Меня зовут Ростислав Такахо, я работаю консультантом по 1C. В этой статье я покажу пошаговый путь от идеи до работающего решения.
- Почему мы выбрали внешнюю обработку вместо изменения типовой конфигурации.
- Как построить гибкий фреймворк сверки, который легко масштабировать.
- Какие подводные камни ждут при сопоставлении данных из разных систем.
- Как преодолеть сопротивление пользователей.
- Сколько реально можно сэкономить на точечной автоматизации.
Суть проблемы: параллельный ввод
Важно понимать, что SAP и 1С это две противоположные философии.
- SAP — монолит, построенный на идеологии «best practices». Система жестко диктует, как должны выглядеть бизнес-процессы. Вы подстраиваетесь под нее, а не она под вас.
- 1С — мощный конструктор, платформа. Главная ее сила — гибкость. 1С можно допилить под самые изощренные запросы.
Миграция с SAP на 1С — это не «экспорт-импорт данных». К сожалению, эти системы сильно различаются по структуре данных, бизнес-логике, подходам к расчетам. Процесс, который в SAP был монолитным, в 1С реализуется через цепочку документов и регистров.
Поэтому перед полным отключением SAP и переходом на 1С существует этап параллельного ввода. Это период, когда обе системы работают одновременно — каждая кадровая операция, приказ или расчет зарплаты вводится и обрабатывается параллельно.Так можно получить стопроцентную уверенность, что новая система в тех же условиях выдает идентичный результат.
На выходе этого этапа — два гигантских, несопоставимых по структуре потока данных, отчеты, которые нужно сравнить. В 99% случаев для этого используют старый добрый Excel: десятки вкладок, сотни столбцов, сотни тысяч строк.
Получается узкое горлышко, от которого очень хочется избавиться.
Сверочные отчеты, как решение
Выбор архитектуры
В экосистеме 1С существует негласное правило: не трогай типовую конфигурацию без крайней нужды. Сегодня вы добавили туда фичу, завтра выходит плановое обновление от вендора — и кастомизация в одночасье ломается. Поэтому мы решили положиться на внешнюю обработку данных, которая подключается к системе извне, использует данные и интерфейс, но не меняет внутреннюю структуру конфигурации.
У такого решения есть ряд преимуществ:
- Безопасность: кастомный код не может случайно сломать стандартные механизмы расчета зарплаты или кадрового учета.
- Обновляемость: можно спокойно обновлять 1С:ЗУП, не опасаясь, что система перестанет работать.
- Быстрое обновление: чтобы добавить нововведения, не нужно останавливать работу компании. Достаточно заменить один файл и попросить пользователей его переоткрыть.
- Простое управление доступом: доступ к запуску обработки легко контролируется стандартными средствами 1С, без сложных настроек.
Проектирование интерфейса
Определившись с архитектурой, мы перешли к проектированию пользовательского интерфейса.
Первым делом позаботились о безопасности. В системе создали специальную роль — ОткрытиеДопОбработкиСверочныйОтчет. Только пользователи с этой ролью могли увидеть и запустить обработку.
Чтобы обеспечить гибкость, заложили в основу алгоритма простую абстракцию — справочник НастройкиСверочныхОтчетов.
Это простая таблица из трех столбцов: Ключ, Значение1 и Значение2.
- Ключ — определял принадлежность к большому разделу учета (например, «Кадры», «Зарплата»).
- Значение1 — конкретный тип сверки (например, «Приемы», «Увольнения», «Сотрудники»).
- Значение2 (необязательное поле) — путь к шаблону или внешнему файлу, если требовался.
Сегодня нужна сверка по приемам на работу, завтра понадобится по увольнениям, кадровым переводам или данным воинского учета. Так что, когда пользователь выбирает из выпадающего списка в интерфейсе «Приемы», система ищет в таблице настроек соответствующую запись, понимает, к какому разделу она относится («Кадры»), и запускает нужный алгоритм сверки.
Это позволяет добиться масштабируемости, дает возможность разграничить доступ на уровне логики и адаптировать интерфейс под задачи пользователя:
- Добавление нового вида сверки это просто добавление одной строки в таблицу настроек. Это может сделать даже продвинутый пользователь 1С без привлечения разработчика.
- Мы привязали Ключ к правам доступа в 1С. Например, если у пользователя не было прав на редактирование кадровых данных, он не видел в выпадающем списке сверки с ключом «Кадры». Система сама фильтровала доступное, избавляя нас от сложной логики прав внутри обработки.
- В зависимости от выбранной настройки интерфейс мог меняться. Для сверки «Приемов» отображалось поле для выбора периода («с... по...»), а для сверки «Сотрудников» — поле для выбора конкретной даты, на которую нужен срез данных. Обработка читала настройку и динамически адаптировала форму.
В результате получился небольшой фреймворк, который можно расширять и дополнять.
Алгоритм сравнения
Основная часть решения — алгоритм сверки. Его задача взять две таблицы разной структуры (одна из 1С, другая из SAP), сопоставить в них семантически одинаковые сущности и подсветить все расхождения в атрибутах.
Процесс сверки
1. Формирование данных 1С
На основе выбранной настройки система запускает соответствующий запрос к базе данных 1С. Мы не стали запрашивать данные напрямую из документов, чтобы не замедлять систему. Вместо этого обращаемся к «плоским» и быстрым регистрам сведений (таким как «Кадровая история сотрудников»), где хранится подготовленный срез информации. Результат запроса выгружается в табличный документ на форме обработки.
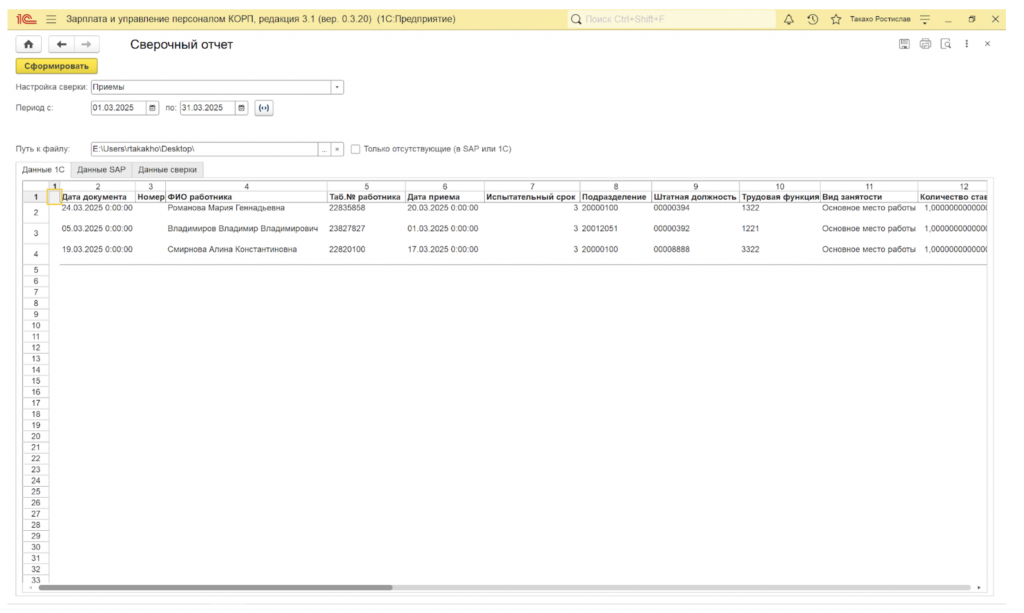
2. Чтение данных SAP
Обработка считывает предоставленный пользователем xlsx-файл. Здесь обнаружился первый подводный камень: форматы данных. Где-то дата была в формате ДД.ММ.ГГГГ, где-то ММ/ДД/ГГ, где-то число было сохранено как текст. Поэтому на этом этапе мы добавили слой нормализации — приведения всех данных к единому, каноническому виду.
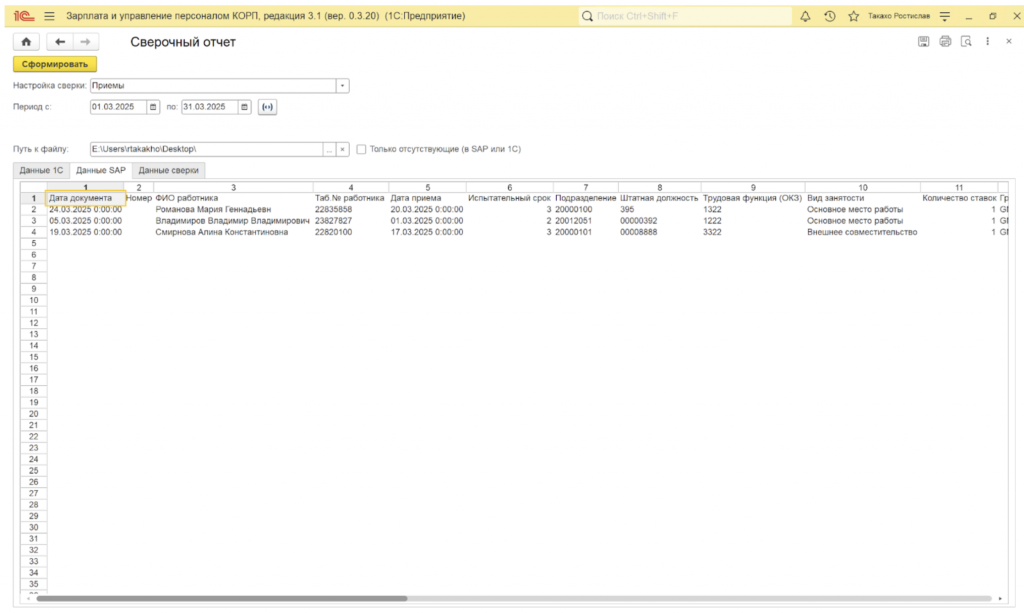
3. Сверка и формирование отчета
Самый важный этап. Как сопоставить запись о «Иванове Иване Ивановиче» из 1С с записью о «Ivanov I. I.» из SAP? По ФИО ненадежно — возможны расхождения. Единственным надежным «якорем» оказался табельный номер — уникальный идентификатор сотрудника в обеих системах. Он стал ключевым полем для сопоставления.
Однако есть ситуации, когда одного ключа недостаточно. Например, для сверки данных о регистрации в налоговом органе нужно было уникально идентифицировать запись по комбинации нескольких полей.
Решение — составной ключ. Мы программно объединяем значения нескольких полей (например, КодРегистрации, КПП, КодПоОКТМО) в одну строку через разделитель #. Получился уникальный «отпечаток пальца» для каждой записи, который гарантирует точное сопоставление.
Алгоритм сравнения работает так:
- Система проходит по каждой строке из таблицы 1С;
- Берет ее ключевое поле (или строит составной ключ);
- Ищет в таблице из SAP строку с таким же ключом;
- Если строка находится, система начинает поэлементное сравнение всех остальных полей (должность, оклад, подразделение и так далее);
- Любое несоответствие заносится в итоговую третью таблицу — «Данные сверки». В этой таблице в одной строке наглядно выводится и значение из 1С, и значение из SAP, чтобы расхождение было видно невооруженным глазом;
- Если строка из 1С не находится в SAP (или наоборот), она также попадает в итоговый отчет с перечислением всех реквизитов, незаполненными в колонке SAP или 1С.
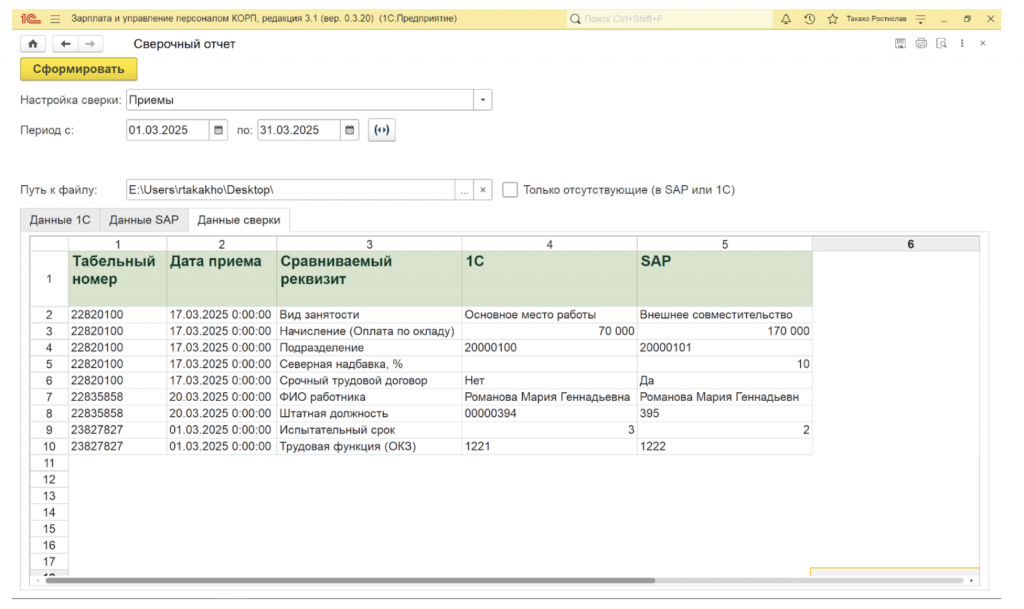
На выходе пользователь получает три вкладки: «Данные 1С», «Данные SAP» и, самое главное, «Данные сверки», где собраны только проблемные записи. Больше не нужно было просматривать сотни тысяч строк, чтобы найти 10–20 расхождений. Алгоритм предоставляет готовый результат для анализа.
Человеческий фактор
С технической точки зрения, внедрение прошло без каких-либо проблем, но вмешался человеческий фактор. Мы подготовили первую версию обработки, загрузили реальные данные и пришли на демонстрацию. Запустили сверку по приемам за последний месяц. Секунда ожидания — и система выдала отчет. Во вкладке «Данные сверки» — тридцать строк.
Далее последовал примерно такой диалог:
— Смотрите, мы нашли 30 расхождений между системами - у 10 сотрудников допустили опечатку в окладе, у 7 расходятся коды штатных должностей, у 5 не совпадают ФИО, а остальные внесены с неправильной ставкой.
— Хм. Странно. У нас в SAP все ведется идеально. Это, должно быть, ваш отчет работает некорректно.
Оказалось, что для команды психологически проще объявить новый инструмент сломанным, чем признать наличие проблем в процессах, которые выстраивались годами. В такой ситуации одних только технических решений недостаточно, нужно менять само восприятие инструмента.
Первым делом мы добавили в обработку автоматическую проверку входящего файла из SAP. Теперь, если формат даты был неправильным, в ячейке с окладом оказывался текст или нарушалась структура столбцов, система не просто выдавала ошибку, а формировала подробный протокол:
«Строка 15, столбец ДатаПриема: ожидается формат ДД.ММ.ГГГГ, получен Март».
Это позволило сразу отсечь огромный пласт проблем, связанных с кривыми выгрузками. Первый аргумент «у нас все правильно» разбивался о конкретный протокол ошибок формата.
Затем мы поменяли формат демонстрации решения. Вместо того чтобы просто показывать итоговый отчет с расхождениями, стали проводить совместные рабочие сессии.
Садились рядом с пользователем, открывали наш отчет и говорили: «Смотрите, система нашла расхождение по окладу у сотрудника Иванова. Давайте не будем верить отчету на слово. Откройте, пожалуйста, карточку этого сотрудника в SAP. А мы сейчас откроем в 1С» и посмотрим. И вот, на одном экране две системы, и все видят, что в одной 70 000, а в другой 70 001.
Построение доверия
Доверие к новому решению накапливалось постепенно, с каждым найденным и подтвержденным расхождением. Переломный момент наступил, когда отчет подсветил системную ошибку в алгоритме переноса данных, из-за которой у целого подразделения неверно проставлялся районный коэффициент.
Это была проблема, которую сотрудники вручную искали бы неделями. После этого случая отношение к нашему решению изменилось кардинально. Из «подозрительной новой программы» оно превратилось в ценный диагностический инструмент. Нас попросили провести сверку и по новым разделам.
Так что создать хороший код — половина дела. Вторая, зачастую более сложная половина — научить людей им правильно пользоваться и доверять ему.
Практические последствия
Сокращение временных затрат
Вспомним исходную точку: команда ключевых пользователей тратила от 3 до 4 часов ежедневно на ручную сверку данных. Это половина рабочего дня, вырванная из жизни IT специалистов, чье время стоит дорого.
В месячном исчислении рутина пожирала около 100 часов, которые могли быть потрачены на анализ, решение методологических вопросов, подготовку к следующим этапам проекта.
