Моя статья будет сторителлингом про боль и ошибки. Речь пойдет про команды, которые не успевают построить свой первый космолет, а напалмом из кабинета финансового директора уже попахивает. Поэтому тема – самые частые ошибки ручного тестирования, а в качестве предметной области – планы обменов.
Автоматизированное тестирование против ручного
Начнем с небольшой вводной: чем вообще куются тесты и какими инструментами они могут быть сделаны.

Инструментов автоматизированного тестирования в 1С сейчас огромное количество. Есть YAxUnit для юнит-тестирования, есть Vanessa и «Тестировщик» для функционального тестирования, есть АПК и Sonar для статического анализа. Все круто: большие, красивые, блестящие, монструозные инструменты.
Но для многих команд они сложны во внедрении. По разным причинам: у кого-то не хватает бюджета, кто-то постоянно тушит пожары, кто-то не может убедить заказчика, что внедрение этих инструментов действительно будет полезно для дальнейшей эксплуатации системы.

Что остается таким командам? Остается ручное тестирование.
Кто-то может сказать, что это доисторический инструмент, который уже свое отжил. Но он все равно продолжает пользоваться популярностью. И возникает вопрос: а хватает ли нам только рук?

Даже если они растут из плеч – мне кажется, нет. Как минимум к ним нужно добавить серьезный опыт, концентрацию, внимание к деталям и стремление к идеалу. Только тогда руками можно тестировать качественно.
Ниже разберем три практических кейса – три проекта. Я дам немного контекста и покажу ошибки, которые возникают при ручном тестировании обменов между базами 1С.
Кейс №1
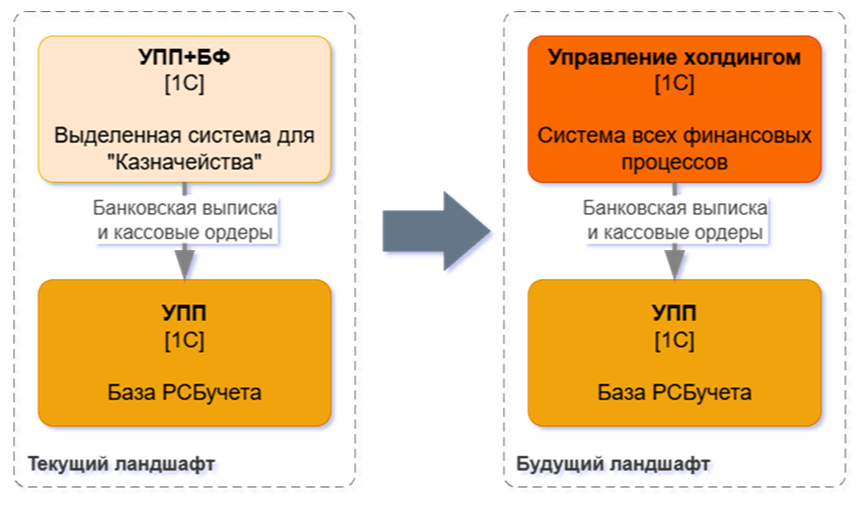
Первый проект – интеграция между УХ и УПП.
Компания занимается розницей и мелким оптом. У нее около 350 точек по России и странам СНГ.
Весь учет ведется в кастомизированной УПП. Причем не в одной базе, а сразу в двух: финансовый контур отделен, там ведутся казначейство, бюджетирование и другие прелести финучета.
В какой-то момент запускается проект внедрения «Управления холдингом», чтобы консолидировать все функциональные области в одной системе. Первой на замену идет специализированная УПП плюс «Битфинанс». Эта система отправляется под снос.
Между базами под капотом строится обмен КД2. Понятно, почему не КД3.
И есть маленькая вишенка на торте. Сроки проекта сдвигаются и в итоге упираются в начало нового года – к этому моменту уже должна вовсю работать интеграция банковских выписок из УХ с регламентированным учетом в УПП.
Это означает, что протестировать «спокойно» мы уже не успеваем. Мы только закончили настройку планов, правил и регистрации.
В итоге команда остается без новогодних каникул. Вместо салатов – тестирование.
И вот к каким ошибкам такая срочность приводит.
Начнем с легкого.
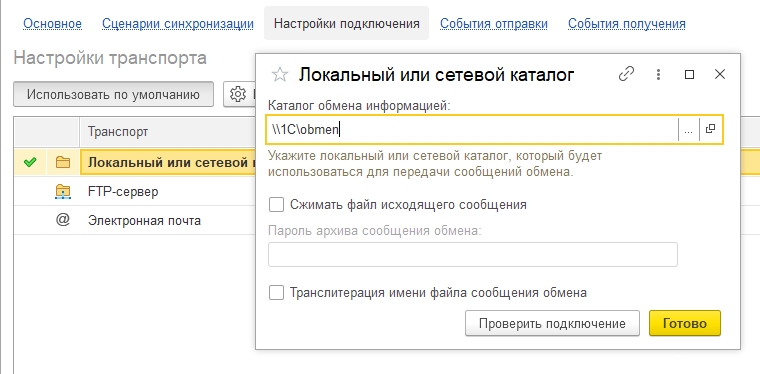
Всем знакомо окно настроек подключения. В качестве транспорта использовалась файловая шара. В процессе проекта мы часто обновляли базы – точнее, восстанавливали их из бэкапов. И в какой-то момент забыли поменять папку. На продакшене это вылилось в крики, оры и удары дубиной по спине от главного казначея. Потому что в его базу вдруг загрузились совершенно левые документы.
