О теме доклада

Расскажу про сравнительный анализ вариантов интеграции. Рассмотрим четыре кейса:
-
обмен данными из конфигурации 1С в базу SQL сайта через XML-файлы с помощью правил, написанных в КД2;
-
трансферная база данных на MySQL;
-
интеграция между «кучкой систем» через JSON и RabbitMQ;
-
интеграция 1С с сайтом через NoSQL базу данных MongoDB.
Все кейсы я выстроил по степени моей удовлетворенности работой этого варианта.
Первый кейс – КД2 в SQL

Первый кейс – обмен с помощью xml.
Суть этого кейса: туристические компании часто имеют сайты, где можно заказать билеты, подобрать тур, поездку или экскурсию. В начале карьеры я работал в такой туристической компании, и они хотели интегрировать свой сайт с самописной системой на 1С.
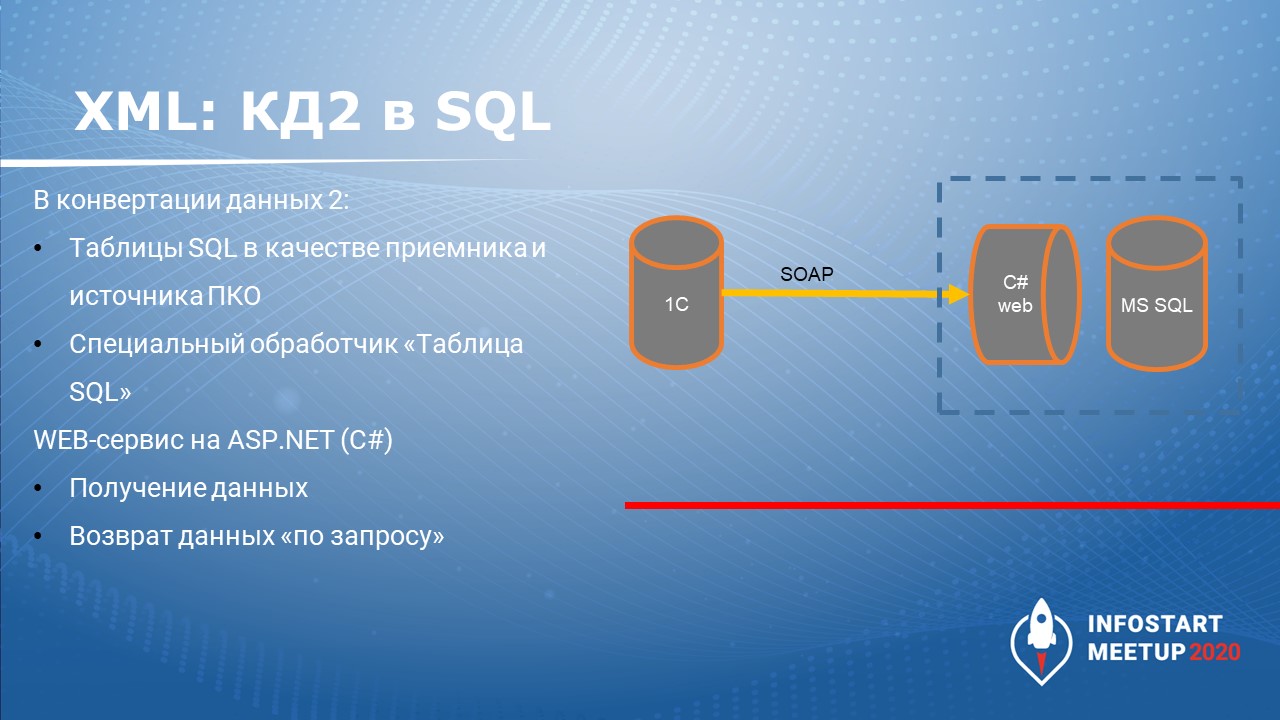
Тогда мне казалось, что требования меняются очень часто, поэтому я пошел по пути разработки конструктора. Чтобы сделать такой конструктор, я немного изменил «Конвертацию данных 2»:
-
Сделал так, чтобы источником или приемником могла быть не только база данных на 1С, но и некоторые SQL-базы данных в качестве объектов.
-
Добавил возможность выбора объекта «Таблица SQL».
С помощью измененной «Конвертации данных 2» настроил правила обмена между 1С и SQL-базой данных, которая используется сайтом.
И написал на С# веб-сервис, который получает данные от 1С и, опираясь на правила КД2, раскладывает эти данные в таблицу SQL.

Работа была интересной, мне было приятно этим заниматься. В этом решении были позитивные стороны:
-
изменения можно было вносить быстро;
-
с помощью КД2 я легко добавлял реквизиты, перенастраивал обработчики;
-
и в 1С это было легко отлаживать.

Но негативных сторон было больше:
-
получилось решение с высокой стоимостью владения, потому что исправлять сервис на C# – большая работа;
-
сложная отладка на стороне веб;
-
все это работало не очень быстро, потому что структура правил КД2 избыточная, а при каждом обращении к сервису они перечитывались;
-
получилось громоздкое решение, которое мы запускали очень долго: два месяца мы только его отлаживали.
Так я больше делать не буду, но кейс был интересным. Для себя я сделал такой вывод, что «Конвертацию данных» лучше не трогать: как ее поставляет вендор, так мы ее и используем.
ТБД MySQL
Следующий кейс – трансферная база данных на MySQL.

Вводные данные кейса: микрофинансовая организация, информационные системы активно развиваются. Система самописная, писалась много лет.
Задача – получать заявки с партнерской сети.
Фактически, нужно было автоматизировать основной бизнес-процесс компании. Партнерская сеть очень большая: десятки партнеров в каждом городе РФ, это сотни и даже тысячи пользователей сайта.
Когда я пришел в компанию, там была реализована первая версия обмена. В ней была куча проблем:
-
постоянная потеря данных;
-
сложно было искать ошибки, мы просто не понимали, что происходит – несмотря на то, что я был руководителем, мне приходилось самому ежедневно копаться в коде, выяснять, что произошло, почему так получилось;
-
в день у нас было до нескольких часов простоя. Еще раз подчеркну: это был основной бизнес-процесс компании, несколько часов простоя – просто недопустимо.
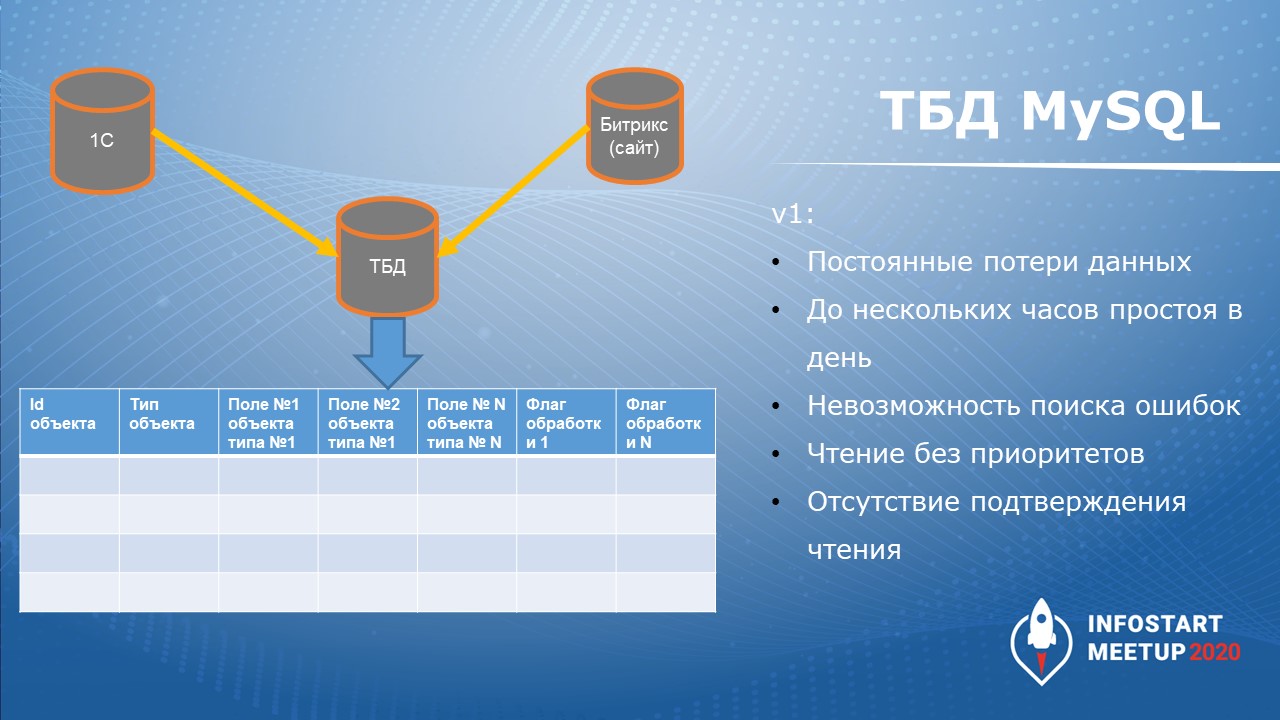
Первая версия обмена подразумевала, что 1С и сайт на Битриксе с двух сторон что-то пишут в трансферную базу данных, а параллельно в цикле опрашивают наличие записей и считывают, если что-то появилось.
Причем на тот момент в этой трансферной базе данных на MySQL была всего одна таблица. Ее структура представлена в левой части слайда. Там есть:
-
ID объекта;
-
тип объекта – например: новый клиент, предварительная заявка, постоянная заявка и т.д.;
-
колонки с полями для каждого типа объекта – некий аналог шахматной ведомости;
-
и набор флагов для обработки объектов – например, флаги «Заявка предварительная», «Заявка постоянная» и т.д.
Главная проблема первой версии обмена заключалась в том, что за то время, пока отрабатывает цикл опроса таблицы, пользователи сайта Битрикс могут несколько раз обновить данные по одной и той же заявке. Они проходят один экран, нажимают «Далее», и запись обновляется, потому что ID объекта одинаковый, появляется только новый флаг обработки. 1С еще предыдущую запись не прочла, а уже появилась следующая.
В итоге 1С читает запись, но у нее не хватает данных, которые должны были быть созданы на предыдущем этапе. Все падает, но мы не понимаем, почему упало.
Первая версия – провальное решение: на одной таблице никогда нельзя организовывать обмен.
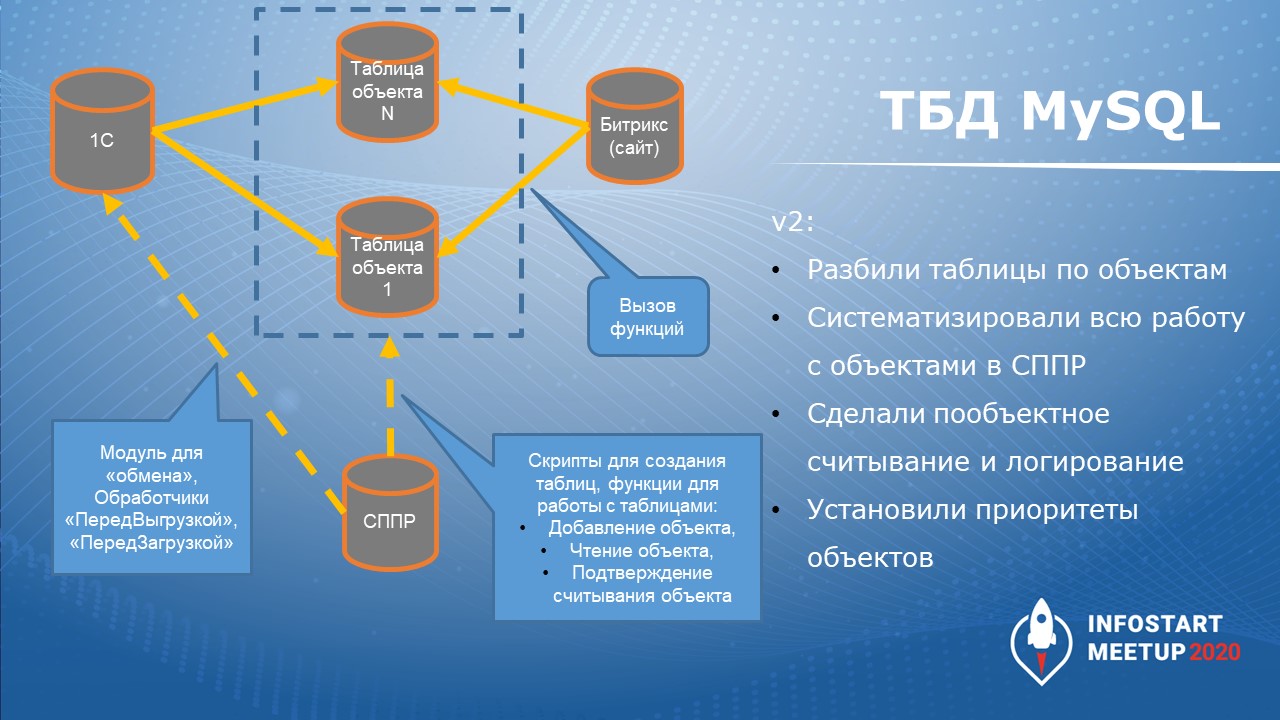
Но сам кейс ТБД мне понравился – после того, как мы его корректно реализовали и переработали.
В чем суть переработки?
-
Мы разбили промежуточную базу данных так, чтобы на каждый объект приходилась своя таблица.
-
Сделали так, что сайт 1С и Битрикс работали с объектами через функции, а не через обращение к таблицам. Это было сделано для унификации и для того, чтобы логика работы была одинаковой. Для этого были добавлены транзакции и определенные механизмы для контроля версионности, чтобы проблем с версионностью не было – про это расскажу чуть позже.
-
Систематизировали всю работу с объектами в СППР – во-первых, потому что там есть весь перечень метаданных, во-вторых, это была наша основная учетная система на тот момент.
-
Добавили в СППР сопоставление некоторых реквизитов 1С с полями в базе данных Битрикс.
-
В СППР генерировались скрипты для создания таблиц в базе данных MySQL – мы перерабатывали обмен очень активно, раз в два дня обновляли правила обмена и трансферную базу данных.
-
Также в СППР генерировался модуль для 1С, который выгружал в трансферную базу данных некоторые данные.
-
-
Конечно, проработали вопрос с приоритетами.
-
Сделали пообъектное считывание и логирование. Не забывайте делать логирование при обменах.
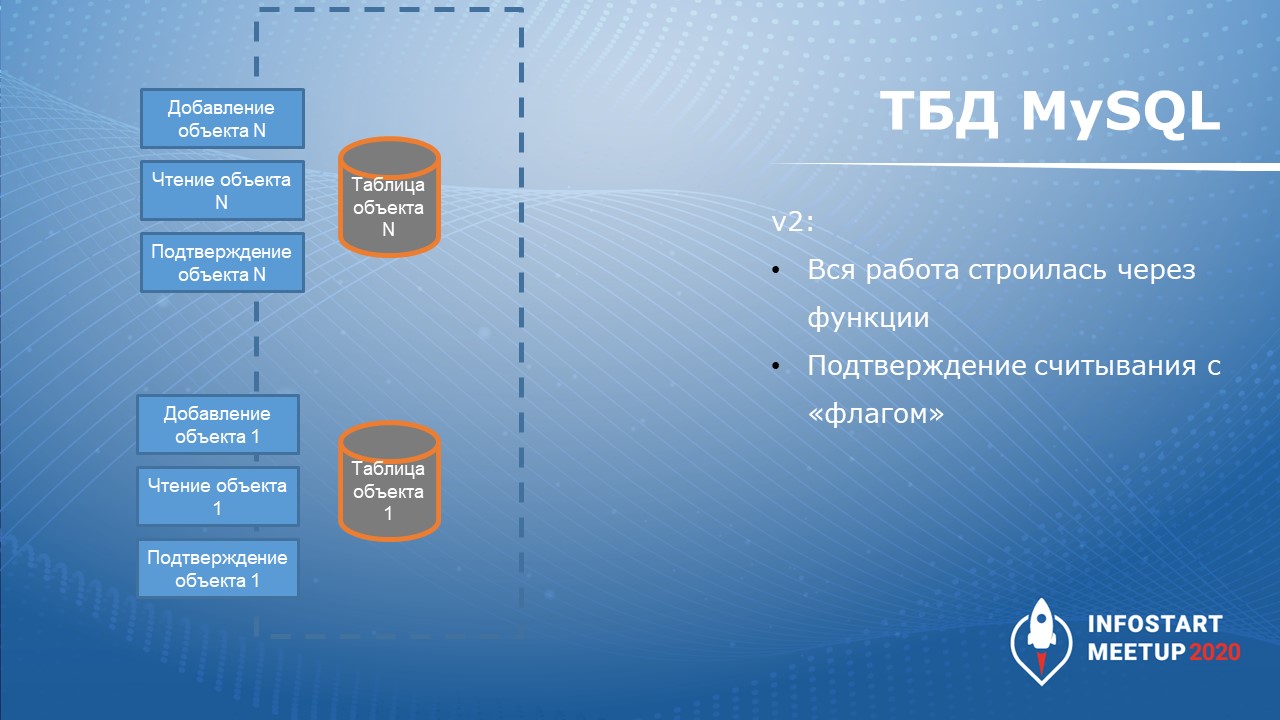
Для взаимодействия с таблицами мы реализовали следующие функции:
-
Добавление объекта
-
Чтение объекта
-
Подтверждение чтения
Функции были одинаковыми для каждой таблицы. Так как СППР генерировала скрипт для создания таблиц в базе данных, это было не очень тяжело сделать.
