Переход в 1С на Postgres в нашей организации начался в 2023 году и продолжается по настоящее время. Перевести 65 информационных систем с одной СУБД на другую непросто.
В 2023 году было переведено порядка 20 относительно небольших баз, переход не вызвал проблем. Единственное – по одной базе ТОИР возникли проблемы с РЛС, которые пришлось оптимизировать.
В 2024 году мы подошли к переводу больших и серьезных баз, работа которых критична для бизнеса. Кроме того, конфигурация этих баз за годы эксплуатации была значительно изменена. Самая большая из них – база консолидации. Ее размер составляет почти 6 терабайт. На втором месте расположились две базы УРБД: размер меньше, но их работа не менее критична для бизнеса.
О некоторых выявленных проблемах при переходе и при эксплуатации после перехода и пойдет речь в статье.
Сначала я расскажу о важных для нас проблемах с настройками Linux и Postgres. Второй блок статьи – проблемы с запросами. Проблем было много, но отмечу самые значимые. О некоторых интересных случаях расскажу подробно. В конце опишу прочие проблемы, выявленные в процессе эксплуатации.
Проблемы миграции больших баз
Если база небольшая, то проще всего выгрузить и загрузить ее с помощью конфигуратора. Для больших баз этот подход не работает, и на помощь приходит автономный сервер от 1С – утилита ibcmd, у которой есть режим replicate, позволяющий выполнить миграцию с одной СУБД на другую. Работа утилиты проста: сначала переносятся таблицы, затем создаются индексы.
Основная проблема при использовании этой утилиты, особенно для больших баз, заключается в невозможности выполнить частичную миграцию. Принцип работы такой: либо все, либо ничего. Если по каким-то причинам миграция падает, ее приходится начинать с самого начала. Наша консолидация объемом 6 терабайт мигрировалась почти сутки: 8 часов переносились таблицы и еще 12 часов создавались индексы. Поэтому при падении процесса все приходилось запускать заново. Хотелось бы, чтобы, во-первых, было более подробное логирование, а во-вторых, появилась возможность частичной миграции. Это бы значительно помогло.
В утилите можно указать количество потоков на чтение и запись, но увеличивать их бездумно нельзя. При слишком больших значениях мы получали аварийное завершение миграции. По нашему опыту, оптимальными были 4 потока на чтение и 6 на запись.
Также при миграции мы отключаем автовакуум, если в кластере Postgres уже есть база, чтобы уменьшить нагрузку на диски.
Ошибки в процессе миграции
Также при работе этой утилиты мы выявили ряд ошибок. Первая ошибка незначительная, но неприятная. При миграции таблицы пользователей v8users по неизвестной причине слетают флаги, отвечающие за аутентификацию 1С:Предприятия и за наличие административной роли. Это проявляется, например, при добавлении нового пользователя или при перезаписи существующего: возникает ошибка, представленная на изображении.

Эта ошибка была зарегистрирована в 1С еще до нас. По их словам, она исправлена в более поздних версиях. Однако при очередной миграции с использованием ibcmd самой последней версии 8.3.25 (подрелиз не помню) мы столкнулись с более серьезной проблемой: индексы не создавались. В логах утилиты отображалось, что миграция прошла успешно, но индексов не было вовсе. Для нас это оказалось критичным, а проблема со слетающими флагами пользователей показалась мелочью на фоне отсутствующих индексов.
Мы быстро вернулись к старой версии утилиты. Тем более, что проблему с пользователями устранить легко. Можно перезаписать пользователя, у которого есть административные роли и включена аутентификация 1С, но для этого нужно заходить в Предприятие. Мы же исправляем проблему проще – выполняем скрипт прямо на СУБД:
UPDATE public.v8users
SET eauth = true,
admrole = true
WHERE name = 'Администратор'
Проблемы с дублированием данных и индексами
Вторая проблема серьезнее. Она заключается в том, что при миграции могут быть созданы не все индексы. Это происходит, если в полях, участвующих в ключах индекса, встречаются задублированные записи. Такое характерно для многострочных реквизитов, в которых используются разные символы – например, конца абзаца или перевода строки. При миграции на Postgres эти символы превращались в один, и фактически разные строки становились одинаковыми. При создании уникального индекса возникала ошибка duplicate key. Мы ее не видели, потому что логирования не было, но индексы не создавались.
Мы обнаружили эту проблему уже при тестировании после миграции: фиксировали просадку производительности, открывали план запроса и видели там сканирование таблицы. Ожидался index scan, но индекса в структуре базы не было.
Для исправления ситуации мы сделали отчет – ревизию индексов. Он показывает расхождение между ожидаемыми индексами 1С и реальными индексами в СУБД. Принцип его работы простой: заготовленные скрипты запускаются на СУБД, получают список фактических индексов, затем отчет сравнивает их с ожидаемыми индексами 1С и выводит расхождения.
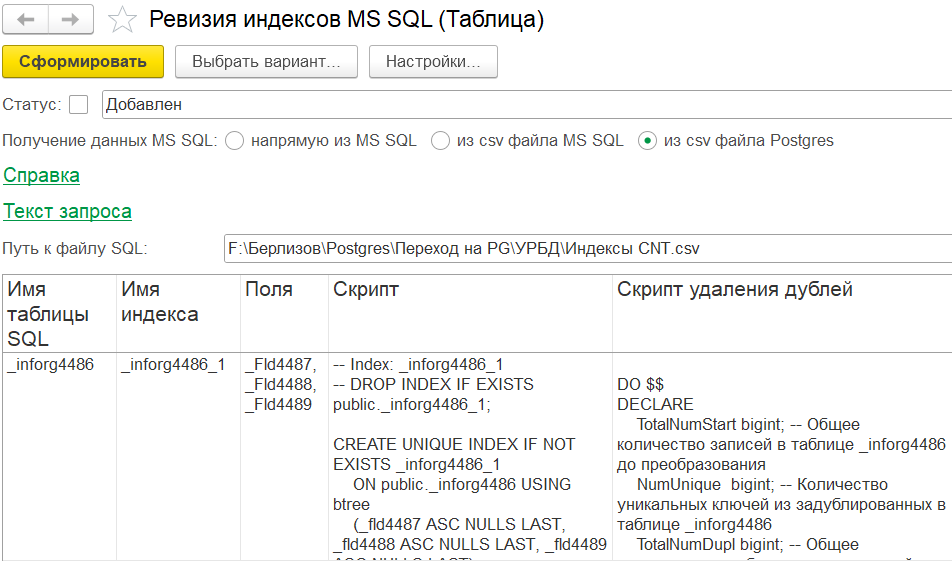
Для отсутствующих индексов генерируются скрипты: один – для удаления задублированных данных, которые препятствуют созданию индекса, второй – для создания самого индекса. Последовательное выполнение этих скриптов позволяет создать все необходимые индексы.
Критичные параметры настройки PostgreSQL
В процессе эксплуатации мы выявили параметры в настройках Postgres, которые вызывали ошибки. Для нас они критичны, потому что их изменение требует перезапуска сервера Postgres. Для наших систем это проблематично: нужны согласования и выделение технических окон, поэтому такие параметры лучше выставлять заранее.
Первая ошибка – слишком много открытых файлов.
Ошибка СУБД: 53000: ERROR: could not seek to end of file "base/3452451/3690331": Too many open files in system
В Postgres мы увеличиваем параметр max_files_per_process до 65 тысяч. Он определяет максимальное количество файлов, которое может открыть каждый подпроцесс Postgres. По умолчанию значение составляет 1 тысячу, этого недостаточно.
Также мы увеличиваем глобальный параметр Linux fs.file-max до больших значений. Для консолидации мы поднимали его в два этапа: сначала до 70 тысяч, затем до 250 тысяч.
Вторая ошибка – слишком много подключений:
FATAL: sorry, too many clients already
Она возникает при превышении максимального количества клиентских подключений к Postgres. За это отвечает параметр max_connections. По умолчанию он равен 100. На большинстве баз мы увеличиваем его до 500–1000, а на консолидации – до 2000.
Отслеживать количество подключений можно через Zabbix, если он настроен, либо вручную через системное представление pg_stat_activity, чтобы вовремя оценивать нагрузку и увеличивать параметр до возникновения ошибки.
Особенности оптимизатора запросов в PostgreSQL
Переходим к самому интересному блоку – проблемам с запросами на Postgres. В большинстве случаев сложности, с которыми мы столкнулись, связаны с тем, что оптимизатор Postgres откровенно проигрывает оптимизатору Microsoft SQL. Запросы, которые на Microsoft SQL выполнялись за приемлемое время, на Postgres работают значительно дольше. Особенно это заметно на больших запросах. Postgres плохо справляется с крупными конструкциями, что особенно характерно для консолидации, где встречаются запросы объемом нескольких тысяч строк.
Эти проблемы известны, поэтому подробно на них я не останавливаюсь. Отмечу только, что нами была разработана система автотестирования, позволяющая выявлять запросы, которые будут тормозить на Postgres, еще до перехода на новую СУБД. Об этой системе я писал на Инфостарте «Прощаемся с MSSQL: как без усилий понять, что в вашей 1С будет тормозить при переходе на PostgreSQL».
Добавлю, что в начале эксплуатации нам сильно помогли Sentry и Elastic. Они оперативно доставляли ошибки, и мы так же оперативно их исправляли, еще до того, как их замечали пользователи.
Избыточная проверка условий в логических выражениях
Одна из интересных особенностей Postgres, с которой мы столкнулись – это избыточная проверка условия. Для примера – простой запрос. У нас тут вложенный запрос с двумя строками: поле Поле1 со значениями NULL и ИСТИНА и поле Знам со значениями 0 и 1.

Как вы думаете, что вернет этот запрос? В верхней части изображения Поле1 сравнивается с ИСТИНА, а выражение 100 / Знам должно быть больше 0.

Ожидается табличка из двух строк. Так бы и было, если бы мы остались на Microsoft SQL. Но на Postgres мы ловим ошибку деления на ноль.
На изображении показано, как конструкция «ВЫБОР КОГДА» транслируется в Postgres. Здесь тоже Поле1 сравнивается с ИСТИНА, и второе логическое подвыражение рассчитывается так же, как в 1С.


Мы привыкли, что логические операторы в конструкции ГДЕ или ВЫБОР КОГДА вычисляются слева направо, и если часть условия уже определена, то оставшиеся подвыражения не вычисляются. Но в Postgres все иначе. После проверки первого условия в первой строке, где Поле1 = NULL, оно сравнивается с ИСТИНА, и второе подвыражение 100 / 0 не должно выполняться, но выполняется.
Интересно, что если заменить первое логическое выражение на функцию ЕСТЬNULL(Поле1, ЛОЖЬ), то ошибка исчезает.


И также ошибки не будет, если перенести условие в блок ГДЕ.

Такое ощущение, будто кто-то внутри Postgres не совсем трезв и «как хочет, так и вычисляет» логические операторы. Но это не так. Это реальная особенность Postgres, и о ней написано в документации. Там прямо сказано, что «Порядок вычисления подвыражений логических операторов не определен. В частности, аргументы оператора или функции не обязательно вычисляются слева направо или в любом другом фиксированном порядке…»
Когда порядок вычисления важен, его можно зафиксировать с помощью конструкции CASE. Выражение:
SELECT ... WHERE x > 0 AND y/x > 1.5;
нужно переделать на
SELECT ... WHERE CASE WHEN x > 0 THEN y/x > 1.5 ELSE false END;
Для 1С это соответствует блокам ВЫБОР и КОГДА.
Проблемы с функцией «Подобно» в PostgreSQL
После перевода одной из баз УРБД мы столкнулись со следующей интересной ошибкой. В шаблоне конструкции ПОДОБНО перестали отрабатывать квадратные скобки. Напомню, что в квадратных скобках приводится перечень символов, который сравнивается с соответствующей строкой.
Проще всего показать это на примере. На изображении приведен простой запрос, который ожидаемо возвращает ИСТИНА.

Функция ПОДОБНО в этом случае трансформируется в Postgres в функцию SIMILAR TO.
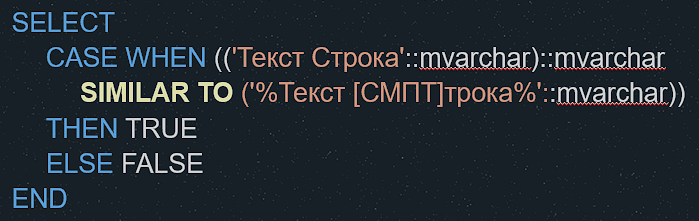
Эта функция поддерживает квадратные скобки и позволяет использовать регулярные выражения. Было бы прекрасно, если бы так происходило всегда. Если использовать ПОДОБНО в соединениях полей, то оно трансформируется уже в функцию LIKE.

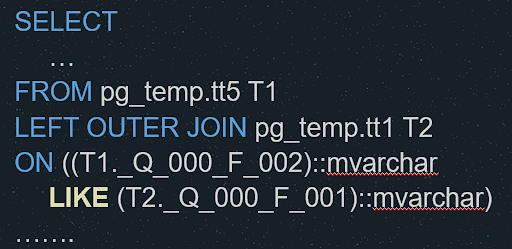
Для Microsoft SQL аналогично: ПОДОБНО также преобразуется в LIKE. Но, как говорится, LIKE LIKE’у рознь. В отличие от майкрософтовского LIKE, постгресовый LIKE не поддерживает квадратные скобки. Они воспринимаются как обычные символы. Поэтому если шаблон содержит квадратные скобки, поведение перестает быть ожидаемым.
Точно такая же ситуация возникает, когда ПОДОБНО используется в блоке запроса ГДЕ. Там оно также трансформируется в LIKE.


Для того, чтобы в интерфейсе у пользователей не было изменений, нам пришлось колхозить доработку, так как просто подправить текст запроса было невозможно.
О функциях поиска по шаблону в Postgres более подробно можно прочитать в документации. А это ссылка на рекомендацию 1С по использованию ПОДОБНО в запросах.
Нюансы работы с NULL в условиях
Дальше расскажу об одной интересной фиче Postgres. На изображении представлен простой запрос. Например, у нас есть таблица, где есть колонка «Т», в которой находятся числовые значения.

Как вы думаете, какой результат вернет представленный на изображении запрос? Очевидно, что все записи не равны единице и не равны NULL.
На Postgres же не будет возвращено ни одной строки. Эту ошибку поймали когда уже перешли на Рostgres. Но как оказалось такое же поведение и у MSSQL, так что непонятно почему эту ошибку не поймали раньше.

Точно так же не будет возвращено ни одной строки, если мы переделаем условие на выборку из временной таблицы, у которой есть колонка «Кол», содержащая значение NULL.

В Postgres логическое выражение NOT (TRUE) возвращает FALSE, но выражение NOT (NULL) всегда возвращает NULL, и нет способа привести такое выражение к булевому значению. Кроме того, эта конструкция плохо оптимизируется: планировщик не может преобразовать ее в хешированный анти-джойн и будет использовать либо хешированный подплан, либо простой подплан, в зависимости от количества строк. В случае использования простого подплана и большого числа строк конструкция будет работать очень медленно. Об этом я расскажу в следующем примере.
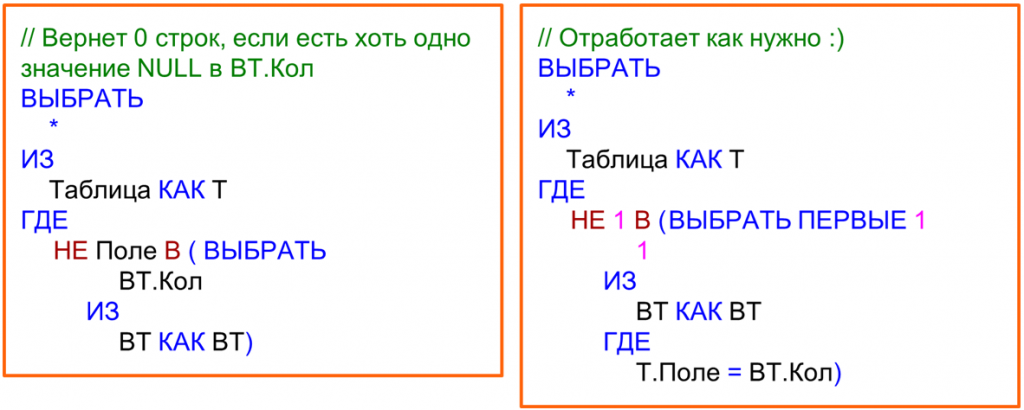
Мы нашли в интернете информацию о том, как можно обойти эту особенность Postgres. В рекомендациях говорилось, что следует использовать конструкцию NOT EXIST. Для 1С это соответствует конструкции «НЕ 1 В (ВЫБРАТЬ ПЕРВЫЕ 1 1».
Если мы наш исходный запрос, который представлен слева, переделаем на «НЕ 1 В (ВЫБРАТЬ ПЕРВЫЕ 1 1», то запрос начинает работать корректно и возвращает правильный результат.
Проблемы с частичным удалением записей
Следующая проблема – долгое частичное удаление записей в таблице регистрации. На разработке у нас была интеграция консолидации с другой системой Data Lake с использованием плана обмена. В плане обмена был один узел. Данные обмена заносились в непериодический регистр сведений с четырьмя измерениями. Управление актуальностью данных для обмена выполнялось программно.
Мы заметили, что частичное удаление данных в таблице регистрации выполнялось очень долго. Например, на тестовой базе общее количество зарегистрированных записей составляло 320 тысяч, и удаление 5000 из них занимало почти 3 минуты. На Microsoft SQL аналогичная конструкция выполнялась за секунды.
Очистку мы выполняем с помощью простого кода, приведенного на изображении. В запросе выбираем 5000 записей по узлу из таблицы регистрации регистра.

Далее выполняем обход результата запроса и заполняем массив отборами с наборами записей по полям выборки. Затем типовым способом выполняем частичную очистку таблицы регистрации.

Снимаем логи выполнения на Postgres. На слайде приведен запрос, который 1С передает Postgres. Видно, что подготовлены две временные таблицы: tt3 с 5000 записями данных для удаления и tt4 с узлами (узел один). Данные этих таблиц перемножаются, и по полученным строкам выполняется удаление записей.
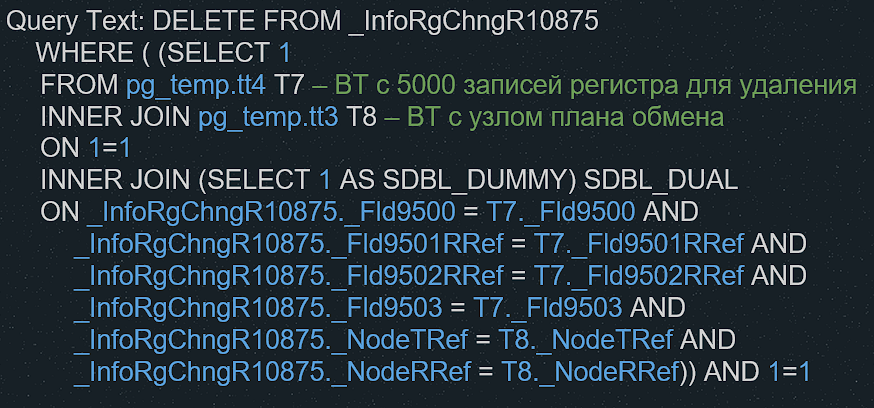
Далее представлен план выполнения запроса. Из него видно, что основное время тратится не на удаление записей, а на их поиск. Оптимизатор выбрал полный обход всей таблицы: для каждой строки применяется обычный подплан.
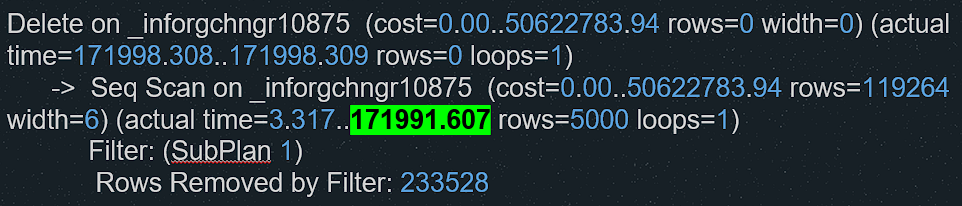
А в подплане выполняется соединение 238 тысяч раз с вложенным циклом по строкам tt4 и соединение 5000 раз с таблицей tt3. То есть фактически выполняется 238 тысяч * 5000 итераций.
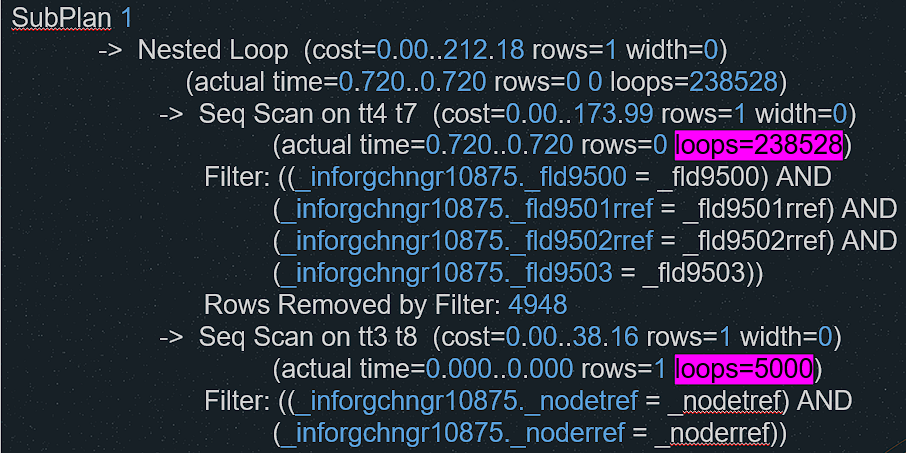
Казалось бы, оптимизатор Postgres должен выбрать более корректный план – например, индексное сканирование таблицы, ведь индекс фактически есть. Но Postgres работает так, как работает. Мы написали в поддержку 1С, они приняли ошибку и сообщили, что исправят. Пока же мы вынуждены удалять записи по одной строке. Это, казалось бы, не оптимально – выполняется 5000 отдельных DELETE, но это на порядки быстрее, чем тот план, который выбирает Postgres при пакетном удалении.
Необходимость расширенной статистики
Расскажу о еще одном неочевидном для Postgres-кейсе – необходимости использования расширенной статистики. По умолчанию Postgres собирает статистику по каждому столбцу отдельно. В нее входит информация о распределении значений, количестве уникальных записей и так далее. Есть глобальные параметры Postgres, есть настройки таблиц по автоматическому вычислению статистики. Однако такая статистика не учитывает зависимости между столбцами, которые участвуют в отборах, группировках и других конструкциях запроса.
Расширенная статистика позволяет собирать информацию о взаимосвязях между несколькими столбцами. Это помогает оптимизатору точнее оценивать селективность условий, когда отборы накладываются на несколько столбцов. Это отдельная тема, подробно останавливаться на ней не буду.
Расскажу на примере, как мы столкнулись с этим и впервые начали использовать. Пользователи пожаловались, что изменение отбора в динамическом списке регистра сведений выполняется очень долго, что на Microsoft SQL все работало быстро, а на Postgres стало медленно. Начали разбираться.
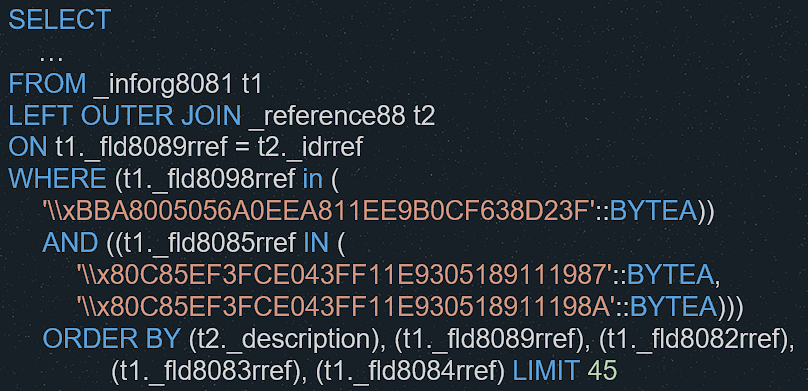
Выше приведен текст запроса, который 1С отправляет на Postgres. Видно, что это простая выборка из регистра сведений. Одно левое соединение для получения значения по ссылке, два отбора: один по индексированному ресурсу, второй – по неиндексированному четвертому измерению. И добавлены сортировки, причем первая сортировка – по таблице, участвующей в соединении.
Далее показан основной узел плана запроса. Видно, что оптимизатор ошибся с оценкой количества строк в основной выборке и выбрал битовую карту. Он ожидал 10 миллионов строк – почти половину регистра, а фактически там оказалось 28 тысяч. Стандартная статистика по одной колонке не помогла оптимизатору, и он ошибся.
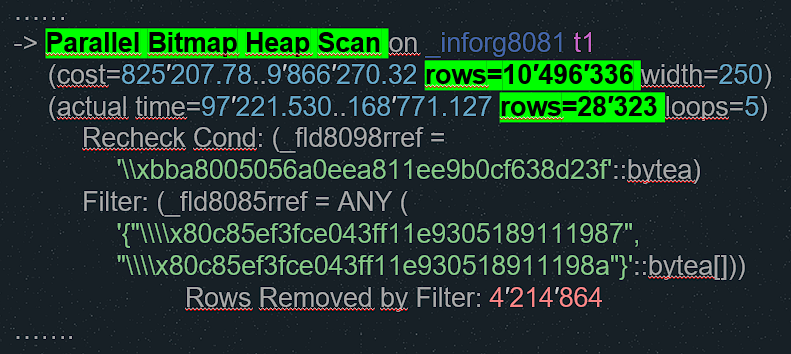
Мы создали расширенную статистику по двум столбцам, участвующим в отборе, по следующему скрипту:

После этого оптимизатор перестал ошибаться, отказался от битовой карты и начал использовать индексное сканирование.
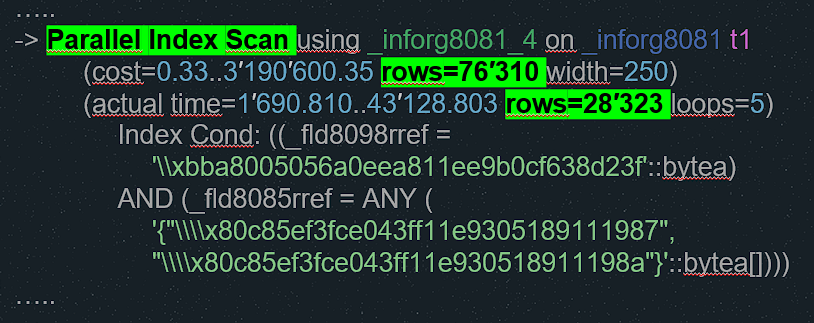
В остальном планы запроса одинаковые, но если в первом случае запрос выполнялся 169 секунд, то во втором – 43 секунды. Если бы пользователи не добавили тяжелую сортировку, запрос работал бы еще быстрее, но в этой части мы ничего сделать не можем.
Microsoft SQL перед выполнением запроса оценивает, достаточно ли существующей статистики, и если нет, создает новую статистику. Обычно это статистика по одному столбцу, но иногда и по двум, трем, реже – по большему количеству. Также в Microsoft SQL можно создавать пользовательскую многоколоночную статистику. Такая статистика по смыслу соответствует расширенной статистике в Postgres.
Если многоколоночная статистика использовалась на Microsoft SQL, логично было бы перенести ее в расширенную статистику Postgres. Тем более что такой статистики мало. Например, на КИСе всего 54 многоколоночных автоматических статистик и одна создана вручную – при том, что всего оптимизатор создал около 21 тысячу статистик. Оценить количество многоколоночной статистики можно по системному представлению sys.stat – например, выполнением запроса, приведенного на изображении.

Прочие проблемы эксплуатации
Если вы используете вьюхи, следующая проблема вас заинтересует. В консолидации у нас есть множество представлений, которые используются сторонними системами. В некоторых из них используется справочник «Организации». После того, как мы добавили реквизит в этот справочник, все представления, в которых он использован, мистическим образом исчезли.
Мы стали разбираться, посмотрели журнал Postgres – там пусто. Почему? Потому что в конфигурации Postgres есть параметр log_statement, который по умолчанию отключен: у него значение none. Если бы значение было ddl, то в журнал Postgres записывались бы системные команды, изменяющие структуру таблиц: CREATE, ALTER, DROP и другие.
Эту настройку мы включать не стали, потому что журнал был бы завален ненужной информацией. Но теперь мы готовы быстро пересоздать представления в случае их удаления.
Еще одна проблема, с которой мы столкнулись, заключается в том, что невозможно сделать логическую репликацию большой базы. Мы не смогли выполнить репликацию нашей консолидации, что бы ни предпринимали. В этом случае приходится использовать только физическую репликацию, а это не всегда удобно, так как нужно копировать целиком кластер.
Для нашей консолидации мы используем систему DataBase Lab.
Проблемы с блокировками от автовакуума
Напоследок расскажу об очень интересной проблеме, которую мы нашли в консолидации. Автовакуум может блокировать таблицы. Проблема была плавающей, мы нашли ее не сразу и потратили много времени.
Как вы знаете, автовакуум выполняет очистку таблиц, удаляя устаревшие версии строк. При этом он накладывает блокировку ShareUpdateExclusiveLock. Это мягкая блокировка, она позволяет другим сеансам Postgres не только читать, но и изменять данные.
Но у таблиц Postgres есть параметр vacuum_truncate, который по умолчанию включен. И если он включен, то после очистки от ненужных версий автовакуум выполняет отсечение пустых страниц, возвращая их операционной системе. Именно при этом отсечении он накладывает самый строгий уровень блокировки – ACCESS EXCLUSIVE, который полностью блокирует таблицу.
В результате мы ловили такие ошибки блокировки по таймауту: ERROR: canceling statement due to lock timeout. Они сыпались в ТЖ через exception. Начали расследовать, но в логах Postgres ничего не было. Причина – нужно правильно настроить параметры логирования.
Мы начали с log_lock_waits = on. Этот параметр позволяет журналировать ожидания блокировок. Затем настроили log_statement = ddl (о нем я рассказывал выше), чтобы в журнал записывались служебные операторы. И установили параметр deadlock_timeout=15000, который определяет длительность ожидания, после которой в журнал пишется сообщение о блокировке.
-- 1. Autovacuum устанавливает блокировку
[25469] LOG: automatic vacuum of table " public._inforg8081": index scans: 1
[25469] LOG: process 25469 acquired AccessExclusiveLock on relation 176812
[25469] CONTEXT: automatic vacuum of table "public._inforg8081"
-- 2. SELECT, который ждет блокировку (ЖЕРТВА)
[19657] LOG: process 19657 still waiting for AccessShareLock on relation 176812….
[19657] DETAIL: Process holding the lock: 25469. Wait queue: 1.
[19657] STATEMENT: SELECT …. FROM _inforg8081 …..;
После этого журнал стал ощутимо расти. Пришлось покопаться, но нужные логи нашли. Вначале нашли лог по ожиданию блокировки – он приведен под номером 2. Поиск мы выполняли по тексту запроса. В нем нашли PID блокирующего процесса и по нему нашли логи виновника, указанные под номером 1. И виновником оказался автовакуум.
Для проблемной таблицы и еще одной похожей мы не стали отключать флаг vacuum_truncate, потому что тогда пришлось бы выполнять очистку вручную. Мы просто уменьшили параметр autovacuum_vacuum_scale_factor с 0,2 до 0,1. Теперь автоочистка запускается при изменении 10% строк таблицы. В этом случае она выполняется быстрее, отсечение пустых страниц происходит быстрее, и блокировки мы больше не ловим.
Выводы и перспективы
Основной вывод – не нужно бояться переходить на Postgres. Если решите переходить, жизнь станет намного веселее. А если серьезно, мы прожили год, падений баз не было, нерешаемых проблем не возникало, все работает корректно.
Если в базе есть сложные самописные запросы, скорее всего, их придется оптимизировать позже, но это будет способствовать вашему росту как специалиста по написанию корректных запросов.
Перед переходом неплохо прогнать вашу базу через нашу систему автотестирования, чтобы выявить запросы, которые можно оптимизировать заранее. В начальный период эксплуатации стоит использовать Elastic и Sentry.
И самое главное: переход на Postgres в нашей компании не завершен. Впереди такие монстры, как база ЦУК в 30 терабайт и наш любимый КИС, который еще недавно весил 120 терабайт. Это интересные задачи, возможно, ими я поделюсь в будущих статьях.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.


Вступайте в нашу телеграмм-группу Инфостарт