
{kind=link}
Технология параллельных вычислений для 1С 8.2
Введение
Существуют множество методов оптимизации производительности информационных систем на базе 1С – MS SQL: линейная оптимизация тяжелых запросов (для этого можно изменить текст запроса, алгоритм формирования, индексный тюнинг), уменьшение множества блокировок (управляемый режим), увеличения производительности аппаратных ресурсов и прочие. Но если все перечисленные способы исчерпаны, а значительного увеличения скорости нет, то для определенных случаев можно применить технологию параллельных вычислений.
Что такое технология параллельных вычислений?
Технологии параллельных вычислений на данный момент применяются в основном для сложных инженерных расчетов в различных областях для ускорения выполнения на супер ЭВМ с большим количеством процессоров. Учитывая тот факт, что многопроцессорные сервера стали промышленным стандартом практически во всех крупных и средних организаций – применение параллельных вычислений в современных информационных системах, в том числе 1С, вполне обоснованно.
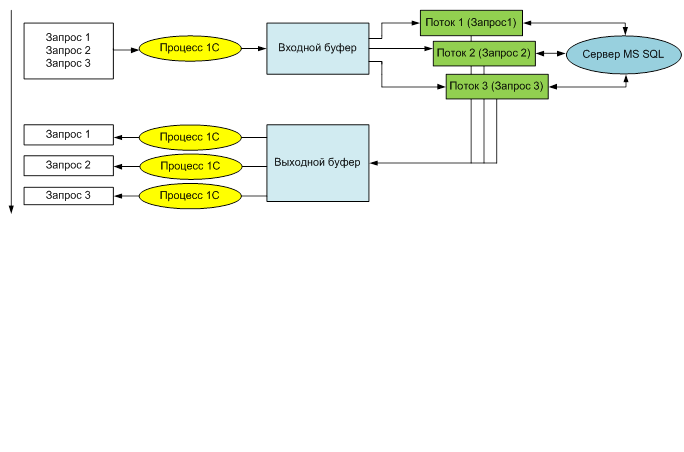
Как видно из рис.1 (см. ниже), из приложения последовательно передаются запросы для параллельного выполнения на сервере БД. После получения выборок запросов данные передаются в приложение и могут дальше обрабатываться.
Основные сложности применения технологии параллельных вычислений:
- Оценить возможность применения параллельных вычислений для запросов.
- Сложность адаптации и внедрения в прикладное решение.
В своем решении мы попытались нивелировать сложности насколько это возможно для уменьшения трудозатрат при внедрении .
В чем секрет ускорения?
Часто заблуждением является тот факт, что при покупке многопроцессорного сервера или работы с многопоточной программой все операции пользователя информационной системы распараллеливаются. Если мы говорим о конкретном сеансе пользователя с последовательным выполнением конкретного функционала приложения – то даже на многоядерном сервере не используется более одного процессора (не берем возможность распараллеливания запроса средствами MS SQL – это немного другая специфика). Таким образом, увеличение аппаратных ресурсов серверов приводит к увеличению скорости совокупной многопользовательской работы, но не увеличению линейной скорости отдельного пользователя.
В случае использования параллельных вычислений мы используем по максимуму все доступные аппаратные ресурсы серверов для увеличения линейной скорости.
Для каких ситуаций применимы параллельные вычисления?
Если бы параллельные вычисления можно было бы сделать для любой операции информационной системы (в том числе 1С), то все системы были бы адаптированы к параллельным вычислениям по умолчанию производителем. На практике существует ряд очень важных ограничений для их использования. Мы перечислим основные ограничения нашего решения:
- Запросы для параллельного выполнения должны быть полностью независимы друг от друга. Под этим понимается следующее: возвращаемые данные одного запросы не влияют на формирование текста другого.
- Нельзя/очень осторожно использовать параллельные вычисления в транзакции.
Несколько основных рисков:
- Запрос из параллельной сессии не видит измененные в транзакции данные (кроме запросов с грязным чтением).
- Запрос может накладывать блокировки на уровне MS SQL.
- Необходимость связывания с транзакцией основной сессии пользователя.
- Для уменьшения влияния меж поточного взаимодействия необходимо, чтобы предполагаемая длительность запросов была более 5 секунд.
- Реализована только для OleDB (ADO, Native) – MS SQL систем.
- Запрос для распараллеливания возвращает только одну выборку (recordset). Для систем 1С 8 – запрос может состоять из последовательности запросов (например, создание виртуальных таблиц, заполнение и прочее), запрос программы на произвольном языке (Delphi, C++ … ) состоит из одной конструкции и одной выборки.
Таким образом, наиболее реальная область применения в 1С 8 –распараллеливание запросов 1С при формировании больших отчетов и обработок. В других системах на других языках – на усмотрение программиста/архитектора.
Как проверить на практике (технология внедрения в информационную систему)?
Подробнее о технологии внедрения можно почитать: http://softpoint.ru/article_id4224.htm
Вступайте в нашу телеграмм-группу Инфостарт