Вот почему это руководство по SQL предоставит вам небольшой обзор некоторых шагов, которые вы можете пройти, чтобы оценить ваш запрос:
- Во-первых, вы начнете с краткого обзора важности обучения SQL для работы в области науки о данных;
- Далее вы сначала узнаете о том, как выполняется обработка и выполнение запросов SQL, чтобы понять важность создания качественных запросов. Конкретнее, вы увидите, что запрос анализируется, переписывается, оптимизируется и окончательно оценивается.
- С учетом этого, вы не только перейдете к некоторым антипаттернам запросов, которые начинающие делают при написании запросов, но и узнаете больше об альтернативах и решениях этих возможных ошибок; Кроме того, вы узнаете больше о методическом подходе к запросам на основе набора.
- Вы также увидите, что эти антипаттерны вытекают из проблем производительности и что, помимо «ручного» подхода к улучшению SQL-запросов, вы можете анализировать свои запросы также более структурированным, углубленным способом, используя некоторые другие инструменты, которые помогают увидеть план запроса; И,
- Вы вкратце узнаете о time complexity и big O notation, для получения представления о сложности плана выполнения во времени перед выполнением запроса;
- Вы кратко узнаете о том, как оптимизировать запрос.
Почему следует изучать SQL для работы с данными?
SQL далеко не мертв: это один из самых востребованных навыков, который вы находите в описаниях должностей из индустрии обработки и анализа данных, независимо от того, претендуете ли вы на аналитику данных, инженера данных, специалиста по данным или на любые другие роли. Это подтверждают 70% респондентов опроса О 'Рейли (O' Reilly Data Science Salary Survey) за 2016 год, которые указывают, что используют SQL в своем профессиональном контексте. Более того, в этом опросе SQL выделяется выше языков программирования R (57%) и Python (54%).
Вы получаете картину: SQL — это необходимый навык, когда вы работаете над получением работы в индустрии информатики.
Неплохо для языка, который был разработан в начале 1970-х, верно?
Но почему именно так часто используется? И почему он не умер, несмотря на то, что он существует так долго?
Есть несколько причин: одной из первых причин могло бы стать то, что компании в основном хранят данные в реляционных системах управления базами данных (RDBMS) или в реляционных системах управления потоками данных (RDSMS), и для доступа к этим данным нужен SQL. SQL — это lingua franca данных: он дает возможность взаимодействовать практически с любой базой данных или даже строить свою собственную локально!
Если этого еще недостаточно, имейте в виду, что существует довольно много реализаций SQL, которые несовместимы между вендорами и не обязательно соответствуют стандартам. Знание стандартного SQL, таким образом, является для вас требованием найти свой путь в индустрии (информатики).
Кроме того, можно с уверенностью сказать, что к SQL также присоединились более новые технологии, такие как Hive, интерфейс языка запросов, похожий на SQL, для запросов и управления большими наборами данных, или Spark SQL, который можно использовать для выполнения запросов SQL. Опять же, SQL, который вы там найдете, будет отличаться от стандарта, который вы могли бы узнать, но кривая обучения будет значительно проще.
Если вы хотите провести сравнение, рассматривайте его как обучение линейной алгебре: приложив все эти усилия в этот один предмет, вы знаете, что вы сможете использовать его, чтобы также освоить машинное обучение!
Короче говоря, вот почему вы должны изучить этот язык запросов:
- Его довольно легко освоить, даже для новичков. Кривая обучения довольно проста и постепенна, поэтому вы будете писать запросы в кратчайшие сроки.
- Он следует принципу «учись один раз, используй везде», так что это отличное вложение твоего времени!
- Это отличное дополнение к языкам программирования; В некоторых случаях написание запроса даже предпочтительнее написания кода, потому что он более производительный!
- ...
Чего вы все еще ждете? :)
Обработка SQL и выполнение запросов
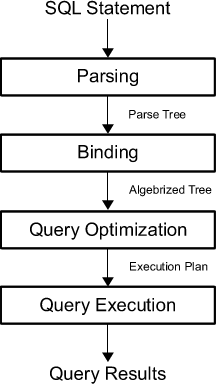
Чтобы повысить производительность вашего SQL-запроса, вы сначала должны знать, что происходит внутри, когда вы нажимаете ярлык для выполнения запроса.
Сначала запрос разбирается в «дерево разбора» (parse tree); Запрос анализируется на предмет соответствия синтаксическим и семантическим требованиям. Синтаксический анализатор создает внутреннее представление входного запроса. Затем эти выходные данные передаются в механизм перезаписи.
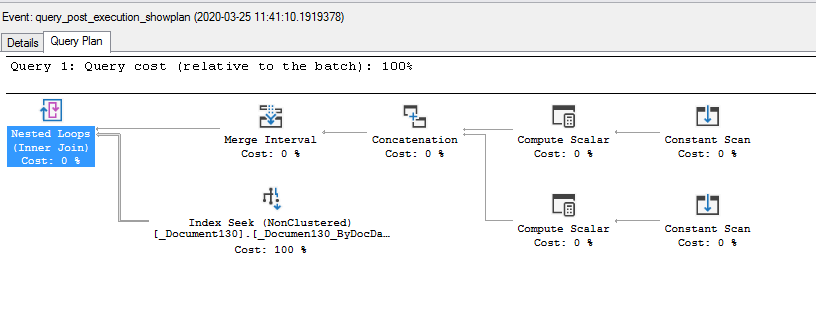
Затем оптимизатор должен найти оптимальное выполнение или план запроса для данного запроса. План выполнения точно определяет, какой алгоритм используется для каждой операции, и как координируется выполнение операций.
Чтобы найти наиболее оптимальный план выполнения, оптимизатор перечисляет все возможные планы выполнения, определяет качество или стоимость каждого плана, принимает информацию о текущем состоянии базы данных, а затем выбирает наилучший из них в качестве окончательного плана выполнения. Поскольку оптимизаторы запросов могут быть несовершенными, пользователям и администраторам баз данных иногда приходится вручную изучать и настраивать планы, созданные оптимизатором, чтобы повысить производительность.
Теперь вы, вероятно, задаетесь вопросом, что считается «хорошим планом запроса».
Как вы уже читали, качество стоимости плана играет немаловажную роль. Более конкретно, такие вещи, как количество дисковых операций ввода-вывода (disk I/Os), которые требуются для оценки плана, стоимость CPU плана и общее время отклика, которое может наблюдать клиент базы данных, и общее время выполнения, имеют важное значение. Вот тут-то и возникнет понятие сложности времени (time complexity). Подробнее об этом вы узнаете позже.
Затем выбранный план запроса выполняется, оценивается механизмом выполнения системы и возвращаются результаты запроса.
Написание SQL-запросов
Из предыдущего раздела, возможно, не стало ясно, что принцип Garbage In, Garbage Out (GIGO) естественным образом проявляется в процессе обработки и выполнения запроса: тот, кто формулирует запрос, также имеет ключи к производительности ваших запросов SQL. Если оптимизатор получит плохо сформулированный запрос, он сможет сделать только столько же…
Это означает, что есть некоторые вещи, которые вы можете сделать, когда пишете запрос. Как вы уже видели во введении, ответственность тут двоякая: речь идет не только о написании запросов, которые соответствуют определенному стандарту, но и о сборе идей о том, где проблемы производительности могут скрыться в вашем запросе.
Идеальная отправная точка — подумать о «местах» в ваших запросах, где могут возникнуть проблемы. И, в общем, есть четыре ключевых слова, в которых новички могут ожидать возникновения проблем с производительностью:
- Условие
WHERE; - Любые ключевые слова
INNER JOINилиLEFT JOIN; А также, - Условие
HAVING;
Конечно, этот подход прост и наивен, но, для новичка, эти пункты являются отличными указателями, и можно с уверенностью сказать, что когда вы только начинаете, именно в этих местах происходят ошибки и, как ни странно, где их также трудно заметить.
Тем не менее, вы также должны понимать, что производительность — это нечто, что должно стать значимым. Однако просто сказать, что эти предложения и ключевые слова плохи — это не то, что нужно, когда вы думаете о производительности SQL. Наличие предложения WHERE или HAVING в запросе не обязательно означает, что это плохой запрос…
Ознакомьтесь со следующим разделом, чтобы узнать больше об антипаттернах и альтернативных подходах к построению вашего запроса. Эти советы и рекомендации предназначены в качестве руководства. То, как и если вам действительно нужно переписать ваш запрос, зависит, помимо прочего, от количества данных, базы данных и количества раз, которое вам нужно для выполнения запроса. Это полностью зависит от цели вашего запроса и иметь некоторые предварительные знания о базе данных, с которой вы будете работать, имеет решающее значение!
1. Извлекате только необходимые данные
Умозаключение «чем больше данных, тем лучше» — не обязательно должна соблюдаться при написании SQL: вы рискуете не только запутаться, получив больше данных, чем вам действительно нужно, но и производительность может пострадать от того, что ваш запрос получает слишком много данных.
Вот почему, как правило, стоит обратить внимание на оператор SELECT, предложение DISTINCT и оператор LIKE.
Оператор SELECT
Первое, что уже можно проверить, когда вы написали запрос, является ли инструкция SELECT максимально компактной. Целью здесь должно быть удаление ненужных столбцов из SELECT. Таким образом вы заставляете себя только извлекать данные, которые служат вашей цели запроса.
Если у вас есть коррелированные подзапросы с EXISTS, вы должны попытаться использовать константу в операторе SELECT этого подзапроса вместо выбора значения фактического столбца. Это особенно удобно, когда вы проверяете только существование.
Помните, что коррелированный подзапрос является подзапросом, использующим значения из внешнего запроса. И обратите внимание, что, несмотря на то, что NULL может работать в этом контексте как «константа», это очень запутанно!
Рассмотрим следующий пример, чтобы понять, что подразумевается под использованием константы:
SELECT driverslicensenr, name
FROM Drivers
WHERE EXISTS
(SELECT '1'
FROM Fines
WHERE fines.driverslicensenr = drivers.driverslicensenr);
Совет: полезно знать, что наличие коррелированного подзапроса не всегда является хорошей идеей. Вы всегда можете рассмотреть возможность избавиться от них, например, переписав их с помощью INNER JOIN:
SELECT driverslicensenr, name
FROM drivers
INNER JOIN fines ON fines.driverslicensenr = drivers.driverslicensenr;
Операция DISTINCT
Инструкция SELECT DISTINCT используется для возврата только различных значений. DISTINCT — это пункт, которого, безусловно, следует стараться избегать, если можно. Как и в других примерах, время выполнения увеличивается только при добавлении этого предложения в запрос. Поэтому всегда полезно рассмотреть, действительно ли вам нужна эта операция DISTINCT, чтобы получить результаты, которые вы хотите достичь.
Оператор LIKE
При использовании оператора LIKE в запросе индекс не используется, если шаблон начинается с % или _. Это не позволит базе данных использовать индекс (если он существует). Конечно, с другой точки зрения, можно также утверждать, что этот тип запроса потенциально оставляет возможность для получения слишком большого количества записей, которые не обязательно удовлетворяют цели запроса.
Опять же, знание данных, хранящихся в базе данных, может помочь вам сформулировать шаблон, который будет правильно фильтровать все данные, чтобы найти только строки, которые действительно важны для вашего запроса.
2. Ограничьте свои результаты
Если вы не можете избежать фильтрации вашего оператора SELECT, вы можете ограничить свои результаты другими способами. Вот здесь и подходят такие подходы, как предложение LIMIT и преобразования типов данных.
Операторы TOP, LIMIT и ROWNUM
Можно добавить операторы LIMIT или TOP в запросы, чтобы задать максимальное число строк для результирующего набора. Вот несколько примеров:
SELECT TOP 3 *
FROM Drivers;
Обратите внимание, что вы можете дополнительно указать PERCENT, например, если вы измените первую строку запроса с помощью SELECT TOP 50 PERCENT *.
SELECT driverslicensenr, name
FROM Drivers
LIMIT 2;
Кроме того, можно добавить предложение ROWNUM, эквивалентное использованию LIMIT в запросе:
SELECT *
FROM Drivers
WHERE driverslicensenr = 123456 AND ROWNUM <= 3;
Преобразования типов данных
Всегда следует использовать наиболее эффективные, т.е. наименьшие, типы данных. Всегда есть риск, когда вы предоставляете огромный тип данных, когда меньший будет более достаточным.
Однако при добавлении преобразования типа данных в запрос увеличивается только время выполнения.
Альтернатива заключается в том, чтобы максимально избежать преобразования типов данных. Обратите внимание также на то, что не всегда возможно удалить или пропустить преобразование типа данных из запросов, но при этом следует обязательно стремиться к их включению и что при этом необходимо проверить эффект добавления перед выполнением запроса.
3. Не делайте запросы более сложными, чем они должны быть
Преобразования типов данных приводят вас к следующему пункту: вам не следует чрезмерно проектировать ваши запросы. Постарайтесь сделать их простыми и эффективными. Это может показаться слишком простым или глупым даже для того, чтобы быть подсказкой, главным образом потому, что запросы могут быть сложными.
Однако в примерах, упомянутых в следующих разделах, вы увидите, что вы можете легко начать делать простые запросы более сложными, чем они должны быть.
Оператор OR
Когда вы используете оператор OR в своем запросе, скорее всего, вы не используете индекс.
Помните, что индекс — это структура данных, которая повышает скорость поиска данных в таблице базы данных, но это обходится дорого: потребуются дополнительные записи и потребуется дополнительное место для хранения, чтобы поддерживать структуру данных индекса. Индексы используются для быстрого поиска или поиска данных без необходимости искать каждую строку в базе данных при каждом обращении к таблице базы данных. Индексы могут быть созданы с использованием одного или нескольких столбцов в таблице базы данных.
Если вы не используете индексы, включенные в базу данных, выполнение вашего запроса неизбежно займет больше времени. Вот почему лучше всего искать альтернативы использованию оператора OR в вашем запросе;
Рассмотрим следующий запрос:
SELECT driverslicensenr, name
FROM Drivers
WHERE driverslicensenr = 123456
OR driverslicensenr = 678910
OR driverslicensenr = 345678;
Оператор можно заменить на:
Условие с IN; или
SELECT driverslicensenr, name
FROM Drivers
WHERE driverslicensenr IN (123456, 678910, 345678);
Две инструкции SELECT с UNION.
Совет: здесь вы должны быть осторожны, чтобы не использовать ненужную операцию UNION, потому что вы просматриваете одну и ту же таблицу несколько раз. В то же время вы должны понимать, что когда вы используете UNIONв своем запросе, время выполнения увеличивается. Альтернативы операции UNION: переформулировка запроса таким образом, чтобы все условия были помещены в одну инструкцию SELECT, или использование OUTER JOIN вместо UNION.
Совет: имейте также в виду, что, хотя OR — и другие операторы, которые будут упомянуты в следующих разделах — скорее всего, не используют индекс, поиск по индексу не всегда предпочтителен!
Оператор NOT
Когда ваш запрос содержит оператор NOT, вполне вероятно, что индекс не используется, как и с оператором OR. Это неизбежно замедлит ваш запрос. Если вы не знаете, что здесь подразумевается, рассмотрите следующий запрос:
SELECT driverslicensenr, name
FROM Drivers
WHERE NOT (year > 1980);
Этот запрос, безусловно, будет выполняться медленнее, чем вы, возможно, ожидаете, в основном потому, что он сформулирован гораздо сложнее, чем может быть: в таких случаях, как этот, лучше всего искать альтернативу. Рассмотрите возможность замены NOT операторами сравнения, такими как >, <> или !>; Приведенный выше пример действительно может быть переписан и выглядеть примерно так:
SELECT driverslicensenr, name
FROM Drivers
WHERE year <= 1980;
Это уже выглядит лучше, не так ли?
Оператор AND
Оператор AND — это другой оператор, который не использует индекс и который может замедлить запрос, если он используется чрезмерно сложным и неэффективным образом, как в следующем примере:
SELECT driverslicensenr, name
FROM Drivers
WHERE year >= 1960 AND year <= 1980;
Лучше переписать этот запрос, используя оператор BETWEEN:
SELECT driverslicensenr, name
FROM Drivers
WHERE year BETWEEN 1960 AND 1980;
Операторы ANY и ALL
Кроме того, операторы ANY и ALL — это те операторы, с которыми вам следует быть осторожным, поскольку, если включить их в свои запросы, индекс не будет использоваться. Здесь пригодятся альтернативные функции агрегирования, такие как MIN или MAX.
Совет: в тех случаях, когда вы используете предлагаемые альтернативы, вы должны знать о том, что все функции агрегации, такие как SUM, AVG, MIN, MAX над многими строками, могут привести к длительному запросу. В таких случаях можно попытаться минимизировать количество строк для обработки или предварительно вычислить эти значения. Вы еще раз видите, что важно знать о своей среде, своей цели запроса,… Когда вы принимаете решение о том, какой запрос использовать!
Изолируйте столбцы в условиях
Также в случаях, когда столбец используется в вычислении или в скалярной функции, индекс не используется. Возможным решением было бы просто выделить конкретный столбец, чтобы он больше не был частью вычисления или функции. Рассмотрим следующий пример:
SELECT driverslicensenr, name
FROM Drivers
WHERE year + 10 = 1980;
Это выглядит забавно, а? Вместо этого попробуйте пересмотреть расчет и переписать запрос примерно так:
SELECT driverslicensenr, name
FROM Drivers
WHERE year = 1970;
4. Отсутствие грубой силы
Этот последний совет означает, что не следует пытаться ограничить запрос слишком сильно, так как это может повлиять на его производительность. Это особенно справедливо для соединений и для предложения HAVING.
Порядок таблиц в соединениях
При соединении двух таблиц может быть важно учитывать порядок таблиц в соединении. Если видно, что одна таблица значительно больше другой, может потребоваться переписать запрос так, чтобы самая большая таблица помещалась последней в соединении.
Избыточные условия при соединениях
При добавлении слишком большого количества условий к соединениям SQL обязан выбрать определенный путь. Однако может быть, что этот путь не всегда является более эффективным.
Условие HAVING
Условие HAVING было первоначально добавлено в SQL, так как ключевое слово WHERE не могло использоваться с агрегатными функциями. HAVING обычно используется с операцией GROUP BY, чтобы ограничить группы возвращаемых строк только теми, которые удовлетворяют определенным условиям. Однако, если это условие используется в запросе, индекс не используется, что, как вы уже знаете, может привести к тому, что запрос на самом деле не так хорошо работает.
Если вы ищете альтернативу, попробуйте использовать условие WHERE.
Рассмотрим следующие запросы:
SELECT state, COUNT(*)
FROM Drivers
WHERE state IN ('GA', 'TX')
GROUP BY state
ORDER BY state
SELECT state, COUNT(*)
FROM Drivers
GROUP BY state
HAVING state IN ('GA', 'TX')
ORDER BY state
Первый запрос использует предложение WHERE, чтобы ограничить количество строк, которые необходимо суммировать, тогда как второй запрос суммирует все строки в таблице, а затем использует HAVING, чтобы отбросить вычисленные суммы. В таких случаях вариант с предложением WHERE явно лучше, так как вы не тратите ресурсы.
Видно, что речь идет не об ограничении результирующего набора, а об ограничении промежуточного числа записей в запросе.
Следует отметить, что различие между этими двумя условиями заключается в том, что предложение WHERE вводит условие для отдельных строк, в то время как предложение HAVING вводит условие для агрегаций или результатов выбора, где один результат, такой как MIN, MAX, SUM,… был создан из нескольких строк.
Вы видите, оценка качества, написание и переписывание запросов не является простой задачей, если учесть, что они должны быть максимально производительными; Предотвращение антипаттернов и рассмотрение альтернативных вариантов также будут частью ответственности при написании запросов, которые необходимо выполнять на базах данных в профессиональной среде.
Этот список был лишь небольшим обзором некоторых антипаттернов и советов, которые, надеюсь, помогут начинающим; Если вы хотите получить представление о том, что более старшие разработчики считают наиболее частыми антиобразцами, ознакомьтесь с этим обсуждением.
Set-based против процедурных подходов к написанию запросов
В вышеприведенных антипаттернах подразумевалось то, что они фактически сводятся к разнице в основанных на наборах и процедурных подходах к построению ваших запросов.
Процедурный подход к запросам — это подход, очень похожий на программирование: вы говорите системе, что делать и как это делать.
Примером этого являются избыточные условия в соединениях или случаи, когда вы злоупотребляете условями HAVING, как в приведенных выше примерах, в которых вы запрашиваете базу данных, выполняя функцию и затем вызывая другую функцию, или вы используете логику, содержащую условия, циклы, пользовательские функции (UDF), курсоры,… чтобы получить конечный результат. При таком подходе вы часто будете запрашивать подмножество данных, затем запрашивать другое подмножество данных и так далее.
Неудивительно, что этот подход часто называют «пошаговым» или «построчным» запросом.
Другой подход — подход, основанный на наборе, где вы просто указываете, что делать. Ваша роль состоит в указании условий или требований для результирующего набора, который вы хотите получить из запроса. То, как ваши данные извлекаются, вы оставляете внутренним механизмам, которые определяют реализацию запроса: вы позволяете ядру базы данных определять лучшие алгоритмы или логику обработки для выполнения вашего запроса.
Поскольку SQL основан на наборах, неудивительно, что этот подход будет более эффективным, чем процедурный, и он также объясняет, почему в некоторых случаях SQL может работать быстрее, чем код.
Совет основанный на наборах подход к запросам — также тот, который большинство ведущих работодателей в отрасли информационных технологий попросит вас освоить! Часто необходимо переключаться между этими двумя типами подходов.
Обратите внимание, что если вам когда либо понадобится процедурный запрос, вы должны рассмотреть возможность его переписывания или рефакторинга.
В следующей части будут расмотрены план и оптимизация запросов (Часть 2)
Вступайте в нашу телеграмм-группу Инфостарт