


Тема разбора табличного документа (Excel, OpenOffice и др.) уже не раз поднималась. Но, к сожалению, почти все решения предполагали использование COM объектов.
Внимательно изучив публикации Андрея М. (//infostart.ru/profile/260967/), в которых были рассмотрены все возможные методы загрузки, включая Open XML и с помощью Табличного документа 1С, я пришел к выводу, что можно все-таки получить структуру файла табличного документа, не прибегая к COM объектам.
Остановился на встроенных средствах 1С – загрузка в Табличный документ 1С. Все бы хорошо, но из табличного документа 1С так и не удалось получить иерархию строк. После нескольких часов танцев с бубном решение было найдено – сериализация (позже мне попалась статья Якова Когана //infostart.ru/public/562724/; но в ней он рассмотрел только общую концепцию разбора табличного документа, не вникая в детали; но все равно огромный респект за неординарный подход).
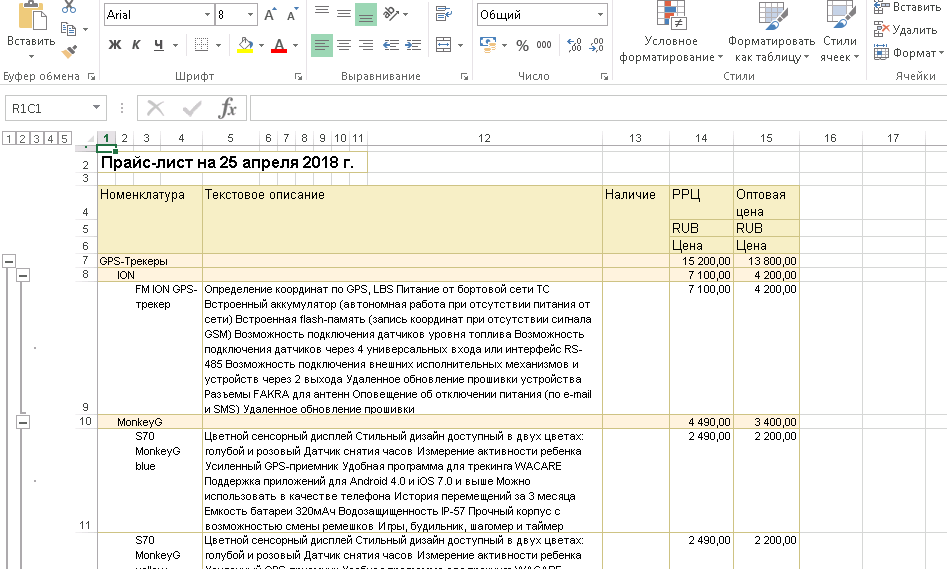
Так, родилась данная обработка, позволяющая разобрать файлы табличных документов по ячейкам, получить форматы ячеек и группировки строк (группировку колонок не рассматривал за ненадобностью). Предупреждаю, что это демонстрационный пример, как можно разобрать данные используя Табличный документ 1С. Полная версия данной разработки для каждого конкретного вида файлов определяет свой метод разбора (потому, как, например, для формата Open XML разбор файла в данной обработке происходит следующим образом: загрузка в табличный документ 1С, сериализация, разбор дерева DOM; хотя, по сути, файл Open XML можно разбирать «напрямую», минуя загрузку в табличный документ).
Обработка работает следующим образом. Определяется формат выбранного файла. Если формат отличен от XLSX, XLS и ODS, тогда файл преобразуется в формат XLSX (вот здесь я использую COM объект – прошу учесть, что это демонстрационная обработка). После чего данные из файла загружаются в табличный документ 1С, сериализуются и разбираются «по кусочкам».
Все это делает функция РазборФайла, возвращающая адрес во временном хранилище с обработанными данными. Обработанные данные имеют вид структуры, в которой:
- МассивДанных – собственно данные в виде двумерного массива; в каждой ячейке массива структура вида «значение,стиль» или пусто;
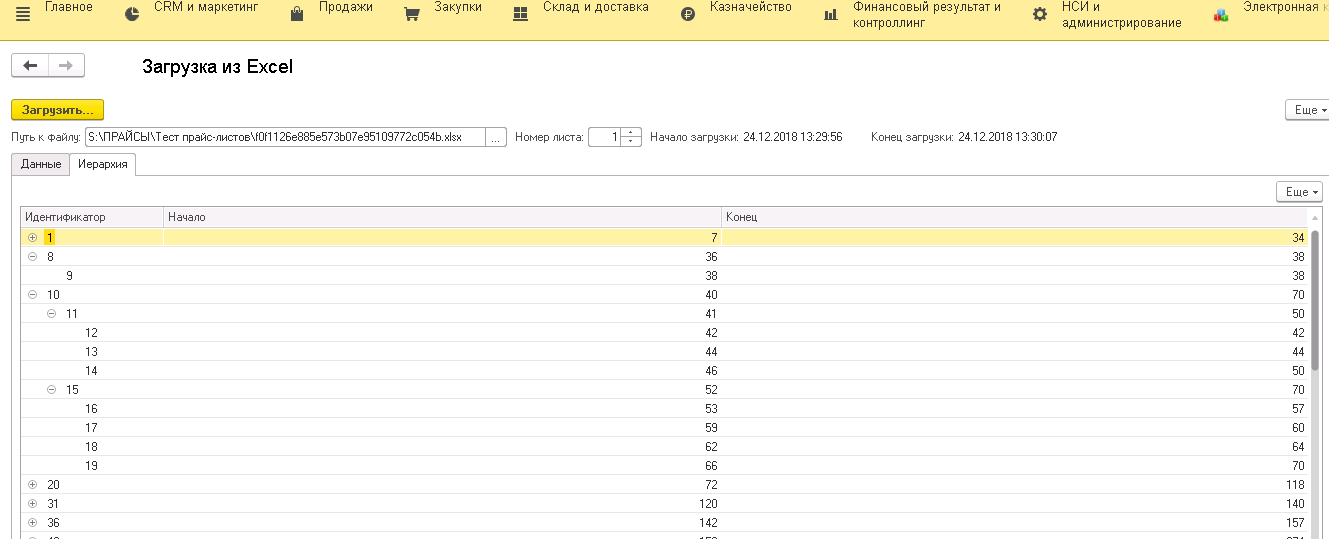
- Колонки – таблица значений: индекс (номер) и стиль колонок;
- Группировки – дерево значений – иерархия группировок строк, как она есть: идентификатор (номер), начальная строка, конечная строка;
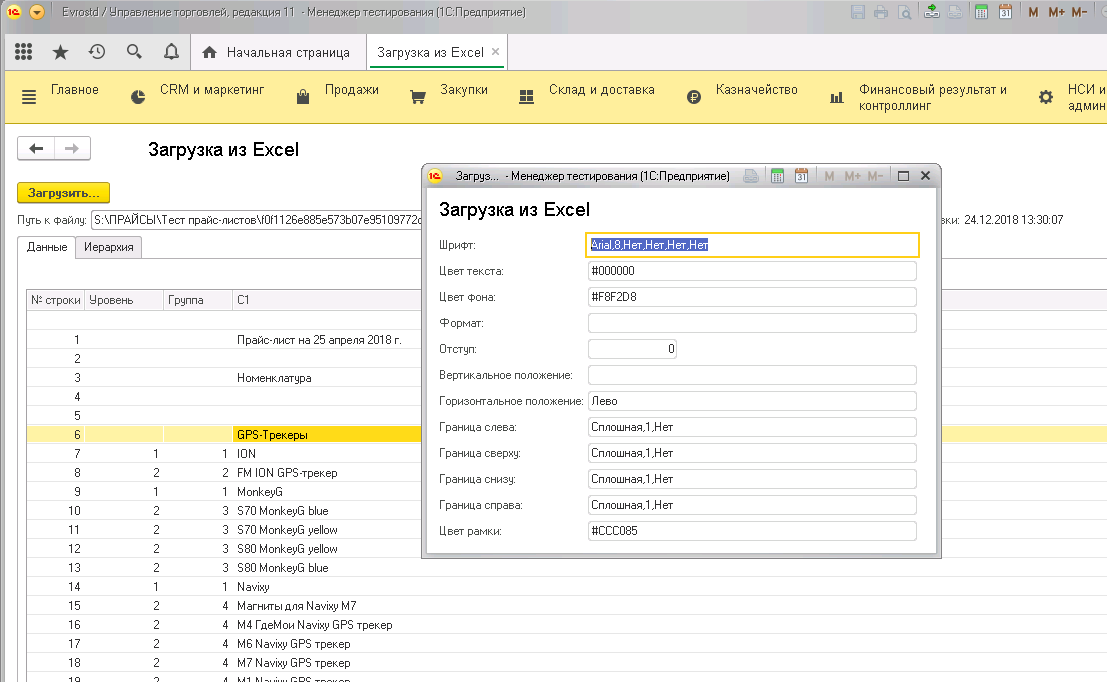
- ТаблицаСтилей – таблица значений с описанием стиля ячейки или колонки: Код, Формат, ОписаниеТипов, Ширина, Шрифт, ЦветТекста, ЦветФона, Отступ, ГоризонтальноеПоложение, ВертикальноеПоложение, ГраницаСверху, ГраницаСнизу, ГраницаСправа, ГраницаСлева, ЦветРамки
- НомерЛиста – фактический номер разобранного листа;
- ИмяЛиста – фактическое имя разобранного листа.
Как пользоваться этими данными, можно посмотреть в функции ОбработатьФайлНаСервере
Обработка рассчитана на любую конфигурацию на базе БСП и релиз платформы не ниже 8.3.10. (Тестировалась на 8.3.12.1440).
Вступайте в нашу телеграмм-группу Инфостарт
{kind=link}