Кажется, что ошибка банальна – простая невнимательность. Но есть причина серьезнее: тестовый контур никак не был изолирован от прода. Мы могли разнести базы по разным серверам без сетевой связанности. Могли настроить разные папки обмена. Этого не сделали – и получили последствия.
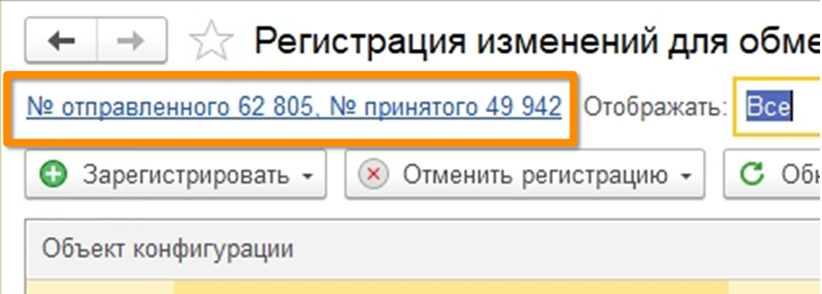
Следующая ситуация тоже достаточно банальна. Сообщения обмена имеют нумерацию. Система контролирует, чтобы не загрузить сообщение с меньшим номером. Иначе возникает ошибка.
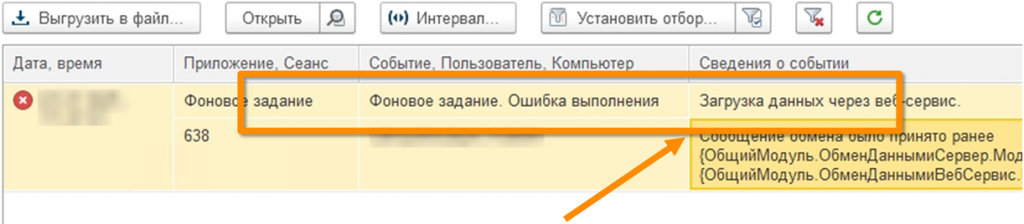
Что происходит, если мы восстанавливаем базу и не меняем нумерацию сообщений обмена? В журнале регистрации появляется запись: «Сообщение принято ранее».
Что делает тестировщик? Он бежит перерегистрировать весь пул документов и тратит на это огромное количество времени.
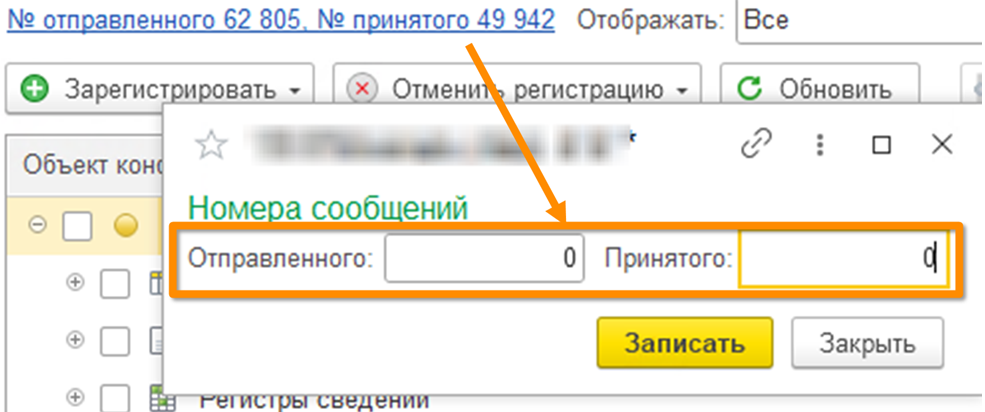
Хотя на самом деле достаточно было просто обнулить нумерацию сообщений в обеих базах. Это не ошибка – скорее псевдоошибка, которая тормозит процесс тестирования и мешает нам выполнить все быстрее.
Кстати, о скорости.
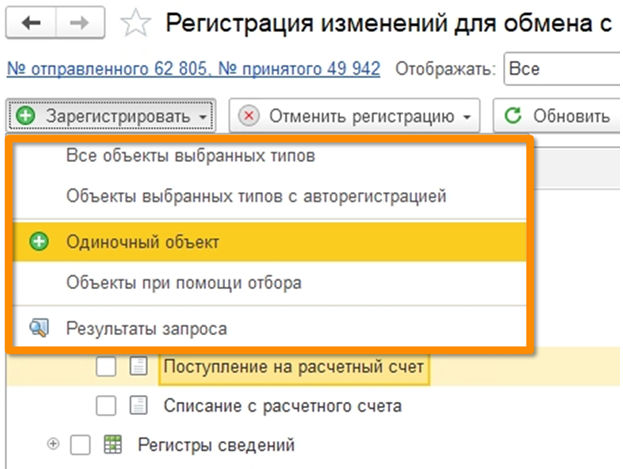
Есть обработка регистрации объектов к обмену. Многие пользовались этим способом – просто натыкиваешь документы в ней – и тестируешь процесс обмена. А потом внезапно на продакшене возникает инцидент. Загружается банковская выписка: документы поступления и списания денежных средств появляются в УХ, но в УПП они не перелетают.
