



В данной статье я продолжу (ну и закончу) тему использования машинного обучения для автоматического (без участия сотрудника техподдержки) решения инцидентов.
Первая часть тут:
Весь код для получения модели, которая будет предлагать наиболее подходящий классификатор:
%%time
def predict(vectorizer, classifier, data):
data_features = vectorizer.transform(data['Description'])
predictions = classifier.predict(data_features)
target = data['ShortDescription']
evaluate_prediction(predictions, target)
def plot_confusion_matrix(cm, title='Confusion matrix', cmap=plt.cm.Blues):
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(my_tags))
target_names = my_tags
plt.xticks(tick_marks, target_names, rotation=90)
plt.yticks(tick_marks, target_names)
plt.ylabel('True label')
plt.xlabel('Predicted label')
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
fig.savefig('test2png.png', dpi=100)
def evaluate_prediction(predictions, target, title="Confusion matrix"):
print('accuracy %s' % accuracy_score(target, predictions))
print('recall %s' % recall_score(target,predictions, average='micro'))
cm = confusion_matrix(target, predictions)
cm_normalized = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
plot_confusion_matrix(cm_normalized, title + ' Normalized')
from sklearn import linear_model
from sklearn.externals import joblib
#Разбиваем наш df на две части, тренировочную и тестовую.
train_data, test_data = train_test_split(df_result_filter, test_size=0.1, random_state=42)
len(test_data)
len(train_data)
#Разделяем все инциденты на слова
test_tokenized = test_data.apply(lambda r: w2v_tokenize_text(r['Description']), axis=1).values
train_tokenized = train_data.apply(lambda r: w2v_tokenize_text(r['Description']), axis=1).values
#Преобразуем все наши слова в векторы
X_train_word_average = word_averaging_list(wv,train_tokenized)
X_test_word_average = word_averaging_list(wv,test_tokenized)
#Для обучения мы будем использовать логистическую регрессию. Вы можете попробовать использовать другие типы регрессий и сравнить результат.
logreg = linear_model.LogisticRegression(n_jobs=1, C=1e5)
#Обучим нашу модель на тестовых данных. Данная процедура самая длительная, в зависимости от размера модели может занимать несколько часов. В моем случае ушло более 6 часов.
logreg_w2v = logreg.fit(X_train_word_average, train_data['ShortDescription'])
#Сохраним полученный результат, он нам потребуется в дальнейшем
joblib.dump(logreg_w2v, 'Data/logreg_w2v.sav')
#Выполним предсказание для нашей тестовой выборки
predicted_w2v = logreg_w2v.predict(X_test_word_average)
#Посмотрим на результат
evaluate_prediction(predicted_w2v, test_data.ShortDescription)
Доля правильных ответов
accuracy 0.7425814736403706
Полнота
recall 0.7425814736403706
Можно считать полученные результаты весьма неплохими.
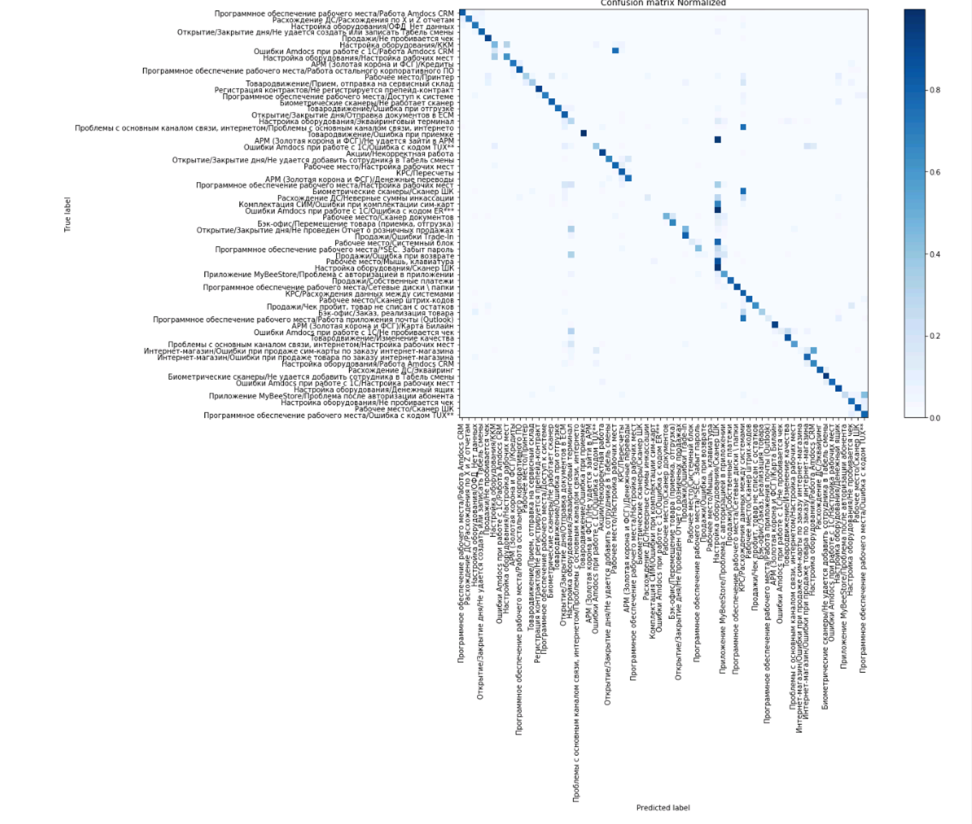
А вот как выглядит так называемая матрица ошибок. Видим, что есть проблемы с классификатором «Проблемы с MyBeeStore/Проблемы с авторизацией», в остальном предсказания в основном укладываются в диагональ, то есть предсказанное и действительное значения классификаторов совпали.
Ну что ж, с обучением мы закончили, теперь давайте превратим наши исследования в полноценный продукт.
Для того, чтобы использовать описанный ранее функционал нам нужен веб-сервис с двумя процедурами, первая по тексту инцидента будет возвращать список похожих инцидентов, а вторая – наиболее подходящий с точки зрения модели классификатор.
Я не буду копировать сюда весь код, вот ссылка на github, если кто-то соберется запустить подобный функционал все равно код придется немного переделать.
При заведении инцидента пользователь выбирает наиболее подходящий по его мнению классификатор и вводит текст инцидента. Затем при записи нового инцидента происходит вызов двух функций, поиск похожих инцидентов и поиск подходящего классификатора.
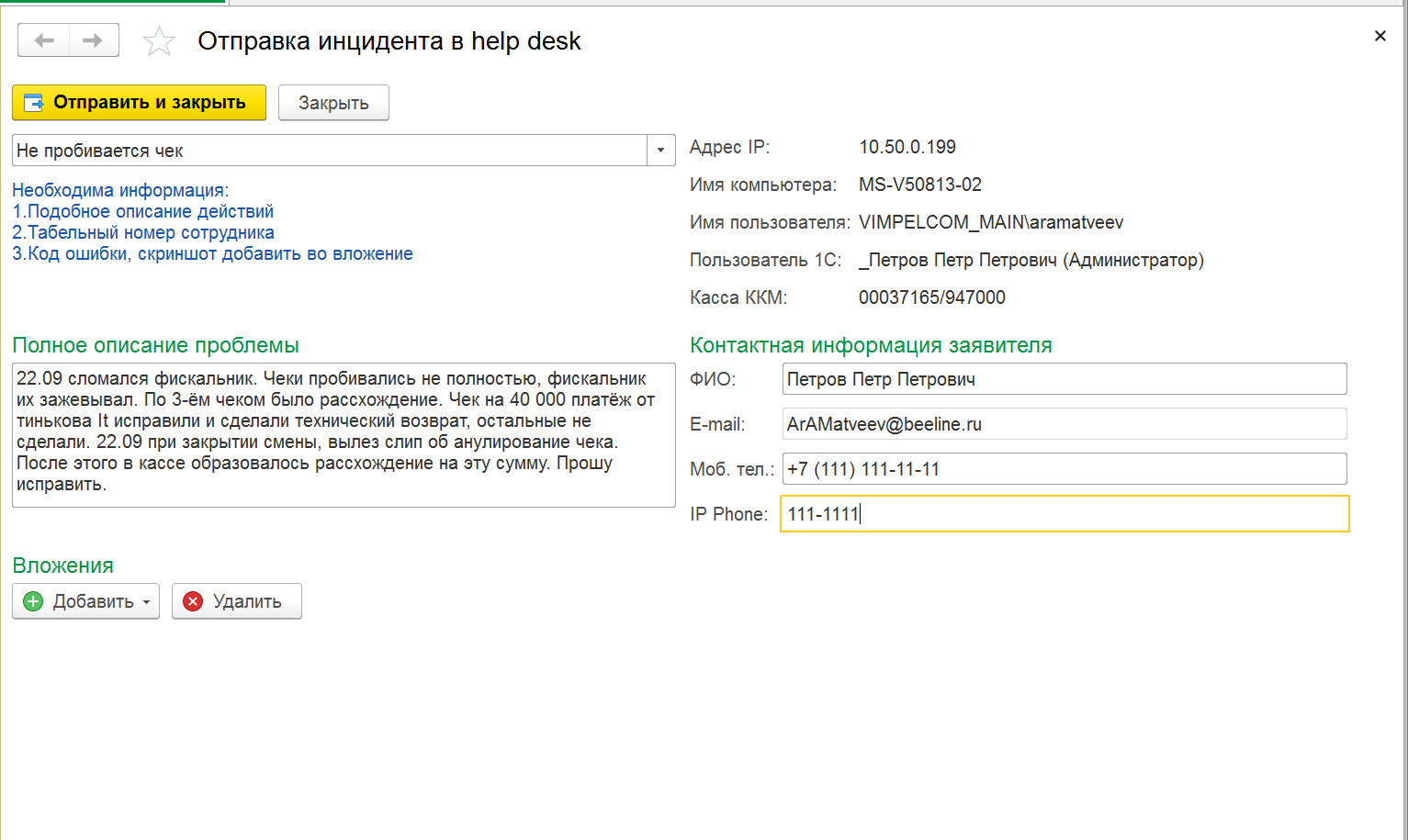
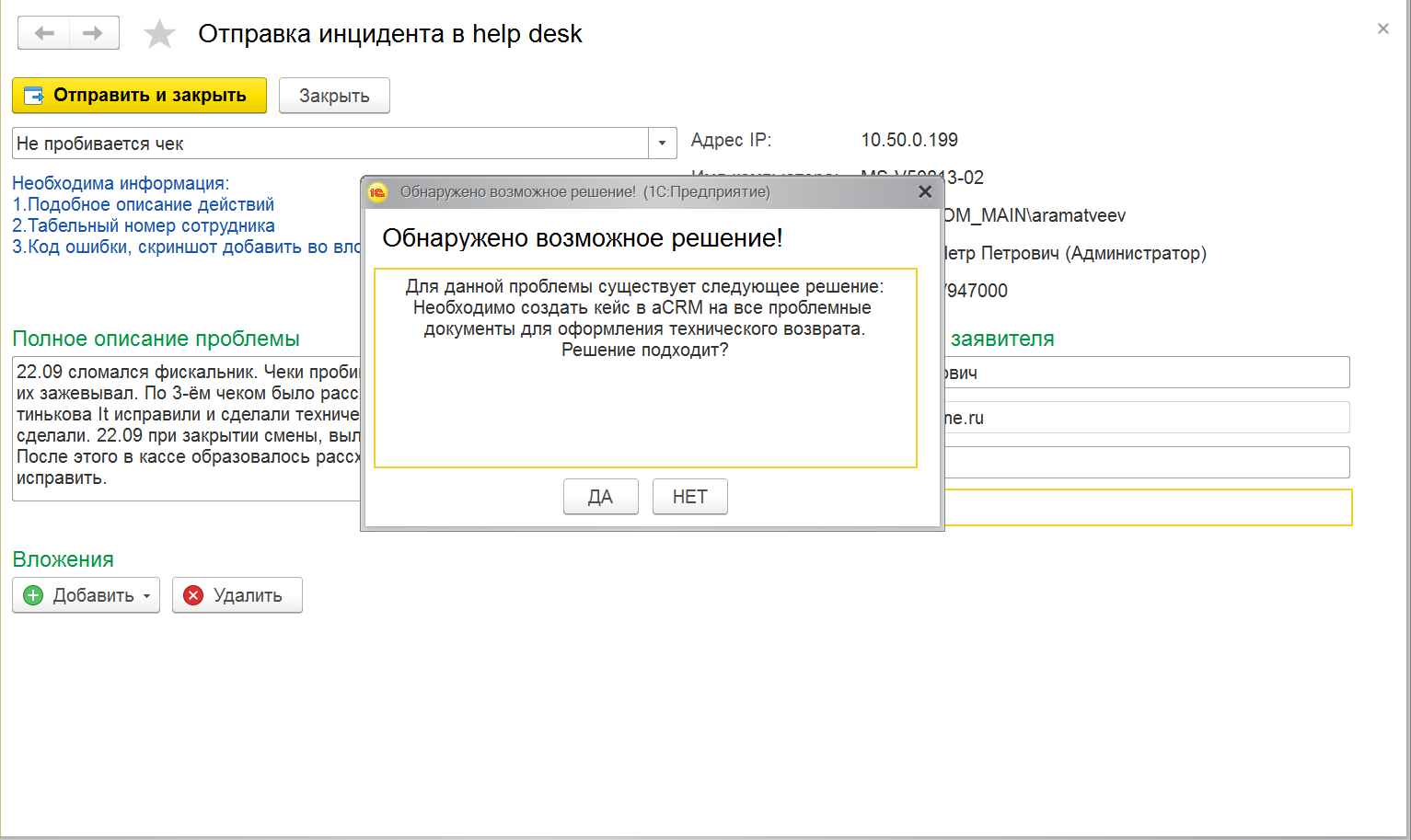
- Поиск готового решения.
Изначально был проведен опрос сотрудников техподдержки, были выделены инциденты, которые сотрудник может решить самостоятельно. Затем по примерному тексту инцидента были выделены все похожие с помощью перекрестного сравнения выбран инцидент, максимально похожий на остальные по выбранной тематике. Затем мы создали базу данных, в которой в одной из таблиц был указан номер инцидента и описанное для него «саморешение», то есть решение, которое может проделать сотрудник самостоятельно. В случае, если на текст инцидента существует похожий инцидент с описанным решением – оно предлагается пользователю и задается вопрос «Решение помогло?» При положительном инциденте мы отмечаем для статистики эту информацию, инцидент не создаем, в противном случае информацию сохраняем и заводим инцидент.
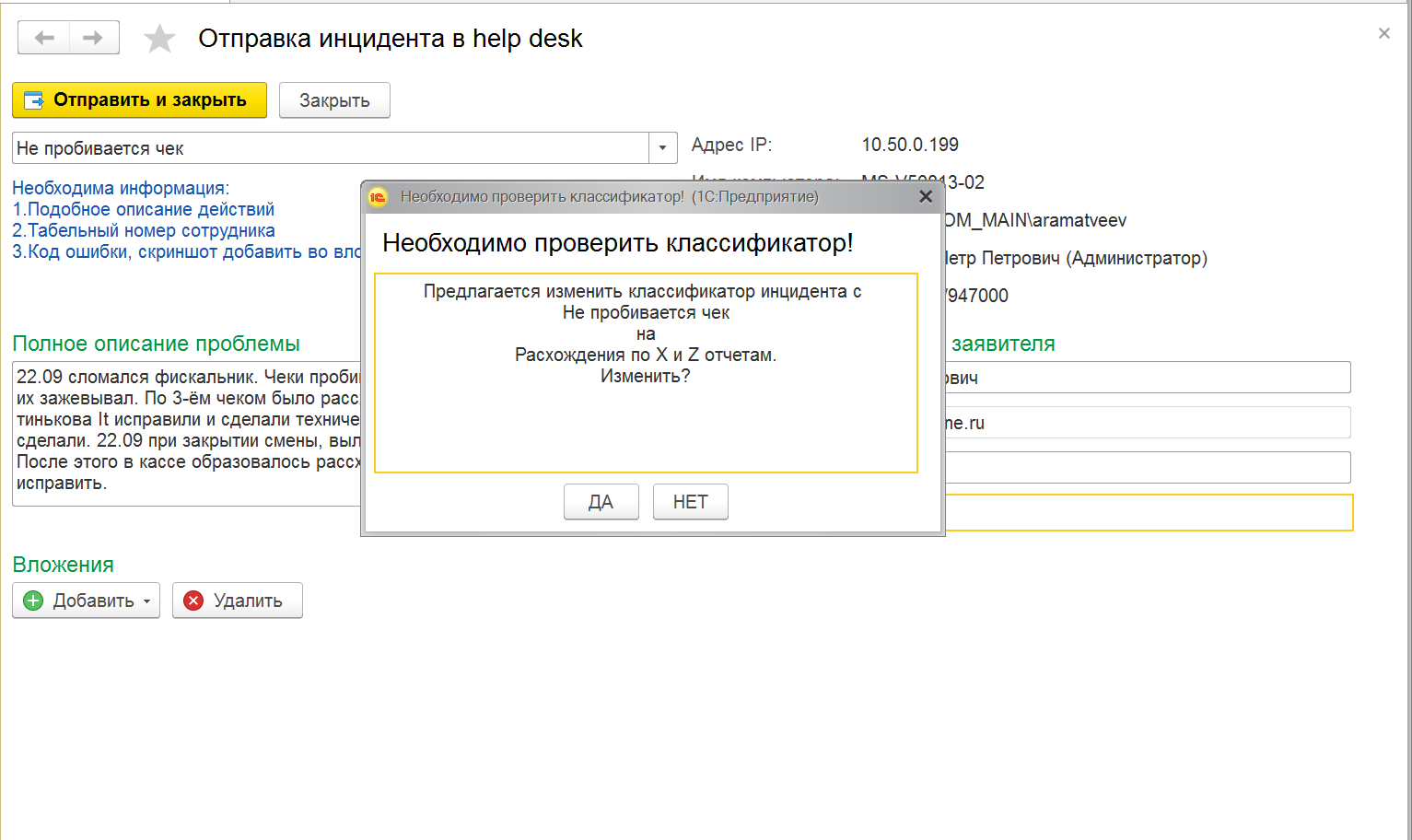
- Подбор классификатора.
Аналогично предыдущему пункту информация о том, подошел ли предложенный классификатор сохраняется в отдельной базе. Сначала мы анализировали полученные данные, но примерно через 2 месяца поняли, что система работает без нашего участия, так что теперь я где то раз в месяц заглядываю туда чтобы посмотреть статистику предсказаний ну или получить сводную информацию для очередной презентации J
Вступайте в нашу телеграмм-группу Инфостарт