Понятие чистых функций
Пускай вас не пугает слово «математика» в названии этой статьи. Речь идет о математическом мышлении при написании кода.
Есть ряд критериев, каким должен быть именно высококачественный код. Это простой, понятный, тестируемый, модульный код, высокая связанность, низкое зацепление и так далее. Вы можете даже не знать все эти критерии. Но если писать код в виде чистых функций, он автоматически начинает соответствовать требованиям высококачественного кода.
Сначала разберемся, как выглядят чистые функции. Чистая функция – это функция в математическом понимании. Вспомните, как мы писали формулы функций на уроках математики в школе.
Чтобы быть чистой, функция не должна иметь побочных эффектов. После выполнения и возврата результата она не оставляет никаких следов.
Кроме того, чистая функция детерминирована: на один и тот же набор входных параметров она всегда возвращает один и тот же результат.
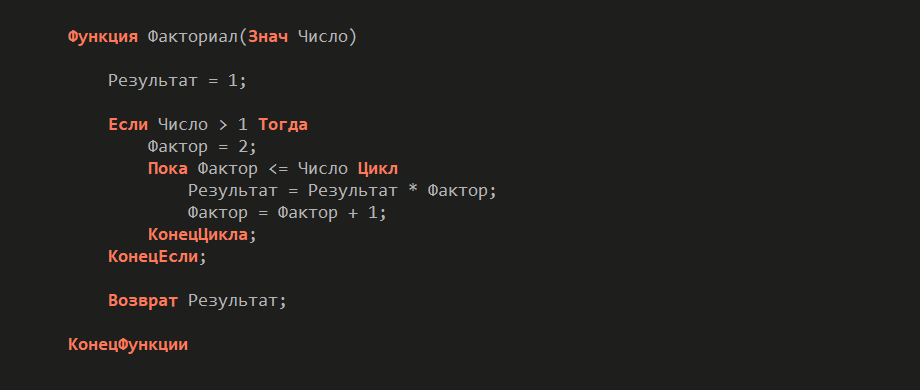
Первый пример чистой функции. Сначала я немного расскажу прямо про математику, покажу примеры, а потом уже перейду к более бизнесовым кейсам. Эта функция вычисляет факториал числа.
Обратите внимание: вся область знаний этой функции находится в ее теле. Она зависит только от входящего параметра – числа. Во время выполнения у нее нет никакой побочки, она не оставляет никаких следов.

Есть такой критерий: если функция чистая, можно условно заменить вызов этой функции в коде на ее результат, и логика программы не должна сломаться.
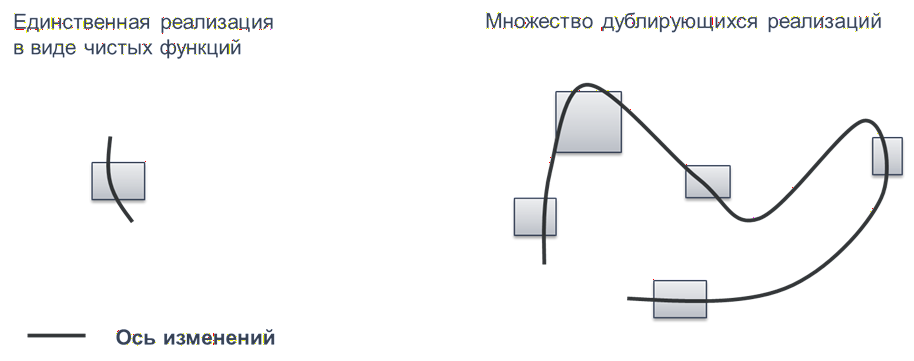
Может показаться, что ничего особенного здесь нет. Но на самом деле за этим стоят очень серьезные концепции. На чистых функциях держатся большие вычисления.
Благодаря своей природе чистые функции отлично распараллеливаются. Их можно выполнять даже в разном порядке. В 1С, конечно, это не используется, но в целом для понимания это важно.
Как это выглядит в реальной жизни? Например, инженеры Google работают с большими данными. Они пишут логику обработки огромных массивов информации – это может быть текст или большие таблицы в базах данных. На вход поступают терабайты информации. Все это распараллеливается по кластеру из сотен, а иногда и тысяч серверов. «Вжух-вжух» – происходит магия чистых функций, магия распараллеливания. Данные обработаны, результат получен.
Зарплата инженера Google – десятки тысяч долларов. Так что чистые функции – это действительно серьезная вещь.
Примеры и состав чистых функций
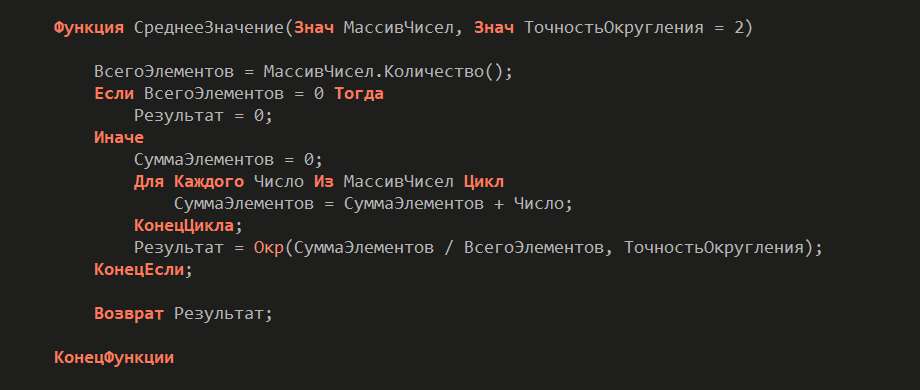
Дальше пример еще одной чистой функции. Она чуть сложнее, чем пример с факториалом. Здесь функция принимает массив чисел и вычисляет среднее арифметическое значение. Но при этом она остается полностью чистой.

С чистыми функциями вы сталкивались уже много раз. Они есть и в глобальном платформенном контексте. Более того, иногда вы сами писали чистые функции, даже не подозревая об этом.
Все знают такие функции, как «НачалоДня», «Год». Обратите внимание на функцию «ПолучитьСклоненияСтроки». За ней скрыта довольно сложная логика: там целый механизм работы с фамилиями, наименованиями должностей и так далее. То есть на чистых функциях можно реализовывать довольно сложную логику – нужно лишь постараться.
Не чистые функции

А теперь пример платформенных функций, которые не являются чистыми. Эти функции зависят от внешнего состояния. То есть им необходимо обращаться куда-то вовне.
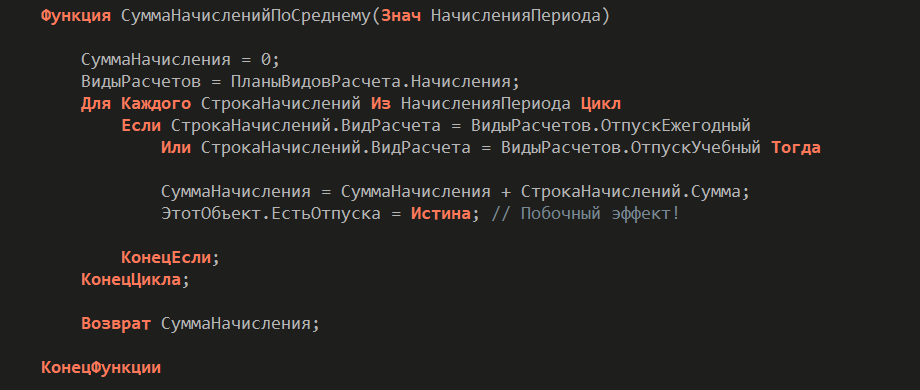
Следующий пример – не чистая функция, написанная прикладным разработчиком. В целом она похожа на чистую функцию, но внутри есть небольшой побочный эффект. В средней строке кода происходит обращение к внешнему контексту – к тому, что находится за пределами области видимости чистой функции. Тем самым нарушается принцип чистоты, и функция перестает быть чистой.

Вот еще один пример не чистой функции. Здесь функция уже работает с базой данных. Она не детерминирована: при каждом обращении к базе, например к регистру накопления, результат может быть другим. Кроме того, сама база данных – это сложная внешняя зависимость, с которой чистая функция не работает.
Из чего состоят чистые функции
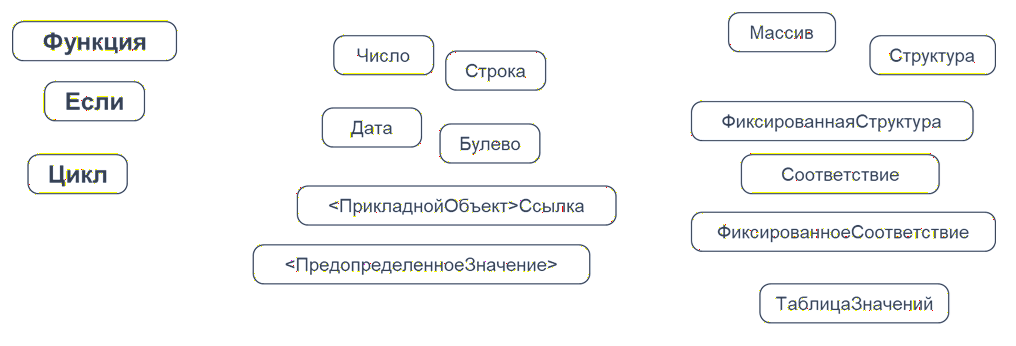
Теперь посмотрим, из чего состоят чистые функции.
Во-первых, это само объявление функции. Далее – блоки принятия решений: «Если», «Иначе», «ИначеЕсли», циклы. Используются примитивные значения, ссылочные значения – но только как значения, без обращений через точку. Также могут использоваться предопределенные значения и коллекции значений, которые оборачивают примитивы и ссылки.
На первый взгляд арсенал небольшой. Но на практике его вполне достаточно, чтобы писать чистые функции.
Если внимательно читать различные финансовые правила и документы, можно заметить интересную закономерность: язык финансов – это язык формул и принятия решений.
Как применять чистые функции
Теперь давайте подробнее посмотрим на применение. С тем, как выглядят чистые функции, мы разобрались. А как их использовать на практике?
Сразу скажу: всю логику системы на чистых функциях вы не напишете. Можете даже не пытаться. Только какая-то часть кода может быть реализована таким образом.
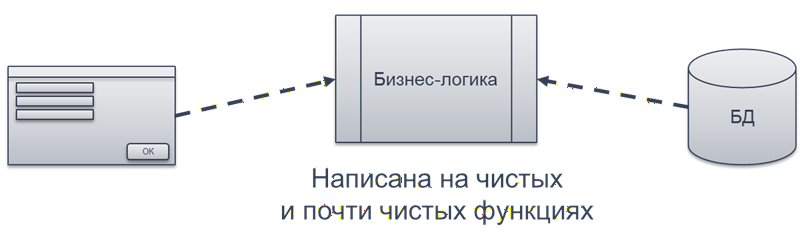
Чтобы это действительно приносило пользу, нужно сделать следующее: самую ценную часть – бизнес-логику – «дистиллировать» в чистые функции. А все сложные зависимости – интерфейс, базу данных, работу с веб-сервисами – вынести за пределы чистых функций.
Перед чистыми функциями мы, например, работаем с базой данных. Получаем результат запроса, передаем его в чистые функции. Чистые функции обрабатывают данные и возвращают результат, который затем можно передать дальше – например, снова в базу данных.
Гексагональная архитектура
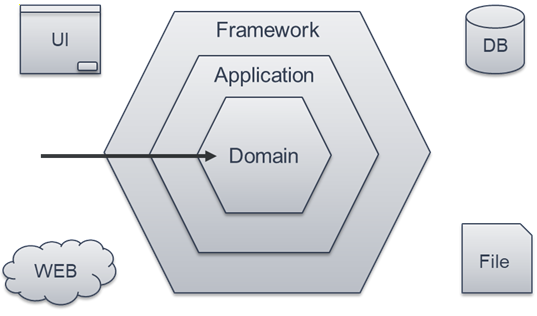
Это та же самая концепция, только в более развитом виде. Она известна как гексагональная архитектура. Есть и другие названия: «луковая архитектура», «порты и адаптеры», «чистая архитектура». По сути, все они говорят примерно об одном и том же, просто разными словами.
Суть этой архитектуры в следующем. В центре находится доменный слой – Domain. Это слой бизнес-логики.
Эта бизнес-логика ведет себя примерно как человек на советском антиалкогольном плакате, который говорит: «Нет! Базу данных не предлагать! Файлы не предлагать! Веб-сервисы не предлагать!»
При этом в гексагональной архитектуре побочные эффекты в доменном слое полностью не запрещены. Например, если метод внутри домена меняет состояние объекта, который тоже находится в доменном слое, – это нормально. Такая побочка считается доброкачественной.
А вот сложные зависимости – работа с базой данных, файловой системой, внешними сервисами – в доменный слой попадать не должны.
Есть разновидность гексагональной архитектуры – функциональная архитектура. В ней доменный слой полностью пишется на чистых функциях.
Зачем я все это рассказываю? Чтобы показать, что отделять бизнес-логику от базы данных и интерфейса – это нормальная и распространенная практика. Так делают многие, и на этой концепции можно строить промышленную разработку приложений.
Как облегчают жизнь чистые функции
Теперь посмотрим, как чистые функции могут облегчить нам жизнь.
Есть несколько распространенных проблем, с которыми вы наверняка сталкивались. Возможно, вы просто не формулировали их именно так. Сейчас я их обозначу, а чуть позже покажу на изображениях – так будет нагляднее.
Первая проблема – недостаточная модульность. В типичных конфигурациях, которые пишем мы сами или разработчики фирмы 1С, модульность часто оставляет желать лучшего. Это, конечно, мое мнение, кому-то может казаться, что все нормально.
Это приводит к лишним трудозатратам при разработке и сопровождении. Чуть ниже поясню подробнее.
Вторая проблема – сложность повторного использования уже написанного функционала. Причина в большом количестве зависимостей.
И третья проблема – юнит-тестирование. Если вы попробуете написать юнит-тесты для уже существующего кода – особенно для кода, который писал кто-то до вас, – вас может ждать разочарование. Это либо очень сложно и трудозатратно, либо к такому коду вообще невозможно подступиться.
Модульность в коде
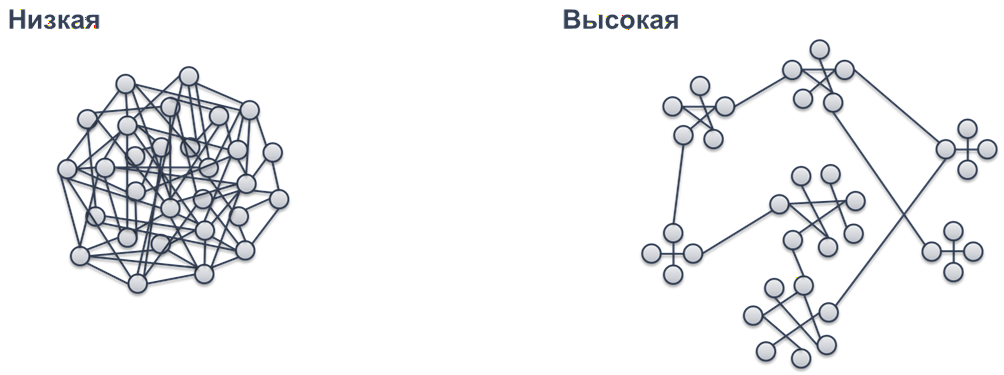
Модульность – это способность приложения распадаться на отдельные независимые или хотя бы минимально зависимые друг от друга части. Когда есть большое приложение, а внутри него есть небольшой модуль – самостоятельный и максимально независимый.
Вообще тема модульности тесно связана с темой API. Чтобы стало понятнее, приведу пример из жизни.
Представим, что вы взаимодействуете с государством и хотите получить какую-то государственную услугу. Вы как гражданин и государственные учреждения – это разные модули, которым нужно взаимодействовать между собой.
Как было раньше? Вы приходите в госучреждение, и вас заставляют собрать множество справок, обойти разные кабинеты, заполнить кучу документов. Только после этого вы получаете нужную услугу. Это пример плохой модульности и плохого API. Плохой модуль – в данном случае государственное учреждение – заставляет вас выполнять его работу и тратить на это время.
Хорошая модульность – это то, как стало сейчас. Вы достаете смартфон, нажимаете несколько кнопок – и услуга получена. Раньше был чудовищный API, который заставлял делать огромное количество лишней работы. Сейчас появился хороший API, который позволяет легко и быстро получить услугу и вообще не вникать во внутреннюю работу госучреждений.
Повторное использование
С модульностью тесно связана концепция повторного использования. Казалось бы, все очевидно: если мы что-то один раз написали, этот код должен использоваться повторно. Он уже готов, заказчик за него заплатил.
Но на практике все оказывается сложнее. Уже написанный код часто обладает множеством зависимостей, из-за чего использовать его повторно очень трудно. И начинается копипаст.
Например, в конфигурации есть документ «Заказ». При открытии формы автоматически подставляются какие-то значения реквизитов – работает автозаполнение. Логика уже написана, она существует.
Но мне нужно использовать эту же логику при программном создании документа. Я пытаюсь к ней обратиться – и не могу. Она гвоздиками прибита к форме. В итоге приходится выдирать куски кода, разбираться в них и копировать их в другое место. Получается не только лишняя работа по изучению логики, но и дублирование кода.
Чистые функции в деле
Чистые функции обладают наивысшей модульностью и их очень легко использовать повторно.
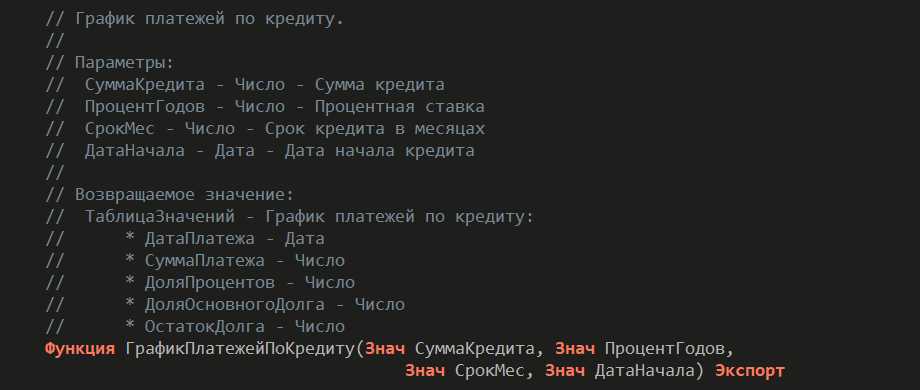
Покажу это на условном примере. Допустим, есть задача – сформировать график платежей по кредиту. Все знают, что такое кредит и график платежей. Многие пользовались кредитными калькуляторами. Здесь есть набор чистых функций, реализующих довольно сложную логику расчета.

Разработчик, который знаком с концепцией чистых функций, выделил бизнес-логику – формирование графика платежей – и отделил ее от интерфейса.
Результат работы чистой функции передается, например, в печатную форму. Это первая итерация разработки.
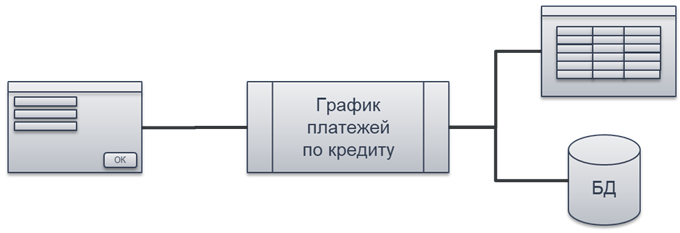
Дальше происходит следующая итерация. Мы снова возвращаемся к этому графику платежей – он снова понадобился. Допустим, появился справочник, в котором нужно использовать данные сформированного графика. Мы просто берем готовый алгоритм на чистых функциях и используем его повторно.
Это легко сделать. Если вы заметили, входные параметры там элементарные – числа и дата.
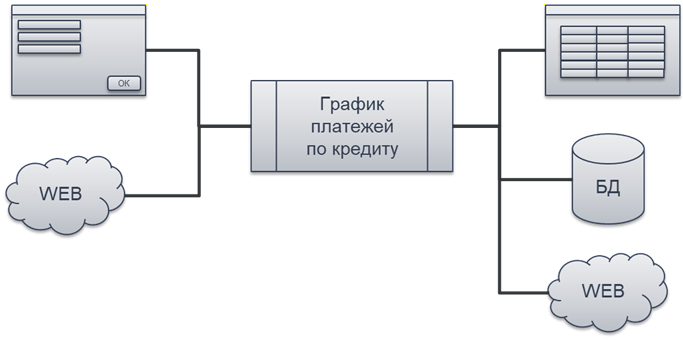
На следующей итерации бизнес-заказчику понравился функционал. Он решает разместить на сайте компании кредитный калькулятор, чтобы посетители могли самостоятельно рассчитать платежи. И снова используется тот же готовый алгоритм. Ничего дорабатывать не нужно. За ним просто ставится HTTP-сервис, результат вычислений передается наружу – и все работает. Одна реализация используется в разных местах.
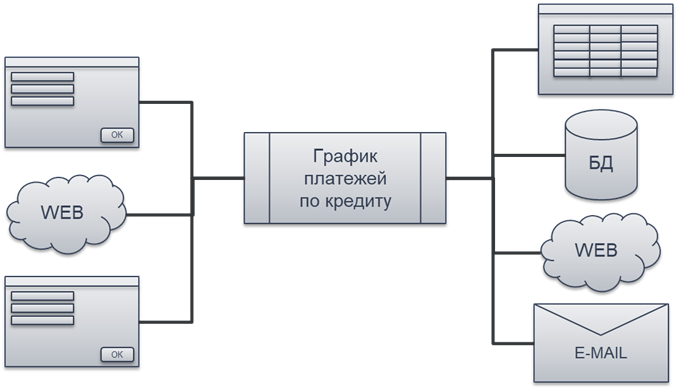
Дальше может появиться новый интерфейс – например, добавится рассылка результатов по электронной почте. И снова используется тот же самый алгоритм. Потому что чистые функции легко переиспользовать.
Разработка без чистых функций
Теперь антипример – разработка без чистых функций.
Допустим, разработчик пишет логику работы с НДС. Как это часто происходит? Создается новая форма, и прямо в обработчиках событий формы начинает писаться вся логика.
В результате логика расчета НДС оказывается жестко привязана к форме документа.

На следующей итерации другой разработчик хочет использовать эту же логику. Но он не может ее переиспользовать, потому что она прибита гвоздями к форме и завязана на множество зависимостей. В итоге он копирует код и делает вторую реализацию той же самой логики.
На следующей итерации ситуация повторяется. Эту логику нельзя использовать ни из одного места, ни из другого. Снова появляется дублирование. Другие разработчики пишут тот же самый алгоритм в новых местах.
К чему это приводит?
Если логика аккуратно инкапсулирована в одном месте – например, реализована через чистые функции – то при необходимости доработки изменения коснутся только одного модуля.
А если одна и та же логика разбросана по десяткам модулей, любая доработка превращается не просто в задачу, а в небольшой проект. Нужно вносить изменения в разных местах, проверять их, тестировать.
В итоге мы тратим огромное количество времени на то, чего могли бы избежать.
На пути к юнит-тестированию
Самая большая польза чистых функций проявляется в юнит-тестировании.
Если вы пишете модульные тесты или планируете писать модульные тесты, то для вас это будет полезная информация.
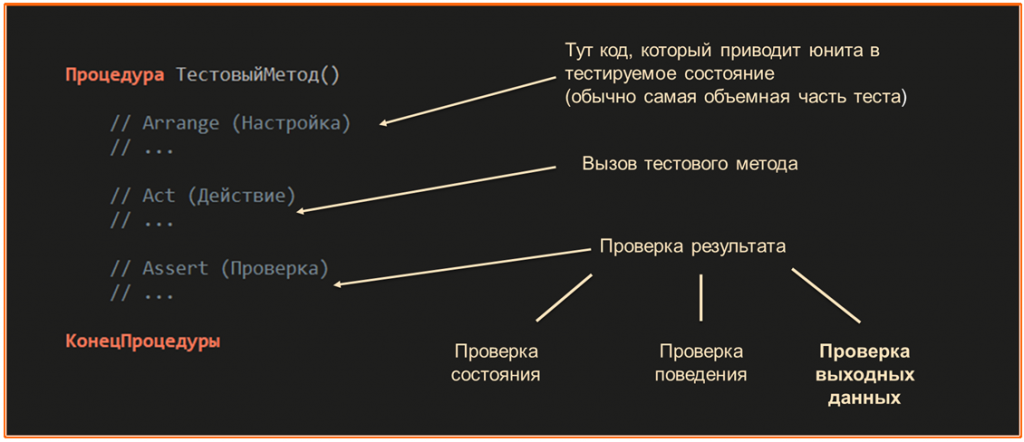
Кратко разберем, что такое модульный тест и как он выглядит.
Модульное тестирование – это когда некоторый сервисный код проверяет работу продуктового кода. Обычно один тест – это один метод или одна процедура. Этот метод делится на несколько частей. Используется паттерн 3A: инициализация, действие и проверка.
-
Первый блок – инициализация. Здесь тестируемый код приводится в нужное состояние, подготавливается тестируемый юнит.
-
Второй блок – действие. Это вызов проверяемой процедуры.
-
Третий блок – проверка. Мы смотрим, какой результат получился после выполнения кода.
Блок инициализации обычно самый большой – в нем больше всего кода. Чем больше зависимостей в системе и чем сложнее эти зависимости, тем длиннее будет этот блок.
Блок действия, как правило, занимает одну строку кода.
Теперь о проверке результата. Есть три основных подхода:
-
Проверка поведения. Это довольно спорный способ. Обычно используется мокирование, и тесты становятся хрупкими. Поэтому такой подход лучше применять осторожно.
-
Проверка состояния. Мы вызываем тестируемый код, он изменяет внешний контекст – например, добавляет записи в базу данных. После этого мы идем и проверяем, что именно было записано. Это уже заметно сложнее.
-
Проверка выходных данных. Мы вызываем функцию, она возвращает результат, и мы сравниваем его с эталонным значением. Это самый простой и эффективный способ проверки результата.
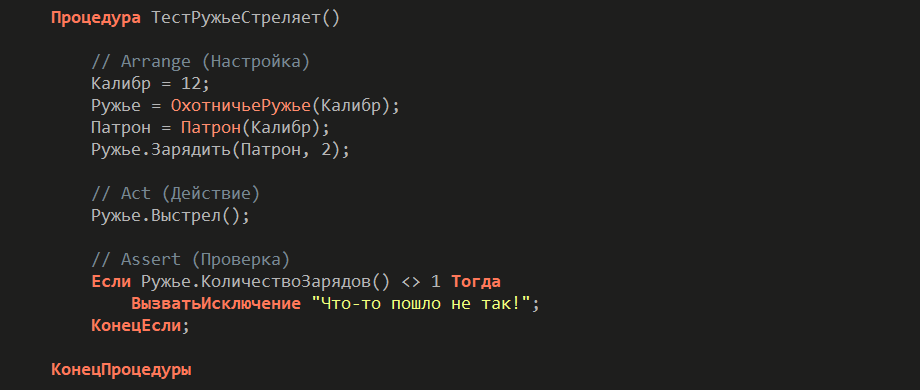
Немного шуточный пример тестового метода: в ружье заряжаются два патрона, производится выстрел, и проверяется, что остался один заряд.
Код разбит на три секции: инициализация, действие и проверка. Здесь пример без использования фреймворка.
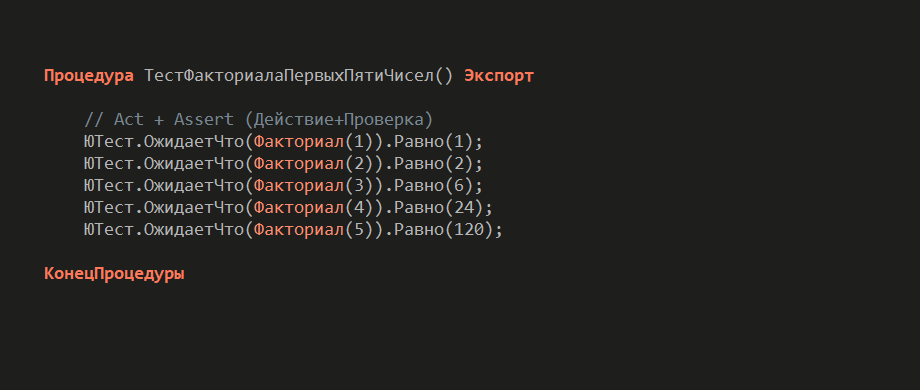
Теперь посмотрим, как в этом помогают чистые функции.
Если вы пишете действительно чистые функции – когда на вход подаются числа и на выходе получаются числа – тестировать их элементарно. Не нужно никакой сложной инициализации. Мы просто вызываем функцию и сравниваем результат с ожидаемым значением. Тест получается очень коротким и очень эффективным.
Решаем задачу
Разберем более прикладной пример – прогрессивную шкалу НДФЛ.
Пунктом 1 ст. 224 НК РФ установлена налоговая ставка в отношении налоговых баз, указанных в п. 2.1 ст. 210 НК РФ. Ее размер составляет:
-
13%, если сумма налоговых баз за налоговый период равна или менее 2,4 млн. руб.;
-
312 тыс. руб. + 15% суммы налоговых баз, превышающей 2,4 млн руб., если сумма налоговых баз за налоговый период превышает 2,4 млн. руб. и составляет не более 5 млн руб.;
-
702 тыс. руб. + 18% суммы налоговых баз, превышающей 5 млн руб., если сумма налоговых баз за налоговый период превышает 5 млн руб. и составляет не более 20 млн руб.;
-
3 402 тыс. руб. + 20% суммы налоговых баз, превышающей 20 млн руб., если сумма налоговых баз за налоговый период превышает 20 млн руб. и составляет не более 50 млн руб.;
-
9 402 тыс. руб. + 22% суммы налоговых баз, превышающей 50 млн руб., если сумма налоговых баз за налоговый период превышает 50 млн руб.
Многие знают, что при определенном уровне дохода ставка НДФЛ повышается: сначала 15%, потом 18% и так далее. Формулировка этой логики в предметной области довольно сложная, но если внимательно посмотреть, становится понятно: язык финансов – это язык формул и решений. Такая логика отлично ложится на чистые функции.
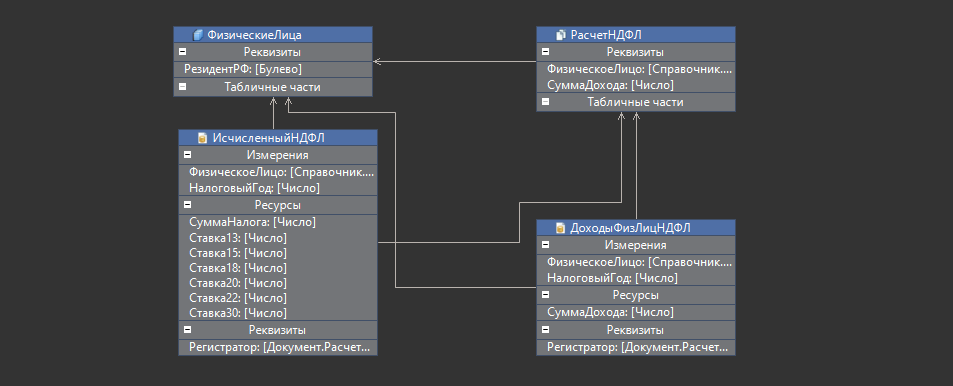
Для решения задачи нам понадобится небольшой набор метаданных. Мы создаем документ «РасчетНДФЛ», в котором есть реквизиты физлица или сотрудника. Этот документ будет формировать движения по двум регистрам накопления. В одном регистре хранится доход физлица с начала года. Во втором регистре хранится рассчитанный НДФЛ в разрезе ставок.
Теперь посмотрим два варианта решения.
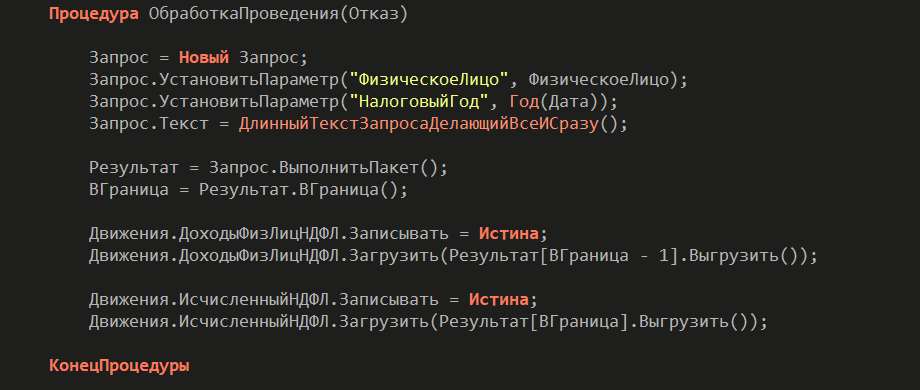
Первый – типичный. При проведении документа рассчитывается НДФЛ и результат записывается в регистр. Обычно для этого пишется большой пакетный запрос, который работает сразу с множеством таблиц: документом, регистрами накопления, временными таблицами. Данные переливаются из одной временной таблицы в другую, выполняются вычисления – и на выходе получается готовый результат. Все работает.
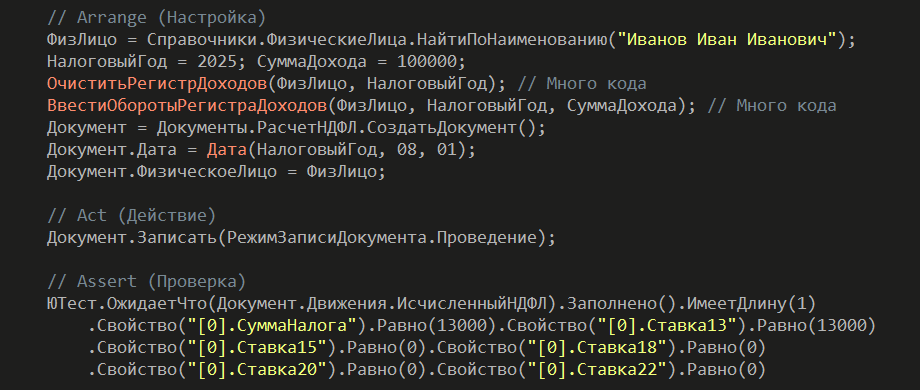
Но когда мы переходим к тестированию, начинаются проблемы. Весь код жестко привязан к базе данных. Тест становится сложным. Нужно писать длинный блок инициализации: очищать регистры накопления, подготавливать данные, создавать документ, проводить его и потом проверять движения.
Тест получается огромным и громоздким. На его написание уходит много времени, а эффективность при этом довольно сомнительная.
Теперь решим ту же задачу с использованием чистых функций.
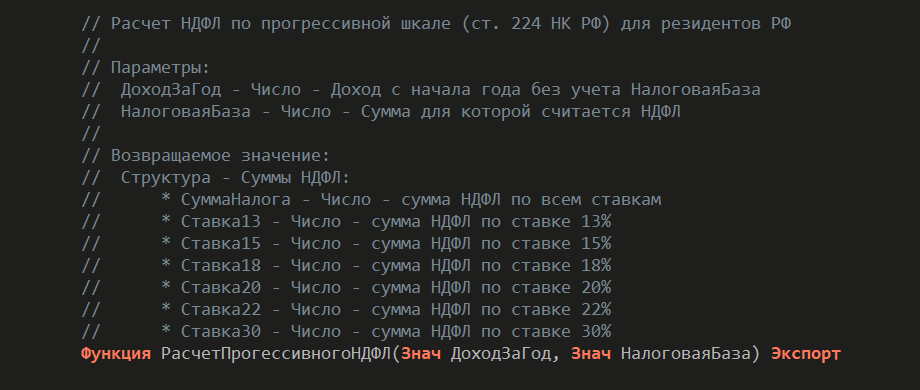
Мы выделяем бизнес-логику расчета НДФЛ в общий модуль и реализуем ее через чистые функции. Здесь я показываю только API. Представьте, что внутри несколько сотен строк кода, организованных в граф чистых функций. Алгоритм довольно сложный, но он отлично укладывается в такую модель.
Алгоритм принимает на вход два числа и возвращает структуру с результатами расчета. Эту структуру удобно записывать в регистр накопления.

Обработка проведения документа остается. Запросы к базе данных тоже остаются – они нужны для получения входящих данных для основного алгоритма чистых функций. Еще остается некоторое количество кода. Но теперь эти запросы становятся намного проще. Они маленькие и тривиальные.
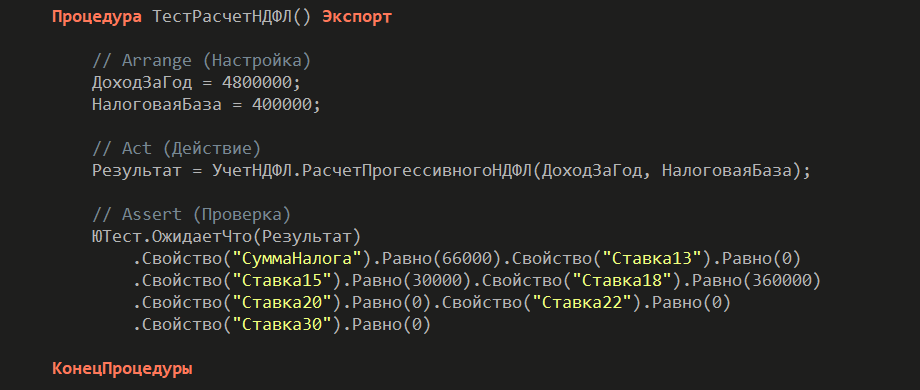
Как тестируется этот вариант? Мы берем основную бизнес-логику, реализованную через чистые функции, и пишем для нее тест. Нам достаточно передать в функцию два числа и проверить, что она вернула структуру с ожидаемыми значениями. Тест получается гораздо проще.
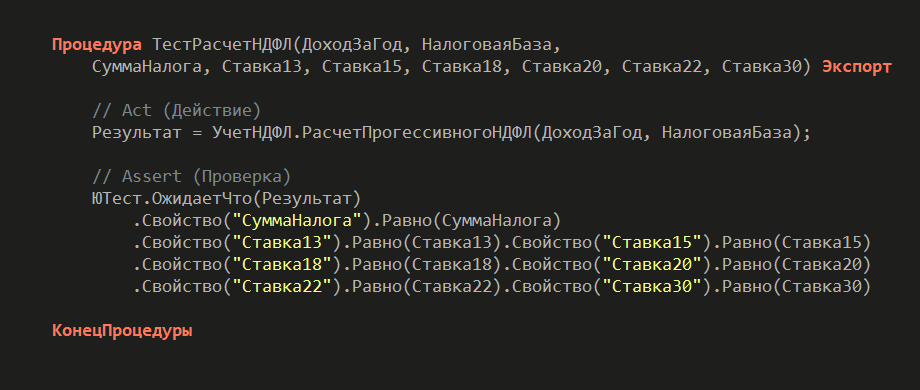
Можно пойти еще дальше: сделать параметризованный тестовый метод. Тогда мы будем проверять не одно значение, а целый набор сценариев. В тест передается таблица – своего рода спецификация. В ней указано: при таком доходе и такой налоговой базе ожидается такой результат расчета.
Один тестовый метод прогоняет сразу множество сценариев: пограничные значения, отсутствие дохода, очень большие доходы, ситуации с переходом между налоговыми ставками.
В итоге один простой тест проверяет сразу большое количество вариантов.
Тест получается коротким, понятным и эффективным. В этом и заключается сила чистых функций.
Чистые функции тестируются легко и удобно. Тесты получаются короткими и эффективными. Чтобы код стал тестируемым, основную логику нужно выделить в чистые функции и писать тесты именно для них.
На предыдущем примере вы могли заметить одну вещь. Неудачный тест проверял проведение документа целиком. А тест для чистых функций не задействует всю картину обработки проведения. Это нормально.
Мы покрываем юнит-тестами самое важное – бизнес-логику. А проведение документа можно проверить сценарным тестом: создать документ, заполнить его, провести и убедиться, что записи создались и ошибок не возникло. Даже не обязательно анализировать движения. Это и есть классическая пирамида тестирования.
Немного про моки
Моки – это прием тестирования, при котором сложные зависимости заменяются заглушками или тестовыми дублерами. Это делается для того, чтобы можно было протестировать алгоритм, не обращаясь к внешним системам.
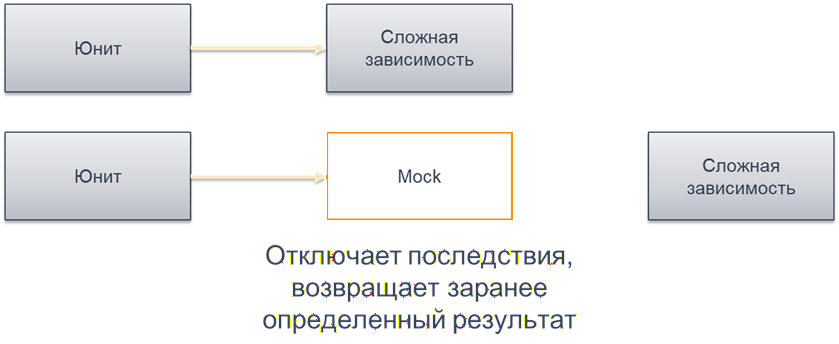
Например, код обращается к HTTP-сервису. Мы не хотим, чтобы каждый тест реально вызывал этот сервис. К тому же он может находиться вне нашей зоны ответственности. Поэтому создается мок – заглушка, которая подменяет обращение к HTTP-сервису. И тогда тест можно выполнить изолированно.
Но здесь есть важный момент: чистые функции не нуждаются в мокировании. У них по определению нет сложных зависимостей, уходящих наружу – ни к базе данных, ни к веб-сервисам. Поэтому для их тестирования ничего не нужно подменять.
Немного про TDD
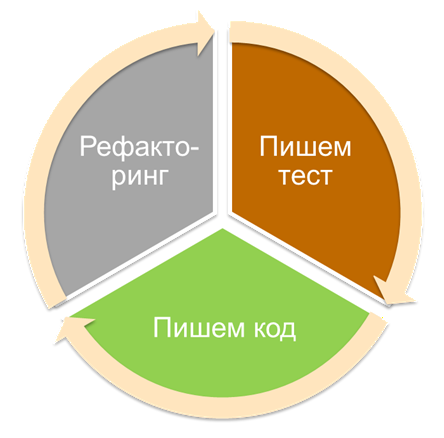
Суть методики TDD – разработки через тестирование – в следующем. Сначала пишется небольшой тест. Затем пишется код, который должен пройти этот тест. После того как тест проходит, выполняется небольшой рефакторинг. И все повторяется.
Получается цикл: тест – код – рефакторинг. Важно, чтобы один такой цикл занимал десятки секунд. Но если в коде есть сложные зависимости – база данных, внешние сервисы, сложные инфраструктурные вещи – этот цикл разваливается.
В режиме TDD можно работать только тогда, когда код легко тестируется. А это как раз тот случай, когда используется подход с чистыми функциями. Как только появляется необходимость работать с базой данных, интерфейсом или другими сложными зависимостями, TDD приходится откладывать и возвращаться к обычному процессу разработки.
Недостатки чистых функций
У любой медали есть две стороны, и у чистых функций тоже есть свои минусы.
Первый недостаток – они стимулируют перенос данных в память. Для работы чистых функций часто нужно заранее получить необходимые данные и передать их в функцию. Иногда часть этих данных может даже не использоваться. В результате увеличивается нагрузка на память сервера приложений. Но на практике эта проблема обычно решается увеличением объема оперативной памяти и редко становится серьезным ограничением.
Вторая проблема более заметная. В 1С мы привыкли писать код в процедурном стиле. Функциональный стиль – когда функция вызывает функцию, а та вызывает следующую – может выглядеть непривычно для других разработчиков. Иногда такой код кажется менее понятным участникам команды.
Но и это, как правило, не критичный недостаток.
Выводы
Чистые функции – это один из способов писать высококачественный код. Такой код легче тестировать, поддерживать и развивать.
Чтобы использовать этот подход, нужно выделить основную бизнес-логику, дистиллировать ее, рассматривать ее как набор математических правил. После этого реализовать ее через чистые функции, а все сложные зависимости – работу с базой данных, интерфейсом и внешними сервисами – вынести за пределы этих функций.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт