Работает на УТ 10.3 ЛЮБОЙ версии.
Обработка полностью рабочая и тестировалась на версиях УТ 10.3.46.3, 10.3.10.3.52.1, 10.3.58.2.
Обработка проверялась на платформе 8.2.19.130, 8.3.13.1926, 8.3.19.1264.
Обработка работает на обычных формах.
Скорость работы - во многом зависит от компьютера.
На проведенных тестах - свертка базы с 1 350 000 документами проходила - 6 часов.
Инструкция
1. Делаем резервную копию информационной базы.
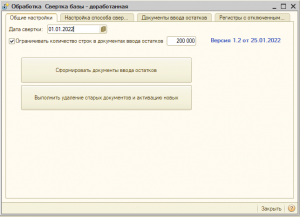
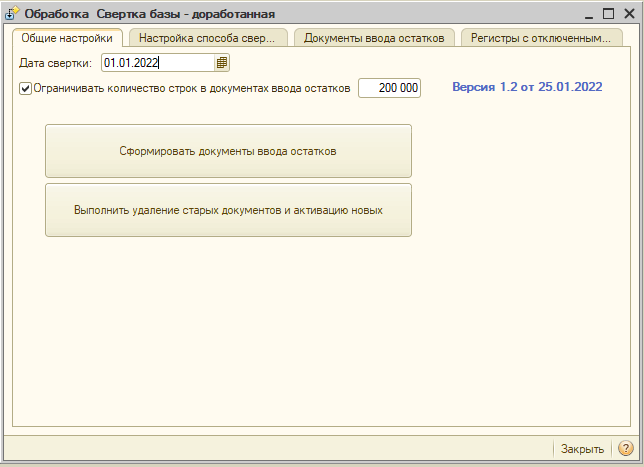
2. Открываем обработку.
а) Устанавливаем дату свертки. Например, если нужно сделать свертку на начало текущего года ставим 01.01.2022.
Документы корректировки будут созданы на 31.12.2021 23:59:59.
б) Нажимаем кнопку "Сформировать документы ввода остатков"
в) Нажимаем кнопку "Выполнить удаление старых документов и активацию новых"
3. Можно сделать дополнительную резервную копию.
4. Запускаем базу в режиме конфигуратора и выполняем тестирование с очисткой ссылок и удалением объектов.
Причины купить
- Быстро, удобно, простой интерфейс
- Подходит для всех версий УТ 10.3.
- Можно использовать много раз, на разных базах.
- Позволяет экономить много времени. Т.к. свертка чаще всего происходит в нерабочее время, это достаточно большой плюс.
- Для программистов - сможете сэкономить время на разработку и оптимизацию.
- Пользователь сам сможет выполнить свёртку и проверить результат.
Достоинства
- Свертка выполняется в несколько раз быстрее, чем стандартная.
- Удаление документов и ссылок на них самым оптимальным образом.
- В отличии от стандартной удаление документов происходит непосредственно без предварительных подготовительных этапов. Контроль возможности удаления не осуществляется. Большинство битых ссылок удаляются в процессе работы обработки. Оставшиеся ссылки удаляются при тестировании и исправлении.
- При удалении документов стандартной обработкой на больших базах часто происходит вылет программы из-за недостатка памяти. В моей обработке такого не происходит.
- Есть все возможности стандартной настройки + скорость работы.
- Удобный, понятный и простой интерфейс.
- Свертка также работает и для распределенной базы данных