Когда проблема уже мешает
Я регулярно сталкиваюсь с ситуацией, когда от бизнес-пользователей поступают сообщения следующего характера:
«Добрый день! С пятницы начались проблемы при проведении документов ПТУ и списания безналичных. Прошу принять меры».
И когда такие сообщения приходят, это уже, как правило, та точка, когда терпеть дальше невозможно. И бизнес, и IT-отдел понимают: с этим нужно что-то делать.
Чтобы стабилизировать ситуацию и оптимизировать систему 1С, мы используем довольно простой рецепт из трех шагов: аудит, оптимизация и контроль.
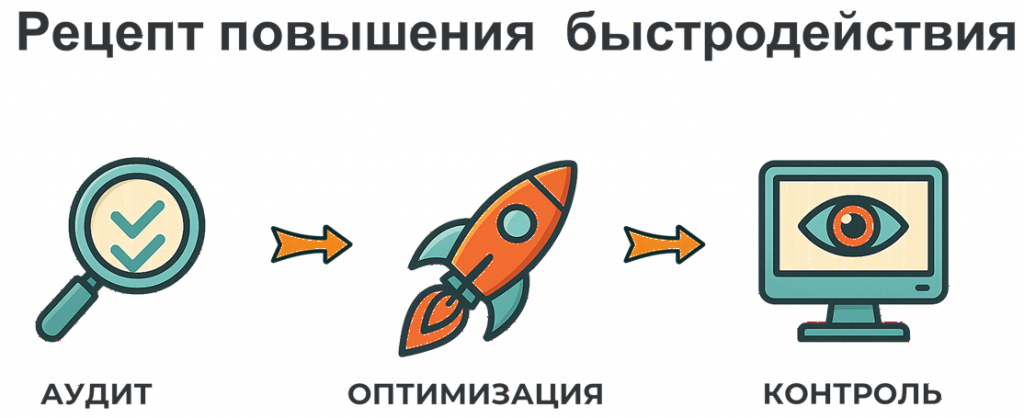
Самый важный этап здесь – аудит. Именно на этом этапе мы локализуем проблему, находим причину и дальше уже переходим к оптимизации, затем к контролю.
Этап 1. Аудит
От экспресс-диагностики к полноценному мониторингу
Когда пользователи обращаются с проблемой, критическая точка обычно уже пройдена: действовать нужно сразу. В этот момент нет времени на долгую настройку сложной системы мониторинга.
Поэтому на первом этапе мы используем простые базовые инструменты: встроенные возможности операционной системы и самой 1С. Это позволяет быстро собрать первичную картину без внедрения на серверах сторонних решений, требующих длительной настройки.
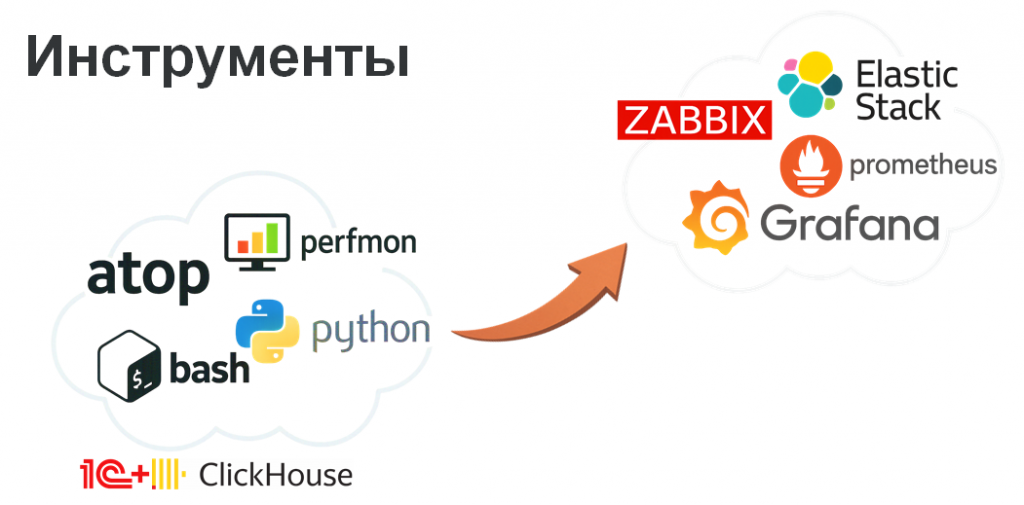
При этом важно понимать: такой этап нужен именно для быстрого анализа и стабилизации. Позже мы все равно переходим к полноценному стеку мониторинга: Grafana, ELK, Prometheus и Zabbix. Этот подход не отменяет, а дополняет экспресс-аудит.
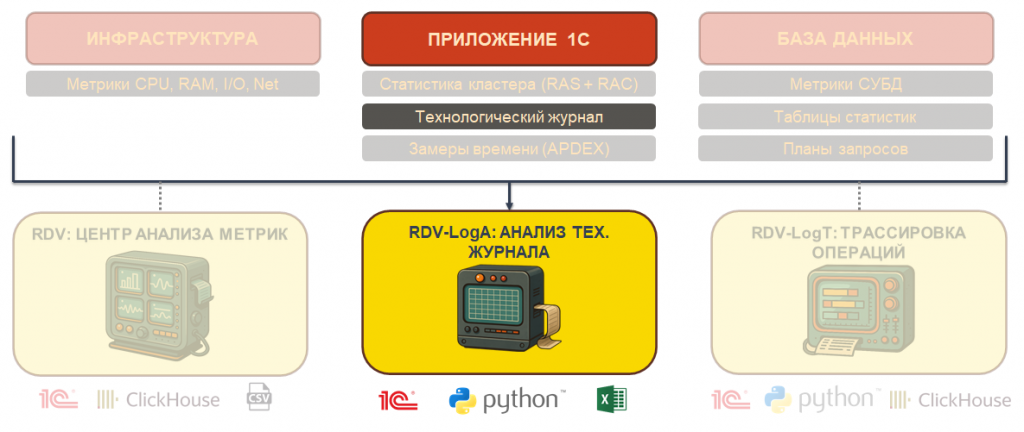
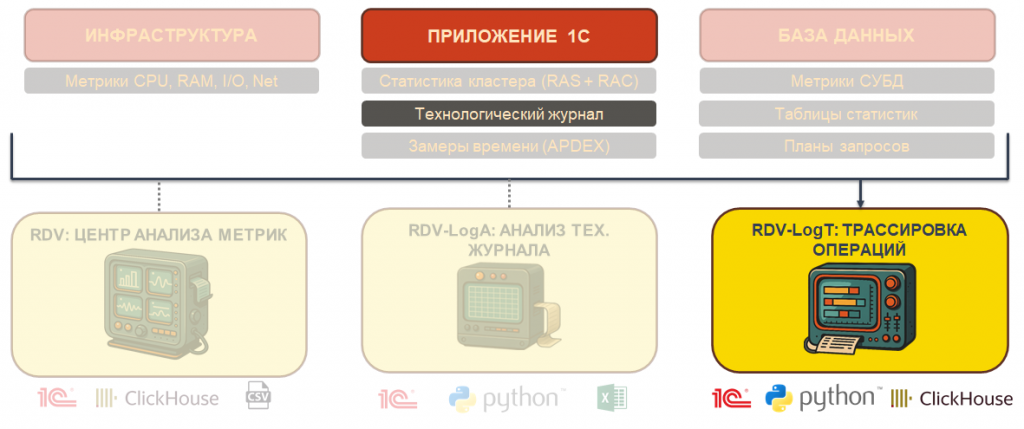
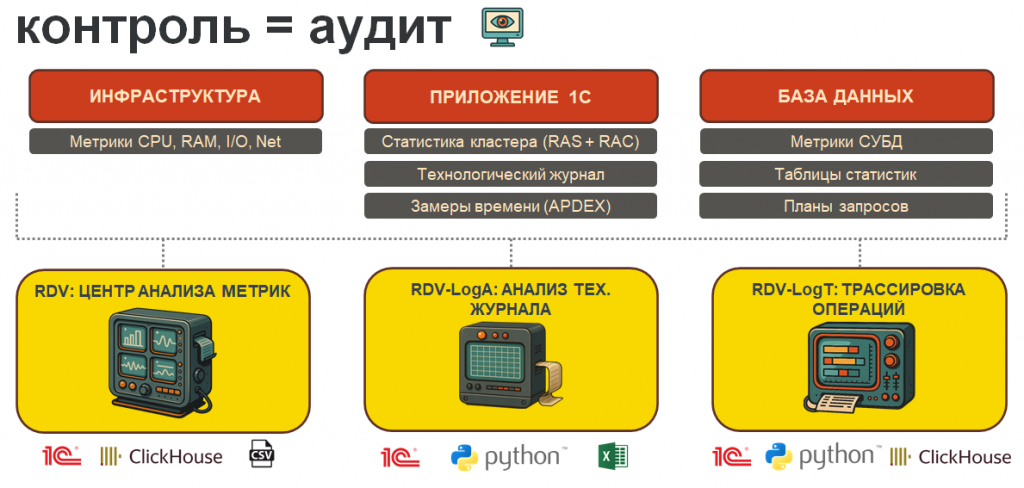
Три слоя IT-ландшафта для сбора метрик
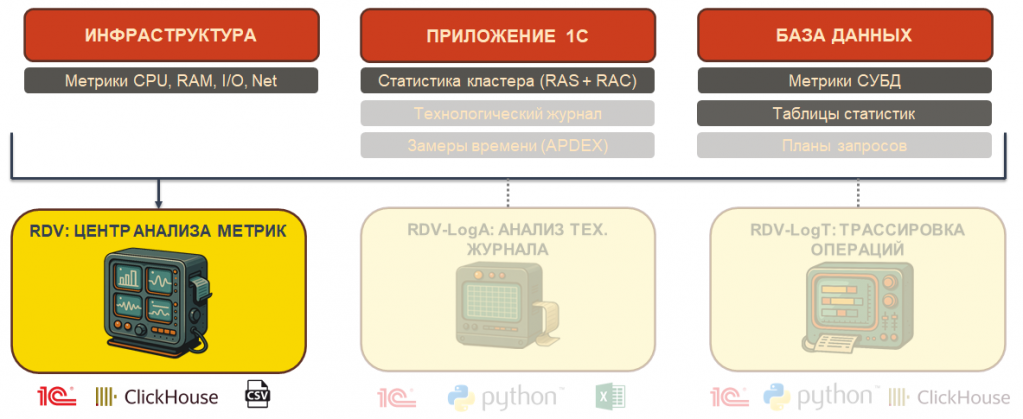
На этапе аудита мы выделяем в IT-ландшафте три слоя: инфраструктура, приложение 1С и база данных.
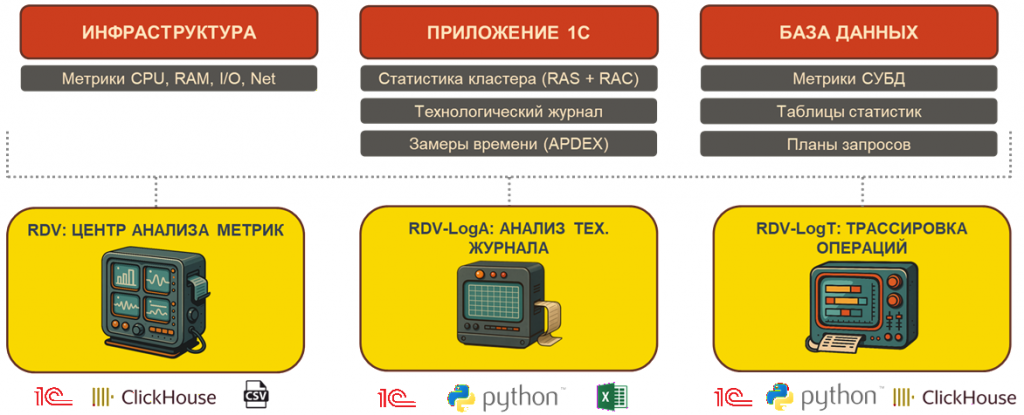
На каждом слое собираем свой набор метрик:
-
Инфраструктура – загрузка оборудования: процессор, память, скорость чтения и записи диска, сетевая активность и так далее.
-
Приложение 1С – технологический журнал, замеры времени (APDEX), статистика кластера через утилиту RAC и сервер администрирования RAS.
-
База данных – метрики СУБД: например, pg_stat в PostgreSQL или PerfMon, если MS SQL Server. При необходимости анализируем планы запросов, если нужно переходить к оптимизации.
Три инструмента для анализа метрик
Собрать метрики недостаточно – их еще нужно анализировать. Для этого мы разработали три инструмента, которыми чаще всего пользуемся. Далее разберу каждый из них.
Инструмент №1. RDV. Центр анализа метрик
На иллюстрации ниже показан инструмент для визуализации метрик.
По сути, это связка 1С и ClickHouse, куда сначала загружаются данные.
Схема работы выглядит так:
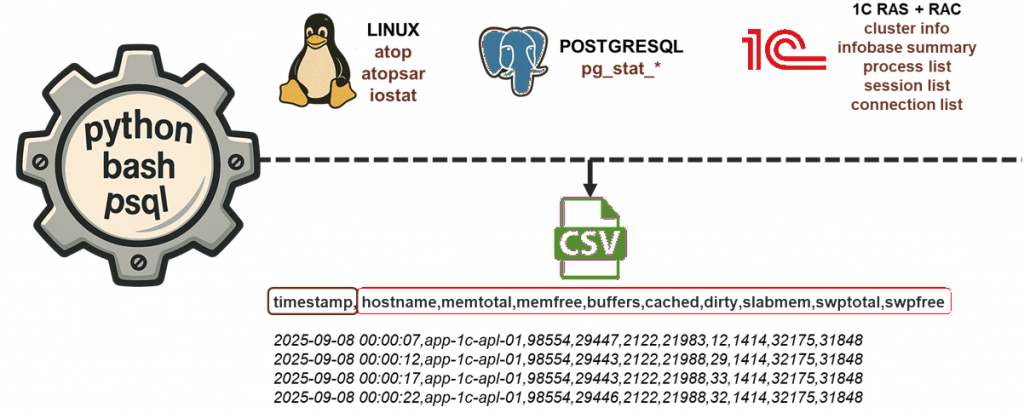
Собираем данные из разных источников. С помощью простых инструментов на Python и Bash приводим их к единому формату – стандартному CSV. В CSV сохраняем временную метку, имя хоста, счетчики и их значения.
По заранее настроенным правилам загружаем этот файл в информационную базу 1С через специальную обработку.
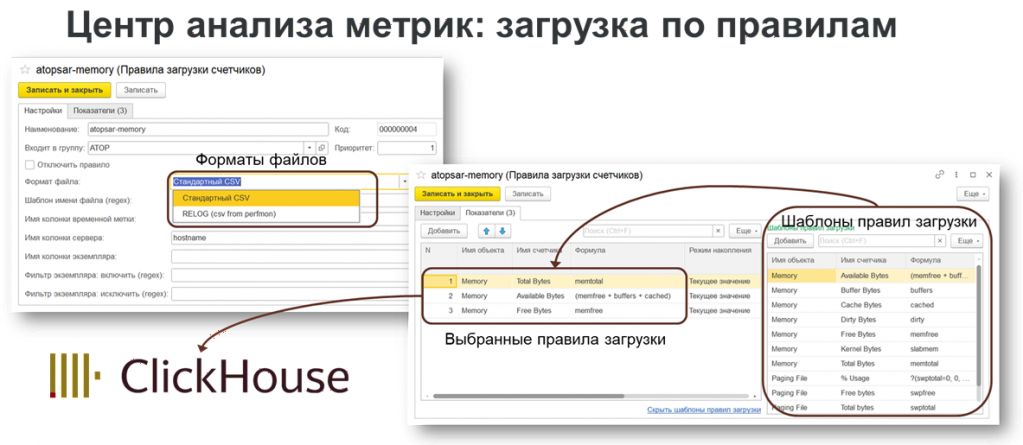
Механизмы обработки преобразовывают и нормализуют данные из файлов, после чего экспортируют их в ClickHouse, где уже хранятся значения счетчиков.
В информационной базе 1С храним только метаданные: имена счетчиков, серверов и так далее.
По готовым правилам и шаблонам строим графики и визуализацию метрик, чтобы оценить работу системы.
Преимущество в том, что мы имеем заранее подготовленные шаблоны как загрузки данных, так и визуализации данных. Три простых шага для начала анализа:
-
загрузили данные,
-
выбрали шаблоны анализа метрик,
-
нажали «Сформировать» и получили графики.
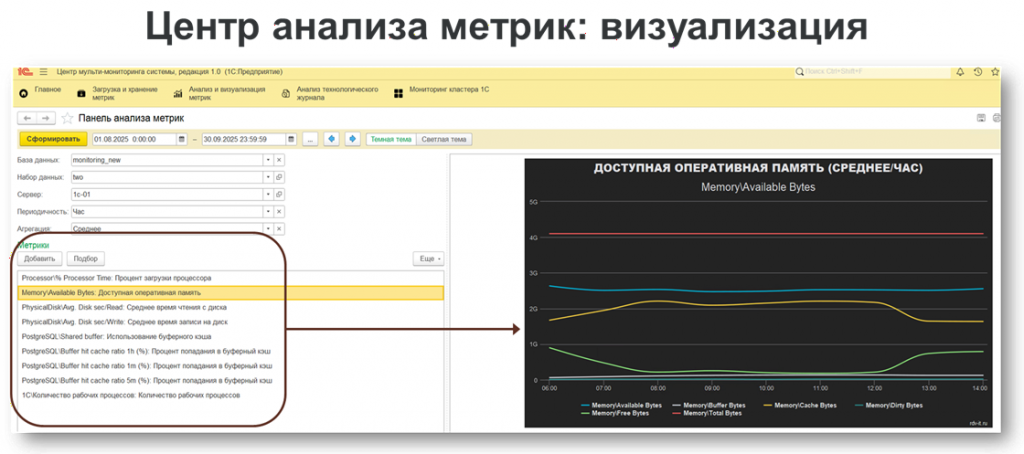
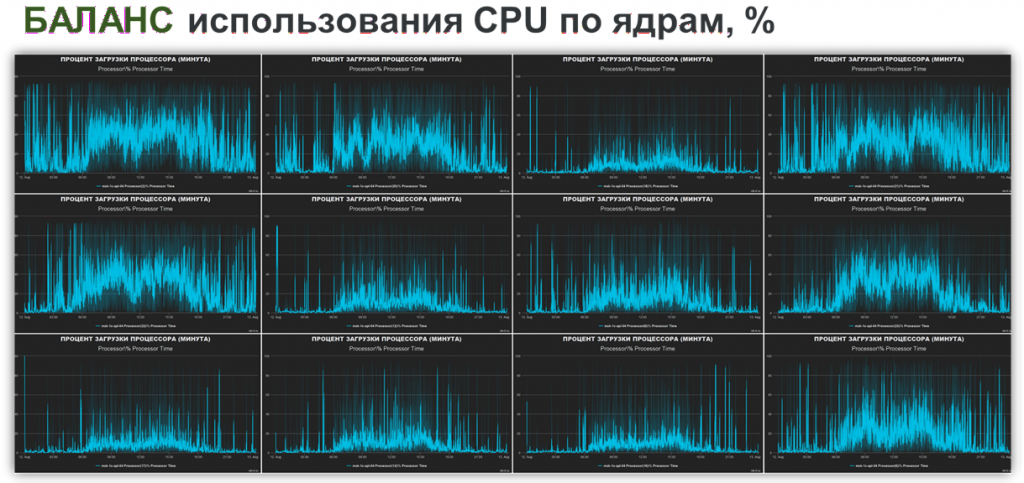
Пример. Мы сделали визуализацию загрузки CPU. Видно, что 12 ядер процессора загружены неравномерно.
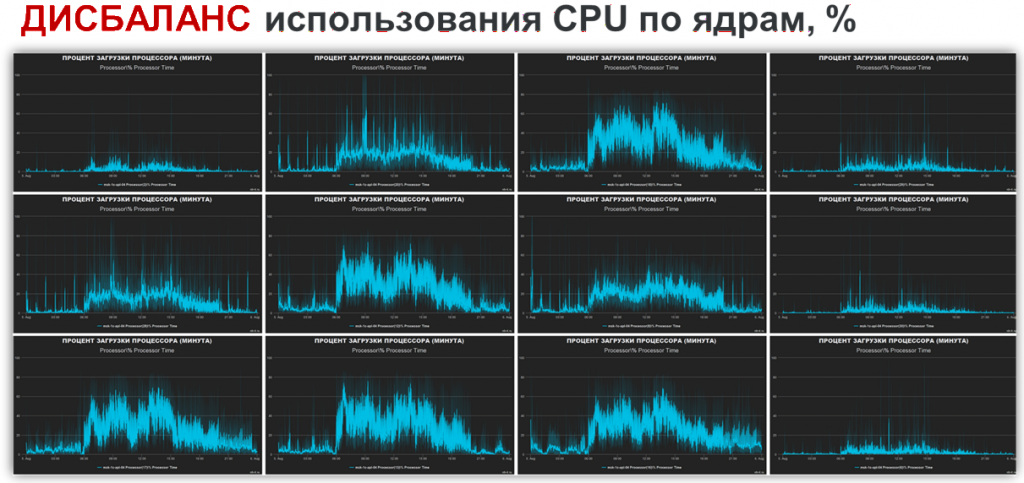
Это была виртуализированная среда с настройкой: шесть сокетов по два ядра на сокет. Вывод команды lscpu показал:
-
Core(s) per socket: 2
-
Socket(s): 6
В итоге каждый рабочий процесс выполнялся в пределах одного сокета и использовал только два ядра. Получалось, что при трех рабочих процессах были задействованы лишь шесть ядер.
Мы увидели это на графике, нашли причину и изменили настройку: сделали один сокет с двенадцатью ядрами, что соответствовало реальной физической архитектуре хоста. Вывод команды lscpu показал:
-
Core(s) per socket: 12
-
Socket(s): 1
После этого система начала работать иначе: загрузка стала равномерной, APDEX вырос, увеличилось и количество транзакций в секунду.
Инструмент №2: RDV-LogA. Анализ технологического журнала за длительный период
Второй инструмент, как и следующий, работает с технологическим журналом. Его задача – агрегировать данные за длительный период: за месяц, за полугодие и так далее. Например, он помогает получить топ запросов по контексту, топ серверных вызовов или топ по потреблению памяти.
https://github.com/rdv-team/loga
Это тоже обработка 1С. При ее разработке мы закладывали два ключевых требования: бережное потребление ресурсов и возможность работать с большими объемами данных. Технологический журнал может занимать сотни гигабайт, поэтому обработка умеет работать многопоточно, а количество потоков мы регулируем вручную, чтобы не перегружать сервер.
При этом она минимально использует оперативную память. Один из недавних кейсов – анализ 130 ГБ технологического журнала на ноутбуке, где было около 5 ГБ свободной памяти. Этого оказалось достаточно для работы.
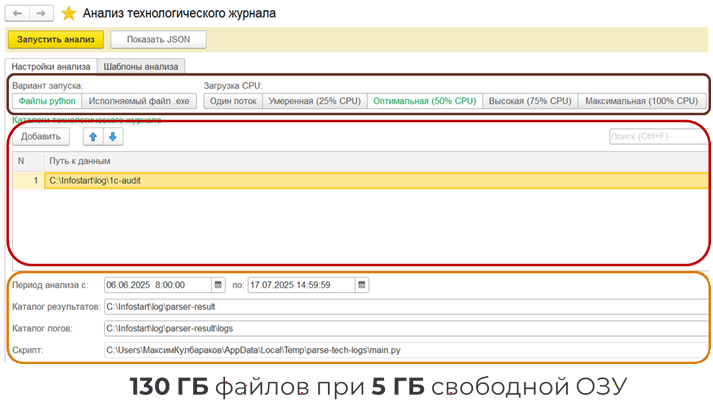
Второй важный момент – предопределенные шаблоны анализа. Мы заранее настраиваем аналитику: как именно хотим разбирать журнал. Дальше остается указать путь к технологическому журналу, выбрать шаблон, нажать «Запустить» и получить результат в виде Excel-таблиц.
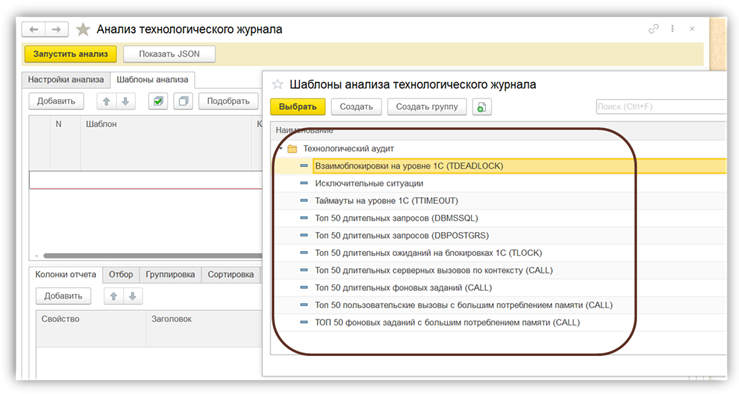
Шаблон анализа задает:
-
какое событие мы анализируем;
-
какие свойства из него берем;
-
какие группировки выполняем;
-
как сортируем результат.
Дополнительно рассчитываем аналитику: среднее, сумму, общую длительность, медиану, перцентили, стандартное отклонение, минимумы и максимумы.
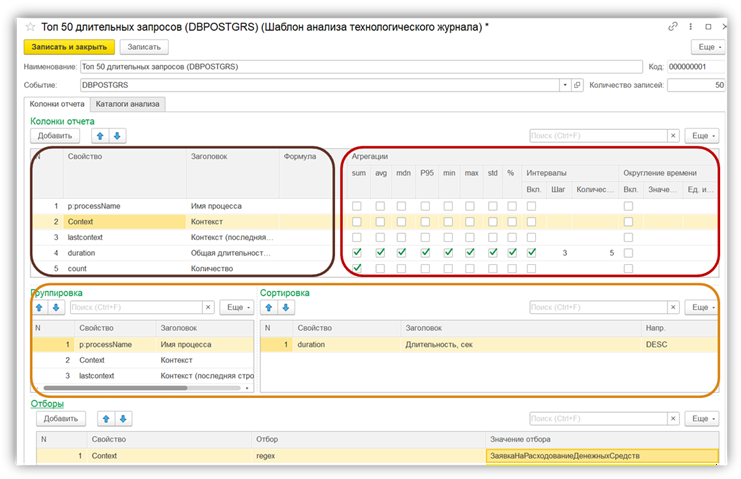
Это нужно, чтобы приоритизировать проблемные операции и выстроить их в таком порядке, где оптимизация даст максимальный эффект для стабильности системы.
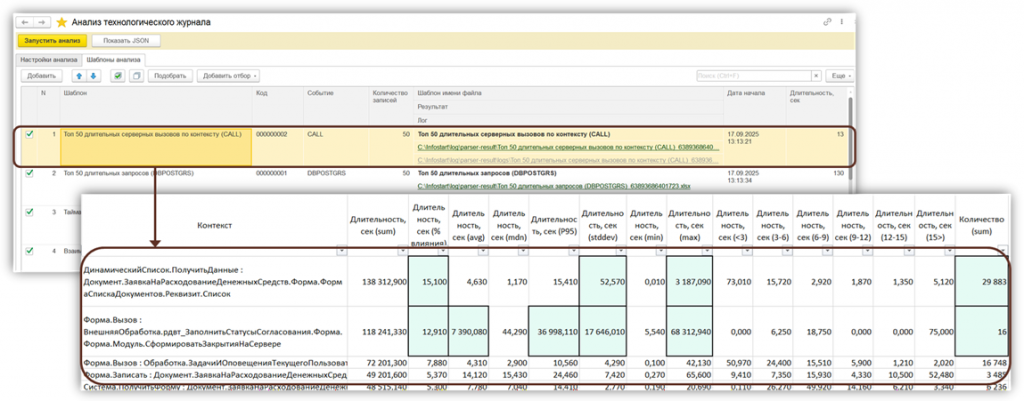
Пример работы инструмента. Мы запускаем готовые шаблоны и получаем Excel-таблицу. Сразу смотрим на ключевые метрики: например, процент длительности показывает, насколько конкретный контекст влияет на общую длительность всех операций за период. Отдельно смотрим на минимумы и максимумы: если максимумы высокие, это тоже повод для анализа. По таким триггерам определяем проблемные операции.
Инструмент №3: RDV-LogT. Трассировка операций за короткий период по конкретному пользователю
Следующий инструмент тоже работает с технологическим журналом, но решает другую задачу.
Если предыдущий инструмент анализирует длительный период, например месяц или полугодие, то здесь мы берем короткий промежуток времени, например час, и разбираем конкретные действия конкретного пользователя.
https://github.com/rdv-team/logt
В полном технологическом журнале огромное количество событий, и все они перемешаны: разные пользователи, разные действия, большой поток данных, отсортированный по времени.
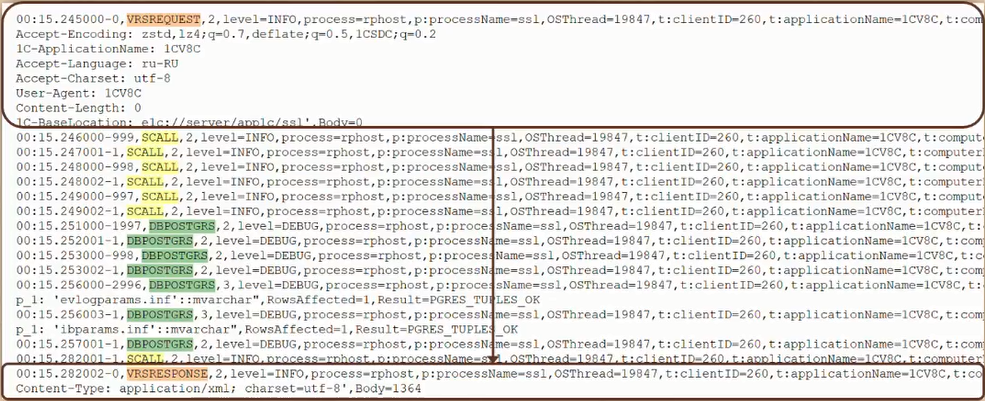
Наша задача – извлечь из этого потока конкретную операцию. Например, пользователь Иванов записывал документ, а пользователь Петров получал данные динамического списка.
Мы знаем, когда это произошло – у нас есть временная метка из замера времени. Дальше мы определяем границы операции. Они задаются двумя событиями: начало – VRSREQUEST и конец – VRSRESPONSE. Между ними собираем все события, которые относятся к этой операции: запросы, серверные вызовы, SQL, ожидания блокировок, исключения, таймауты – все, что произошло внутри.
Таким образом, мы формируем «корзину» событий – по сути, реконструкцию одной пользовательской операции или фонового задания.
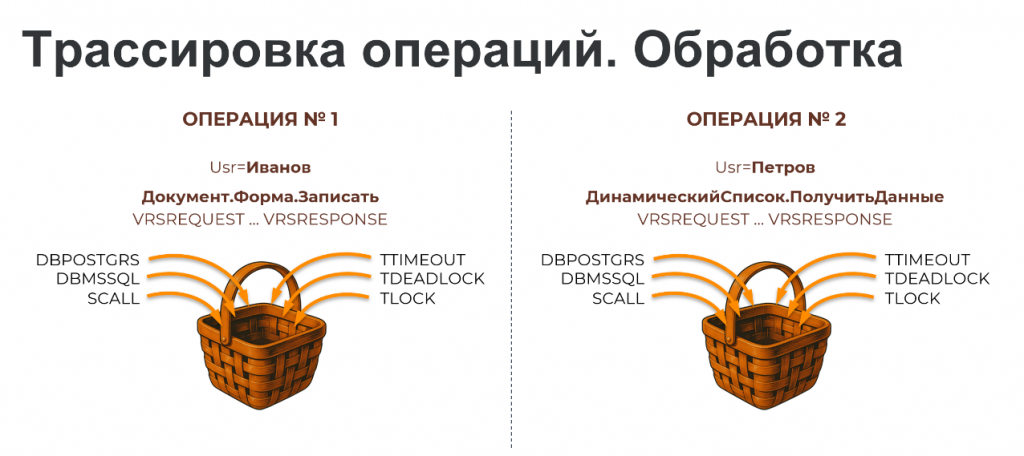
Алгоритм следующий: полный технологический журнал обрабатывается Python-скриптом, определяются связанные в одну операцию события, загружаются в ClickHouse.
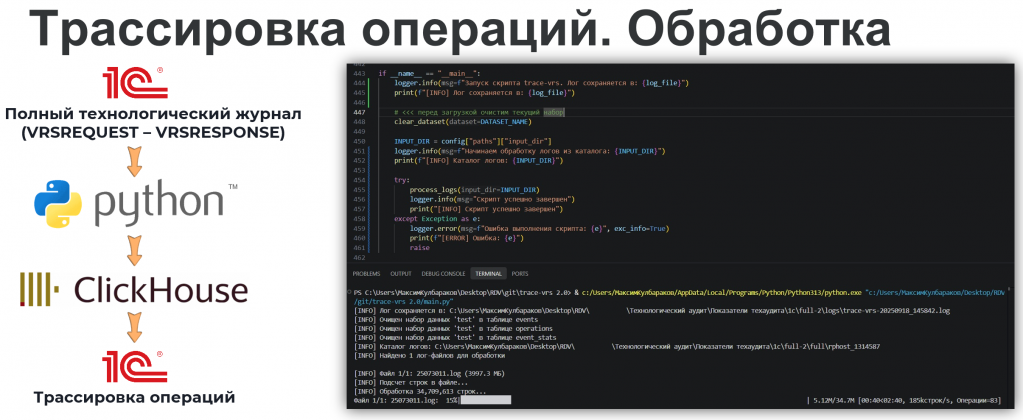
После этого через специализированную обработку «Трассировка длительных операций» мы выполняем детальный анализ того, какие бизнес-операции выполнял пользователь или фоновое задание и из каких событий технологического журнала состояли их действия.
Рассмотрим, как это происходит.
Выбираем базу, задаем отборы, нажимаем «загрузить» – получаем список операций.
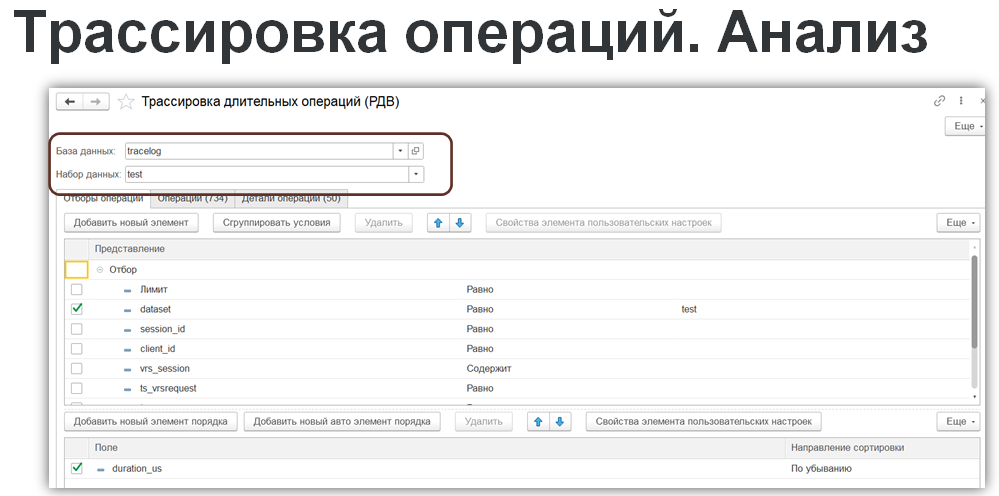
Каждая строка – это одно действие пользователя: с временной меткой и длительностью. Например, обновление динамического списка – 445 секунд. Очевидно, что это слишком долго. Вызываем «Выполнить анализ операции» и получаем список всех событий внутри.
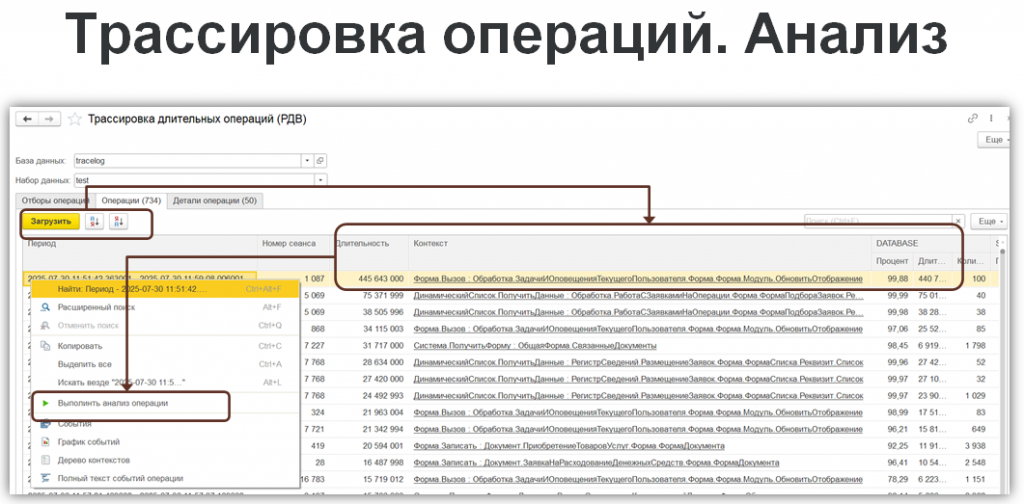
На первом месте оказывается запрос, который по длительности занимает почти все время операции. Значит, проблема именно в нем. С помощью команды «Полный контекст события» откроем текстовый документ и посмотрим, как это событие выглядит в технологическом журнале.
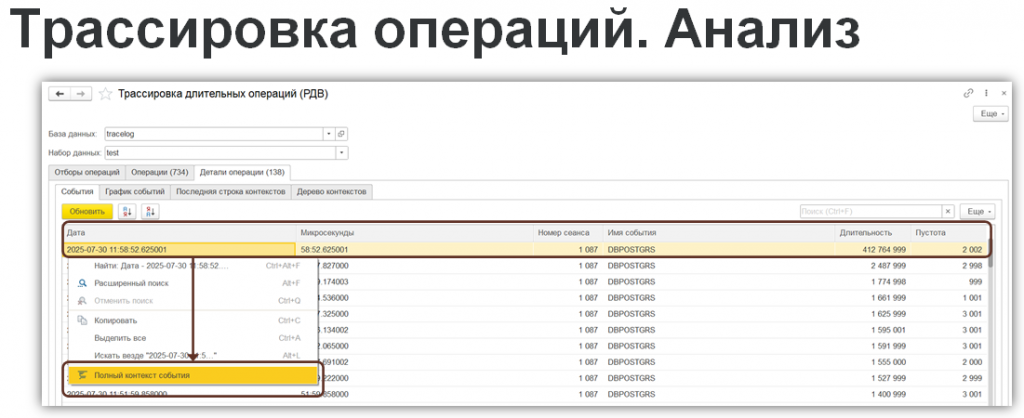
Видим текст запроса и большое количество LEFT JOIN. Это сразу наводит на мысль о неявном обращении к полям составного типа и о потенциальной проблеме в самом запросе.