После запуска инструмента процесс сверки сжался до 10–15 минут. Это время уходит на то, чтобы выбрать нужную настройку, указать путь к файлу выгрузки из SAP и запустить обработку. Сама сверка занимала секунды. Остальное время пользователь тратит на анализ уже готового, отфильтрованного отчета, где подсвечены только реальные расхождения.
В масштабах месяца: снижение трудозатрат со 100 часов до примерно 5 часов. Сокращение в 20 раз.
От поиска опечаток к диагностике системы
За первые недели использования наши отчеты позволили выявить более 30 ранее не обнаруженных расхождений в данных. Это были системные, глубоко укоренившиеся несоответствия, которые ручная сверка, сфокусированная на отдельных строках, просто не могла заметить.
Призрачные коэффициенты
Отчет показал, что у целого подразделения, переведенного из одного филиала в другой, в 1С не обновился районный коэффициент. В SAP он был верным, а в 1С — устаревшим. Это означало, что вся зарплата для этих сотрудников рассчитывалась бы неверно.
Несоответствие кодов должностей
Система позволила определить, что одна и та же должность в справочниках SAP и 1С имела разные идентификаторы. Это могло привести к ошибкам при формировании штатного расписания и аналитической отчетности.
Ошибки миграции
Всплыли случаи, когда из-за сбоя в скрипте первоначальной миграции данных у некоторых сотрудников не перенеслись данные о стаже или количестве положенных дней отпуска.
Экономический эффект
Переведем эти достижения в конкретные финансовые показатели. Возьмем сэкономленное время: 100 часов в месяц минус 5 часов равно 95 часам чистого выигрыша ежемесячно. Умножим это на 12 месяцев и получим 1140 сэкономленных человеко-часов в год.
Среднерыночная стоимость часа работы специалиста уровня бухгалтера по расчету зарплаты или специалиста по кадрам, с учетом налогов и накладных расходов, колеблется в районе 1500–2500 рублей. Возьмем консервативную оценку — 1100 рублей в час.
1140 часов/год × 1100 рублей/час = 1 254 000 рублей в год
Это прямая годовая экономия только на сокращении трудозатрат. Деньги, которые компания не потратила на механическую, низкоквалифицированную по своей сути работу.
Эта оценка не учитывает стоимость потенциальных ошибок, которые могли бы обойтись компании в разы дороже. Так, опечатка в расчете НДФЛ для какого-нибудь подразделения могла привести к штрафам, пени и репутационным потерям, которые с легкостью перекрывают эту сумму.
Самое важное — эту экономию обеспечила небольшая, точечная утилита.Принцип Парето в действии: 20% усилий, вложенных в правильную точку, приносят 80% результата, а в нашем случае — все 100%.
Стратегический актив
Последнее, но не по значению, последствие в том, что мы создали не одноразовый скрипт, а масштабируемый фреймворк. Когда через месяц возникла потребность в сверке данных по увольнениям, нам не пришлось начинать работу с нуля. Мы просто добавили новую запись в таблицу настроек, написали новый, относительно простой запрос для выборки данных из 1С и настроили сопоставление полей.
Ядро, движок сравнения, интерфейс — все уже было готово и отлажено.
Нужно сверить кадровые перемещения? Пожалуйста. Данные по воинскому учету? Не проблема. Любой участок, где требовалось сопоставление двух источников данных, теперь может быть автоматизирован с минимальными усилиями.
Этот кейс ярко показывает, какой огромный эффект может быть скрыт в самых скучных и рутинных процессах, маленьких, но умных автоматизациях.
Заключение
Если сформулировать главный вывод одной фразой: «Написать рабочий код — самая легкая часть задачи». Любое, даже самое гениальное техническое решение обречено на провал, если вы не смогли его «продать» конечным пользователям. Речь не о маркетинге, а о построении доверия.
С технической точки зрения ключевым фактором успеха этого проекта стал первоначальный архитектурный выбор — внешняя обработка. Прежде чем лезть в ядро сложной системы, всегда стоит задать себе вопрос: «А можно ли достичь того же результата, не трогая основной механизм?» Плагины, микросервисы, внешние модули, API — существует масса возможностей для расширения функциональности.
Что касается самого инструмента, то его история только начинается. Благодаря заложенной модульной архитектуре мы получили полноценный фреймворк для сверки данных. Он стал стандартным инструментом контроля качества данных на всех последующих проектах миграции в компании, создав основу для тиражирования в другие подразделения.