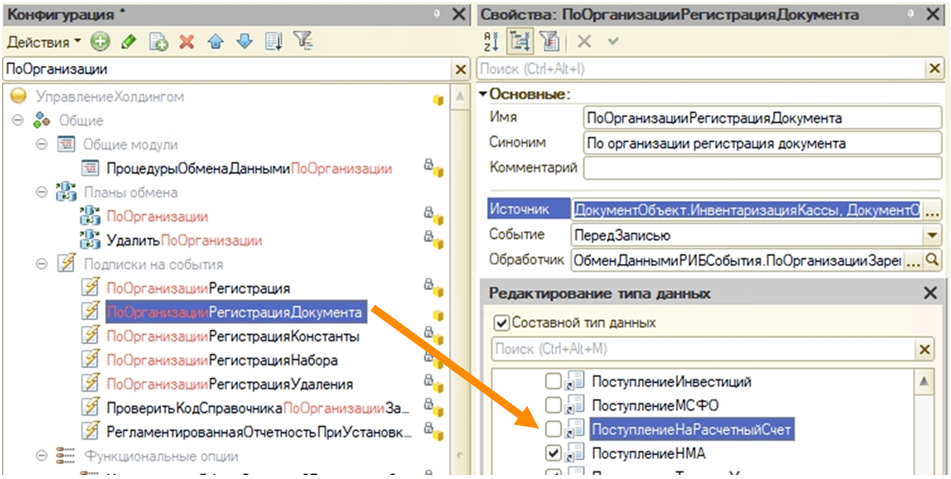
Причина проста: кто-то просто не поставил нужную галочку в подписке на регистрацию.
И может показаться, что виноват разработчик – он что-то напутал, про что-то забыл. Но на самом деле нет.
Мы организовали стерильную регистрацию, не прошлись по пользовательскому сценарию – и именно поэтому словили инцидент на продакшене.
С легкими примерами закончили.
Кейс №2
Теперь проект чуть посвежее.
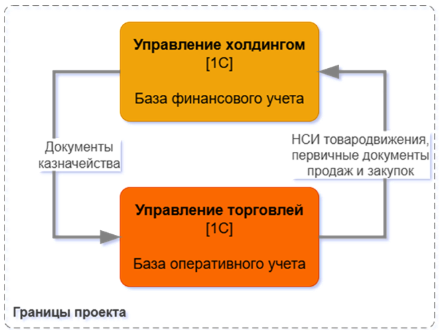
Есть компания, которая занимается мелким оптом и работает по давальческой схеме: то есть она отдает свое сырье на переработку и взамен получает некий продукт. Весь учет ведется в «Управлении холдингом». И в какой-то момент стартует проект: выделить процесс товародвижения в отдельную базу «Управления торговлей», чтобы теперь уже отделить оперативный контур от финансового.
Под капотом для этого строим КД3. Почему – понятно: чтобы не зависеть от обновлений систем – этот обмен уже строится «вдолгую». Плюс учитываем, что разные команды поддерживают разные системы и могут быть «огрехи» в коммуникации и планировании.
И очередная вишенка: всего за три месяца нужно переписать процессы, обучить пользователей, интегрироваться. И еще, дополнительно, внедрить модуль производства. Потому что купить самописный модуль для «Управления торговлей» в моменте быстрее и дешевле, чем организовывать закупку ERP’а.
Что из этого выходит?
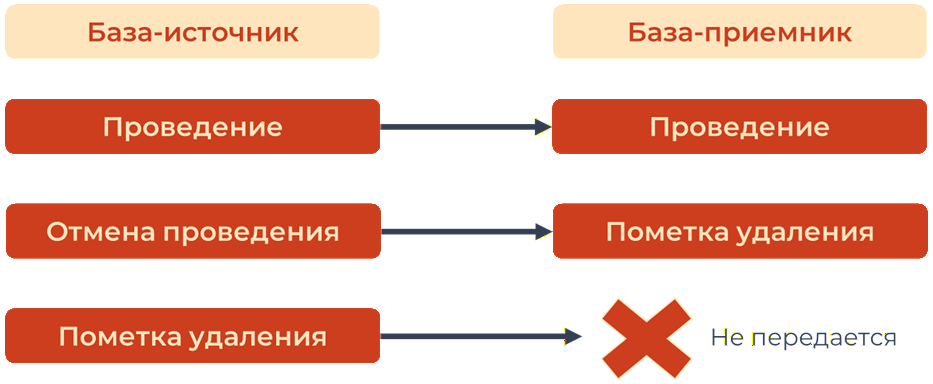
Допустим, у нас есть база-источник и база-приемник. Все хорошо. Если мы проводим документ в базе-источнике – он проводится и в базе-приемнике. Если отменяем проведение – передается пометка на удаление в базу-приемник. Если документ помечен на удаление, ничего никуда уже не переходит.
Но в нашем случае обнаружился нюанс.
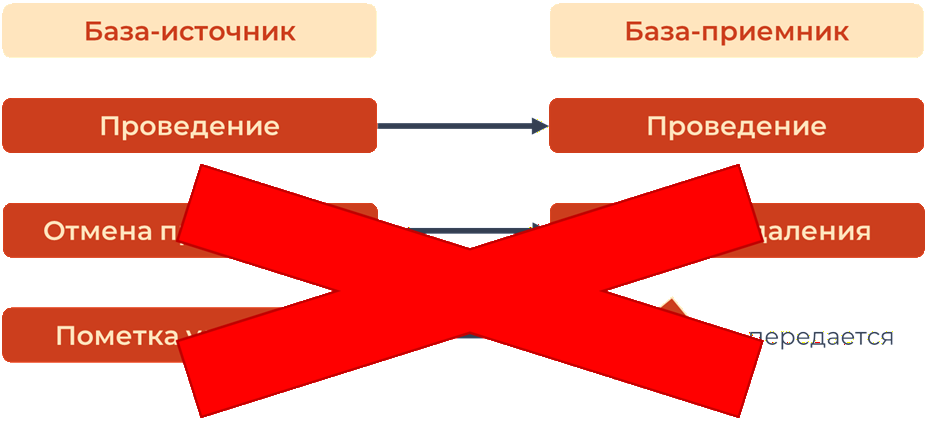
Вот эти два события в обмене просто не обрабатывались – передавались только проведенные документы и все.
К чему это приводило бы на продакшене? К тому, что начинали бы дублироваться данные.
Например, из ЭДО в УТ загрузили документ «Приобретение товаров и услуг». Потом его аннулировали, пометили на удаление, загрузили новый документ (поставщик вовремя скорректировал и переотправил). В «Управлении холдингом» в итоге оказывается два документа. И внезапно остатки в двух базах перестают совпадать.
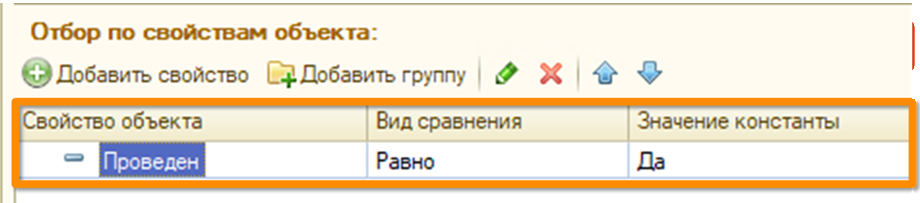
Причина снова оказалась банальной: кто-то поставил отбор по свойству «проведен» для документов.
Но где ошибка именно с точки зрения тестирования? Вместо того, чтобы пройтись по всем состояниям объектов и проверить идентичность данных на каждом этапе, многие проверяют только один факт – обменялся документ вообще или нет. А о тестировании смены состояния очень часто забывают.
Следующий кейс.
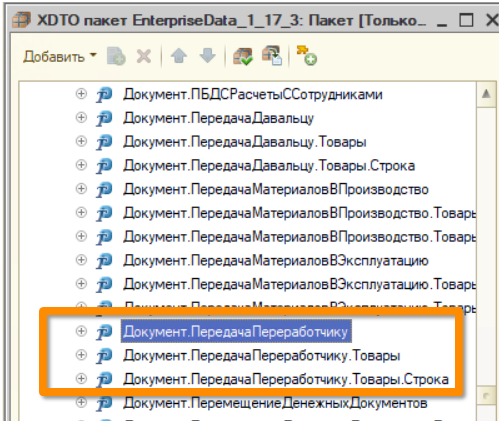
Я уже говорил, что параллельно мы внедряли модуль производства. Для Enterprise Data с точки зрения «Управления торговлей» это новые объекты. Для них нет ни одного обработчика отправки данных. То есть это полноценная кастомизация правил обмена на КД3.
Не очень приятная работа.
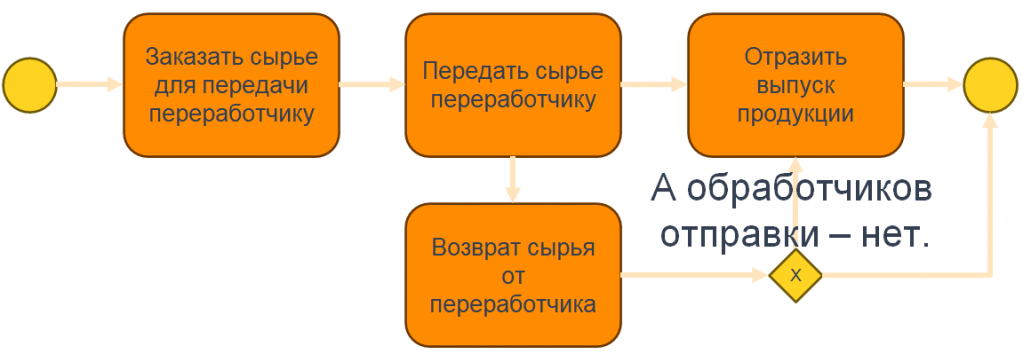
Как строится процесс работы с переработчиком? Мы создаем заказ, чтобы зарезервировать сырье. Передаем сырье переработчику. В результате получаем выпуск продукции.
Именно такой процесс нам описали пользователи. Они сказали: «У нас всегда так. Все линейно, все идеально».
А потом на продакшене возникает другая ситуация. Сырье, которое передали переработчику, портится или оказывается бракованным. То есть его необходимо вернуть обратно, оформив «возврат сырья от переработчика». А такого в ТЗ не было, как говорится.
Что происходит дальше? Срочно приходится дорабатывать КД3: добавлять объекты в XDTO-пакет, писать обработчики отправки, дополнять правила регистрации и все такое.
Где ошибка с точки зрения тестирования? Мы прошли только по «золотому» сценарию. Мы не проверили граничные варианты и не задали уточняющих вопросов. А если и задали – то соломку не подстелили и удовлетворились «честными» ответами пользователей.
Еще один пример.
Мы дорабатывали КД3, чтобы организовать обмен присоединенными файлами. Сами файлы лежали на файловой шаре, а между базами передавались элементы справочников, которые содержали на них ссылки.
Мы добавили множество типов: для приобретений, реализаций, договоров и т.д. и т.п. Настроили обмен, прогнали тест, проверили выборочно. Вроде бы все хорошо – файлы переходят.
А потом прибегают документоведы, которые работают в УХ, и говорят: «По договорам ни одного файла не прилетело. А нам надо – мы же читаем их при согласовании счетов».
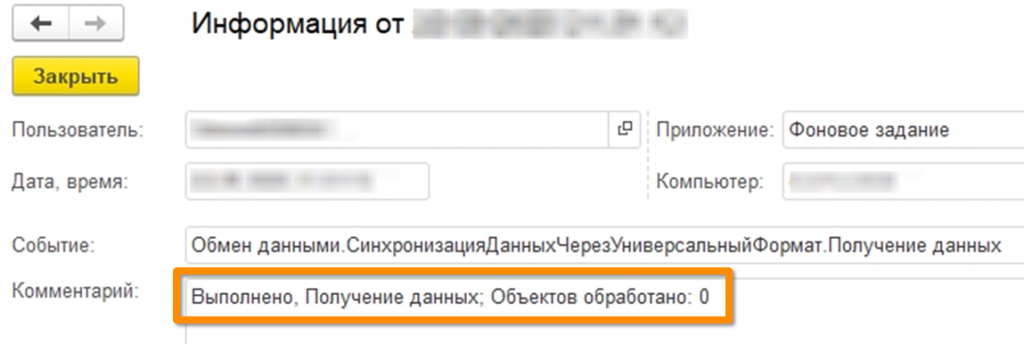
Мы проверяем и действительно видим сообщение: «Обработано объектов: 0».
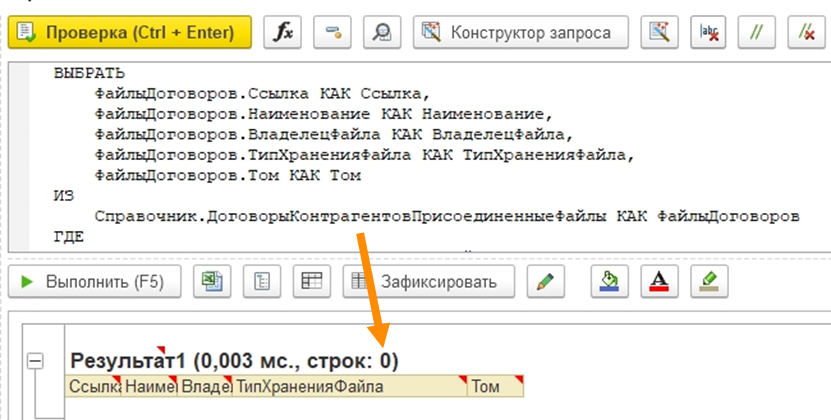
Ладно, думаем, проверим с другой стороны. Может быть, файлы все-таки есть? Делаем запрос – ничего. Ноль.
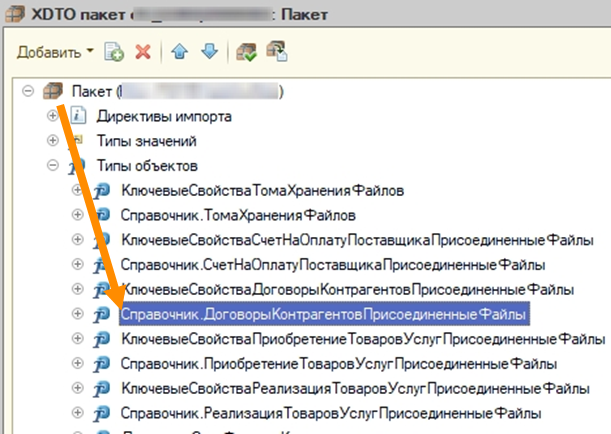
Ошибка скрывалась недолго: в XDTO-пакет просто не был добавлен один объект, который показан на изображении. Мы его забыли добавить, не успели или пропустили. А КД3 работает очень просто. Если она читает XML и не знает, что делать с каким-то объектом, она просто молчит. Никакой ошибки не будет – даже записи в ЖР. Просто «обработано объектов: 0».
Где здесь ошибка тестирования? Выборка для оценки результата обмена была некорретна. Проверялось всего несколько типов объектов из большого массива, а надо было пройтись по каждому типу хотя бы раз.
Кейс №3
Следующий пример – множественный обмен.
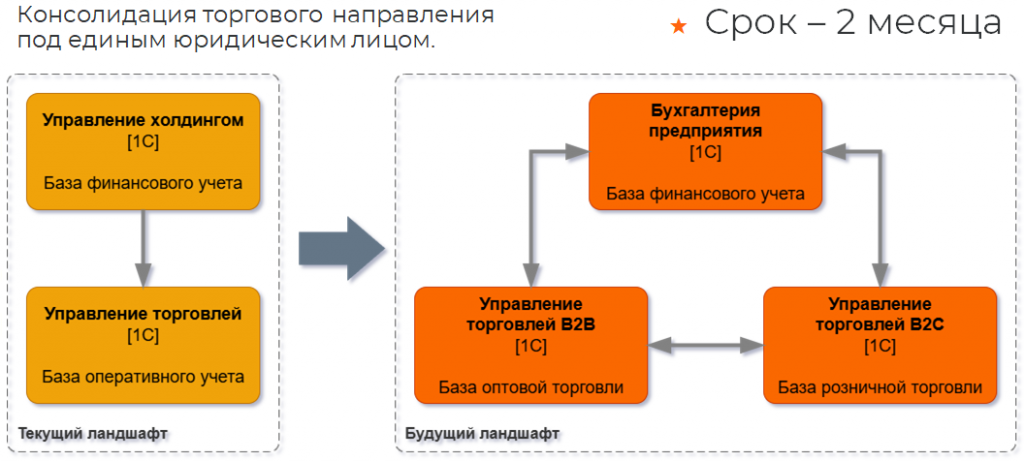
Некая компания решает выделить (или продать) бизнес по розничной и e-com продаже товаров в отдельное юридическое лицо партнера. У партнера тоже была «Управление торговлей», только на три года старше: версия 11.4.14. У нас – 11.5.17, новенькая на тот момент.
И снова все портят дедлайны: два месяца на весь переезд. Нужно перенести базы и донастроить все интеграции, чтобы повторить тот обмен, который уже был сделан с «Управлением холдингом». Только теперь – с «Бухгалтерией предприятия» на стороне партнера.
Что происходит дальше? Под капотом, кстати, все также КД3.
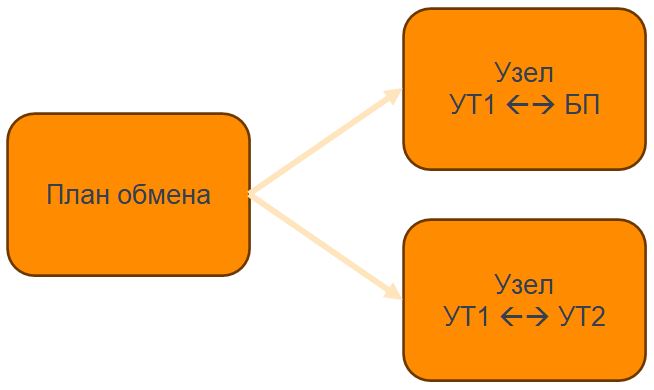
Есть план обмена и узлы. Например: узел УТ1 с БП, УТ1 с УТ2.
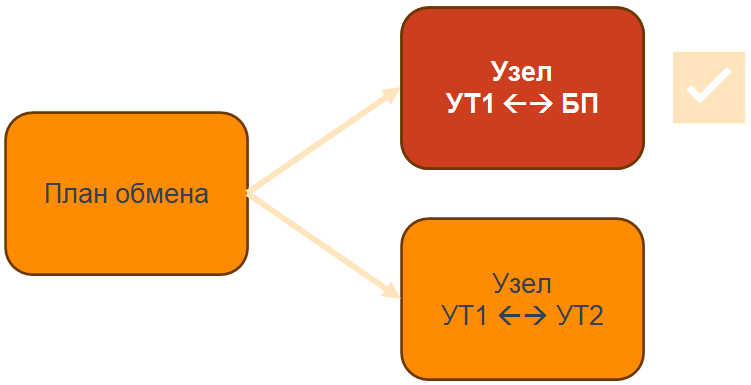
Тестируем первый обмен – все хорошо. Если находим баги, отдаем разработчику, все исправляется, процесс идет и он стабилен.
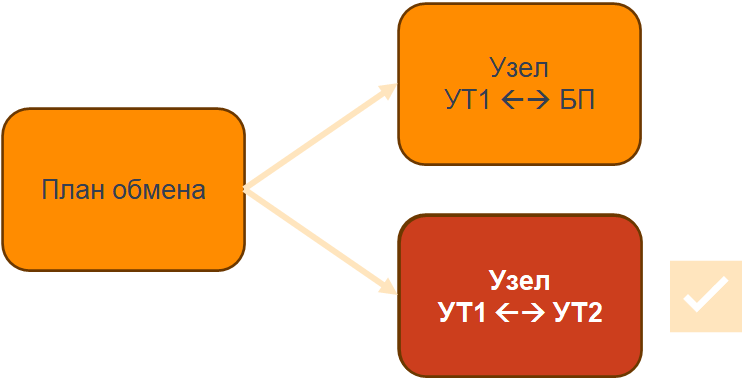
Тестируем второй обмен – тоже все хорошо.
Но что будет, если протестировать обмен одновременно с его запуском по двум узлам одного плана обмена? Имея при этом пересекающиеся таблицы обмениваемых объектов.
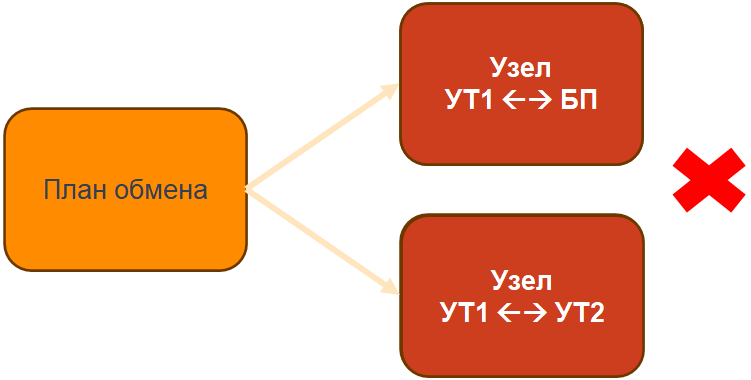
Будет плохо.

Возникает конфликт блокировок: один узел уже заблокировал нужные ресурсы, а второй, разумеется, споткнулся об эту блокировку.
Ошибка тестирования здесь кроется в том, что условия первичного тестирования оказались стерильными: обмены по разным узлам тестировались отдельно. Но если в реальной работе используются два узла одного плана обмена одновременно, то тестировать нужно именно их совместную работу. Если бы это было сделано сразу, то можно было бы заранее поднастроить расписания так, чтобы избежать падений.
Следующая ситуация.
Я ранее уже показывал это изображение. Мы же как работаем? Учимся на своих ошибках.
Поэтому мы отменяем проведение и идем смотреть, что будет с документом перемещения, когда он уйдет в другую базу.
Действительно, состояние передалось. Win-win, все замечательно, все классно.
А потом внезапно приходят пользователи и говорят: «Знаете, я пометила на удаление документ, а в другой базе он не пометился».
Мы такие: «Как? Покажите!».
Идем проверять. Но пользователь ведет нас не в форму списка документов, а в журнал.
И в журнале действительно видим, что там осталось предыдущее состояние документа. Хотя мы сами видели, что документ пришел измененным, и запрос возвращает, что «Пометка удаления = Истина».
В чем была проблема? В регистре «Реестр документов».
Все журналы в ERP (а значит, и в производных от нее конфигурациях) строятся по «Реестру документов». И почему-то обмен в момент записи документа в базу просто не прокидывал туда эту информацию.
Ошибка с точки зрения тестирования в том, что мы не учли скрытые зависимости и не пошли по пути пользователя – не учли, как он видит и работает с данными. Мы знаем, что форма списка документов покажет нам реальный результат. Но пользователь-то про нее может и не знать. Она вообще спрятана где-то под шестеренкой.
Следующая история.
Мы дорабатывали часть реквизитов для договоров. Сами знаете, у «Управления холдингом» с этим все очень серьезно. Там, по-моему, порядка 250 дополнительных реквизитов в справочнике. Финансовый департамент, который Уху любил и обожал, попросил добавить часть из них и в УТ, и в БП.
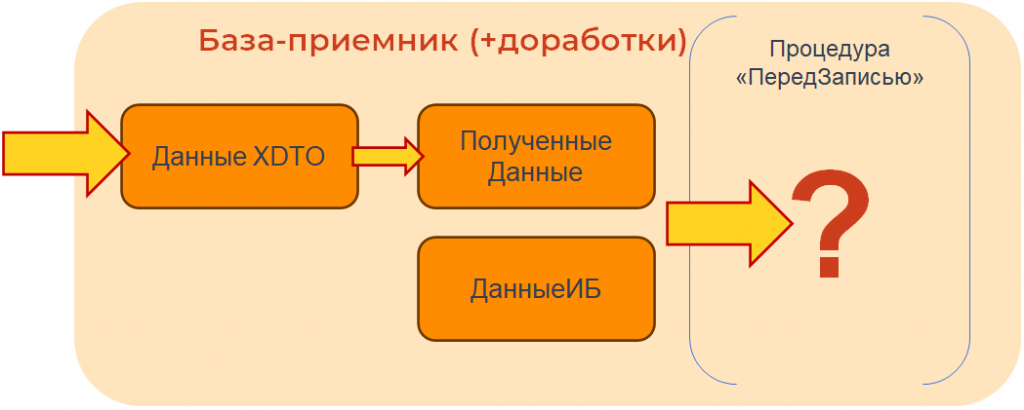
У нас есть база-приемник. Что в нее попадает? Данные XDTO. Потом они преобразуются в «Полученные данные». И дальше, перед записью, определяется, что именно мы будем записывать – «полученные данные» или «данные ИБ», которые в ней уже присутствуют.
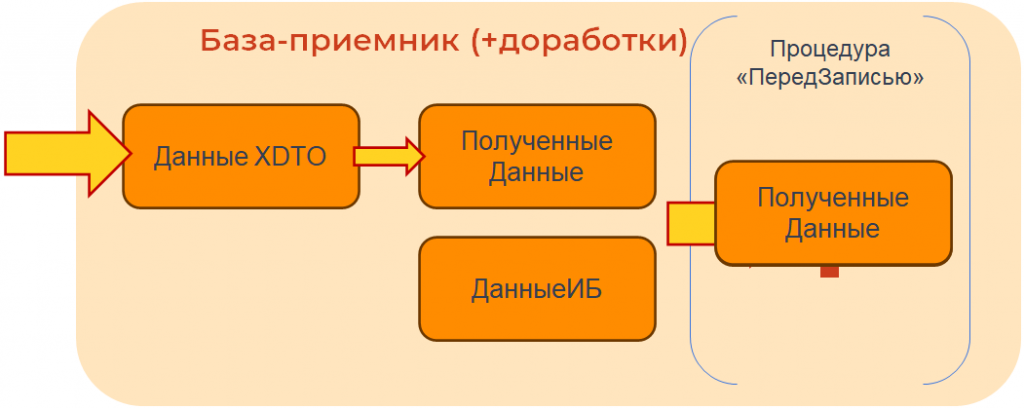
Если это первый обмен, то записываются «полученные данные». И, естественно, в первый раз все передается нормально.
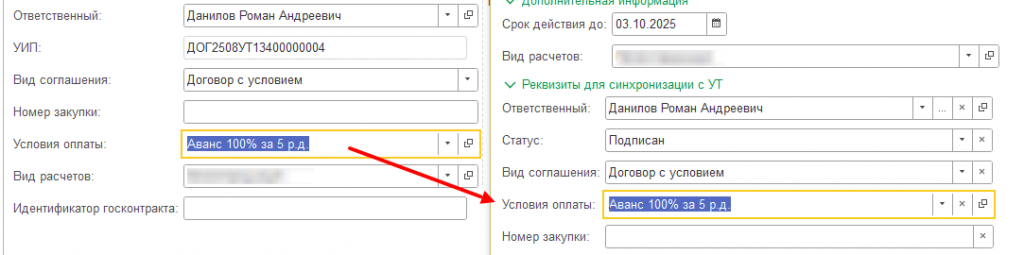
А что будет, если данные, допустим, в Бухгалтерии уже есть?
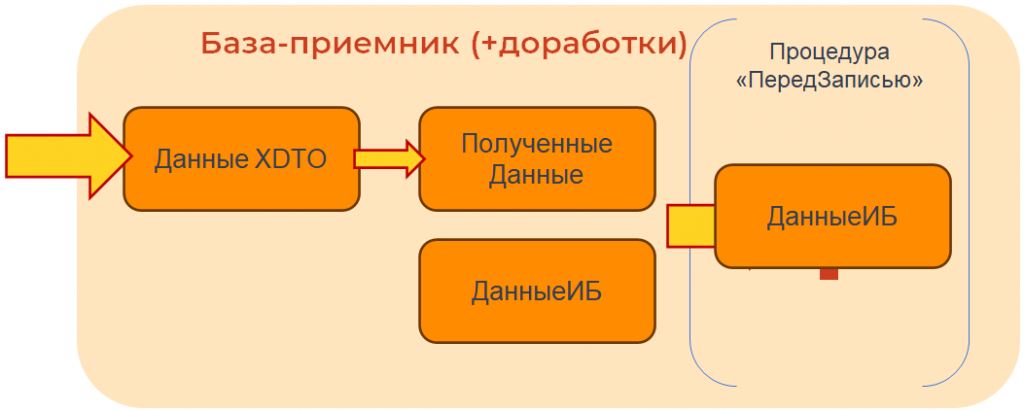
Тогда записаны должны быть «данные ИБ».
То есть если в этом событии «ПередЗаписью» мы не доработаем передачу новых реквизитов в данные ИБ, которые, мы точно знаем, будут записаны в базу, то получим вот такую картину: новые значения доработанных реквизитов не передаются в базу-приемник.
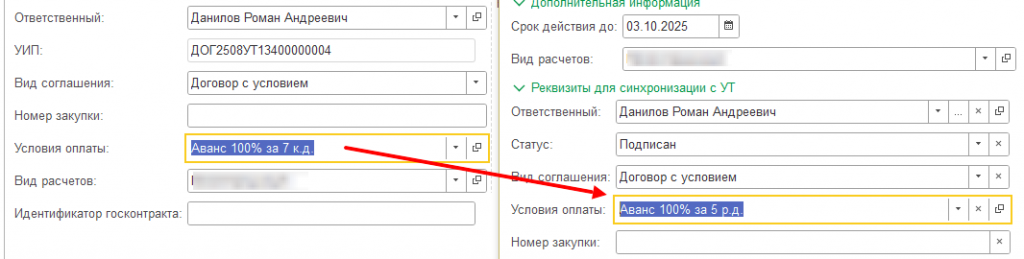
И опять кажется, что где-то ошибся разработчик. Но дело не только и не столько в нем. Мы не проверяли полноту передаваемых данных с учетом перезаписи. Мы убедились в самом факте первичной передачи и на этом поставили галочку – проверено. Все хорошо, все работает. А повторный обмен уже никто не проверял.
Итоги и принципы ручного тестирования интеграций
Хочется подвести итоги и ответить на банальный вопрос, откуда вообще берутся ошибки при тестировании.
-
В первую очередь здесь играет роль человеческий фактор. Мы не заметили, забыли, не успели. Мы отводили ребенка в школу, обещали ночью посидеть над обменом и доработать, и казалось, что все получится.
-
Мы хотели ускорить процесс. Вспомните ту же регистрацию: хотелось побыстрее закончить и отдать на прод.
-
Где-то – просто не хватало опыта и знаний.
Какими принципами нужно руководствоваться при организации ручного тестирования интеграций, чтобы не наступать на те грабли, о которых я рассказывал?
В процессе подготовки тестового контура:
-
Соблюдать полную идентичность тестового и продуктового контура. Это касается не только самой конфигурации, ее состава по метаданным, доработкам и так далее, но и транспорта обмена, и размещения баз. Они должны быть идентичны.
-
Тестовый контур нужно изолировать, чтобы потом никто случайно не нажал не ту кнопку, и данные из теста не улетели в прод.
-
Условия эксплуатации тоже нужно повторять. Вспомним кейс про два узла на одном плане обмена. Если в реальности работают оба сценария одновременно, значит, и тестировать их нужно одновременно, чтобы отловить такие ошибки с блокировками.
В процессе регистрации:
-
Повторять именно пользовательский сценарий, а не пользоваться разными ускорителями и стерильной регистрацией, как это можно делать в обработке.
-
Учитывать разные состояния объектов. Нам мало единожды передать объект. Нужно, чтобы он жил своей жизнью между двумя базами, и при этом сохранялась идентичность данных.
При проверке результата:
-
Нельзя полагаться на «авось». Подход с приемо-сдаточными испытаниями, когда из партии достают пару агрегатов вместо проверки всей партии, здесь не работает. При ручном тестировании вы обязательно какую-нибудь ошибку пропустите. Это не завод, здесь другая история.
-
И, конечно, важно знание технологий. Когда мы знаем технологии и те инструменты, которые мы тестируем, это позволяет нам быстрее и качественнее находить причины ошибок.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт