЗМодель.Колонки.Добавить("Площадь2этажа");
ТЗМодель.Колонки.Добавить("КоличествоПолныхСанузлов");
ТЗМодель.Колонки.Добавить("КоличествоСпален");
ТЗМодель.Колонки.Добавить("КоличествоКомнат");
ТЗМодель.Колонки.Добавить("Цена");
ТЗПрогноз=ТЗМодель.Скопировать();
для й=2 по Макет.ВысотаТаблицы цикл
нстр=ТЗМодель.Добавить();
нстр.ПлощадьУчастка=число(Макет.Область(й,5).Текст);
нстр.ГодПостройки=число(Макет.Область(й,20).Текст);
нстр.Площадь1этажа=число(Макет.Область(й,44).Текст);
нстр.Площадь2этажа=число(Макет.Область(й,45).Текст);
нстр.КоличествоПолныхСанузлов=число(Макет.Область(й,50).Текст);
нстр.КоличествоСпален=число(Макет.Область(й,52).Текст);
нстр.КоличествоКомнат=число(Макет.Область(й,55).Текст);
нстр.Цена=число(Макет.Область(й,81).Текст);
если й<11 тогда
нстрпрогноз=ТЗПрогноз.Добавить();
ЗаполнитьЗначенияСвойств(нстрпрогноз,нстр);
конецесли;
конеццикла;
//подготовка
Анализ=новый АнализДанных;
Анализ.ТипАнализа=Тип("АнализДанныхДеревоРешений");
Анализ.ИсточникДанных=ТЗМодель;
Анализ.Параметры.ТипУпрощения.Значение=ТипУпрощенияДереваРешений.НеУпрощать;
РДерево=Анализ.Выполнить();
//прогноз
Прогноз=РДерево.СоздатьМодельПрогноза();
Прогноз.ИсточникДанных=ТЗПрогноз;
Результат=Прогноз.Выполнить();
//визуализация
ТабДок.Очистить();
ТабДок.УстановитьРастягиваниеПоГоризонтали(Истина);
для й=1 по Результат.Колонки.Количество()-1 цикл
ТабДок.Область(1,й).Текст=Результат.Колонки[й-1].Имя;
ТабДок.Область(1,й).Шрифт=Новый Шрифт(ТабДок.Область(1,й).Шрифт, ,, Истина);
конеццикла;
для й=1 по Результат.Количество() цикл
для ы=1 по Результат.Колонки.Количество()-1 цикл
ТабДок.Область(й+1,ы).Текст=строка(Результат[й-1][ы-1]);
конеццикла;
конеццикла;
В Python все то же самое выглядит несколько более компактно:
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
iowa_file_path = '../input/iowa-house-prices/train.csv'
home_data = pd.read_csv(iowa_file_path)
feature_names = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']
X = home_data[feature_names]
y = home_data.SalePrice
iowa_model = DecisionTreeRegressor()
iowa_model.fit(X, y)
print(iowa_model.predict(X.head()))
print(y.head().tolist())
Но, на самом деле, особой разницы здесь нет. Мне просто лень было писать мало-мальски красивую визуализацию результатов. Я ограничился всего двумя строчками:
print(iowa_model.predict(X.head()))
print(y.head().tolist())
Не так уж и принципиально, сколько строк уходит на выделение 7 колонок. Если оставить саму суть, а именно подготовку модели и прогноз, то в 1С это выглядит так:
//подготовка
Анализ=новый АнализДанных;
Анализ.ТипАнализа=Тип("АнализДанныхДеревоРешений");
Анализ.ИсточникДанных=ТЗМодель;
Анализ.Параметры.ТипУпрощения.Значение=ТипУпрощенияДереваРешений.НеУпрощать;
РДерево=Анализ.Выполнить();
//прогноз
Прогноз=РДерево.СоздатьМодельПрогноза();
Прогноз.ИсточникДанных=ТЗПрогноз;
Результат=Прогноз.Выполнить();
А в Python так:
iowa_model = DecisionTreeRegressor()
iowa_model.fit(X, y)
print(iowa_model.predict(X.head()))
Ну да, компактнее, но самое интересное впереди.
Как отмечалось в прошлый раз, такой анализ полностью бесполезен, потому что модель подготавливается и проверяется на одних и тех же данных. Когда данные попадают в руки дата-сатанистасаентиста, он первым делом делит их на две части. В 1С мы делали это так:
МодельСтроки=новый массив;
ГСЧ=новый ГенераторСлучайныхЧисел(1969);
й=0;
пока й<цел(Макет.ВысотаТаблицы/2) цикл
сч=ГСЧ.СлучайноеЧисло(2,Макет.ВысотаТаблицы);
если МодельСтроки.Найти(сч)=неопределено тогда
МодельСтроки.Добавить(сч);
й=й+1;
конецесли;
конеццикла;
для й=2 по Макет.ВысотаТаблицы цикл
если МодельСтроки.Найти(й)=неопределено тогда
нстр=ТЗПрогноз.Добавить();
иначе
нстр=ТЗМодель.Добавить();
конецесли;
...
В Pyton это будет ровно одна строка
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 1)
Нет, вру. В случае если вы решили быть аккуратным и не грузить библиотеки целиком, то в начале надо будет загрузить соответствующий раздел библиотеки sklearn
from sklearn.model_selection import train_test_split
Для понимания того, насколько точен оказался наш прогноз, мы рассчитывали т.н. среднюю абсолютную ошибку, MAE, mean absolute error
СуммаОшибок=0;
для каждого стр из Результат цикл
СуммаОшибок=СуммаОшибок+макс(стр.Цена-стр.ЦенаПрогнозЗначение,стр.ЦенаПрогнозЗначение-стр.Цена);
конеццикла;
СредняяАбсолютнаяОшибка=СуммаОшибок/Результат.количество();
В Python это опять же одна строка кода и одна строка подключения раздела библиотеки
from sklearn.metrics import mean_absolute_error
...
val_mae = mean_absolute_error(val_y,val_predictions)
Полный листинг на Python будет выглядеть так:
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
iowa_file_path = '../input/iowa-house-prices/train.csv'
home_data = pd.read_csv(iowa_file_path)
feature_names = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']
X = home_data[feature_names]
y = home_data.SalePrice
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 1)
iowa_model = DecisionTreeRegressor(random_state = 1)
iowa_model.fit(train_X, train_y)
val_predictions = iowa_model.predict(val_X)
val_mae = mean_absolute_error(val_y,val_predictions)
print(val_mae)

Становится интереснее, но учтите, что это даже не верхушка айсберга, это снежинка на верхушке айсберга!
В прошлый раз нас не устроило качество предсказания и мы стали искать способы его улучшить. Напомню, что мы пытались найти наилучшее дерево путем перебора всевозможных значений количества листьев в одном узле. Мы не будем здесь воспроизводить это решение, потому что есть идеи получше. Вместо того, чтобы искать одно идеальное дерево, мы создадим целый лес деревьев решений и будем использовать для прогноза усредненное значение по всему лесу. Вы можете сами прикинуть, как это сделать в 1С, используя все тот же АнализДанных. Что бы мы ни понаписали в 1С, в Python это уложится, по сути, в одну строку:
rf_model = RandomForestRegressor(random_state = 1)
Полный листинг с загрузкой данных, разделением на части, подготовкой, прогнозированием и выводом результата выглядит так:
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
from sklearn.ensemble import RandomForestRegressor
iowa_file_path = '../input/iowa-house-prices/train.csv'
home_data = pd.read_csv(iowa_file_path)
feature_names = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']
X = home_data[feature_names]
y = home_data.SalePrice
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 1)
rf_model = RandomForestRegressor(random_state = 1)
rf_model.fit(train_X,train_y)
rf_val_mae = mean_absolute_error(val_y, rf_model.predict(val_X))
print(rf_val_mae)
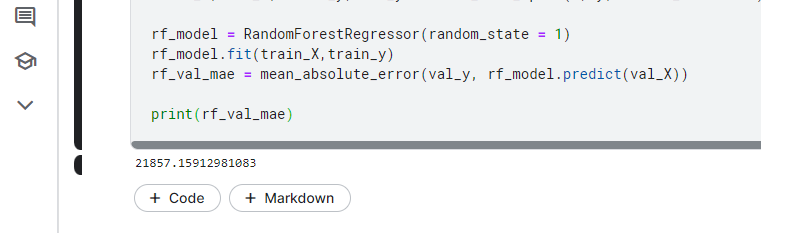
Но и это еще не все.
То, что я показывал до сих пор, считается учебным материалом. Эти методы слишком просты и не используются в реальной работе. То, что применяется на практике, намного более изощренно, хотя и основывается все на тех же деревьях и лесах деревьев. В конце прошлой статьи я обращал ваше внимание на то, что мы использовали 7 колонок для предсказания, но в исходных данных у нас их вообще-то 80. И тут есть над чем поработать. Один из актуальных алгоритмов работает следующим образом. Берутся все колонки (тут есть один нюанс, но о нем позже). Строится лес деревьев. Вычисляется отклонение. Затем по определенному принципу меняется "вес" той или иной колонки, снова строится лес деревьев и процесс повторяется. Точность прогноза увеличивается шаг за шагом. В DS это называется "бустинг". Сначала появился т.н. градиентный бустинг (или градиентный спуск), а потом XGBoost. Последняя библиотека (XGBoost) в настоящее время считается рабочим инструментом специалиста DS. Внутри у нее серьезная математика: ряды Тейлора, метод Ньютона-Рафсона. В библиотеке, как водится, больше 10 тысяч строк кода (можете сами заглянуть на Git, библиотека, разумеется, открыта). И если простой лес деревьев все еще можно было бы написать на 1С. То в случае с XGBoost это было бы нелепо. Для программиста на Python, как вы уже наверное догадались, все снова сводится к одной строке
my_model = XGBRegressor(random_state=0)
В полном виде работающий код для нашего набора данных будет выглядеть так:
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
X = pd.read_csv('../input/iowa-house-prices/train.csv', index_col='Id')
X_test_full = pd.read_csv('../input/iowa-house-prices/test.csv', index_col='Id')
X.dropna(axis=0, subset=['SalePrice'], inplace=True)
y = X.SalePrice
X.drop(['SalePrice'], axis=1, inplace=True)
X_train_full, X_valid_full, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2,
random_state=0)
low_cardinality_cols = [cname for cname in X_train_full.columns if X_train_full[cname].nunique() < 10 and
X_train_full[cname].dtype == "object"]
numeric_cols = [cname for cname in X_train_full.columns if X_train_full[cname].dtype in ['int64', 'float64']]
my_cols = low_cardinality_cols + numeric_cols
X_train = X_train_full[my_cols].copy()
X_valid = X_valid_full[my_cols].copy()
X_test = X_test_full[my_cols].copy()
X_train = pd.get_dummies(X_train)
X_valid = pd.get_dummies(X_valid)
X_test = pd.get_dummies(X_test)
X_train, X_valid = X_train.align(X_valid, join='left', axis=1)
X_train, X_test = X_train.align(X_test, join='left', axis=1)
my_model = XGBRegressor(random_state=0)
my_model.fit(X_train,y_train)
predictions = my_model.predict(X_valid)
mae = mean_absolute_error(predictions, y_valid)
print(mae)
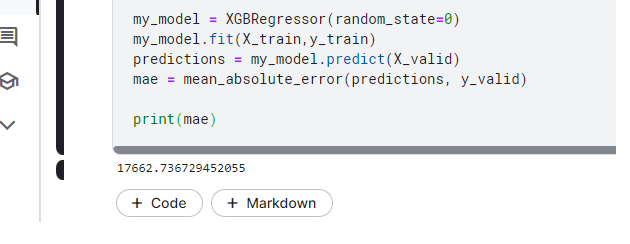
Смысл всего, что стоит выше обращения к XGBRegressor, заключается в следующем. Отбираются чисто числовые колонки. К ним добавляются колонки, которые можно превратить в числовые без ущерба для качества прогноза, такие колонки превращаются таки в числовые. Ну и заодно убираются строки, в которых не задана цена. Как видите, все сводится к предварительной подготовке. Если ваши данные уже находятся в правильном виде, ничего этого делать не надо. Я привел вам листинг в таком виде, чтобы вы могли поэкспериментировать и со своими данными.
Что мы имеем в итоге. Несмотря на то, что в 1С есть такой объект, как АнализДанных, пользоваться им не получится. Сейчас DS одна из самых динамичных областей в ИТ. Тут все развивается достаточно быстро и надо признать, что 1Совский АнализДанных не поспевает за ходом событий. Поэтому, если вы решили заняться DS, то вам придется освоить Python. В этой ситуации есть свои плюсы. Как по мне, так Python один из лучших языков для 1С-ника. Он достаточно прост и он дает максимум возможностей в той сфере, что, на мой взгляд, наиболее близка к 1С. Все 1С-ники так или иначе работают с данными. В сущности, если вдуматься, средний 1С-ник это практически готовый data engineer. Попробовать сделать шаг от data engineer к data scientist выглядит разумно. Задачи, которые вы будете решать в процессе обучения будут выглядеть знакомо. Данные для экспериментов у вас всегда найдутся. Так что, всем рекомендую. А я со своей стороны постараюсь находить время, чтобы делиться с вами интересными моментами на этом пути.
Вступайте в нашу телеграмм-группу Инфостарт