Рассмотрим только динамические списки с динамическим считыванием данных, т.к. без динамического считывания данных платформа исполняет обычный запрос, для которого действуют общие правила оптимизации.
Динамические списки достаточно чувствительны к качеству текста запроса. Такие запросы, как правило, выполняются очень часто и многими пользователями, поэтому неоптимальная реализация приводит к повышенной нагрузке на железо и замедлению работы системы в целом.
При написании текста запроса следует учитывать то, что при его исполнении в динамическом списке платформа модифицирует запрос - добавляется выбор порции данных ("ПЕРВЫЕ N"), условие на граничную ссылку, а также сортировка по дате и ссылке или по определенным в настройках полям сортировки. Таким образом, отладка текста запроса через консоль не является правильным, т.к. платформа фактически будет исполнять совсем другой запрос.
Дополнительные неудобства доставляет тот факт, что в платформе нет удобных инструментов для отладки запросов динамических списков. Стандартный замер производительности ничего не покажет. Но получить длительность и план исполнения запроса можно через технологический журнал, или трассировку запросов в СУБД.
Рассмотрим несколько примеров и способов их оптимизации.
Запросы упрощены, чтобы более четко была видна проблема.
Пример 1. Вывод простого признака, основываясь на данных других таблиц.
Очень частый сценарий. Например, пользователи просят вывести в списке реализации признак наличия счет-фактуры, или признак наличия прикрепленных файлов и т.д. и т.п.
Много раз сталкивался с тем, что это реализовывали путем левого соединения таблиц с последующей группировкой:
ВЫБРАТЬ
Р.Ссылка,
Р.Контрагент,
Р.Склад,
МАКСИМУМ(ВЫБОР
КОГДА Х.Ссылка ЕСТЬ NULL
ТОГДА ЛОЖЬ
ИНАЧЕ ИСТИНА
КОНЕЦ) КАК ЕстьСФ
ИЗ
Документ.РеализацияТоваровУслуг КАК Р
ЛЕВОЕ СОЕДИНЕНИЕ Документ.СчетФактураВыданный КАК Х
ПО Р.Ссылка = Х.ДокументОснование
СГРУППИРОВАТЬ ПО
Р.Ссылка,
Р.Контрагент,
Р.Склад
При фактическом выполнении запроса получаем такую статистику:
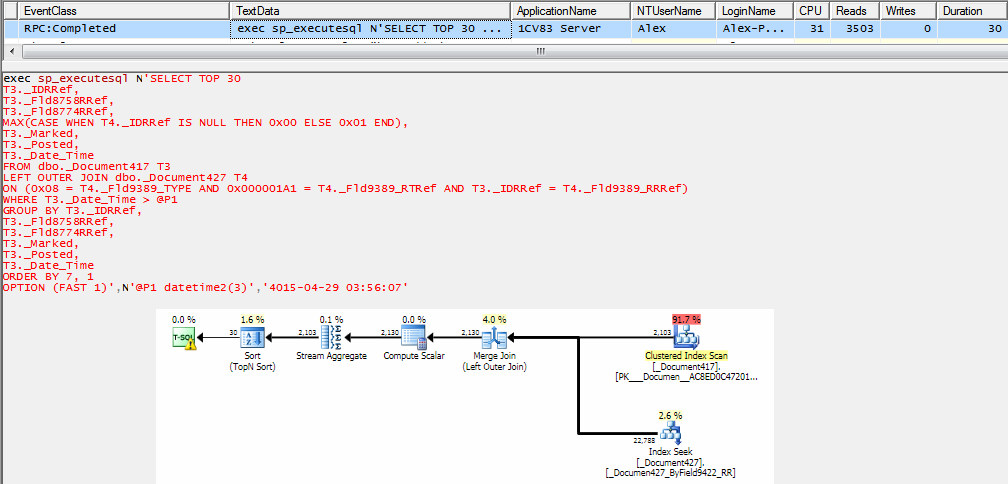
В плане запроса на стрелках обозначено количество обработанных строк из таблиц.
Или такой вариант в комментариях предлагают:
ВЫБРАТЬ
Р.Ссылка,
Р.Контрагент,
Р.Склад,
ЕСТЬNULL(Х.Признак, ЛОЖЬ) КАК ЕстьСФ
ИЗ
Документ.РеализацияТоваровУслуг КАК Р
ЛЕВОЕ СОЕДИНЕНИЕ (ВЫБРАТЬ РАЗЛИЧНЫЕ
ИСТИНА КАК Признак,
Х.ДокументОснование КАК ДокументОснование
ИЗ
Документ.СчетФактураВыданный КАК Х) КАК Х
ПО Р.Ссылка = Х.ДокументОснование
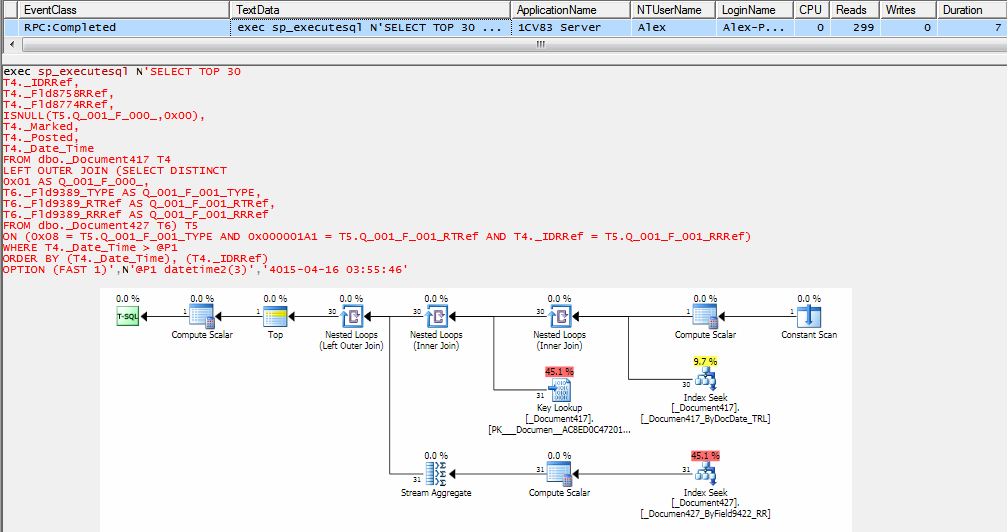
Во втором случае ситуация значительно лучше, но когда начинают соединять по 3-4-5 таблиц, а еще и со вложенными запросами без отборов (например, виртуальные таблицы), то время исполнения запроса увеличивается в разы и порядки.
При этом важно понимать, что второй запрос также крайне не оптимален - вложенный подзапрос не содержит отбора.
В MSSQL он работает быстро, т.к. оптимизатор этой СУБД достаточно "умный" и понимает, что можно отфильтровать данные, а не выбирать все.
Пробуем выполнить похожий запрос в файловой базе, и видим, что все плохо.
Выполнение запроса заняло 1,5 секунды, а выборка затронула 27 тысяч строк.
18:36.368001-155991,DBV8DBEng,2,process=1CV8C,Trans=0,Sql="SELECT TOP 45
T4._IDRRef,
T4._Fld2070RRef,
ISNULL(T5.Q_001_F_000_,FALSE),
T4._Marked,
T4._Posted,
T4._Date_Time
FROM _Document59 T4
LEFT OUTER JOIN (SELECT DISTINCT
TRUE AS Q_001_F_000_,
T6._Fld428_TYPE AS Q_001_F_001_TYPE,
T6._Fld428_RTRef AS Q_001_F_001_RTRef,
T6._Fld428_RRRef AS Q_001_F_001_RRRef
FROM _Reference53 T6) T5
ON (0x08 = T5.Q_001_F_001_TYPE AND 0x0000003B = T5.Q_001_F_001_RTRef AND T4._IDRRef = T5.Q_001_F_001_RRRef)
WHERE T4._Date_Time < {ts '2015-05-14 17:49:12'}
ORDER BY (T4._Date_Time) DESC, (T4._IDRRef) DESC",NParams=0,
planSQLText='Fields:(
T4._IDRRef,
T4._Fld2070RRef,
ISNULL(T5.Q_001_F_000_,FALSE),
T4._Marked,
T4._Posted,
T4._Date_Time
)
_DOCUMENT59 (T4) RANGE SCAN USING REVERSE INDEX (_DOCUMENT59_BYDOCDATE_TRL) (1 fields)
NESTED OUTER LOOP BY SELECT RANGE SCAN USING INDEX (AUTOINDEX) (1 fields)
(
Fields:(
TRUE,
T6._Fld428_TYPE,
T6._Fld428_RTRef,
T6._Fld428_RRRef
)
_REFERENCE53 (T6) FULL SCAN
WITHOUT DUPLICATES
SORTING
)
WHERE
(08 = T5.Q_001_F_001_TYPE)
AND
(0000003B = T5.Q_001_F_001_RTRef)
AND
(T4._IDRRef = T5.Q_001_F_001_RRRef)
Statistics: RecordsScanned = 27345, ParseTime = 0, ExecuteTime = 79, BuffersMemory = 25699, ResultRecords = 45, RecordSize = 57',Rows=45,Context=ДинамическийСписок.ПолучитьДанные : ВнешняяОбработка.ВнешняяОбработка1.Форма.Форма.Реквизит.ДС
Конкретно в этом примере пользователю не нужна информация из таблицы со счет-фактурами, важен лишь факт, что для текущей реализации там есть хотя бы одна строка.
Запрос можно преобразовать в декларативном стиле:
ВЫБРАТЬ
Р.Ссылка,
Р.Контрагент,
Р.Склад,
ВЫБОР
КОГДА 1 В
(ВЫБРАТЬ ПЕРВЫЕ 1
1
ИЗ
Документ.СчетФактураВыданный КАК Х
ГДЕ
Р.Ссылка = Х.ДокументОснование)
ТОГДА ИСТИНА
ИНАЧЕ ЛОЖЬ
КОНЕЦ КАК ЕстьСФ
ИЗ
Документ.РеализацияТоваровУслуг КАК Р
Несколько раз слышал от "true SQL DBA", что такой подход не очень желателен, т.к. оставляет меньше свободы оптимизатору СУБД на выбор плана исполнения, но работает ведь существенно быстрее!
Оптимизированный запрос:
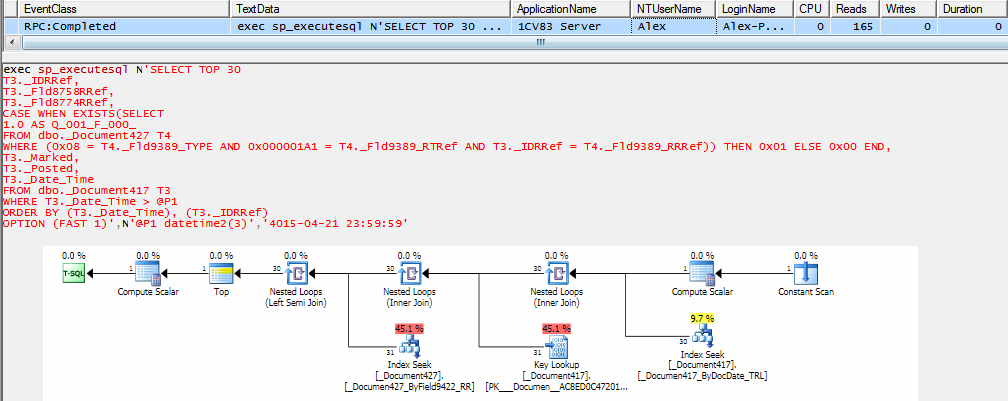
В файловом варианте все также работает быстро:
31:41.704020-3,DBV8DBEng,2,process=1CV8C,Trans=0,Sql="SELECT TOP 45
T3._IDRRef,
T3._Fld2070RRef,
CASE WHEN EXISTS(SELECT
1 AS Q_001_F_000_
FROM _Reference53 T4
WHERE (0x08 = T4._Fld428_TYPE AND 0x0000003B = T4._Fld428_RTRef AND T3._IDRRef = T4._Fld428_RRRef)) THEN TRUE ELSE FALSE END,
T3._Marked,
T3._Posted,
T3._Date_Time
FROM _Document59 T3
WHERE T3._Date_Time < {ts '2015-05-26 14:54:58'}
ORDER BY (T3._Date_Time) DESC, (T3._IDRRef) DESC",NParams=0,planSQLText='Fields:(
T3._IDRRef,
T3._Fld2070RRef,
CASE WHEN EXISTS(SELECT
Fields:(
1
)
_REFERENCE53 (T4) RANGE SCAN USING INDEX (_REFERENC53_BYFIELD8195_RSRL) (3 fields)
WHERE
(0000003B = T4._Fld428_RTRef)
AND
(T3._IDRRef = T4._Fld428_RRRef)
) THEN TRUE ELSE FALSEEND,
T3._Marked,
T3._Posted,
T3._Date_Time
)
_DOCUMENT59 (T3) RANGE SCAN USING REVERSE INDEX (_DOCUMENT59_BYDOCDATE_TRL) (1 fields)
Statistics: RecordsScanned = 61, ParseTime = 1, ExecuteTime = 0, BuffersMemory = 25699, ResultRecords = 45, RecordSize = 57',Rows=45,Context=ДинамическийСписок.ПолучитьДанные : ВнешняяОбработка.ВнешняяОбработка1.Форма.Форма.Реквизит.ДС
При этом исполнение оптимизированного запроса вне динамического списка (без порционной выборки), вероятно, покажет более плохой результат, чем исходный запрос.
т.е. подобная оптимизация работает только при выборке малого количества строк из основной таблицы.
Пример 2. Соединение таблицы с небольшим набором относительно статичных данных.
Из недавних примеров - список документов нужно фильтровать по таблице с разрешенными складами для данного пользователя.
RLS, видимо, тут не подошел.
ВЫБРАТЬ
Р.Ссылка,
Р.Контрагент,
Р.Склад
ИЗ
Документ.РеализацияТоваровУслуг КАК Р
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.РазрешенныеСклады.СрезПоследних(, Пользователь = &Пользователь) КАК РазрешенныеСкладыСрезПоследних
ПО Р.Склад = РазрешенныеСкладыСрезПоследних.Склад
Тут еще и срез последних без передачи отбора по Складу внутрь параметров виртуальной таблицы...
Но зачем вообще вовлекать регистр сведений в этот запрос? Перечень складов относительно небольшой и статичный, его можно сформировать при открытии формы, а затем передать как параметр запроса динамического списка.
ВЫБРАТЬ
Р.Ссылка,
Р.Контрагент,
Р.Склад
ИЗ
Документ.РеализацияТоваровУслуг КАК Р
ГДЕ
Р.Склад В(&Склады)
Понятно, что появляются ограничения - разрешенные склады фактически кэшируются и пользователю придется закрыть и открыть форму заново, чтобы применились изменения в регистре с разрешенными скаладам. В большинстве случаев, это должно быть приемлемо.
Пример 3. Использование "В ИЕРАРХИИ" в условии запроса.
Частным сценарием является фильтрация списка по группе элементов (группа складов или группа номенклатуры, например).
Пользователям выносят на форму поле для выбора группы и при его изменении передают параметр в динамический список.
ВЫБРАТЬ
Р.Ссылка,
Р.Контрагент,
Р.Склад
ИЗ
Документ.РеализацияТоваровУслуг КАК Р
ГДЕ
Р.Склад В ИЕРАРХИИ(&ГруппаСкладов)
В этом случае, платформа будет формировать перечень складов, входящих в данную группу при каждом обновлении списка. Результат не кэшируется!
Вот трассировка одного обновления формы списка для данного запроса:
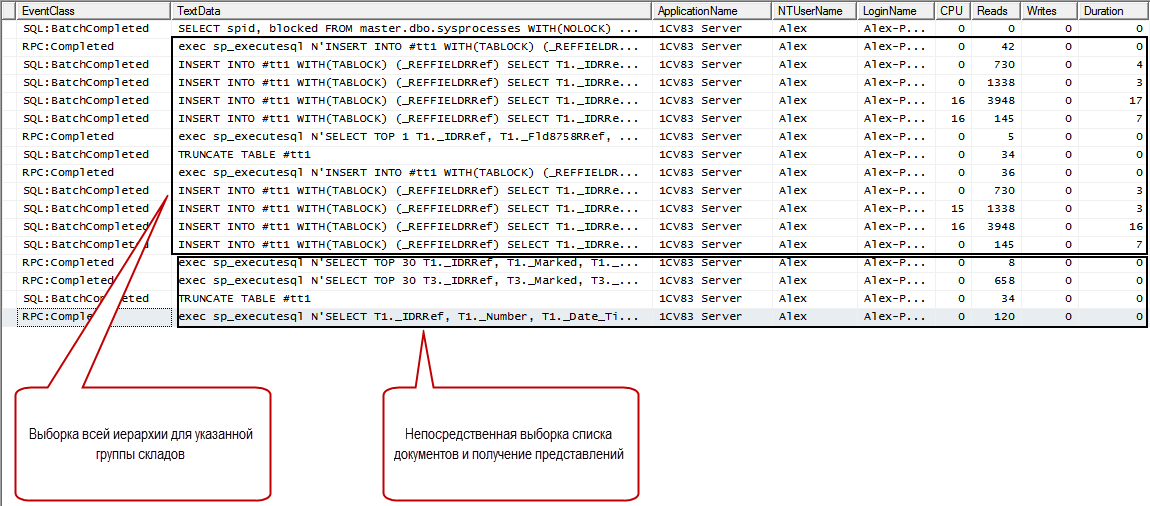
Видно, что на формирование иерархии ушло значительно больше ресурсов, чем на непосредственную выборка списка реализаций по этим складам.
Решением может быть самостоятельное формирование списка складов при изменении отбора и передача его в качестве параметра - это позволит заменить "В ИЕРАРХИИ" на просто "В".
Выбраем все склады вне динамического списка:
ВЫБРАТЬ
Склады.Ссылка
ИЗ
Справочник.Склады КАК Склады
ГДЕ
Склады.Ссылка В ИЕРАРХИИ(&ГруппаСкладов)
Выгружаем в массив и передаем в динамический список.
Запрос при этом упрощается до:
ВЫБРАТЬ
Р.Ссылка,
Р.Контрагент,
Р.Склад
ИЗ
Документ.РеализацияТоваровУслуг КАК Р
ГДЕ
Р.Склад В (&СписокСкладов)
Количество запросов к MSSQL уменьшается:

При этом следует учесть, что в платформе есть определенное ограничение на количество параметров, передаваемых в запрос (256?).
Если число элементов в параметре "&СписокСкладов" превысит это ограничение, то платформа меняет текст запроса.
Вместо обычной выборки из списка:
WHERE ((T1._Fld8774RRef IN (@P1, @P2, @P3, @P4, @P5, ...)
будет выборка из временной таблицы:
WHERE (T3._Fld8774RRef IN
(SELECT
T4._INVALUELISTRRef AS INVALUELISTRRef
FROM #tt4 T4 WITH(NOLOCK)
WHERE T4._INVALUELISTRRef IS NOT NULL))
А наполнение этой временной таблицы будет происходить при каждом обновлении динамического списка и эффект от оптимизации будет уже менее заметен.
Пример 4. Из смежных таблиц требуется получение дополнительных данных.
Например, в списке реализаций вывести номер выданной счет-фактуры, или отобразить статус документа по данным периодического регистра сведений.
В простых случаях особых проблем с быстродействием не будет заметно, но условия чуть сложнее вызовут существенное замедление.
Вот это, например, работает довольно медленно:
ВЫБРАТЬ
ДокументСчетФактураПолученный.Ссылка,
ДокументСчетФактураПолученный.ВерсияДанных,
ДокументСчетФактураПолученный.ПометкаУдаления,
ДокументСчетФактураПолученный.Номер,
...
МАКСИМУМ(ЗначенияСвойствОбъектов.Значение) КАК НомерЗаявкиНаОсвоение
ИЗ
Документ.СчетФактураПолученный КАК ДокументСчетФактураПолученный
ЛЕВОЕ СОЕДИНЕНИЕ Документ.СчетФактураПолученный.ДокументыОснования КАК СчетФактураПолученныйДокументыОснования
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ЗначенияСвойствОбъектов КАК ЗначенияСвойствОбъектов
ПО СчетФактураПолученныйДокументыОснования.ДокументОснование = ЗначенияСвойствОбъектов.Объект
И (ЗначенияСвойствОбъектов.Свойство = ЗНАЧЕНИЕ(ПланВидовХарактеристик.СвойстваОбъектов.ПереданОригиналВБухгалтерию))
ПО (СчетФактураПолученныйДокументыОснования.Ссылка = ДокументСчетФактураПолученный.Ссылка)
СГРУППИРОВАТЬ ПО
ДокументСчетФактураПолученный.Ссылка,
ДокументСчетФактураПолученный.ВерсияДанных,
ДокументСчетФактураПолученный.ПометкаУдаления,
ДокументСчетФактураПолученный.Номер
Как мне кажется, оптимальным решением тут было бы кэширование результатов в промежуточной таблице.
Создать регистр сведений "КэшЗначенийСчетФактураПолученный" с измерением "Объект" и ресурсом "НомерЗаявкиНаОсвоение".
Запись в этот регистр сведений производить при записи самого счет-фактуры, а также при записи самой "заявки на освоение" (если изменился номер, то найти введенные СФ и обновить номера в регистре).
Дополнительная нагрузка на систему будет создана несущественная, а вот информацию для вывода в динамический список можно будет получить значительно легче.
Запрос получается существенно проще:
ВЫБРАТЬ
ДокументСчетФактураПолученный.Ссылка,
ДокументСчетФактураПолученный.ВерсияДанных,
ДокументСчетФактураПолученный.ПометкаУдаления,
ДокументСчетФактураПолученный.Номер,
ЕСТЬNULL(КэшЗначенийСчетФактураПолученный.НомерЗаявкиНаОсвоение, "") КАК НомерЗаявкиНаОсвоение
ИЗ
Документ.СчетФактураПолученный КАК ДокументСчетФактураПолученный
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.КэшЗначенийСчетФактураПолученный КАК КэшЗначенийСчетФактураПолученный
ПО ДокументСчетФактураПолученный.Ссылка = КэшЗначенийСчетФактураПолученный.Объект
Пример 5. Сложные опциональные отборы
Часто пользователям необходимо дать возможность фильтровать списки по некоторым сложным отборам, которые нельзя просто установить в виде параметров отбора.
Пример из нашей практики: есть список документов "Инцидент" и регистр сведений с комментариями пользователей по этим инцидентам. Пользователи просили дать возможность отбирать список документов по пользователям из комментариев, например, показать все инциденты, которые прокомментировал Иванов.
Стандартным отбором тут не обойтись, и как вариант, можно доработать запрос динамического списка:

Если параметр "Автор комментария" заполнен пустой ссылкой - срабатывает левая часть условия и показываются все документы.
Если в параметре указан пользователь, то список фильтруется по регистру сведений.
При этом СУБД для обоих вариантов будет строить одинаковый план запроса с выборкой из регистра сведений. В некоторых ситуациях это влияет на производительность весьма негативно.
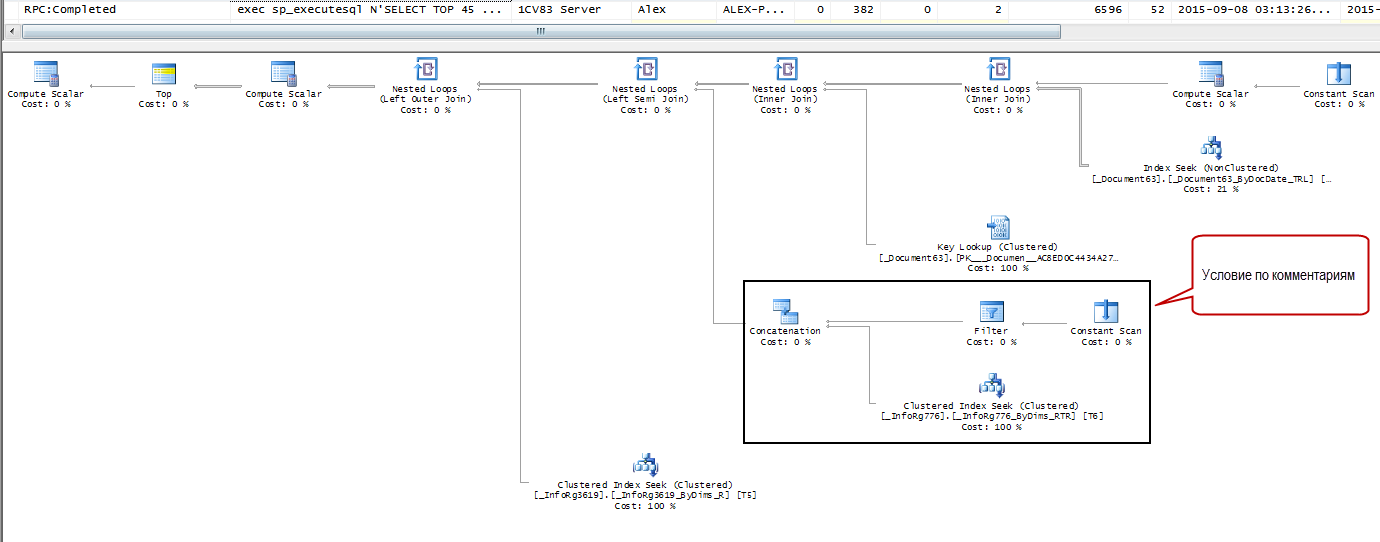
Чтобы обойти эту проблему - необходимо переписать запрос с использованием функционала компоновки. Фактически сделать условие опциональным:

В этом случае, если параметр "Автор комментария" не заполнен, то данный участок исключается из текста запроса.
План запроса при этом получается чуть проще:
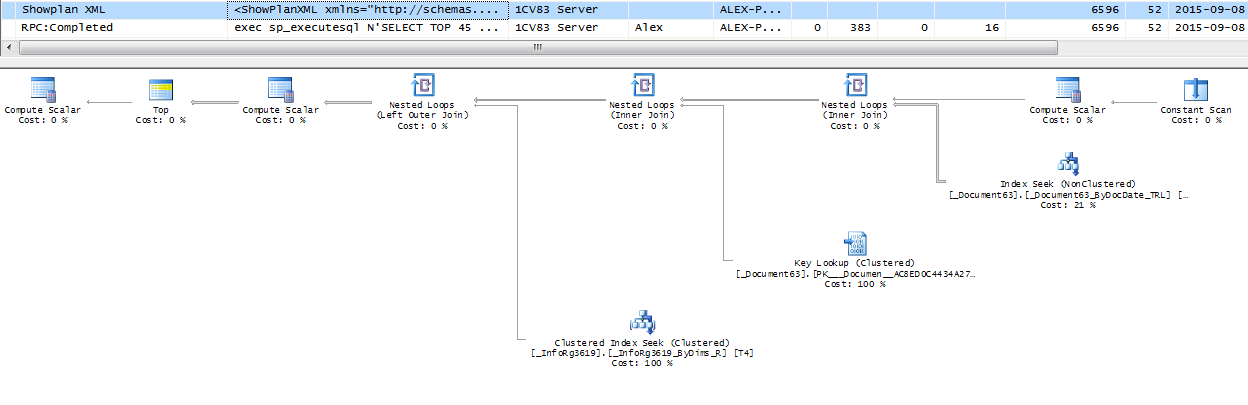
Если параметр установлен, то план запроса будет точно таким же, как и в предыдущей ситуации.
Аналогично функционал компоновщика можно задействовать для опционально отображаемых полей, исключая при этом ненужные в данном контексте соединения и поля.
Буду признателен за комментарии с дополнениями и собственным опытом.
Вступайте в нашу телеграмм-группу Инфостарт
