Хочу рассказать, как нам удалось сократить время доставки наших изменений в продакшен и как это улучшило наши процессы. Надеюсь, статья будет интересна тем коллегам, которые присматриваются к автоматизации, и тем, кто хочет осуществить fine-tuning своего CI.
Рассмотрим преимущество автоматизации перед ручным деплоем: я покажу наш стек инструментов, стратегии оптимизации CI-CD пайплайнов, узкие места и как их преодолеть.
Причины сопротивления автоматизации
Почему команды боятся автоматизации? В нашей компании есть обязательные требования по деплою приложения через пайплайн, но когда мы запускали этот процесс, был переходный период, в котором мы позволяли командам 1С пользоваться своими старыми автоматизациями или иным подходом. Команды оттягивали процесс перехода на общий CI.
И вот в чем была их мотивация:
-
Привычка к ручному деплою. Несмотря на то, что наш пайплайн обеспечивал развертывание на несколько баз, автотесты и откат, разработчики говорили, что им руками привычнее, быстрее, отсутствует бюрократия.
-
Неверная оценка времени. Они не учитывали, что ручной деплой с развертыванием на N баз в разных окружениях, тестами и проверками занимает больше времени. Можно зайти в конфигуратор в продакшене и что-то подправить без тестов, но тогда есть риск, что вы будете заниматься другой доставкой.
-
Страх сложности. Любые изменения требуют адаптации.
Мы поняли, что, для того чтобы убедить команды, нужно не только требовать, но и улучшать инструменты. Поэтому мы оптимизировали свой CI, чтобы приблизиться к ручному деплою по скорости и превзойти его по надежности.
Текущая конфигурация и базовые метрики

На этом изображении пример одной из наших конфигураций. Время деплоя коррелирует с размером метаданных конфигураций, поэтому здесь я привожу наши цифры, чтобы вы понимали контекст временных метрик, которые я буду далее озвучивать.
У нас порядка 300 справочников, 400 документов, 500 регистров сведений и размер CF-файла 950 мегабайт.

На этом изображении видно, что время деплоя нашей основной конфигурации до оптимизации, если опустить тесты, составляло более полутора часов, а после оптимизации мы смогли уложиться в плюс-минус 30 минут.

Для расширения это время после оптимизации стало еще меньше: мы стали выкатываться менее чем за 15 минут. В случае расширений временные показатели для нас особенно важны, потому что мы используем их для исправлений в продакшене и хотфиксов, где счет идет на минуты.
Используемый технологический стек
Расскажу о стеке, который мы используем, чтобы вы понимали контекст оптимизации и причины упоминания того или иного инструмента.

У нас есть EDT, конфигуратор, GitLab как средство автоматизации развертывания, GitSync для синхронизации хранилища, OneScript для скриптовой автоматизации и Docker под управлением Kubernetes с операционной системой Ubuntu.
Общие стратегии оптимизации CI/CD
Какие могут быть стратегии оптимизации пайплайнов?

Можно использовать инструменты от вендора: например автономный сервер вместо пакетного конфигуратора. Можно использовать различные стратегии управления репозиториями git на раннерах и механизм кеша и артефактов GitLab. Еще можно смотреть с сторону оптимизации работы с докер образами, минимизируя их размер.
Архитектура и базовые элементы GitLab CI
Теперь рассмотрим концепт GitLab.
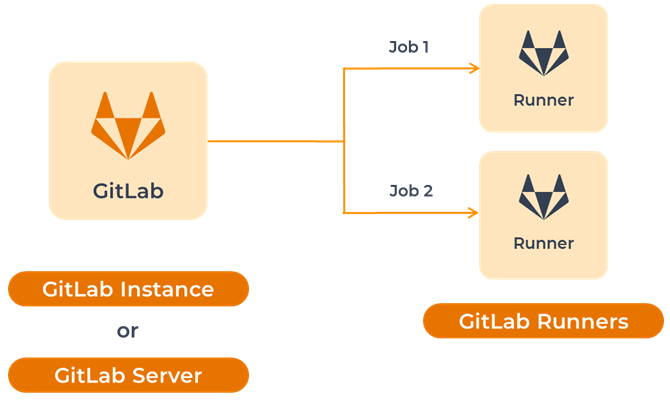
У него есть три основных элемента:
-
GitLab-сервер или инстанс GitLab,
-
GitLab YAML, в котором перечислено, что и в какой момент выполнять: когда сборка, когда деплой, когда тесты,
-
GitLab Runners – они устанавливаются как службы на локальной машине и выполняют инструкции, перечисленные в YAML-файле.
Что в этой схеме неэффективно по умолчанию? Перед тем, как выполнять инструкции из YAML, GitLab-раннер полностью выкачивает репозиторий, и только после этого приступает к выполнению скриптов.
Настройка стратегий клонирования и глубины репозитория

В GitLab есть настройки, которые позволяют переопределить это поведение. Первая настройка – это Git Strategy. Она может принимать значения clone, fetch, none, empty.
-
Clone – самый медленный вариант. Он полностью клонирует репозиторий перед выполнением задания. Если на раннере существует рабочее дерево, оно будет удалено.
-
Вторая стратегия – fetch. Она работает быстрее, переиспользует существующий репозиторий и обновляет его командой git fetch. Если репозиторий отсутствует, выполняется полный клон.
-
Стратегия none удобна в случаях, когда репозиторий не нужен и работа идет только с кэшем и артефактами.
-
Последняя стратегия – empty. Она отличается от none тем, что перед выкачиванием кэша и артефактов полностью удаляет существующий каталог сборки и только после этого приступает к загрузке кэша и артефактов.
Вторая переменная – GIT_DEPTH. Она управляет глубиной и количеством выкачиваемых версий репозитория. Если указать значение GIT_DEPTH=1, мы получим последнюю актуальную версию репозитория. Управлять этой переменной важно для больших репозиториев: она позволяет существенно сократить объем и количество выкачиваемой информации.
Механизмы кэширования в GitLab
Следующий механизм – кэширование и артефакты. Зачем нужен кэш в GitLab? Каждый раз, когда выполняется задание, ему могут потребоваться данные и зависимости, которые уже были собраны на предыдущем этапе. Нет смысла выкачивать и собирать их заново. Их можно передавать между джобами и пайплайнами и таким образом экономить время.

Например, в контексте 1С, если на этапе compile мы собрали cf-файл, нет смысла собирать его заново на этапе обновления базы. Кэш позволяет оптимизировать пайплайн благодаря использованию уже подготовленных данных.
У кэша есть три основных свойства:
-
Key – уникальный идентификатор кэша,
-
Path – список файлов и папок, которые нужно кэшировать,
-
Policy – политика кэширования.
Каждый файл кэша хранится под именем ключа. В примере ключом является имя джобы, что означает, что кэш будет храниться в разрезе джобы, и джобы с одинаковым названием смогут его переиспользовать.

Кэш может быть двух видов: локальный и распределенный. Это настраивается на раннерах. При локальном кэше файлы хранятся на хосте, где запущен раннер. При распределенном кэше файлы хранятся во внешнем хранилище, например в S3.
Перед выполнением задания архив кэша выкачивается из хранилища, разархивируется, затем выполняется джоба, после чего обновленный кэш архивируется обратно и отправляется во внешнее хранилище.
При этом полностью файл выкачивается, а не его изменения. Поэтому следует избегать хранения больших файлов в кэше.

Поведением кеша Gitlab можно управлять с помощью политик кеширования, которые могут принимать следующие значения:
-
pull and push – по умолчанию: полное выкачивание кэша перед выполнением задания, затем загрузка обновленного кэша после выполнения.
-
push – сохраняется только обновленный кэш после выполнения задания.
-
pull – выкачивается только кэш перед выполнением, обновленный кэш не сохраняется.
Есть параметр CACHE_COMPRESSION_LEVEL, который позволяет указать уровень сжатия кэша. Чем выше уровень, тем сильнее сжатие и тем медленнее разархивирование.
Артефакты и управление ими

Следующий механизм – артефакты. Они также позволяют передавать файлы и папки между джобами. Их отличительная особенность состоит в том, что они передают файлы между джобами одного пайплайна, тогда как кэш позволяет передавать данные между разными пайплайнами, но наличие кэша не гарантируется.
По умолчанию перед выполнением джобы будут выкачаны все артефакты, созданные в этом же пайплайне на предыдущих этапах. Например, если на этапе compile собирается cf-файл и в этом же пайплайне есть джоба тестов, джоба тестов выкачает себе собранный cf-файл и потратит время, хотя на этапе тестов этот файл не нужен.
Чтобы решить эту проблему, есть ключевые слова needs:artifact и dependencies. Они позволяют указать, какие конкретно файлы и из каких джоб нужно выкачивать (или отказаться от выкачивания артефактов полностью). В примере, где для dependencies указан пустой массив, артефакты выкачаны не будут.
Эти настройки выглядят простыми, но достаточно часто встречаются YAML-файлы на десятки джоб, в которых ни одна из этих настроек не используется. В результате применяются настройки по умолчанию или настройки проекта. Это неэффективно для многих случаев. Поэтому пользуйтесь этими настройками, особенно если вы используете Docker раннеры и распределенный кеш.
Анализ неоптимизированного пайплайна

На этом изображении разбор нашего пайплайна до оптимизации и временные отметки для каждого этапа.
Первый этап – синхронизация хранилища и Git. До оптимизации время выполнения составляло примерно 30 минут. Мы использовали для синхронизации расписание GitLab, которое запускалось раз в 5–10 минут, что вносило дополнительные задержки и провоцировало холостые запуски.
Затем идет этап Compile. Для Compile мы использовали пакетный режим конфигуратора, и время сборки составляло порядка 40 минут.
После этого выполнялось обновление STG, время которого составляло около 17 минут при отсутствии реструктуризации.
Далее шли тесты. Тесты выполняются долго, время прогона зависит от количества тестов. В нашем случае минимум час.
Заключительный этап – обновление PROD, время выполнения которого составляло около 17 минут.
Итого полный цикл пайплайна без учета тестов занимал более полутора часов. В случае основной конфигурации эти этапы были разнесены по времени: к моменту начала работы хранилище уже было синхронизировано, тесты выполнялись ночью, но даже с учетом разнесения процесс оставался достаточно долгим.
Оптимизация синхронизации хранилища и Git
Посмотрим, как можно оптимизировать эти этапы. Начнем с синхронизации хранилища и Git. Мы отказались от синхронизации по расписанию и перешли на событийную модель. Для такого подхода существует несколько инструментов: например, TCP-прокси https://github.com/infina15/oproxy.
Такой подход помимо ускорения позволяет организовать дополнительные проверки при помещении в хранилище: проверять статус тикета, соответствие комментариев к помещению в хранилище требованиям компании.
Дополнительный буст дал перенос этой джобы в Docker. Мы сократили время синхронизации до 5–10 минут. Раньше эта операция выполнялась 30 минут. Положительным фактором является то, что мы используем монтирование каталога сборки в оперативную память для Docker контейнеров, и это существенно влияет на скорость выгрузки конфигурации в файлы.
Альтернативный вариант событийной модели работы с хранилищем – WEB-хук https://github.com/asosnoviy/commitHook, который отправляет запрос на указанный сервер при помещении в хранилище.
Оптимизация этапа Compile

Следующий этап – Compile. Здесь мы отказались от пакетного режима конфигуратора и стали использовать автономный сервер. Автономный сервер работает в разы быстрее. Полная сборка полной конфигурации стала занимать около 5–6 минут, тогда как раньше эта операция занимала 40 минут.

Второй шаг оптимизации для джобы Compile – использование стратегии GIT_DEPTH=1. Нам нужна только последняя актуальная версия репозитория, чтобы собрать cf-файл, и это сократило объем выкачиваемой информации.

Джоба Compile собирает cf-файл и передает его в следующие этапы с помощью кэша.
Задача – собрать cf-файл и положить его в кэш. При этом предыдущее значение cf-файла нам не нужно, поэтому мы применяем политику push и только кладем данные в кэш.
Еще одна стратегия оптимизации для джобы Compile – запараллеливание ее со вспомогательными джобами. На этом изображении приведен пример релизного пайплайна, где видно, что раньше был этап build. Мы отказались от него, запараллелили джобу Compile со вспомогательными джобами, и это вместе с использованием автономного сервера позволило нам получать готовый cf-файл к моменту завершения выполнения вспомогательных джоб.
Оптимизация этапа обновления STG

Следующий этап – обновление STG-контура. Здесь мы применили стратегию GIT_STRATEGY=none, потому что на этом этапе репозиторий нам не нужен. Нам нужен только cf-файл из артефактов и скрипты для обновления базы. Скрипты мы выкачиваем точечно с помощью REST API GitLab, а cf-файл получаем из артефактов.
После этого мы посмотрели на другие джобы, где репозиторий также не нужен, применили аналогичную стратегию и сократили около двух минут на каждой такой джобе.
Также для обновления мы используем оптимизированный механизм обновления v2. Мы начали использовать его практически сразу. Недавно от коллег узнал, что даже в крупных компаниях он внедрен не везде. У нас он используется давно, на разных конфигурациях проблем не было.

Это фрагмент джобы staging, и здесь видно, что применена стратегия GIT_STRATEGY=none.
Оптимизация тестов

Затем идут тесты. Для тестов можно применять несколько стратегий оптимизации:
-
Распараллеливание выполнения тестов на несколько баз с разными настройками.
-
Оптимизация кода тестов. Мы используем vanessa-add для дымового тестирования обычных форм и тесты, которые идут с ней из коробки. В нашем случае только построение дерева тестов занимало около получаса. Мы оптимизировали этот шаг, перевели его в многопоточность, и построение дерева стало занимать несколько минут.
-
Правильное управление артефактами. Я уже упоминал, что по умолчанию джобы выкачивают все артефакты, созданные на предыдущих этапах. Если не управлять этим, джоба тестов будет получать артефакт и тратить на это время, хотя для выполнения тестов артефакты не нужны.
-
Настройка для быстрых тестов.
В контексте оптимизации тестов важно рассмотреть работу с Hotfix. Для Hotfix мы используем расширения: они быстро собираются и быстро обновляются. Но затем все упирается в джобу тестов, которая может выполняться несколько часов. Здесь два варианта развития событий: либо не тестировать изменения, выкатываемые по Hotfix, либо выполнять отдельные быстрые тесты для Hotfix.
Мы выбрали второй вариант и разработали на фреймворке YAxUnit несколько быстрых юнит-тестов. Дополнительно мы сделали один тест, который компилирует все модули расширения и выполняет таким образом синтаксическую проверку этих модулей. Такой подход позволил получить быструю экспресс-проверку изменений перед выкаткой в продакшен.
Проблемы и решения при переходе на Docker
Теперь расскажу про Docker и сложности, с которыми мы столкнулись при переводе джоб в Docker. Основная сложность заключалась в том, что время выполнения сравнения и объединения конфигурации после переноса в Docker стало почти в два раза выше, чем на Windows-раннерах. Это стало блокером для большинства команд. Нам пришлось приостановить переход и разобраться с причинами.

Мы настроили технологический журнал. На изображении пример настройки: мы отбираем все события без детализации. Аналогичную настройку сделали на Windows-раннере, проанализировали логи и выявили, что в Docker мы теряем платформенный кэш. Окружение в Docker создается заново, временные файлы не сохраняются, и платформенного кэша нет.

Как решили проблему: помог кэш GitLab. На изображении показано, что мы в файле location указываем папку для хранения временных файлов платформы и говорим GitLab, что эту папку необходимо кэшировать. В качестве ключа используем строку подключения к базе данных, чтобы каждая база имела собственный кэш. Такой подход позволил нам получить время выполнения сравнения и объединения, сопоставимое с Windows-раннерами.

Вторая проблема – потеря файла ConfigDumpInfo.xml. Платформа использует его для инкрементной выгрузки конфигурации. Он нужен GitSync, чтобы определять тип выгрузки: полную или инкрементную. Причина та же: окружение пересоздается, файлы с прошлого запуска не сохраняются.
Мы также решили это с помощью кэша: указали GitLab, что ConfigDumpInfo необходимо кэшировать. Такой подход исключает потерю файла, и он доступен при следующей итерации синхронизации.

Следующая проблема – резкое замедление определенных тестов, в данном случае тестов открытия управляемых форм. На изображении видно: на Windows-раннере набор тестов выполняется за 400 миллисекунд, а в Docker – за 3000 миллисекунд. Мы настроили технологический журнал и обнаружили, что на Windows-раннере из-за особенностей запуска раннера тесты фактически не выполнялись. Поэтому разница во времени объясняется тем, что в Docker тесты действительно выполняются.
Оптимизировать этот аспект не удалось, но мы выявили, что часть тестов у нас не работала.


Можно использовать кэш, и на изображении видно, что использование кэша для этих типов тестов дает прирост порядка 20%. Но если между запусками тестов изменяется конфигурация, возможны ошибки и побочные эффекты. Поэтому мы пока не применяем такой механизм.
Итоговый чеклист оптимизации

Подведем краткий чеклист оптимизации.
-
Используйте автономный сервер вместо пакетного режима конфигуратора.
-
Применяйте стратегию git_depth=1 там, где не нужно выкачивать большое количество версий репозитория.
-
Применяйте стратегию git_strategy = none для джоб, которые используют только кэш и артефакты.
-
Запараллеливайте этапы там, где это возможно.
-
Используйте многопоточные тесты.
-
Используйте быстрые тесты для проверки Hotfix.
-
Можно создать отдельные репозитории для скриптов, чтобы не выкачивать полностью основной репозиторий там, где это не требуется.
-
Помните про платформенный кэш и учитывайте, что скорость деплоя зависит от ресурсов раннера. Следите за джобами, между которыми эти ресурсы разделяются.
Итоговые результаты оптимизации

-
После оптимизации нам удалось сократить время синхронизации до 5 минут. Раньше эта операция занимала 30 минут.
-
Сборка стала занимать около 5–6 минут вместо 40 минут ранее.
-
Обновление стало выполняться за 11 минут.
-
Вспомогательные шаги в общем тайминге стали занимать 0 минут, потому что мы запараллелили их со сборкой.
-
Итоговый результат: выкатка основной конфигурации занимает плюс-минус 30 минут, а выкатка расширения – менее 20 минут.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт