







Кейс миграции данных из 1С:УПП в 1С:УХ через SQLite и Python COM
Материал подготовлен как технический разбор практического кейса миграции данных из 1С:УПП в 1С:УХ без привязки к конкретному заказчику. Текст ориентирован на архитекторов, разработчиков 1С, интеграторов и технических руководителей, которым важны не общие слова про перенос, а управляемый и воспроизводимый контур миграции.
Зачем понадобился отдельный контур миграции
В реальных проектах перехода с УПП на УХ быстро выясняется, что стандартной конвертации недостаточно.
Типовые проблемы такие:
- состав и качество данных в
УППсильно зависят от доработок и истории эксплуатации; - один и тот же объект в источнике и приемнике формально называется похоже, но отличается по структуре, типам реквизитов и бизнес-смыслу;
- часть сущностей можно перенести только после подготовки ссылок, перечислений, счетов и табличных частей;
- команде нужен не одноразовый перенос, а управляемый цикл: выгрузили, проверили, доработали маппинг, повторили.
На практике это приводит к требованию: между источником и приемником нужен прозрачный промежуточный слой, в котором можно анализировать данные, управлять зависимостями и повторять загрузку без хаоса.
Именно под эту задачу был собран контур на Python + SQLite + COM.
Заготовка с открытым кодом на github.com
Целевая архитектура
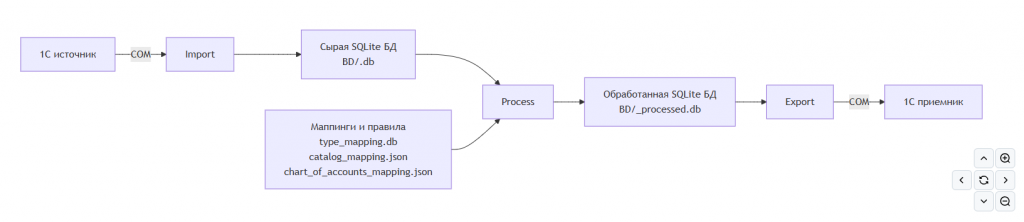
Вместо прямой записи из УПП в УХ используется трехэтапный конвейер:
importчитает данные из1С:УППчерез COM и сохраняет их в сырые SQLite-базы.processпреобразует данные под модель1С:УХ, используя маппинги, правила обработки, свертки счетов и подготовку ссылок.exportзаписывает обработанные данные в1С:УХчерез COM.
Это выглядит тривиально только на уровне блок-схемы. Ключевая ценность в том, что между импортом и экспортом появляется реальный контролируемый слой данных, а не временный буфер, который нельзя инспектировать.
Какие задачи должен был закрыть контур
Перед реализацией были сформулированы прикладные требования.
- Поддержать перенос не одной таблицы, а набора взаимосвязанных сущностей.
- Разделить чтение, преобразование и запись на независимые стадии.
- Сохранять промежуточные результаты в форме, удобной для анализа.
- Поддержать ручные и автоматические маппинги полей, типов и перечислений.
- Управлять ссылочными объектами отдельно от основного потока записи.
- Иметь возможность точечно переэкспортировать каталог или отдельные записи.
- Дать веб-интерфейс для операционного запуска и просмотра состояния без постоянной работы в консоли.
- Поддержать автоматический запуск по расписанию и уведомления после завершения процессов.
Почему выбран SQLite как промежуточный слой
Решение с SQLite оказалось удачным не из-за моды на lightweight storage, а из-за инженерной практичности.
SQLite в этом кейсе дает:
- отдельную БД на каждый каталог;
- быстрый локальный просмотр данных без поднятия отдельного сервера;
- возможность сравнивать сырую и обработанную версии;
- устойчивый формат для повторных прогонов;
- удобный слой для отладки, аналитики и ручных проверок.
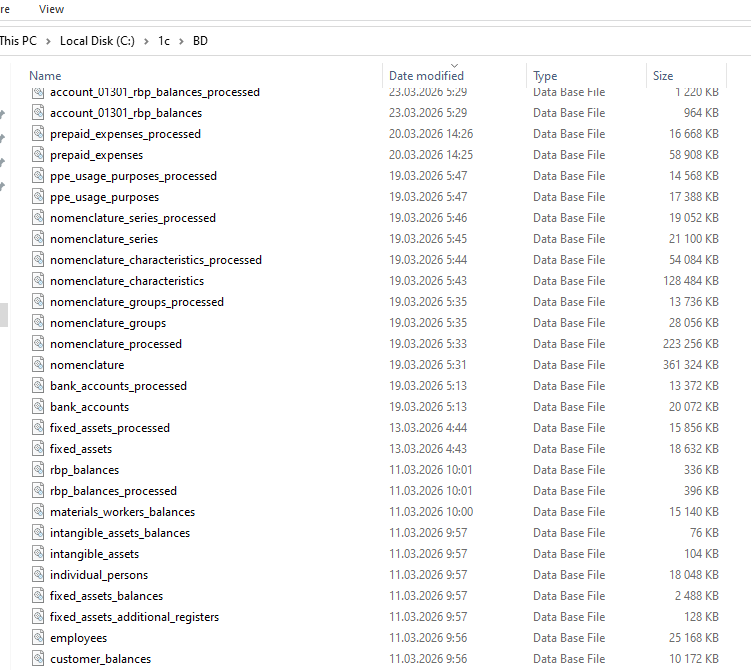
Дополнительно SQLite отлично ложится на модульную структуру миграции: один каталог -> один набор loader/processor/writer -> одна или две БД.
На практике это выглядит как набор отдельных файлов БД по сущностям и стадиям обработки:
Как устроен импорт из УПП
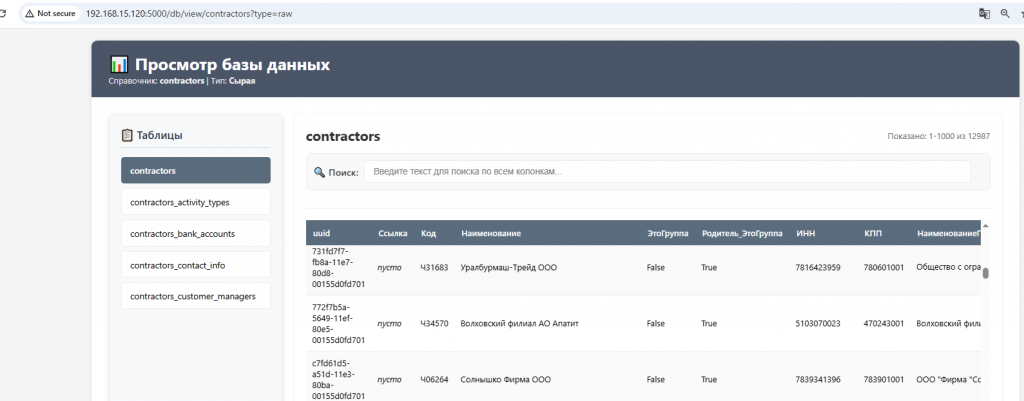
Этап импорта реализован через набор модулей в IN/. Для каждого каталога есть свой loader, который:
- подключается к источнику
1С:УППпо COM; - выполняет запрос или читает объектную модель;
- нормализует результат;
- сохраняет строки в SQLite.
На этом этапе проект уже не ограничивается простым SELECT *.
Нужно решать как минимум три задачи:
- извлекать представления и UUID ссылок;
- аккуратно обрабатывать перечисления;
- сохранять типы так, чтобы потом процессор мог принимать решение о преобразовании.
Для ссылочных полей в БД сохраняется JSON с минимумом служебных данных:
{
"presentation": "ООО Ромашка",
"uuid": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"type": "Справочник.Контрагенты"
}
Для перечислений используется нормализованная строка вида:
Перечисление.ИмяПеречисления.Значение
Это важно, потому что на следующем этапе уже можно работать не с «черным COM-объектом», а с предсказуемым представлением данных.
Зачем понадобилось обновление метаданных обеих конфигураций
Один из самых частых источников ошибок в миграции между конфигурациями 1С это неправильные ожидания по структуре объектов.
Чтобы не жить догадками, в проекте отдельно выгружаются метаданные:
- источника
УПП; - приемника
УХ.
Это дает возможность:
- строить автоматические черновые маппинги;
- сравнивать реквизиты, табличные части и типы;
- актуализировать перечисления и их значения;
- быстро диагностировать, почему конкретное поле или тип не маппится.
По сути, метаданные становятся еще одним слоем данных проекта, а не внешним «знанием в голове аналитика».
Что происходит на этапе обработки
Этап process это ядро всей схемы. Здесь сырая БД превращается в БД, пригодную для записи в УХ.
На практике обработка решает такие задачи:
- переименование полей под приемник;
- преобразование типов;
- перевод значений перечислений;
- обработка мультитипов;
- свертка и маппинг счетов;
- работа с табличными частями;
- подготовка ссылочных значений для поиска или создания в приемнике.
Базовая логика обработки вынесена в общий процессор маппинга, а прикладные особенности живут в отдельных PROCESS/<catalog>_processor.py.
Это позволяет не смешивать инфраструктурный код и бизнес-логику конкретной сущности.
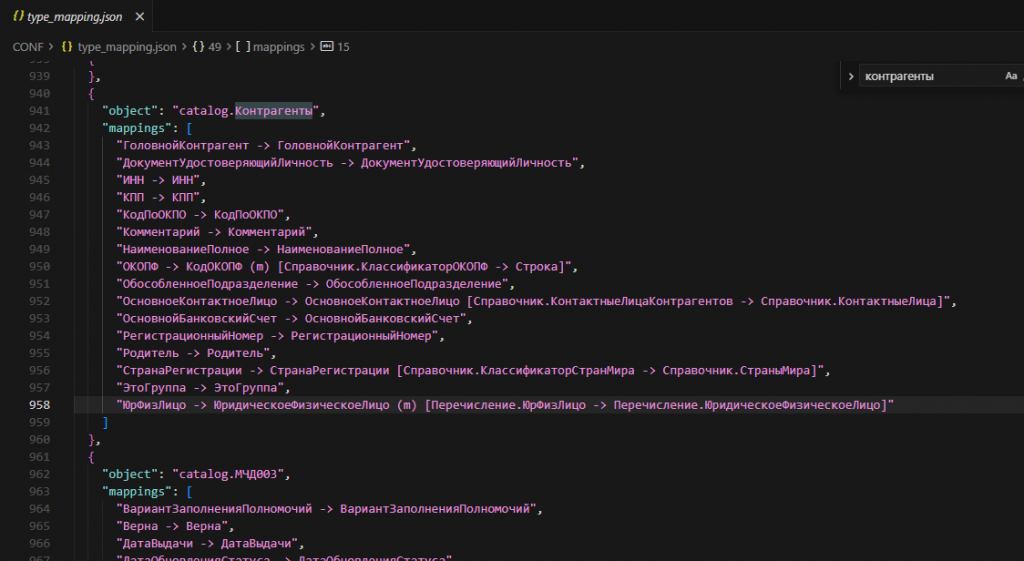
Как устроены маппинги
Ключевой элемент проекта это рабочая база маппинга. В ней хранится несколько уровней соответствий:
- соответствие объектов источника и приемника;
- соответствие полей;
- соответствие типов;
- соответствие значений перечислений.
Кроме этого используются:
catalog_mapping.jsonкак реестр маршрутовloader -> processor -> writer;chart_of_accounts_mapping.jsonдля маппинга плана счетов и субконто.
Такой разнос по артефактам оказался практичным.
Почему не все положить в один giant JSON:
- разные уровни маппинга живут в разном ритме;
- часть правил удобно редактировать вручную;
- часть может генерироваться автоматически;
- часть должна использоваться прямо в рантайме процессора.
Автоматический и ручной маппинг
Автоматика в проекте используется как ускоритель, а не как магия.
Черновой маппинг можно построить из метаданных по именам и структурам объектов. Но на реальном проекте этого недостаточно, потому что:
- имя может совпадать, а смысл поля отличаться;
- смысл может совпадать, а структура и типы нет;
- отдельные перечисления в разных сущностях требуют разной логики перевода;
- иногда объект в
УППдолжен лечь не в прямой аналог, а в прикладную сущность вУХ.
Поэтому ручной маппинг не является «исключением», а нормальной частью промышленной миграции.
В нашем подходе это означает, что команда может:
- быстро получить стартовый черновик;
- руками закрепить спорные соответствия;
- сохранить это в рабочей базе маппинга;
- повторно прогонять обработку уже на стабильной основе.
Отдельный контур для ссылочных объектов
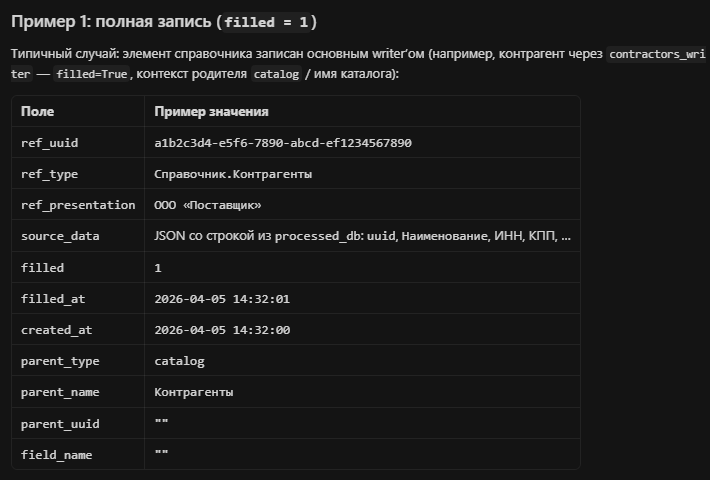
Одна из самых полезных частей решения это отдельная база reference_objects, которая заполняется на этапе экспорта.
Ее задача проста: не терять ссылочные объекты, которые writer создает или обрабатывает при записи в приемник, даже если запись прошла не полностью.
Что это дает practically:
- все ссылки по УИД сохраняются в отдельной базе;
- можно видеть, какие объекты уже записаны, а какие еще нет;
- можно понять, из какого объекта и поля пришла ссылка;
- можно запускать отдельный проход дозаполнения незаписанных ссылок;
- можно управлять повторной записью не вслепую, а по явному состоянию.
Это важное отличие от сценариев, где после ошибки в середине обмена команда пытается «на глаз» понять, что уже создано в приемнике, а что нет.
В данном подходе ссылочный контур становится наблюдаемым и управляемым.
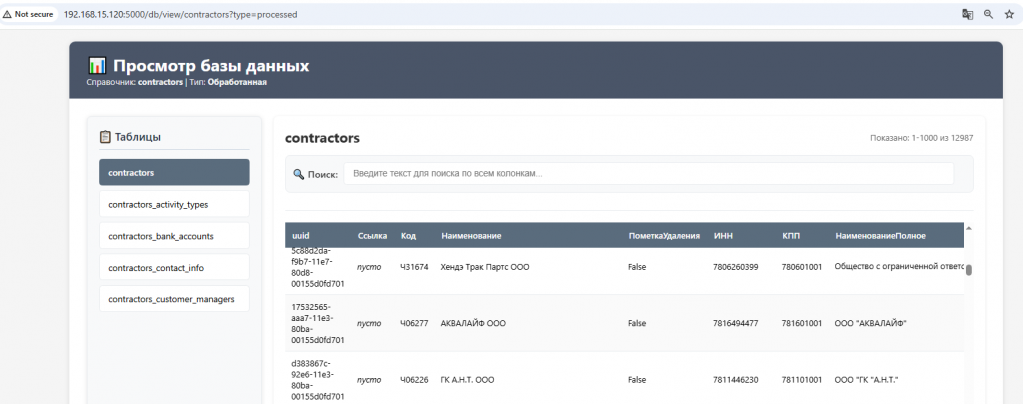
Как устроен экспорт в УХ
После подготовки данных включается стадия export.
На этой стадии writer:
- читает уже обработанную SQLite-базу;
- ищет объект в
УХпо нужному ключу; - при необходимости создает его;
- заполняет реквизиты и табличные части;
- фиксирует состояние ссылок и записывает сведения в
reference_objects; - пишет результат через COM в приемник.
С точки зрения архитектуры это принципиально лучше прямой конвертации, потому что writer получает уже подготовленные данные, а не решает все проблемы сразу на лету.
Именно за счет этого проще сопровождать проект, отлаживать узкие места и повторять выгрузку только там, где это нужно.

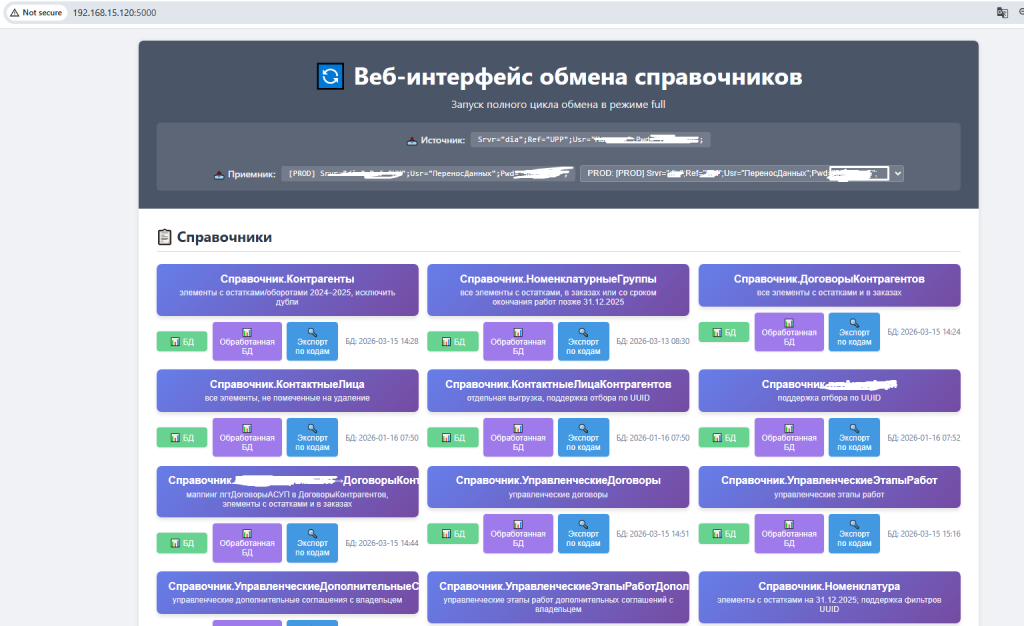
Веб-интерфейс как операционный слой
На проектах миграции быстро появляется еще одна задача: нужно дать команде запускаемый и наблюдаемый интерфейс, а не только набор консольных команд.
Поэтому поверх того же пайплайна был сделан веб-интерфейс, который позволяет:
- запускать обмен по выбранному каталогу;
- смотреть логи;
- просматривать сырые и обработанные SQLite-базы;
- запускать точечный экспорт по кодам или UUID;
- выбирать нужный приемник;
- контролировать состояние выполнения.
Для архитектуры это важно по двум причинам:
- веб не дублирует бизнес-логику, а использует тот же исполняемый контур;
- операции становятся доступными не только разработчику, который сидит в терминале.
Запуск по расписанию и уведомления
Отдельная практическая ценность решения в том, что это не только «ручной инструмент разработчика».
Контур можно встроить в регулярный операционный цикл:
- выполнять загрузку по расписанию;
- запускать пакетные сценарии ночью или в окна сопровождения;
- получать уведомления после завершения процесса в мессенджер;
- разбирать результат уже по факту выполнения, а не ждать перед экраном.
Для проектов миграции это означает переход от разовых ручных запусков к управляемому процессу.
Чем этот подход лучше стандартной конвертации
Если коротко, стандартная конвертация чаще всего воспринимается как черный ящик: настроили правила, запустили, получили результат или ошибку. В нашем кейсе ставка была сделана не на «магическую кнопку переноса», а на управляемый технический контур.
Что это дало:
- полную промежуточную прозрачность по данным;
- контролируемый цикл
выгрузка -> анализ -> доработка -> повтор; - явный слой маппингов;
- управляемую работу со ссылками по УИД;
- точечный повторный экспорт;
- удобный веб-слой для операционной команды;
- возможность ставить процессы на расписание;
- уведомления по завершению;
- более быструю адаптацию новых сущностей.
Последний пункт особенно важен. При модульной архитектуре IN / PROCESS / OUT и при использовании современных AI-заряженных IDE подключение новой сущности становится заметно быстрее: можно быстро собрать новый loader, процессор и writer, затем уточнить маппинг и уже на тестовом цикле увидеть результат.
Что оказалось самым полезным на практике
Если убрать весь технологический шум, то на проекте особенно полезными оказались пять вещей.
- Разделение стадий импорта, обработки и экспорта.
- Отдельный слой маппинга, а не набор случайных преобразований в коде.
- Сохранение сырых и обработанных БД для анализа.
- Наблюдаемая база ссылочных объектов.
- Возможность повторять миграцию не целиком, а управляемыми частями.
Именно эти свойства превращают миграцию из разовой рискованной операции в инженерный процесс.
Ограничения подхода
Важно честно сказать и про ограничения.
- Это не коробочное решение «для всех конфигураций без доработок».
- Качество результата напрямую зависит от качества маппинга и знания предметной области.
- Для сложных сущностей все равно нужен прикладной код обработки.
- COM-контур требует Windows и доступной установленной платформы 1С.
- Для промышленного использования нужен дисциплинированный процесс сопровождения артефактов миграции.
Вывод
В кейсе миграции из 1С:УПП в 1С:УХ наилучший результат дал не «универсальный конвертер», а модульный контур с промежуточным SQLite-слоем, формализованным маппингом, отдельной обработкой ссылок и повторяемым экспортом через COM.
Такой подход требует инженерной дисциплины, но взамен дает то, чего обычно не хватает на проектах миграции:
- предсказуемость;
- наблюдаемость;
- повторяемость;
- управляемость;
- возможность быстро наращивать покрытие новыми сущностями.
Если вам нужно пройти путь от наследованной УПП к целевой модели УХ не через одноразовый эксперимент, а через контролируемую техпроцедуру, то подобная архитектура на практике оказывается существенно сильнее стандартного «прямого переноса».
Проект: msrv-tech/1c_conversion
Вступайте в нашу телеграмм-группу Инфостарт