Немного о себе
Я работаю в крупной строительной организации «Трансстроймеханизация». Наша организация является крупным строительным холдингом, занимается строительством дорог общественного пользования, взлетно-посадочных полос. Нашу технику можно было видеть в Шереметьево, в сочинских аэропортах.
О чем будет доклад
Тема доклада – “Менеджер потоков”, инструмент, позволяющий вести разработку алгоритмов, которые будут работать параллельно. При этом “Менеджер потоков” возьмет на себя максимум трудностей, с которыми может столкнуться разработчик при работе с потоками.
Кто далек от этой темы, кратко расскажу:
- что такое “потоки”;
- какие бывают способы распараллеливания;
- чем является “Менеджер потоков”;
- какие методы он позволяет использовать при распараллеливании;
- архитектура “Менеджера потоков” при обмене данными;
- общие принципы его работы;
- “События” и “ресурсы”.
Для тех, кто захочет попробовать “Менеджер потоков” в деле, будет показано, как реализовать самые простые примеры.
Чтобы подогреть интерес к докладу, покажу результаты, которых можно достичь с помощью данного инструмента.
Результаты тестов по восстановлению последовательности партий
Многие из Вас знают такую процедуру, как “Восстановление последовательности партий”. Насколько данная процедура является ресурсоемкая по времени и ничтожна по затрачиваемым ресурсам. Также она достаточно критична к времени захвата таблицы и важна для каждого закрытия месяца.
На чем проводились тесты? Тесты проводились на платформе 8.3.10, режим совместимости 8.2.13, read committed snapshot у нас отсутствует. Мы еще не переехали на вариант без режима совместимости. База данных – “Управление производственным предприятием”. Размер базы 280 гигабайт, 1 юридическое лицо.
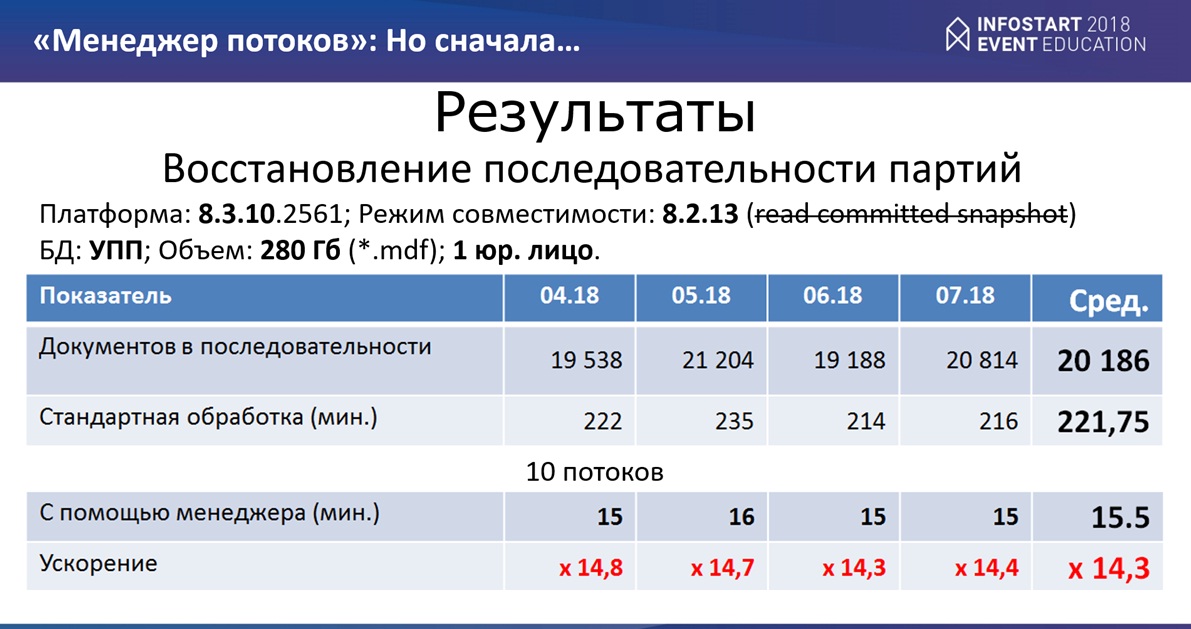
Тесты проводились на реальной базе, по четырем месяцам, размеры базы по количеству документов не очень большие – всего 20 тысяч документов месяц. Стандартное время обработки данного объема данных у нас занимает примерно 3,5 часа. Притом доступ у нас монопольный. Ни один из пользователей не может провести никакой документ, связанный с партиями, иначе у нас партии могут не восстановиться.
Запускался “Менеджер потоков” на 10 потоках.
Результаты получились у нас следующие: “Восстановление партий” у нас, стало происходить за 15,5 минут - ускорение в 14,5 раз и самое главное без монопольного доступа.
Вопрос в студию: ни у кого вопросов не возникает по данным результатам?
Возникает?
Я думаю, это вопрос “Как получились такие результаты”?

С чем связан этот вопрос? Связан он с тем, что в стандартном механизме “Восстановления партии” есть одна очень ресурсоемкая процедура, которая называется «СдвинутьПоследовательностьВперед». Именно она занимает львиную долю времени. Если ее убрать (при восстановлении в потоках, мы ей не пользуемся), то стандартное время восстановление будет проходить, в нашем случае, за 1,5 часа. Тогда восстановление в потоках у нас будет уже не 14-кратное, а 6-кратное. Это уже более-менее логично.
В нашем докладе будут принимать участие:
 сеанс «Основной программы» – этакий босс, ставит задачу, ждет результатов;
сеанс «Основной программы» – этакий босс, ставит задачу, ждет результатов;

 сеанс «Менеджера потоков» – строгий дядька, контролирует все, следит за тем, чтобы вся работа шла;
сеанс «Менеджера потоков» – строгий дядька, контролирует все, следит за тем, чтобы вся работа шла;

 сеансы “Потоков” – ребята-работяги, им сказали копать отсюда и до обеда, вопросов не задают - работают.
сеансы “Потоков” – ребята-работяги, им сказали копать отсюда и до обеда, вопросов не задают - работают.

Это наши герои.
Помимо этого, у нас еще будет супер-герой – господин “Зануда”  . Он будет присутствовать на ряде слайдов. Где он будет присутствовать, слайд будет достаточно важным с точки зрения понимания архитектуры или внутренних тонкостей.
. Он будет присутствовать на ряде слайдов. Где он будет присутствовать, слайд будет достаточно важным с точки зрения понимания архитектуры или внутренних тонкостей.
Еще, как во многих фильмах, у нас будет с Вами массовка. Чтобы было не очень скучно.

Что такое потоки
Кратко для тех, кто далек и не знает что такое “потоки”. Это запуск каких-то инструкций или процедур в нескольких узлах, на которые мы подаем определенные данные и ускоряем работу за счет того, что большой массив бьем на маленькие кусочки.
Основная цель очень простая – ускорение работы и утилизация свободных ресурсов сервера.
Способы распараллеливания
По классификации Флинна способов распараллеливания 4. Они описывают работу процессоров, но для лучшего понимания в принципе тоже подойдут.
- Первый способ самый простой – полное отсутствие распараллеливания;
- Второй способ – дублирование расчетов. Данный способ используется на критически важных объектах, где стоимость ошибки очень высока. Например, я точно знаю, что при запуске в СССР корабля “Буран” расчетом телеметрии и определенных параметров занимались несколько модулей сразу – по-моему, три. Если какой-то давал результат, который не совпадал с двумя другими, его данные просто-напросто отбраковывались.
- Следующий вариант, он очень многим знаком, это как раз, когда массив данных бьется на маленькие кусочки, которые посылается в разные узлы и над ними выполняется какая-то инструкция.
- Последний вариант – это то, как работают нынешние многопроцессорные системы, многоядерные процессоры. Когда у Вас, в один момент времени, над объемом данных работают разные инструкции. Один из методов, реализованных в “Менеджере потоков”, позволяет использовать такой подход.

Что же такое менеджер потоков?
С точки зрения метаданных это один общий модуль. Больше ничего нет. Вообще. Как хотите, так и используйте его. Хотите – в расширение заталкиваете, хотите – в метаданные засовываете.
Пока это идет как обычная *.cf, просто обновляете конфигурацию.

Но этого будет мало. Помимо этого, Вам, как разработчикам, потребуются “модули событий разработчика”. Что это такое, расскажу дальше. Сейчас я только лишь расскажу, где Вы можете их разместить.
- Первый вариант – самый простой и самый лучший, как я считаю, – это под каждую процедуру многопоточной обработки делать отдельный “Общий модуль”. Таким образом Вы, по крайней мере, как-то локализуете свой пакет событий. Это просто упрощает дальнейшую навигацию, поиск каких-то корректировок, ошибок, доработки своих алгоритмов.
- Следующий вариант – разместить алгоритмы в “Модуле объекта” внешней обработки. Когда может потребоваться? Например, у заказчика уже установлен “Менеджер потоков” конфигурации, а Вы хотите произвести какую-то обработку, которая будет многопоточно обрабатывать данные. Вы полностью весь код можете разместить в этой обработке, абсолютно не внося код в конфигурацию поставщика. И все будет работать.
- И последний вариант, в принципе, я его не рекомендую использовать, но он, как пережиток прошлого, остался. Это размещение событий разработчиков в самом “модуле менеджера потоков”. Не рекомендую по той простой причине, что если будут выходить обновления, придется заниматься сравнением и объединением, как со всеми конфигурациями.
Поэтому пользуйтесь отдельными общими модулями под каждую задачу.
Если с другой стороны посмотреть. Можно провести аналогию с 1С. В 1С, мы знаем, есть инструмент – платформа (конфигуратор) и есть решения, которые мы получаем с помощью этого инструмента. Есть другой инструмент, например, “Конвертация данных”. эту конфигурацию многие знают, умеют пользоваться. И есть решения, которые мы можем с помощью этого инструмента получить. “Менеджер потоков” также является инструментом, а “модули событий разработчика” являются вашими решениями, которые Вы можете разрабатывать и использовать в своей работе.
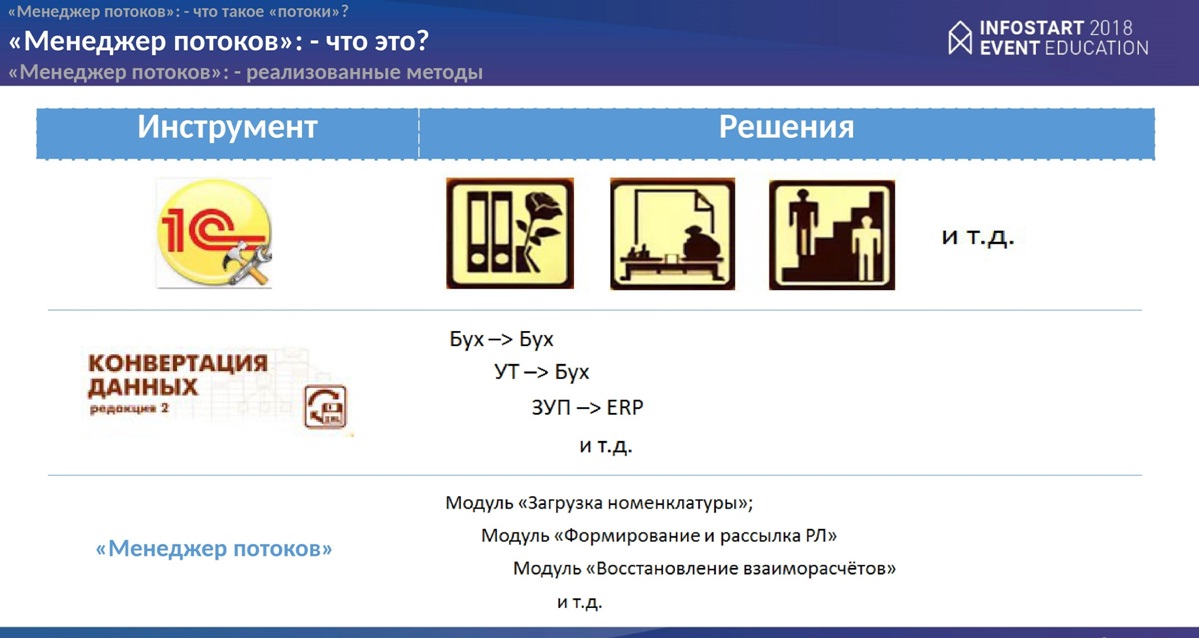
Реализованные методы
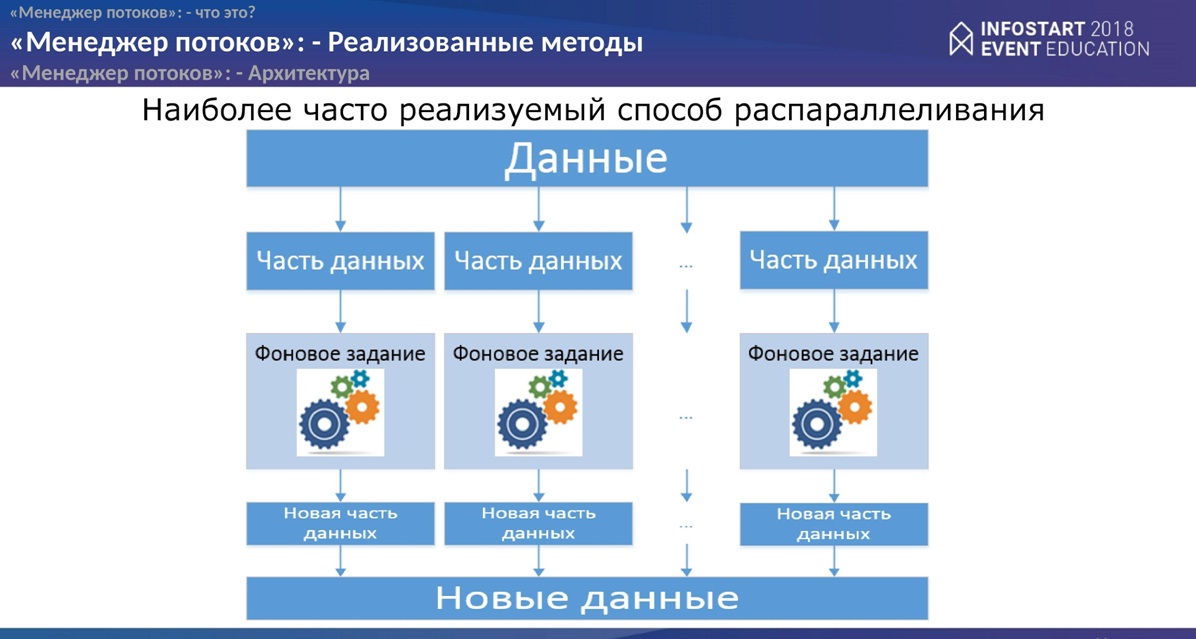
Прежде чем говорить о реализованных методах, расскажу о тех способах, как часто используют распараллеливание в 1С.
У нас есть большой массив данных, который мы бьем на много-много маленьких кусочков. Каждый кусочек посылаем свое фоновое задание, где его как-то обрабатываем. В принципе все - никаких проблем. Но бывают иногда случаи, когда нужно данные вернуть обратно. Тут уже возникают некоторые сложности. Сложности, например, могут возникнуть с таким понятием, как “склейка”. Потому что данные, например, надо склеить в той же самой последовательности, в какой они были до того как отправились в потоки. Еще появляется вопрос, как вернуть данные из фоновых заданий обратно клиенту? Обычно тут используется “Временное хранилище”.
Но сложностей будет гораздо больше. Эти все проблемы на себя берет “Менеджер потоков”. Вам больше не надо будет ломать голову, как решить ту или иную задачу.
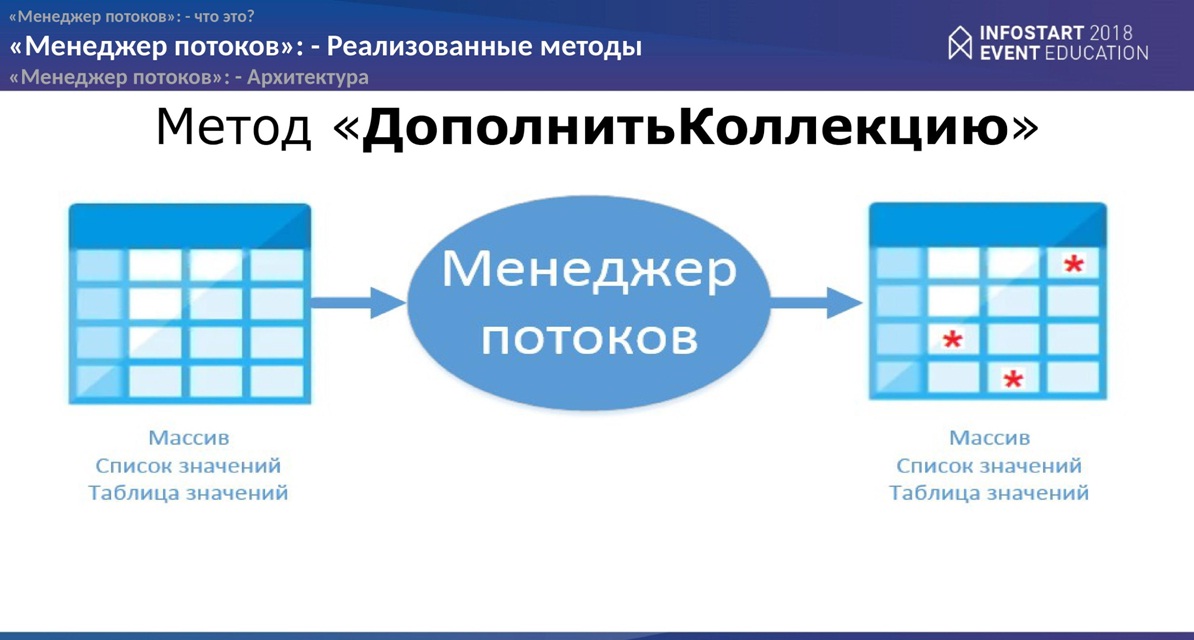
Методы, которые реализованы в “Менеджере потоков”.
На данный момент их насчитывается 3.
- Первый – самый простой – «ДополнитьКоллекцию». Допустим, у Вас есть коллекция либо “Массив”, “СписокЗначений”, “ТаблицаЗначений”. Вы эту коллекцию посылаете в “Менеджер потоков”, на выходе получаете копию этой коллекции, но уже измененную, на сколько измененную, Вы опишете в событиях разработчика.
- Второй вариант очень похож на первый, но на выходе Вы получаете произвольный тип данных. Какой, также Вы сами определите. Можете вообще никакие данные не возвращать, просто обработать коллекцию в многопоточном режиме.
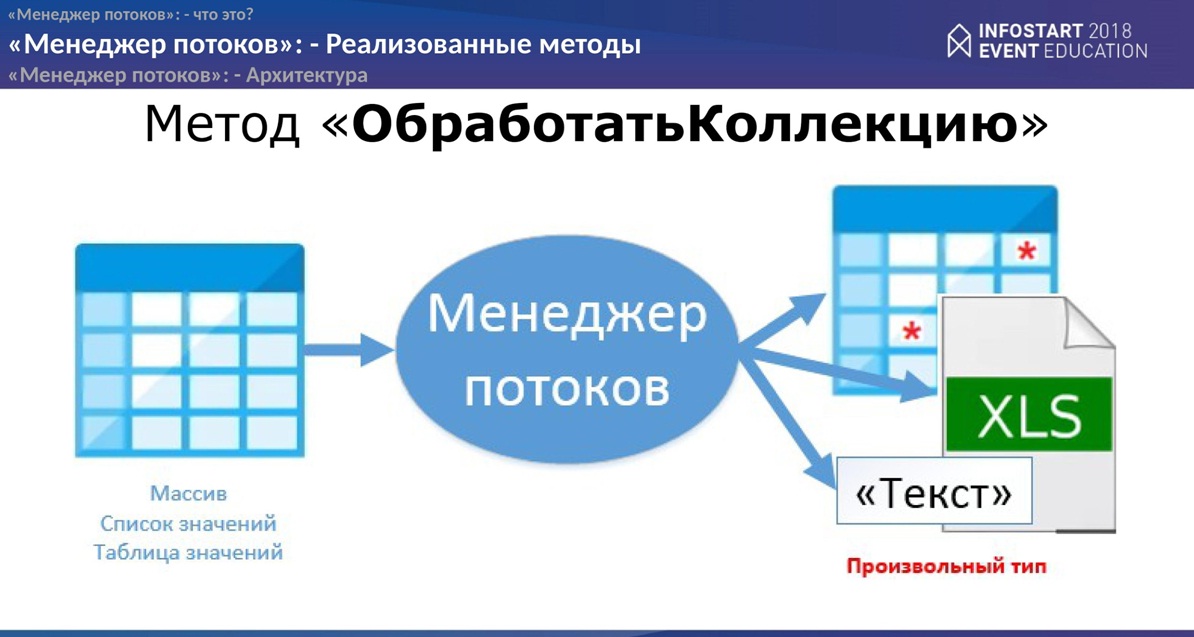
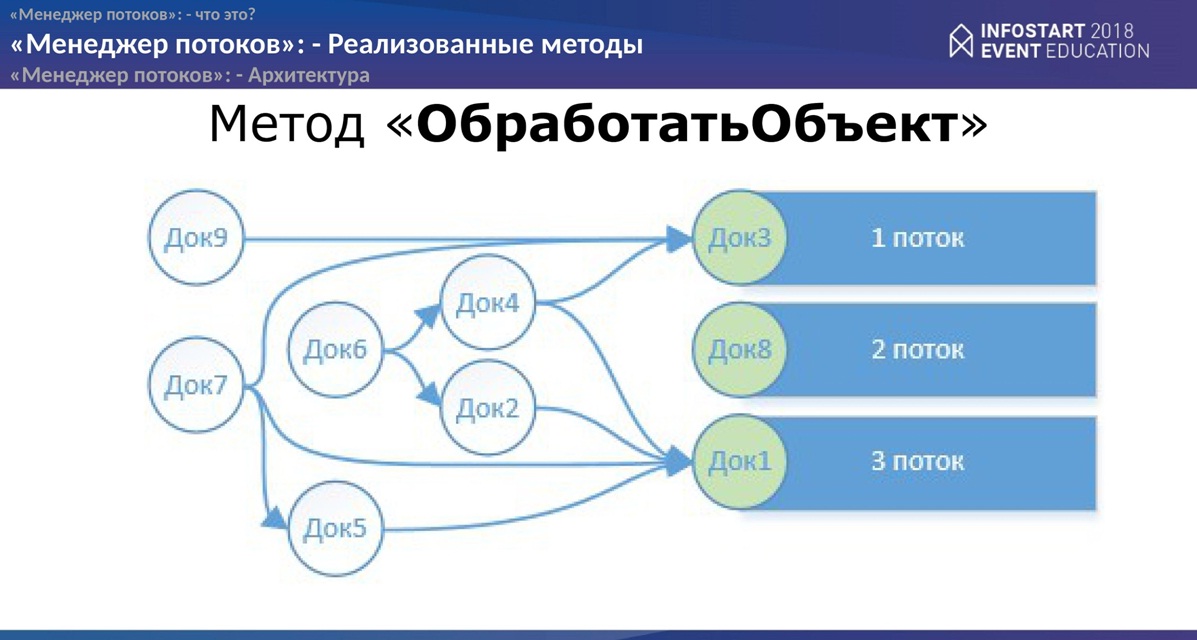
- Третий вариант, наверное, самый сложный, но и самый интересный. Из этой задачи и родился “Менеджер потоков”, как отдельная разработка. Данный метод позволяет “Менеджеру потоков” строить граф зависимости объектов в своей памяти и посылать объекты на обработку уже не в порядке следования в той коллекции, которую Вы берете для обработки, а по определенным механизмам связывания объектов. Как объекты будут связаны между собой, также определяете Вы в “событиях разработчика”.
Данный вариант Вам подойдет, например, в процедуре “восстановления партии”, процедуре “восстановления взаиморасчетов контрагентов”. Может быть, есть какие-то “цепочки формирования производственных документов”, где документы должны идти в строгой последовательности. Как вариант еще может быть обработка каких-то объектов, которые друг друга блокируют по пересечению измерения регистров. Чисто теоретически тоже можно воспользоваться “Менеджером потоков” и обработать массив объектов в потоках без блокировок.
Архитектура
Как организована вся архитектура внутри менеджера потоков?
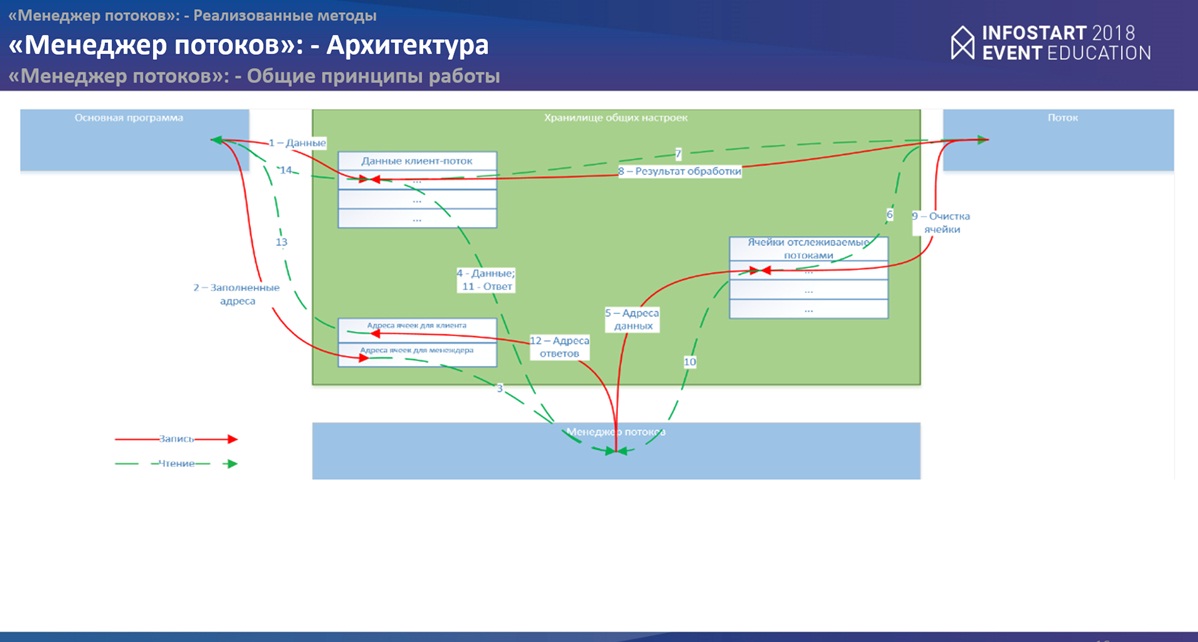
У нас есть “Основная программа”, есть “Фоновое задание менеджера потоков”, есть запущенные “Потоки”. Весь обмен данных между ними происходит с помощью “Хранилища общих настроек”. Замечательный объект в 1С, который позволяет хранить произвольный тип данных. То есть мы уходим от “Временного хранилища”, мы уходим от файловой передачи данных. Замечательный объект, который позволяет эти все вопросы решить. В рамках данного хранилища реализуется следующее:
- Пул данных “ячеек потоков”, который равен количеству запущенных потоков, для каждого потока своя отдельная ячейка, за которой он следит.
- Пул данных “клиент-поток”. Это те ячейки, куда подаются данные для обработки потоками. Их количество несколько другое и зависит от определенного коэффициента. На значение данного коэффициента Вы, как разработчик, также можете влиять. По умолчанию я его поставил равным 3. Данный коэффициент имеет очень высокое значение, он может позволить как увеличить распараллеливание и ускорить обработку данных, так и уменьшить ее, т.к. при большом значении этого коэффициента “Менеджер потоков” может заниматься больше обсчетом графа, нежели “Потоки” будут выполнять работу непосредственно с самими данными. Количество этих ячеек определяет размер графа, с которым одновременно работает “Менеджер потоков”. Те данные, которые не успевают попадать в граф, копятся в отдельные очереди.
- Еще один пул ячеек – их всего 2е – для того, чтобы менеджер потоков и основная программа как-то тоже обменивались данными.

Как в общем происходит самая работа?
- “Основная программа” подает данные на обработку в свободные ячейки (пул “клиент-поток”).
- Для “Менеджера потоков” сообщает адреса, в которых находятся данные, которые мы посылаем на обработку.
- Менеджер потоков крутится в цикле (других вариантов придумать не получилось), мониторит свою ячейку обмена с “Основной программой”, смотрит, появились там данные или нет. Если данные появились, “Менеджер потоков” их забирает.
- По полученным адресам “Менеджер потоков”, забирает данные из пула “Клиент-Поток”. После этого он строит независимый граф, определяет, какие потоки свободны.
- В свободные потоки перенаправляет адреса ячеек, где хранятся данные.
- “Поток” также крутится в цикле, следит за своей одной ячейкой. Как только “поток” видит, что данные в ней появились, он их считывает.
- По полученному адресу “поток” забирает данные из пула “клиент-поток” и как-то их обрабатывает.
- После того как данные будут обработаны, “ответ” от “потока” складывается в ту же самую ячейку, откуда были данные взяты (пул “клиент-поток”).
- Ячейка, за которой “поток” следит - очищается.
- “Менеджер потоков” знает, какие “потоки” у него сейчас работают, следит за теми ячейками, с которыми “потоки” работают. Как только он видит, что ячейка освободилась, “Менеджер потоков” понимает, что “поток” закончил свою работу
- “Менеджер потоков” забирает данные для анализа. На этом этапе “Менеджер потоков” принимает решение, что делать дальше. Вариантов может быть три:
- Первый вариант – “Пропуск” – мы сообщаем “Основной программе”, что объект не требует никакой дальнейшей обработки. Если смотреть с точки зрения “Восстановления последовательности партии”, это у нас может быть обработка документа “Поступление товаров и услуг”.
- Второй вариант - потоки “Рассчитали ресурсы” (об этом будет сказано дальше). “Менеджер потоков” забирает данные по этому объекту к себе, строит граф, уже зависимый. Устанавливает связи по рассчитанным ресурсам этого объекта с другими объектами, которые стоят в обработке, и при наступлении определенного момента посылает этот объект дальше на обработку в “потоки”.
- Третий вариант - “поток” вернул “Ответ”, то есть полностью закончил обработку объекта
- “Менеджер потоков” консолидирует информацию на данной итерации и сообщает “Основной программе”, список адресов с результатами.
- “Основная программа”, пока работает “Менеджер потоков”, также крутится в цикле. Она смотрит за своей ячейкой, где ей будут приходить результаты. Увидев, что там появились какие-то данные, она их забирает
- По полученным адресам “Основная программа” забирает результаты из пула “клиент-поток”.

Общая схема в принципе выглядит примерно так:
Общие принципы работы
Тут на самом деле все очень просто.
Инициализация. Что у нас есть? У нас есть “Основная программа”. В ее рамках
Мы, как разработчик, определяем параметры для работы с “Менеджером потоков” после чего происходит запуск фонового задания “Менеджера потоков”. В свою очередь “Менеджер потоков” принимает на себя весь пакет параметров, который Мы передали при инициализации и производит запуск самих фоновых “Потоков”.

Поддержка работоспособности. У нас есть “Менеджер потоков”, есть “Фоновые задания потоков”. “Менеджер потоков” раздает данные “Потокам” и бдительно за ними следит, чтобы “Потоки” работали корректно.
Но не все бывает так гладко - “потоки” могут падать. “Менеджер потоков” знает, что такая проблема бывает, он “поднимает поток”. Но “поток” может снова упасть. “Менеджер потоков” знает, что эта процедура бывает непростая. Он это все дело пытается повторить несколько раз. Сколько раз, определяется с помощью определенного параметра – “ПределКоличестваПопытокОбработатьОбъект”. По умолчанию этот параметр равен 5 (в последней версии сокращен до 1). То есть 5 раз “Менеджер потоков” пытается обработать один и тот же объект. Но может быть ситуация, что объект просто нельзя обработать, потому что какой-то реквизит не задан и объект, например, не проводится и не записывается. По достижении данного порога “Менеджер потоков” все-таки возобновляет работу “потока”, но данные в него уже не передает, а “Основной программе” он сообщает, что обработать данный объект не удалось.

Завершение работы. Как было сказано, у нас “Менеджер потоков” бдительно следит за работой “потоков”. Но при этом “потоки” – это тоже ребята не простые, они тоже присматривают за менеджером. Если по каким-то причинам “Менеджер потоков” выходит из строя, а причины могут быть разные. “Потоки” говорят, что им тоже жизнь не мила без их менеджера.
Если “Менеджер потоков” прекратил свою работу на этапе обработки данных, предположим, вскрылась какая-то критическая ошибка, “Основная программа” выдаст ошибку. Если же “Менеджер потоков” прекратил свою деятельность по той простой причине, что он просто все обработал и больше обрабатывать ничего, “Основная программа” продолжает дальнейшую работу.
Если по каким-то причинам придется непосредственно остановить “Менеджер потоков” (всякое бывает), никаких проблем нет. Вызываем одноименный метод, “ОстановитьМенеджерПотоков”, где указываем его идентификатор (строковый, указанный при инициализации). В рамках информационной базы выполнения данного метода можно произвести на любом сеансе.

События
Что такое события?
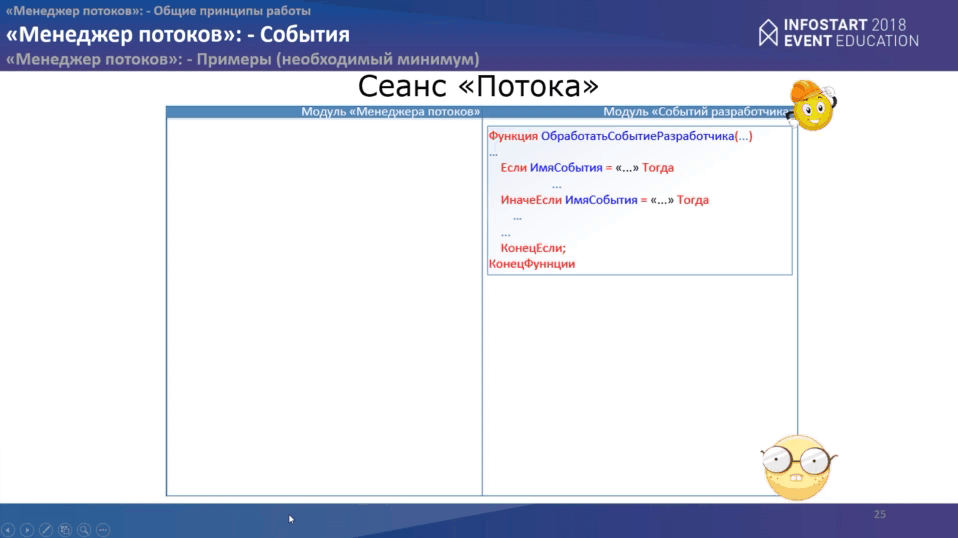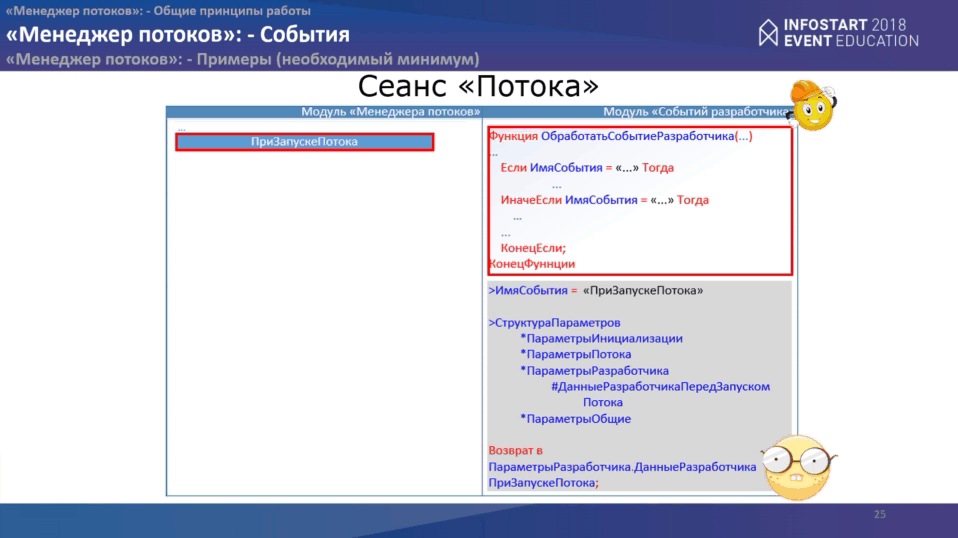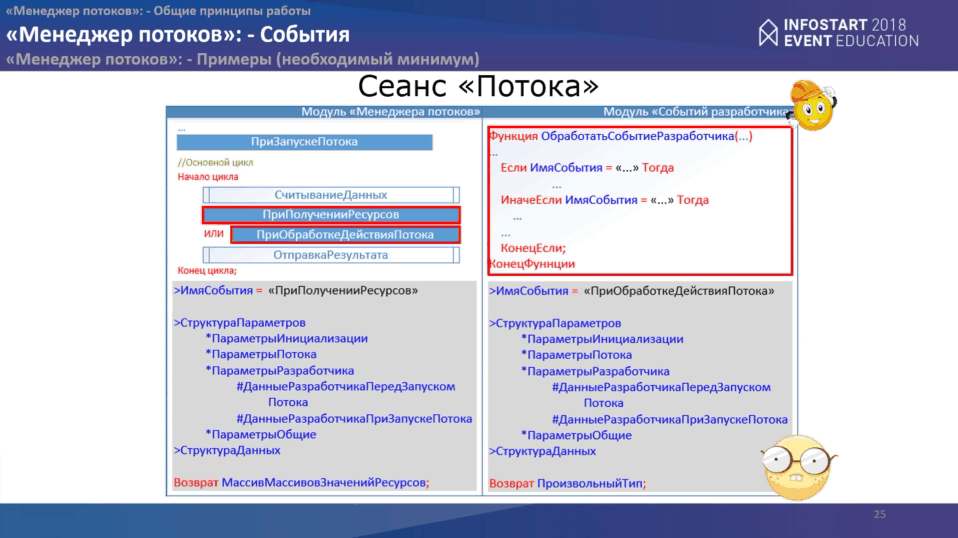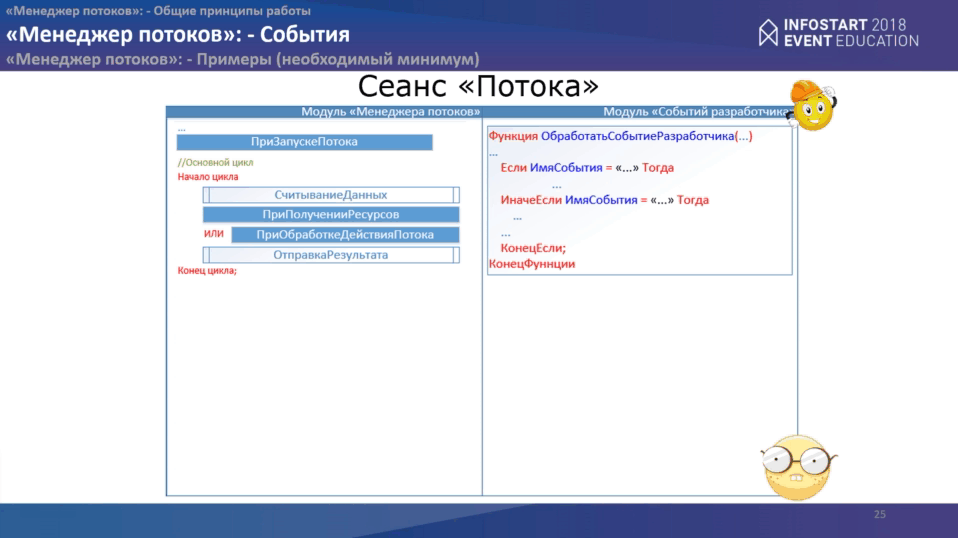
“События” – это, можно так сказать, “окошки” в алгоритмах менеджера потока, с помощью которых разработчик может существенно влиять на работу “Менеджера потоков”. По большому счёту, это эквивалент подписок на события. Они даже примерно так и называются. Количество событий на сегодняшний момент 15. Между нашими героями они распределены примерно в таком варианте:

Можно заметить, что некоторые события являются процедурами, некоторые – функциями. События, являющиеся функциями, позволяют свой результат передавать в другие события, притом даже между участниками. Если, например, в событии “ПриЗапускеМенеджераПотоков” выполнить какие-то действия, собрать какой-то пул данных, то его можно получить на стороне каждого потока, при этом не рассчитывая каждый раз.
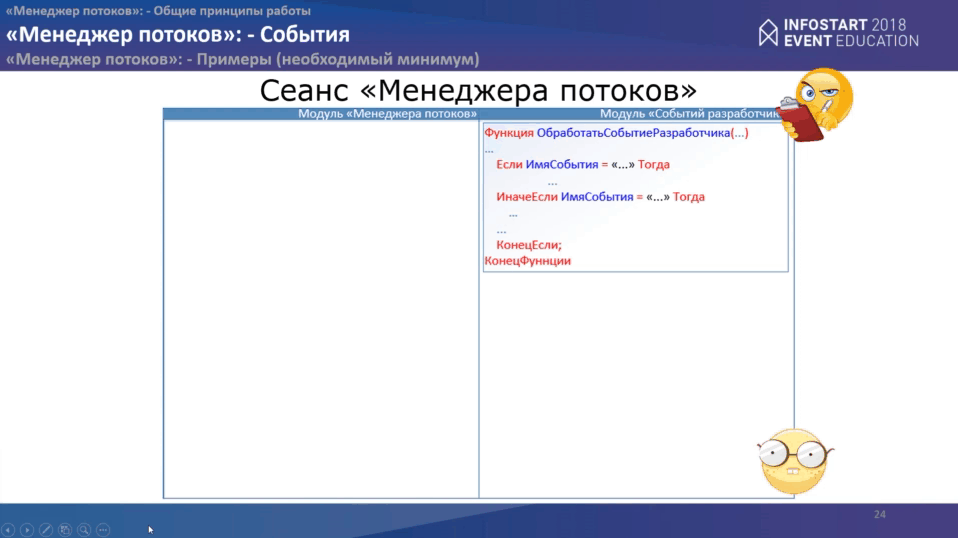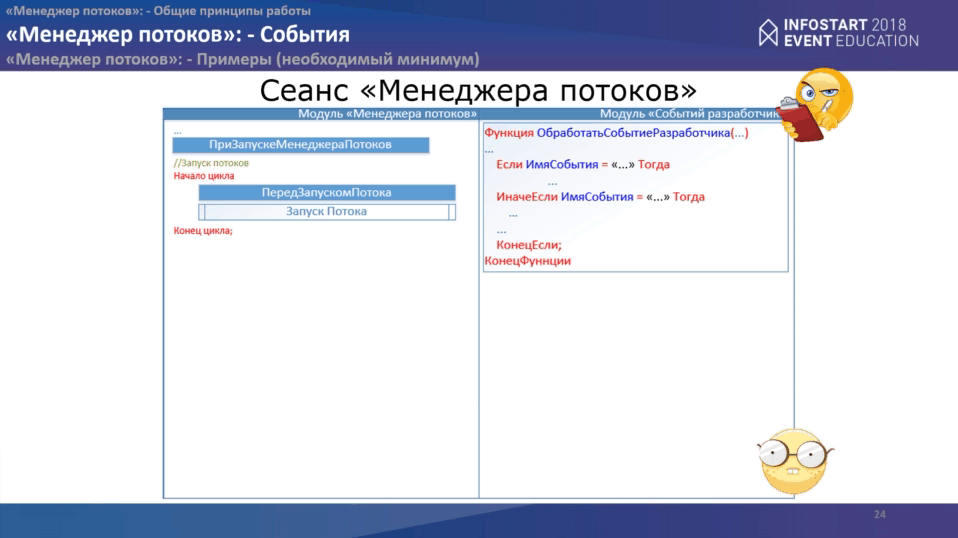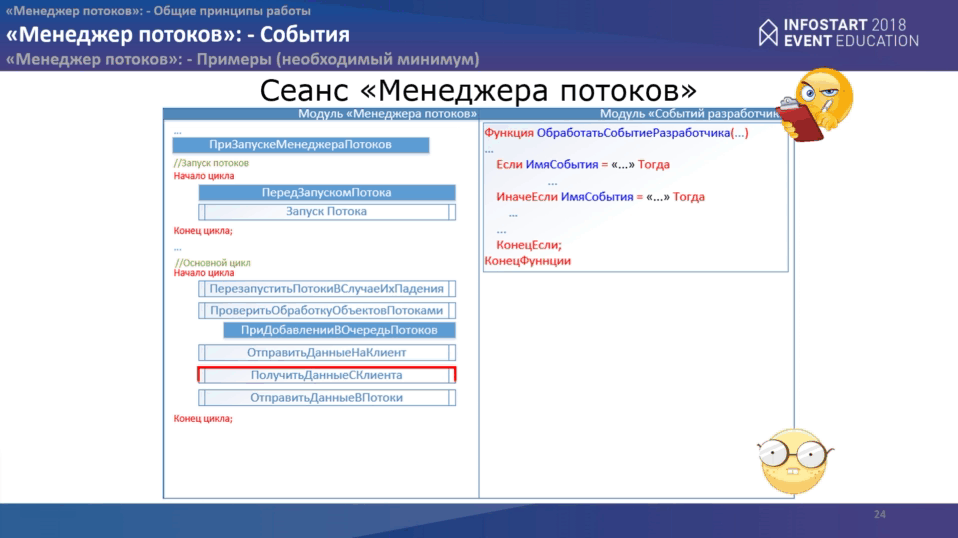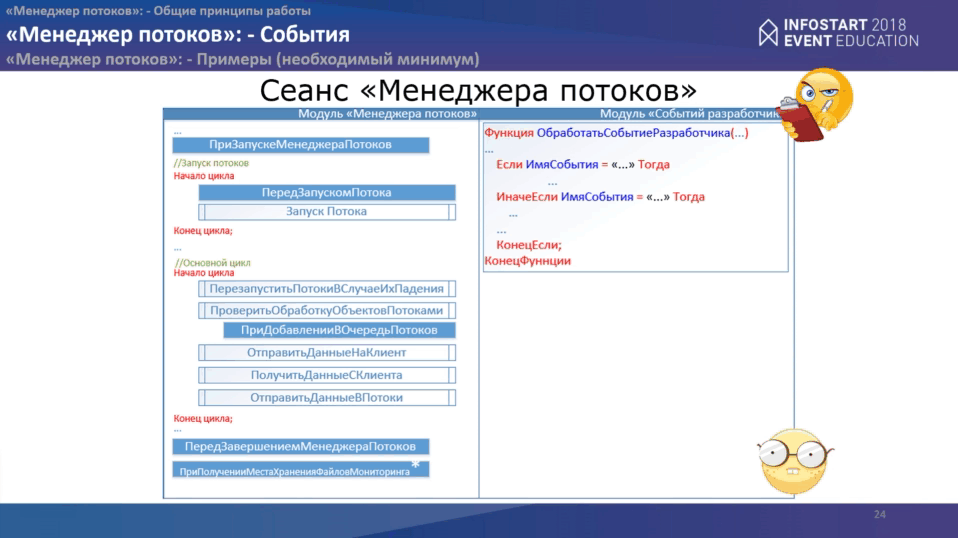
Работа менеджера потоков в разных сеансах.
Сеанс основной программы. У нас есть модуль “Основной программы”, есть модуль “Менеджера потоков”. В рамках “Основной программы” надо произвести инициализацию, где указать место расположения событий разработчика “менеджера потоков” как имя модуля и имя функции. В этот момент подключается библиотека с событиями разработчика. Она достаточно простая – одна функция, где через оператор “Если” мы перебираем все события, которые у нас могут быть и в зависимости от события, мы выполняем те или иные действия.
Дальше производим инициализацию “Менеджера потоков”. Срабатывает самое первое событие “ПередЗапускомМенеджераПотоков”, где вызывается функция, куда передается по умолчанию два параметра, но параметров может быть 3 (максимум) в зависимости от событий. После этого происходит запуск “Менеджера потоков”. Затем происходит запуск основного цикла обработки коллекции, где мы передаем объекты. В рамках данного цикла происходит:
- получение данных из “Менеджера потоков” и обработка следующих событий
- ПриОбработкеОшибки;
- ПриОбработкеОтвета;
- ПриОбработкеПропуска.
- Потом происходит отправка новых данные в “Менеджер потоков”
После обхода основного цикла выполняется метод «ДождатьсяОстановкиМенеджераПотоков», в рамках которого накопленная очередь продолжает обрабатываться, потому что не все может происходить в один момент времени, она обрабатывается по тому же самому алгоритму, как и основная обработка всех объектов.
В конце вызывается завершение метода “Менеджера потоков” и еще 2 события:
- первое связано с мониторингом;
- второе - “ПослеЗавершенияМенеджераПотоков” - последнее событие, в котором Вы можете что-то еще дополнительно сделать.

В рамках “Менеджера потоков” все чуть проще.
У нас срабатывает первое событие при начале менеджера потоков “ПриЗапускеМенеджераПотоков”, как и в основном сеансе программы. Затем запускается цикл запуска “потоков”, перед запуском каждого потока, можно обработать еще одно события “ПередЗапускомПотока”, затем выполняется запуск самого потока.
После этого идет основной цикл программы, в рамках которого мы проверяем:
- состояние потоков;
- проверяем данные, которые у нас были обработаны;
- отправляем данные “Основной программе”;
- получаем новые данные от “Основной программы”;
- отправляем данные в “потоки”.
В конце снова два события:
- “ПередЗавершениемМенеджераПотоков”
- и еще одно событие, связанное с мониторингом.
У “потока” все еще проще. Также у нас первое событие “ПриЗапускеПотока”. Основной цикл здесь очень простой:
- считываем данные;
- выполняем одно из двух действий. Поток на сегодняшний момент выполняет только два действия:
- либо рассчитывает ресурсы,
- либо обрабатывает сам объект.
- затем он отправляет результаты своей работы.
Примеры
Самые простые примеры, необходимый минимум, что необходимо сделать для того, чтобы что-то заработало.
Метод “ДополнитьКоллекцию” очень простой. Что нам надо? На стороне основной программы пишем две строчки:
- получаем структуру параметров инициализации “Менеджера потоков”, куда передаем идентификатор менеджера и место расположения событий разработчика.
- После этого вызываем метод «ДополнитьКоллекцию», куда передаем структуру параметров и коллекцию.
Между двумя этими методами Вы, как разработчик, можете поменять параметры менеджера как Вам угодно. Все основные параметры, которые необходимы закладываются по умолчанию.
На стороне менеджера Вам нужно обработать всего одно событие “ПриОбработкеДействияПотока”. Код будет выглядеть примерно так:
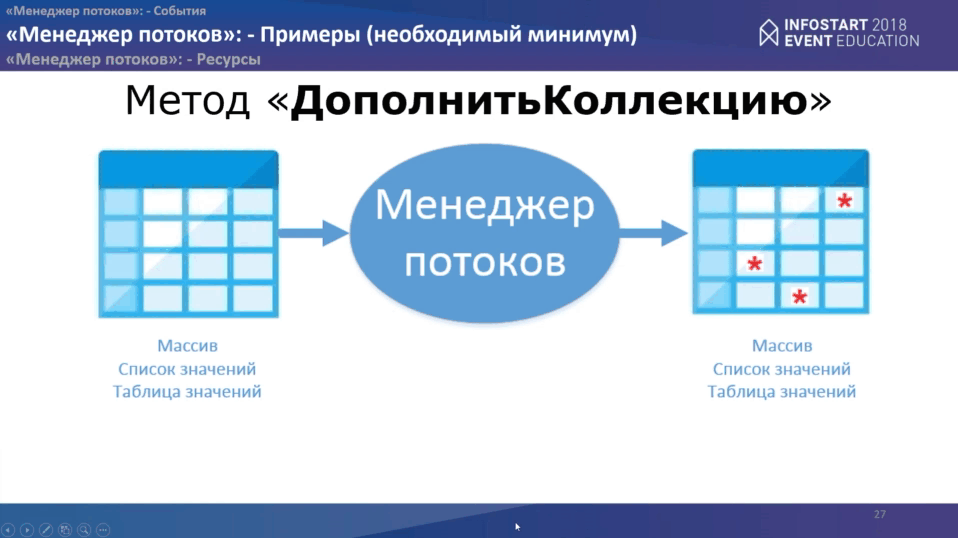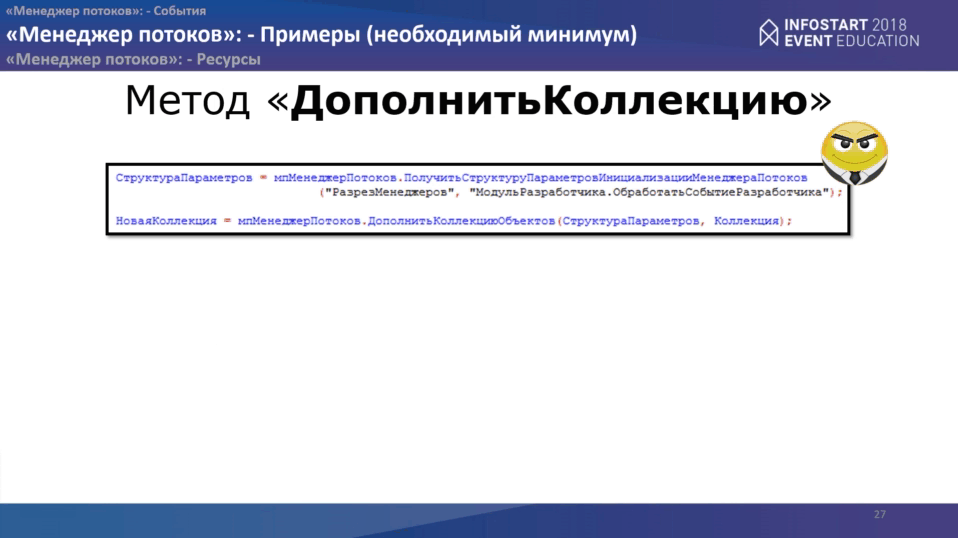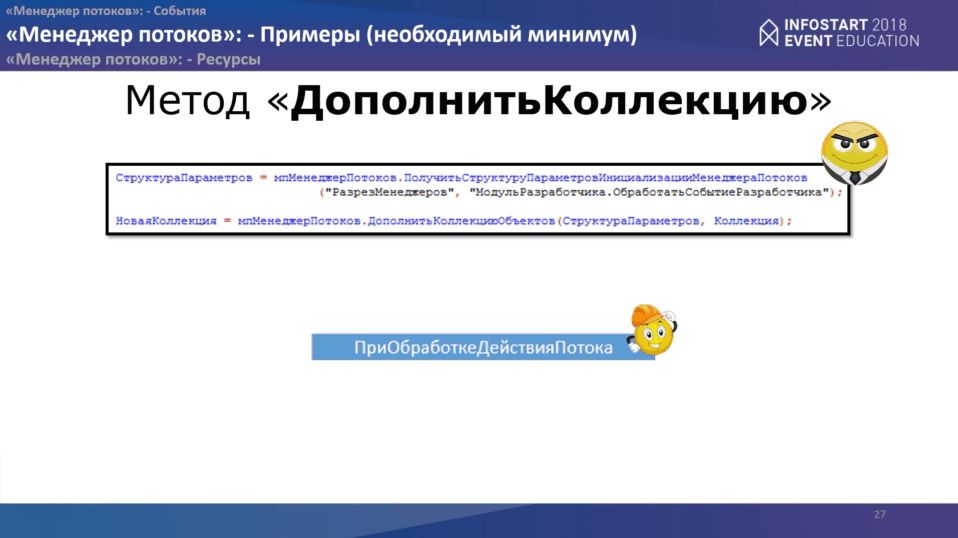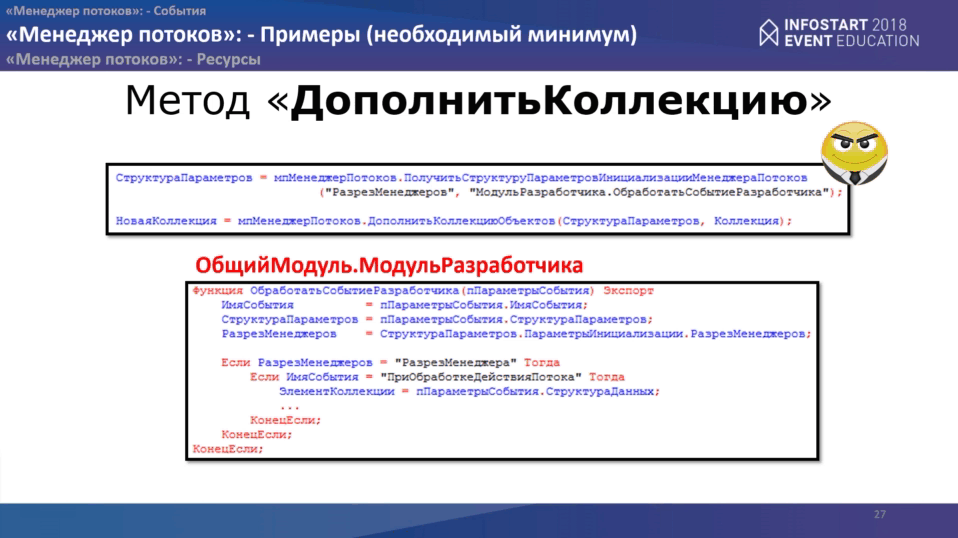
Это Ваш модулей событий разработчика, маленькая заготовка, где показан код, как можно достучаться до элемента коллекции. Дальше с этим элементом делаете всевозможные манипуляции – меняете, делаете поиск данных, подставляете какие-то значения, все, что хотите. И в конце в переменную “НоваяКоллекция” у Вас вернется уже обновленная коллекция, обработанная в потоках.
Метод “ОбработатьКоллекцию” очень похож на предыдущий. Здесь все
очень просто, все то же самое. Единственное – меняется сам метод, который Вы используете. Но событий надо обработать уже два:
- первое событие точно такое же как “ПриОбработкеДействийПотока”
- второе – “ПриОбработкеМассиваОбработанныхФрагментовКоллекции”.
Здесь код примерно такой же.
Но здесь немножко меняется концепция: в события “ПриОбработкеДействияПотока” уже дается не элемент коллекции, а фрагмент коллекции, с которым Вы производите какие-то манипуляции.
И в событии “ПриОбработкеМассиваОбработанныхФрагментовКоллекции” мы получаем уже отсортированный в нужном порядке массив фрагментов, который посылался на обработку в потоке, объявляется новая коллекция, которую Вы хотите получить на выходе, ее каким-то образом компонуете (как внешние таблицы СКД, как табличный документ и т.д.).
Про метод «ОбработатьОбъект» пока рано говорить. Надо сначала обсудить ситуацию с “Ресурсами”.
Ресурсы
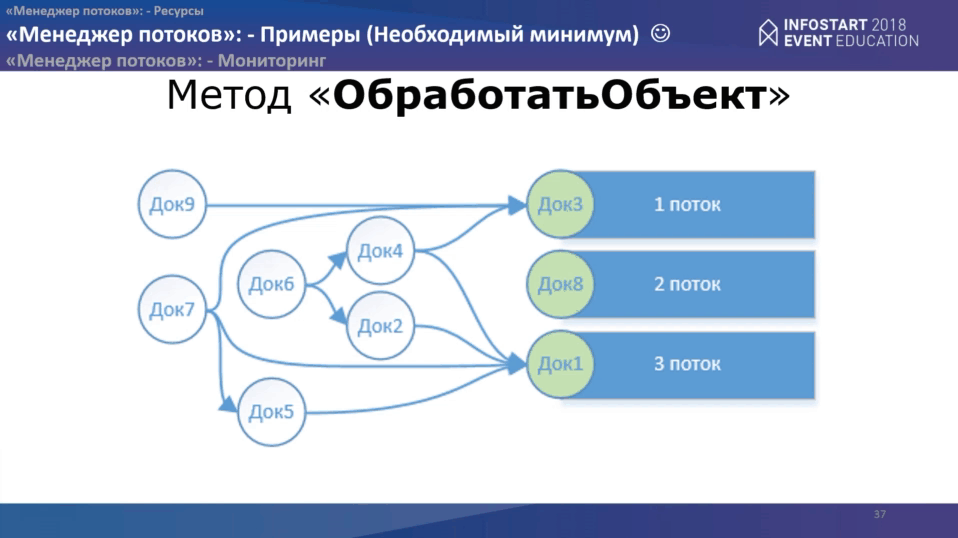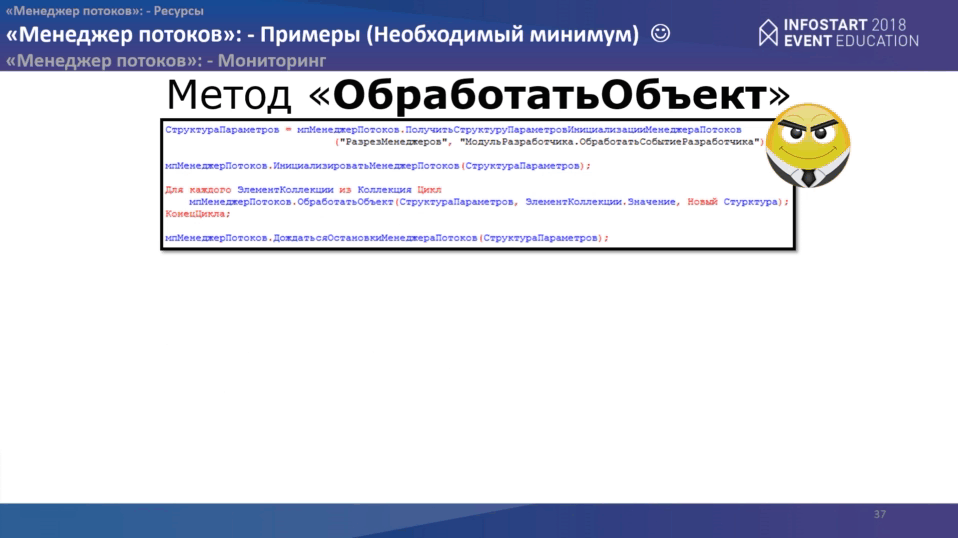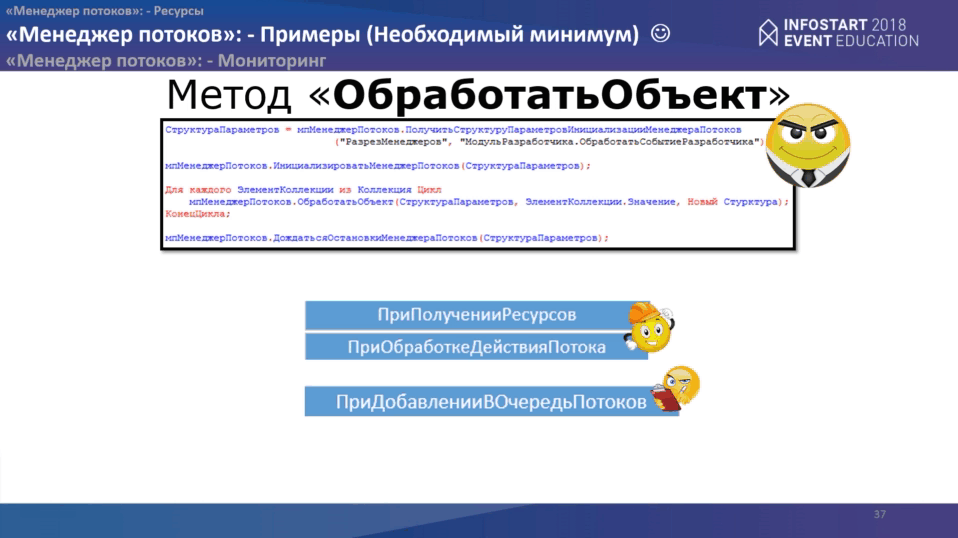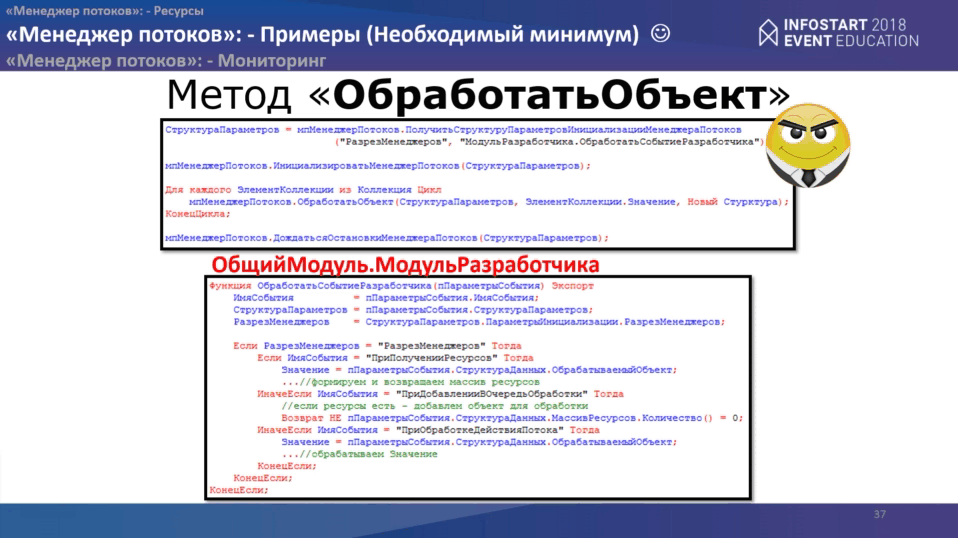
“Ресурс” – это то, что позволяет “Менеджеру потоков” построить граф. Графы – это у нас кружочки, их ещё называют узлами. И есть еще стрелочки, их ещё называют ребрами или дугами. Больше нам ничего не требуется для того, чтобы построить графы. Если смотреть с точки зрения теории графов, то там есть еще очень большое количество понятий и определений, но разработчику они будут не нужны. Все, что нужно разработчику, – это понимать, как строятся сами связи.
Связи строятся очень просто: они строятся на основании ресурсов. У нового объекта, добавляемого в граф, рассчитываются ресурсы и если какие-то из этих ресурсов совпадают с ресурсами других объектов уже находящихся в этом графе, то между ними устанавливается связь. Притом связь в одном направлении: от более позднего к более раннему. Если, предположим, объектов с одним и тем же ресурсов в графе будет найдено несколько, тогда связь устанавливается до самого позднего среди ранних. Те объекты, которые не ссылаются на какой-либо другой объект, то есть ни от какого другого объекта не зависят, посылаются в “потоки”.

Дальше показан механизм, как строить ресурсы. Методов пока не предусмотрено, поэтому, разработчики, пользуйтесь данной схемой.

Ниже приведены простые примеры, как это делается на примере “Восстановления партий”.
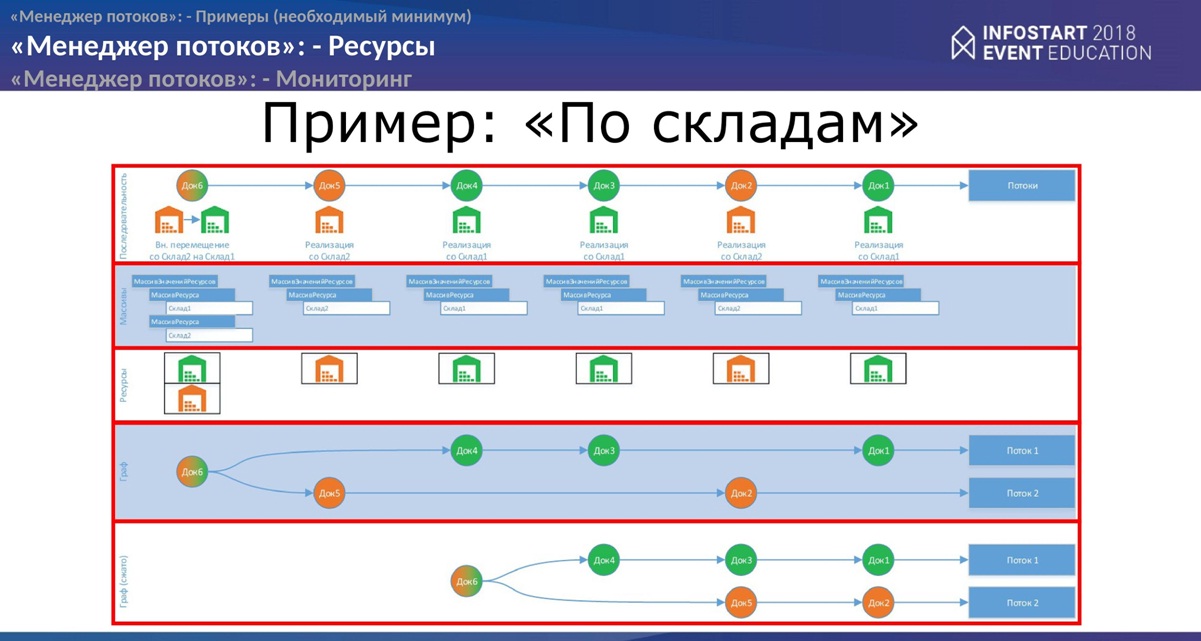
Наверху у нас последовательность документов, реализации и перемещения. Каждый цвет это отдельный склад. Разработчик определяет состав ресурсов (как он выглядит графически, смотрите на слайде). На основании этих ресурсов “Менеджер потоков” строит граф. И объекты по такому графу посылаются в обработку в потоки.
Если немного усложнить, то мы делаем с Вами обработку объектов не только по складам, но и по составу документа, то есть у нас будет склад и материал.
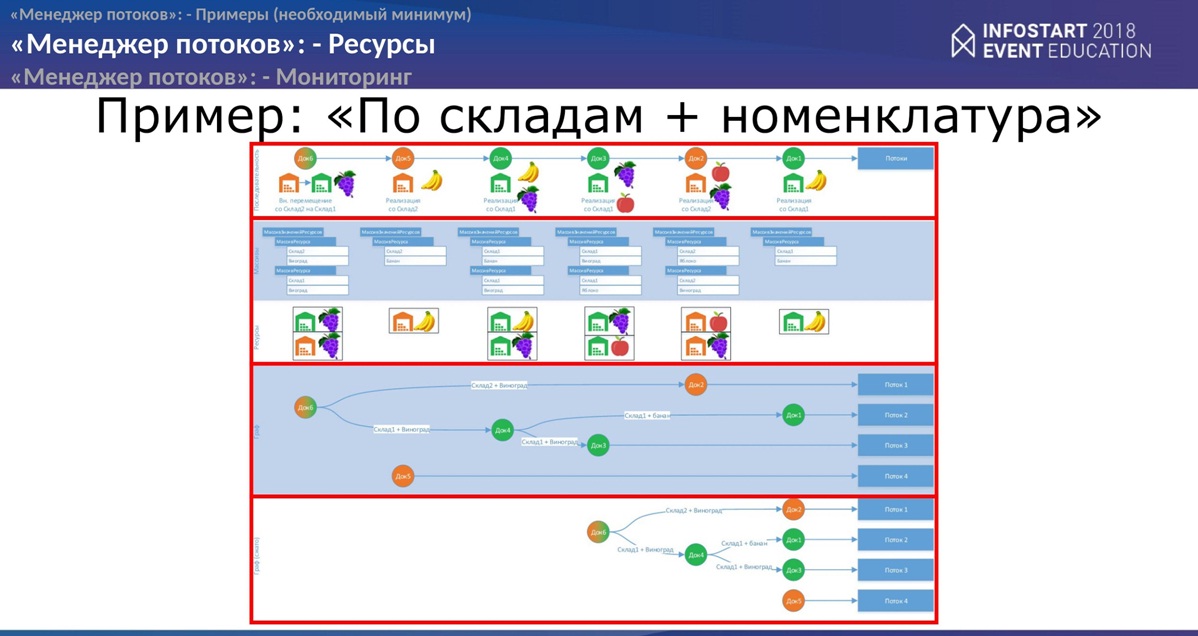
С точки зрения обычной обработки у нас ничего не меняется. Как был поток, так он идет. Если мы с Вами рассчитаем ресурсы, то менеджер потоков на основании таких ресурсов построит другой граф. И объекты он пошлет уже по-другому количеству потоков.
Слайд для сравнения
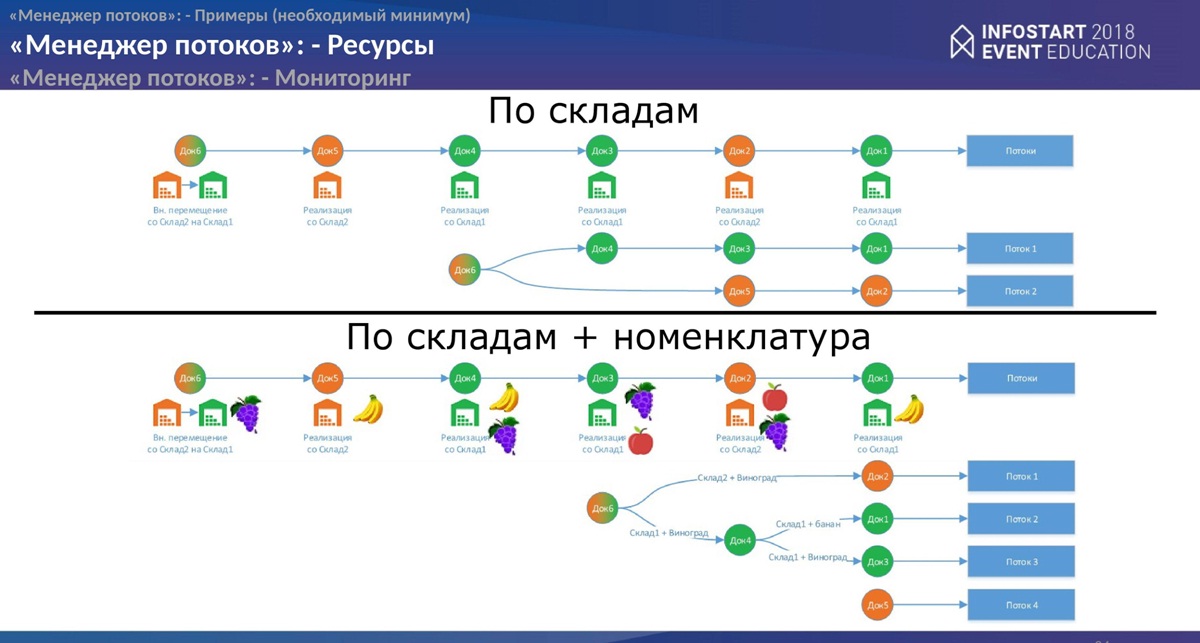
Можно увидеть, что в зависимости того как Вы будете строить ресурсы, будут получены и разные графы. И от этих графов будет получен разный результат работы объектов. То есть в принципе все зависит от Вас, как от разработчиков.
Механизм формирования ресурсов
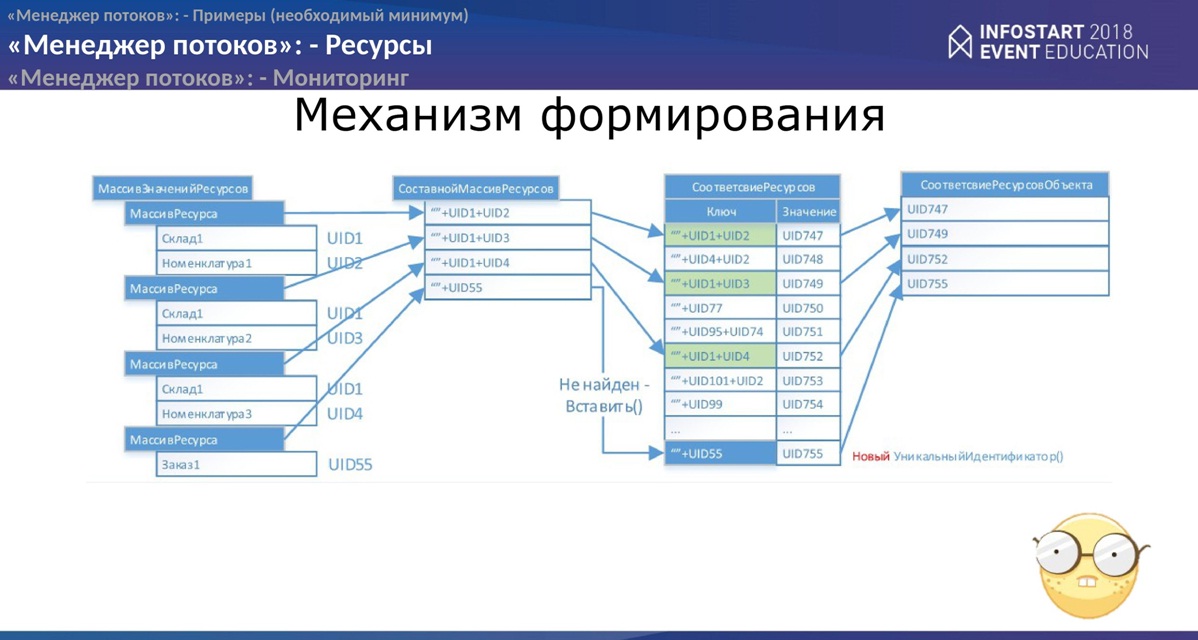
По большому счету здесь рассчитывается хэш ресурсов. Притом состав ресурса может быть совершенно разным, не обязательно у нас состав ресурса должен быть однотипный. Обратите внимание на левой табличке, где формируется массив ресурсов, внизу лежит ещё “заказ”. То есть мы можем формировать разными способами связывание объектов.
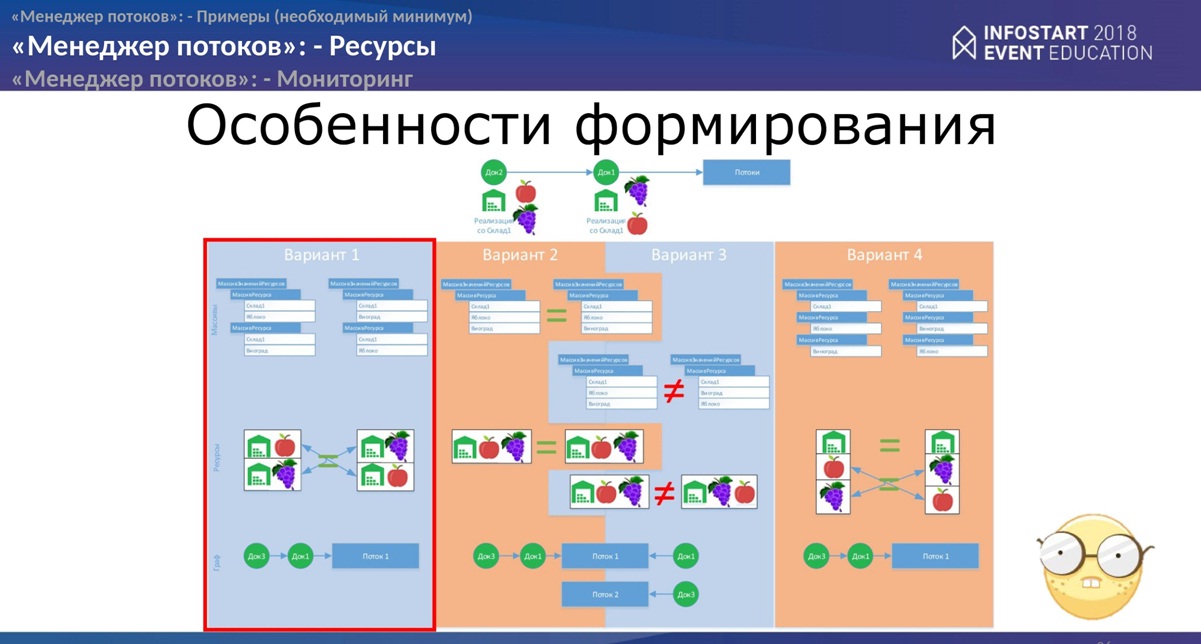
Следующий слайд показывает особенности формирования. В рамках нашего варианта “восстановления партии” правильный будет только один, но в принципе другие тоже могут быть – в зависимости от ваших задач.
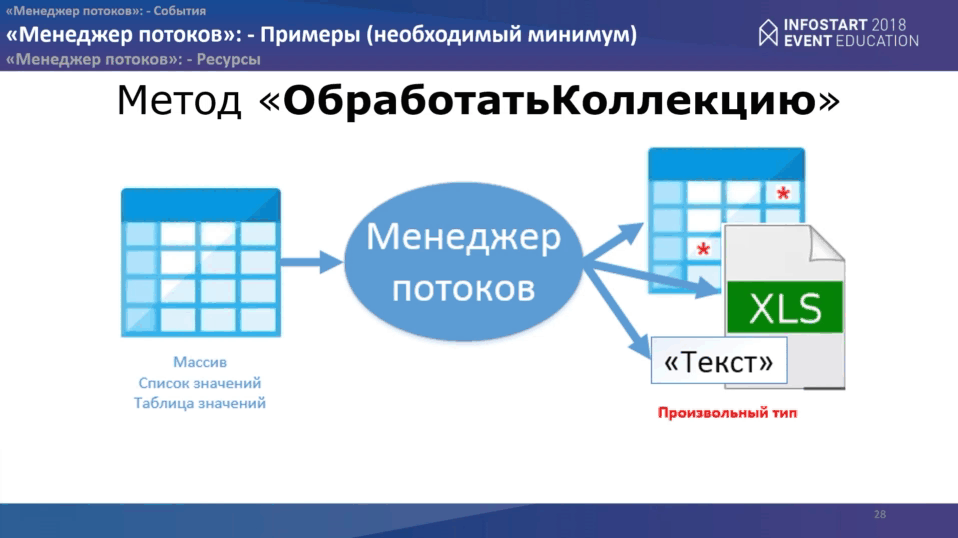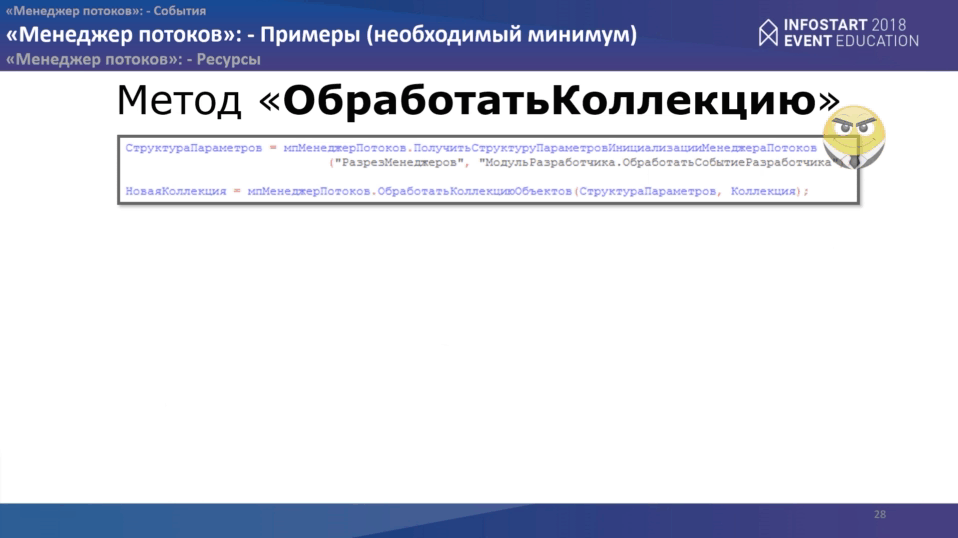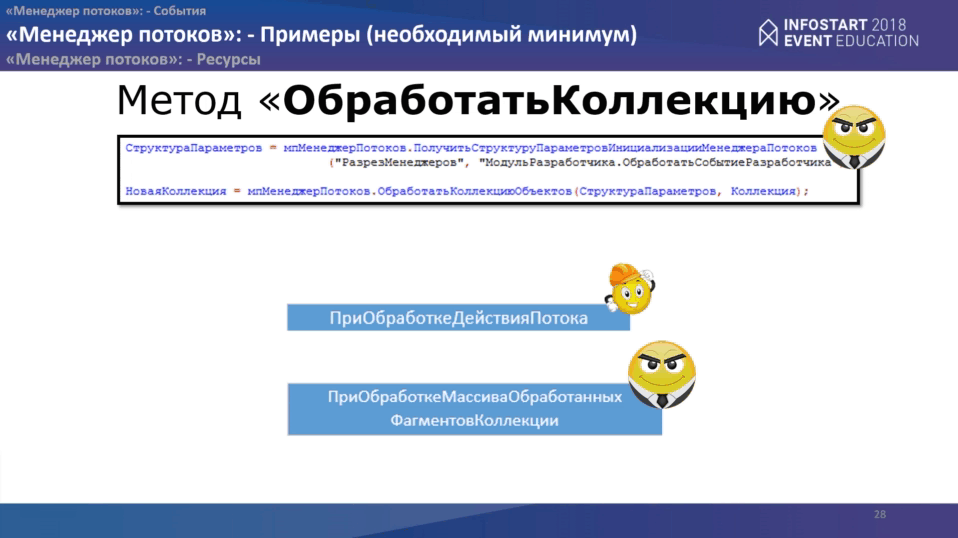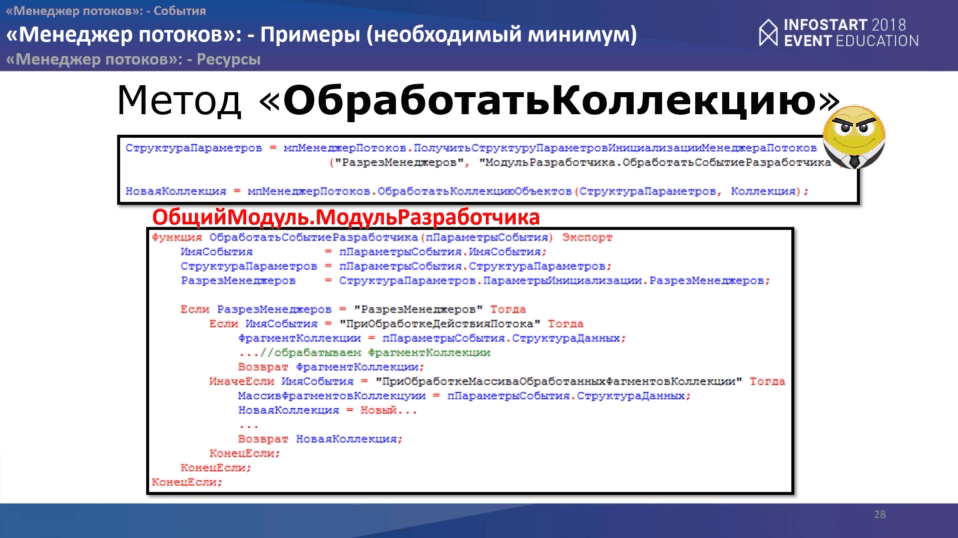
Остался метод «ОбработатьОбъект». Здесь немножко и структура меняется, нужно также получить параметры, проинициализировать “Менеджер потоков”, запустить обработку коллекции, куда мы передаем:
- параметры менеджера;
- элемент для обработки;
- дополнительную произвольную структуру с параметрами необходимыми для обработки конкретного элемента.
На стороне менеджера потоков нам надо обработать три события: “ПриПолученииРесурса”, “ПриОбработкеДействияПотока” и “ПриДобавленииВОчередьПотока”. Весь код на слайде.
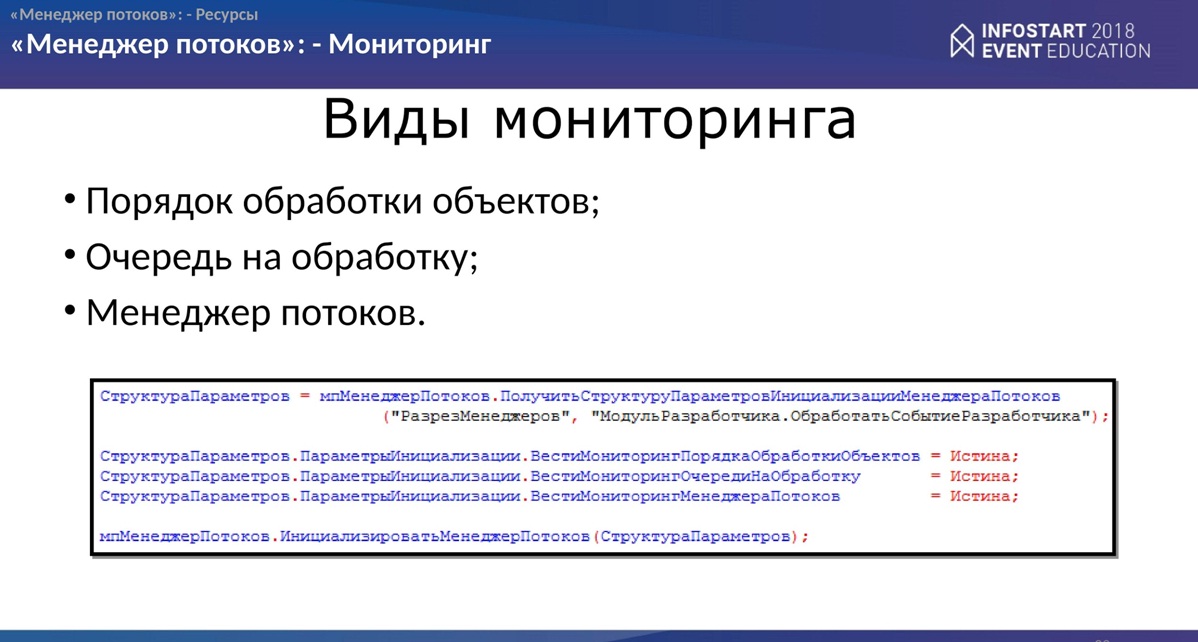
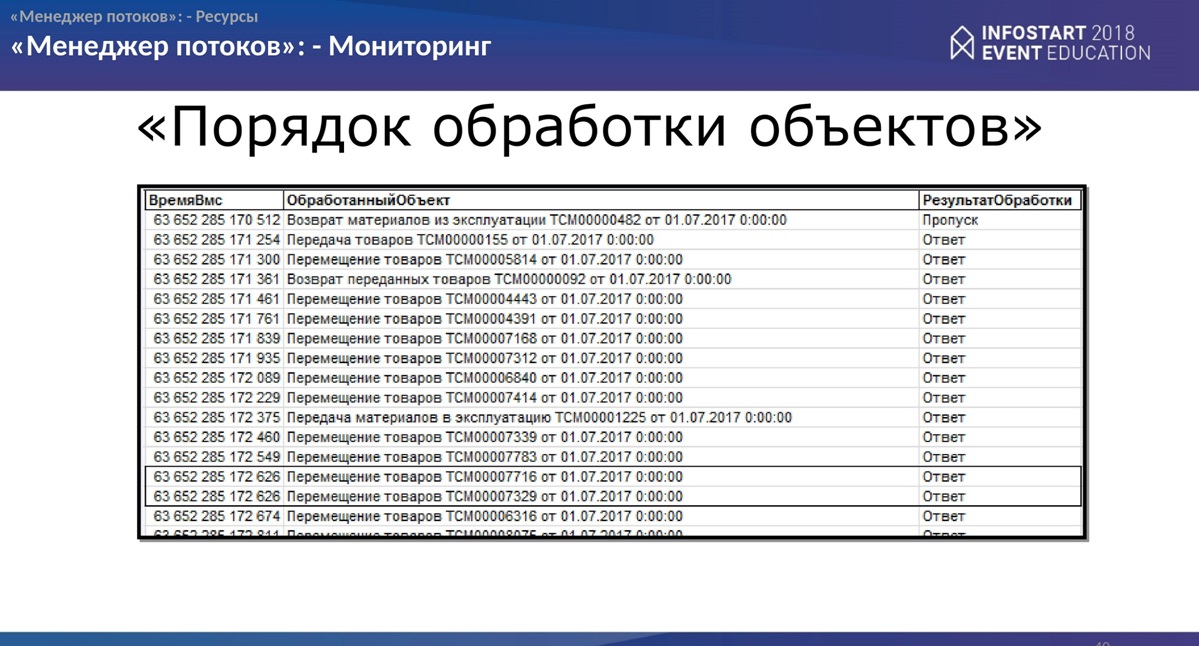
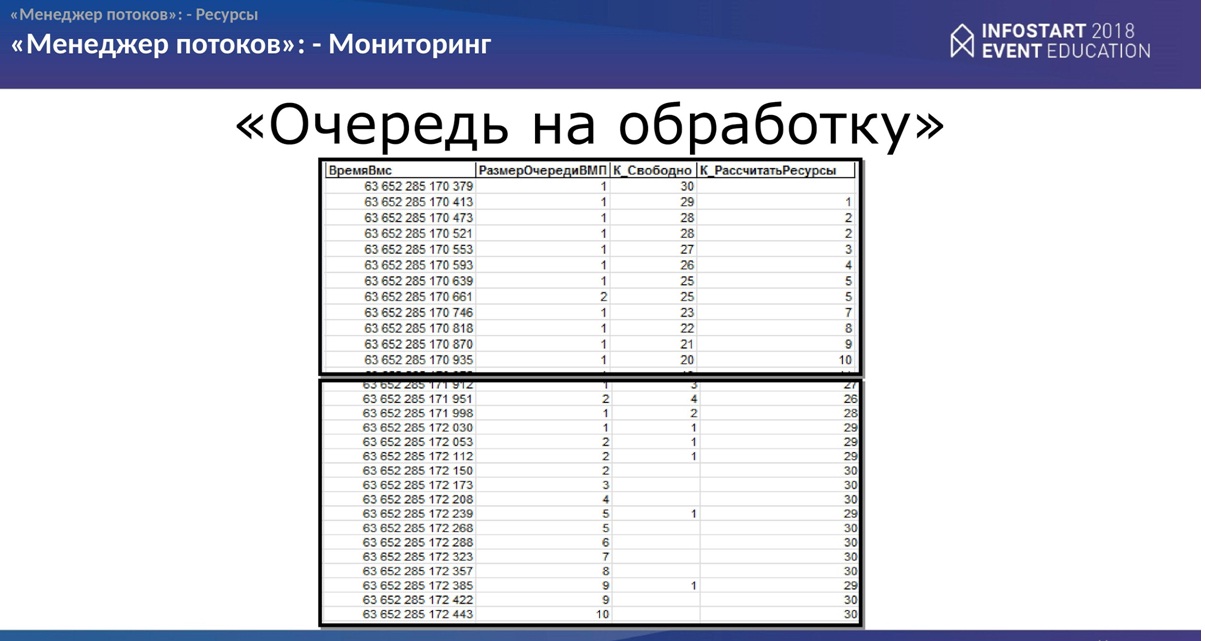
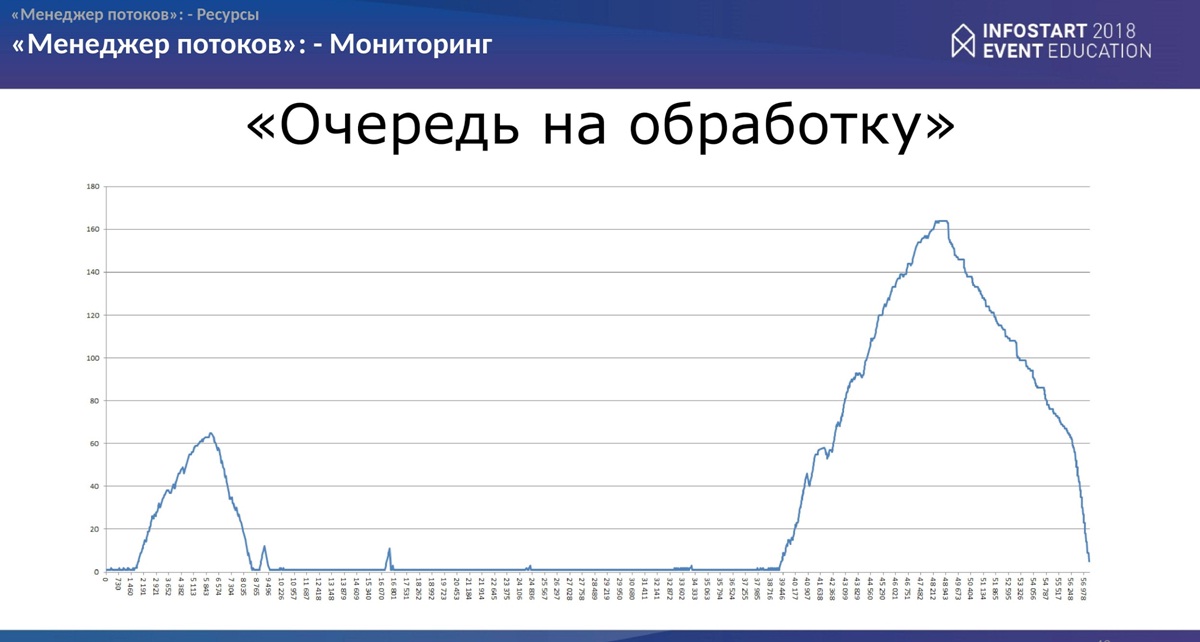
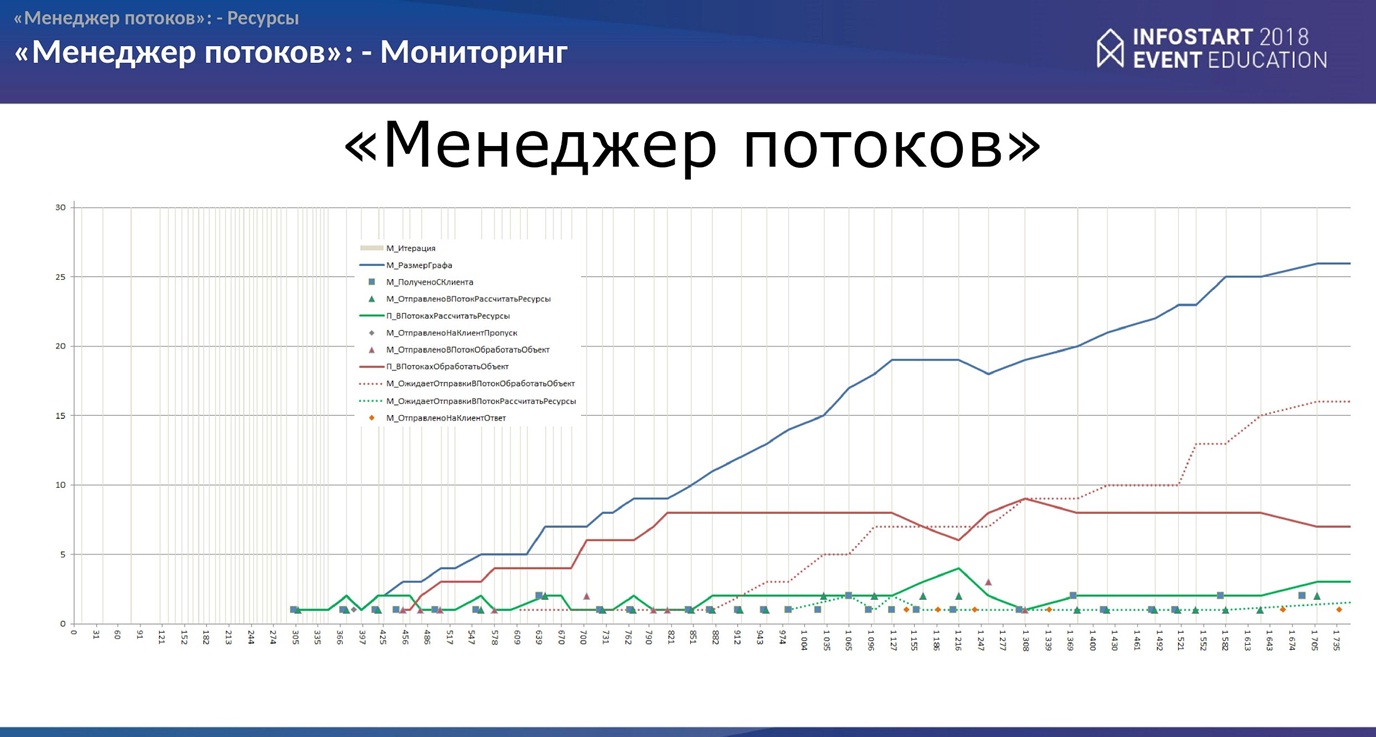
Мониторинг
Здесь все просто. Тут буквально несколько слайдов, что еще можно сделать.
Спасибо за внимание.
Менеджер потоков: //infostart.ru/public/778905/
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2018 EDUCATION.


Вступайте в нашу телеграмм-группу Инфостарт