Логика работы с таблицами строилась следующим образом:
-
когда 1С хотела отправить на сайт обновленную заявку или обновленного контрагента, она вызывала функцию добавления объекта;
-
а сайт в свою очередь – функцию чтения объекта;
-
и если прочитал успешно – функцию подтверждение чтения объекта.

Все было достаточно стройно и логично. Решение было позитивное, держало большую нагрузку, но было два НО.
-
Первое «но» – иногда зависали запросы, отправляющие бинарную информацию. Проблема была простой: сайт закидывает в базу бинарные данные с документами клиента, а 1С эти данные читает – и при чтении запрос зависал наглухо. Пытались решить правильно: перелопатили всю документацию по MySQL, перепробовали разные версии MySQL, разные дистрибутивы Linux – много времени угробили на то, чтобы разобраться, почему оно так зависает, но не нашли в чем проблема. Мы решили проблему по-простому: сделали сервис на сервере баз данных, который проверяет: если есть запрос выполняющийся больше 10 секунд, он его прибивал.
-
Вторая проблема – на сайте были пользователи, которых мы называли «машинистками». Они умудрялись так быстро вводить заявки и переводить их из одного этапа в другой, что складывалась ситуация, когда 1С еще не прочла данные объекта, а уже прилетела информация о его обновлении.

На схеме это выглядит так: объект добавился, 1С его прочитала, но в этот момент к объекту прилетает обновление, имеющаяся база 1С записывала не так уж быстро. Поэтому ситуация, когда 1С еще читает данные и проводит документ, а в это время уже прилетает обновление с сайта – иногда проявлялась.
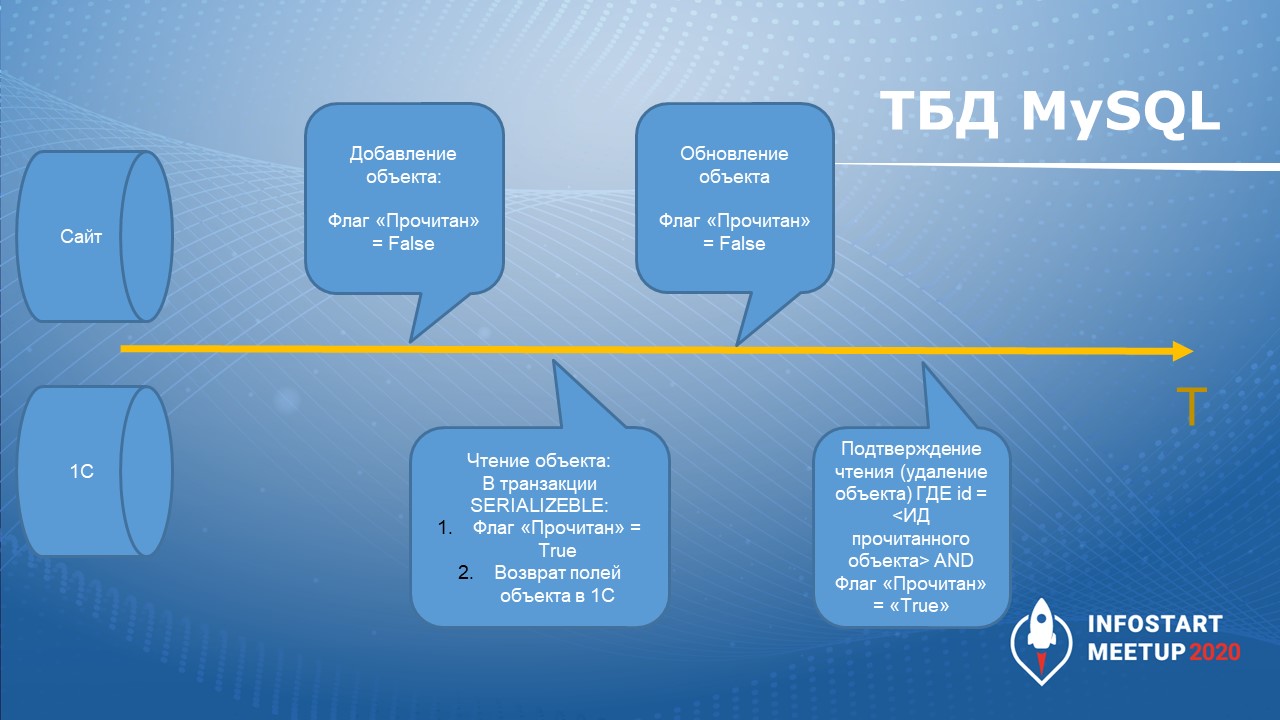
Нам удалось решить эту ситуацию:
-
Когда объект добавляется, у него остается флаг «Прочитан» = Ложь.
-
В транзакции с максимальным уровнем изоляции 1С получает эти поля, начинает объект считывать, мы ставим флаг «Прочитан» = Истина.
-
Когда приходит обновление объекта, опять ставится флаг «Прочитан» = Ложь.
-
При подтверждении чтения удаление из таблицы происходит только при условии, что ID равен ID переданного объекта и флаг «Прочитан» = Истина.
Схема простая и эффективная, позволила решить проблему с обновлением объекта. Если у вас будет подобный кейс – пользуйтесь.
Выводы по этому кейсу:
-
Сама по себе схема обмена через трансферную базу данных – неплохая. Мы применили такой прием, потому что заказчик проекта настаивал на обмене через промежуточную базу данных.
-
Буду ли я повторять? После того как я познакомился с RabbitMQ и другими технологиями, я не уверен, что буду вкладывать опять такие трудозатраты в реализацию этого кейса. Но сам по себе кейс – неплохой.
JSON, Rabbit и «кучка систем»
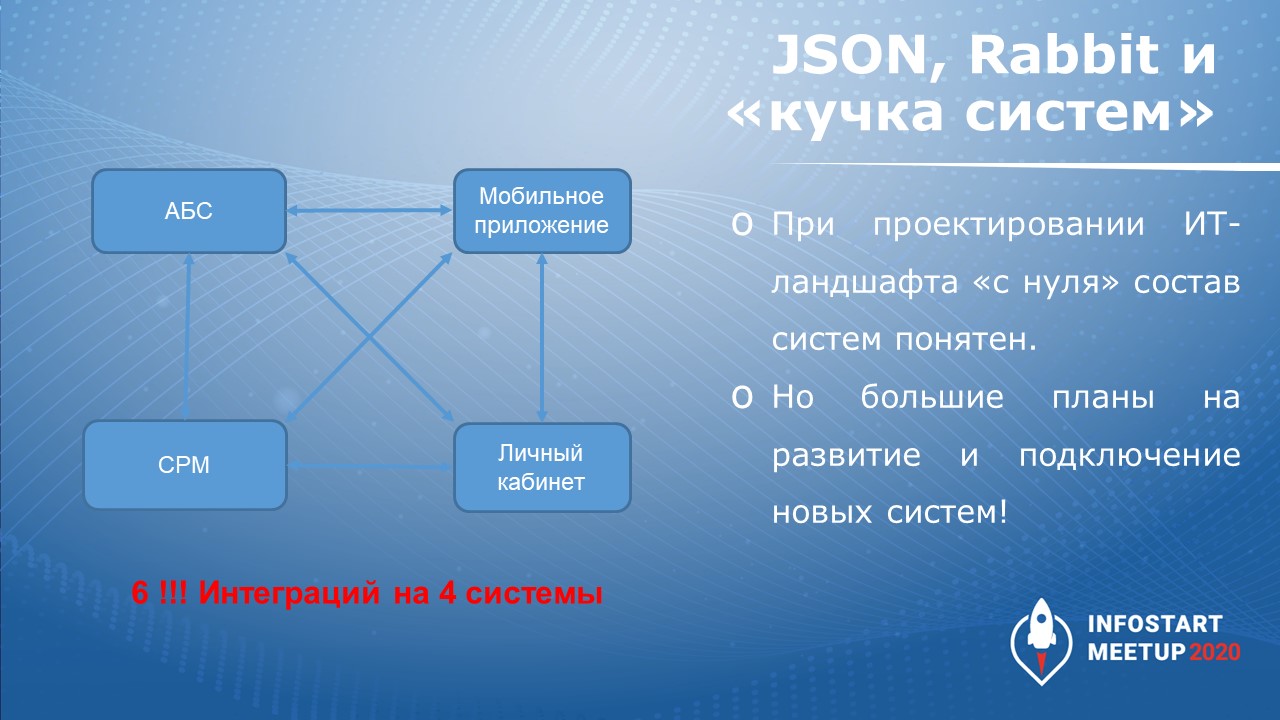
Следующий кейс – об интеграции между «кучкой систем» через JSON и RabbitMQ.
Об этом кейсе я подробно рассказывал в докладе 2019-го года. Сегодня я не буду повторять рассказ о бизнесовой «обвеске», расскажу только то, что у этого кейса внутри.
Основная проблема «кучки систем» показана на картинке слева – здесь видно, что для того, чтобы заинтегрировать между собой 4 системы, нужно 6 интеграций. Поэтому было решено реализовать промежуточную BPM-систему, с которой будут обмениваться все остальные системы, чтобы делать не шесть интеграций, а каждую систему интегрировать с шиной данных.
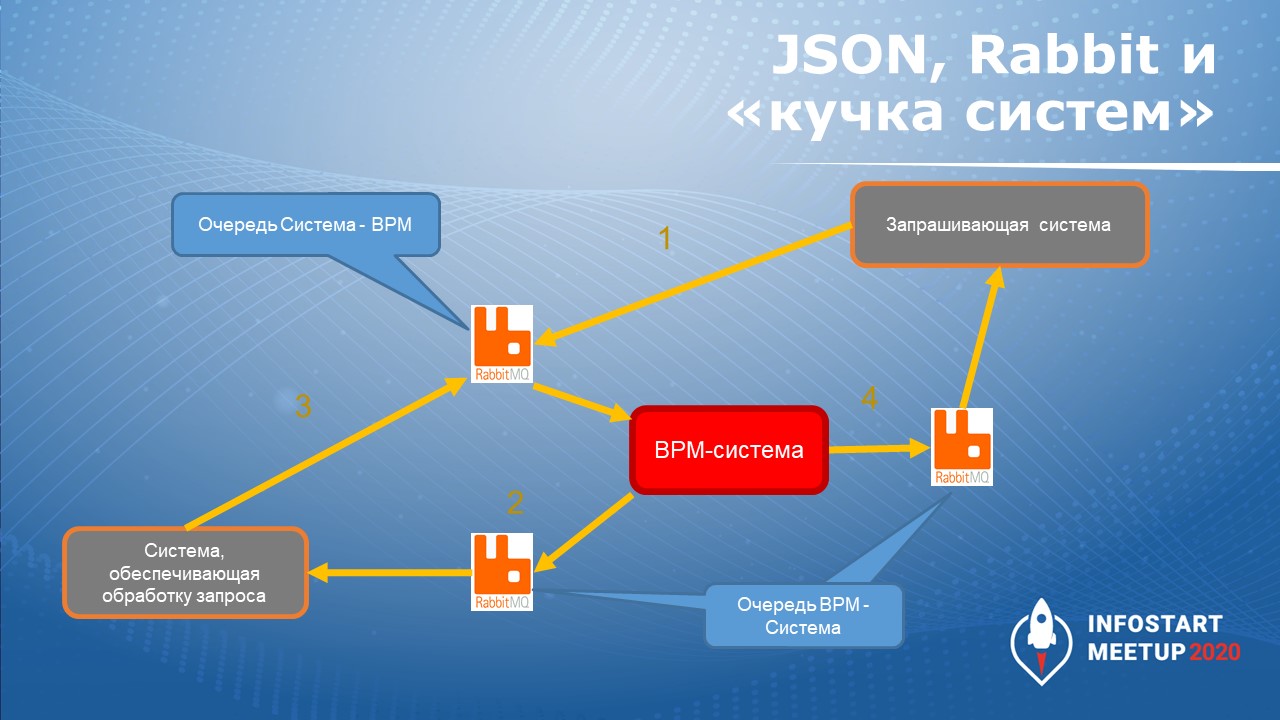
BPM-система принимает сообщения от запрашивающей системы, производит маршрутизацию сообщения и направляет сообщение в систему, которая обеспечивает обработку запроса. После получения ответа BPM-система возвращает ответ запрашивающей системе. Все потоки сообщений BPM-системой обрабатываются через очереди «кролика».
BPM-система плюс «кролик» – по сути, ESB-система. С одной стороны, эта система гарантирует доставку сообщений, а с другой стороны – их маршрутизацию и, возможно, трансформацию. И в BPM системе реализована некоторая бизнес-логика.

Мы сделали BPM-систему на 1С, потому что это было быстро – мы не нашли интегратора, который подписался бы под сроками, которые нам были нужны. В нашей команде профильного опыта не было, поэтому сделали на 1С.
Как видите, функциональность по обработке сценариев данных получилась серьезная: BPM-система поддерживала сессии мобильного приложения (чтобы при повторном запуске приложения не спрашивать пароль, проверялись активные сессии), обслуживала сайт.
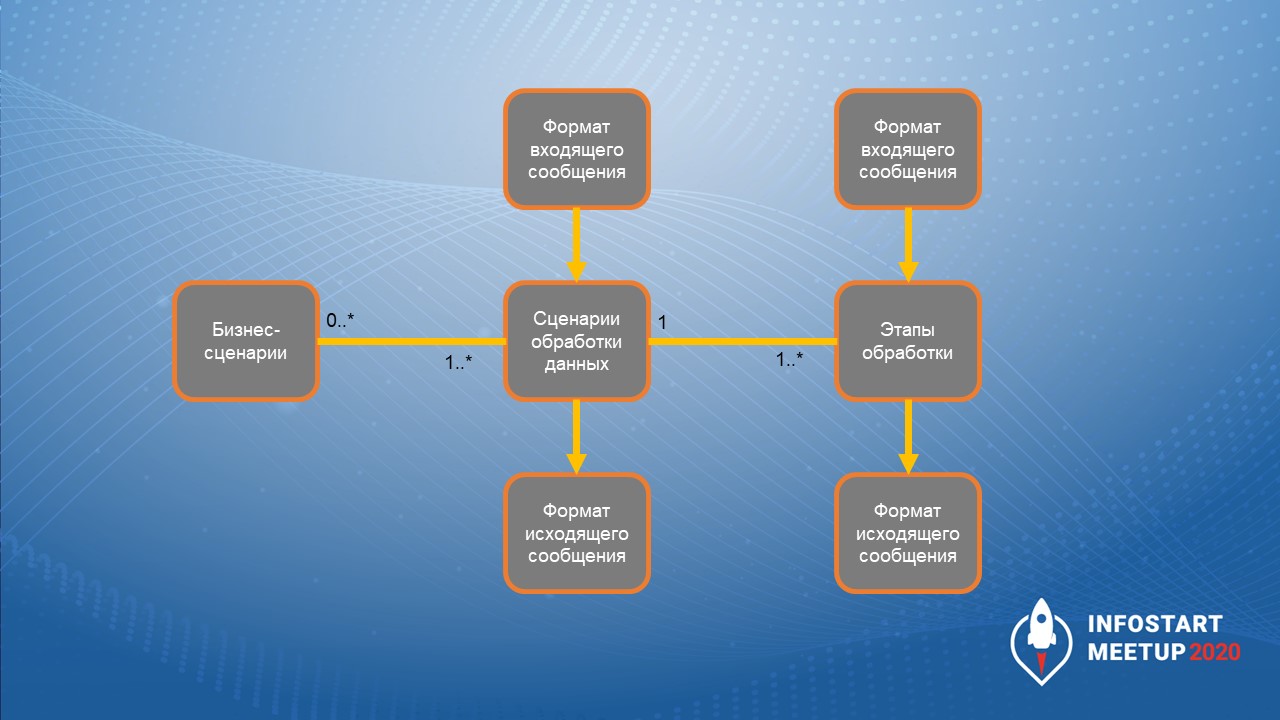
Самое интересное во всем этом – мы применили подход к тому, что форматы сообщений описываются внутри BPM-системы.
Все сообщения были записаны в JSON определенного формата. На вход сценария обработки данных идет сообщение в JSON – в сообщении должен быть написан ID сценария (допустим, это будет сценарий «Получить автомобили»). Сценарий производит обработку сообщения и выдает сообщение в описанном формате.
Мы применили интересный кейс: включили моделирование бизнес-сценариев в BPM-систему. Обратите внимание: на слайде стоят цифры, это из диаграммы классов UML, там есть нотация, которая обозначает, что:
-
бизнес-сценария может не быть, поэтому связь пронумерована как 0;
-
бизнес-сценарию соответствует «Сценарий обработки данных». Причем, для одного бизнес-сценария точно должен быть хотя бы один сценарий, таких сценариев обработки данных может быть несколько (в обозначениях 0..* и 1..* «звездочка» значит «многие ко многим»)
-
и внутри каждого сценария обработки данных точно должен быть «Этап обработки данных», иначе сценарий не заработает.
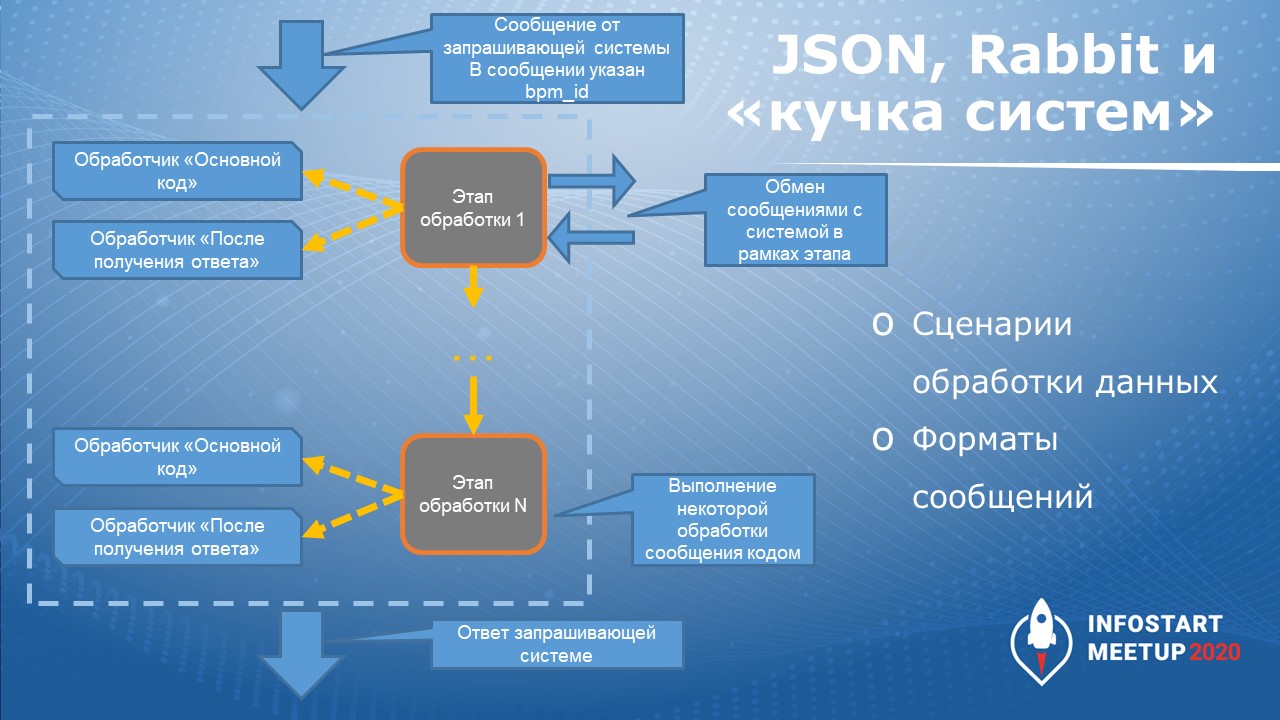
Что делает сценарий обработки данных?
-
На вход идет сообщение в JSON, там указан bpm_id – ID сценария, который должен обрабатываться.
-
Этапы обработки данных производят обмен сообщениями с другими системами,
-
И на выходе сценария – ответ запрашивающей системы.
Я опять же, сделал конструктор. Внутри этапа обработки данных можно писать кодом разные обработчики – программный код для обработки входящего сообщения, программный код обработки получения ответа.
Всего на это у меня ушло порядка месяца. Разработка не очень сложная, но возможностей дала много, мы интегрировали пять систем: мобильное приложение, сайт, CRM, АБС-система, личные кабинеты.
Такой подход позволил сократить время на настройку обмена – она сводилась к тому, что мы добавляем новый сценарий и настраиваем, к кому этот сценарий должен обращаться.
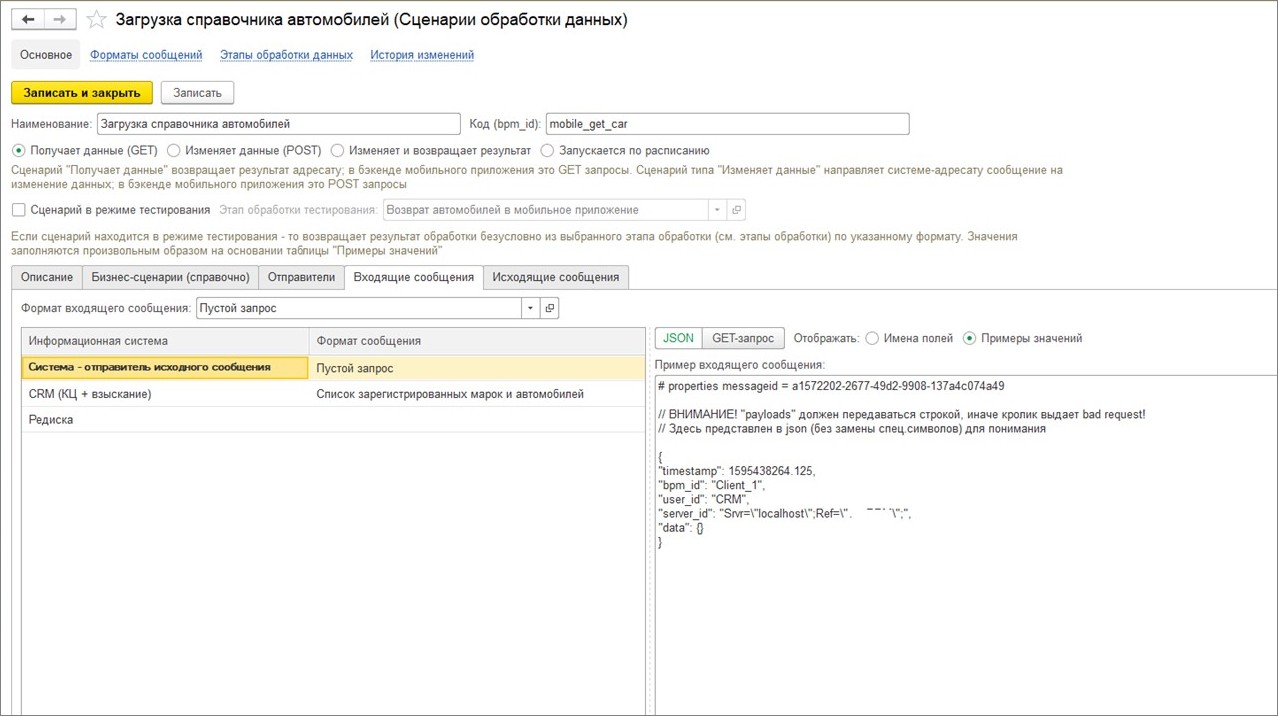
Вот так выглядит сценарий, в котором мобильное приложение запрашивает список автомобилей у CRM-системы. Сверху мы задаем его код – реквизит «Код (bpm_id)».
Сам сценарий обработки данных может только получать данные, изменять данные или запускаться по расписанию. Причем мы можем явно ограничить, кто может запрашивать этот сценарий обработки данных (кто отправитель) – говорим, что такие запросы могут отправлять только определенные приложения, другие приложения такие запросы отправлять не могут.
Справа внизу можно увидеть, что мы сделали для себя удобный сервис, что система генерит некоторые примеры значений. Для отладки это тоже было очень удобно.
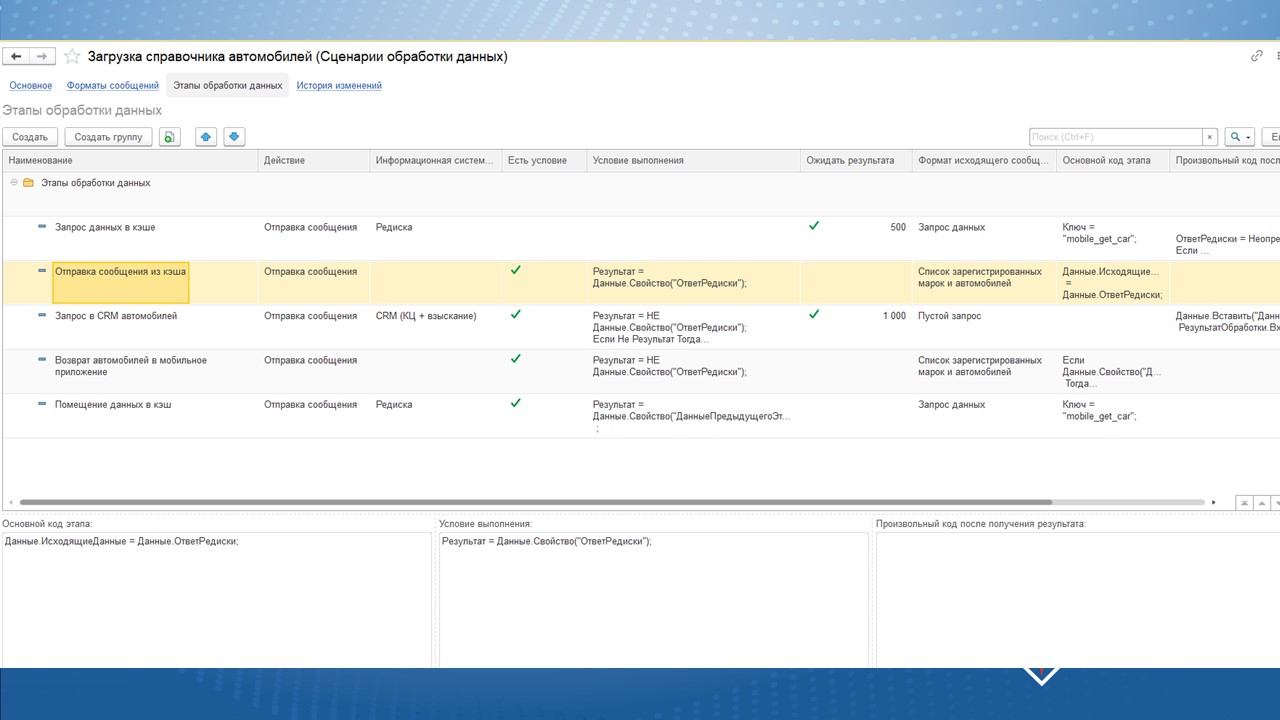
На этом слайде показаны этапы обработки данных для сценария – тут видны условия выполнения, возможные разветвления, трансформация в основном коде этапа. Можно задать время ожидания.
Всю эту функциональность я «запилил» за месяц.
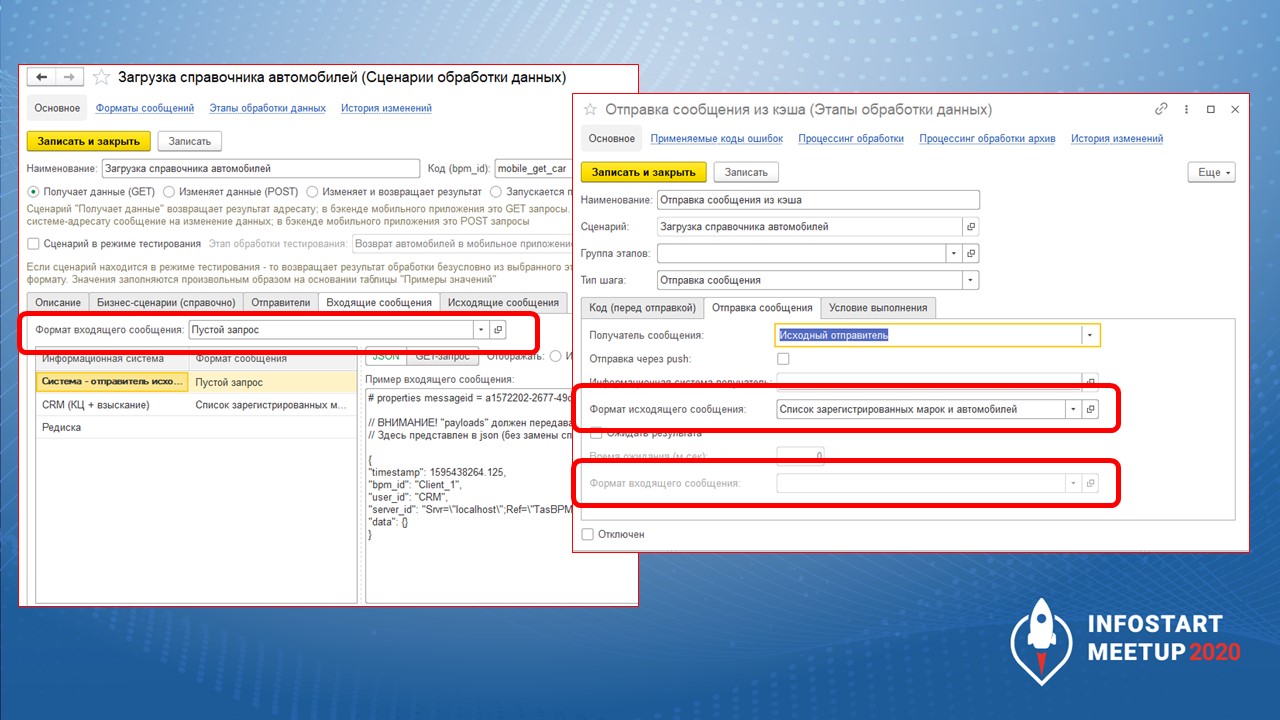
Самое интересное – для сценария и конкретного этапа обработки данных можно задать формат входящего и исходящего сообщения.
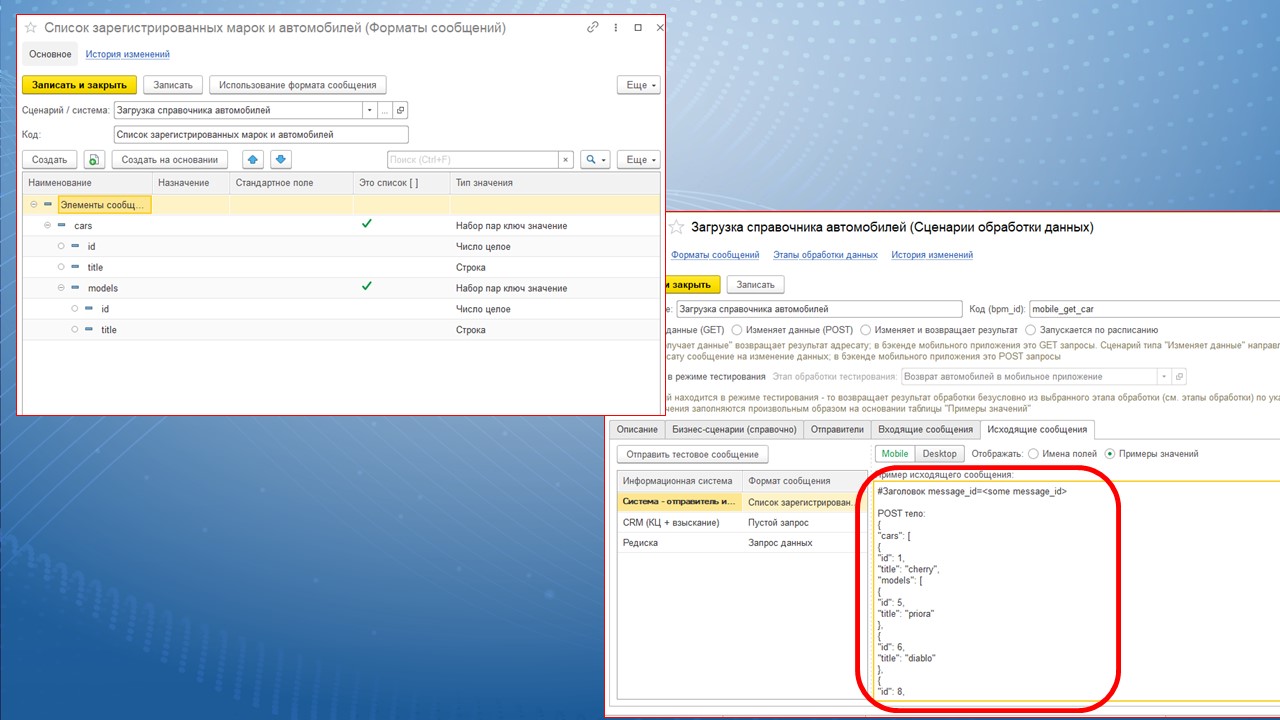
Что такое формат сообщений? Это простой иерархический справочник, который позволяет описать структуру JSON-сообщения. Когда приходит сообщение для сценария обработки данных, система проверяет, соответствует ли формат сообщения справочнику. Если не соответствует – возвращает ошибку.
На левом скриншоте – формат, описанный с помощью справочника 1С, справа – JSON, сгенерированный по этому формату (некоторый тестовый JSON, который мы использовали для тестирования системы).
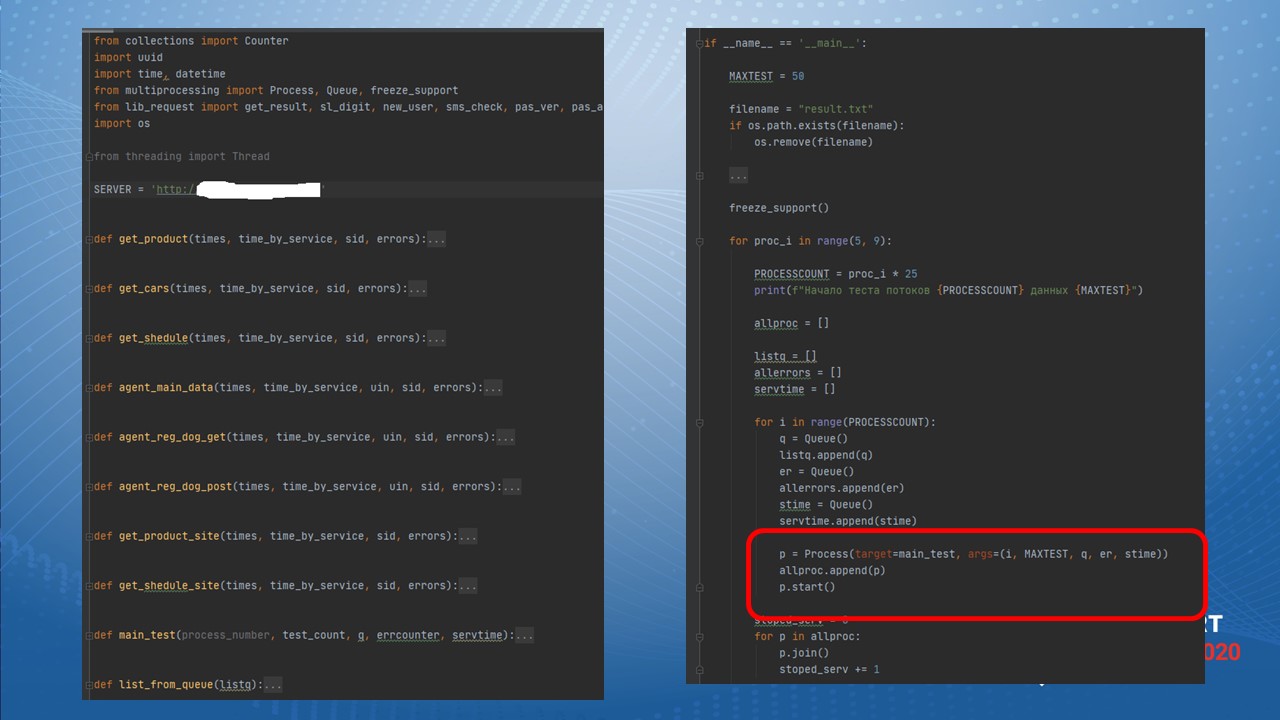
Мы всю эту систему обложили тестами на Python, причем мы сделали мультипоточные тесты: на разных компьютерах запускали тестирование на много потоков.
Мой ноутбук, выдерживал всего 50 потоков тестирования. Мы арендовали виртуальные сервера для серьезного нагрузочного тестирования. Но так как это основная инфраструктурная система, это было оправданно.
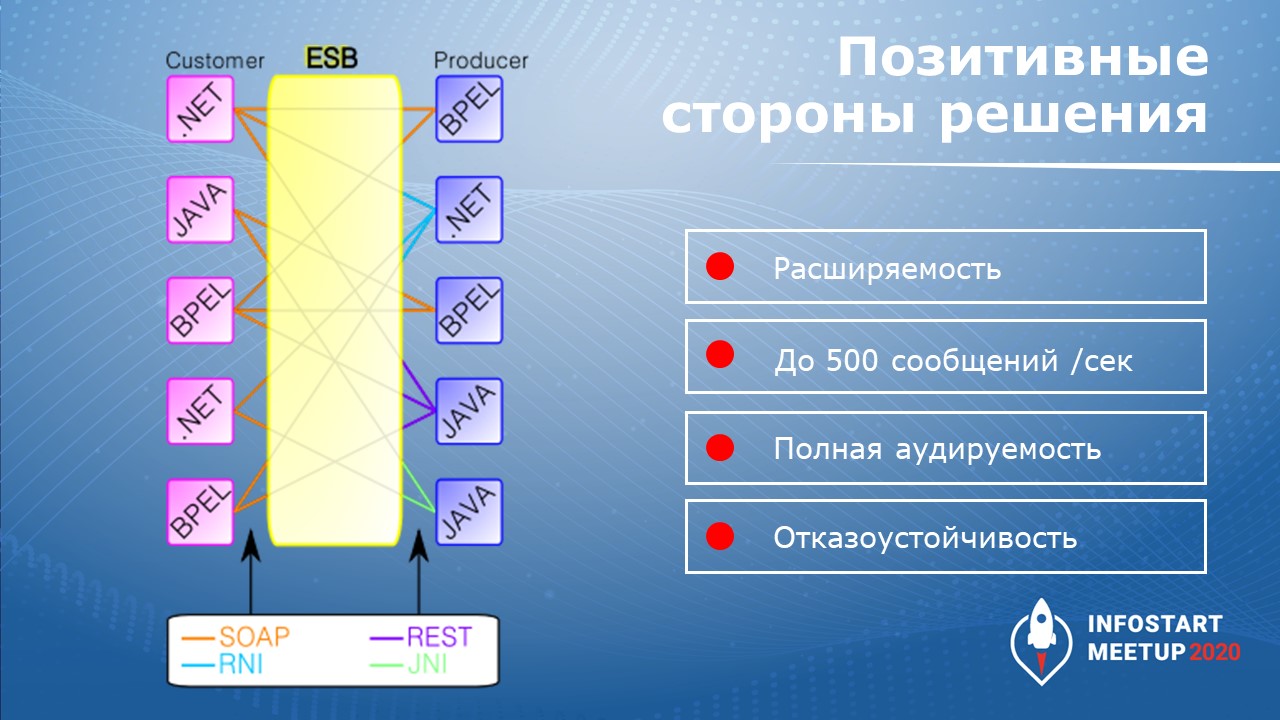
Что получилось
-
По результатам тестов в нагруженном режиме система у нас тянула несколько сотен сообщений в секунду. Причем, ее очень легко масштабировать – можно открыть рядом вторую такую же BPM-базу или добавить ядер, потому что там многопоточная обработка, 1С по моему опыту примерно 1.5 процесса на ядро хорошо обрабатывает.
-
Система получилось расширяемая – новые системы подключить очень легко.
-
Полная аудируемость достигается за счет того, что каждое сообщение сохраняется в специальный регистр сведений. Когда сообщение приходит, оно тут же логируется. При этом мы сделали интересный кейс, когда количество сообщений в этом регистре сведений становится очень большим, мы перекладываем его в архивный регистр сведений. За счет этого в основном регистре сведений с данными сообщений всегда немного и всегда он быстро открывается, в нем всегда можно быстро найти нужное сообщение
-
Система показала себя устойчивой, время обработки запросов (время ответа на запрос сайта) когда система не очень загружена – 100-200 миллисекунд, но когда мы ее при тестах сильно загрузили, оно не поднималось выше 700 миллисекунд.
Хороший кейс, но в следующий раз, если я захочу повторить, то в центре поставлю промышленную ESB. Здесь из-за нехватки времени мы пошли простым путем, но при наличии разумных временных ресурсов я попробую поставить промышленную ESB для этой архитектуры. Но сама архитектура мне очень понравилась.
MongoDB

Следующий кейс – это интеграция через СУБД MongoDB, которая основана на JSON. Я не сразу понял, как с этой СУБД можно работать, но после того, как применил ее в последнем проекте, я в восторге от этой СУБД.
Не буду подробно рассказывать про формат JSON, который в ней используется, вкратце скажу, вместо таблиц в этой СУБД – коллекции.
Коллекции, в свою очередь, содержат документы. Документ – это аналог записи таблицы.
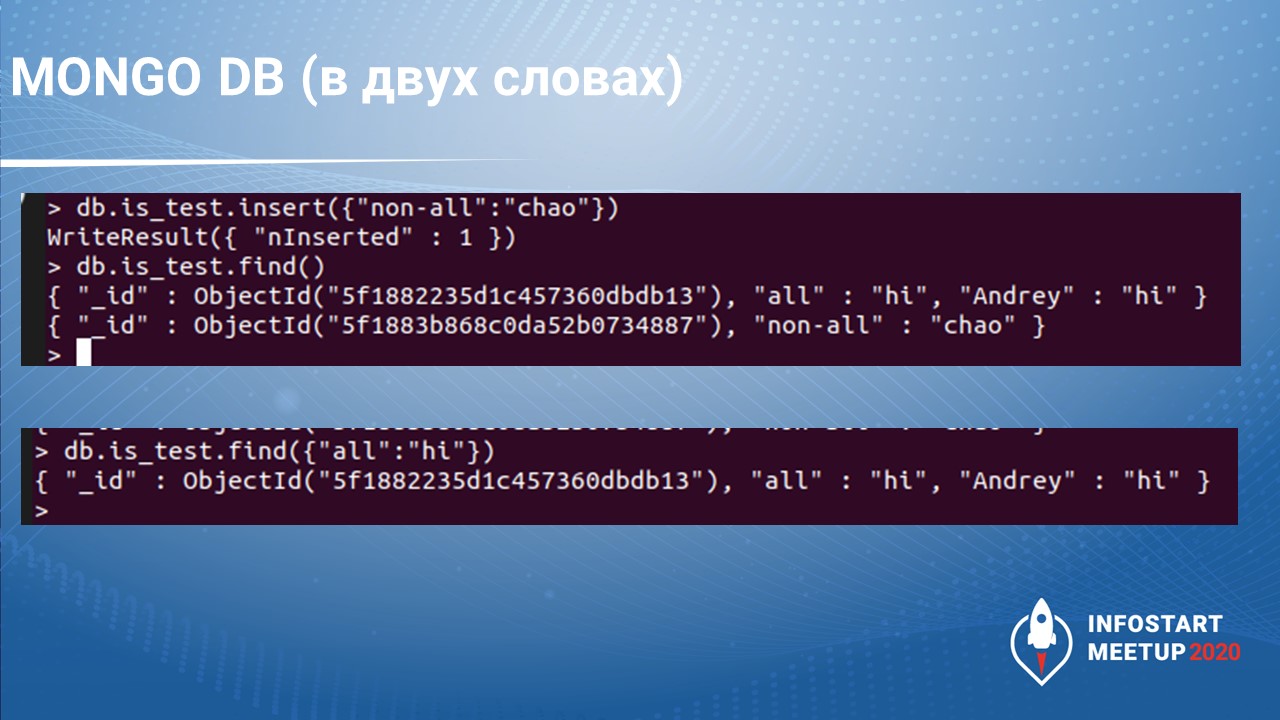
При этом каждый документ может иметь свой набор полей. Поле – как колонка таблицы.
Один документ – запись в.JSON.
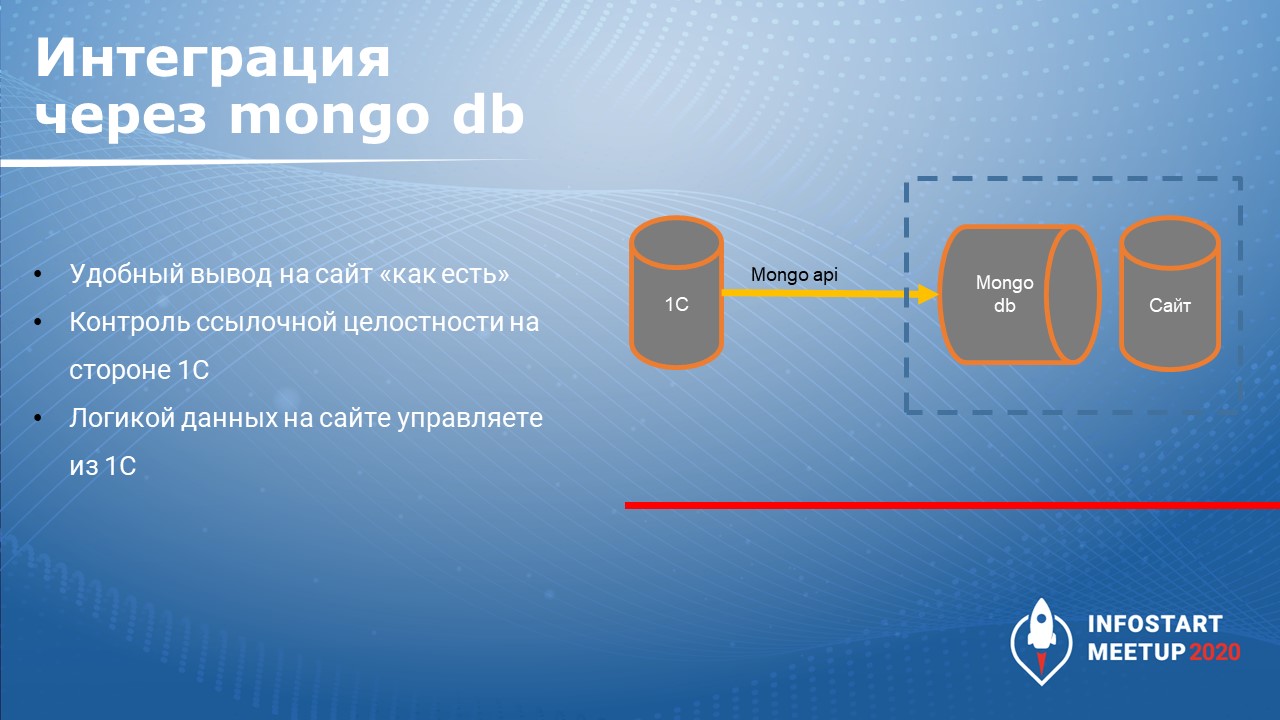
Работа с MongoDB мне понравилась, потому что это удобно именно при интеграции с сайтами. Вы просто говорите вэб-программисту: «Я тебе эту таблицу в JSON раскладываю, и ты ее на главную страницу выводишь. Как я тебе положил, так же и выводишь». И с программистом просто найти общий язык, и выгружать просто.
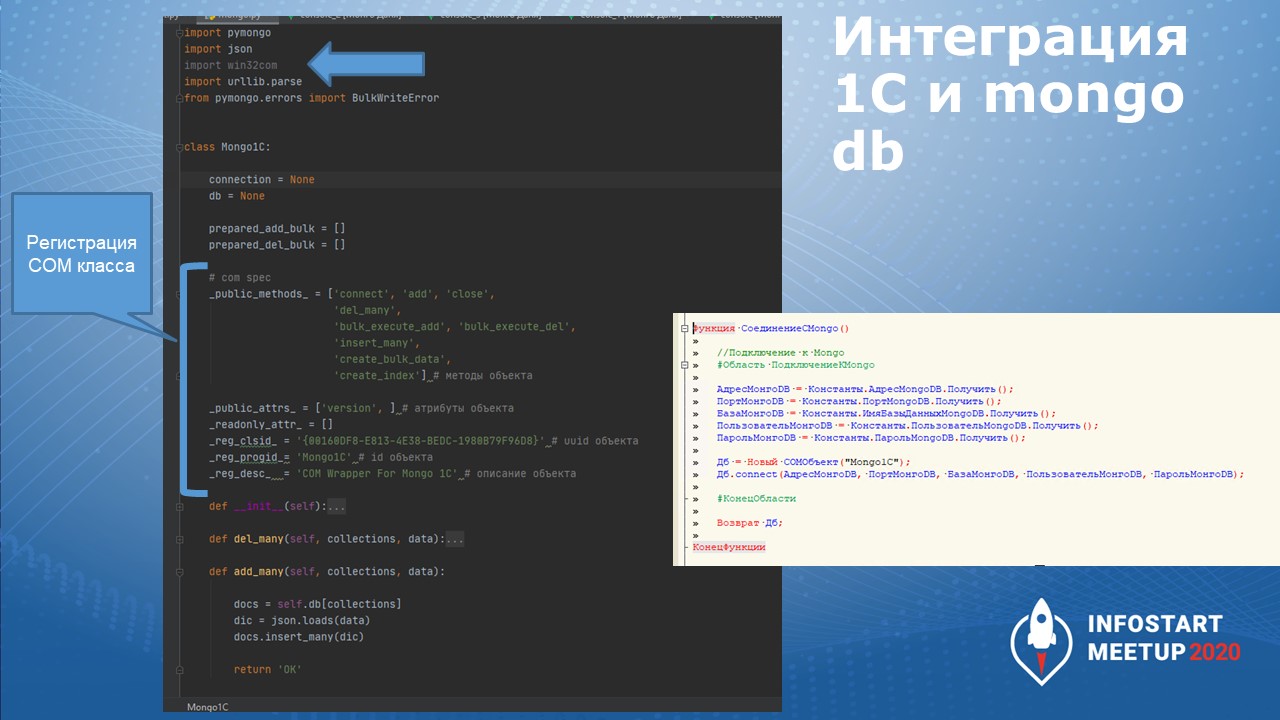
Чтобы написать интеграцию с MongoDB на Python, мне потребовалось два часа.
В Python с MongoDB легко работать, например я применял методы – insert_many() и delete_many().
Делаете класс для обертки «питоновского» кода в COM-библиотеку и вызываете этот COMОбъект откуда хотите. Справа показан пример того, как я из 1С подключаюсь к MongoDB.

Было пару непонятных моментов, которые не испортили впечатление.
-
Почему-то, если держать открытым соединение, деградирует производительность. После 5-6 запросов нужно переподключаться к базе данных. Пробовали на двух серверах, ситуация воспроизводится.
-
И еще меня удивило, что добавление индекса в таблицы не повлияло на время удаления и записи для нашего случая. Когда мы индексы добавили, скорость чтения возросла в десятки раз. Но мы ожидали, что сильная индексация таблиц повлияет на запись и удаление – не повлияла, что очень понравилось.

Что еще понравилось:
-
База в MongoDB занимала 18 Гб (при том, что 1С-ная база была в районе 100 Гб). Выгрузка этих 18 Гб на сервер в интернете с контролем каждой записи у нас заняла 16 часов. Казалось бы, с современными скоростями интернета это много. Но сервер, на который выливались данные, имел совсем смешные характеристики (у нас на этапе разработки на стороне WEB стояла совсем легкая, арендованная виртуалка), и такие скорости меня приятно удивили.
-
Поиск в таблице – это миллисекунды, очень здорово. Обратите внимание, у нас в MongoDB все данные хранились всего в двух таблицах – т.е. примерно по 9 Гб на таблицу.
-
Очень легко было работать с веб-разработчиком. Говоришь ему: «Вот таблица, ты ее выводишь». Они JSON хорошо понимают. Я эти таблицы спроектировал и все было очень просто и понятно.

И, конечно, как вы поняли из предыдущих кейсов, я очень люблю пилить конструкторы, поэтому запилил конструктор по трансформации данных реляционной СУБД в нереляционную MongoDB, но расскажу вам об этом в следующий раз.
Кейсы 2-4 я реализовал вместе в Даниилом Коневым (DaGlob).
Надеюсь, вам было интересно.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "Интеграционные решения в 1С".


Вступайте в нашу телеграмм-группу Инфостарт