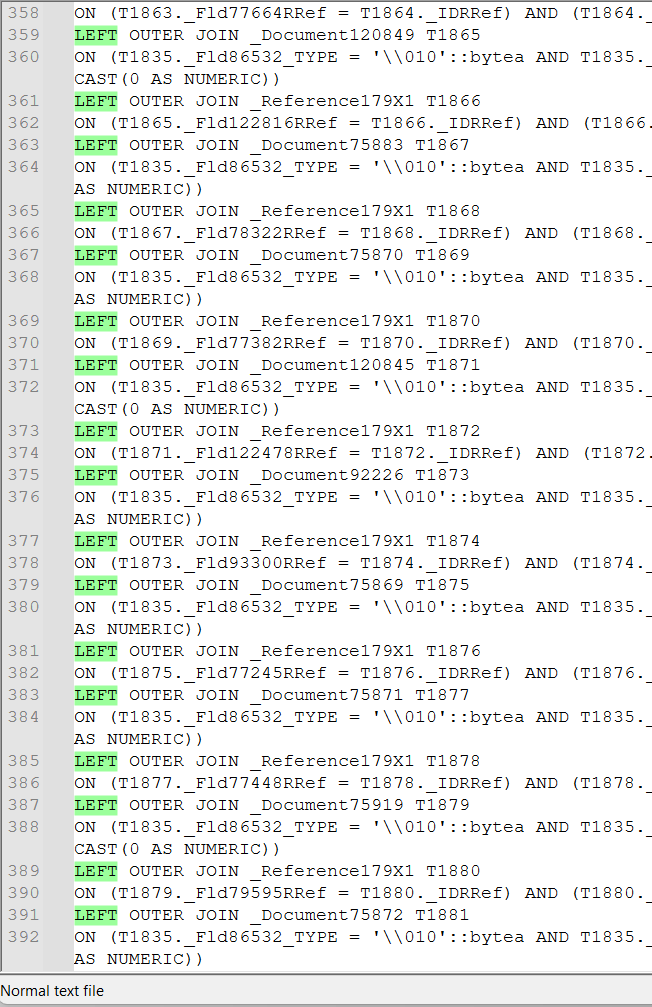
Найдем код в конфигураторе 1С по контексту этого события.
НовыйЭлемент = Элементы.Вставить("ВерсииСоглашенияПодразделение", Тип("ПолеФормы"), Элементы.ВерсииСоглашения);
НовыйЭлемент.Вид = ВидПоляФормы.ПолеВвода;
НовыйЭлемент.ПутьКДанным = "ВерсииСоглашения.Ссылка.Подразделение";
НовыйЭлемент.Заголовок = "Подразделение";
НовыйЭлемент = Элементы.Вставить("ВерсииСоглашениСрокСогласования", Тип("ПолеФормы"), Элементы.ВерсииСоглашения,Элементы.ВерсииСоглашенияДата);
НовыйЭлемент.Вид = ВидПоляФормы.ПолеВвода;
НовыйЭлемент.ПутьКДанным = "ВерсииСоглашения.Ссылка.СрокСогласования";
НовыйЭлемент.Заголовок = "Срок согласования";
Здесь ВерсииСоглашения.Ссылка является составным типом данных.
После того как мы локализовали проблему и нашли конкретную строчку кода, где она возникает, переходим к этапу оптимизации.
Этап 2. Оптимизация
Здесь нет жесткого регламента или набора шагов в духе «сделай раз, сделай два, сделай три». В каждом случае это отдельная инженерная задача. Мы используем все, что помогает: отладку кода, замеры производительности, анализ планов запросов. Иногда приходится менять саму методологию работы или функциональность.
Например, если видим, что пользователю в динамическом списке не нужны группировки, но он их использует, хотя 90% пользователей этого не делают, мы можем просто отключить эти группировки. Или добавить в отчет обязательные отборы. Это не меняет бизнес-процесс, но корректирует поведение системы и дает прирост производительности при работе с формой.
Конечно, после оптимизации результат нужно обязательно проверить. И мы плавно подходим к последнему этапу.
Этап 3. Контроль
Для контроля мы возвращаемся к первому этапу аудита и используем те же инструменты. Сбор данных при этом не прекращается: они продолжают архивироваться и накапливаться.
Дальше снова загружаем данные, анализируем их и сравниваем с тем, что было до оптимизации, и с тем, что получили после. Смотрим, какая оптимизация дала эффект, а какая – нет.
Часто на этом этапе проявляются новые проблемы, и приходится переходить к следующей итерации оптимизации и контроля. Это нормальный итерационный процесс. Обычно хватает двух-трех итераций, чтобы система стала стабильной.
Что можно сделать прямо сейчас
-
Включить технологический журнал. Конфигурационный файл можно взять из нашего репозитория GitHub.
-
Настроить ежедневную архивацию с историей 24 часа.
-
Собрать данные за пару дней или неделю.
-
Скачать инструменты анализа технологического журнала из нашего репозитория GitHub.
-
Дальше все просто: указать путь к журналу, выбрать список шаблонов и нажать «Запустить». В результате получите Excel-таблицы с полезными данными: проблемные операции, их контекст кода и другие метрики.
Это хороший способ разобраться в своей системе, попробовать инструменты на практике и, возможно, подготовиться к экзамену эксперта.
Ссылки на инструменты
https://github.com/rdv-team/loga
https://github.com/rdv-team/logt
Здесь собраны ссылки на два наших инструмента: для анализа технологического журнала за длительный период и для трассировки операций по полному журналу. Будем рады, если начнете использовать их в работе.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт